 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Summarizing Differences between Text Distributions with Natural Language
Jan 28, 2022
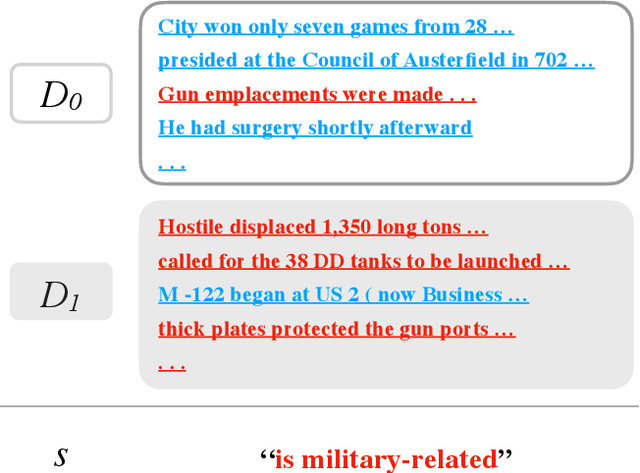


How do two distributions of texts differ? Humans are slow at answering this, since discovering patterns might require tediously reading through hundreds of samples. We propose to automatically summarize the differences by "learning a natural language hypothesis": given two distributions $D_{0}$ and $D_{1}$, we search for a description that is more often true for $D_{1}$, e.g., "is military-related." To tackle this problem, we fine-tune GPT-3 to propose descriptions with the prompt: "[samples of $D_{0}$] + [samples of $D_{1}$] + the difference between them is _____". We then re-rank the descriptions by checking how often they hold on a larger set of samples with a learned verifier. On a benchmark of 54 real-world binary classification tasks, while GPT-3 Curie (13B) only generates a description similar to human annotation 7% of the time, the performance reaches 61% with fine-tuning and re-ranking, and our best system using GPT-3 Davinci (175B) reaches 76%. We apply our system to describe distribution shifts, debug dataset shortcuts, summarize unknown tasks, and label text clusters, and present analyses based on automatically generated descriptions.
Bioinspired Cortex-based Fast Codebook Generation
Jan 28, 2022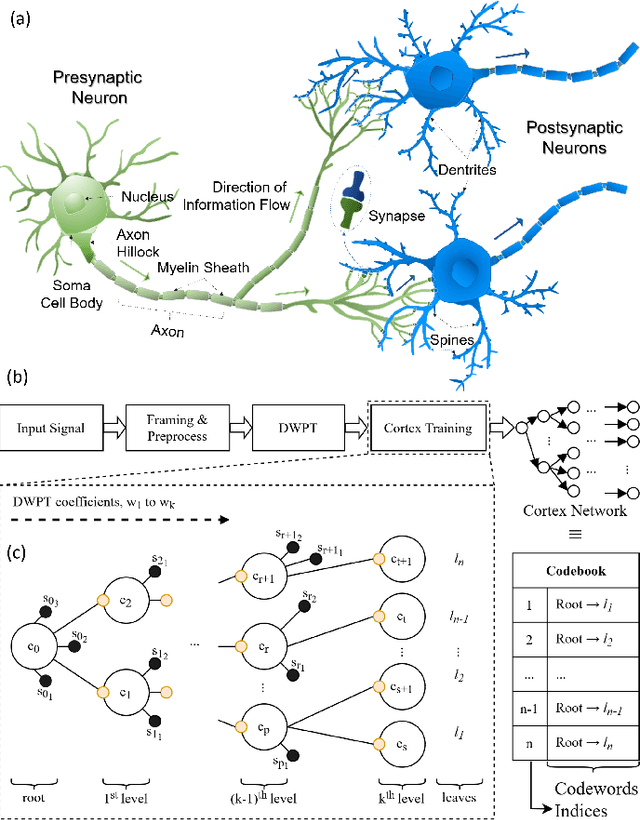
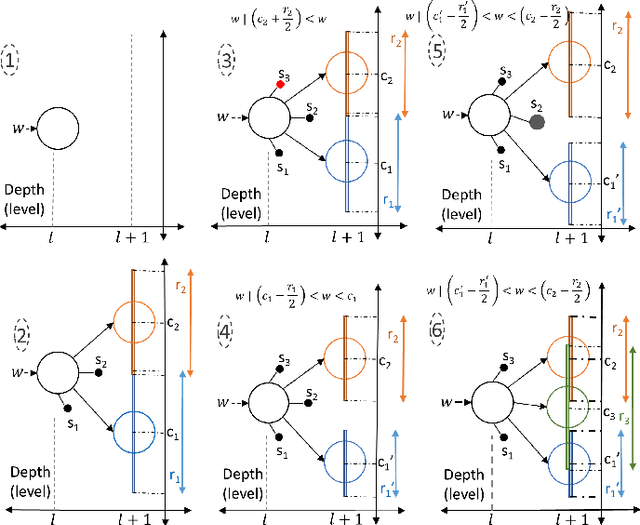
