 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Integrated Optimization and Machine Learning Models to Predict the Admission Status of Emergency Patients
Feb 18, 2022
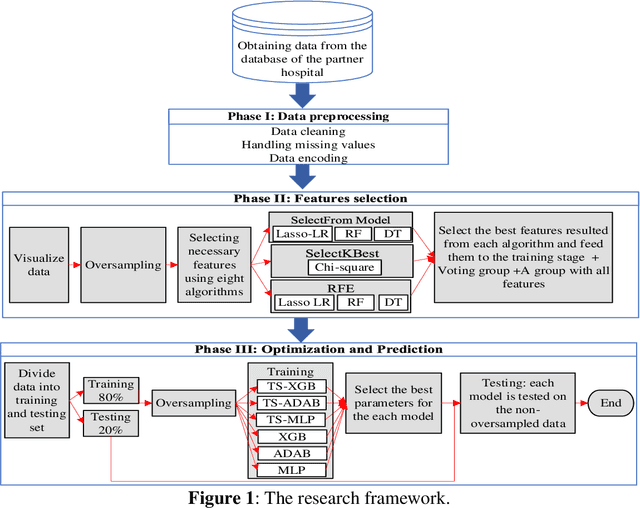
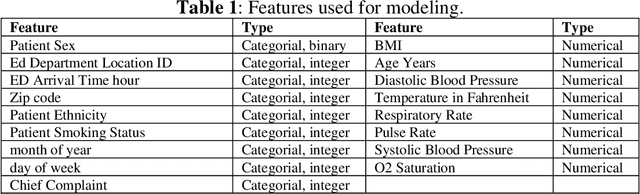

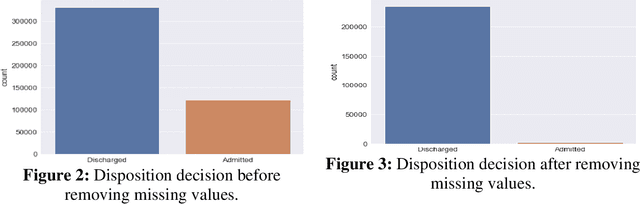
This work proposes a framework for optimizing machine learning algorithms. The practicality of the framework is illustrated using an important case study from the healthcare domain, which is predicting the admission status of emergency department (ED) patients (e.g., admitted vs. discharged) using patient data at the time of triage. The proposed framework can mitigate the crowding problem by proactively planning the patient boarding process. A large retrospective dataset of patient records is obtained from the electronic health record database of all ED visits over three years from three major locations of a healthcare provider in the Midwest of the US. Three machine learning algorithms are proposed: T-XGB, T-ADAB, and T-MLP. T-XGB integrates extreme gradient boosting (XGB) and Tabu Search (TS), T-ADAB integrates Adaboost and TS, and T-MLP integrates multi-layer perceptron (MLP) and TS. The proposed algorithms are compared with the traditional algorithms: XGB, ADAB, and MLP, in which their parameters are tunned using grid search. The three proposed algorithms and the original ones are trained and tested using nine data groups that are obtained from different feature selection methods. In other words, 54 models are developed. Performance was evaluated using five measures: Area under the curve (AUC), sensitivity, specificity, F1, and accuracy. The results show that the newly proposed algorithms resulted in high AUC and outperformed the traditional algorithms. The T-ADAB performs the best among the newly developed algorithms. The AUC, sensitivity, specificity, F1, and accuracy of the best model are 95.4%, 99.3%, 91.4%, 95.2%, 97.2%, respectively.
