 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimizing Memory in Reservoir Computers
Jan 05, 2022
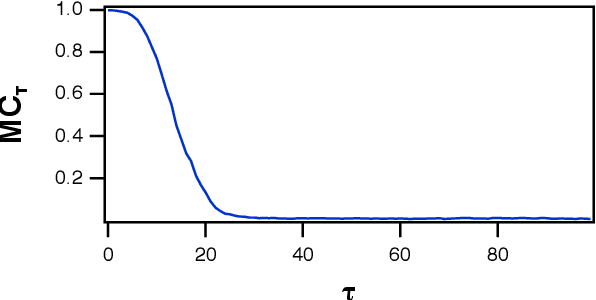
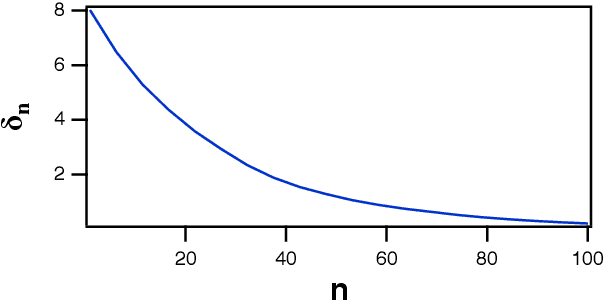
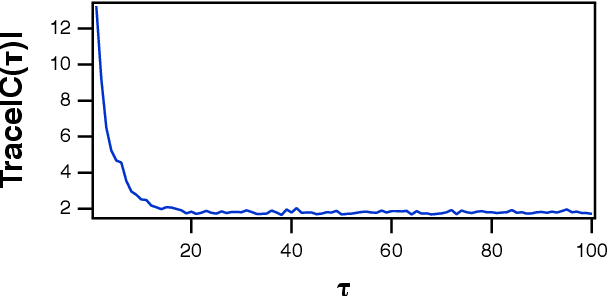
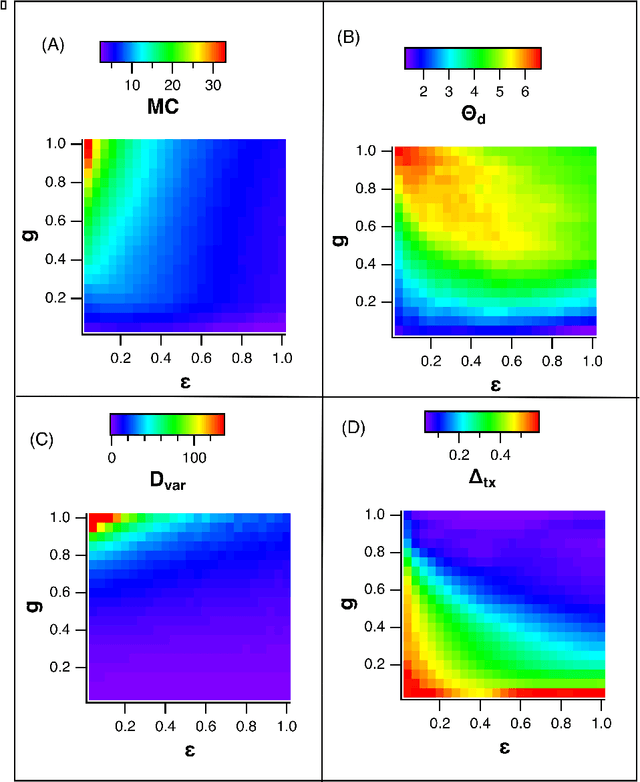
A reservoir computer is a way of using a high dimensional dynamical system for computation. One way to construct a reservoir computer is by connecting a set of nonlinear nodes into a network. Because the network creates feedback between nodes, the reservoir computer has memory. If the reservoir computer is to respond to an input signal in a consistent way (a necessary condition for computation), the memory must be fading; that is, the influence of the initial conditions fades over time. How long this memory lasts is important for determining how well the reservoir computer can solve a particular problem. In this paper I describe ways to vary the length of the fading memory in reservoir computers. Tuning the memory can be important to achieve optimal results in some problems; too much or too little memory degrades the accuracy of the computation.