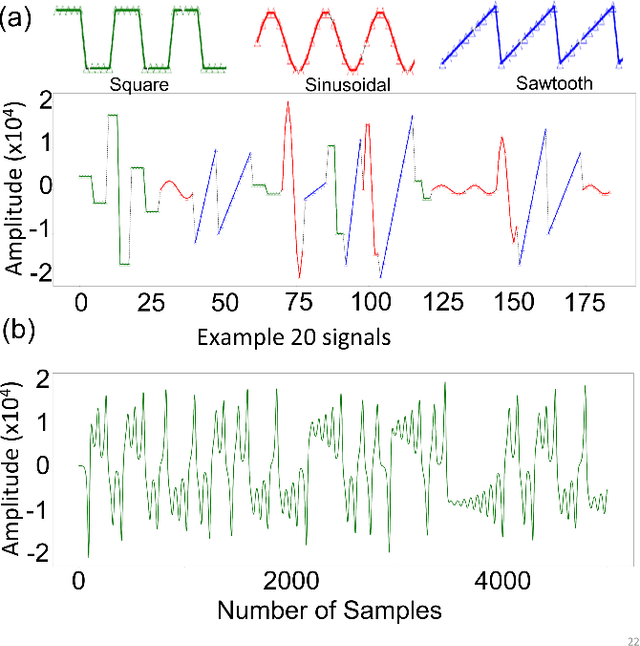
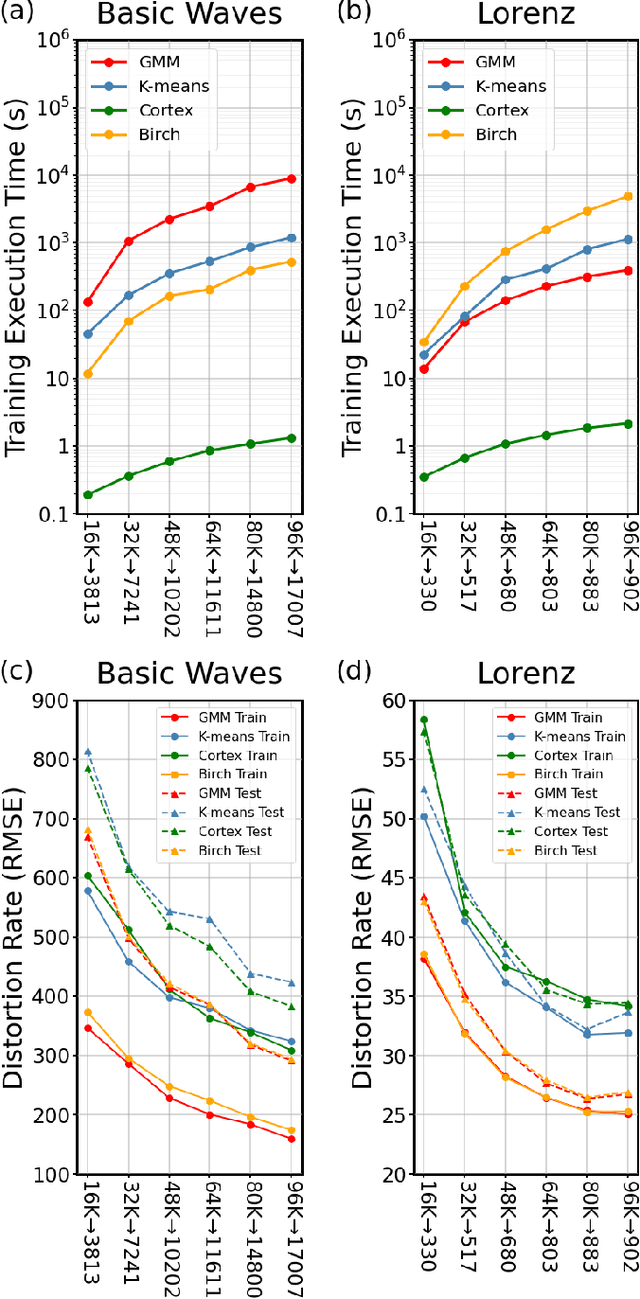
A major archetype of artificial intelligence is developing algorithms facilitating temporal efficiency and accuracy while boosting the generalization performance. Even with the latest developments in machine learning, a key limitation has been the inefficient feature extraction from the initial data, which is essential in performance optimization. Here, we introduce a feature extraction method inspired by sensory cortical networks in the brain. Dubbed as bioinspired cortex, the algorithm provides convergence to orthogonal features from streaming signals with superior computational efficiency while processing data in compressed form. We demonstrate the performance of the new algorithm using artificially created complex data by comparing it with the commonly used traditional clustering algorithms, such as Birch, GMM, and K-means. While the data processing time is significantly reduced, seconds versus hours, encoding distortions remain essentially the same in the new algorithm providing a basis for better generalization. Although we show herein the superior performance of the cortex model in clustering and vector quantization, it also provides potent implementation opportunities for machine learning fundamental components, such as reasoning, anomaly detection and classification in large scope applications, e.g., finance, cybersecurity, and healthcare.
