 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A prediction-based approach for online dynamic radiotherapy scheduling
Dec 16, 2021
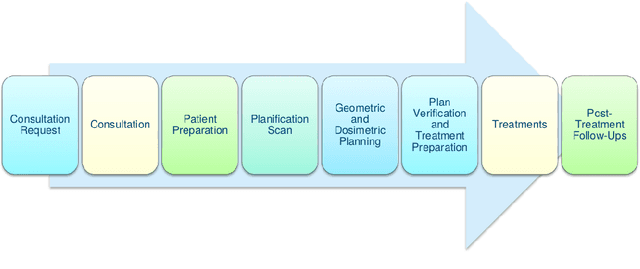
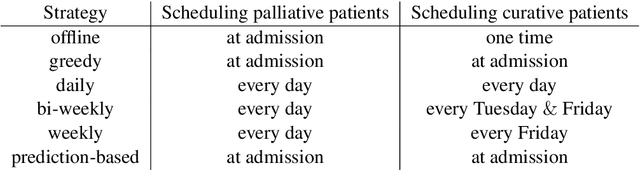
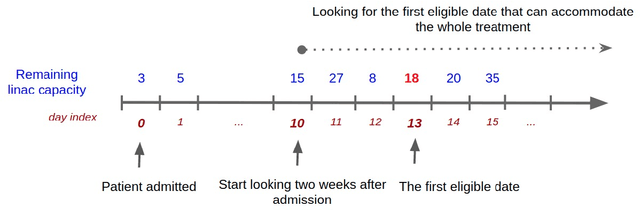
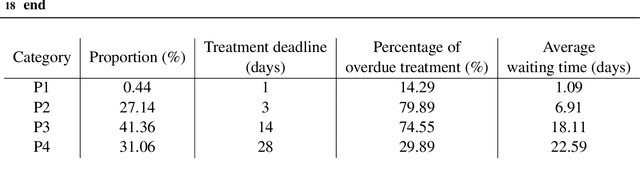
Patient scheduling is a difficult task as it involves dealing with stochastic factors such as an unknown arrival flow of patients. Scheduling radiotherapy treatments for cancer patients faces a similar problem. Curative patients need to start their treatment within the recommended deadlines, i.e., 14 or 28 days after their admission while reserving treatment capacity for palliative patients who require urgent treatments within 1 to 3 days after their admission. Most cancer centers solve the problem by reserving a fixed number of treatment slots for emergency patients. However, this flat-reservation approach is not ideal and can cause overdue treatments for emergency patients on some days while not fully exploiting treatment capacity on some other days, which also leads to delaying treatment for curative patients. This problem is especially severe in large and crowded hospitals. In this paper, we propose a prediction-based approach for online dynamic radiotherapy scheduling. An offline problem where all future patient arrivals are known in advance is solved to optimality using Integer Programming. A regression model is then trained to recognize the links between patients' arrival patterns and their ideal waiting time. The trained regression model is then embedded in a prediction-based approach that schedules a patient based on their characteristics and the present state of the calendar. The numerical results show that our prediction-based approach efficiently prevents overdue treatments for emergency patients while maintaining a good waiting time compared to other scheduling approaches based on a flat-reservation policy.
