 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RailLoMer: Rail Vehicle Localization and Mapping with LiDAR-IMU-Odometer-GNSS Data Fusion
Nov 30, 2021

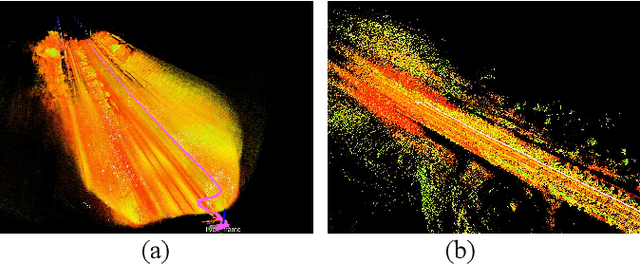
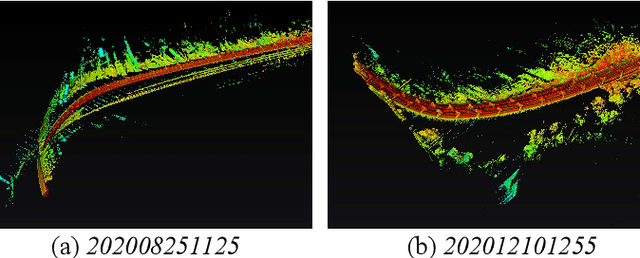
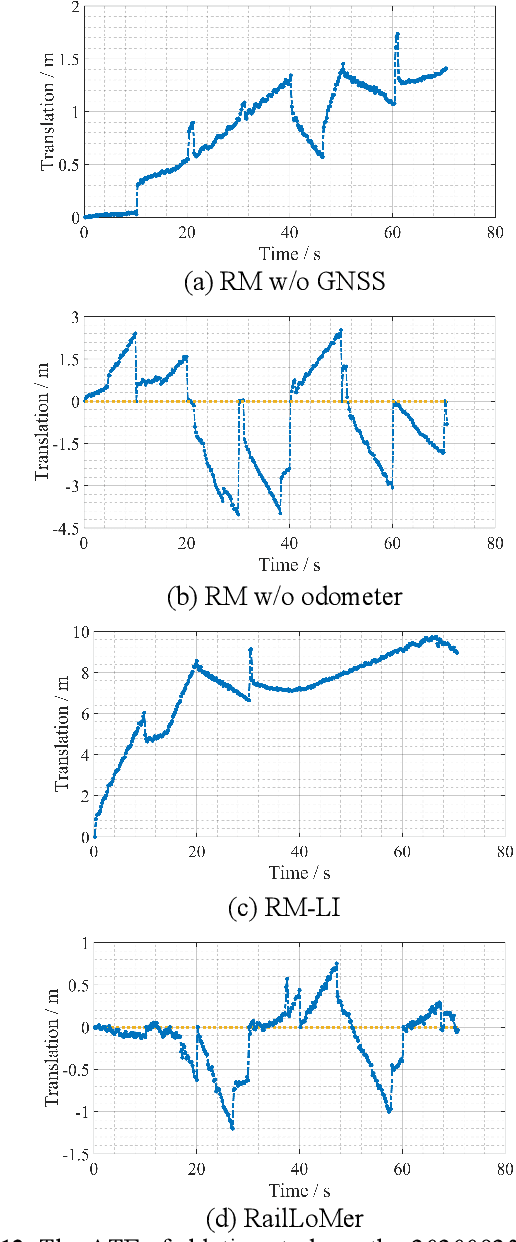
We present RailLoMer in this article, to achieve real-time accurate and robust odometry and mapping for rail vehicles. RailLoMer receives measurements from two LiDARs, an IMU, train odometer, and a global navigation satellite system (GNSS) receiver. As frontend, the estimated motion from IMU/odometer preintegration de-skews the denoised point clouds and produces initial guess for frame-to-frame LiDAR odometry. As backend, a sliding window based factor graph is formulated to jointly optimize multi-modal information. In addition, we leverage the plane constraints from extracted rail tracks and the structure appearance descriptor to further improve the system robustness against repetitive structures. To ensure a globally-consistent and less blurry mapping result, we develop a two-stage mapping method that first performs scan-to-map in local scale, then utilizes the GNSS information to register the submaps. The proposed method is extensively evaluated on datasets gathered for a long time range over numerous scales and scenarios, and show that RailLoMer delivers decimeter-grade localization accuracy even in large or degenerated environments. We also integrate RailLoMer into an interactive train state and railway monitoring system prototype design, which has already been deployed to an experimental freight traffic railroad.