Scheduling Servers with Stochastic Bilinear Rewards
Dec 13, 2021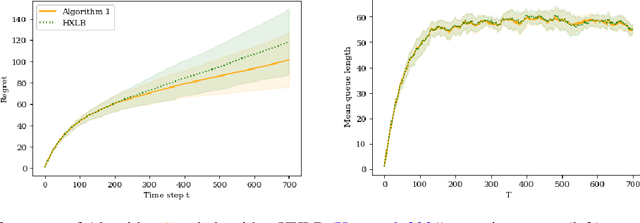
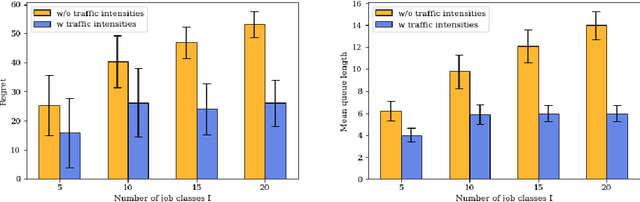
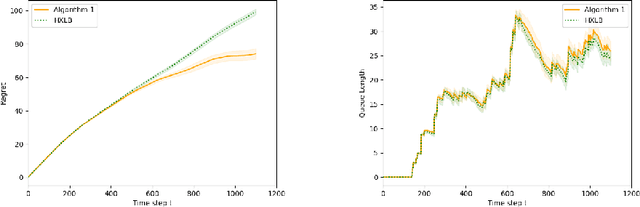
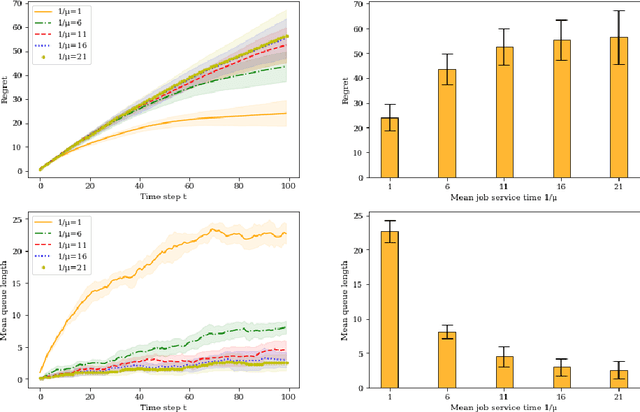
In this paper we study a multi-class, multi-server queueing system with stochastic rewards of job-server assignments following a bilinear model in feature vectors representing jobs and servers. Our goal is regret minimization against an oracle policy that has a complete information about system parameters. We propose a scheduling algorithm that uses a linear bandit algorithm along with dynamic allocation of jobs to servers. For the baseline setting, in which mean job service times are identical for all jobs, we show that our algorithm has a sub-linear regret, as well as a sub-linear bound on the mean queue length, in the horizon time. We further show that similar bounds hold under more general assumptions, allowing for non-identical mean job service times for different job classes and a time-varying set of server classes. We also show that better regret and mean queue length bounds can be guaranteed by an algorithm having access to traffic intensities of job classes. We present results of numerical experiments demonstrating how regret and mean queue length of our algorithms depend on various system parameters and compare their performance against a previously proposed algorithm using synthetic randomly generated data and a real-world cluster computing data trace.