Infrastructure-enabled GPS Spoofing Detection and Correction
Feb 11, 2022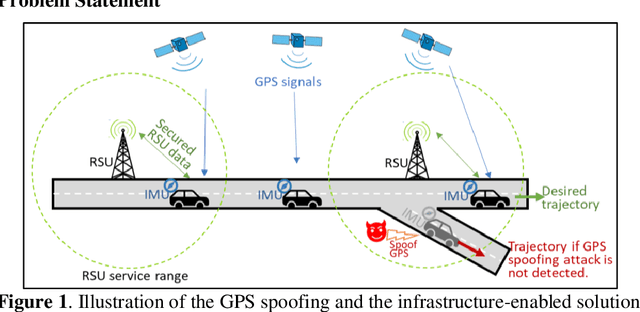
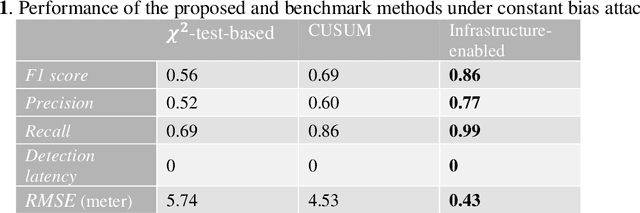
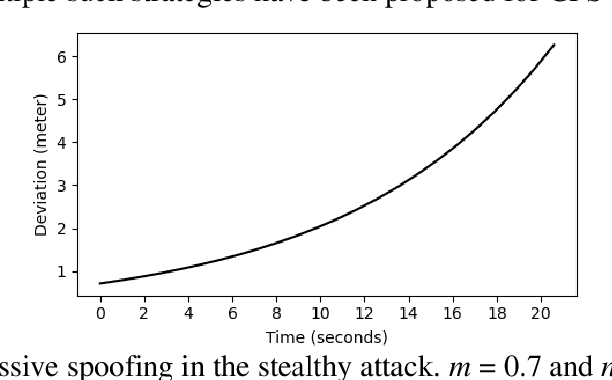
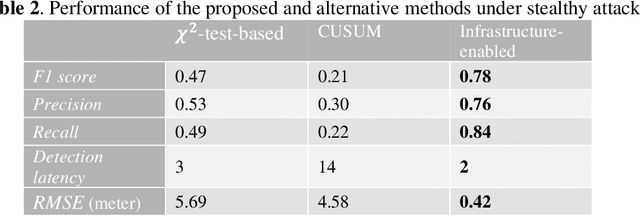
Accurate and robust localization is crucial for supporting high-level driving automation and safety. Modern localization solutions rely on various sensors, among which GPS has been and will continue to be essential. However, GPS can be vulnerable to malicious attacks and GPS spoofing has been identified as a high threat. GPS spoofing injects false information into true GPS measurements, aiming to deviate a vehicle from its true trajectory, endangering the safety of road users. With various types of vehicle-based sensors emerging, recent studies propose to detect GPS spoofing by fusing data from multiple sensors and identifying inconsistencies among them. Yet, these methods often require sophisticated algorithms and cannot handle stealthy or coordinated attacks targeting multiple sensors. With infrastructure becoming increasingly important in supporting emerging vehicle technologies and systems (e.g., automated vehicles), this study explores the potential of applying infrastructure data in defending against GPS spoofing. We propose an infrastructure-enabled method by deploying roadside infrastructure as an independent, secured data source. A real-time detector, based on the Isolation Forest, is constructed to detect GPS spoofing. Once spoofing is detected, GPS measurements are isolated, and the potentially compromised location estimator is corrected