Timage -- A Robust Time Series Classification Pipeline
Sep 19, 2019
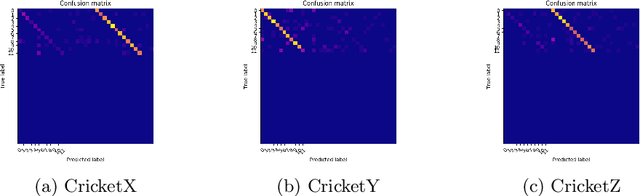
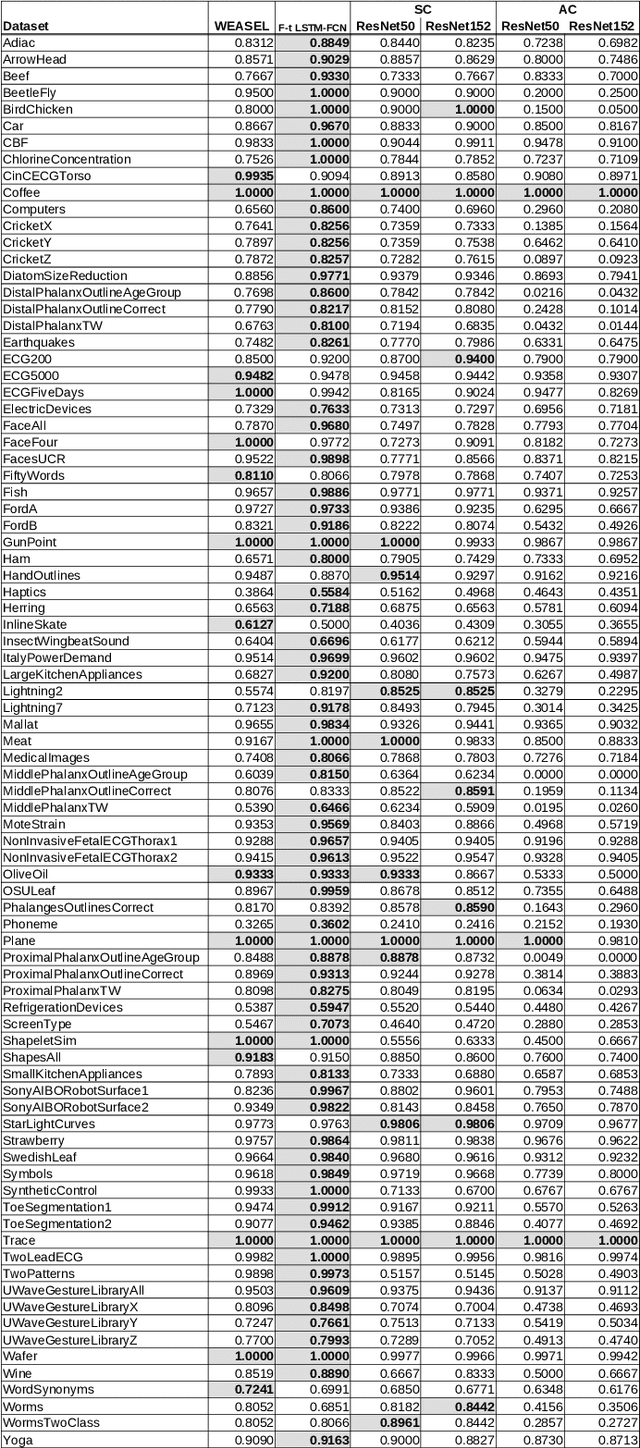
Time series are series of values ordered by time. This kind of data can be found in many real world settings. Classifying time series is a difficult task and an active area of research. This paper investigates the use of transfer learning in Deep Neural Networks and a 2D representation of time series known as Recurrence Plots. In order to utilize the research done in the area of image classification, where Deep Neural Networks have achieved very good results, we use a Residual Neural Networks architecture known as ResNet. As preprocessing of time series is a major part of every time series classification pipeline, the method proposed simplifies this step and requires only few parameters. For the first time we propose a method for multi time series classification: Training a single network to classify all datasets in the archive with one network. We are among the first to evaluate the method on the latest 2018 release of the UCR archive, a well established time series classification benchmarking dataset.
