 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Collaborative adversary nodes learning on the logs of IoT devices in an IoT network
Dec 22, 2021
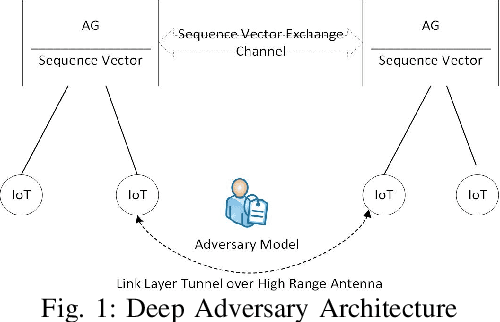
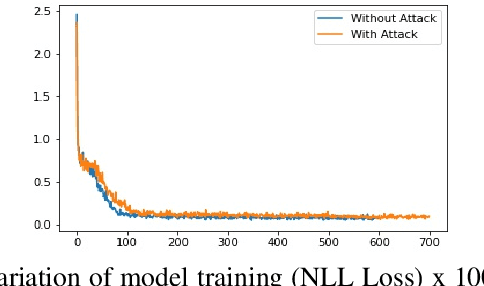

Artificial Intelligence (AI) development has encouraged many new research areas, including AI-enabled Internet of Things (IoT) network. AI analytics and intelligent paradigms greatly improve learning efficiency and accuracy. Applying these learning paradigms to network scenarios provide technical advantages of new networking solutions. In this paper, we propose an improved approach for IoT security from data perspective. The network traffic of IoT devices can be analyzed using AI techniques. The Adversary Learning (AdLIoTLog) model is proposed using Recurrent Neural Network (RNN) with attention mechanism on sequences of network events in the network traffic. We define network events as a sequence of the time series packets of protocols captured in the log. We have considered different packets TCP packets, UDP packets, and HTTP packets in the network log to make the algorithm robust. The distributed IoT devices can collaborate to cripple our world which is extending to Internet of Intelligence. The time series packets are converted into structured data by removing noise and adding timestamps. The resulting data set is trained by RNN and can detect the node pairs collaborating with each other. We used the BLEU score to evaluate the model performance. Our results show that the predicting performance of the AdLIoTLog model trained by our method degrades by 3-4% in the presence of attack in comparison to the scenario when the network is not under attack. AdLIoTLog can detect adversaries because when adversaries are present the model gets duped by the collaborative events and therefore predicts the next event with a biased event rather than a benign event. We conclude that AI can provision ubiquitous learning for the new generation of Internet of Things.
Computing Semilinear Sparse Models for Approximately Eventually Periodic Signals
Oct 19, 2021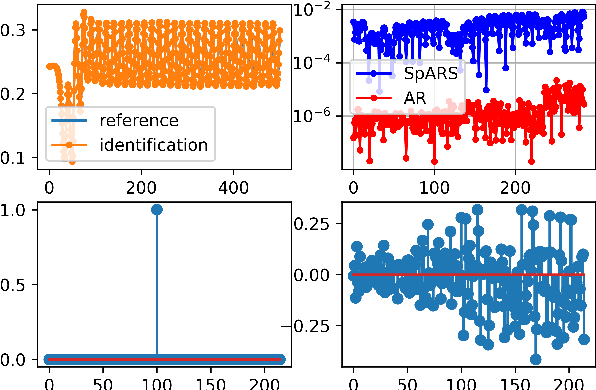
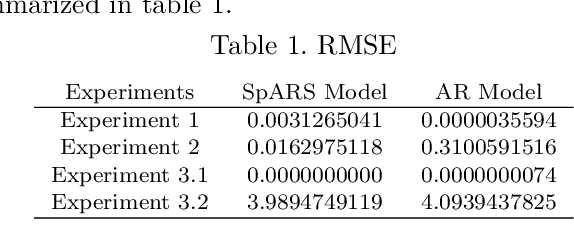
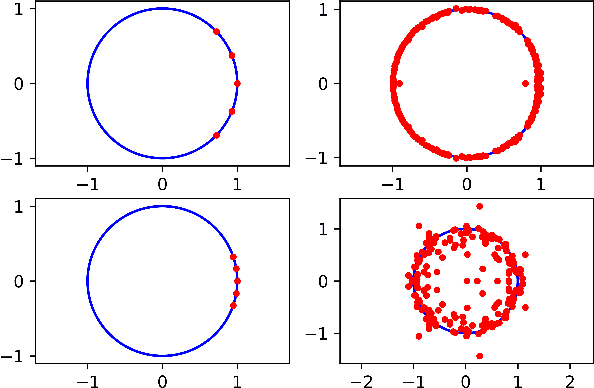
