 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An efficient label-free analyte detection algorithm for time-resolved spectroscopy
Nov 15, 2020
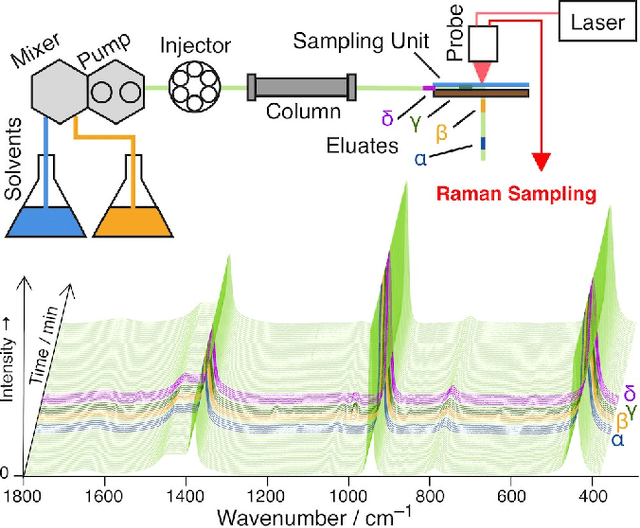
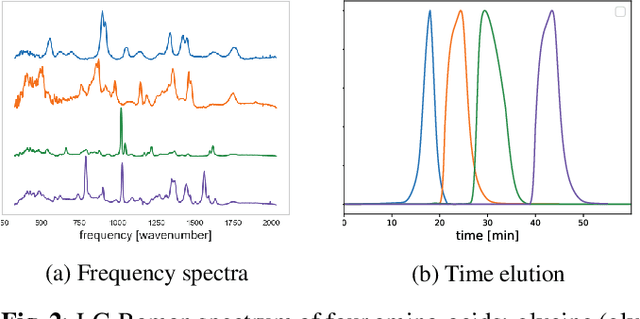
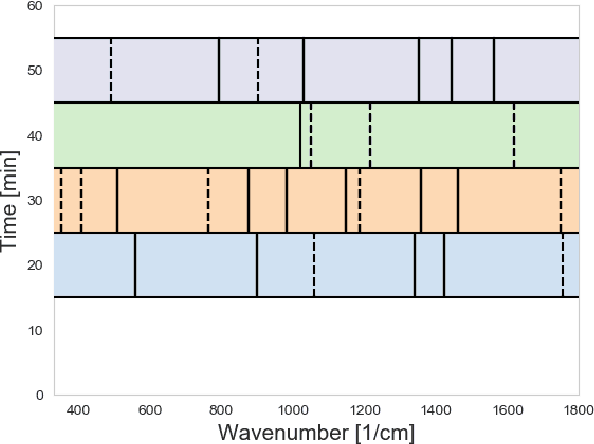
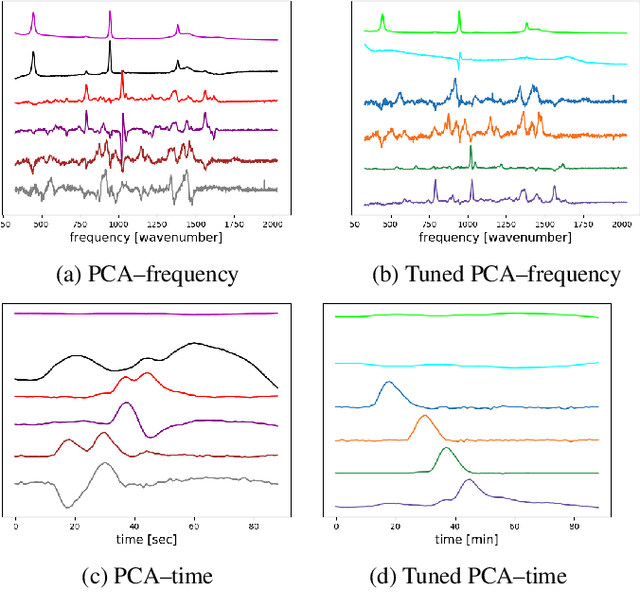
Time-resolved spectral techniques play an important analysis tool in many contexts, from physical chemistry to biomedicine. Customarily, the label-free detection of analytes is manually performed by experts through the aid of classic dimensionality-reduction methods, such as Principal Component Analysis (PCA) and Non-negative Matrix Factorization (NMF). This fundamental reliance on expert analysis for unknown analyte detection severely hinders the applicability and the throughput of these such techniques. For this reason, in this paper, we formulate this detection problem as an unsupervised learning problem and propose a novel machine learning algorithm for label-free analyte detection. To show the effectiveness of the proposed solution, we consider the problem of detecting the amino-acids in Liquid Chromatography coupled with Raman spectroscopy (LC-Raman).
