 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Nash Convergence of Mean-Based Learning Algorithms in First Price Auctions
Oct 08, 2021
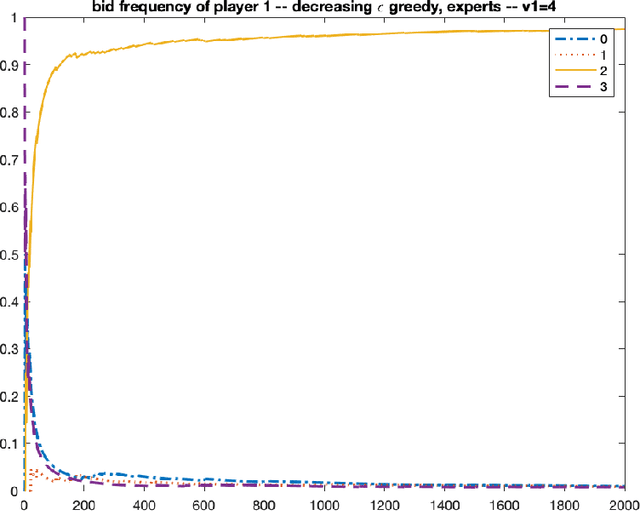
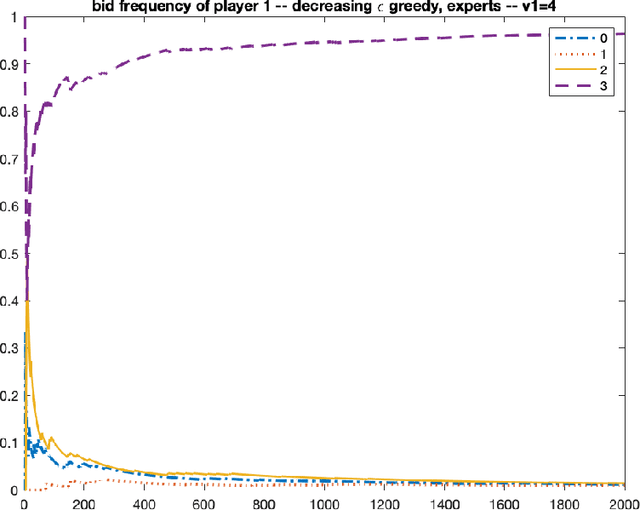
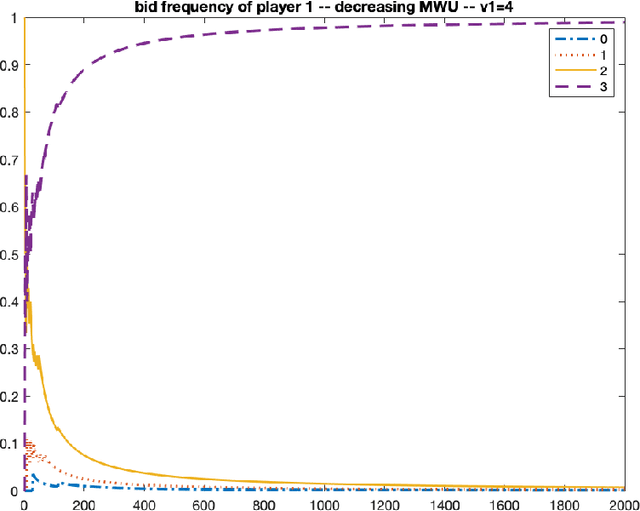
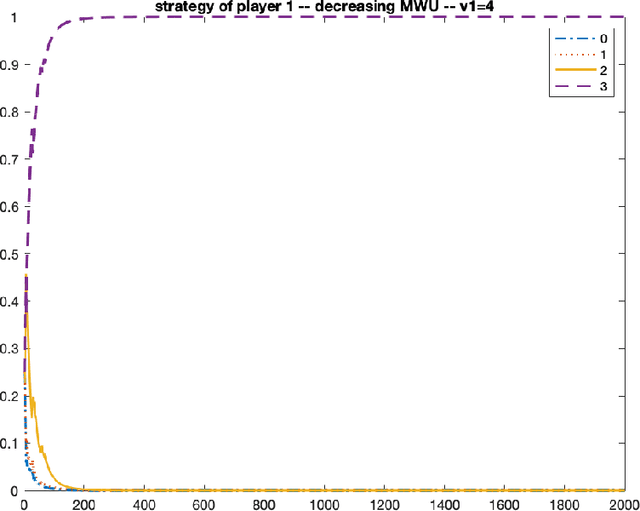
We consider repeated first price auctions where each bidder, having a deterministic type, learns to bid using a mean-based learning algorithm. We completely characterize the Nash convergence property of the bidding dynamics in two senses: (1) time-average: the fraction of rounds where bidders play a Nash equilibrium approaches to 1 in the limit; (2) last-iterate: the mixed strategy profile of bidders approaches to a Nash equilibrium in the limit. Specifically, the results depend on the number of bidders with the highest value: - If the number is at least three, the bidding dynamics almost surely converges to a Nash equilibrium of the auction, both in time-average and in last-iterate. - If the number is two, the bidding dynamics almost surely converges to a Nash equilibrium in time-average but not necessarily in last-iterate. - If the number is one, the bidding dynamics may not converge to a Nash equilibrium in time-average nor in last-iterate. Our discovery opens up new possibilities in the study of convergence dynamics of learning algorithms.
