 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multivariate time-series modeling with generative neural networks
Feb 25, 2020
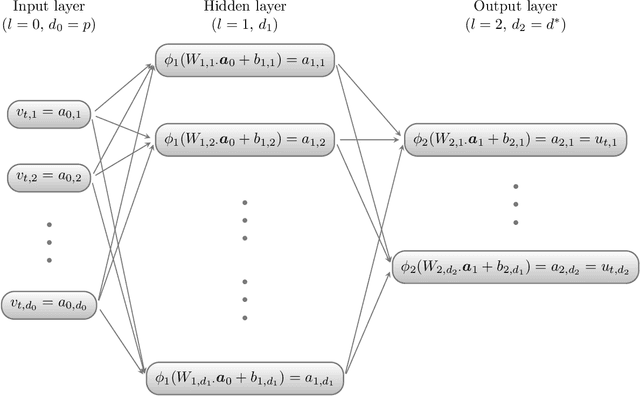
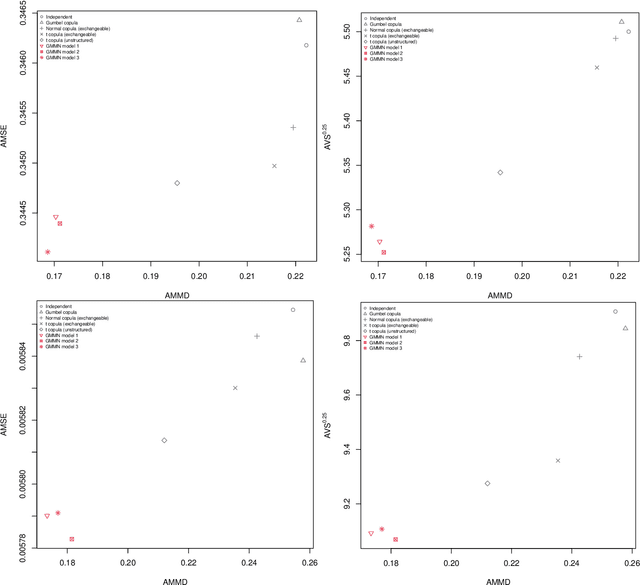
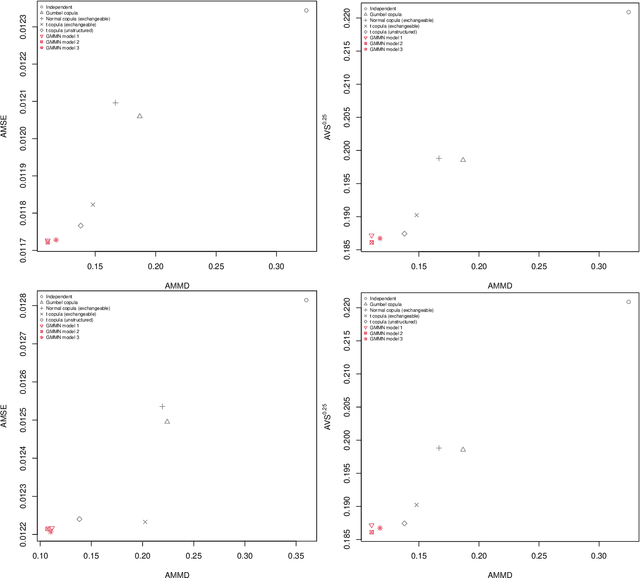
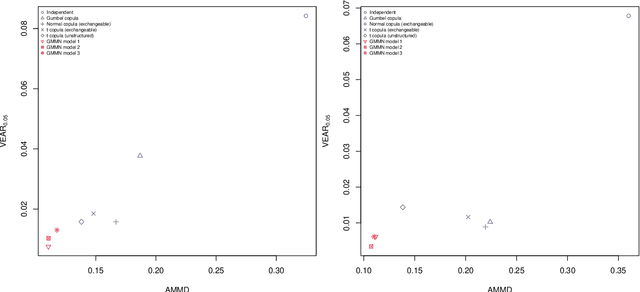
Generative moment matching networks (GMMNs) are introduced as dependence models for the joint innovation distribution of multivariate time series (MTS). Following the popular copula-GARCH approach for modeling dependent MTS data, a framework allowing us to take an alternative GMMN-GARCH approach is presented. First, ARMA-GARCH models are utilized to capture the serial dependence within each univariate marginal time series. Second, if the number of marginal time series is large, principal component analysis (PCA) is used as a dimension-reduction step. Last, the remaining cross-sectional dependence is modeled via a GMMN, our main contribution. GMMNs are highly flexible and easy to simulate from, which is a major advantage over the copula-GARCH approach. Applications involving yield curve modeling and the analysis of foreign exchange rate returns are presented to demonstrate the utility of our approach, especially in terms of producing better empirical predictive distributions and making better probabilistic forecasts. All results are reproducible with the demo GMMN_MTS_paper of the R package gnn.