Compute, Time and Energy Characterization of Encoder-Decoder Networks with Automatic Mixed Precision Training
Aug 18, 2020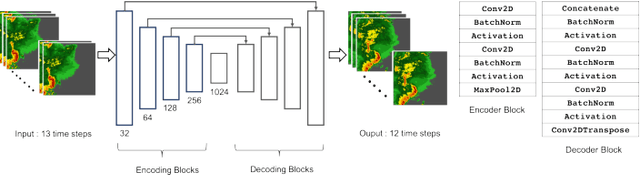
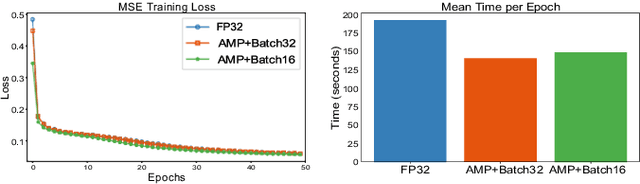
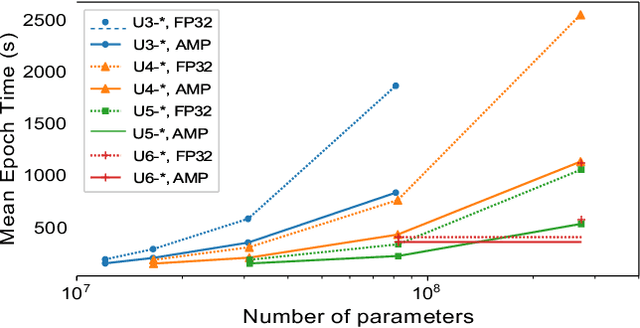
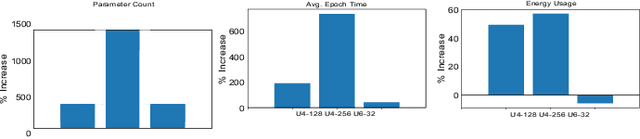
Deep neural networks have shown great success in many diverse fields. The training of these networks can take significant amounts of time, compute and energy. As datasets get larger and models become more complex, the exploration of model architectures becomes prohibitive. In this paper we examine the compute, energy and time costs of training a UNet based deep neural network for the problem of predicting short term weather forecasts (called precipitation Nowcasting). By leveraging a combination of data distributed and mixed-precision training, we explore the design space for this problem. We also show that larger models with better performance come at a potentially incremental cost if appropriate optimizations are used. We show that it is possible to achieve a significant improvement in training time by leveraging mixed-precision training without sacrificing model performance. Additionally, we find that a 1549% increase in the number of trainable parameters for a network comes at a relatively smaller 63.22% increase in energy usage for a UNet with 4 encoding layers.
Enhancement or Super-Resolution: Learning-based Adaptive Video Streaming with Client-Side Video Processing
Jan 20, 2022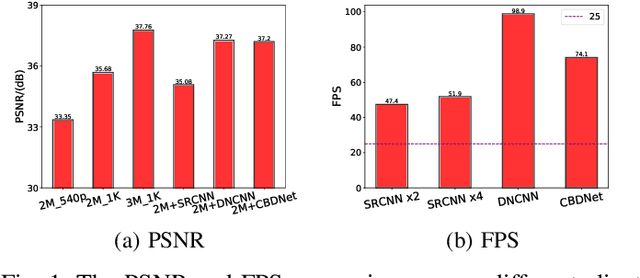
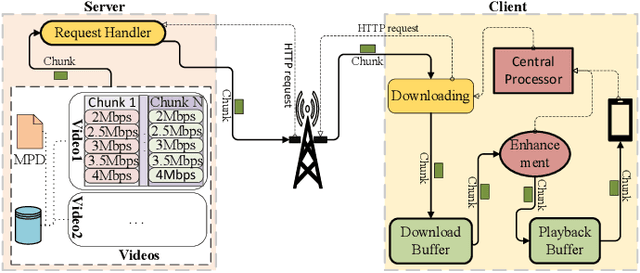
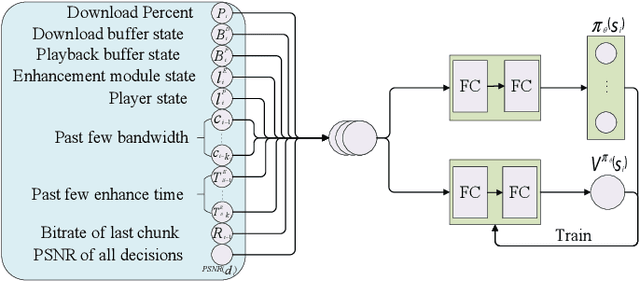
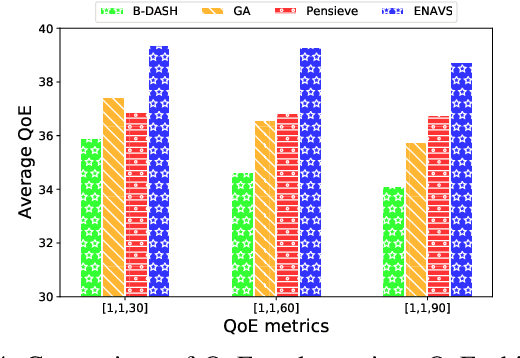
The rapid development of multimedia and communication technology has resulted in an urgent need for high-quality video streaming. However, robust video streaming under fluctuating network conditions and heterogeneous client computing capabilities remains a challenge. In this paper, we consider an enhancement-enabled video streaming network under a time-varying wireless network and limited computation capacity. "Enhancement" means that the client can improve the quality of the downloaded