 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine Learning Based Relative Orbit Transfer for Swarm Spacecraft Motion Planning
Jan 28, 2022
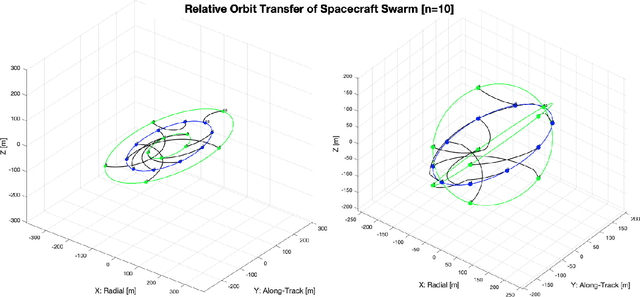

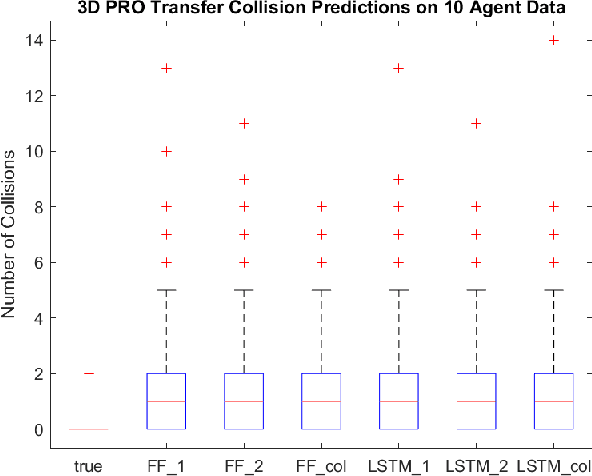
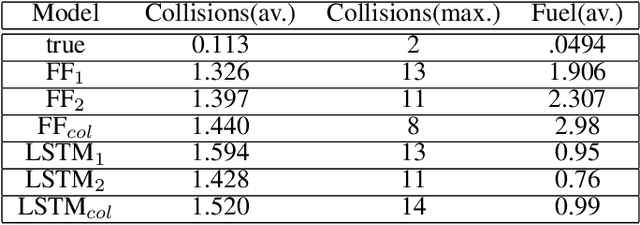
In this paper we describe a machine learning based framework for spacecraft swarm trajectory planning. In particular, we focus on coordinating motions of multi-spacecraft in formation flying through passive relative orbit(PRO) transfers. Accounting for spacecraft dynamics while avoiding collisions between the agents makes spacecraft swarm trajectory planning difficult. Centralized approaches can be used to solve this problem, but are computationally demanding and scale poorly with the number of agents in the swarm. As a result, centralized algorithms are ill-suited for real time trajectory planning on board small spacecraft (e.g. CubeSats) comprising the swarm. In our approach a neural network is used to approximate solutions of a centralized method. The necessary training data is generated using a centralized convex optimization framework through which several instances of the n=10 spacecraft swarm trajectory planning problem are solved. We are interested in answering the following questions which will give insight on the potential utility of deep learning-based approaches to the multi-spacecraft motion planning problem: 1) Can neural networks produce feasible trajectories that satisfy safety constraints (e.g. collision avoidance) and low in fuel cost? 2) Can a neural network trained using n spacecraft data be used to solve problems for spacecraft swarms of differing size?