Drift-Adjusted And Arbitrated Ensemble Framework For Time Series Forecasting
Mar 16, 2020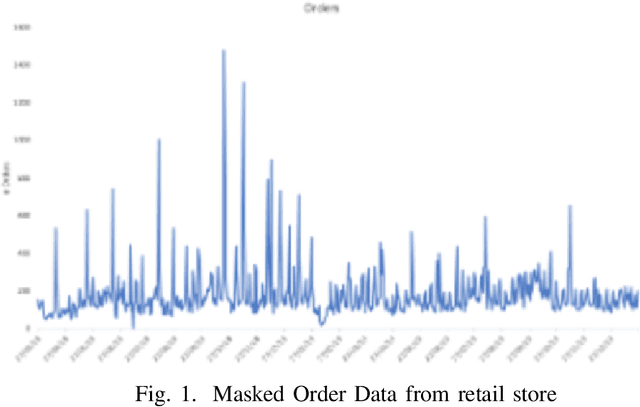
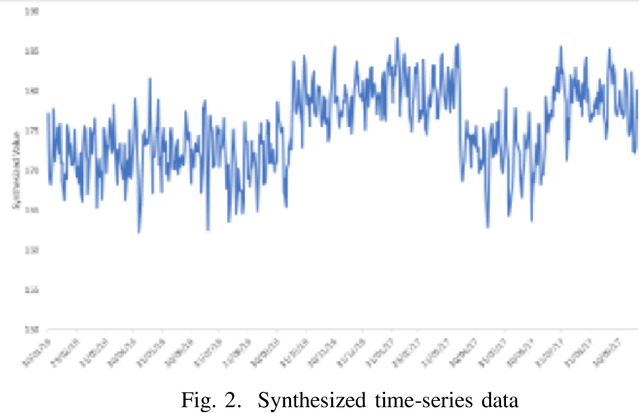
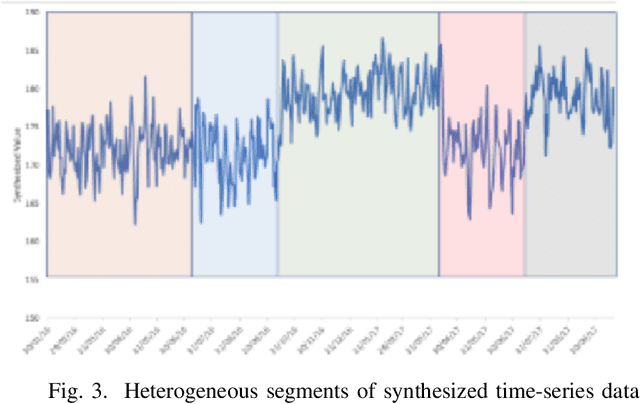
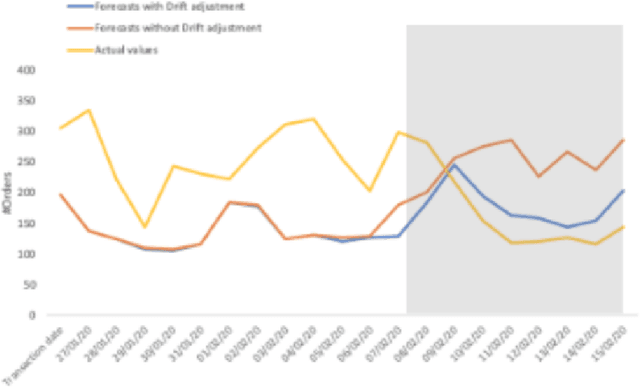
Time Series Forecasting is at the core of many practical applications such as sales forecasting for business, rainfall forecasting for agriculture and many others. Though this problem has been extensively studied for years, it is still considered a challenging problem due to complex and evolving nature of time series data. Typical methods proposed for time series forecasting modeled linear or non-linear dependencies between data observations. However it is a generally accepted notion that no one method is universally effective for all kinds of time series data. Attempts have been made to use dynamic and weighted combination of heterogeneous and independent forecasting models and it has been found to be a promising direction to tackle this problem. This method is based on the assumption that different forecasters have different specialization and varying performance for different distribution of data and weights are dynamically assigned to multiple forecasters accordingly. However in many practical time series data-set, the distribution of data slowly evolves with time. We propose to employ a re-weighting based method to adjust the assigned weights to various forecasters in order to account for such distribution-drift. An exhaustive testing was performed against both real-world and synthesized time-series. Experimental results show the competitiveness of the method in comparison to state-of-the-art approaches for combining forecasters and handling drift.
