 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stain-free Detection of Embryo Polarization using Deep Learning
Nov 08, 2021
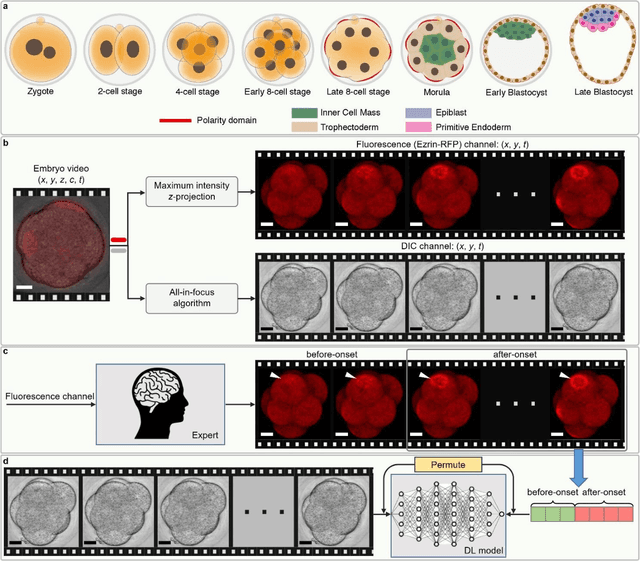
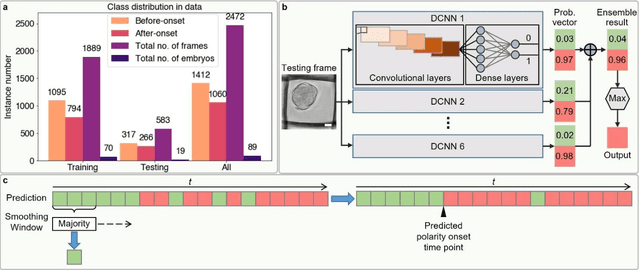
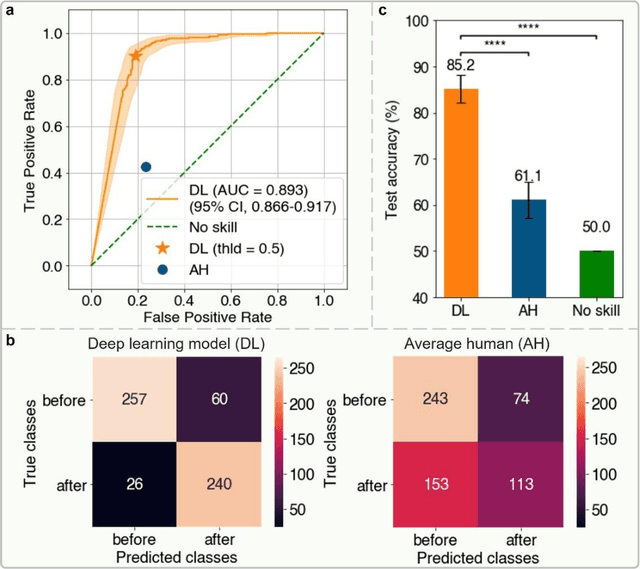

Polarization of the mammalian embryo at the right developmental time is critical for its development to term and would be valuable in assessing the potential of human embryos. However, tracking polarization requires invasive fluorescence staining, impermissible in the in vitro fertilization clinic. Here, we report the use of artificial intelligence to detect polarization from unstained time-lapse movies of mouse embryos. We assembled a dataset of bright-field movie frames from 8-cell-stage embryos, side-by-side with corresponding images of fluorescent markers of cell polarization. We then used an ensemble learning model to detect whether any bright-field frame showed an embryo before or after onset of polarization. Our resulting model has an accuracy of 85% for detecting polarization, significantly outperforming human volunteers trained on the same data (61% accuracy). We discovered that our self-learning model focuses upon the angle between cells as one known cue for compaction, which precedes polarization, but it outperforms the use of this cue alone. By compressing three-dimensional time-lapsed image data into two-dimensions, we are able to reduce data to an easily manageable size for deep learning processing. In conclusion, we describe a method for detecting a key developmental feature of embryo development that avoids clinically impermissible fluorescence staining.