Should I take a walk? Estimating Energy Expenditure from Video Data
Feb 01, 2022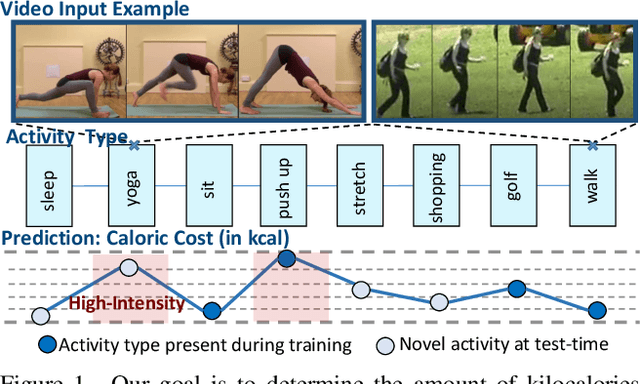

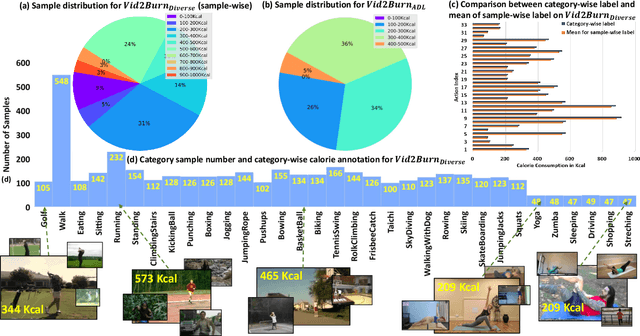
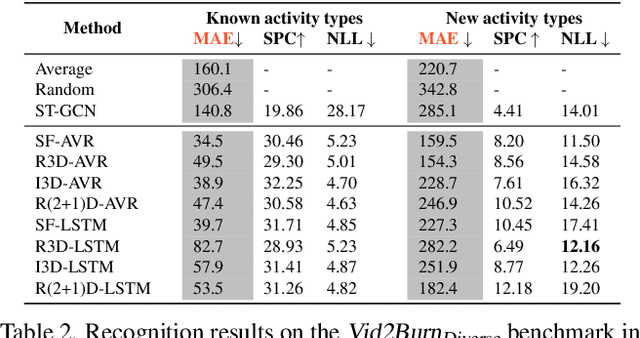
We explore the problem of automatically inferring the amount of kilocalories used by human during physical activity from his/her video observation. To study this underresearched task, we introduce Vid2Burn -- an omni-source benchmark for estimating caloric expenditure from video data featuring both, high- and low-intensity activities for which we derive energy expenditure annotations based on models established in medical literature. In practice, a training set would only cover a certain amount of activity types, and it is important to validate, if the model indeed captures the essence of energy expenditure, (e.g., how many and which muscles are involved and how intense they work) instead of memorizing fixed values of specific activity categories seen during training. Ideally, the models should look beyond such category-specific biases and regress the caloric cost in videos depicting activity categories not explicitly present during training. With this property in mind, Vid2Burn is accompanied with a cross-category benchmark, where the task is to regress caloric expenditure for types of physical activities not present during training. An extensive evaluation of state-of-the-art approaches for video recognition modified for the energy expenditure estimation task demonstrates the difficulty of this problem, especially for new activity types at test-time, marking a new research direction. Dataset and code are available at https://github.com/KPeng9510/Vid2Burn.
Robotic Tissue Sampling for Safe Post-mortem Biopsy in Infectious Corpses
Jan 28, 2022
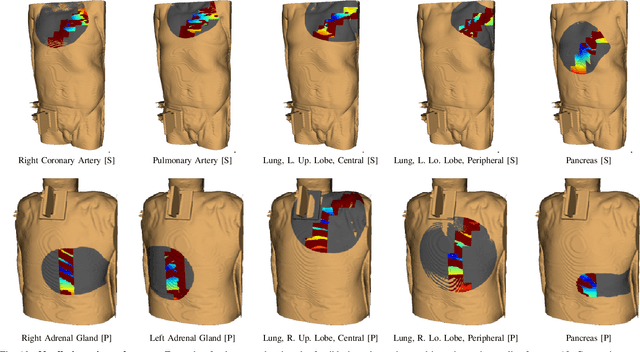
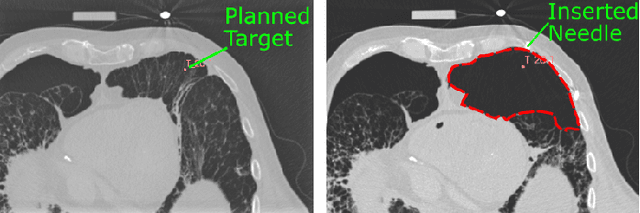
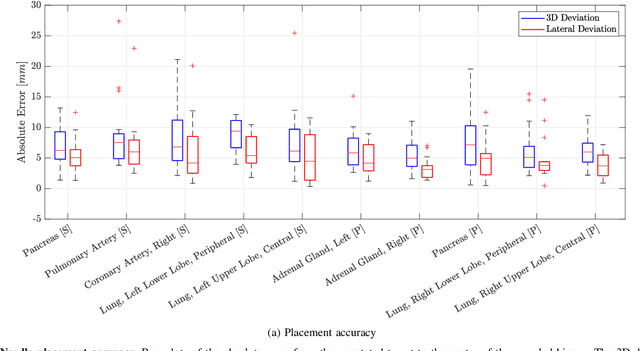
In pathology and legal medicine, the histopathological and microbiological analysis of tissue samples from infected deceased is a valuable information for developing treatment strategies during a pandemic such as COVID-19. However, a conventional autopsy carries the risk of disease transmission and may be rejected by relatives. We propose minimally invasive biopsy with robot assistance under CT guidance to minimize the risk of disease transmission during tissue sampling and to improve accuracy. A flexible robotic system for biopsy sampling is presented, which is applied to human corpses placed inside protective body bags. An automatic planning and decision system estimates optimal insertion point. Heat maps projected onto the segmented skin visualize the distance and angle of insertions and estimate the minimum cost of a puncture while avoiding bone collisions. Further, we test multiple insertion paths concerning feasibility and collisions. A custom end effector is designed for inserting needles and extracting tissue samples under robotic guidance. Our robotic post-mortem biopsy (RPMB) system is evaluated in a study during the COVID-19 pandemic on 20 corpses and 10 tissue targets, 5 of them being infected with SARS-CoV-2. The mean planning time including robot path planning is (5.72+-1.67) s. Mean needle placement accuracy is (7.19+-4.22) mm.