using the infrastructure data. The proposed method relies less on vehicular onboard data than existing solutions. Enabled by the secure infrastructure data, we can design a simpler yet more effective solution against GPS spoofing, compared with state-of-the-art defense methods. We test the proposed method using both simulation data and real-world GPS data, and show its effectiveness in defending various types of GPS spoofing attacks, including a type of stealthy attacks that are proposed to fail the production-grade autonomous driving systems.
Indoor Localization Using Smartphone Magnetic with Multi-Scale TCN and LSTM
Sep 24, 2021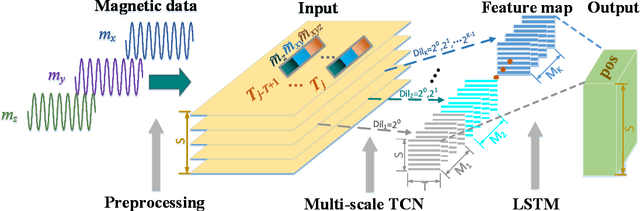
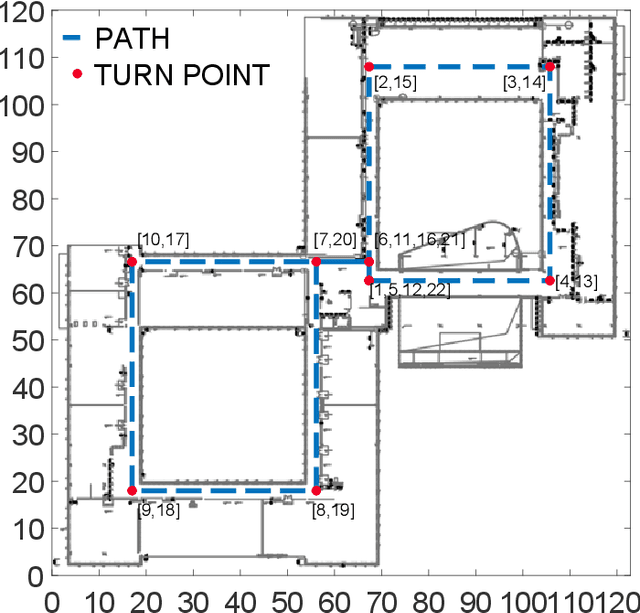
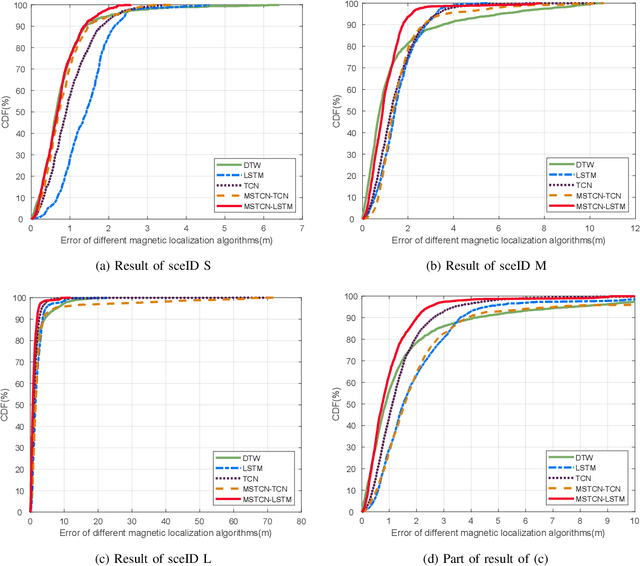
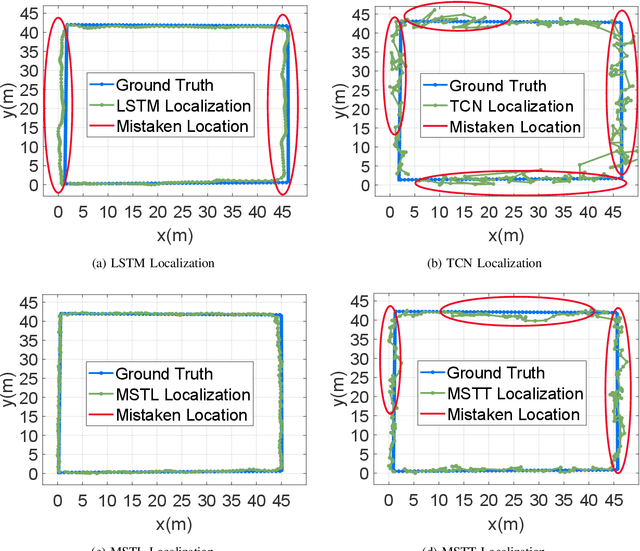
A novel multi-scale temporal convolutional network (TCN) and long short-term memory network (LSTM) based magnetic localization approach is proposed. To enhance the discernibility of geomagnetic signals, the time-series preprocessing approach is constructed at first. Next, the TCN is invoked to expand the feature dimensions on the basis of keeping the time-series characteristics of LSTM model. Then, a multi-scale time-series layer is constructed with multiple TCNs of different dilation factors to address the problem of inconsistent time-series speed between localization model and mobile users. A stacking framework of multi-scale TCN and LSTM is eventually proposed for indoor magnetic localization. Experiment results demonstrate the effectiveness of the proposed algorithm in indoor localization.