Some elements of the theory and algorithmics corresponding to the computation of semilinear sparse models for discrete-time signals are presented. In this study, we will focus on approximately eventually periodic discrete-time signals, that is, signals that can exhibit an aperiodic behavior for an initial amount of time, and then become approximately periodic afterwards. The semilinear models considered in this study are obtained by combining sparse representation methods, linear autoregressive models and GRU neural network models, initially fitting each block model independently using some reference data corresponding to some signal under consideration, and then fitting some mixing parameters that are used to obtain a signal model consisting of a linear combination of the previously fitted blocks using the aforementioned reference data, computing sparse representations of some of the matrix parameters of the resulting model along the process. Some prototypical computational implementations are presented as well.
Language-driven Semantic Segmentation
Jan 10, 2022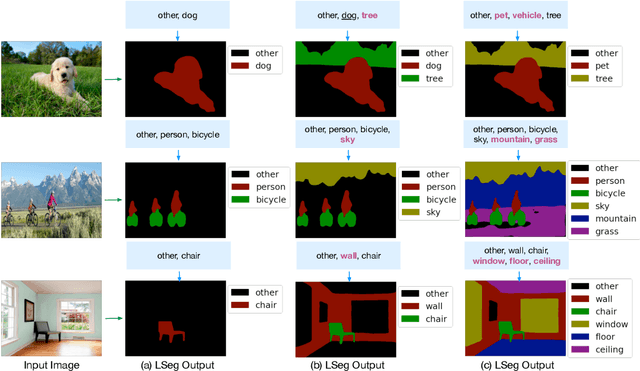
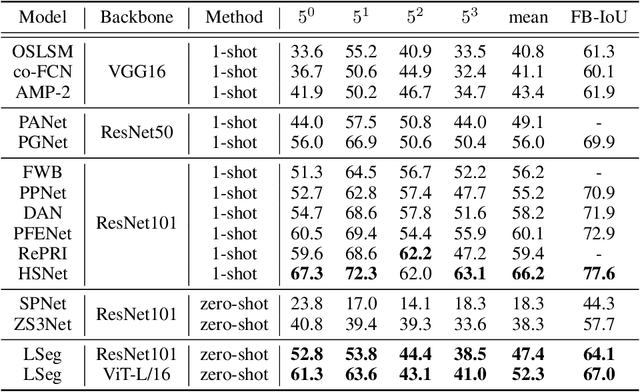
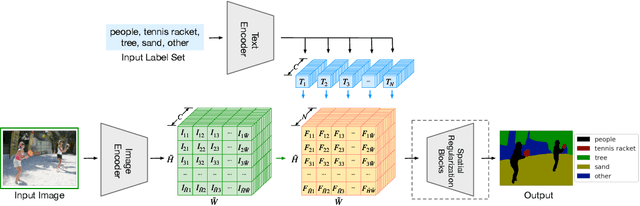
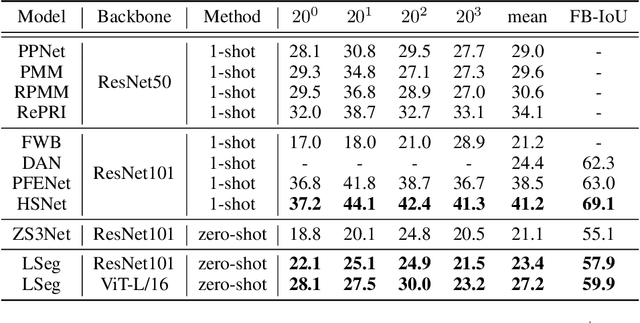
We present LSeg, a novel model for language-driven semantic image segmentation. LSeg uses a text encoder to compute embeddings of descriptive input labels (e.g., "grass" or "building") together with a transformer-based image encoder that computes dense per-pixel embeddings of the input image. The image encoder is trained with a contrastive objective to align pixel embeddings to the text embedding of the corresponding semantic class. The text embeddings provide a flexible label representation in which semantically similar labels map to similar regions in the embedding space (e.g., "cat" and "furry"). This allows LSeg to generalize to previously unseen categories at test time, without retraining or even requiring a single additional training sample. We demonstrate that our approach achieves highly competitive zero-shot performance compared to existing zero- and few-shot semantic segmentation methods, and even matches the accuracy of traditional segmentation algorithms when a fixed label set is provided. Code and demo are available at https://github.com/isl-org/lang-seg.