Learning-based Measurement Scheduling for Loosely-Coupled Cooperative Localization
Dec 06, 2021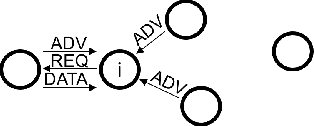
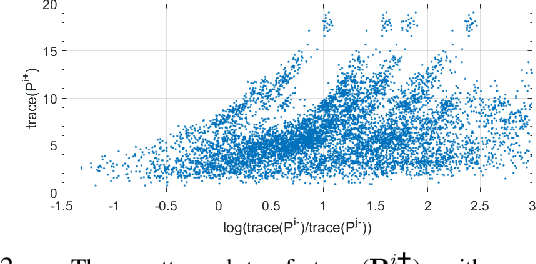
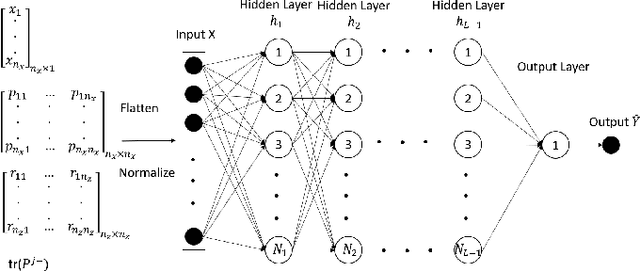
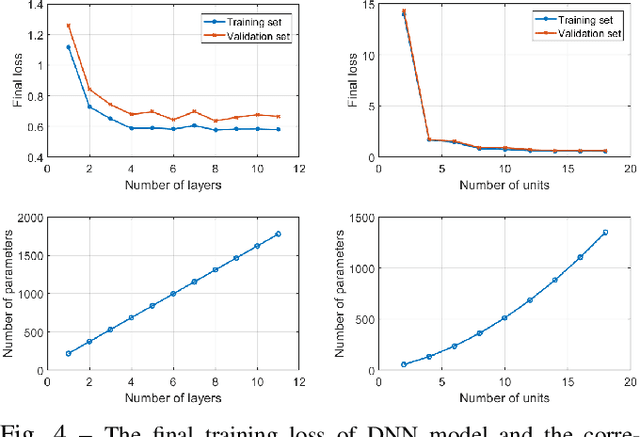
In cooperative localization, communicating mobile agents use inter-agent relative measurements to improve their dead-reckoning-based global localization. Measurement scheduling enables an agent to decide which subset of available inter-agent relative measurements it should process when its computational resources are limited. Optimal measurement scheduling is an NP-hard combinatorial optimization problem. The so-called sequential greedy (SG) algorithm is a popular suboptimal polynomial-time solution for this problem. However, the merit function evaluation for the SG algorithms requires access to the state estimate vector and error covariance matrix of all the landmark agents (teammates that an agent can take measurements from). This paper proposes a measurement scheduling for CL that follows the SG approach but reduces the communication and computation cost by using a neural network-based surrogate model as a proxy for the SG algorithm's merit function. The significance of this model is that it is driven by local information and only a scalar metadata from the landmark agents. This solution addresses the time and memory complexity issues of running the SG algorithm in three ways: (a) reducing the inter-agent communication message size, (b) decreasing the complexity of function evaluations by using a simpler surrogate (proxy) function, (c) reducing the required memory size.Simulations demonstrate our results.