Approximation Algorithms for ROUND-UFP and ROUND-SAP
Feb 07, 2022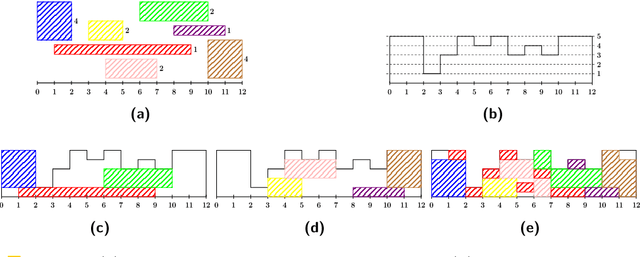
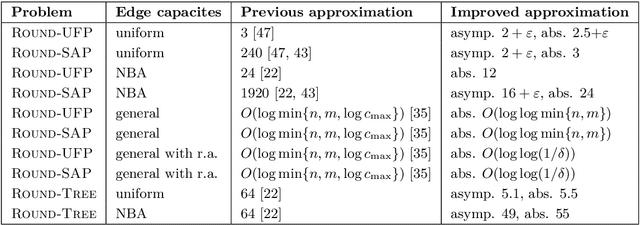

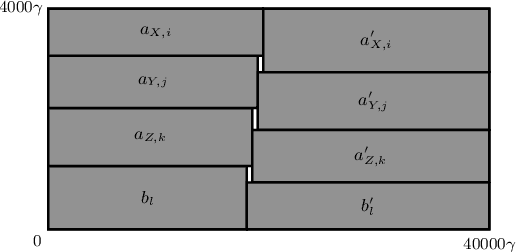
We study ROUND-UFP and ROUND-SAP, two generalizations of the classical BIN PACKING problem that correspond to the unsplittable flow problem on a path (UFP) and the storage allocation problem (SAP), respectively. We are given a path with capacities on its edges and a set of tasks where for each task we are given a demand and a subpath. In ROUND-UFP, the goal is to find a packing of all tasks into a minimum number of copies (rounds) of the given path such that for each copy, the total demand of tasks on any edge does not exceed the capacity of the respective edge. In ROUND-SAP, the tasks are considered to be rectangles and the goal is to find a non-overlapping packing of these rectangles into a minimum number of rounds such that all rectangles lie completely below the capacity profile of the edges. We show that in contrast to BIN PACKING, both the problems do not admit an asymptotic polynomial-time approximation scheme (APTAS), even when all edge capacities are equal. However, for this setting, we obtain asymptotic $(2+\varepsilon)$-approximations for both problems. For the general case, we obtain an $O(\log\log n)$-approximation algorithm and an $O(\log\log\frac{1}{\delta})$-approximation under $(1+\delta)$-resource augmentation for both problems. For the intermediate setting of the no bottleneck assumption (i.e., the maximum task demand is at most the minimum edge capacity), we obtain absolute $12$- and asymptotic $(16+\varepsilon)$-approximation algorithms for ROUND-UFP and ROUND-SAP, respectively.
Generation of Synthetic Rat Brain MRI scans with a 3D Enhanced Alpha-GAN
Dec 27, 2021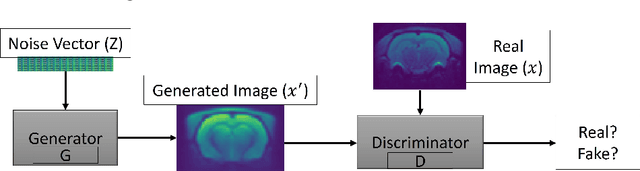
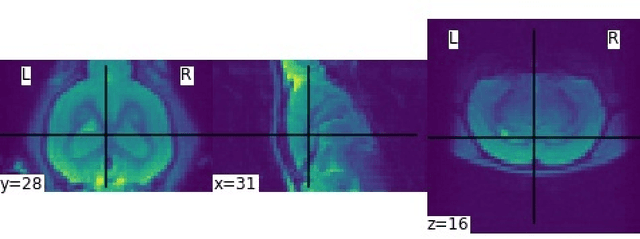
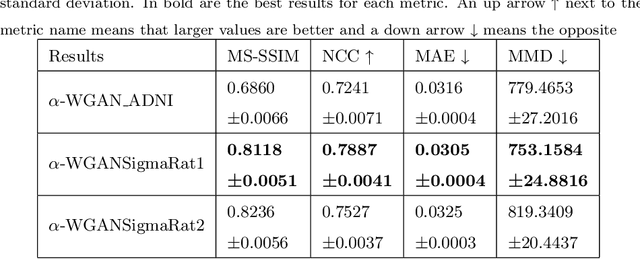
Translational brain research using Magnetic Resonance Imaging (MRI) is becoming increasingly popular as animal models are an essential part of scientific studies and ultra-high-field scanners become more available. Some drawbacks of MRI are MRI scanner availability, and the time needed to perform a full scanning session (it usually takes over 30 minutes). Data protection laws and 3R ethical rule also make it difficult to create large data sets for training Deep Learning models. Generative Adversarial Networks (GAN) have been shown capable of performing data augmentation with higher quality than other techniques. In this work, the alpha-GAN architecture is used to test its ability to generate realistic 3D MRI scans of the rat brain. As far as the authors are aware, this is the first time an approach based on GANs is used for data augmentation in preclinical data. The generated scans are evaluated using various qualitative and quantitative metrics. A Turing test performed by 4 experts has shown that the generated scans can trick almost any expert. The generated scans were also used to evaluate their impact on the performance of an existing deep learning model developed for rat brain segmentation of white matter, grey matter, and cerebrospinal fluid. The models were compared using the Dice score. The best results for the segmentation of whole brain and white matter were achieved when 174 real scans and 348 synthetic ones were used, with improvements of 0.0172 and 0.0129. The use of 174 real scans and 87 synthetic ones led to improvements of 0.0038 and 0.0764 of grey matter and cerebrospinal fluid segmentation. Thus, by using the proposed new normalisation layer and loss functions, it was possible to improve the realism of the generated rat MRI scans and it was demonstrated that using the data generated improved the segmentation model more than using conventional data augmentation.