Few-shot Unsupervised Domain Adaptation for Multi-modal Cardiac Image Segmentation
Jan 28, 2022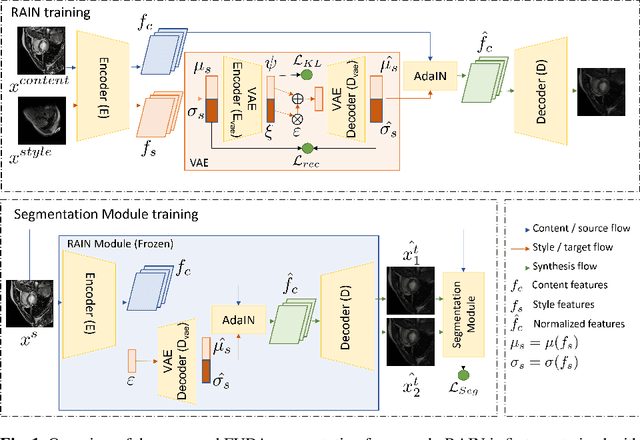
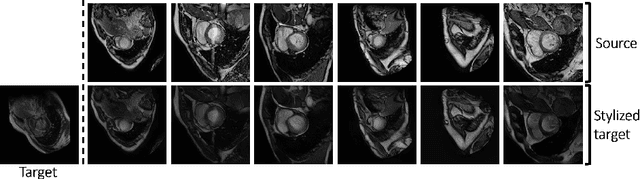

Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by using unlabeled target domain and labeled source domain data, however, in the medical domain, target domain data may not always be easily available, and acquiring new samples is generally time-consuming. This restricts the development of UDA methods for new domains. In this paper, we explore the potential of UDA in a more challenging while realistic scenario where only one unlabeled target patient sample is available. We call it Few-shot Unsupervised Domain adaptation (FUDA). We first generate target-style images from source images and explore diverse target styles from a single target patient with Random Adaptive Instance Normalization (RAIN). Then, a segmentation network is trained in a supervised manner with the generated target images. Our experiments demonstrate that FUDA improves the segmentation performance by 0.33 of Dice score on the target domain compared with the baseline, and it also gives 0.28 of Dice score improvement in a more rigorous one-shot setting. Our code is available at \url{https://github.com/MingxuanGu/Few-shot-UDA}.
Safe Linear Leveling Bandits
Dec 13, 2021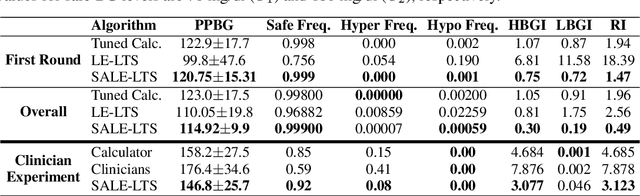
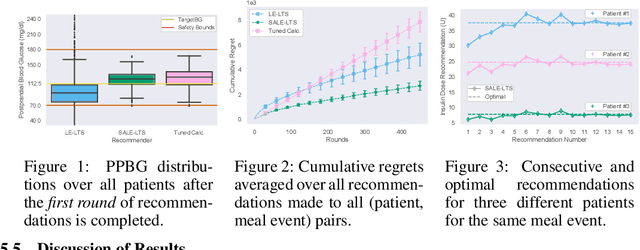
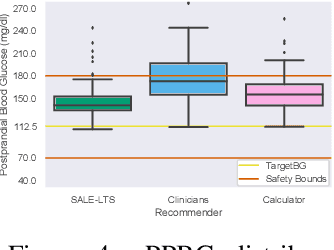
Multi-armed bandits (MAB) are extensively studied in various settings where the objective is to \textit{maximize} the actions' outcomes (i.e., rewards) over time. Since safety is crucial in many real-world problems, safe versions of MAB algorithms have also garnered considerable interest. In this work, we tackle a different critical task through the lens of \textit{linear stochastic bandits}, where the aim is to keep the actions' outcomes close to a target level while respecting a \textit{two-sided} safety constraint, which we call \textit{leveling}. Such a task is prevalent in numerous domains. Many healthcare problems, for instance, require keeping a physiological variable in a range and preferably close to a target level. The radical change in our objective necessitates a new acquisition strategy, which is at the heart of a MAB algorithm. We propose SALE-LTS: Safe Leveling via Linear Thompson Sampling algorithm, with a novel acquisition strategy to accommodate our task and show that it achieves sublinear regret with the same time and dimension dependence as previous works on the classical reward maximization problem absent any safety constraint. We demonstrate and discuss our algorithm's empirical performance in detail via thorough experiments.