Fully Test-time Adaptation by Entropy Minimization
Jun 18, 2020
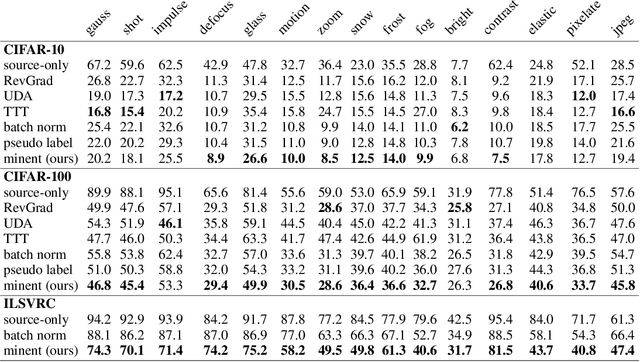

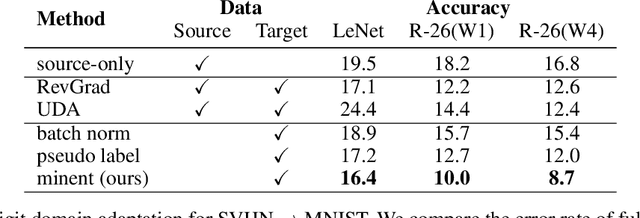
Faced with new and different data during testing, a model must adapt itself. We consider the setting of fully test-time adaptation, in which a supervised model confronts unlabeled test data from a different distribution, without the help of its labeled training data. We propose an entropy minimization approach for adaptation: we take the model's confidence as our objective as measured by the entropy of its predictions. During testing, we adapt the model by modulating its representation with affine transformations to minimize entropy. Our experiments show improved robustness to corruptions for image classification on CIFAR-10/100 and ILSVRC and demonstrate the feasibility of target-only domain adaptation for digit classification on MNIST and SVHN.