video segments via image processing modules. We aim to design a joint bitrate adaptation and client-side enhancement algorithm toward maximizing the quality of experience (QoE). We formulate the problem as a Markov decision process (MDP) and propose a deep reinforcement learning (DRL)-based framework, named ENAVS. As video streaming quality is mainly affected by video compression, we demonstrate that the video enhancement algorithm outperforms the super-resolution algorithm in terms of signal-to-noise ratio and frames per second, suggesting a better solution for client processing in video streaming. Ultimately, we implement ENAVS and demonstrate extensive testbed results under real-world bandwidth traces and videos. The simulation shows that ENAVS is capable of delivering 5%-14% more QoE under the same bandwidth and computing power conditions as conventional ABR streaming.
Why-So-Deep: Towards Boosting Previously Trained Models for Visual Place Recognition
Jan 10, 2022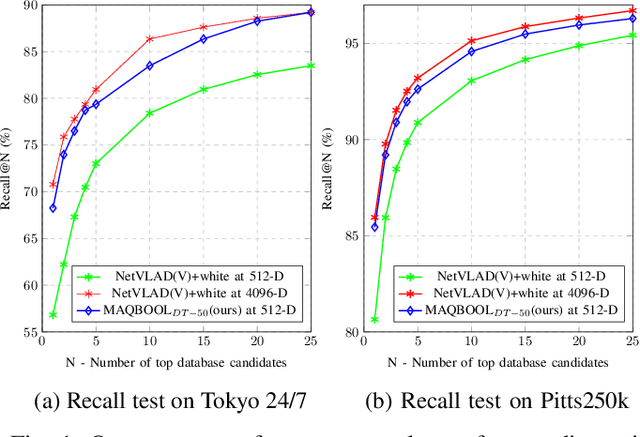

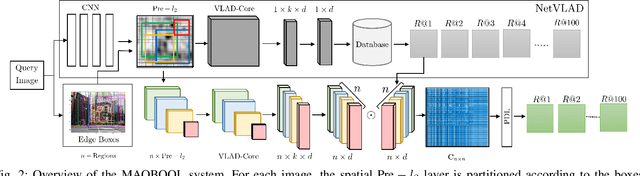

Deep learning-based image retrieval techniques for the loop closure detection demonstrate satisfactory performance. However, it is still challenging to achieve high-level performance based on previously trained models in different geographical regions. This paper addresses the problem of their deployment with simultaneous localization and mapping (SLAM) systems in the new environment. The general baseline approach uses additional information, such as GPS, sequential keyframes tracking, and re-training the whole environment to enhance the recall rate. We propose a novel approach for improving image retrieval based on previously trained models. We present an intelligent method, MAQBOOL, to amplify the power of pre-trained models for better image recall and its application to real-time multiagent SLAM systems. We achieve comparable image retrieval results at a low descriptor dimension (512-D), compared to the high descriptor dimension (4096-D) of state-of-the-art methods. We use spatial information to improve the recall rate in image retrieval on pre-trained models.