Fully Test-time Adaptation by Entropy Minimization
Jun 18, 2020
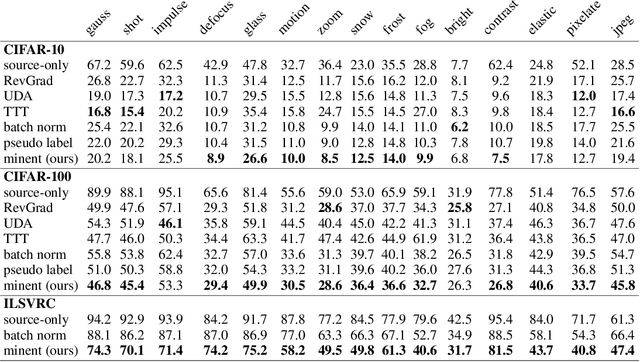

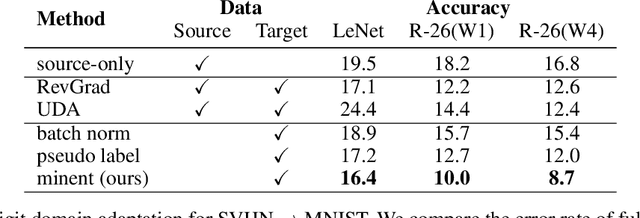
Faced with new and different data during testing, a model must adapt itself. We consider the setting of fully test-time adaptation, in which a supervised model confronts unlabeled test data from a different distribution, without the help of its labeled training data. We propose an entropy minimization approach for adaptation: we take the model's confidence as our objective as measured by the entropy of its predictions. During testing, we adapt the model by modulating its representation with affine transformations to minimize entropy. Our experiments show improved robustness to corruptions for image classification on CIFAR-10/100 and ILSVRC and demonstrate the feasibility of target-only domain adaptation for digit classification on MNIST and SVHN.
Supervised and Self-supervised Pretraining Based COVID-19 Detection Using Acoustic Breathing/Cough/Speech Signals
Jan 22, 2022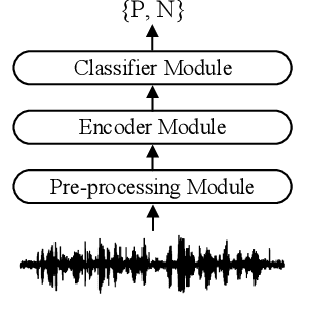
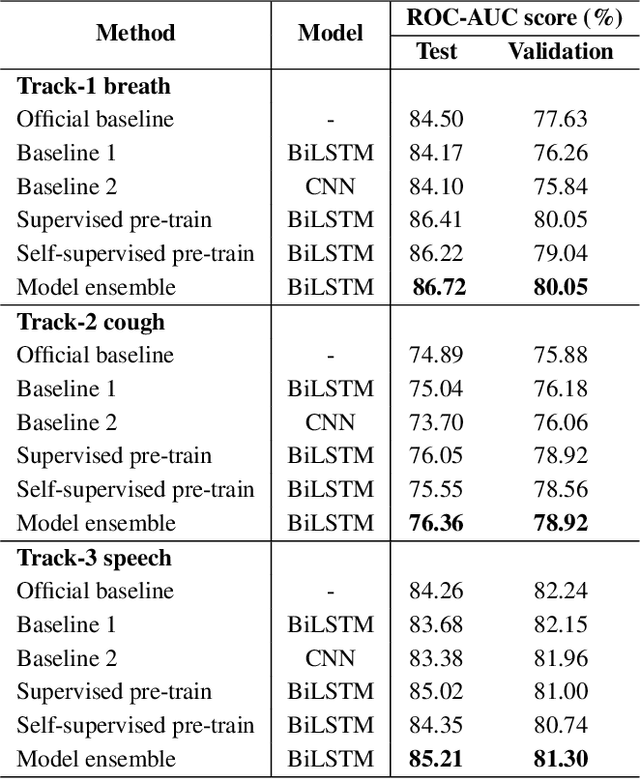
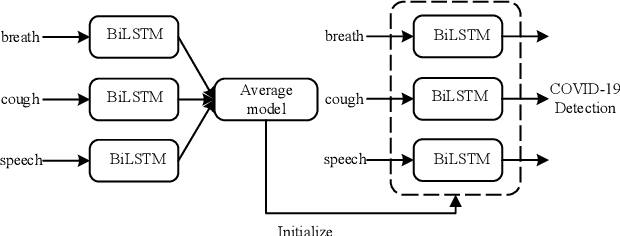
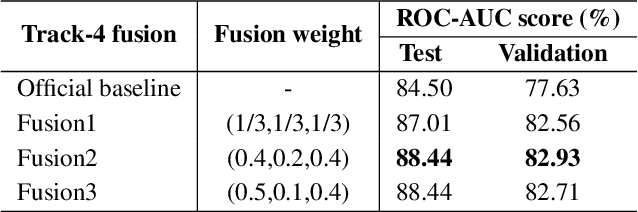
In this work, we propose a bi-directional long short-term memory (BiLSTM) network based COVID-19 detection method using breath/speech/cough signals. By using the acoustic signals to train the network, respectively, we can build individual models for three tasks, whose parameters are averaged to obtain an average model, which is then used as the initialization for the BiLSTM model training of each task. This initialization method can significantly improve the performance on the three tasks, which surpasses the official baseline results. Besides, we also utilize a public pre-trained model wav2vec2.0 and pre-train it using the official DiCOVA datasets. This wav2vec2.0 model is utilized to extract high-level features of the sound as the model input to replace conventional mel-frequency cepstral coefficients (MFCC) features. Experimental results reveal that using high-level features together with MFCC features can improve the performance. To further improve the performance, we also deploy some preprocessing techniques like silent segment removal, amplitude normalization and time-frequency mask. The proposed detection model is evaluated on the DiCOVA dataset and results show that our method achieves an area under curve (AUC) score of 88.44% on blind test in the fusion track.