Solving Inventory Management Problems with Inventory-dynamics-informed Neural Networks
Jan 16, 2022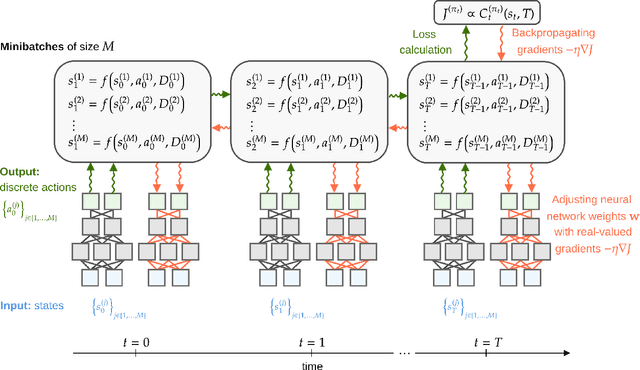
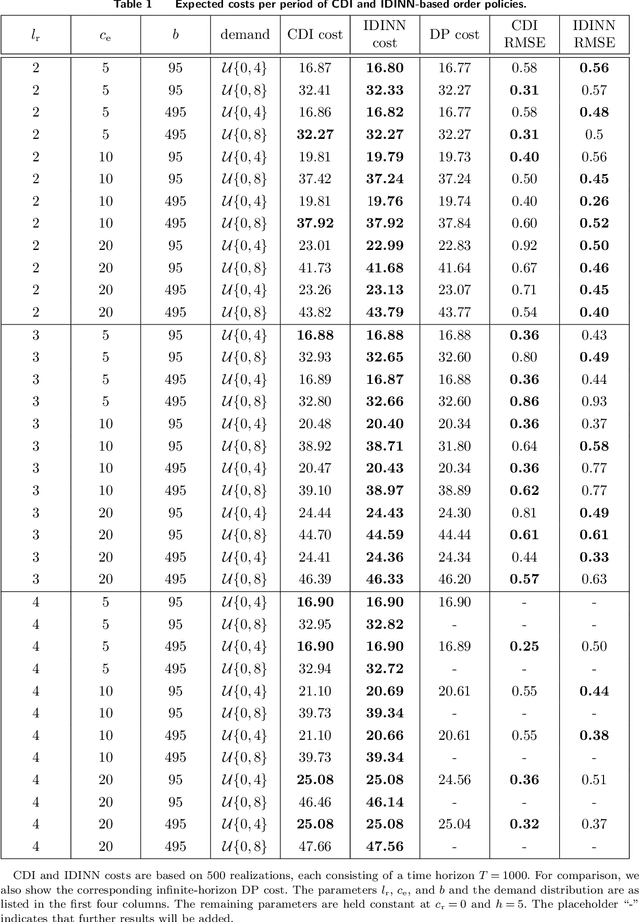

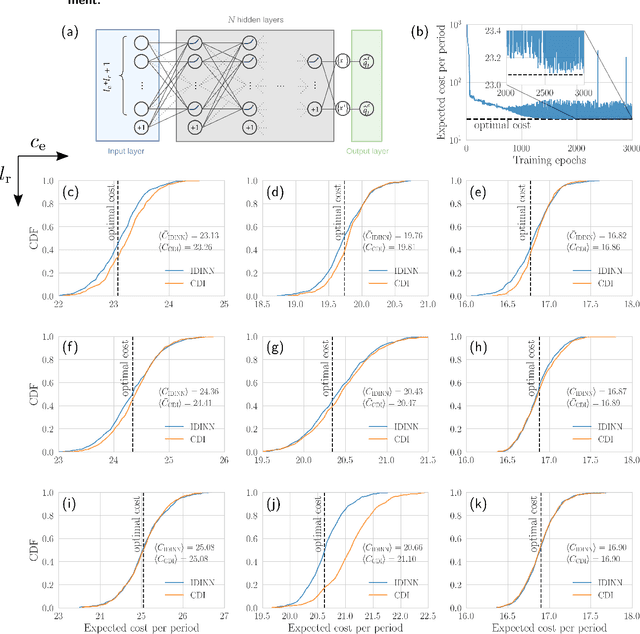
A key challenge in inventory management is to identify policies that optimally replenish inventory from multiple suppliers. To solve such optimization problems, inventory managers need to decide what quantities to order from each supplier, given the on-hand inventory and outstanding orders, so that the expected backlogging, holding, and sourcing costs are jointly minimized. Inventory management problems have been studied extensively for over 60 years, and yet even basic dual sourcing problems, in which orders from an expensive supplier arrive faster than orders from a regular supplier, remain intractable in their general form. In this work, we approach dual sourcing from a neural-network-based optimization lens. By incorporating inventory dynamics into the design of neural networks, we are able to learn near-optimal policies of commonly used instances within a few minutes of CPU time on a regular personal computer. To demonstrate the versatility of inventory-dynamics-informed neural networks, we show that they are able to control inventory dynamics with empirical demand distributions that are challenging to tackle effectively using alternative, state-of-the-art approaches.