Microdosing: Knowledge Distillation for GAN based Compression
Jan 07, 2022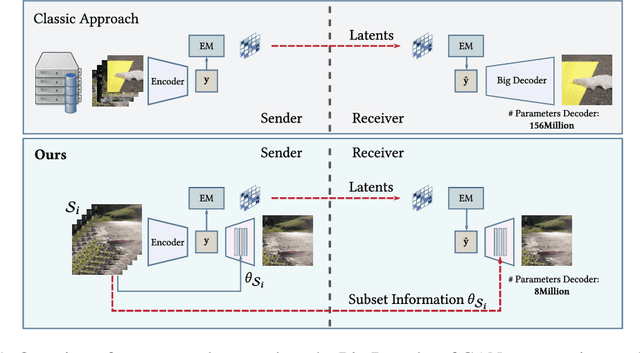
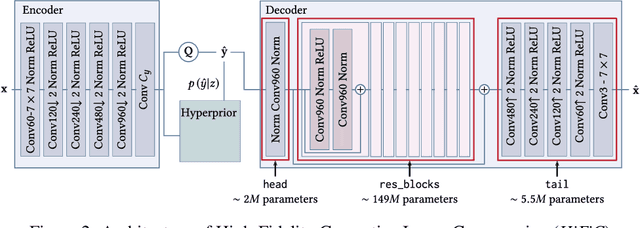
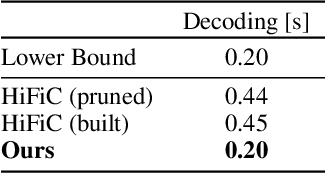

Recently, significant progress has been made in learned image and video compression. In particular the usage of Generative Adversarial Networks has lead to impressive results in the low bit rate regime. However, the model size remains an important issue in current state-of-the-art proposals and existing solutions require significant computation effort on the decoding side. This limits their usage in realistic scenarios and the extension to video compression. In this paper, we demonstrate how to leverage knowledge distillation to obtain equally capable image decoders at a fraction of the original number of parameters. We investigate several aspects of our solution including sequence specialization with side information for image coding. Finally, we also show how to transfer the obtained benefits into the setting of video compression. Overall, this allows us to reduce the model size by a factor of 20 and to achieve 50% reduction in decoding time.