Safety and Liveness Guarantees through Reach-Avoid Reinforcement Learning
Dec 23, 2021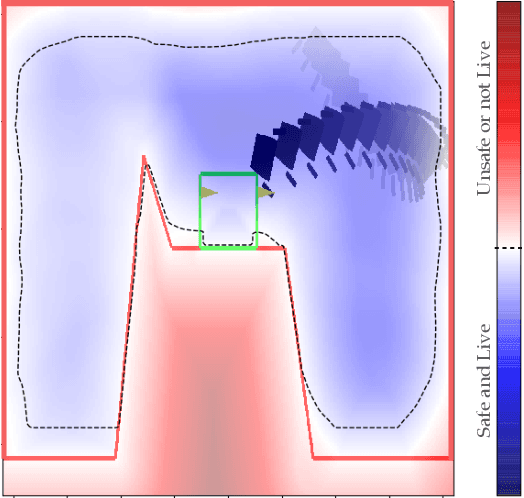
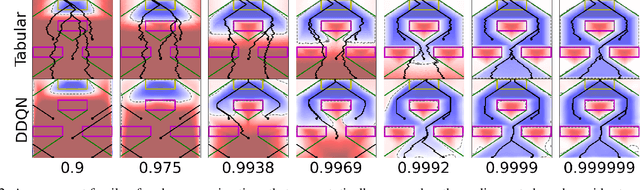
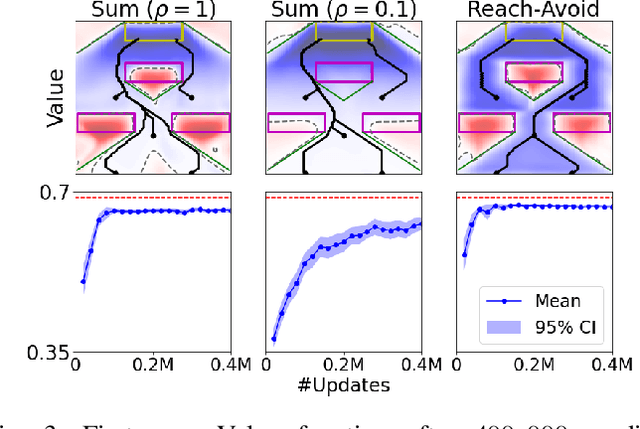
Reach-avoid optimal control problems, in which the system must reach certain goal conditions while staying clear of unacceptable failure modes, are central to safety and liveness assurance for autonomous robotic systems, but their exact solutions are intractable for complex dynamics and environments. Recent successes in reinforcement learning methods to approximately solve optimal control problems with performance objectives make their application to certification problems attractive; however, the Lagrange-type objective used in reinforcement learning is not suitable to encode temporal logic requirements. Recent work has shown promise in extending the reinforcement learning machinery to safety-type problems, whose objective is not a sum, but a minimum (or maximum) over time. In this work, we generalize the reinforcement learning formulation to handle all optimal control problems in the reach-avoid category. We derive a time-discounted reach-avoid Bellman backup with contraction mapping properties and prove that the resulting reach-avoid Q-learning algorithm converges under analogous conditions to the traditional Lagrange-type problem, yielding an arbitrarily tight conservative approximation to the reach-avoid set. We further demonstrate the use of this formulation with deep reinforcement learning methods, retaining zero-violation guarantees by treating the approximate solutions as untrusted oracles in a model-predictive supervisory control framework. We evaluate our proposed framework on a range of nonlinear systems, validating the results against analytic and numerical solutions, and through Monte Carlo simulation in previously intractable problems. Our results open the door to a range of learning-based methods for safe-and-live autonomous behavior, with applications across robotics and automation. See https://github.com/SafeRoboticsLab/safety_rl for code and supplementary material.