Machine learning time series regressions with an application to nowcasting
May 28, 2020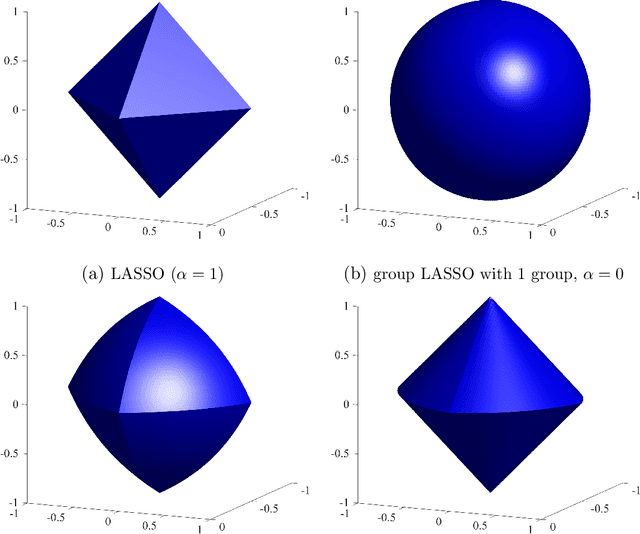

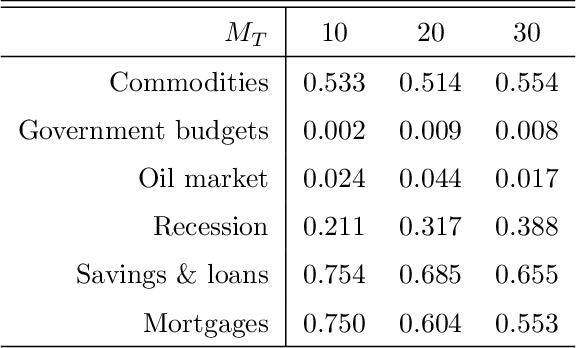
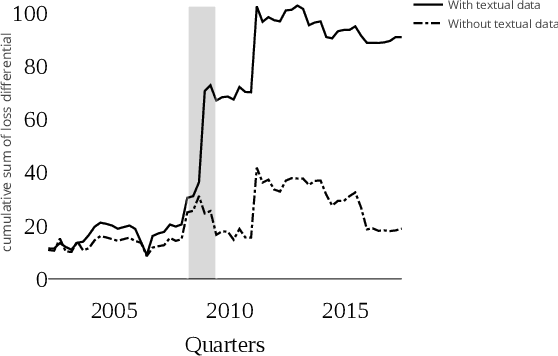
This paper introduces structured machine learning regressions for high-dimensional time series data potentially sampled at different frequencies. The sparse-group LASSO estimator can take advantage of such time series data structures and outperforms the unstructured LASSO. We establish oracle inequalities for the sparse-group LASSO estimator within a framework that allows for the mixing processes and recognizes that the financial and the macroeconomic data may have heavier than exponential tails. An empirical application to nowcasting US GDP growth indicates that the estimator performs favorably compared to other alternatives and that the text data can be a useful addition to more traditional numerical data.
Crop mapping from image time series: deep learning with multi-scale label hierarchies
Feb 17, 2021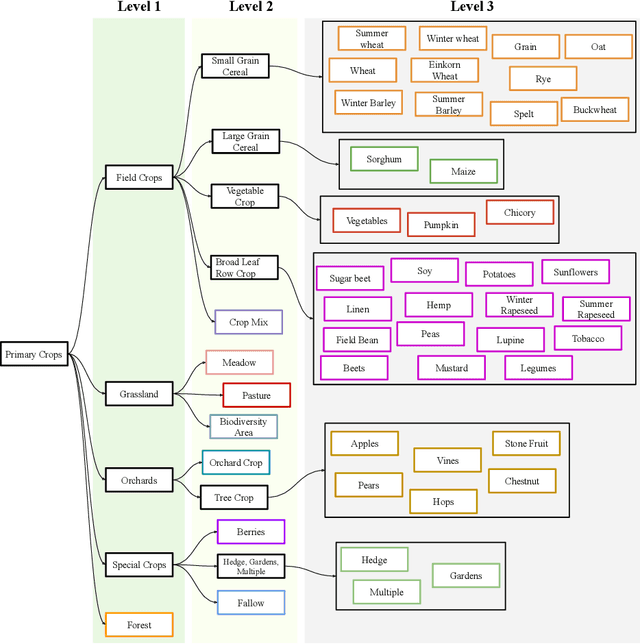
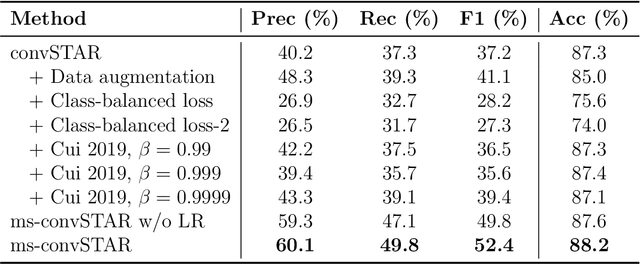
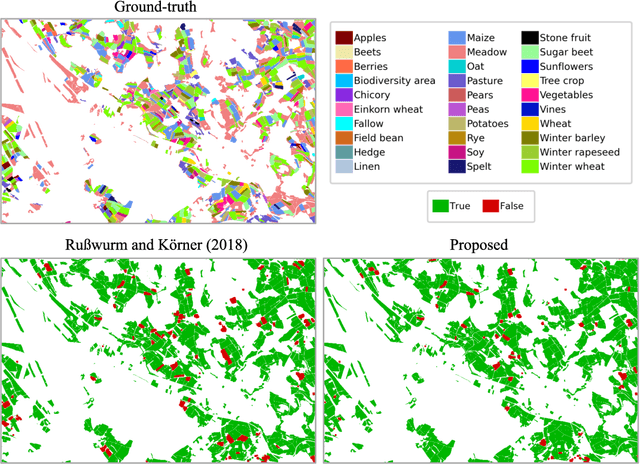
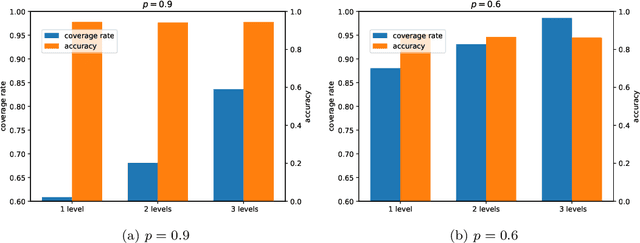
The aim of this paper is to map agricultural crops by classifying satellite image time series. Domain experts in agriculture work with crop type labels that are organised in a hierarchical tree structure, where coarse classes (like orchards) are subdivided into finer ones (like apples, pears, vines, etc.). We develop a crop classification method that exploits this expert knowledge and significantly improves the mapping of rare crop types. The three-level label hierarchy is