A hybrid deep learning approach for purchasing strategy of carbon emission rights -- Based on Shanghai pilot market
Jan 24, 2022
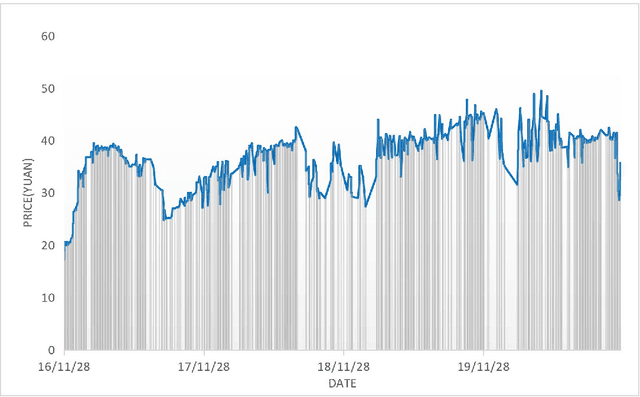
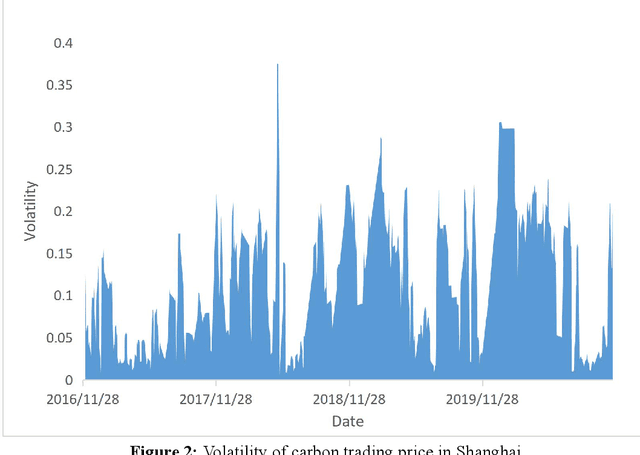
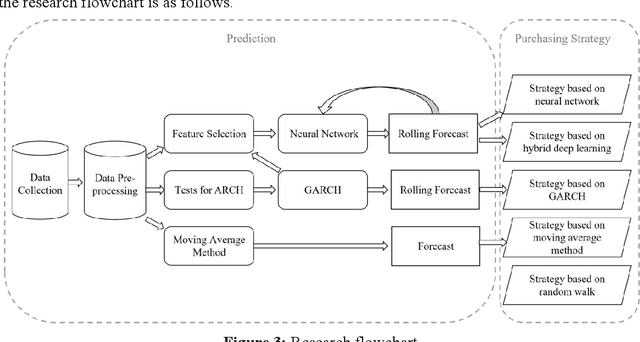
The price of carbon emission rights play a crucial role in carbon trading markets. Therefore, accurate prediction of the price is critical. Taking the Shanghai pilot market as an example, this paper attempted to design a carbon emission purchasing strategy for enterprises, and establish a carbon emission price prediction model to help them reduce the purchasing cost. To make predictions more precise, we built a hybrid deep learning model by embedding Generalized Autoregressive Conditional Heteroskedastic (GARCH) into the Gate Recurrent Unit (GRU) model, and compared the performance with those of other models. Then, based on the Iceberg Order Theory and the predicted price, we proposed the purchasing strategy of carbon emission rights. As a result, the prediction errors of the GARCH-GRU model with a 5-day sliding time window were the minimum values of all six models. And in the simulation, the purchasing strategy based on the GARCH-GRU model was executed with the least cost as well. The carbon emission purchasing strategy constructed by the hybrid deep learning method can accurately send out timing signals, and help enterprises reduce the purchasing cost of carbon emission permits.