Attention-based Proposals Refinement for 3D Object Detection
Jan 26, 2022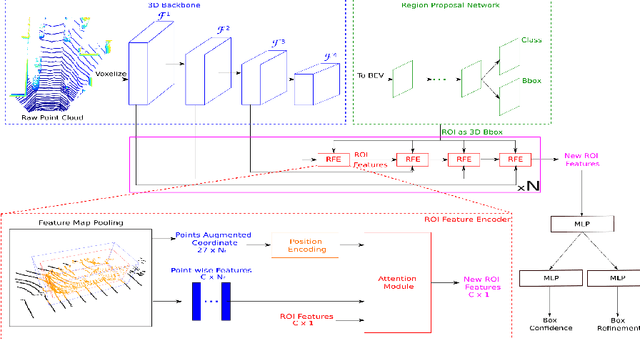
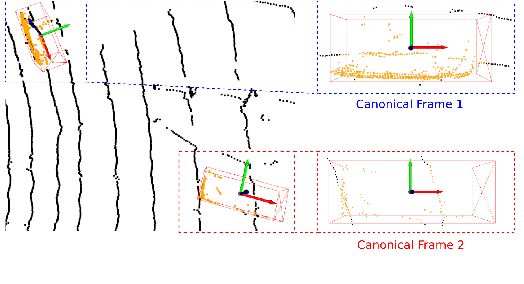
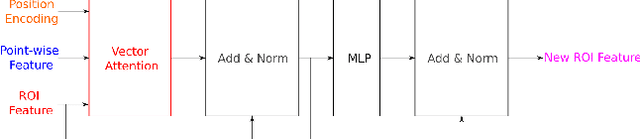
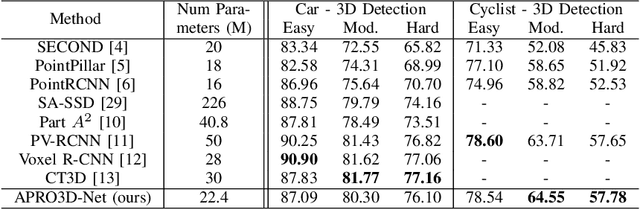
Recent advances in 3D object detection is made by developing the refinement stage for voxel-based Region Proposal Networks (RPN) to better strike the balance between accuracy and efficiency. A popular approach among state-of-the-art frameworks is to divide proposals, or Regions of Interest (ROI), into grids and extract feature for each grid location before synthesizing them to form ROI feature. While achieving impressive performances, such an approach involves a number of hand crafted components (e.g. grid sampling, set abstraction) which requires expert knowledge to be tuned correctly. This paper proposes a data-driven approach to ROI feature computing named APRO3D-Net which consists of a voxel-based RPN and a refinement stage made of Vector Attention. Unlike the original multi-head attention, Vector Attention assigns different weights to different channels within a point feature, thus being able to capture a more sophisticated relation between pooled points and ROI. Experiments on KITTI \textit{validation} set show that our method achieves competitive performance of 84.84 AP for class Car at Moderate difficulty while having the least parameters compared to closely related methods and attaining a quasi-real time inference speed at 15 FPS on NVIDIA V100 GPU. The code is released in https://github.com/quan-dao/APRO3D-Net.