Optimal Probing Sequences for Polarization-Multiplexed Coherent Phase OTDR
Nov 11, 2021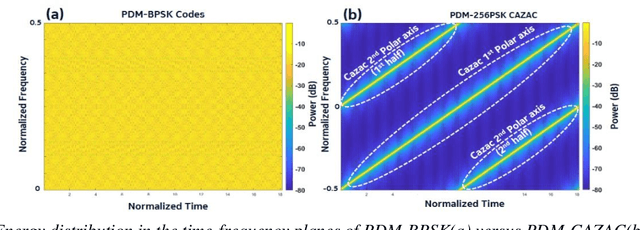
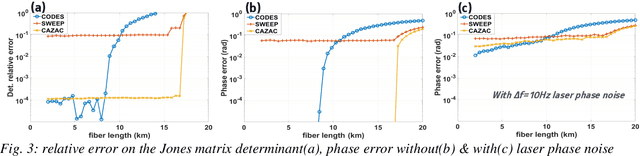
We introduce dual-polarization probing codes based on two circularly shifted frequency sweep signals enabling perfect channel estimation. This is achieved with a probing length equal to at least twice the fiber round-trip propagation time.
Tight Concentrations and Confidence Sequences from the Regret of Universal Portfolio
Oct 27, 2021
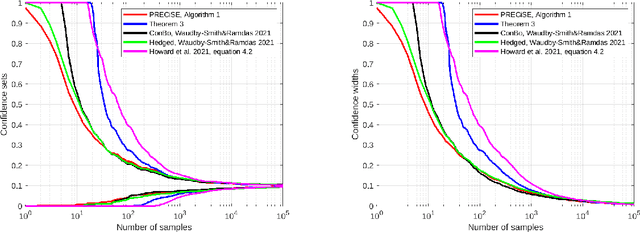
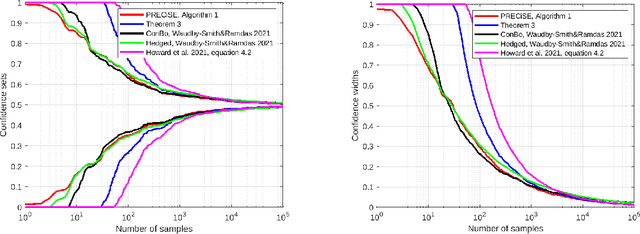
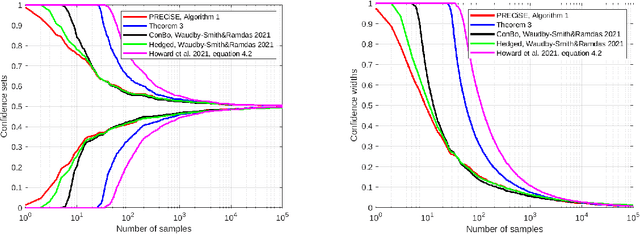
A classic problem in statistics is the estimation of the expectation of random variables from samples. This gives rise to the tightly connected problems of deriving concentration inequalities and confidence sequences, that is confidence intervals that hold uniformly over time. Jun and Orabona [COLT'19] have shown how to easily convert the regret guarantee of an online betting algorithm into a time-uniform concentration inequality. Here, we show that we can go even further: We show that the regret of a minimax betting algorithm gives rise to a new implicit empirical time-uniform concentration. In particular, we use a new data-dependent regret guarantee of the universal portfolio algorithm. We then show how to invert the new concentration in two different ways: in an exact way with a numerical algorithm and symbolically in an approximate way. Finally, we show empirically that our algorithms have state-of-the-art performance in terms of the width of the confidence sequences up to a moderately large amount of samples. In particular, our numerically obtained confidence sequences are never vacuous, even with a single sample.