encoded in a convolutional, recurrent neural network (convRNN), such that for each pixel the model predicts three labels at different level of granularity. This end-to-end trainable, hierarchical network architecture allows the model to learn joint feature representations of rare classes (e.g., apples, pears) at a coarser level (e.g., orchard), thereby boosting classification performance at the fine-grained level. Additionally, labelling at different granularity also makes it possible to adjust the output according to the classification scores; as coarser labels with high confidence are sometimes more useful for agricultural practice than fine-grained but very uncertain labels. We validate the proposed method on a new, large dataset that we make public. ZueriCrop covers an area of 50 km x 48 km in the Swiss cantons of Zurich and Thurgau with a total of 116'000 individual fields spanning 48 crop classes, and 28,000 (multi-temporal) image patches from Sentinel-2. We compare our proposed hierarchical convRNN model with several baselines, including methods designed for imbalanced class distributions. The hierarchical approach performs superior by at least 9.9 percentage points in F1-score.
Differentiable and Scalable Generative Adversarial Models for Data Imputation
Jan 10, 2022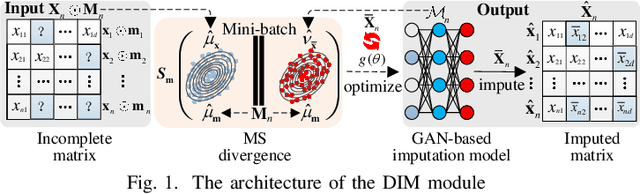
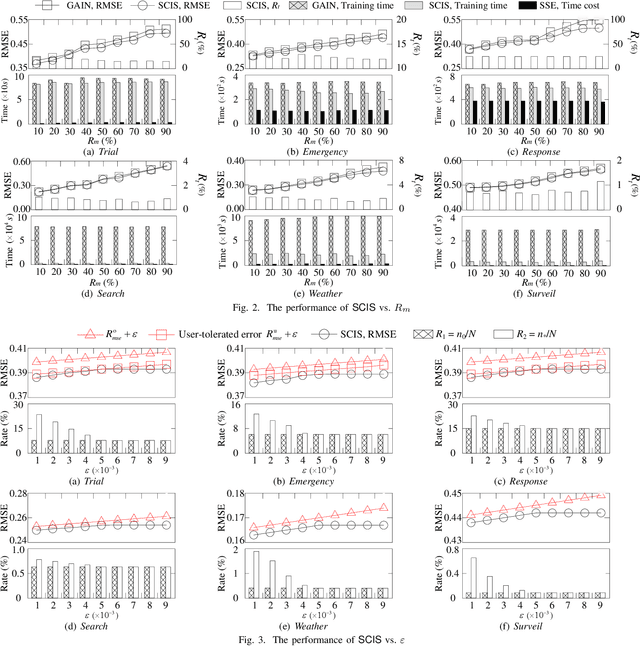
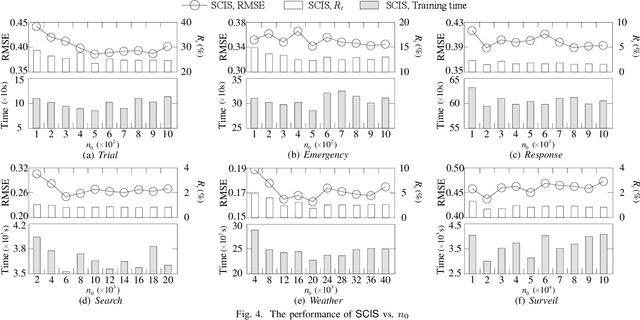
Data imputation has been extensively explored to solve the missing data problem. The dramatically increasing volume of incomplete data makes the imputation models computationally infeasible in many real-life applications. In this paper, we propose an effective