Learning Graphon Mean Field Games and Approximate Nash Equilibria
Dec 17, 2021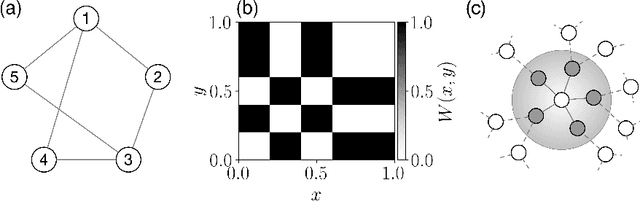
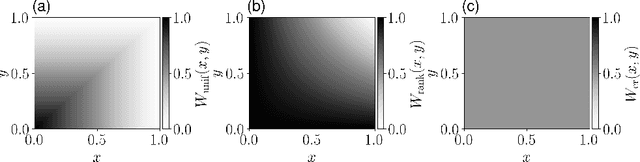
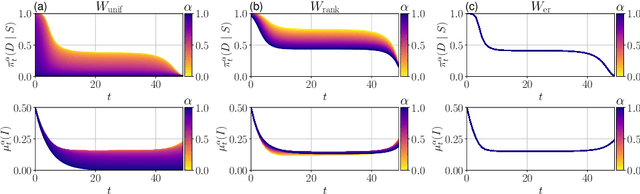
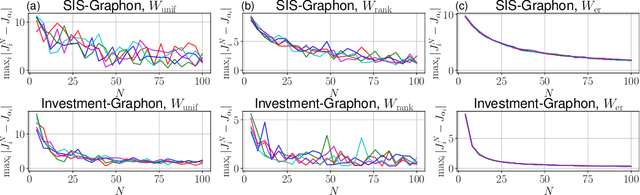
Recent advances at the intersection of dense large graph limits and mean field games have begun to enable the scalable analysis of a broad class of dynamical sequential games with large numbers of agents. So far, results have been largely limited to graphon mean field systems with continuous-time diffusive or jump dynamics, typically without control and with little focus on computational methods. We propose a novel discrete-time formulation for graphon mean field games as the limit of non-linear dense graph Markov games with weak interaction. On the theoretical side, we give extensive and rigorous existence and approximation properties of the graphon mean field solution in sufficiently large systems. On the practical side, we provide general learning schemes for graphon mean field equilibria by either introducing agent equivalence classes or reformulating the graphon mean field system as a classical mean field system. By repeatedly finding a regularized optimal control solution and its generated mean field, we successfully obtain plausible approximate Nash equilibria in otherwise infeasible large dense graph games with many agents. Empirically, we are able to demonstrate on a number of examples that the finite-agent behavior comes increasingly close to the mean field behavior for our computed equilibria as the graph or system size grows, verifying our theory. More generally, we successfully apply policy gradient reinforcement learning in conjunction with sequential Monte Carlo methods.