Unobserved Local Structures Make Compositional Generalization Hard
Jan 15, 2022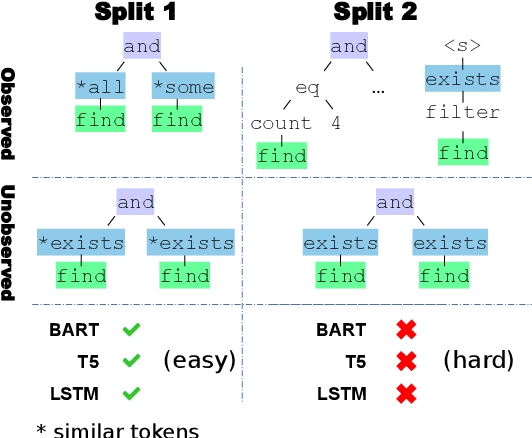

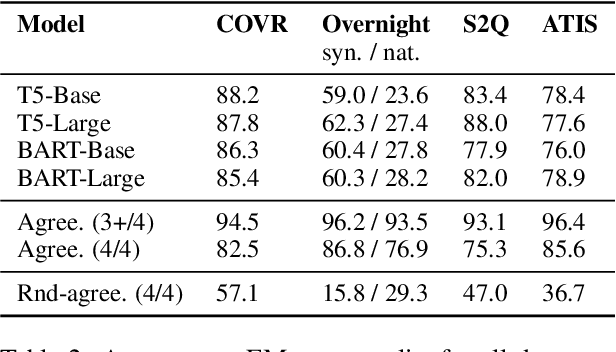
While recent work has convincingly showed that sequence-to-sequence models struggle to generalize to new compositions (termed compositional generalization), little is known on what makes compositional generalization hard on a particular test instance. In this work, we investigate what are the factors that make generalization to certain test instances challenging. We first substantiate that indeed some examples are more difficult than others by showing that different models consistently fail or succeed on the same test instances. Then, we propose a criterion for the difficulty of an example: a test instance is hard if it contains a local structure that was not observed at training time. We formulate a simple decision rule based on this criterion and empirically show it predicts instance-level generalization well across 5 different semantic parsing datasets, substantially better than alternative decision rules. Last, we show local structures can be leveraged for creating difficult adversarial compositional splits and also to improve compositional generalization under limited training budgets by strategically selecting examples for the training set.
SPIRAL: Self-supervised Perturbation-Invariant Representation Learning for Speech Pre-Training
Jan 29, 2022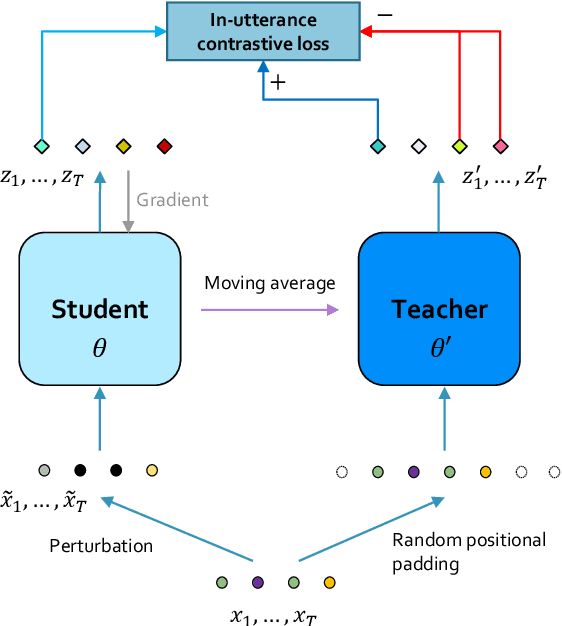
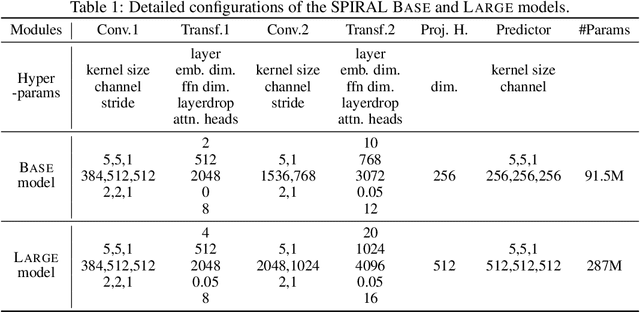


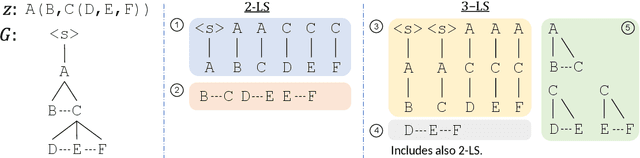
We introduce a new approach for speech pre-training named SPIRAL which works by learning denoising representation of perturbed data in a teacher-student framework. Specifically, given a speech utterance, we first feed the utterance to a teacher network to obtain corresponding representation. Then the same utterance