scalable imputation system named SCIS to significantly speed up the training of the differentiable generative adversarial imputation models under accuracy-guarantees for large-scale incomplete data. SCIS consists of two modules, differentiable imputation modeling (DIM) and sample size estimation (SSE). DIM leverages a new masking Sinkhorn divergence function to make an arbitrary generative adversarial imputation model differentiable, while for such a differentiable imputation model, SSE can estimate an appropriate sample size to ensure the user-specified imputation accuracy of the final model. Extensive experiments upon several real-life large-scale datasets demonstrate that, our proposed system can accelerate the generative adversarial model training by 7.1x. Using around 7.6% samples, SCIS yields competitive accuracy with the state-of-the-art imputation methods in a much shorter computation time.
Multi-Airport Delay Prediction with Transformers
Nov 04, 2021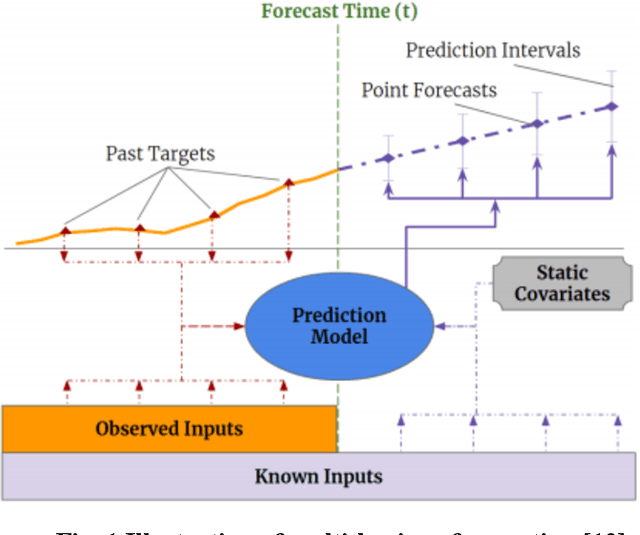
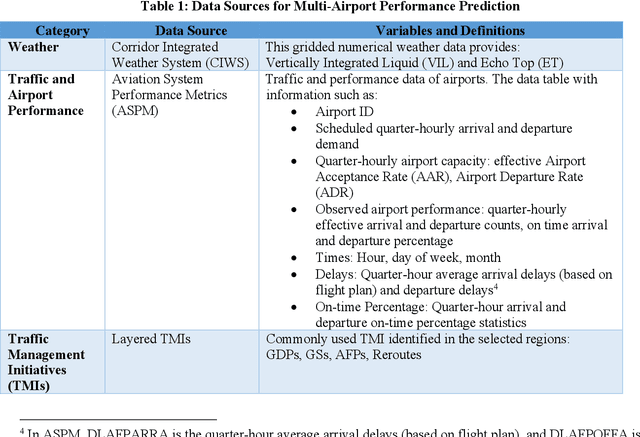
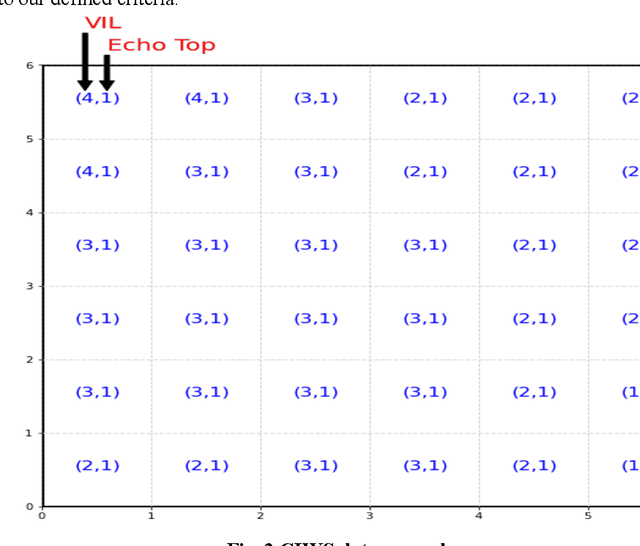
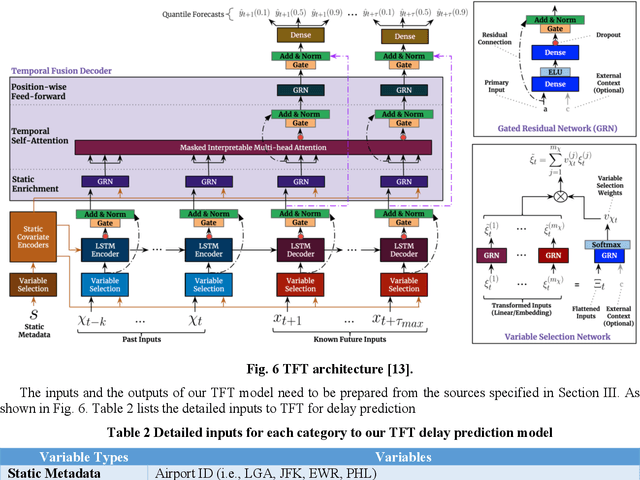
Airport performance prediction with a reasonable look-ahead time is a challenging task and has been attempted by various prior research. Traffic, demand, weather, and traffic management actions are all critical inputs to any prediction model. In this paper, a novel approach based on Temporal Fusion Transformer (TFT) was proposed to predict departure and arrival delays simultaneously for multiple airports at once. This approach can capture complex temporal dynamics of the inputs known at the time of prediction and then forecast