Improving Robustness on Seasonality-Heavy Multivariate Time Series Anomaly Detection
Jul 25, 2020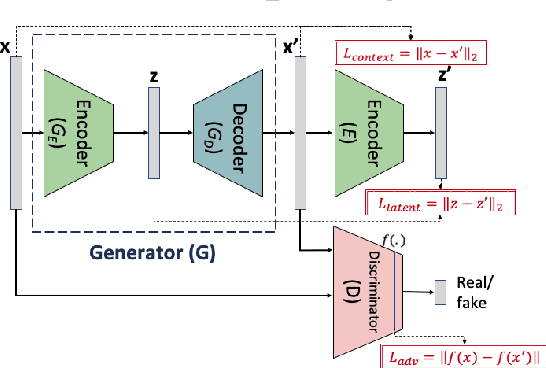
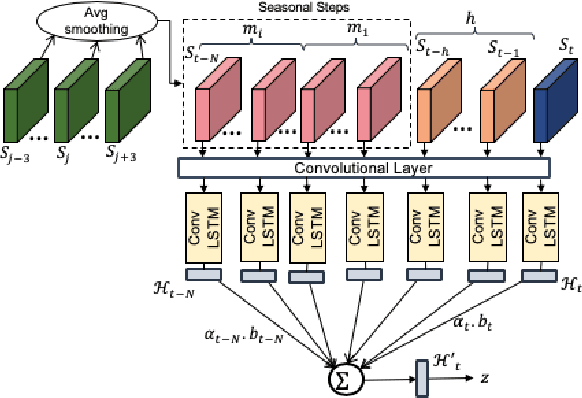
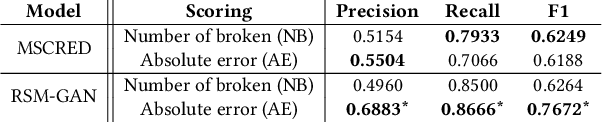
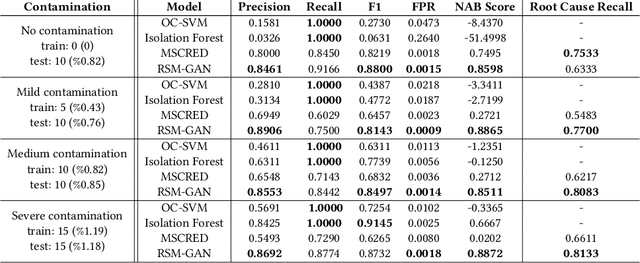
Robust Anomaly Detection (AD) on time series data is a key component for monitoring many complex modern systems. These systems typically generate high-dimensional time series that can be highly noisy, seasonal, and inter-correlated. This paper explores some of the challenges in such data, and proposes a new approach that makes inroads towards increased robustness on seasonal and contaminated data, while providing a better root cause identification of anomalies. In particular, we propose the use of Robust Seasonal Multivariate Generative Adversarial Network (RSM-GAN) that extends recent advancements in GAN with the adoption of convolutional-LSTM layers and attention mechanisms to produce excellent performance on various settings. We conduct extensive experiments in which not only do this model displays more robust behavior on complex seasonality patterns, but also shows increased resistance to training data contamination. We compare it with existing classical and deep-learning AD models, and show that this architecture is associated with the lowest false positive rate and improves precision by 30% and 16% in real-world and synthetic data, respectively.