3D-FlowNet: Event-based optical flow estimation with 3D representation
Jan 28, 2022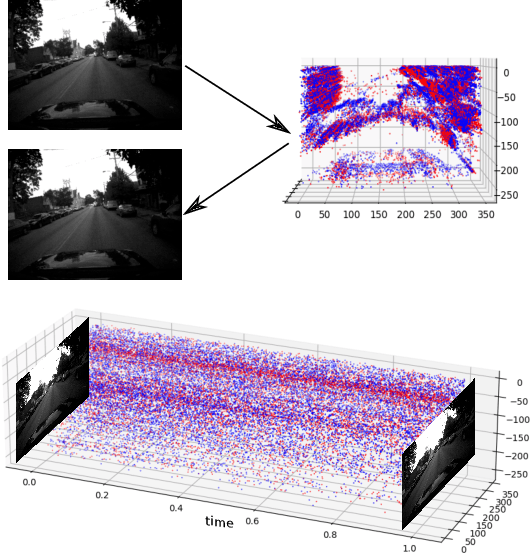
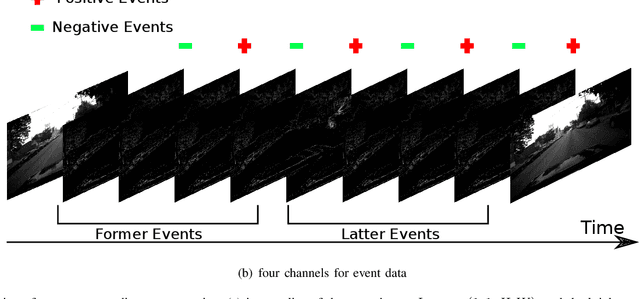
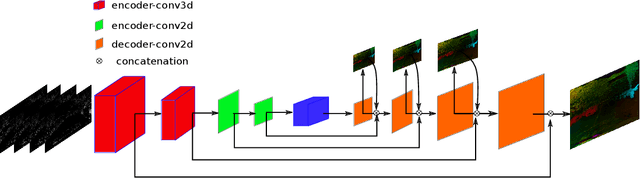

Event-based cameras can overpass frame-based cameras limitations for important tasks such as high-speed motion detection during self-driving cars navigation in low illumination conditions. The event cameras' high temporal resolution and high dynamic range, allow them to work in fast motion and extreme light scenarios. However, conventional computer vision methods, such as Deep Neural Networks, are not well adapted to work with event data as they are asynchronous and discrete. Moreover, the traditional 2D-encoding representation methods for event data, sacrifice the time resolution. In this paper, we first improve the 2D-encoding representation by expanding it into three dimensions to better preserve the temporal distribution of the events. We then propose 3D-FlowNet, a novel network architecture that can process the 3D input representation and output optical flow estimations according to the new encoding methods. A self-supervised training strategy is adopted to compensate the lack of labeled datasets for the event-based camera. Finally, the proposed network is trained and evaluated with the Multi-Vehicle Stereo Event Camera (MVSEC) dataset. The results show that our 3D-FlowNet outperforms state-of-the-art approaches with less training epoch (30 compared to 100 of Spike-FlowNet).
Robophysical modeling of spacetime dynamics
Feb 10, 2022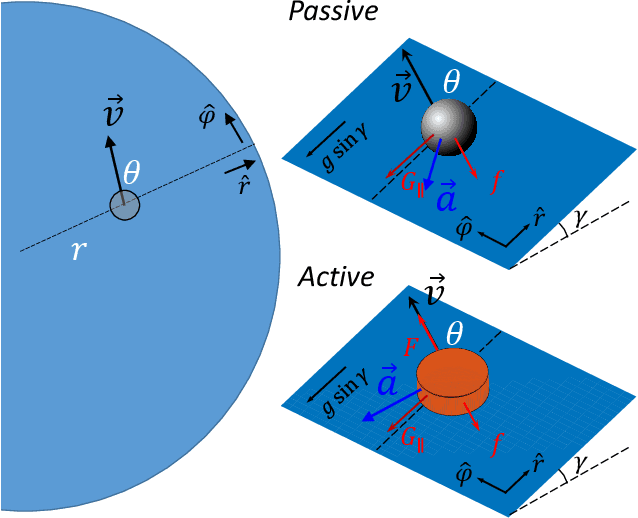