Second-Order Neural ODE Optimizer
Sep 29, 2021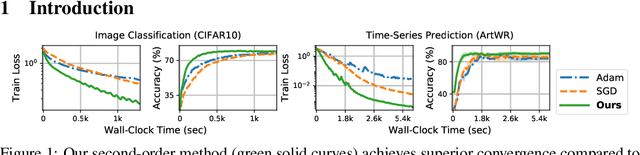


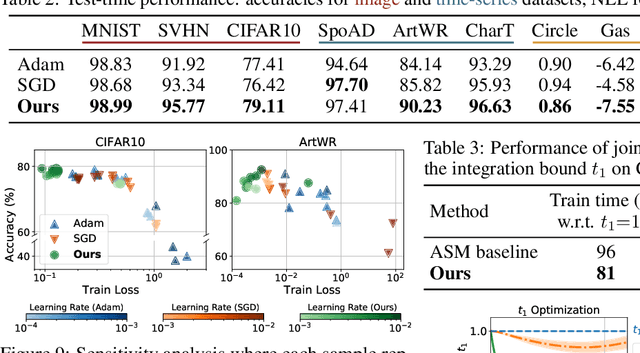
We propose a novel second-order optimization framework for training the emerging deep continuous-time models, specifically the Neural Ordinary Differential Equations (Neural ODEs). Since their training already involves expensive gradient computation by solving a backward ODE, deriving efficient second-order methods becomes highly nontrivial. Nevertheless, inspired by the recent Optimal Control (OC) interpretation of training deep networks, we show that a specific continuous-time OC methodology, called Differential Programming, can be adopted to derive backward ODEs for higher-order derivatives at the same O(1) memory cost. We further explore a low-rank representation of the second-order derivatives and show that it leads to efficient preconditioned updates with the aid of Kronecker-based factorization. The resulting method converges much faster than first-order baselines in wall-clock time, and the improvement remains consistent across various applications, e.g. image classification, generative flow, and time-series prediction. Our framework also enables direct architecture optimization, such as the integration time of Neural ODEs, with second-order feedback policies, strengthening the OC perspective as a principled tool of analyzing optimization in deep learning.
VGAER: graph neural network reconstruction based community detection
Jan 19, 2022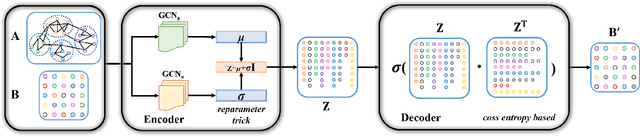
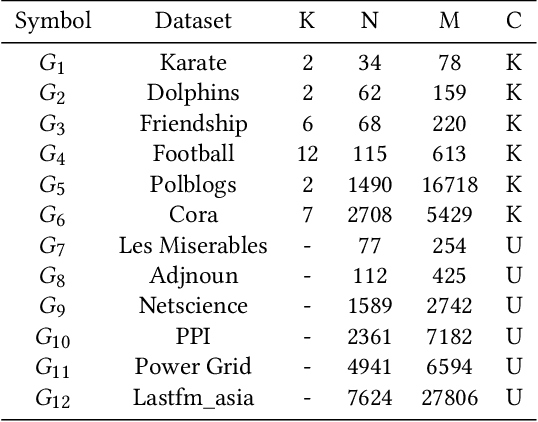
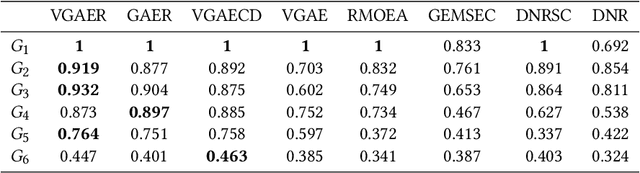
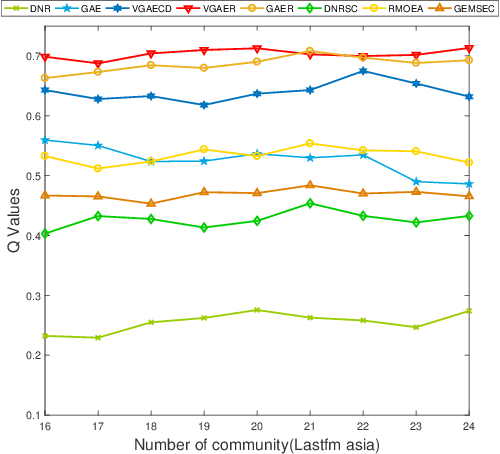
Community detection is a fundamental and important issue in network science, but there are only a few community detection algorithms based on graph neural networks, among which unsupervised algorithms are almost blank. By fusing the high-order modularity information with network features, this paper proposes a Variational Graph AutoEncoder Reconstruction based community detection VGAER for the first time, and gives its non-probabilistic version. They do not need any prior information. We have carefully designed corresponding input features, decoder, and downstream tasks based on the community detection task and these designs are concise, natural, and perform well (NMI values under our design