A Deep-Learning Based Optimization Approach to Address Stop-Skipping Strategy in Urban Rail Transit Lines
Sep 17, 2021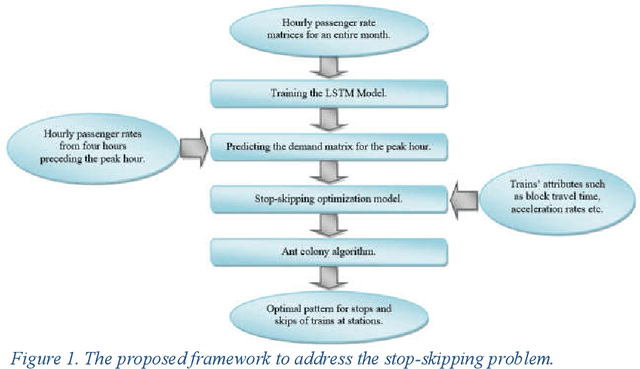

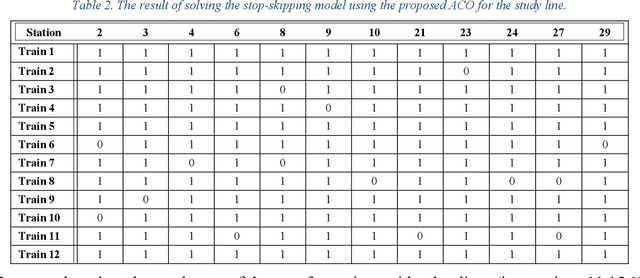
Different passenger demand rates in transit stations underscore the importance of adopting operational strategies to provide a demand-responsive service. Aiming at improving passengers' travel time, the present study introduces an advanced data-driven optimization approach to determine the optimal stop-skip pattern in urban rail transit lines. In detail, first, using the time-series smart card data for an entire month, we employ a Long Short-Term Memory (LSTM) deep learning model to predict the station-level demand rates for the peak hour. This prediction is based on four preceding hours and is especially important knowing that the true demand rates of the peak hour are posterior information that can be obtained only after the peak hour operation is finished. Moreover, utilizing a real-time prediction instead of assuming fixed demand rates, allows us to account for unexpected real-time changes which can be detrimental to the subsequent analyses. Then, we integrate the output of the LSTM model as an input to an optimization model with the objective of minimizing patrons' total travel time. Considering the exponential nature of the problem, we propose an Ant Colony Optimization technique to solve the problem in a desirable amount of time. Finally, the performance of the proposed models and the solution algorithm is assessed using real case data. The results suggest that the proposed approach can enhance the performance of the service by improving both passengers' in-vehicle time as well as passengers' waiting time.