is perturbed and fed to a student network. The student network is trained to output representation resembling that of the teacher. At the same time, the teacher network is updated as moving average of student's weights over training steps. In order to prevent representation collapse, we apply an in-utterance contrastive loss as pre-training objective and impose position randomization on the input to the teacher. SPIRAL achieves competitive or better results compared to state-of-the-art speech pre-training method wav2vec 2.0, with significant reduction of training cost (80% for Base model, 65% for Large model). Furthermore, we address the problem of noise-robustness that is critical to real-world speech applications. We propose multi-condition pre-training by perturbing the student's input with various types of additive noise. We demonstrate that multi-condition pre-trained SPIRAL models are more robust to noisy speech (9.0% - 13.3% relative word error rate reduction on real noisy test data), compared to applying multi-condition training solely in the fine-tuning stage. The code will be released after publication.
Landscape of Neural Architecture Search across sensors: how much do they differ ?
Jan 20, 2022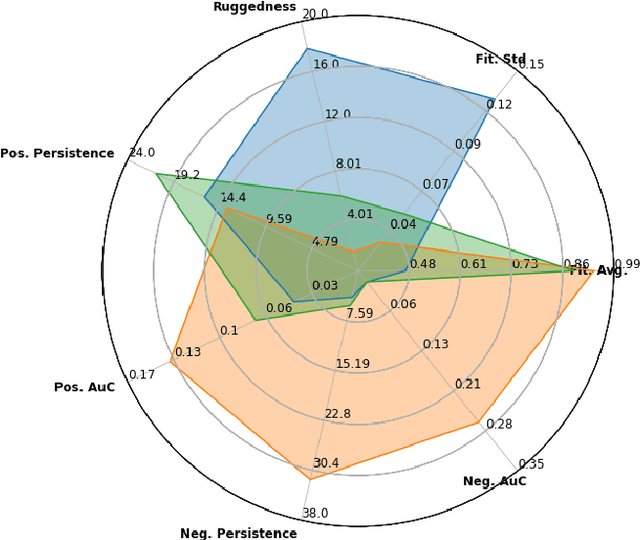
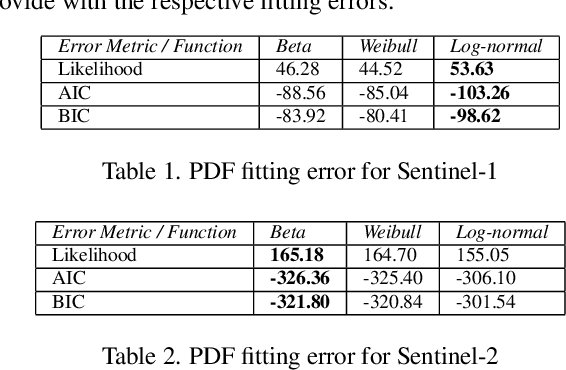

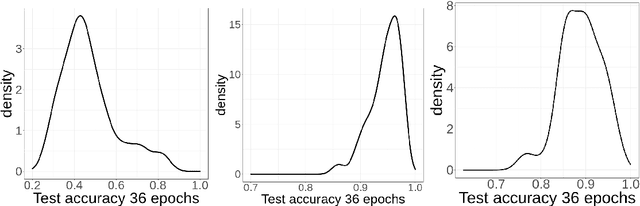
With the rapid rise of neural architecture search, the ability to understand its complexity from the perspective of a search algorithm is desirable. Recently, Traor\'e et al. have proposed the framework of Fitness Landscape Footprint to help describe and compare neural architecture search problems. It attempts at describing why a search strategy might be successful, struggle or fail on a target task. Our study leverages this methodology in the context of searching across sensors, including sensor data fusion. In