Exact Decomposition of Joint Low Rankness and Local Smoothness Plus Sparse Matrices
Jan 29, 2022
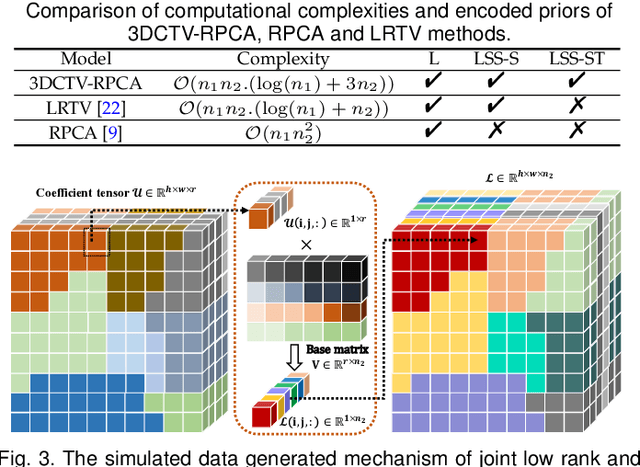
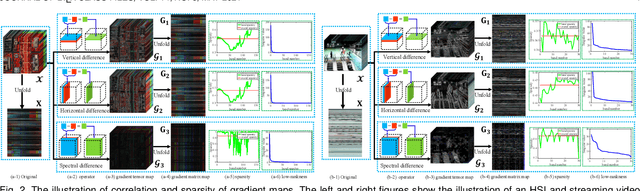
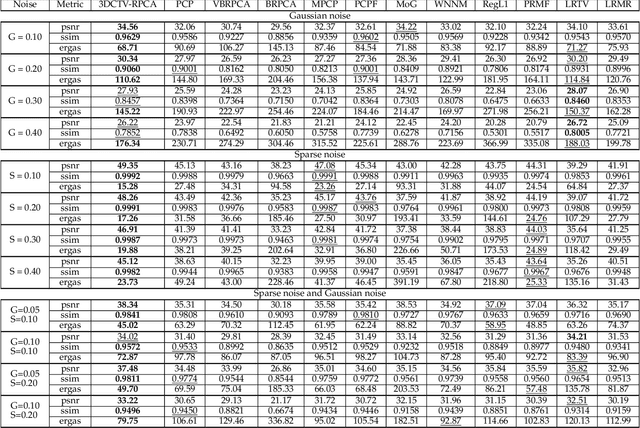
It is known that the decomposition in low-rank and sparse matrices (\textbf{L+S} for short) can be achieved by several Robust PCA techniques. Besides the low rankness, the local smoothness (\textbf{LSS}) is a vitally essential prior for many real-world matrix data such as hyperspectral images and surveillance videos, which makes such matrices have low-rankness and local smoothness properties at the same time. This poses an interesting question: Can we make a matrix decomposition in terms of \textbf{L\&LSS +S } form exactly? To address this issue, we propose in this paper a new RPCA model based on three-dimensional correlated total variation regularization (3DCTV-RPCA for short) by fully exploiting and encoding the prior expression underlying such joint low-rank and local smoothness matrices. Specifically, using a modification of Golfing scheme, we prove that under some mild assumptions, the proposed 3DCTV-RPCA model can decompose both components exactly, which should be the first theoretical guarantee among all such related methods combining low rankness and local smoothness. In addition, by utilizing Fast Fourier Transform (FFT), we propose an efficient ADMM algorithm with a solid convergence guarantee for solving the resulting optimization problem. Finally, a series of experiments on both simulations and real applications are carried out to demonstrate the general validity of the proposed 3DCTV-RPCA model.