Deep Reinforcement Learning for Real-Time Optimization of Pumps in Water Distribution Systems
Oct 13, 2020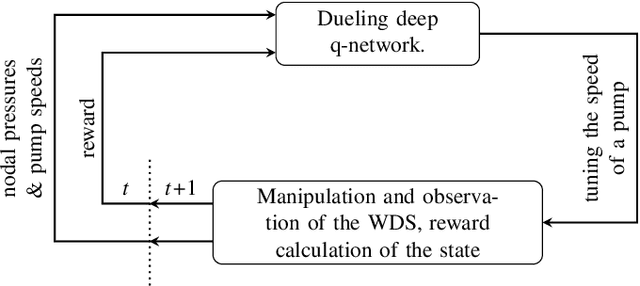

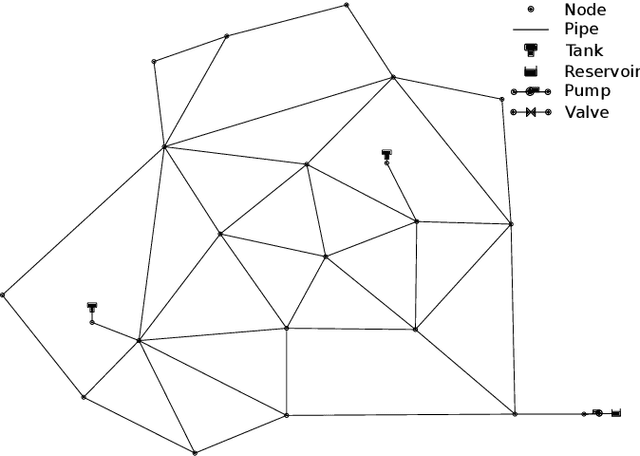

Real-time control of pumps can be an infeasible task in water distribution systems (WDSs) because the calculation to find the optimal pump speeds is resource-intensive. The computational need cannot be lowered even with the capabilities of smart water networks when conventional optimization techniques are used. Deep reinforcement learning (DRL) is presented here as a controller of pumps in two WDSs. An agent based on a dueling deep q-network is trained to maintain the pump speeds based on instantaneous nodal pressure data. General optimization techniques (e.g., Nelder-Mead method, differential evolution) serve as baselines. The total efficiency achieved by the DRL agent compared to the best performing baseline is above 0.98, whereas the speedup is around 2x compared to that. The main contribution of the presented approach is that the agent can run the pumps in real-time because it depends only on measurement data. If the WDS is replaced with a hydraulic simulation, the agent still outperforms conventional techniques in search speed.
Benchmarking Robustness of 3D Point Cloud Recognition Against Common Corruptions
Jan 28, 2022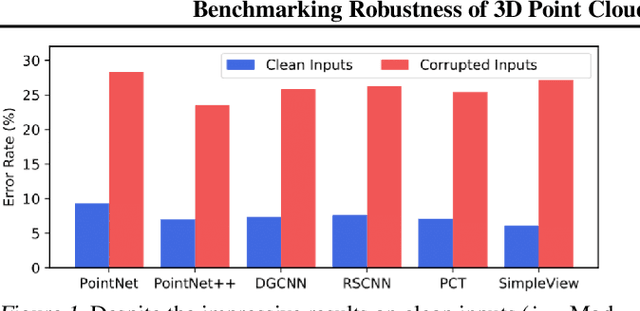
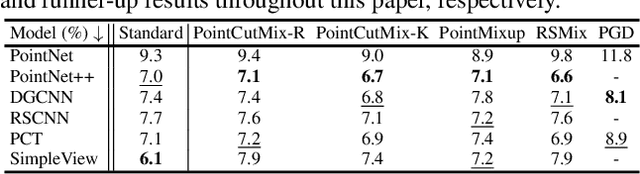
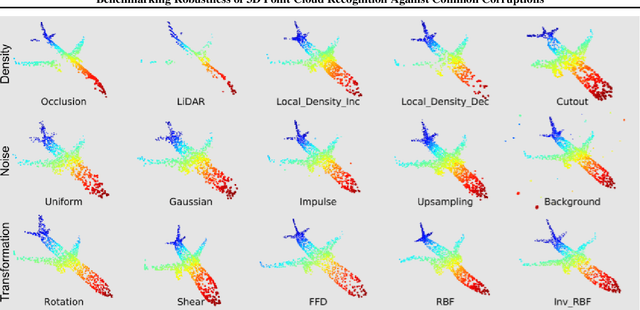

Deep neural networks on 3D point cloud data have been widely used in the real world, especially in safety-critical applications. However, their robustness against corruptions is less studied. In this paper, we present ModelNet40-C, the first comprehensive benchmark on 3D point cloud corruption robustness, consisting of 15 common and realistic corruptions. Our evaluation shows a significant gap between the performances on ModelNet40 and ModelNet40-C