are improved by 59.1% - 565.9%). Based on a series of experiments with wide range of datasets and advanced methods, VGAER has achieved superior performance and shows strong competitiveness and potential with a simpler design. Finally, we report the results of algorithm convergence analysis and t-SNE visualization, which clearly depicted the stable performance and powerful network modularity ability of VGAER. Our codes are available at https://github.com/qcydm/VGAER.
Comparative study of 3D object detection frameworks based on LiDAR data and sensor fusion techniques
Feb 05, 2022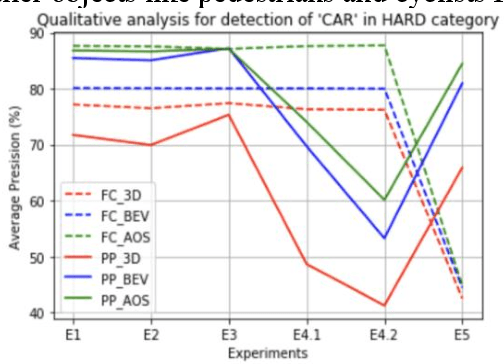
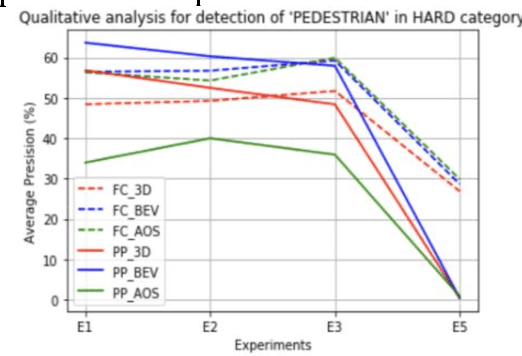
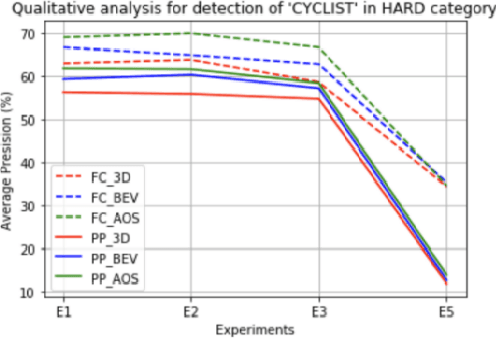
Estimating and understanding the surroundings of the vehicle precisely forms the basic and crucial step for the autonomous vehicle. The perception system plays a significant role in providing an accurate interpretation of a vehicle's environment in real-time. Generally, the perception system involves various subsystems such as localization, obstacle (static and dynamic) detection, and avoidance, mapping systems, and others. For perceiving the environment, these vehicles will be equipped with various exteroceptive (both passive and active) sensors in particular cameras, Radars, LiDARs, and others. These systems are equipped with deep learning techniques that transform the huge amount of data from the sensors into semantic information on which the object detection and localization tasks are performed. For numerous driving tasks, to provide accurate results, the location and depth information of a particular object is necessary. 3D object detection methods, by utilizing the additional pose data from the sensors such as LiDARs, stereo cameras, provides information on the size and location of the object. Based on recent research, 3D object detection frameworks performing object detection and localization on LiDAR data and sensor fusion techniques show significant improvement in their performance. In this work, a comparative study of the effect of using LiDAR data for object detection frameworks and the performance improvement seen by using sensor fusion techniques are performed. Along with discussing various state-of-the-art methods in both the cases, performing experimental analysis, and providing future research directions.