DenseTact: Optical Tactile Sensor for Dense Shape Reconstruction
Jan 04, 2022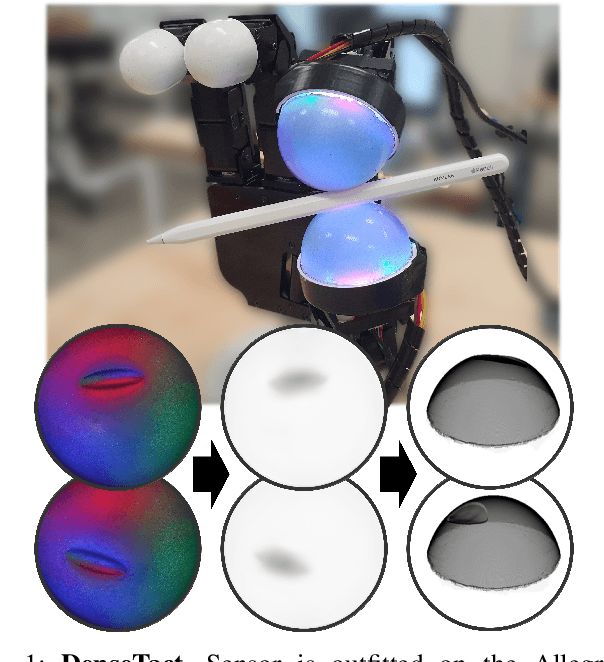
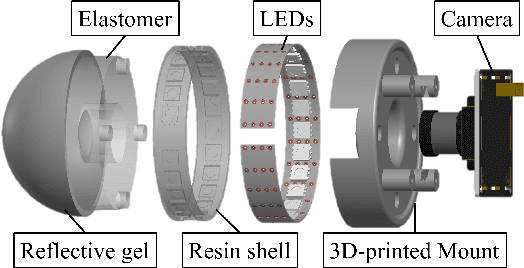
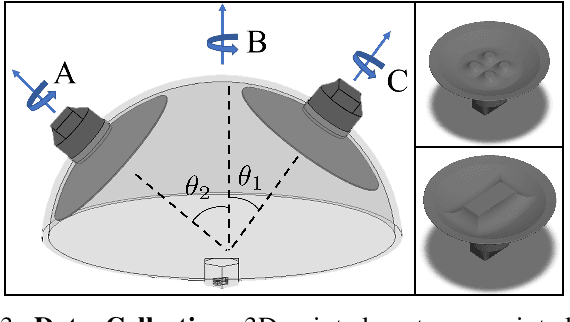
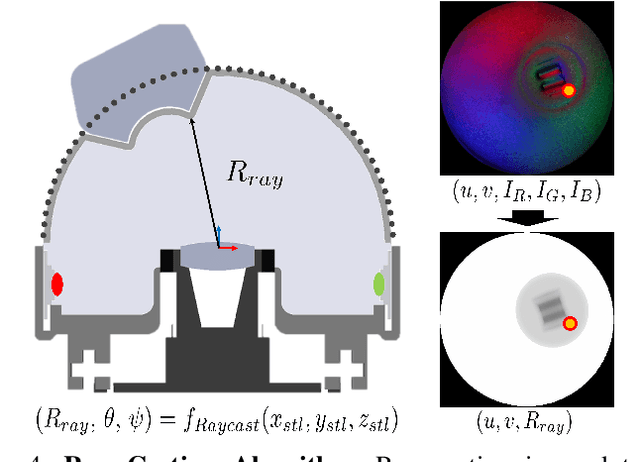
Increasing the performance of tactile sensing in robots enables versatile, in-hand manipulation. Vision-based tactile sensors have been widely used as rich tactile feedback has been shown to be correlated with increased performance in manipulation tasks. Existing tactile sensor solutions with high resolution have limitations that include low accuracy, expensive components, or lack of scalability. In this paper, an inexpensive, scalable, and compact tactile sensor with high-resolution surface deformation modeling for surface reconstruction of the 3D sensor surface is proposed. By measuring the image from the fisheye camera, it is shown that the sensor can successfully estimate the surface deformation in real-time (1.8ms) by using deep convolutional neural networks. This sensor in its design and sensing abilities represents a significant step toward better object in-hand localization, classification, and surface estimation all enabled by high-resolution shape reconstruction.