Succinct Differentiation of Disparate Boosting Ensemble Learning Methods for Prognostication of Polycystic Ovary Syndrome Diagnosis
Jan 02, 2022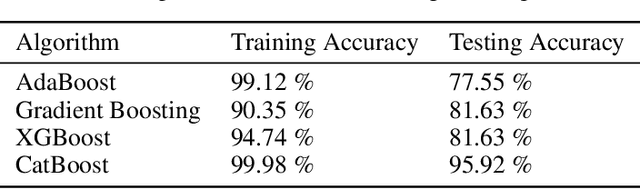
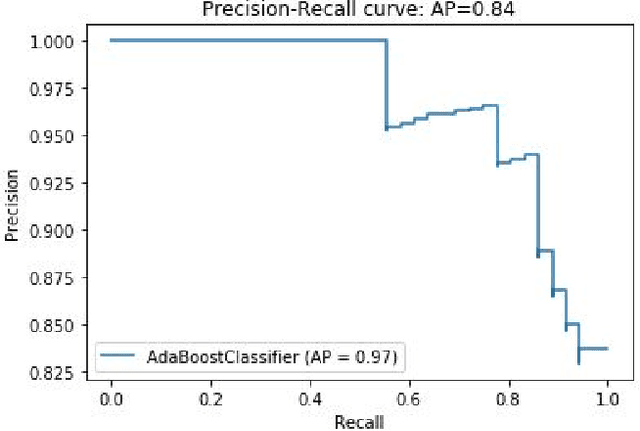
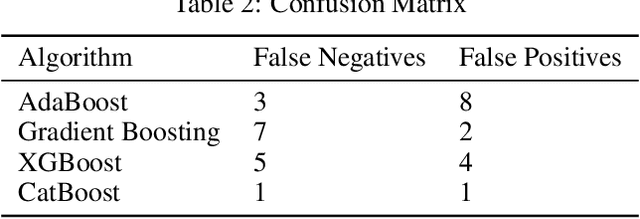
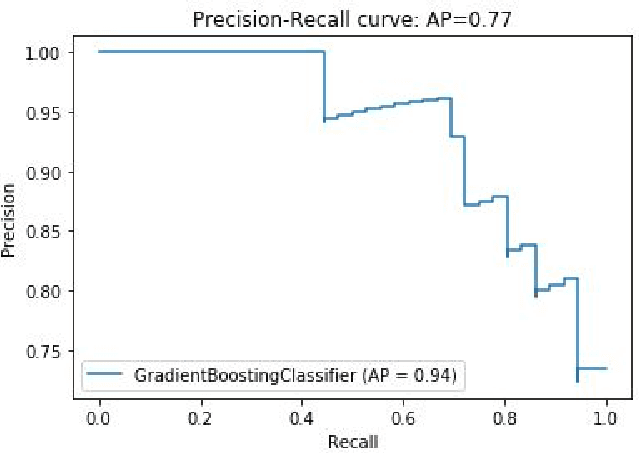
Prognostication of medical problems using the clinical data by leveraging the Machine Learning techniques with stellar precision is one of the most important real world challenges at the present time. Considering the medical problem of Polycystic Ovary Syndrome also known as PCOS is an emerging problem in women aged from 15 to 49. Diagnosing this disorder by using various Boosting Ensemble Methods is something we have presented in this paper. A detailed and compendious differentiation between Adaptive Boost, Gradient Boosting Machine, XGBoost and CatBoost with their respective performance metrics highlighting the hidden anomalies in the data and its effects on the result is something we have presented in this paper. Metrics like Confusion Matrix, Precision, Recall, F1 Score, FPR, RoC Curve and AUC have been used in this paper.
TFW2V: An Enhanced Document Similarity Method for the Morphologically Rich Finnish Language
Dec 23, 2021
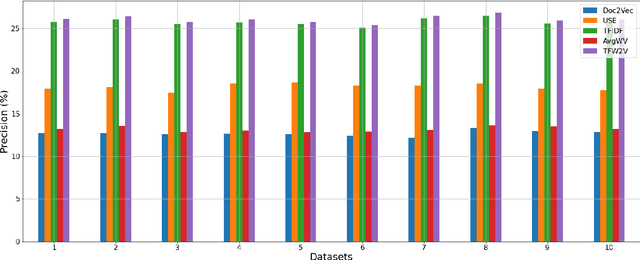
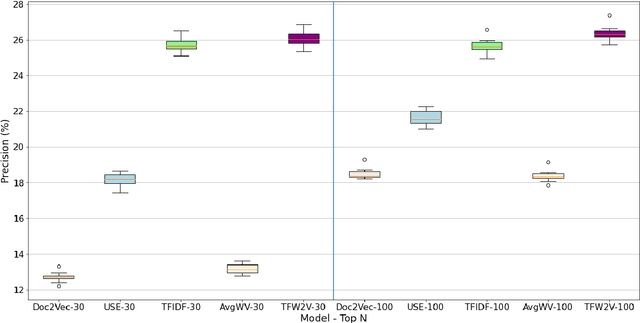
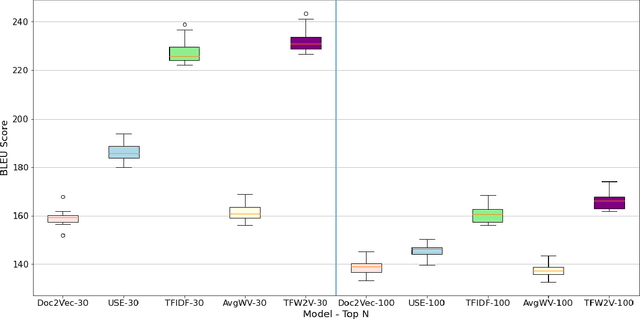
Measuring the semantic similarity of different texts has many important applications in Digital Humanities research such as information retrieval, document clustering and text summarization. The performance of different methods depends on the length of the text, the domain and the language. This study focuses on experimenting with some of the current approaches to Finnish, which is a morphologically rich language. At the same time, we propose a simple method, TFW2V, which shows high efficiency in handling both long text documents and limited amounts of data. Furthermore, we design an objective evaluation method which can be used as a framework for benchmarking text similarity approaches.