FastSGD: A Fast Compressed SGD Framework for Distributed Machine Learning
Dec 08, 2021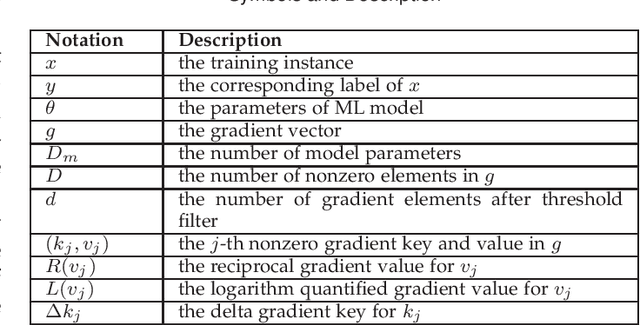
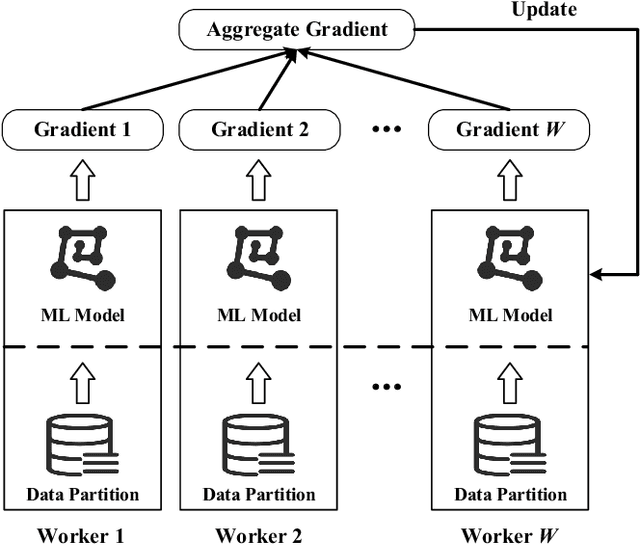
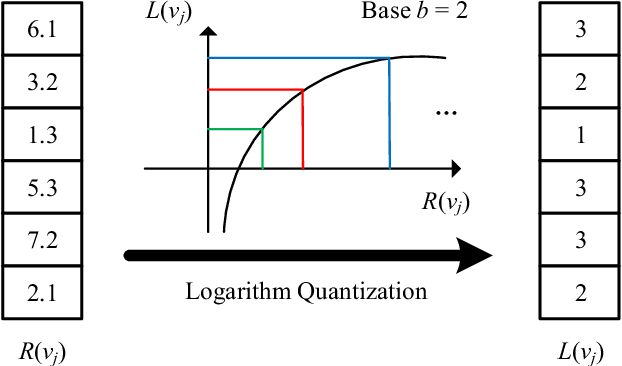
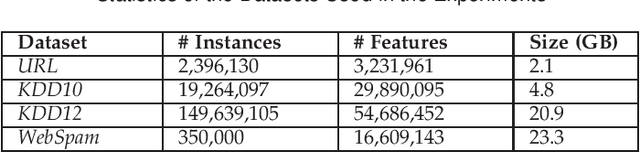
With the rapid increase of big data, distributed Machine Learning (ML) has been widely applied in training large-scale models. Stochastic Gradient Descent (SGD) is arguably the workhorse algorithm of ML. Distributed ML models trained by SGD involve large amounts of gradient communication, which limits the scalability of distributed ML. Thus, it is important to compress the gradients for reducing communication. In this paper, we propose FastSGD, a Fast compressed SGD framework for distributed ML. To achieve a high compression ratio at a low cost, FastSGD represents the gradients as key-value pairs, and compresses both the gradient keys and values in linear time complexity. For the gradient value compression, FastSGD first uses a reciprocal mapper to transform original values into reciprocal values, and then, it utilizes a logarithm quantization to further reduce reciprocal values to small integers. Finally, FastSGD filters reduced gradient integers by a given threshold. For the gradient key compression, FastSGD provides an adaptive fine-grained delta encoding method to store gradient keys with fewer bits. Extensive experiments on practical ML models and datasets demonstrate that FastSGD achieves the compression ratio up to 4 orders of magnitude, and accelerates the convergence time up to 8x, compared with state-of-the-art methods.