selected delay metrics up to four hours into the future. When dealing with weather inputs, a self-supervised learning (SSL) model was developed to encode high-dimensional weather data into a much lower-dimensional representation to make the training of TFT more efficiently and effectively. The initial results show that the TFT-based delay prediction model achieves satisfactory performance measured by smaller prediction errors on a testing dataset. In addition, the interpretability analysis of the model outputs identifies the important input factors for delay prediction. The proposed approach is expected to help air traffic managers or decision makers gain insights about traffic management actions on delay mitigation and once operationalized, provide enough lead time to plan for predicted performance degradation.
Assessing Post-editing Effort in the English-Hindi Direction
Dec 18, 2021
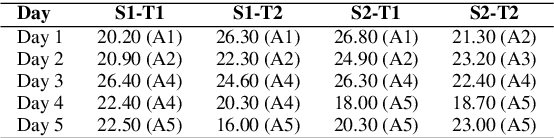
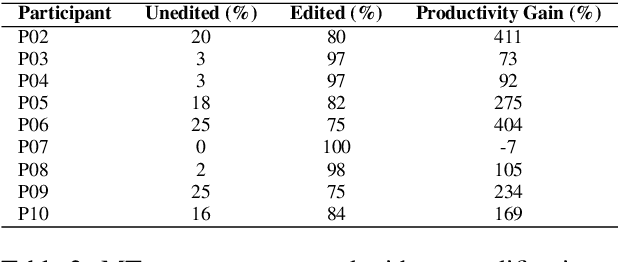
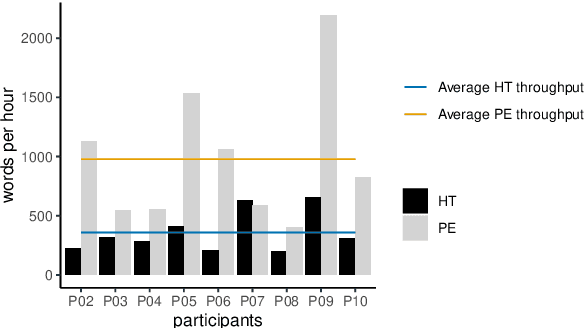
We present findings from a first in-depth post-editing effort estimation study in the English-Hindi direction along multiple effort indicators. We conduct a controlled experiment involving professional translators, who complete assigned tasks alternately, in a translation from scratch and a post-edit condition. We find that post-editing reduces translation time (by 63%), utilizes fewer keystrokes (by 59%), and decreases the number of pauses (by 63%) when compared to translating from scratch. We further verify the quality of translations thus produced via a human evaluation task in which we do not detect any discernible quality differences.