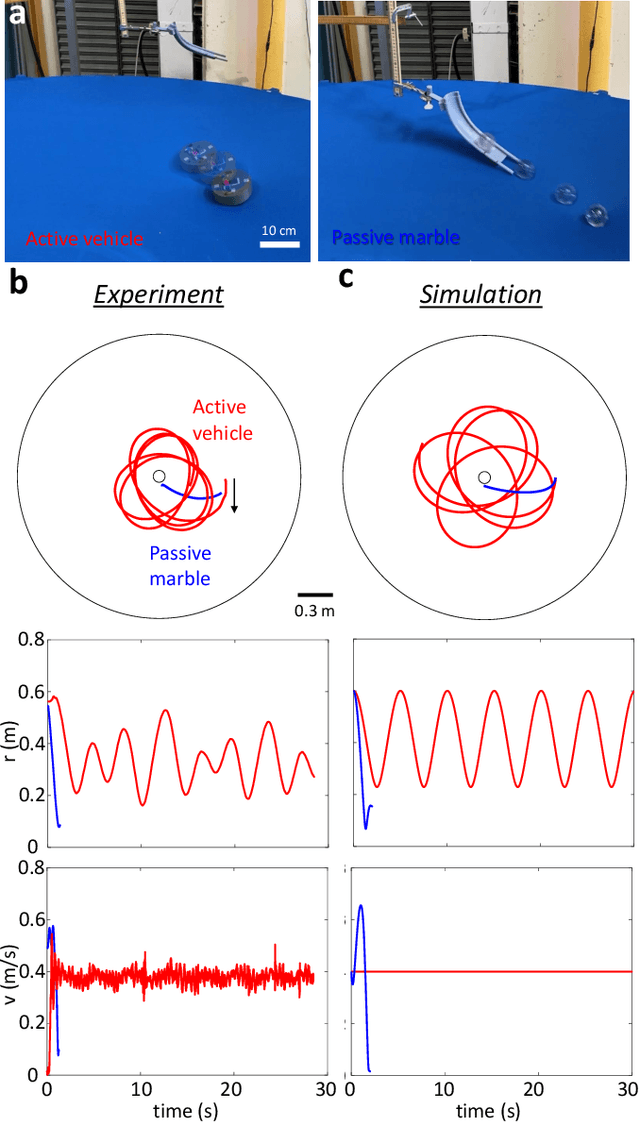
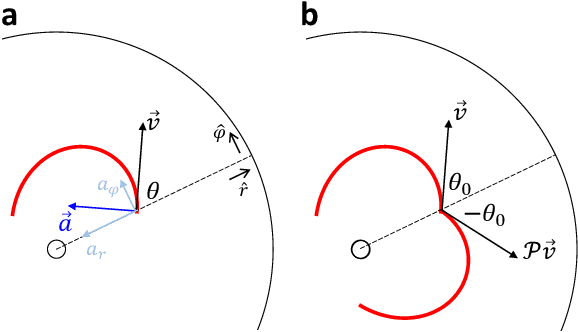
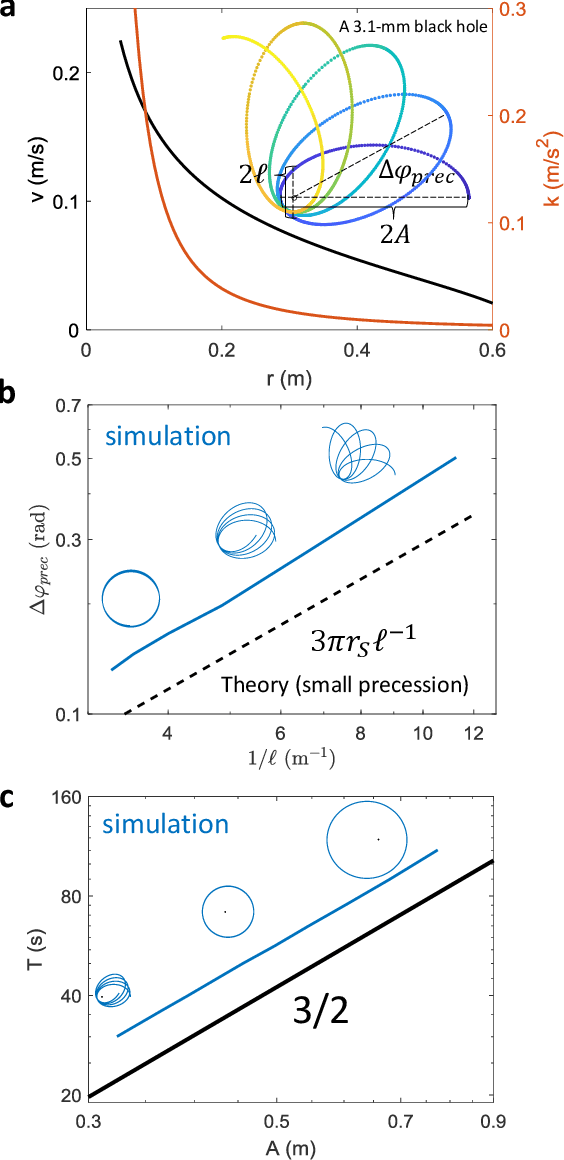
Systems consisting of spheres rolling on elastic membranes have been used as educational tools to introduce a core conceptual idea of General Relativity (GR): how curvature guides the movement of matter. However, previous studies have revealed that such schemes cannot accurately represent relativistic dynamics in the laboratory. Dissipative forces cause the initially GR-like dynamics to be transient and consequently restrict experimental study to only the beginnings of trajectories; dominance of Earth's gravity forbids the difference between spatial and temporal spacetime curvatures. Here by developing a mapping between dynamics of a wheeled vehicle on a spandex membrane, we demonstrate that an active object that can prescribe its speed can not only obtain steady-state orbits, but also use the additional parameters such as speed to tune the orbits towards relativistic dynamics. Our mapping demonstrates how activity mixes space and time in a metric, shows how active particles do not necessarily follow geodesics in the real space but instead follow geodesics in a fiducial spacetime. The mapping further reveals how parameters such as the membrane elasticity and instantaneous speed allow programming a desired spacetime such as the Schwarzschild metric near a non-rotating black hole. Our mapping and framework point the way to the possibility to create a robophysical analog gravity system in the laboratory at low cost and provide insights into active matter in deformable environments and robot exploration in complex landscapes.