Non-Stationary Dueling Bandits
Feb 02, 2022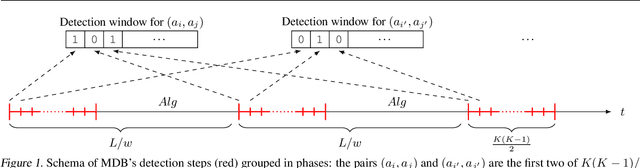
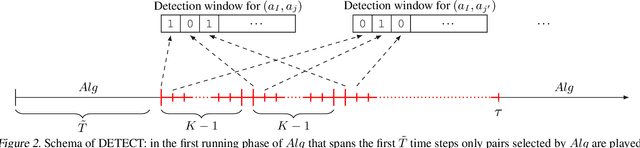


We study the non-stationary dueling bandits problem with $K$ arms, where the time horizon $T$ consists of $M$ stationary segments, each of which is associated with its own preference matrix. The learner repeatedly selects a pair of arms and observes a binary preference between them as feedback. To minimize the accumulated regret, the learner needs to pick the Condorcet winner of each stationary segment as often as possible, despite preference matrices and segment lengths being unknown. We propose the $\mathrm{Beat\, the\, Winner\, Reset}$ algorithm and prove a bound on its expected binary weak regret in the stationary case, which tightens the bound of current state-of-art algorithms. We also show a regret bound for the non-stationary case, without requiring knowledge of $M$ or $T$. We further propose and analyze two meta-algorithms, $\mathrm{DETECT}$ for weak regret and $\mathrm{Monitored\, Dueling\, Bandits}$ for strong regret, both based on a detection-window approach that can incorporate any dueling bandit algorithm as a black-box algorithm. Finally, we prove a worst-case lower bound for expected weak regret in the non-stationary case.
End-To-End Real-Time Visual Perception Framework for Construction Automation
Jul 27, 2021
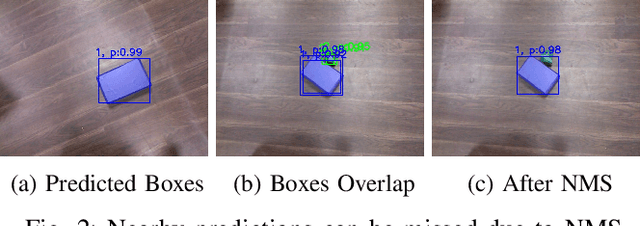

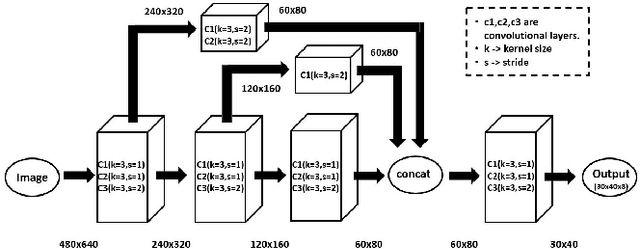
In this work, we present a robotic solution to automate the task of wall construction. To that end, we present an end-to-end visual perception framework that can quickly detect and localize bricks in a clutter. Further, we present a light computational method of brick pose estimation that incorporates the above information. The proposed detection network predicts a rotated box compared to YOLO and SSD, thereby maximizing the object's region in the predicted box regions. In addition, precision P, recall R, and mean-average-precision (mAP) scores are reported to evaluate the proposed framework. We observed that for our task, the proposed scheme outperforms the upright bounding box detectors. Further, we deploy the proposed visual perception framework on a robotic system endowed with a UR5 robot manipulator and demonstrate that the system can successfully replicate a simplified version of the wall-building task in an autonomous mode.