Learn to Generate Time Series Conditioned Graphs with Generative Adversarial Nets
Mar 03, 2020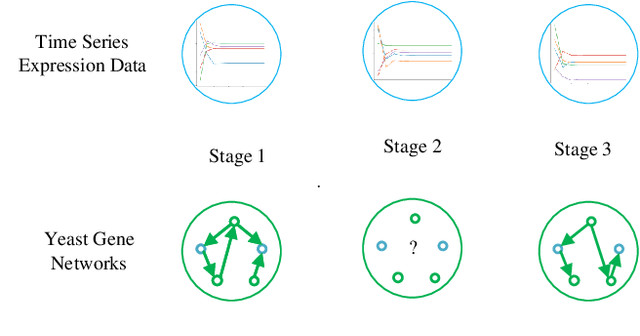
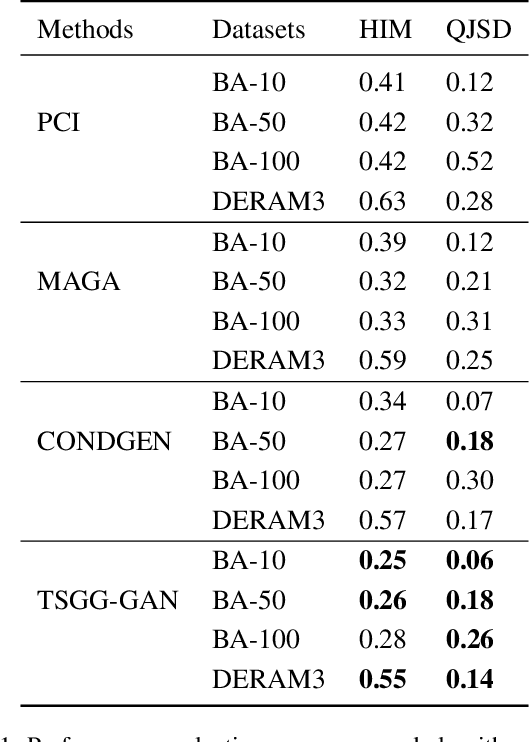
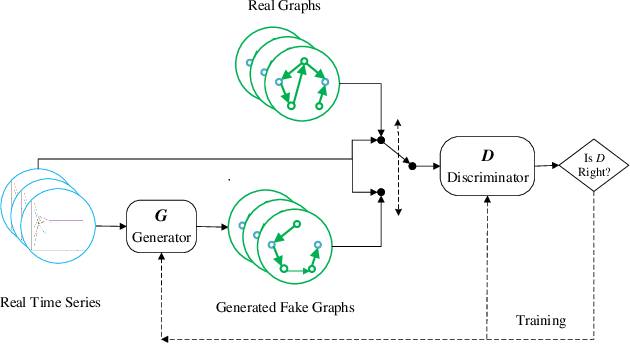
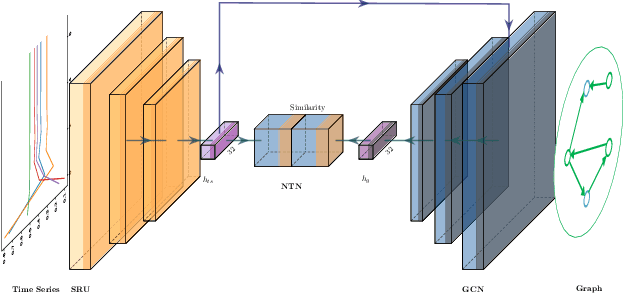
Deep learning based approaches have been utilized to model and generate graphs subjected to different distributions recently. However, they are typically unsupervised learning based and unconditioned generative models or simply conditioned on the graph-level contexts, which are not associated with rich semantic node-level contexts. Differently, in this paper, we are interested in a novel problem named Time Series Conditioned Graph Generation: given an input multivariate time series, we aim to infer a target relation graph modeling the underlying interrelationships between time series with each node corresponding to each time series. For example, we can study the interrelationships between genes in a gene regulatory network of a certain disease conditioned on their gene expression data recorded as time series. To achieve this, we propose a novel Time Series conditioned Graph Generation-Generative Adversarial Networks (TSGG-GAN) to handle challenges of rich node-level context structures conditioning and measuring similarities directly between graphs and time series. Extensive experiments on synthetic and real-word gene regulatory networks datasets demonstrate the effectiveness and generalizability of the proposed TSGG-GAN.