for state-of-the-art (SOTA) models. To reduce the gap, we propose a simple but effective method by combining PointCutMix-R and TENT after evaluating a wide range of augmentation and test-time adaptation strategies. We identify a number of critical insights for future studies on corruption robustness in point cloud recognition. For instance, we unveil that Transformer-based architectures with proper training recipes achieve the strongest robustness. We hope our in-depth analysis will motivate the development of robust training strategies or architecture designs in the 3D point cloud domain. Our codebase and dataset are included in https://github.com/jiachens/ModelNet40-C
Warping Resilient Time Series Embeddings
Jun 12, 2019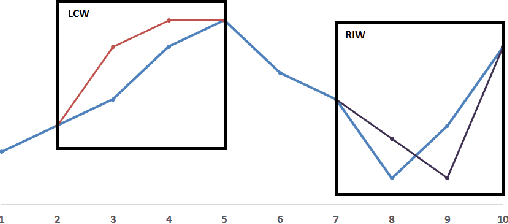
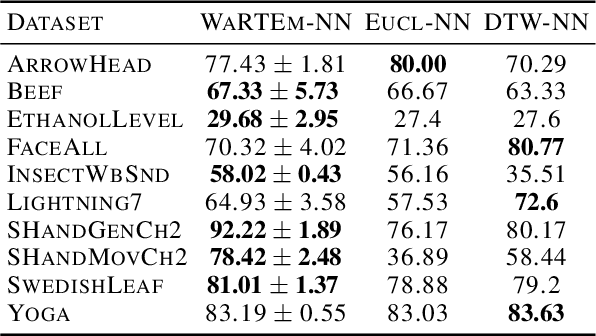
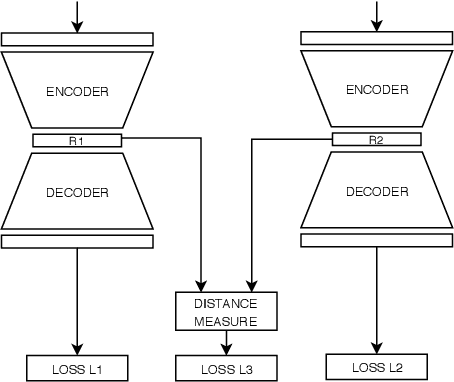
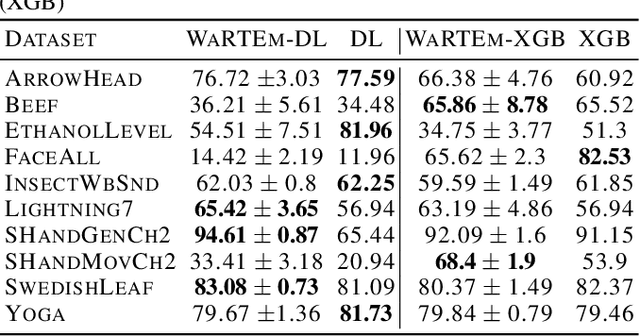
Time series are ubiquitous in real world problems and computing distance between two time series is often required in several learning tasks. Computing similarity between time series by ignoring variations in speed or warping is often encountered and dynamic time warping (DTW) is the state of the art. However DTW is not applicable in algorithms which require kernel or vectors. In this paper, we propose a mechanism named WaRTEm to generate vector embeddings of time series such that distance measures in the embedding space exhibit resilience to warping. Therefore, WaRTEm is more widely applicable than DTW. WaRTEm is based on a twin auto-encoder architecture and a training strategy involving warping operators for generating warping resilient embeddings for time series datasets. We evaluate the performance of WaRTEm and observed more than $20\%$ improvement over DTW in multiple real-world datasets.
Optimal Localization with Sequential Pseudorange Measurements for Moving Users in a Time Division Broadcast Positioning System