A 1.5GS/s 8b Pipelined-SAR ADC with Output Level Shifting Settling Technique in 14nm CMOS
Jan 08, 2022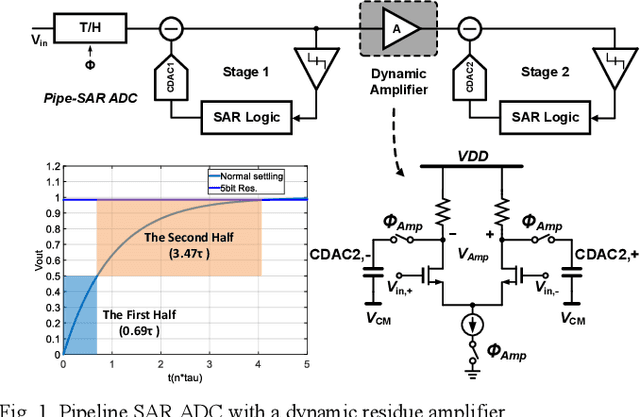
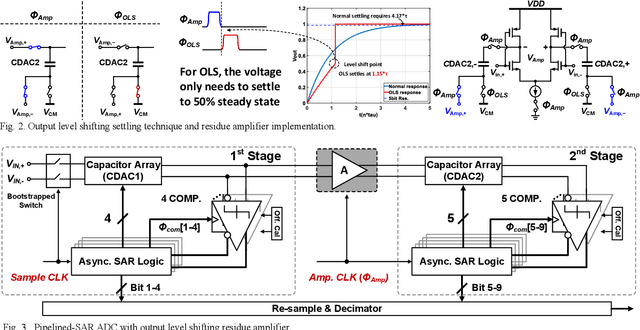
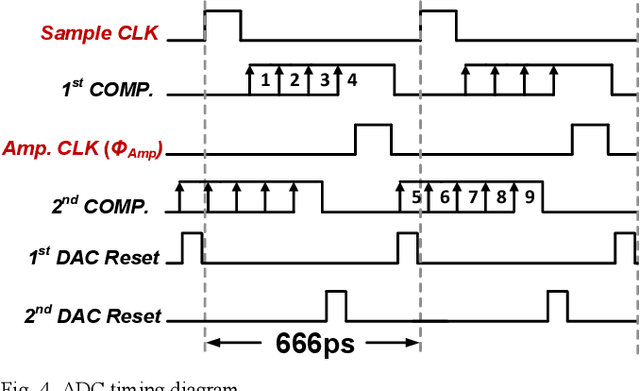
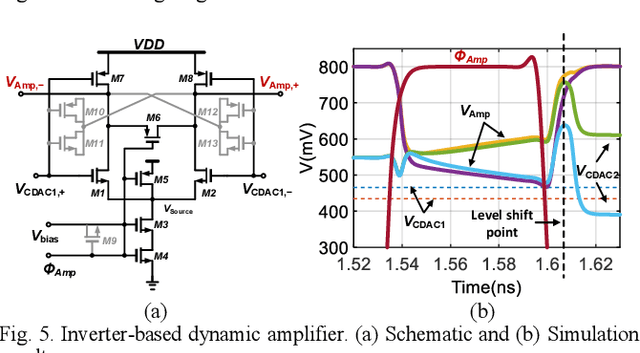
A single channel 1.5GS/s 8-bit pipelined-SAR ADC utilizes a novel output level shifting (OLS) settling technique to reduce the power and enable low-voltage operation of the dynamic residue amplifier. The ADC consists of a 4-bit first stage and a 5-bit second stage, with 1-bit redundancy to relax the offset, gain, and settling requirements of the first stage. Employing the OLS technique allows for an inter-stage gain of ~4 from the dynamic residue amplifier with a settling time that is only 28% of a conventional CML amplifier. The ADC's conversion speed is further improved with the use of parallel comparators in the two asynchronous stages. Fabricated in a 14nm FinFET technology, the ADC occupies 0.0013mm2 core area and operates with a 0.8V supply. 6.6-bit ENOB is achieved at Nyquist while consuming 2.4mW, resulting in an FOM of 16.7fJ/conv.-step.