SDT-DCSCN for Simultaneous Super-Resolution and Deblurring of Text Images
Jan 15, 2022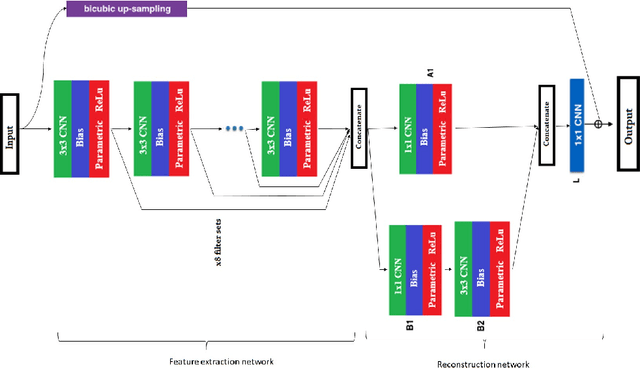
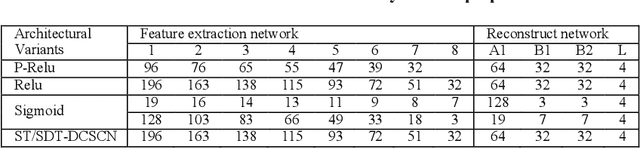
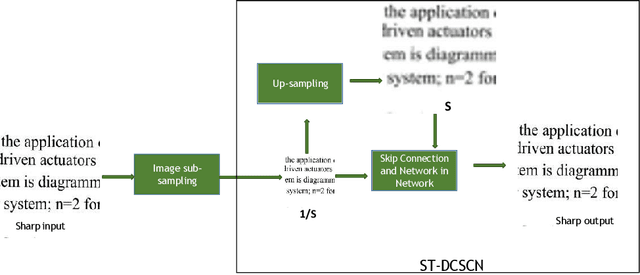
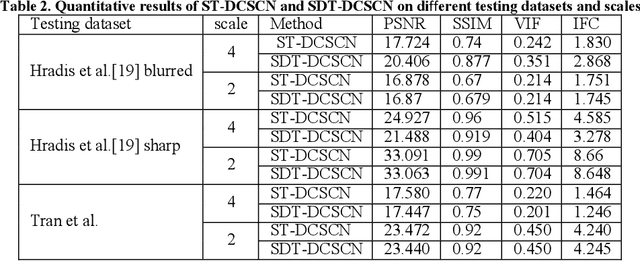
Deep convolutional neural networks (Deep CNN) have achieved hopeful performance for single image super-resolution. In particular, the Deep CNN skip Connection and Network in Network (DCSCN) architecture has been successfully applied to natural images super-resolution. In this work we propose an approach called SDT-DCSCN that jointly performs super-resolution and deblurring of low-resolution blurry text images based on DCSCN. Our approach uses subsampled blurry images in the input and original sharp images as ground truth. The used architecture is consists of a higher number of filters in the input CNN layer to a better analysis of the text details. The quantitative and qualitative evaluation on different datasets prove the high performance of our model to reconstruct high-resolution and sharp text images. In addition, in terms of computational time, our proposed method gives competitive performance compared to state of the art methods.