particular, we apply the Fitness Landscape Footprint to the real-world image classification problem of So2Sat LCZ42, in order to identify the most beneficial sensor to our neural network hyper-parameter optimization problem. From the perspective of distributions of fitness, our findings indicate a similar behaviour of the search space for all sensors: the longer the training time, the larger the overall fitness, and more flatness in the landscapes (less ruggedness and deviation). Regarding sensors, the better the fitness they enable (Sentinel-2), the better the search trajectories (smoother, higher persistence). Results also indicate very similar search behaviour for sensors that can be decently fitted by the search space (Sentinel-2 and fusion).
Small Object Detection using Deep Learning
Jan 10, 2022
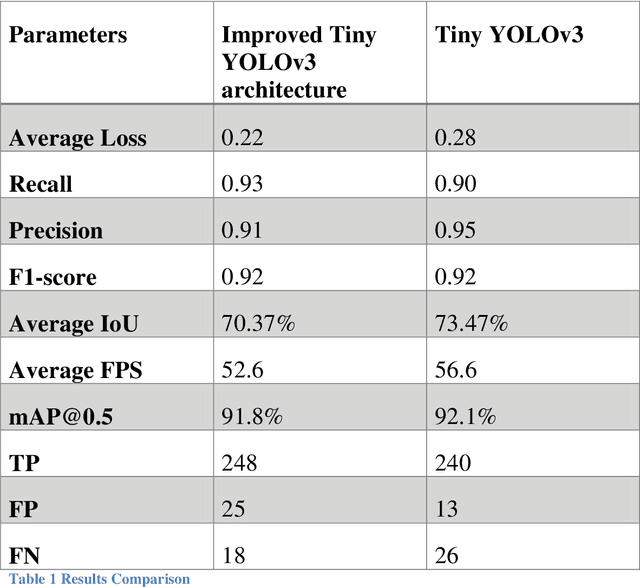

Now a days, UAVs such as drones are greatly used for various purposes like that of capturing and target detection from ariel imagery etc. Easy access of these small ariel vehicles to public can cause serious security threats. For instance, critical places may be monitored by spies blended in public using drones. Study in hand proposes an improved and efficient Deep Learning based autonomous system which can detect and track very small drones with great precision. The proposed system consists of a custom deep learning model Tiny YOLOv3, one of the flavors of very fast object detection model You Look Only Once (YOLO) is built and used for detection. The object detection algorithm will efficiently the detect the drones. The proposed architecture has shown significantly better performance as compared to the previous YOLO version. The improvement is observed in the terms of resource usage and time complexity. The performance is measured using the metrics of recall and precision that are 93% and 91% respectively.