Vision-Guided Forecasting -- Visual Context for Multi-Horizon Time Series Forecasting
Jul 27, 2021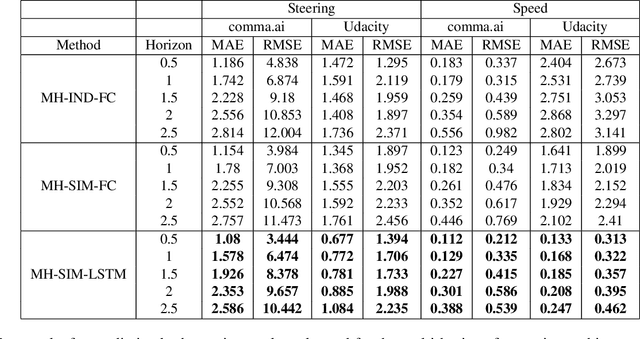
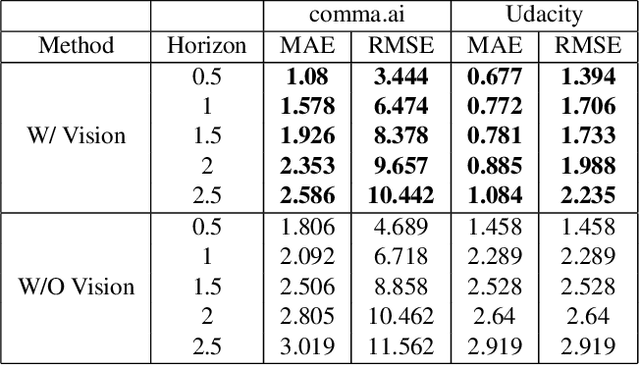
Autonomous driving gained huge traction in recent years, due to its potential to change the way we commute. Much effort has been put into trying to estimate the state of a vehicle. Meanwhile, learning to forecast the state of a vehicle ahead introduces new capabilities, such as predicting dangerous situations. Moreover, forecasting brings new supervision opportunities by learning to predict richer a context, expressed by multiple horizons. Intuitively, a video stream originated from a front-facing camera is necessary because it encodes information about the upcoming road. Besides, historical traces of the vehicle's states give more context. In this paper, we tackle multi-horizon forecasting of vehicle states by fusing the two modalities. We design and experiment with 3 end-to-end architectures that exploit 3D convolutions for visual features extraction and 1D convolutions for features extraction from speed and steering angle traces. To demonstrate the effectiveness of our method, we perform extensive experiments on two publicly available real-world datasets, Comma2k19 and the Udacity challenge. We show that we are able to forecast a vehicle's state to various horizons, while outperforming the current state-of-the-art results on the related task of driving state estimation. We examine the contribution of vision features, and find that a model fed with vision features achieves an error that is 56.6% and 66.9% of the error of a model that doesn't use those features, on the Udacity and Comma2k19 datasets respectively.
A probabilistic model for fast-to-evaluate 2D crack path prediction in heterogeneous materials
Dec 27, 2021
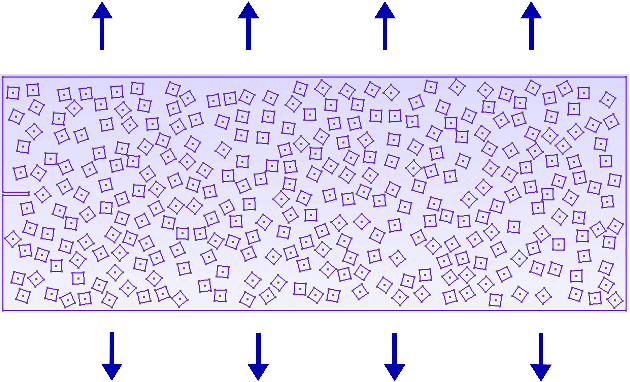


This paper is devoted to the construction of a new fast-to-evaluate model for the prediction of 2D crack paths in concrete-like microstructures. The model generates piecewise linear cracks paths with segmentation points selected using a Markov chain model. The Markov chain kernel involves local indicators of mechanical interest and its parameters are learnt from numerical full-field 2D simulations of craking using a cohesive-volumetric finite element solver called XPER. The resulting model exhibits a drastic improvement of CPU time in comparison to simulations from XPER.