* arXiv admin note: substantial text overlap with arXiv:1911.07104
Metric Hypertransformers are Universal Adapted Maps
Jan 31, 2022

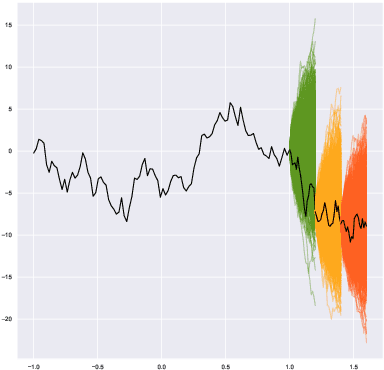

We introduce a universal class of geometric deep learning models, called metric hypertransformers (MHTs), capable of approximating any adapted map $F:\mathscr{X}^{\mathbb{Z}}\rightarrow \mathscr{Y}^{\mathbb{Z}}$ with approximable complexity, where $\mathscr{X}\subseteq \mathbb{R}^d$ and $\mathscr{Y}$ is any suitable metric space, and $\mathscr{X}^{\mathbb{Z}}$ (resp. $\mathscr{Y}^{\mathbb{Z}}$) capture all discrete-time paths on $\mathscr{X}$ (resp. $\mathscr{Y}$). Suitable spaces $\mathscr{Y}$ include various (adapted) Wasserstein spaces, all Fr\'{e}chet spaces admitting a Schauder basis, and a variety of Riemannian manifolds arising from information geometry. Even in the static case, where $f:\mathscr{X}\rightarrow \mathscr{Y}$ is a H\"{o}lder map, our results provide the first (quantitative) universal approximation theorem compatible with any such $\mathscr{X}$ and $\mathscr{Y}$. Our universal approximation theorems are quantitative, and they depend on the regularity of $F$, the choice of activation function, the metric entropy and diameter of $\mathscr{X}$, and on the regularity of the compact set of paths whereon the approximation is performed. Our guiding examples originate from mathematical finance. Notably, the MHT models introduced here are able to approximate a broad range of stochastic processes' kernels, including solutions to SDEs, many processes with arbitrarily long memory, and functions mapping sequential data to sequences of forward rate curves.
Frequency comb and machine learning-based breath analysis for COVID-19 classification
Feb 04, 2022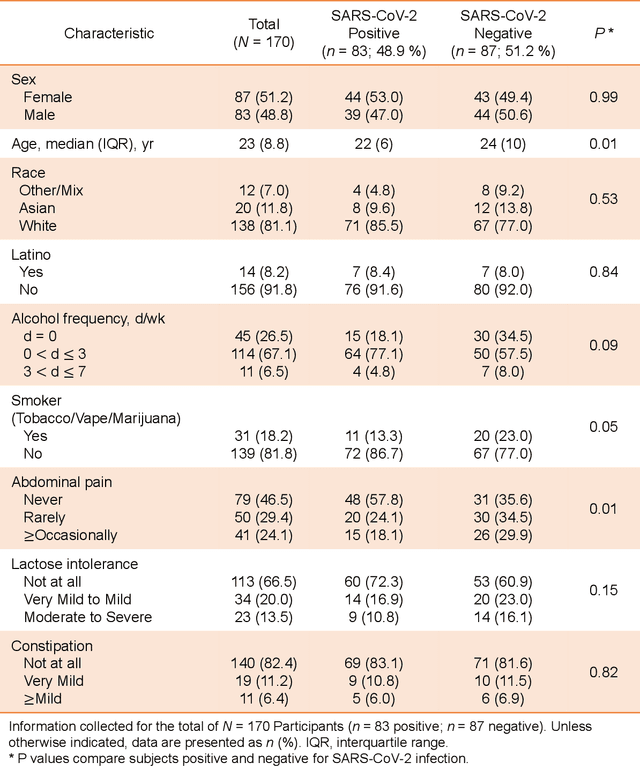