DiPS: Differentiable Policy for Sketching in Recommender Systems
Dec 08, 2021

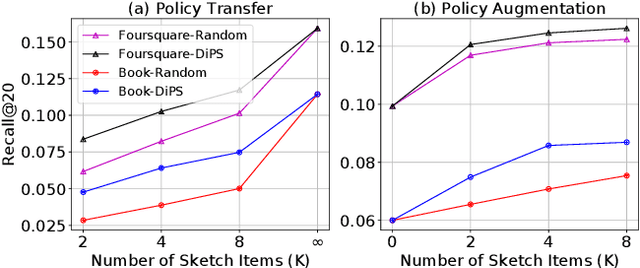
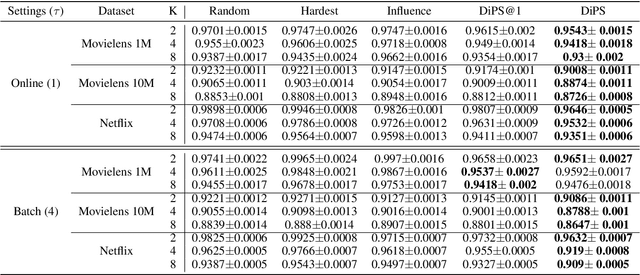
In sequential recommender system applications, it is important to develop models that can capture users' evolving interest over time to successfully recommend future items that they are likely to interact with. For users with long histories, typical models based on recurrent neural networks tend to forget important items in the distant past. Recent works have shown that storing a small sketch of past items can improve sequential recommendation tasks. However, these works all rely on static sketching policies, i.e., heuristics to select items to keep in the sketch, which are not necessarily optimal and cannot improve over time with more training data. In this paper, we propose a differentiable policy for sketching (DiPS), a framework that learns a data-driven sketching policy in an end-to-end manner together with the recommender system model to explicitly maximize recommendation quality in the future. We also propose an approximate estimator of the gradient for optimizing the sketching algorithm parameters that is computationally efficient. We verify the effectiveness of DiPS on real-world datasets under various practical settings and show that it requires up to $50\%$ fewer sketch items to reach the same predictive quality than existing sketching policies.
Stochastic optimization in digital pre-distortion of the signal
Jan 28, 2022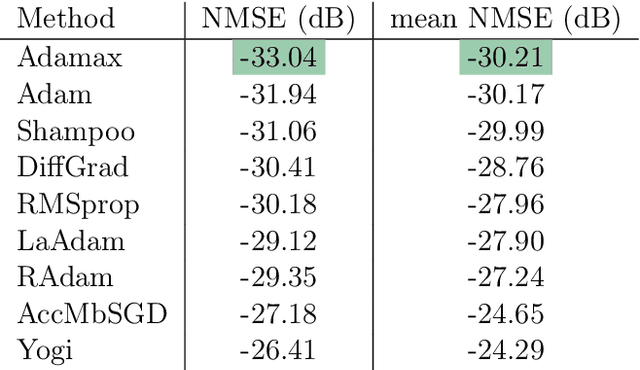
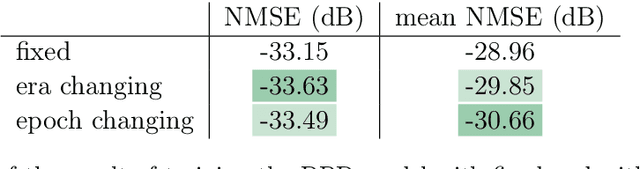
In this paper, we test the performance of some modern stochastic optimization methods and practices in application to digital pre-distortion problem, that is a valuable part of processing signal on base stations providing wireless communication. In first part of our study, we focus on search of the best performing method and its proper modifications. In the second part, we proposed the new, quasi-online, testing framework that allows us to fit our modelling results with the behaviour of real-life DPD prototype, retested some selected of practices considered in previous section and approved the advantages of the method occured to be the best in real-life conditions. For the used model, maximum achieved improvement in depth was 7% in standard regime and 5% in online one (metric itself is of logarithmic scale). We also achieved a halving of the working time preserving 3% and 6% improvement in depth for the standard and online regime, correspondingly. All comparisons are made to the Adam method, which was highlighted as the best stochastic method for DPD problem in paper [Pasechnyuk et al., 2021], and to the Adamax method, that is the best in the proposed online regime.
Surrogate-assisted distributed swarm optimisation for computationally expensive models
Jan 18, 2022Advances in parallel and distributed computing have enabled efficient implementation of the distributed swarm and evolutionary algorithms for complex and computationally expensive models. Evolutionary algorithms provide gradient-free optimisation which is beneficial for models that do not have such information available, for instance, geoscientific landscape evolution models. However, such models are so computationally expensive that even distributed swarm and evolutionary algorithms with the power of parallel computing struggle. We need to incorporate efficient strategies such as surrogate assisted optimisation that further improves their performance; however, this becomes a challenge given parallel processing and inter-process communication for implementing surrogate training and prediction. In this paper, we implement surrogate-based estimation of fitness evaluation in distributed swarm optimisation over a parallel computing architecture. Our results demonstrate very promising results for benchmark functions and geoscientific landscape evolution models. We obtain a reduction in computationally time while retaining optimisation solution accuracy through the use of surrogates in a parallel computing environment.