* it is a 4 page and 9 figure IEEE Custom Integrated Circuit Conference paper
Adaptive Activation-based Structured Pruning
Jan 21, 2022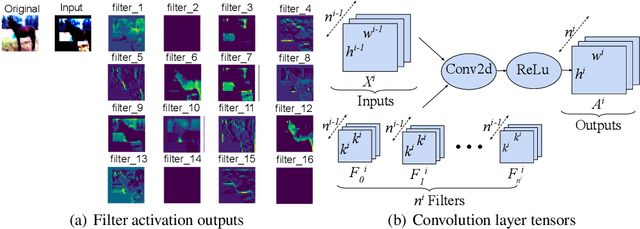
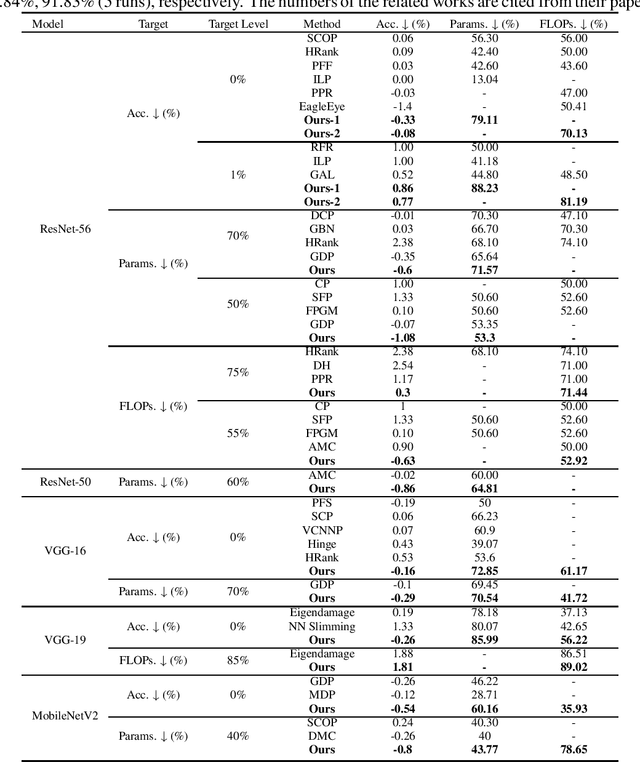
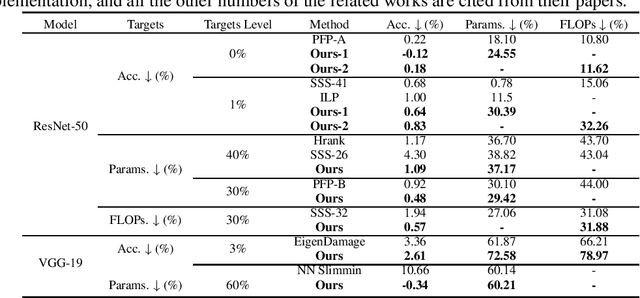
Pruning is a promising approach to compress complex deep learning models in order to deploy them on resource-constrained edge devices. However, many existing pruning solutions are based on unstructured pruning, which yield models that cannot efficiently run on commodity hardware, and require users to manually explore and tune the pruning process, which is time consuming and often leads to sub-optimal results. To address these limitations, this paper presents an adaptive, activation-based, structured pruning approach to automatically and efficiently generate small, accurate, and hardware-efficient models that meet user requirements. First, it proposes iterative structured pruning using activation-based attention feature maps to effectively identify and prune unimportant filters. Then, it proposes adaptive pruning policies for automatically meeting the pruning objectives of accuracy-critical, memory-constrained, and latency-sensitive tasks. A comprehensive evaluation shows that the proposed method can substantially outperform the state-of-the-art structured pruning works on CIFAR-10 and ImageNet datasets. For example, on ResNet-56 with CIFAR-10, without any accuracy drop, our method achieves the largest parameter reduction (79.11%), outperforming the related works by 22.81% to 66.07%, and the largest FLOPs reduction (70.13%), outperforming the related works by 14.13% to 26.53%.