Feb 01, 2021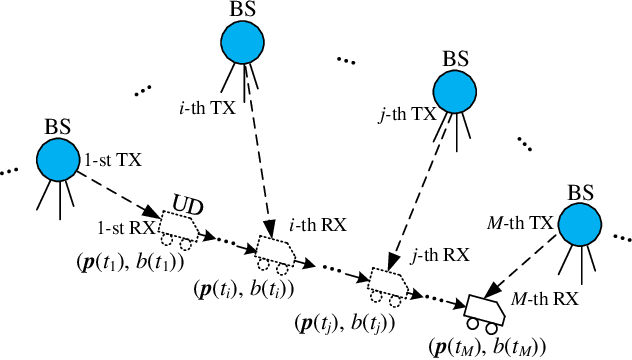
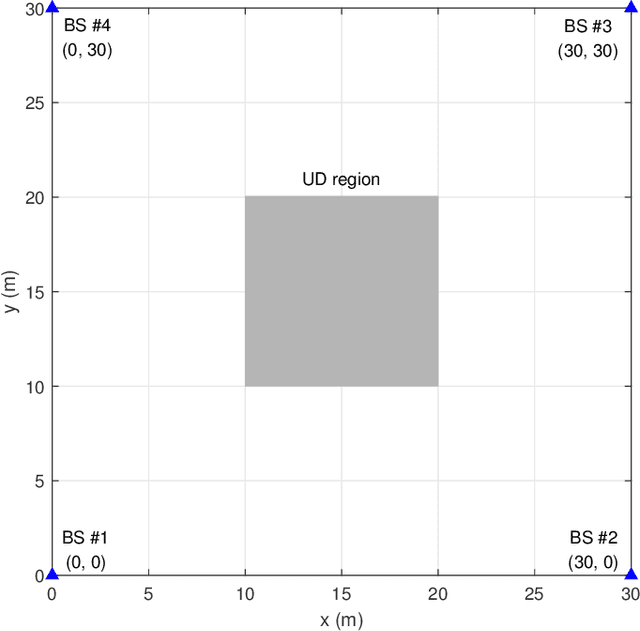
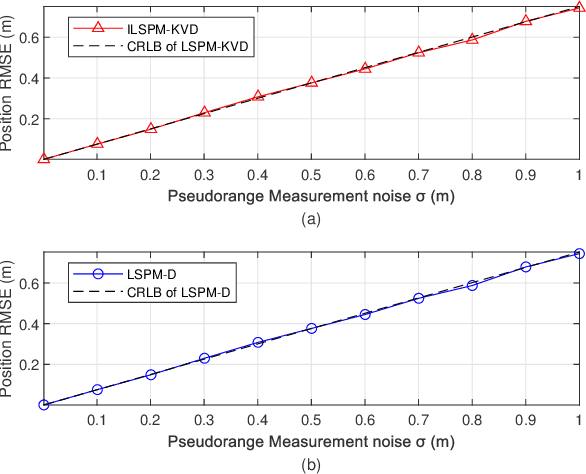
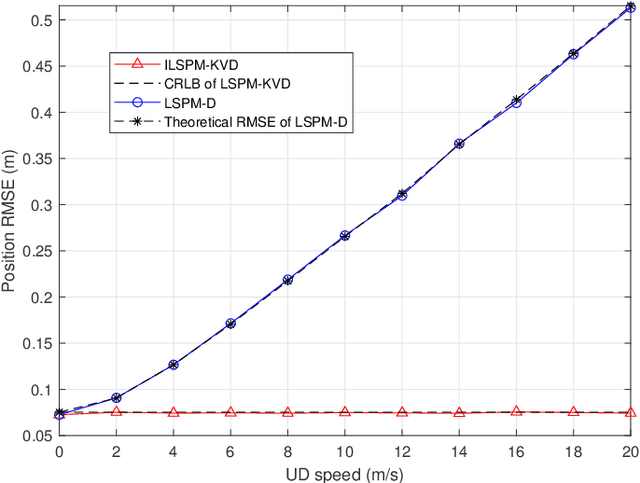
In a time division broadcast positioning system (TDBPS), a user device (UD) determines its position by obtaining sequential time-of-arrival (TOA) or pseudorange measurements from signals broadcast by multiple synchronized base stations (BSs). The existing localization method using sequential pseudorange measurements and a linear clock drift model for the TDPBS, namely LSPM-D, does not compensate the position displacement caused by the UD movement and will result in position error. In this paper, depending on the knowledge of the UD velocity, we develop a set of optimal localization methods for different cases. First, for known UD velocity, we develop the optimal localization method, namely LSPM-KVD, to compensate the movement-caused position error. We show that the LSPM-D is a special case of the LSPM-KVD when the UD is stationary with zero velocity. Second, for the case with unknown UD velocity, we develop a maximum likelihood (ML) method to jointly estimate the UD position and velocity, namely LSPM-UVD. Third, in the case that we have prior distribution information of the UD velocity, we present a maximum a posteriori (MAP) estimator for localization, namely LSPM-PVD. We derive the Cramer-Rao lower bound (CRLB) for all three estimators and analyze their localization error performance. We show that the position error of the LSPM-KVD increases as the assumed known velocity deviates from the true value. As expected, the LSPM-KVD has the smallest position error while the LSPM-PVD and the LSPM-UVD are more robust when the prior knowledge of the UD velocity is limited. Numerical results verify the theoretical analysis on the optimality and the positioning accuracy of the proposed methods.