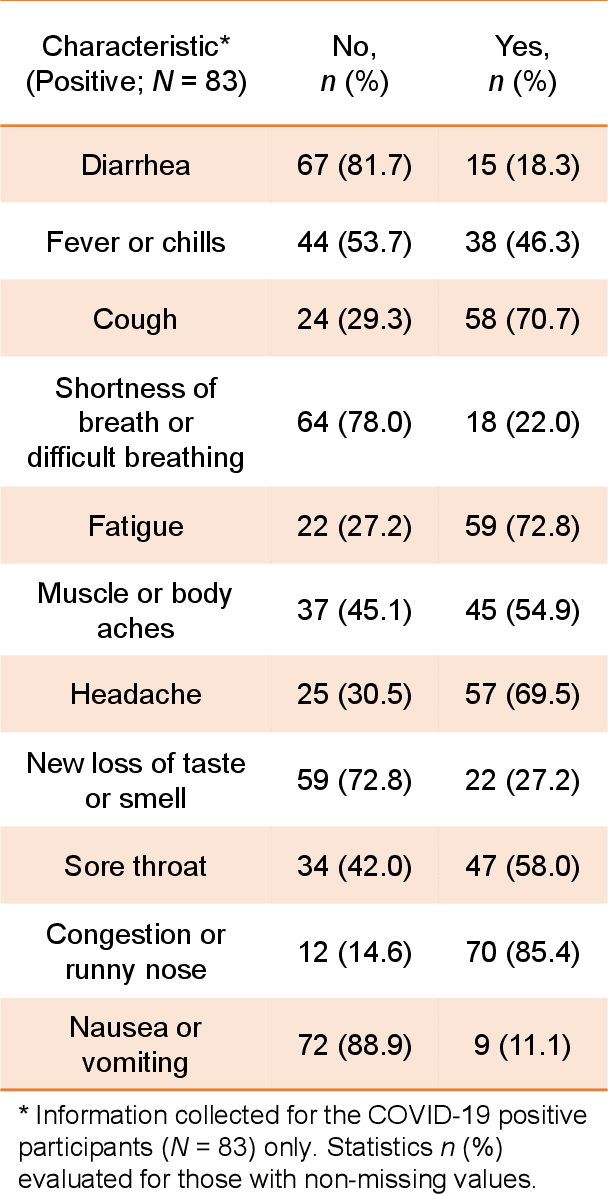
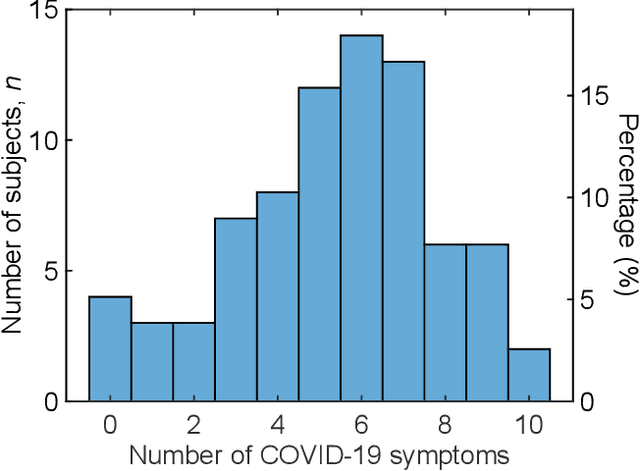
Human breath contains hundreds of volatile molecules that can provide powerful, non-intrusive spectral diagnosis of a diverse set of diseases and physiological/metabolic states. To unleash this tremendous potential for medical science, we present a robust analytical method that simultaneously measures tens of thousands of spectral features in each breath sample, followed by efficient and detail-specific multivariate data analysis for unambiguous binary medical response classification. We combine mid-infrared cavity-enhanced direct frequency comb spectroscopy (CE-DFCS), capable of real-time collection of tens of thousands of distinct molecular features at parts-per-trillion sensitivity, with supervised machine learning, capable of analysis and verification of extremely high-dimensional input data channels. Here, we present the first application of this method to the breath detection of Coronavirus Disease 2019 (COVID-19). Using 170 individual samples at the University of Colorado, we report a cross-validated area under the Receiver-Operating-Characteristics curve of 0.849(4), providing excellent prediction performance. Further, this method detected a significant difference between male and female breath as well as other variables such as smoking and abdominal pain. Together, these highlight the utility of CE-DFCS for rapid, non-invasive detection of diverse biological conditions and disease states. The unique properties of frequency comb spectroscopy thus help establish precise digital spectral fingerprints for building accurate databases and provide means for simultaneous multi-response classifications. The predictive power can be further enhanced with readily scalable comb spectral coverage.