Language bias in Visual Question Answering: A Survey and Taxonomy
Nov 16, 2021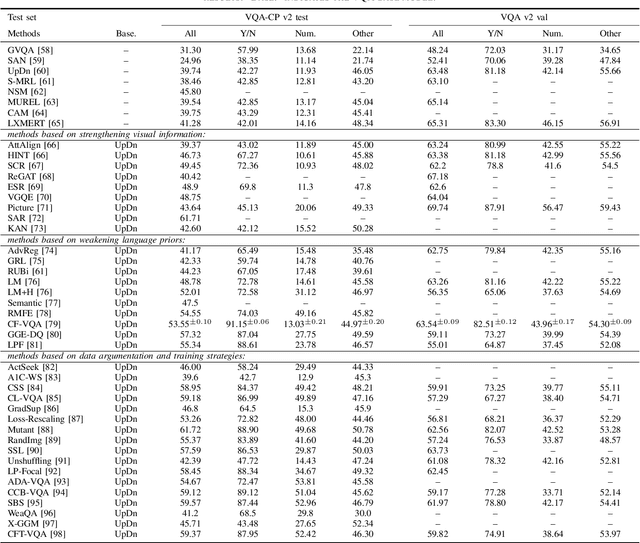
Visual question answering (VQA) is a challenging task, which has attracted more and more attention in the field of computer vision and natural language processing. However, the current visual question answering has the problem of language bias, which reduces the robustness of the model and has an adverse impact on the practical application of visual question answering. In this paper, we conduct a comprehensive review and analysis of this field for the first time, and classify the existing methods according to three categories, including enhancing visual information, weakening language priors, data enhancement and training strategies. At the same time, the relevant representative methods are introduced, summarized and analyzed in turn. The causes of language bias are revealed and classified. Secondly, this paper introduces the datasets mainly used for testing, and reports the experimental results of various existing methods. Finally, we discuss the possible future research directions in this field.
RailLoMer: Rail Vehicle Localization and Mapping with LiDAR-IMU-Odometer-GNSS Data Fusion
Nov 30, 2021
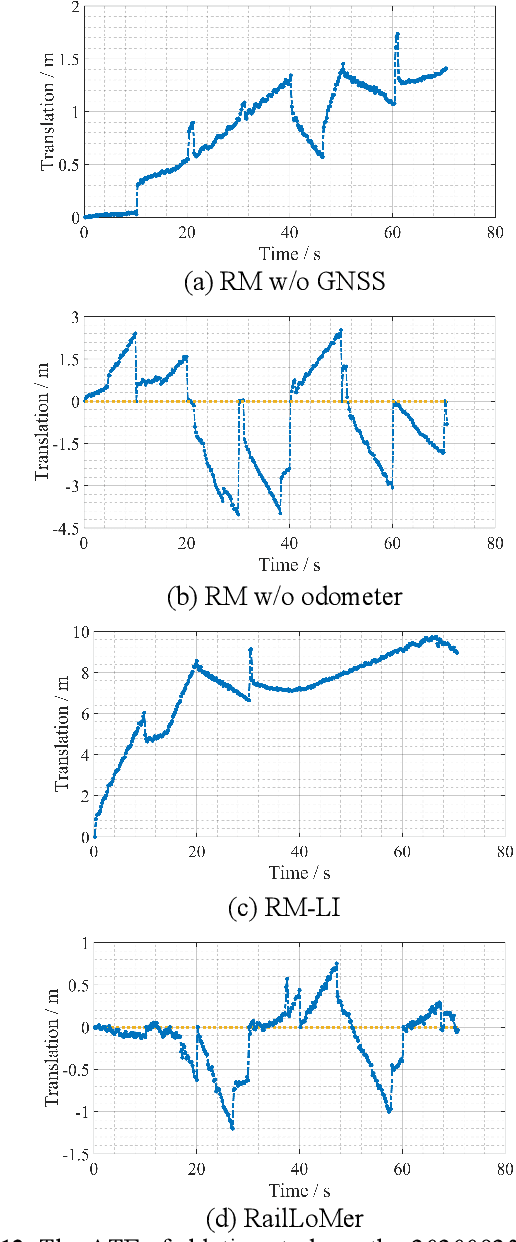
We present RailLoMer in this article, to achieve real-time accurate and robust odometry and mapping for rail vehicles. RailLoMer receives measurements from two LiDARs, an IMU, train odometer, and a global navigation satellite system (GNSS) receiver. As frontend, the estimated motion from IMU/odometer preintegration de-skews the denoised point clouds and produces initial guess for frame-to-frame LiDAR odometry. As backend, a sliding window based factor graph is formulated to jointly optimize multi-modal information. In addition, we leverage the plane constraints from extracted rail tracks and the structure appearance descriptor to further improve the system robustness against repetitive structures. To ensure a globally-consistent and less blurry mapping result, we develop a two-stage mapping method that first performs scan-to-map in local scale, then utilizes the GNSS information to register the submaps. The proposed method is extensively evaluated on datasets gathered for a long time range over numerous scales and scenarios, and show that RailLoMer delivers decimeter-grade localization accuracy even in large or degenerated environments. We also integrate RailLoMer into an interactive train state and railway monitoring system prototype design, which has already been deployed to an experimental freight traffic railroad.