Anomaly Detection And Classification In Time Series With Kervolutional Neural Networks
May 14, 2020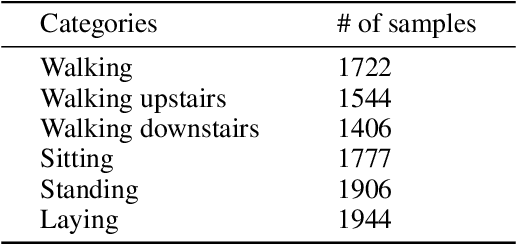

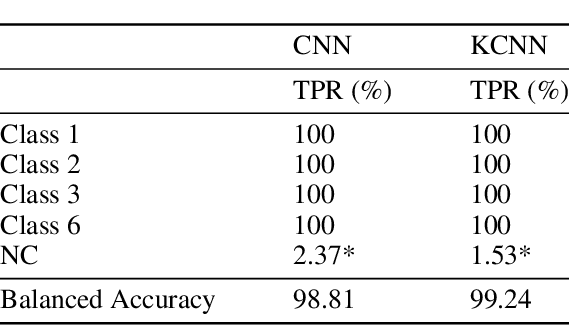
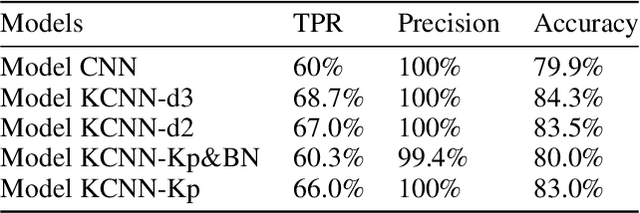
Recently, with the development of deep learning, end-to-end neural network architectures have been increasingly applied to condition monitoring signals. They have demonstrated superior performance for fault detection and classification, in particular using convolutional neural networks. Even more recently, an extension of the concept of convolution to the concept of kervolution has been proposed with some promising results in image classification tasks. In this paper, we explore the potential of kervolutional neural networks applied to time series data. We demonstrate that using a mixture of convolutional and kervolutional layers improves the model performance. The mixed model is first applied to a classification task in time series, as a benchmark dataset. Subsequently, the proposed mixed architecture is used to detect anomalies in time series data recorded by accelerometers on helicopters. We propose a residual-based anomaly detection approach using a temporal auto-encoder. We demonstrate that mixing kervolutional with convolutional layers in the encoder is more sensitive to variations in the input data and is able to detect anomalous time series in a better way.
Dynamic Time Warp Convolutional Networks
Nov 05, 2019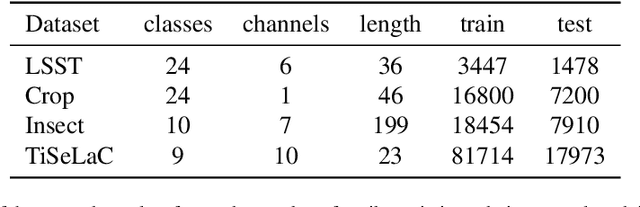
Where dealing with temporal sequences it is fair to assume that the same kind of deformations that motivated the development of the Dynamic Time Warp algorithm could be relevant also in the calculation of the dot product ("convolution") in a 1-D convolution layer. In this work a method is proposed for aligning the convolution filter and the input where they are locally out of phase utilising an algorithm similar to the Dynamic Time Warp. The proposed method enables embedding a non-parametric warping of temporal sequences for increasing similarity directly in deep networks and can expand on the generalisation capabilities and the capacity of standard 1-D convolution layer where local sequential deformations are present in the input. Experimental results demonstrate the proposed method exceeds or matches the standard 1-D convolution layer in terms of the maximum accuracy achieved on a number of time series classification tasks. In addition the impact of different hyperparameters settings is investigated given different datasets and the results support the conclusions of previous work done in relation to the choice of DTW parameter values. The proposed layer can be freely integrated with other typical layers to compose deep artificial neural networks of an arbitrary architecture that are trained using standard stochastic gradient descent.