Using Deep Learning to Bootstrap Abstractions for Hierarchical Robot Planning
Feb 02, 2022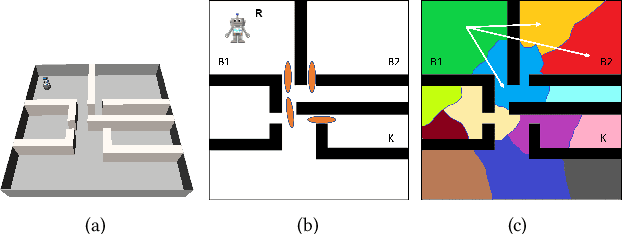
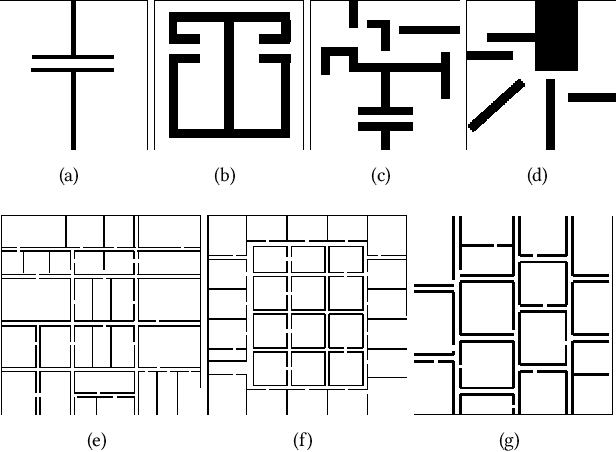
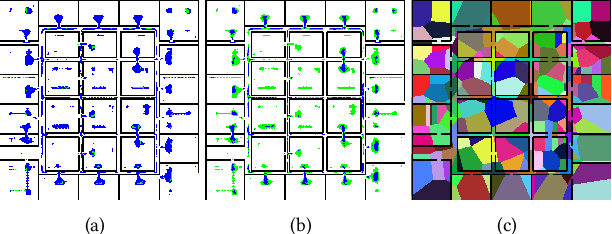
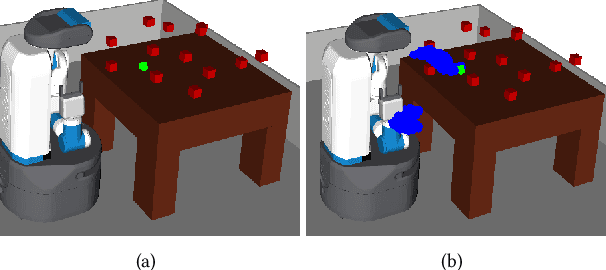
This paper addresses the problem of learning abstractions that boost robot planning performance while providing strong guarantees of reliability. Although state-of-the-art hierarchical robot planning algorithms allow robots to efficiently compute long-horizon motion plans for achieving user desired tasks, these methods typically rely upon environment-dependent state and action abstractions that need to be hand-designed by experts. We present a new approach for bootstrapping the entire hierarchical planning process. It shows how abstract states and actions for new environments can be computed automatically using the critical regions predicted by a deep neural-network with an auto-generated robot specific architecture. It uses the learned abstractions in a novel multi-source bi-directional hierarchical robot planning algorithm that is sound and probabilistically complete. An extensive empirical evaluation on twenty different settings using holonomic and non-holonomic robots shows that (a) the learned abstractions provide the information necessary for efficient multi-source hierarchical planning; and that (b) this approach of learning abstraction and planning outperforms state-of-the-art baselines by nearly a factor of ten in terms of planning time on test environments not seen during training.