Enhancement or Super-Resolution: Learning-based Adaptive Video Streaming with Client-Side Video Processing
Jan 20, 2022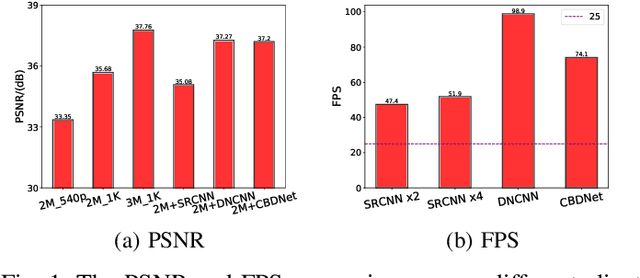
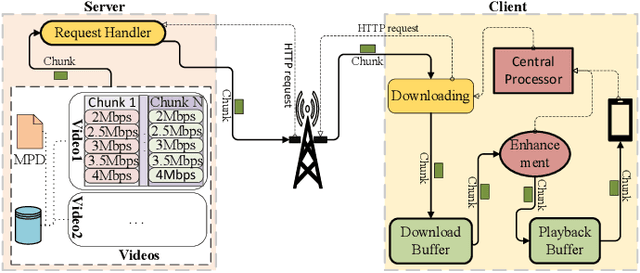
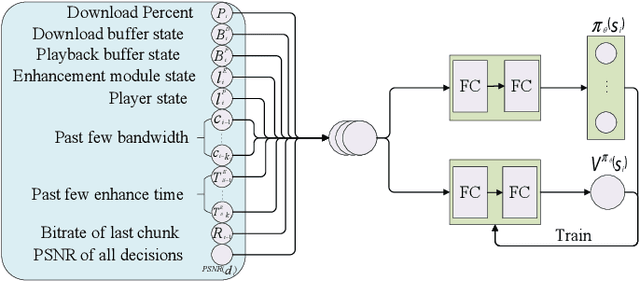
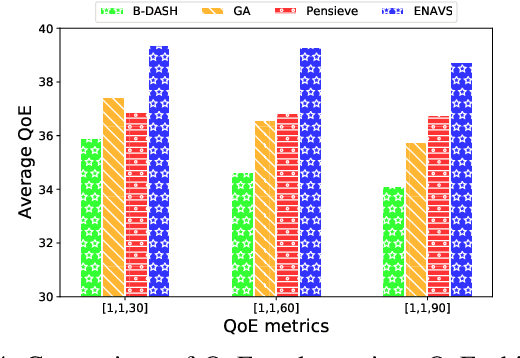
The rapid development of multimedia and communication technology has resulted in an urgent need for high-quality video streaming. However, robust video streaming under fluctuating network conditions and heterogeneous client computing capabilities remains a challenge. In this paper, we consider an enhancement-enabled video streaming network under a time-varying wireless network and limited computation capacity. "Enhancement" means that the client can improve the quality of the downloaded video segments via image processing modules. We aim to design a joint bitrate adaptation and client-side enhancement algorithm toward maximizing the quality of experience (QoE). We formulate the problem as a Markov decision process (MDP) and propose a deep reinforcement learning (DRL)-based framework, named ENAVS. As video streaming quality is mainly affected by video compression, we demonstrate that the video enhancement algorithm outperforms the super-resolution algorithm in terms of signal-to-noise ratio and frames per second, suggesting a better solution for client processing in video streaming. Ultimately, we implement ENAVS and demonstrate extensive testbed results under real-world bandwidth traces and videos. The simulation shows that ENAVS is capable of delivering 5%-14% more QoE under the same bandwidth and computing power conditions as conventional ABR streaming.