An Efficient and Accurate Rough Set for Feature Selection, Classification and Knowledge Representation
Dec 29, 2021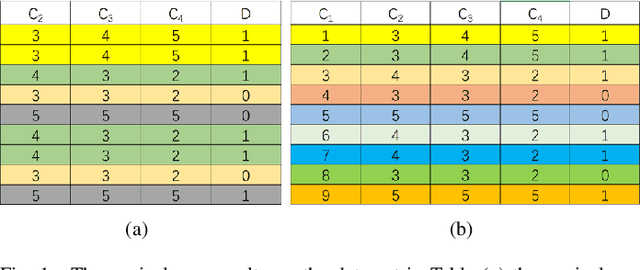
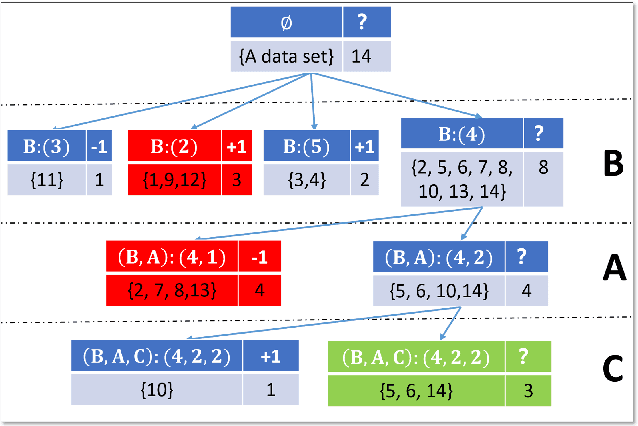
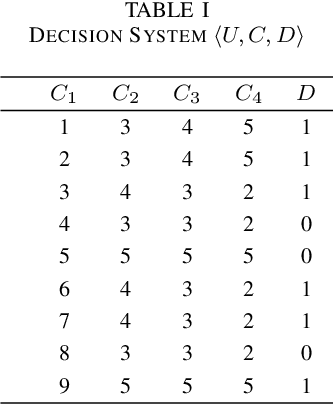
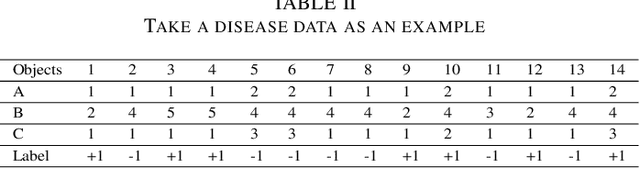
This paper present a strong data mining method based on rough set, which can realize feature selection, classification and knowledge representation at the same time. Rough set has good interpretability, and is a popular method for feature selections. But low efficiency and low accuracy are its main drawbacks that limits its application ability. In this paper,corresponding to the accuracy, we first find the ineffectiveness of rough set because of overfitting, especially in processing noise attribute, and propose a robust measurement for an attribute, called relative importance.we proposed the concept of "rough concept tree" for knowledge representation and classification. Experimental results on public benchmark data sets show that the proposed framework achieves higher accurcy than seven popular or the state-of-the-art feature selection methods.
Multivariate time-series modeling with generative neural networks
Feb 25, 2020
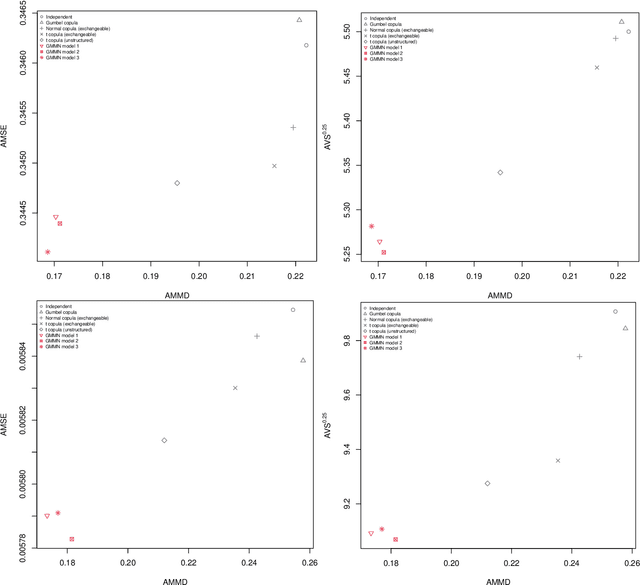
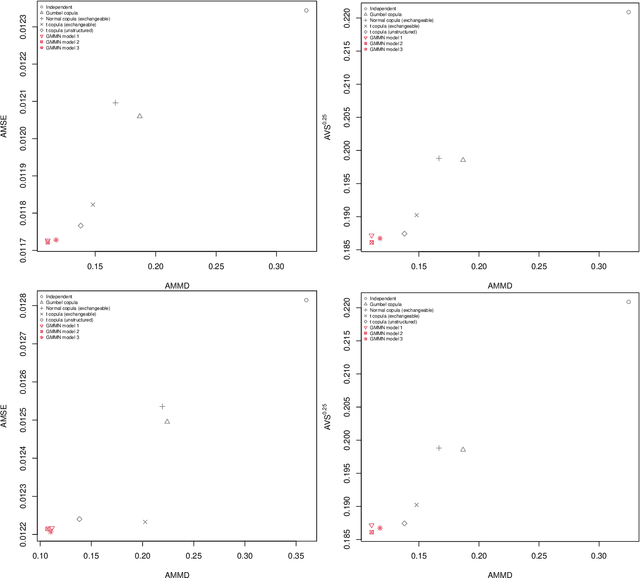
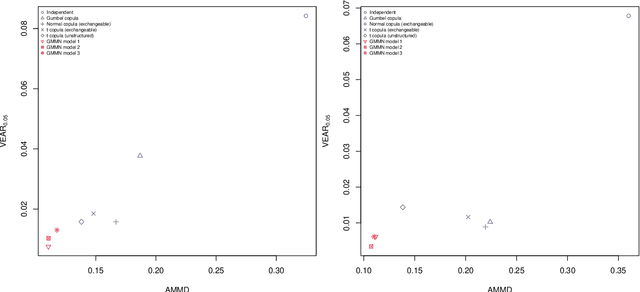
Generative moment matching networks (GMMNs) are introduced as dependence models for the joint innovation distribution of multivariate time series (MTS). Following the popular copula-GARCH approach for modeling dependent MTS data, a framework allowing us to take an alternative GMMN-GARCH approach is presented. First, ARMA-GARCH models are utilized to capture the serial dependence within each univariate marginal time series. Second, if the number of marginal time series is large, principal component analysis (PCA) is used as a dimension-reduction step. Last, the remaining cross-sectional dependence is modeled via a GMMN, our