Assisting Unknown Teammates in Unknown Tasks: Ad Hoc Teamwork under Partial Observability
Jan 10, 2022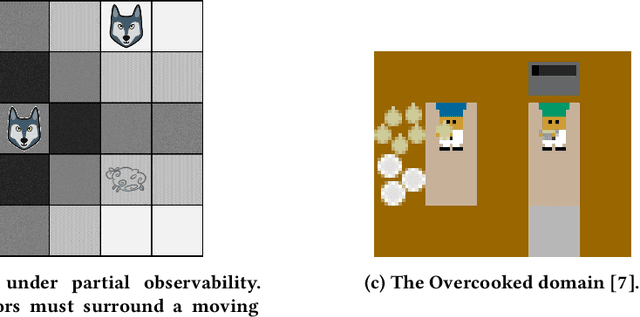
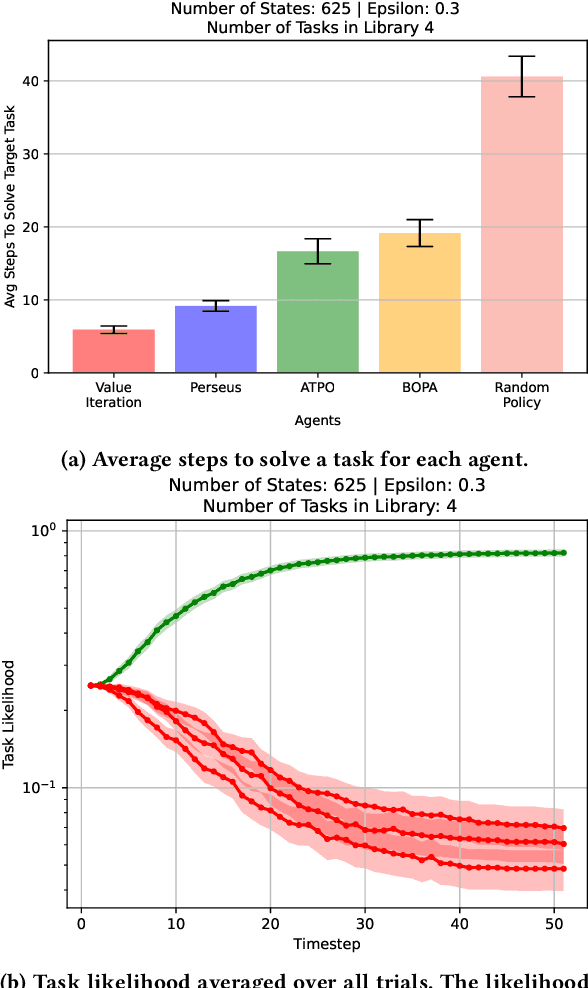
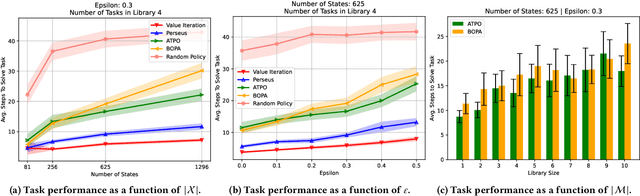
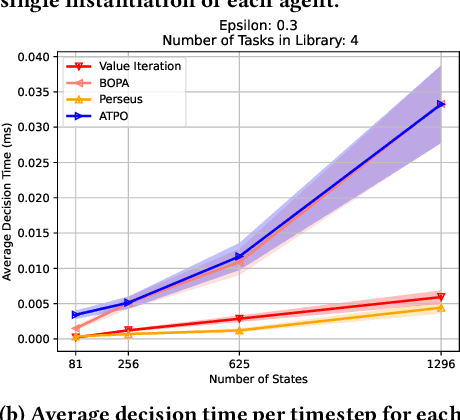
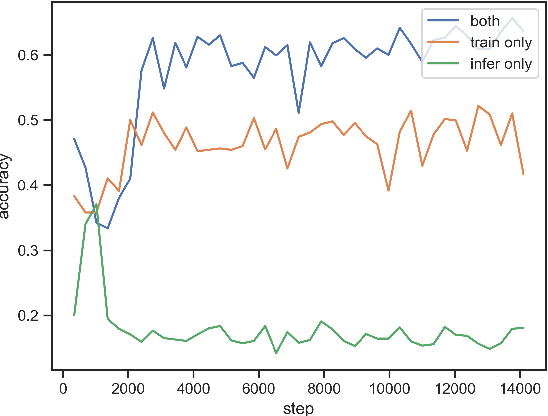
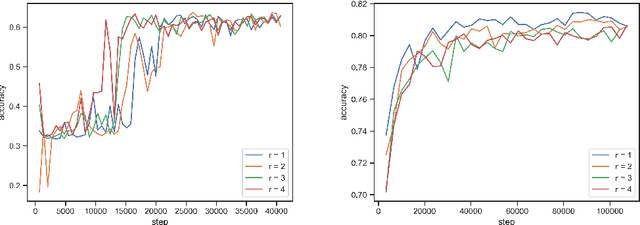
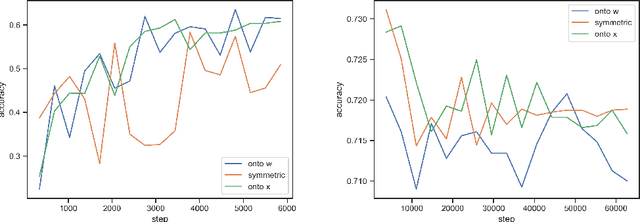
In this paper, we present a novel Bayesian online prediction algorithm for the problem setting of ad hoc teamwork under partial observability (ATPO), which enables on-the-fly collaboration with unknown teammates performing an unknown task without needing a pre-coordination protocol. Unlike previous works that assume a fully observable state of the environment, ATPO accommodates partial observability, using the agent's observations to identify which task is being performed by the teammates. Our approach assumes neither that the teammate's actions are visible nor an environment reward signal. We evaluate ATPO in three domains -- two modified versions of the Pursuit domain with partial observability and the overcooked domain. Our results show that ATPO is effective and robust in identifying the teammate's task from a large library of possible tasks, efficient at solving it in near-optimal time, and scalable in adapting to increasingly larger problem sizes.
Short-term Multi-horizon Residential Electric Load Forecasting using Deep Learning and Signal Decomposition Methods
Feb 01, 2022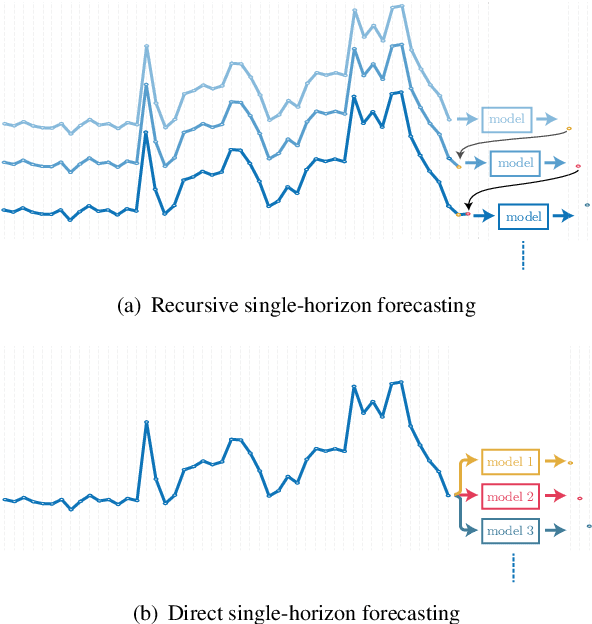

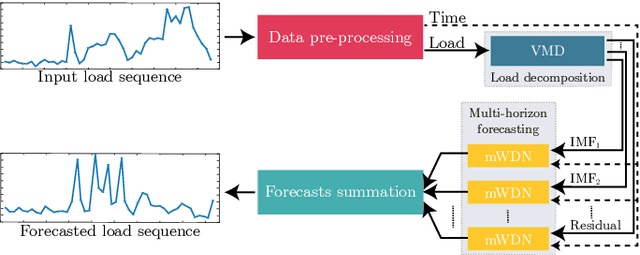
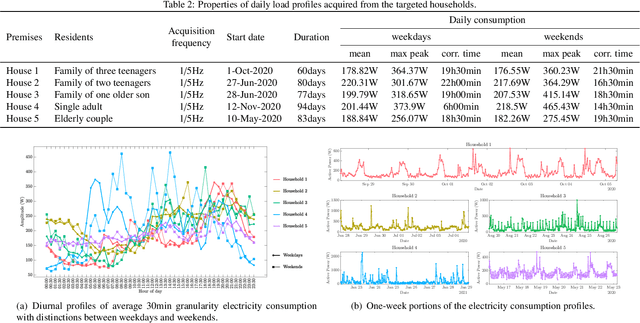