Interpretable Real-Time Win Prediction for Honor of Kings, a Popular Mobile MOBA Esport
Sep 04, 2020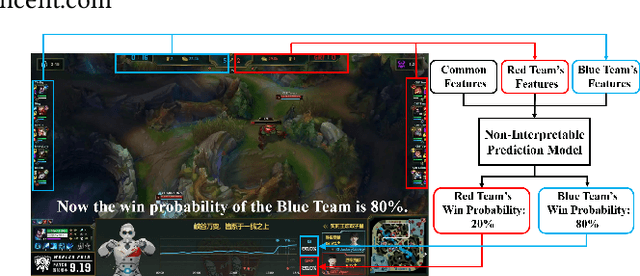

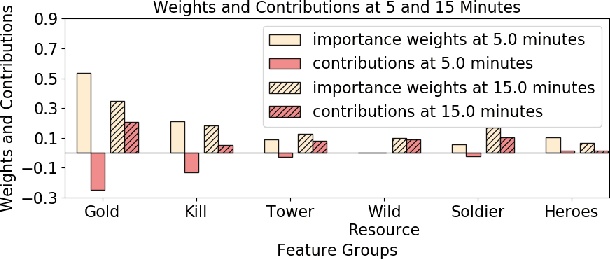
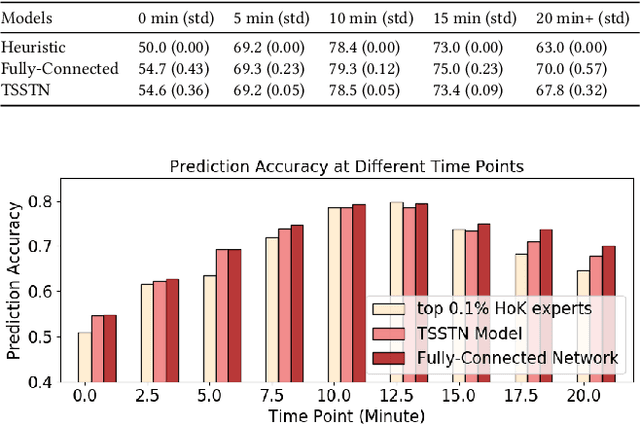
With the rapid prevalence and explosive development of MOBA esports (Multiplayer Online Battle Arena electronic sports), many research efforts have been devoted to automatically predicting the game results (win predictions). While this task has great potential in various applications such as esports live streaming and game commentator AI systems, previous studies suffer from two major limitations: 1) insufficient real-time input features and high-quality training data; 2) non-interpretable inference processes of the black-box prediction models. To mitigate these issues, we collect and release a large-scale dataset that contains real-time game records with rich input features of the popular MOBA game Honor of Kings. For interpretable predictions, we propose a Two-Stage Spatial-Temporal Network (TSSTN) that can not only provide accurate real-time win predictions but also attribute the ultimate prediction results to the contributions of different features for interpretability. Experiment results and applications in real-world live streaming scenarios show that the proposed TSSTN model is effective both in prediction accuracy and interpretability.
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 08, 2021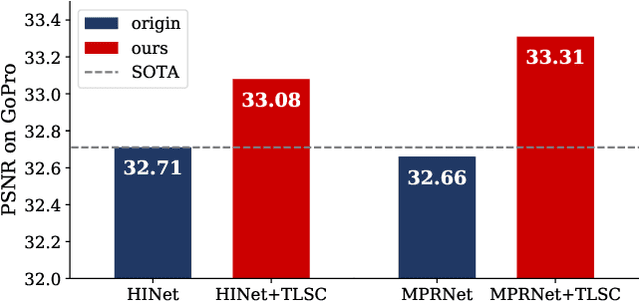
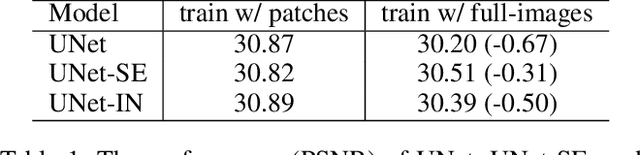
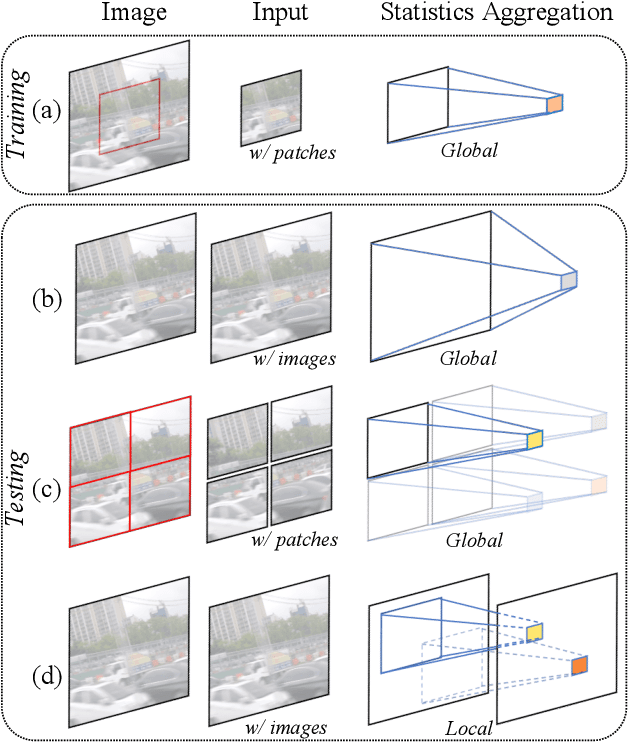
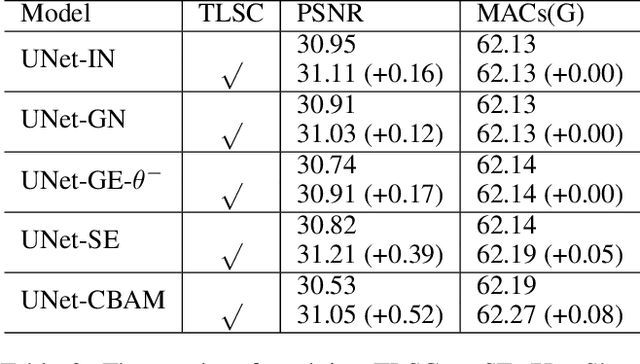