Temporal Knowledge Graph Reasoning Triggered by Memories
Nov 03, 2021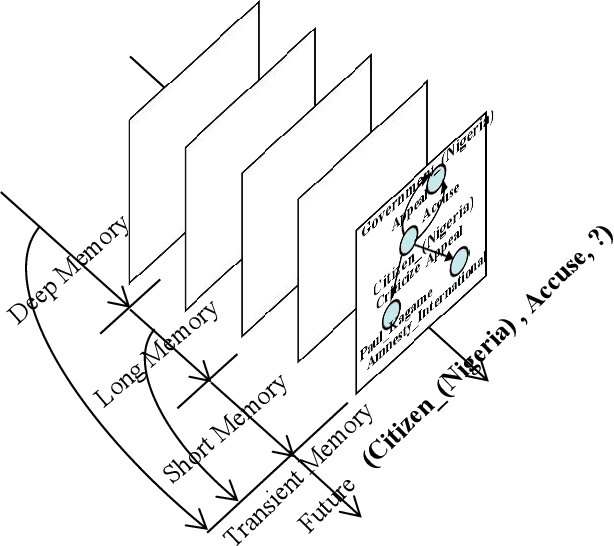
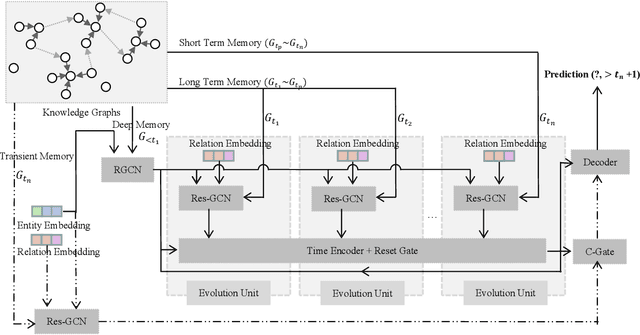
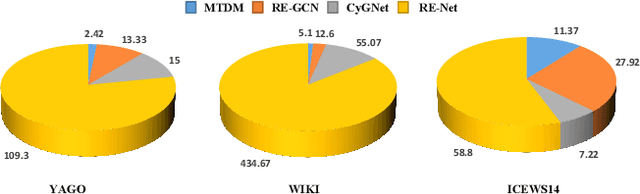
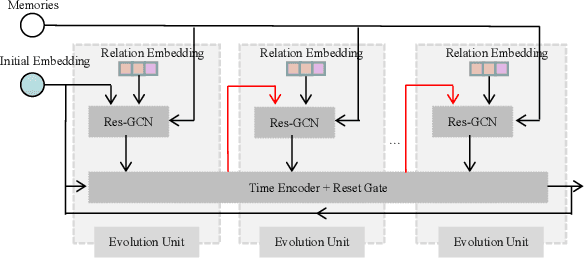
Inferring missing facts in temporal knowledge graphs is a critical task and has been widely explored. Extrapolation in temporal reasoning tasks is more challenging and gradually attracts the attention of researchers since no direct history facts for prediction. Previous works attempted to apply evolutionary representation learning to solve the extrapolation problem. However, these techniques do not explicitly leverage various time-aware attribute representations, i.e. the reasoning performance is significantly affected by the history length. To alleviate the time dependence when reasoning future missing facts, we propose a memory-triggered decision-making (MTDM) network, which incorporates transient memories, long-short-term memories, and deep memories. Specifically, the transient learning network considers transient memories as a static knowledge graph, and the time-aware recurrent evolution network learns representations through a sequence of recurrent evolution units from long-short-term memories. Each evolution unit consists of a structural encoder to aggregate edge information, a time encoder with a gating unit to update attribute representations of entities. MTDM utilizes the crafted residual multi-relational aggregator as the structural encoder to solve the multi-hop coverage problem. We also introduce the dissolution learning constraint for better understanding the event dissolution process. Extensive experiments demonstrate the MTDM alleviates the history dependence and achieves state-of-the-art prediction performance. Moreover, compared with the most advanced baseline, MTDM shows a faster convergence speed and training speed.