Auditory Model based Phase-Aware Bayesian Spectral Amplitude Estimator for Single-Channel Speech Enhancement
Feb 10, 2022
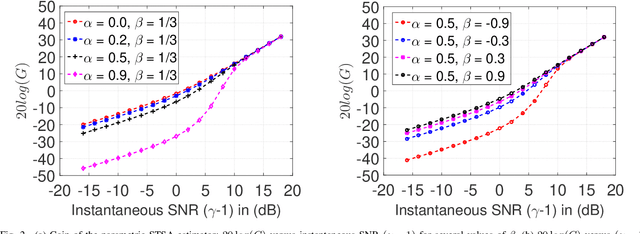
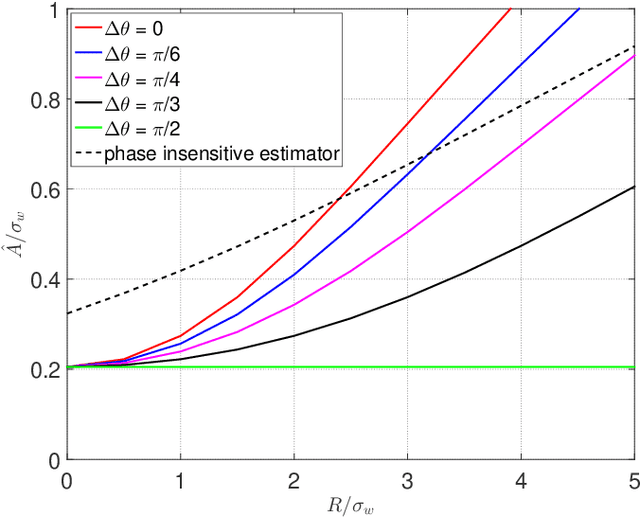
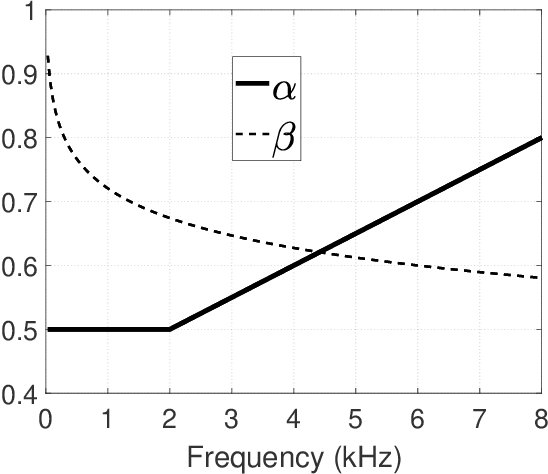
Bayesian estimation of short-time spectral amplitude is one of the most predominant approaches for the enhancement of the noise corrupted speech. The performance of these estimators are usually significantly improved when any perceptually relevant cost function is considered. On the other hand, the recent progress in the phase-based speech signal processing have shown that the phase-only enhancement based on spectral phase estimation methods can also provide joint improvement in the perceived speech quality and intelligibility, even in low SNR conditions. In this paper, to take advantage of both the perceptually motivated cost function involving STSAs of estimated and true clean speech and utilizing the prior spectral phase information, we have derived a phase-aware Bayesian STSA estimator. The parameters of the cost function are chosen based on the characteristics of the human auditory system, namely, the dynamic compressive nonlinearity of the cochlea, the perceived loudness theory and the simultaneous masking properties of the ear. This type of parameter selection scheme results in more noise reduction while limiting the speech distortion. The derived STSA estimator is optimal in the MMSE sense if the prior phase information is available. In practice, however, typically only an estimate of the clean speech phase can be obtained via employing different types of spectral phase estimation techniques which have been developed throughout the last few years. In a blind setup, we have evaluated the proposed Bayesian STSA estimator with different types of standard phase estimation methods available in the literature. Experimental results have shown that the proposed estimator can achieve substantial improvement in performance than the traditional phase-blind approaches.