A Simple and Fast Baseline for Tuning Large XGBoost Models
Nov 12, 2021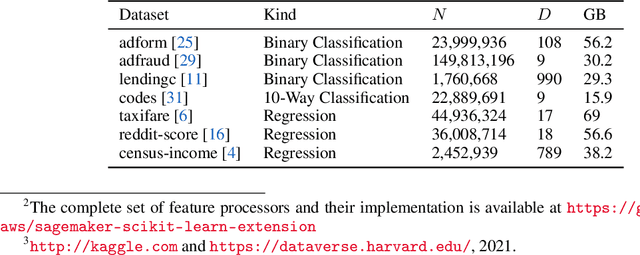
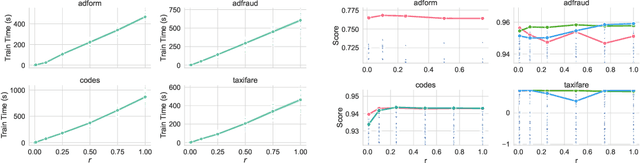
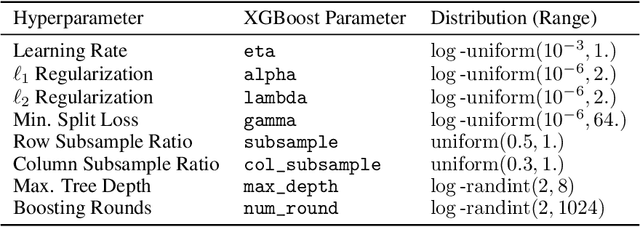
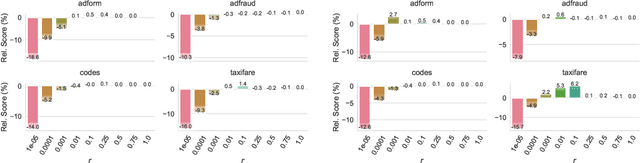
XGBoost, a scalable tree boosting algorithm, has proven effective for many prediction tasks of practical interest, especially using tabular datasets. Hyperparameter tuning can further improve the predictive performance, but unlike neural networks, full-batch training of many models on large datasets can be time consuming. Owing to the discovery that (i) there is a strong linear relation between dataset size & training time, (ii) XGBoost models satisfy the ranking hypothesis, and (iii) lower-fidelity models can discover promising hyperparameter configurations, we show that uniform subsampling makes for a simple yet fast baseline to speed up the tuning of large XGBoost models using multi-fidelity hyperparameter optimization with data subsets as the fidelity dimension. We demonstrate the effectiveness of this baseline on large-scale tabular datasets ranging from $15-70\mathrm{GB}$ in size.
ARC Nav -- A 3D Navigation Stack for Autonomous Robots
Nov 12, 2021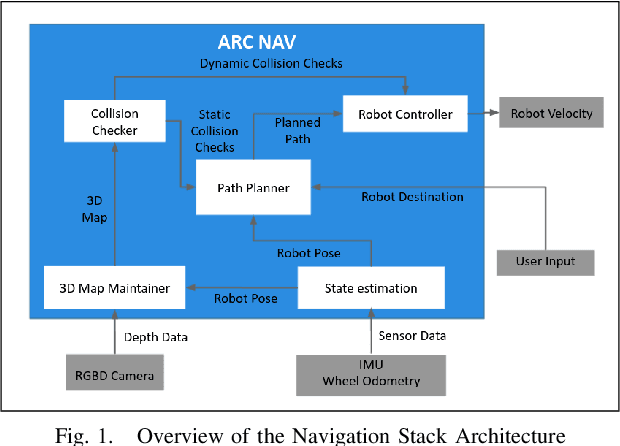

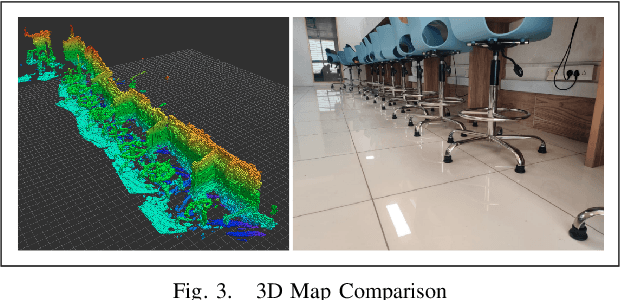
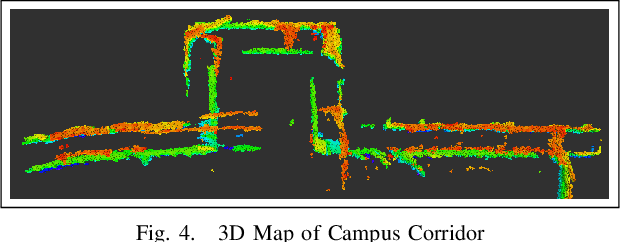
Popular navigation stacks implemented on top of open-source frameworks such as ROS(Robot Operating System) and ROS2 represent the robot workspace using a discretized 2D occupancy grid. This method, while requiring less computation, restricts the use of such navigation stacks to wheeled robots navigating on flat surfaces. In this paper, we present a navigation stack that uses a volumetric representation of the robot workspace, and hence can be extended to aerial and legged robots navigating through uneven terrain. Additionally, we present a new sampling-based motion planning algorithm which introduces a bi-directional approach to the Batch Informed Trees (BIT*) motion planning algorithm, whilst wrapping it with a strategy switching approach in order to reduce the initial time taken to find a path, in addition to the time taken to find the shortest path.