Flexible learning of quantum states with generative query neural networks
Feb 14, 2022
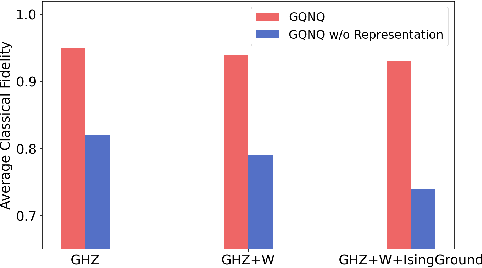
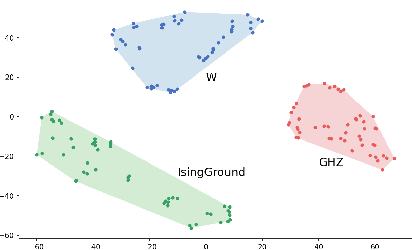
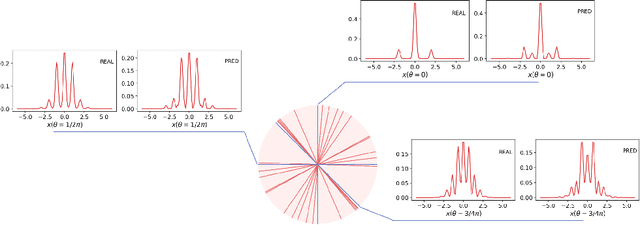
Deep neural networks are a powerful tool for characterizing quantum states. In this task, neural networks are typically trained with measurement data gathered from the quantum state to be characterized. But is it possible to train a neural network in a general-purpose way, which makes it applicable to multiple unknown quantum states? Here we show that learning across multiple quantum states and different measurement settings can be achieved by a generative query neural network, a type of neural network originally used in the classical domain for learning 3D scenes from 2D pictures. Our network can be trained offline with classically simulated data, and later be used to characterize unknown quantum states from real experimental data. With little guidance of quantum physics, the network builds its own data-driven representation of quantum states, and then uses it to predict the outcome probabilities of requested quantum measurements on the states of interest. This approach can be applied to state learning scenarios where quantum measurement settings are not informationally complete and predictions must be given in real time, as experimental data become available, as well as to adversarial scenarios where measurement choices and prediction requests are designed to expose learning inaccuracies. The internal representation produced by the network can be used for other tasks beyond state characterization, including clustering of states and prediction of physical properties. The features of our method are illustrated on many-qubit ground states of Ising model and continuous-variable non-Gaussian states.
Generative Adversarial Network (GAN) and Enhanced Root Mean Square Error (ERMSE): Deep Learning for Stock Price Movement Prediction