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
DynaMixer: A Vision MLP Architecture with Dynamic Mixing
Jan 28, 2022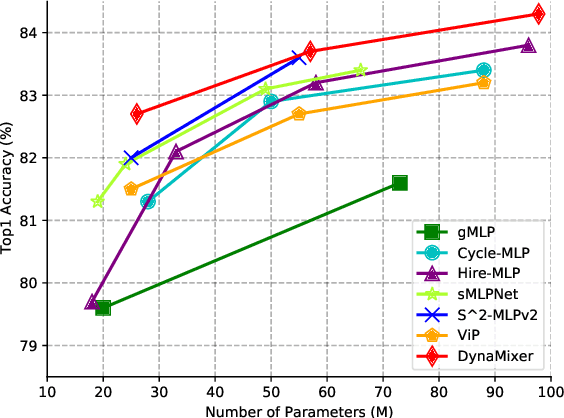
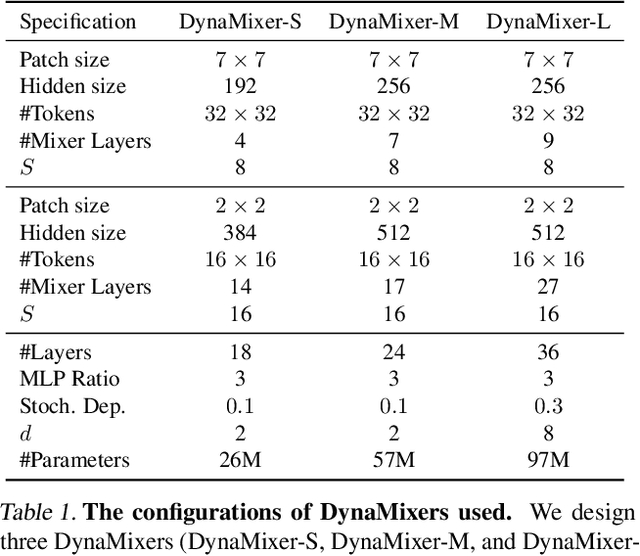
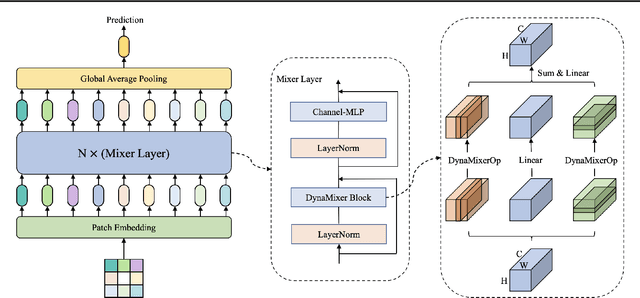
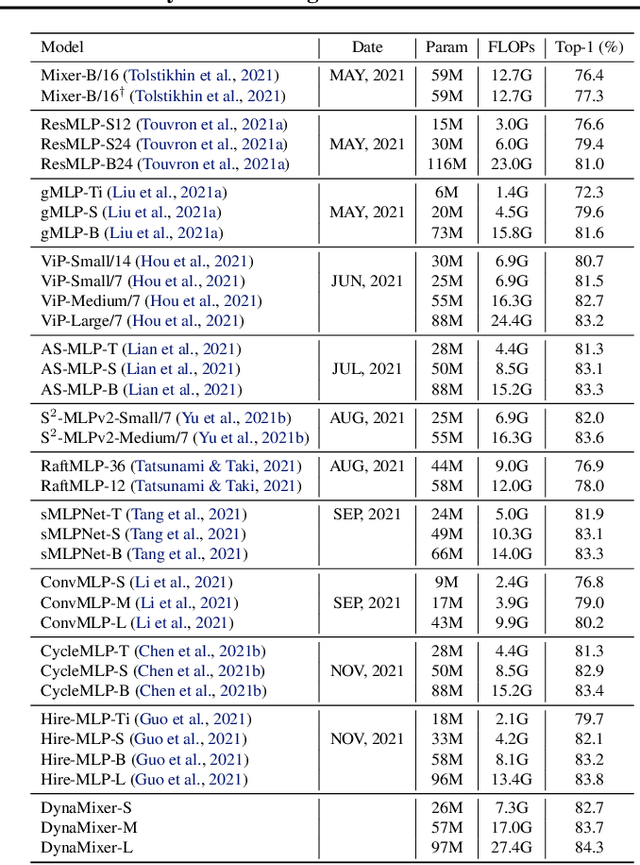
Recently, MLP-like vision models have achieved promising performances on mainstream visual recognition tasks. In contrast with vision transformers and CNNs, the success of MLP-like models shows that simple information fusion operations among tokens and channels can yield a good representation power for deep recognition models. However, existing MLP-like models fuse tokens through static fusion operations, lacking adaptability to the contents of the tokens to be mixed. Thus, customary information fusion procedures are not effective enough. To this end, this paper presents an efficient MLP-like network architecture, dubbed DynaMixer, resorting to dynamic information fusion. Critically, we propose a procedure, on which the DynaMixer model relies, to dynamically generate mixing matrices by leveraging the contents of all the tokens to be mixed. To reduce the time complexity and improve the robustness, a dimensionality reduction technique and a multi-segment fusion mechanism are adopted. Our proposed DynaMixer model (97M parameters) achieves 84.3\% top-1 accuracy on the ImageNet-1K dataset without extra training data, performing favorably against the state-of-the-art vision MLP models. When the number of parameters is reduced to 26M, it still achieves 82.7\% top-1 accuracy, surpassing the existing MLP-like models with a similar capacity. The implementation of DynaMixer will be made available to the public.