Machine learning time series regressions with an application to nowcasting
May 29, 2020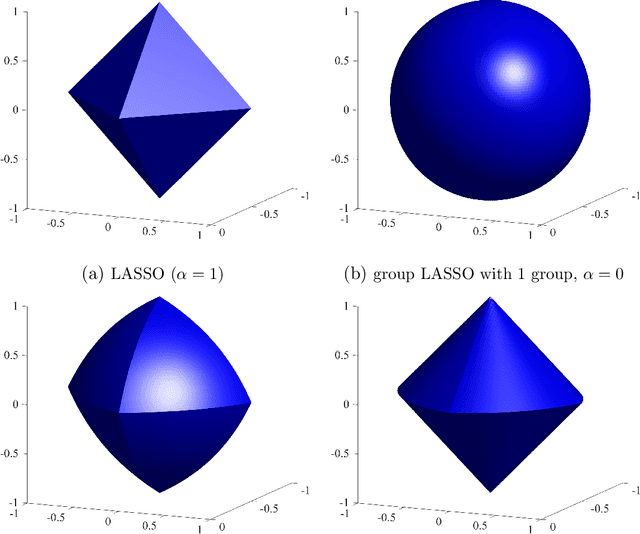

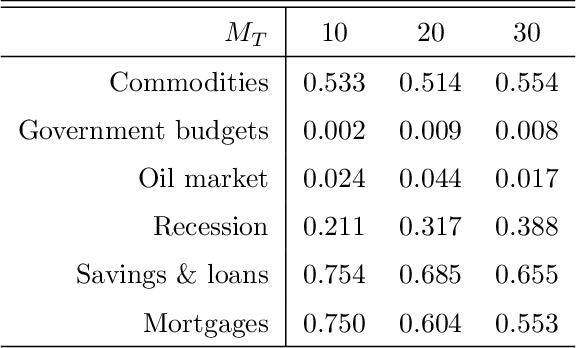
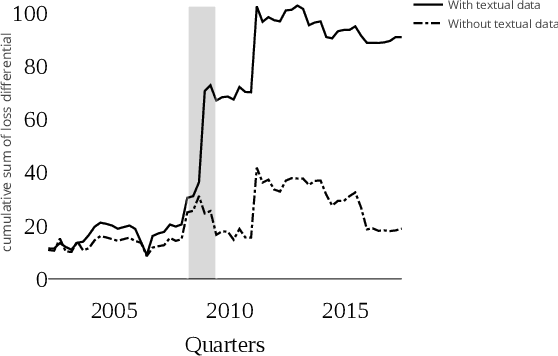
This paper introduces structured machine learning regressions for high-dimensional time series data potentially sampled at different frequencies. The sparse-group LASSO estimator can take advantage of such time series data structures and outperforms the unstructured LASSO. We establish oracle inequalities for the sparse-group LASSO estimator within a framework that allows for the mixing processes and recognizes that the financial and the macroeconomic data may have heavier than exponential tails. An empirical application to nowcasting US GDP growth indicates that the estimator performs favorably compared to other alternatives and that the text data can be a useful addition to more traditional numerical data.