Online Action Detection in Streaming Videos with Time Buffers
Oct 06, 2020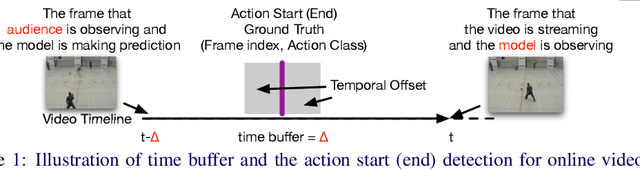

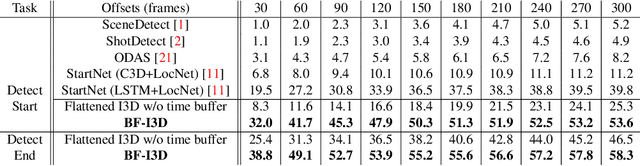
We formulate the problem of online temporal action detection in live streaming videos, acknowledging one important property of live streaming videos that there is normally a broadcast delay between the latest captured frame and the actual frame viewed by the audience. The standard setting of the online action detection task requires immediate prediction after a new frame is captured. We illustrate that its lack of consideration of the delay is imposing unnecessary constraints on the models and thus not suitable for this problem. We propose to adopt the problem setting that allows models to make use of the small `buffer time' incurred by the delay in live streaming videos. We design an action start and end detection framework for this online with buffer setting with two major components: flattened I3D and window-based suppression. Experiments on three standard temporal action detection benchmarks under the proposed setting demonstrate the effectiveness of the proposed framework. We show that by having a suitable problem setting for this problem with wide-applications, we can achieve much better detection accuracy than off-the-shelf online action detection models.
Deep Reinforcement Learning Assisted Federated Learning Algorithm for Data Management of IIoT
Feb 03, 2022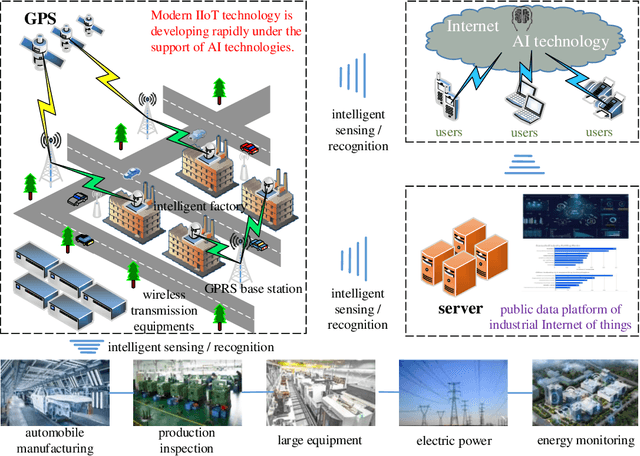
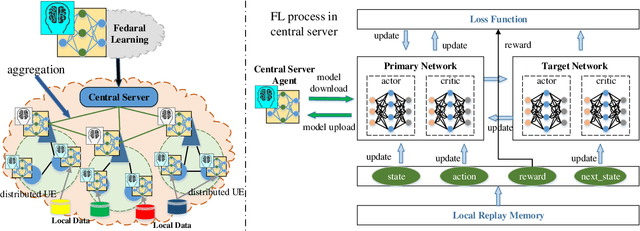
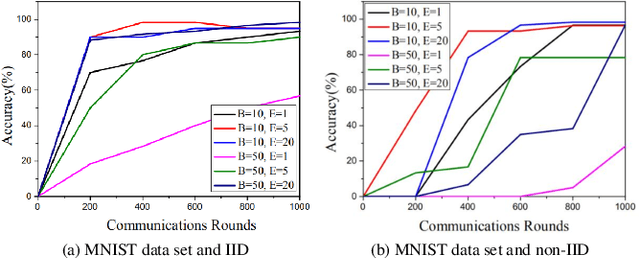
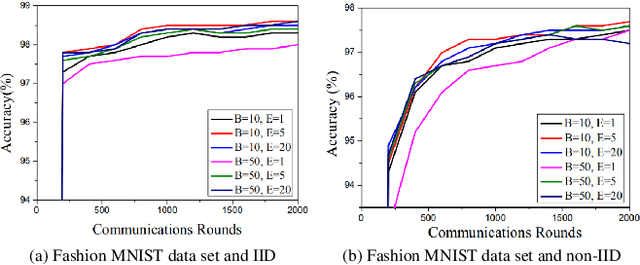
The continuous expanded scale of the industrial Internet of Things (IIoT) leads to IIoT equipments generating massive amounts of user data every moment. According to the different requirement of end users, these data usually have high heterogeneity and privacy, while most of users are reluctant to expose them to the public view. How to manage these time series data in an efficient and safe way in the field of IIoT is still an open issue, such that it has attracted extensive attention from academia and industry. As a new machine