Firm-based relatedness using machine learning
Feb 01, 2022
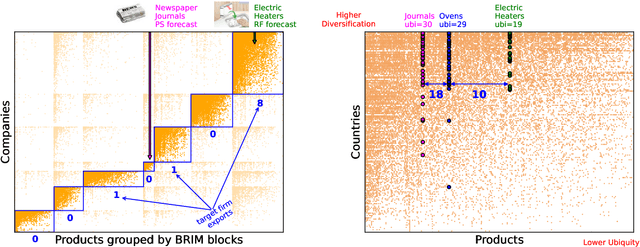
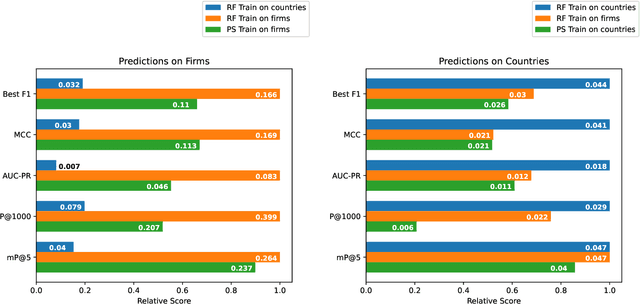
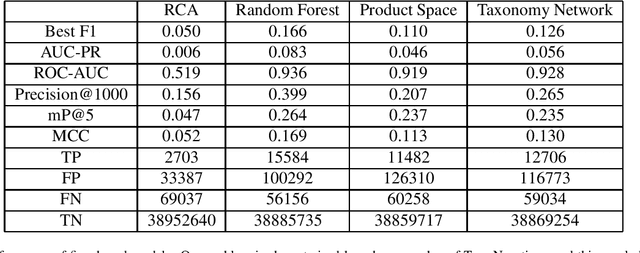
The relatedness between an economic actor (for instance a country, or a firm) and a product is a measure of the feasibility of that economic activity. As such, it is a driver for investments both at a private and institutional level. Traditionally, relatedness is measured using complex networks approaches derived by country-level co-occurrences. In this work, we compare complex networks and machine learning algorithms trained on both country and firm-level data. In order to quantitatively compare the different measures of relatedness, we use them to predict the future exports at country and firm-level, assuming that more related products have higher likelihood to be exported in the near future. Our results show that relatedness is scale-dependent: the best assessments are obtained by using machine learning on the same typology of data one wants to predict. Moreover, while relatedness measures based on country data are not suitable for firms, firm-level data are quite informative also to predict the development of countries. In this sense, models built on firm data provide a better assessment of relatedness with respect to country-level data. We also discuss the effect of using community detection algorithms and parameter optimization, finding that a partition into a higher number of blocks decreases the computational time while maintaining a prediction performance that is well above the network based benchmarks.