Nov 30, 2021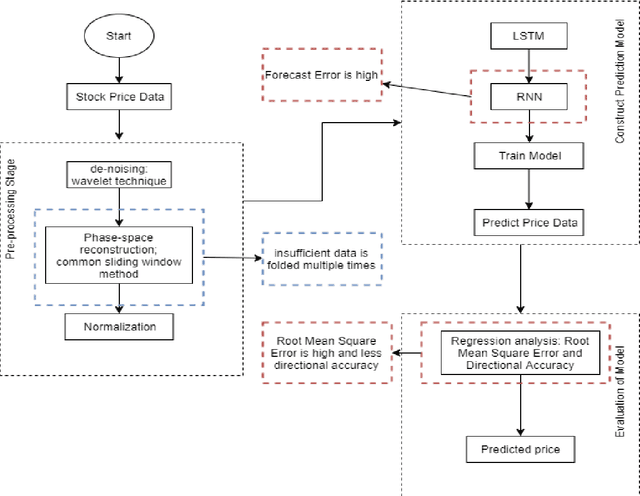
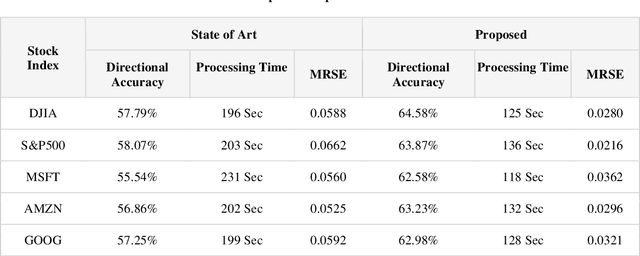
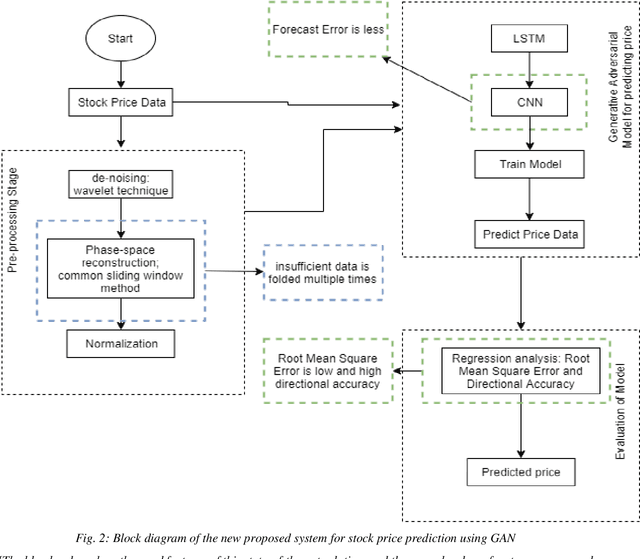
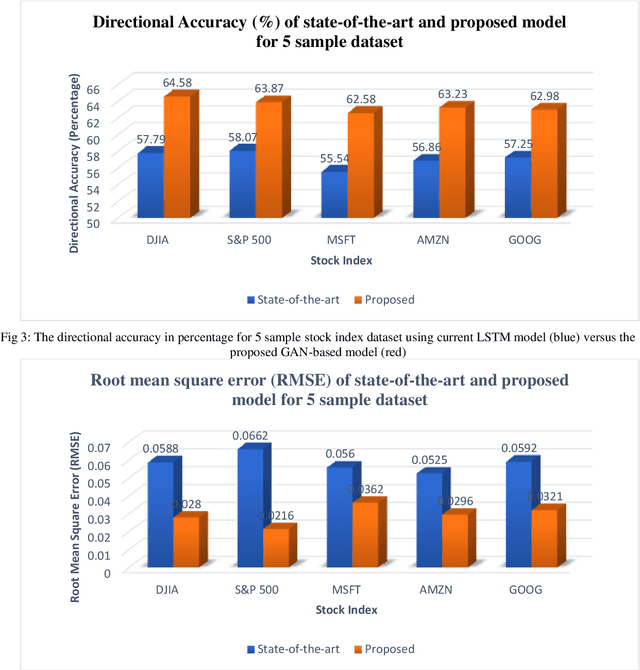
The prediction of stock price movement direction is significant in financial circles and academic. Stock price contains complex, incomplete, and fuzzy information which makes it an extremely difficult task to predict its development trend. Predicting and analysing financial data is a nonlinear, time-dependent problem. With rapid development in machine learning and deep learning, this task can be performed more effectively by a purposely designed network. This paper aims to improve prediction accuracy and minimizing forecasting error loss through deep learning architecture by using Generative Adversarial Networks. It was proposed a generic model consisting of Phase-space Reconstruction (PSR) method for reconstructing price series and Generative Adversarial Network (GAN) which is a combination of two neural networks which are Long Short-Term Memory (LSTM) as Generative model and Convolutional Neural Network (CNN) as Discriminative model for adversarial training to forecast the stock market. LSTM will generate new instances based on historical basic indicators information and then CNN will estimate whether the data is predicted by LSTM or is real. It was found that the Generative Adversarial Network (GAN) has performed well on the enhanced root mean square error to LSTM, as it was 4.35% more accurate in predicting the direction and reduced processing time and RMSE by 78 secs and 0.029, respectively. This study provides a better result in the accuracy of the stock index. It seems that the proposed system concentrates on minimizing the root mean square error and processing time and improving the direction prediction accuracy, and provides a better result in the accuracy of the stock index.