learning (ML) paradigm, federated learning (FL) has great advantages in training heterogeneous and private data. This paper studies the FL technology applications to manage IIoT equipment data in wireless network environments. In order to increase the model aggregation rate and reduce communication costs, we apply deep reinforcement learning (DRL) to IIoT equipment selection process, specifically to select those IIoT equipment nodes with accurate models. Therefore, we propose a FL algorithm assisted by DRL, which can take into account the privacy and efficiency of data training of IIoT equipment. By analyzing the data characteristics of IIoT equipments, we use MNIST, fashion MNIST and CIFAR-10 data sets to represent the data generated by IIoT. During the experiment, we employ the deep neural network (DNN) model to train the data, and experimental results show that the accuracy can reach more than 97\%, which corroborates the effectiveness of the proposed algorithm.
Structure-Exploiting Newton-Type Method for Optimal Control of Switched Systems
Dec 14, 2021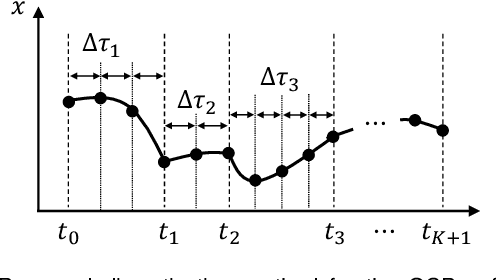
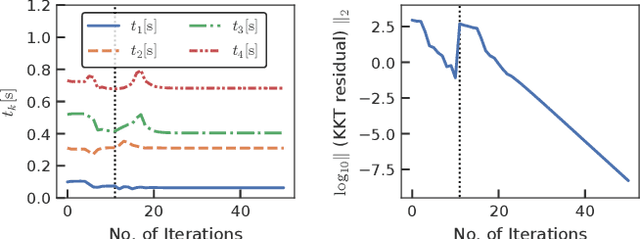
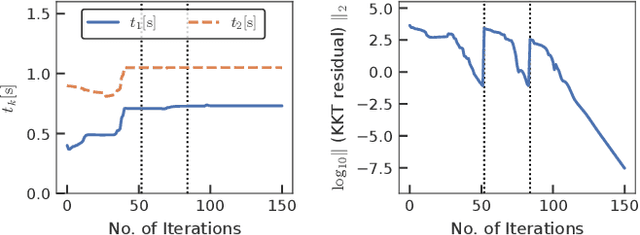
This study proposes an efficient Newton-type method for the optimal control of switched systems under a given mode sequence. A mesh-refinement-based approach is utilized to discretize continuous-time optimal control problems (OCPs) using the direct multiple-shooting method to formulate a nonlinear program (NLP), which guarantees the local convergence of a Newton-type method. A dedicated structure-exploiting algorithm (Riccati recursion) is proposed that efficiently performs a Newton-type method for the NLP because its sparsity structure is different from a standard OCP. The proposed method computes each Newton step with linear time-complexity for the total number of discretization grids as the standard Riccati recursion algorithm. Additionally, it can always solve the Karush-Kuhn-Tucker (KKT) systems arising in the Newton-type method if the solution is sufficiently close to a local minimum. Conversely, general quadratic programming (QP) solvers cannot accomplish this because the Hessian matrix is inherently indefinite. Moreover, a modification on the reduced Hessian matrix is proposed using the nature of the Riccati recursion algorithm as the dynamic programming for a QP subproblem to enhance the convergence. A numerical comparison is conducted with off-the-shelf NLP solvers, which demonstrates that the proposed method is up to two orders of magnitude faster. Whole-body optimal control of quadrupedal gaits is also demonstrated and shows that the proposed method can achieve the whole-body model predictive control (MPC) of robotic systems with rigid contacts.
Micro-entries: Encouraging Deeper Evaluation of Mental Models Over Time for Interactive Data Systems
Sep 02, 2020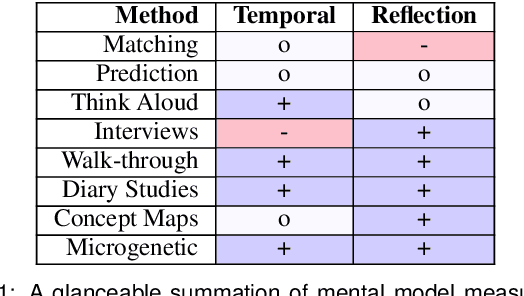
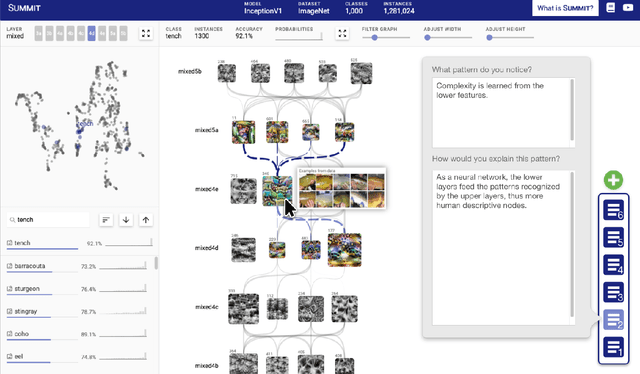
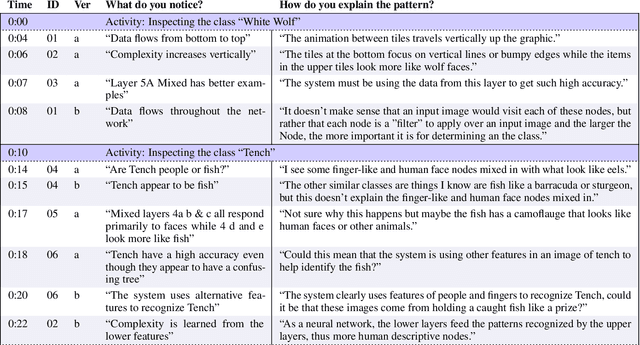
Many interactive data systems combine visual representations of data with embedded algorithmic support for automation and data exploration. To effectively support transparent and explainable data systems, it is important for researchers and designers to know how users understand the system. We discuss the evaluation of users' mental models of system logic. Mental models are challenging to capture and analyze. While common evaluation methods aim to approximate the user's final mental model after a period of system usage, user understanding continuously evolves as users interact with a system over time. In this paper, we review many common mental model measurement techniques, discuss tradeoffs, and recommend methods for deeper, more meaningful evaluation of mental models when using interactive data analysis and visualization systems. We present guidelines for evaluating mental models over time that reveal the evolution of specific model updates and how they may map to the particular use of interface features and data queries. By asking users to describe what they know and how they know it, researchers can collect structured, time-ordered insight into a user's conceptualization process while also helping guide users to their own discoveries.