main contribution. GMMNs are highly flexible and easy to simulate from, which is a major advantage over the copula-GARCH approach. Applications involving yield curve modeling and the analysis of foreign exchange rate returns are presented to demonstrate the utility of our approach, especially in terms of producing better empirical predictive distributions and making better probabilistic forecasts. All results are reproducible with the demo GMMN_MTS_paper of the R package gnn.
Zero-Shot Sketch Based Image Retrieval using Graph Transformer
Jan 25, 2022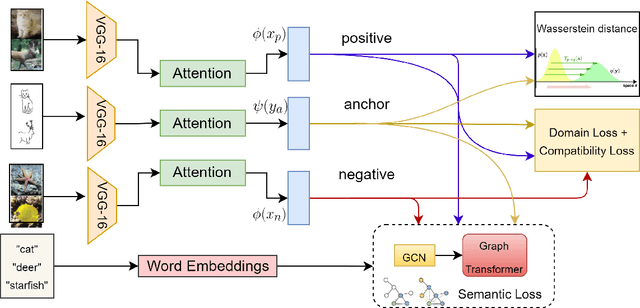
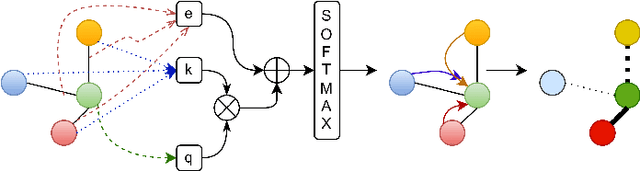

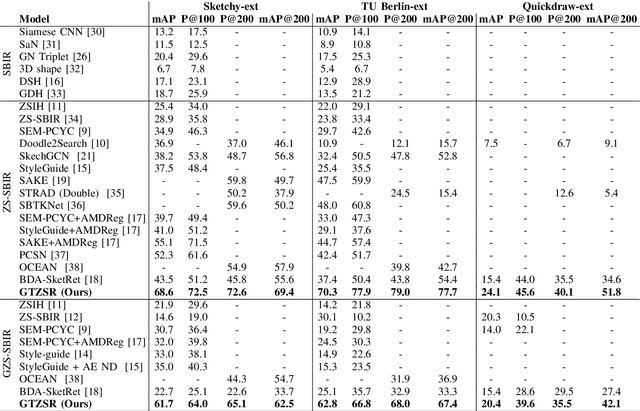
The performance of a zero-shot sketch-based image retrieval (ZS-SBIR) task is primarily affected by two challenges. The substantial domain gap between image and sketch features needs to be bridged, while at the same time the side information has to be chosen tactfully. Existing literature has shown that varying the semantic side information greatly affects the performance of ZS-SBIR. To this end, we propose a novel graph transformer based zero-shot sketch-based image retrieval (GTZSR) framework for solving ZS-SBIR tasks which uses a novel graph transformer to preserve the topology of the classes in the semantic space and propagates the context-graph of the classes within the embedding features of the visual space. To bridge the domain gap between the visual features, we propose minimizing the Wasserstein distance between images and sketches in a learned domain-shared space. We also propose a novel compatibility loss that further aligns the two visual domains by bridging the domain gap of one class with respect to the domain gap of all other classes in the training set. Experimental results obtained on the extended Sketchy, TU-Berlin, and QuickDraw datasets exhibit sharp improvements over the existing state-of-the-art methods in both ZS-SBIR and generalized ZS-SBIR.