With the booming growth of advanced digital technologies, it has become possible for users as well as distributors of energy to obtain detailed and timely information about the electricity consumption of households. These technologies can also be used to forecast the household's electricity consumption (a.k.a. the load). In this paper, we investigate the use of Variational Mode Decomposition and deep learning techniques to improve the accuracy of the load forecasting problem. Although this problem has been studied in the literature, selecting an appropriate decomposition level and a deep learning technique providing better forecasting performance have garnered comparatively less attention. This study bridges this gap by studying the effect of six decomposition levels and five distinct deep learning networks. The raw load profiles are first decomposed into intrinsic mode functions using the Variational Mode Decomposition in order to mitigate their non-stationary aspect. Then, day, hour, and past electricity consumption data are fed as a three-dimensional input sequence to a four-level Wavelet Decomposition Network model. Finally, the forecast sequences related to the different intrinsic mode functions are combined to form the aggregate forecast sequence. The proposed method was assessed using load profiles of five Moroccan households from the Moroccan buildings' electricity consumption dataset (MORED) and was benchmarked against state-of-the-art time-series models and a baseline persistence model.
Electric Vehicle Battery Remaining Charging Time Estimation Considering Charging Accuracy and Charging Profile Prediction
Dec 09, 2020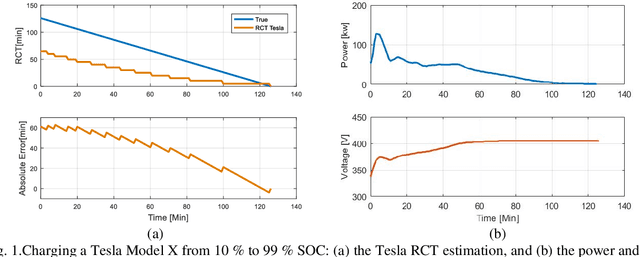
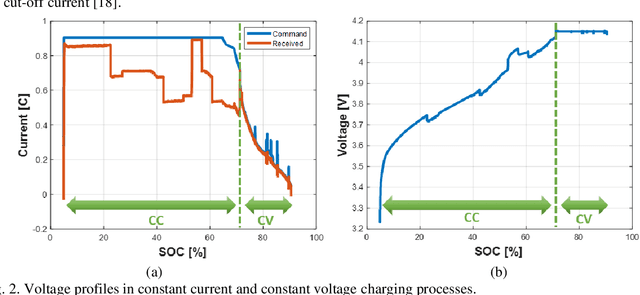
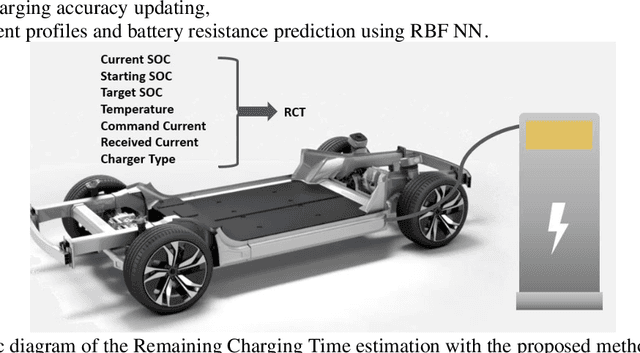
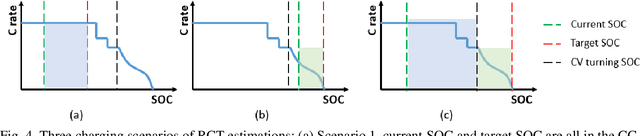
Electric vehicles (EVs) have been growing rapidly in popularity in recent years and have become a future trend. It is an important aspect of user experience to know the Remaining Charging Time (RCT) of an EV with confidence. However, it is difficult to find an algorithm that accurately estimates the RCT for vehicles in the current EV market. The maximum RCT estimation error of the Tesla Model X can be as high as 60 minutes from a 10 % to 99 % state-of-charge (SOC) while charging at direct current (DC). A highly accurate RCT estimation algorithm for electric vehicles is in high demand and will continue to be as EVs become more popular. There are currently two challenges to arriving at an accurate RCT estimate. First, most commercial chargers cannot provide requested charging currents during a constant current (CC) stage. Second, it is hard to predict the charging current profile in a constant voltage (CV) stage. To address the first issue, this study proposes an RCT algorithm that updates the charging accuracy online in the CC stage by considering the confidence interval between the historical charging accuracy and real-time charging accuracy data. To solve the second issue, this study proposes a battery resistance prediction model to predict charging current profiles in the CV stage, using a Radial Basis Function (RBF) neural network (NN). The test results demonstrate that the RCT algorithm proposed in this study achieves an error rate improvement of 73.6 % and 84.4 % over the traditional method in the CC and CV stages, respectively.