Machine Learning Aided Holistic Handover Optimization for Emerging Networks
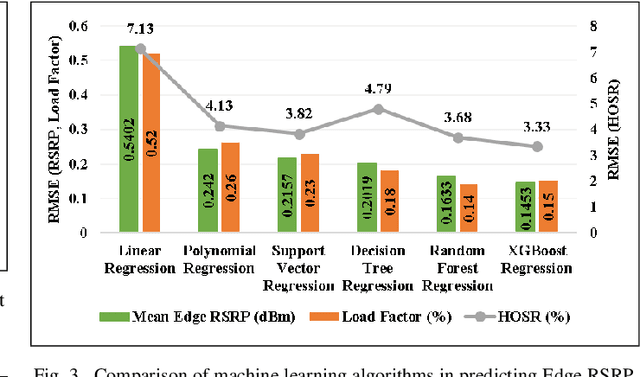
Feb 06, 2022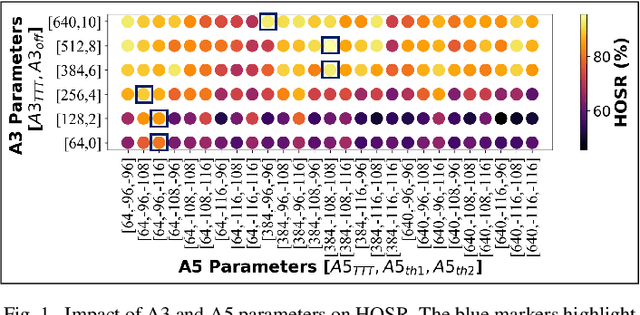

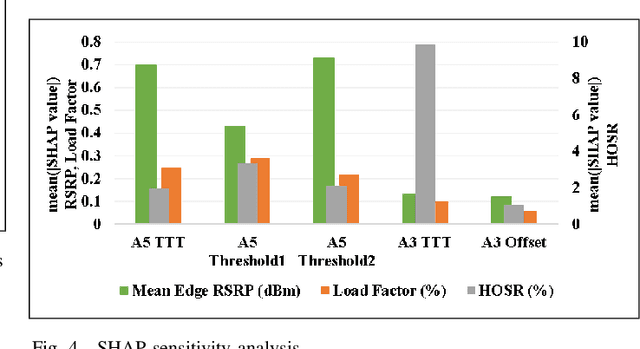
In the wake of network densification and multi-band operation in emerging cellular networks, mobility and handover management is becoming a major bottleneck. The problem is further aggravated by the fact that holistic mobility management solutions for different types of handovers, namely inter-frequency and intra-frequency handovers, remain scarce. This paper presents a first mobility management solution that concurrently optimizes inter-frequency related A5 parameters and intra-frequency related A3 parameters. We analyze and optimize five parameters namely A5-time to trigger (TTT), A5-threshold1, A5-threshold2, A3-TTT, and A3-offset to jointly maximize three critical key performance indicators (KPIs): edge user reference signal received power (RSRP), handover success rate (HOSR) and load between frequency bands. In the absence of tractable analytical models due to system level complexity, we leverage machine learning to quantify the KPIs as a function of the mobility parameters. An XGBoost based model has the best performance for edge RSRP and HOSR while random forest outperforms others for load prediction. An analysis of the mobility parameters provides several insights: 1) there exists a strong coupling between A3 and A5 parameters; 2) an optimal set of parameters exists for each KPI; and 3) the optimal parameters vary for different KPIs. We also perform a SHAP based sensitivity to help resolve the parametric conflict between the KPIs. Finally, we formulate a maximization problem, show it is non-convex, and solve it utilizing simulated annealing (SA). Results indicate that ML-based SA-aided solution is more than 14x faster than the brute force approach with a slight loss in optimality.