Time Series Forecasting of New Cases and New Deaths Rate for COVID-19 using Deep Learning Methods
Apr 28, 2021
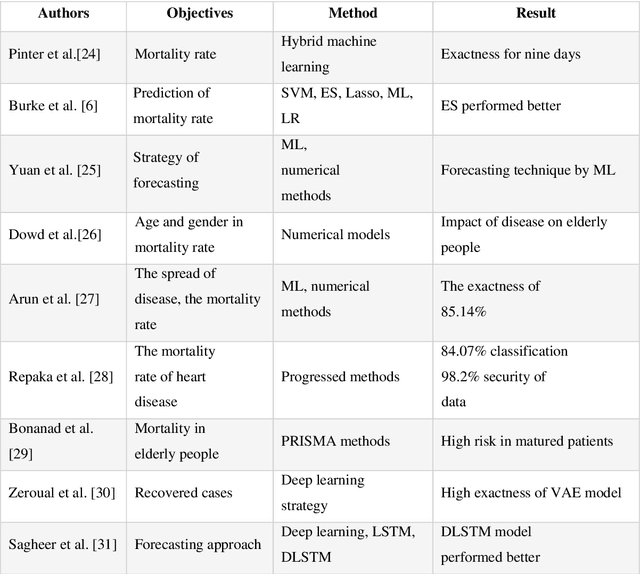
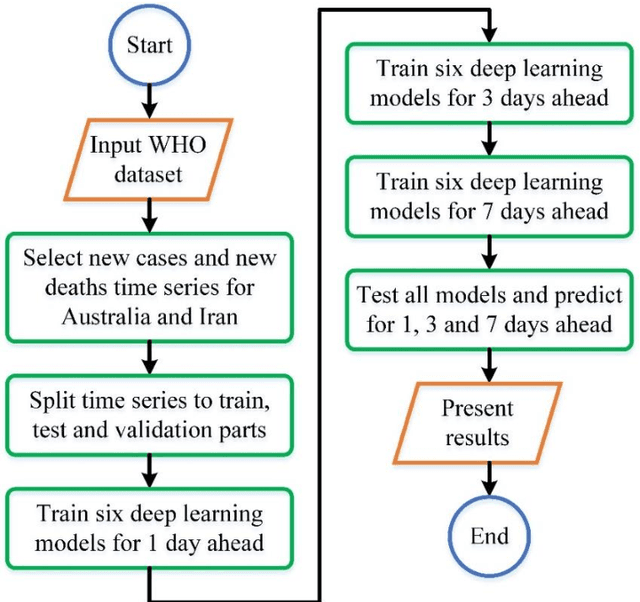

Covid-19 has been started in the year 2019 and imposed restrictions in many countries and costs organisations and governments. Predicting the number of new cases and deaths during this period can be a useful step in predicting the costs and facilities required in the future. The purpose of this study is to predict new cases and death rate for seven days ahead. Deep learning methods and statistical analysis model these predictions for 100 days. Six different deep learning methods are examined for the data adopted from the WHO website. Three methods are known as LSTM, Convolutional LSTM, and GRU. The bi-directional mode is then considered for each method to forecast the rate of new cases and new deaths for Australia and Iran countries. This study is novel as it attempts to implement the mentioned three deep learning methods, along with their Bi-directional models, to predict COVID-19 new cases and new death rate time series. All methods are compared, and results are presented. The results are examined in the form of graphs and statistical analyses. The results show that the Bi-directional models have lower error than other models. Several error evaluation metrics are presented to compare all models, and finally, the superiority of Bi-directional methods are determined. The experimental results and statistical test show on datasets to compare the proposed method with other baseline methods. This research could be useful for organisations working against COVID-19 and determining their long-term plans.