Smooth Deformation Field-based Mismatch Removal in Real-time
Jul 16, 2020
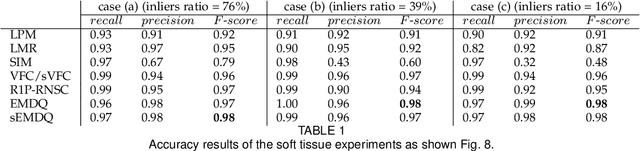

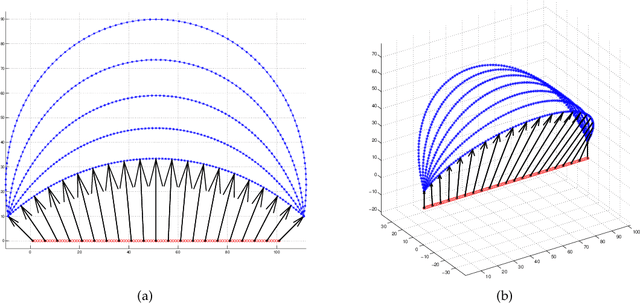
This paper studies the mismatch removal problem, which may serve as the subsequent step of feature matching. Non-rigid deformation makes it difficult to remove mismatches because no parametric transformation can be found. To solve this problem, we first propose an algorithm based on the re-weighting and 1-point RANSAC strategy (R1P-RNSC), which is a parametric method under a reasonable assumption that the non-rigid deformation can be approximately represented by multiple locally rigid transformations. R1P-RNSC is fast but suffers from a drawback that the local smoothing information cannot be taken into account. Then, we propose a non-parametric algorithm based on the expectation maximization algorithm and dual quaternion (EMDQ) representation to generate the smooth deformation field. The two algorithms compensate for the drawbacks of each other. Specifically, EMDQ needs good initial values provided by R1P-RNSC, and R1P-RNSC needs EMDQ for refinement. Experimental results with real-world data demonstrate that the combination of the two algorithms has the best accuracy compared to other state-of-the-art methods, which can handle up to 85% of outliers in real-time. The ability to generate dense deformation field from sparse matches with outliers in real-time makes the proposed algorithms have many potential applications, such as non-rigid registration and SLAM.