Multi-Task Network Pruning and Embedded Optimization for Real-time Deployment in ADAS
Jan 19, 2021
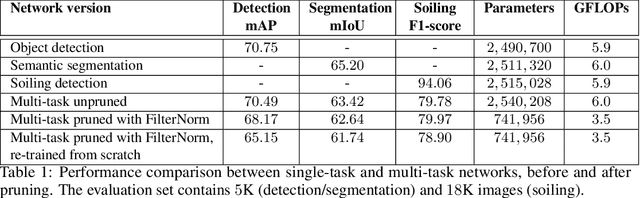
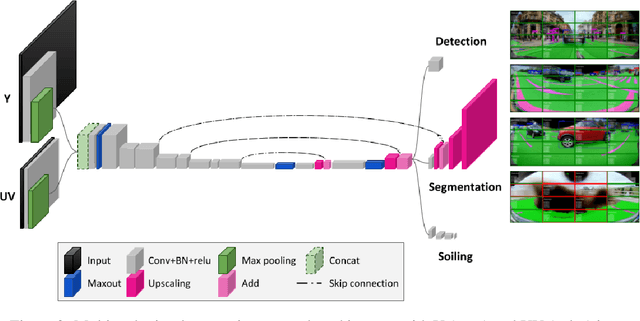
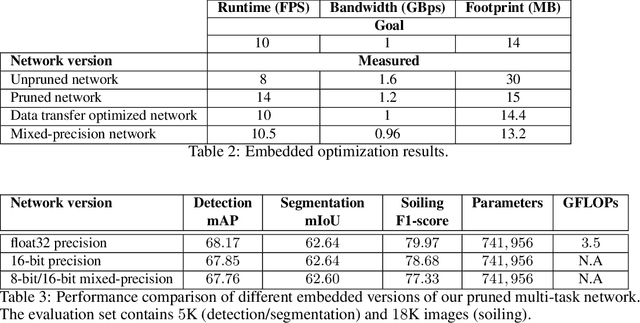
Camera-based Deep Learning algorithms are increasingly needed for perception in Automated Driving systems. However, constraints from the automotive industry challenge the deployment of CNNs by imposing embedded systems with limited computational resources. In this paper, we propose an approach to embed a multi-task CNN network under such conditions on a commercial prototype platform, i.e. a low power System on Chip (SoC) processing four surround-view fisheye cameras at 10 FPS. The first focus is on designing an efficient and compact multi-task network architecture. Secondly, a pruning method is applied to compress the CNN, helping to reduce the runtime and memory usage by a factor of 2 without lowering the performances significantly. Finally, several embedded optimization techniques such as mixed-quantization format usage and efficient data transfers between different memory areas are proposed to ensure real-time execution and avoid bandwidth bottlenecks. The approach is evaluated on the hardware platform, considering embedded detection performances, runtime and memory bandwidth. Unlike most works from the literature that focus on classification task, we aim here to study the effect of pruning and quantization on a compact multi-task network with object detection, semantic segmentation and soiling detection tasks.