An efficient label-free analyte detection algorithm for time-resolved spectroscopy
Nov 15, 2020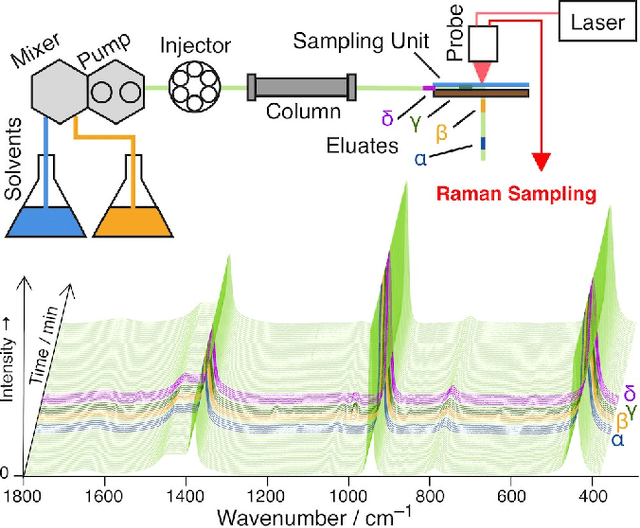
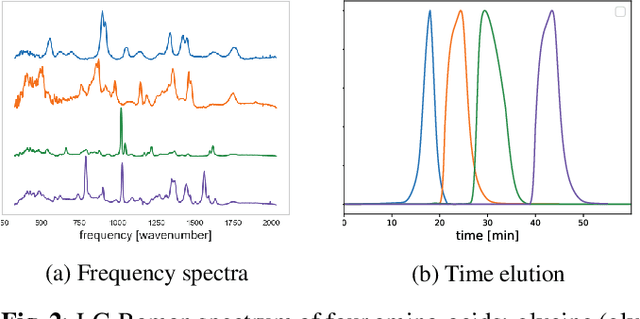
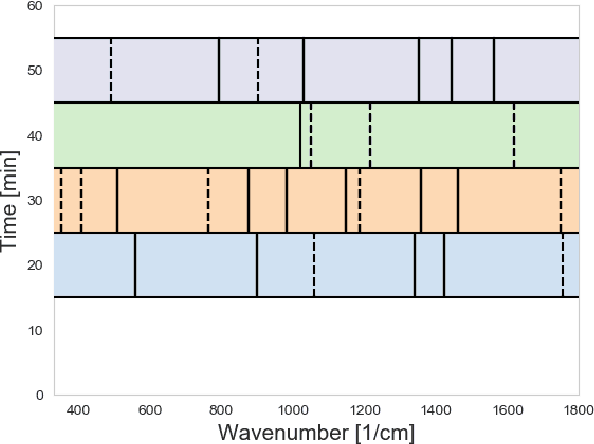
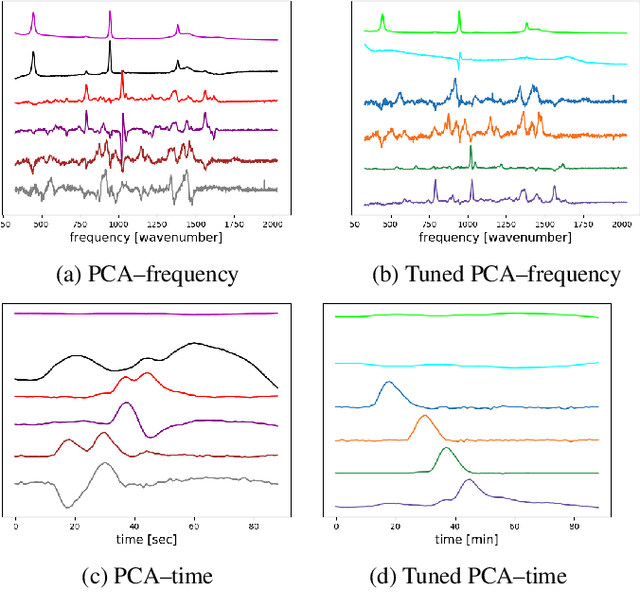
Time-resolved spectral techniques play an important analysis tool in many contexts, from physical chemistry to biomedicine. Customarily, the label-free detection of analytes is manually performed by experts through the aid of classic dimensionality-reduction methods, such as Principal Component Analysis (PCA) and Non-negative Matrix Factorization (NMF). This fundamental reliance on expert analysis for unknown analyte detection severely hinders the applicability and the throughput of these such techniques. For this reason, in this paper, we formulate this detection problem as an unsupervised learning problem and propose a novel machine learning algorithm for label-free analyte detection. To show the effectiveness of the proposed solution, we consider the problem of detecting the amino-acids in Liquid Chromatography coupled with Raman spectroscopy (LC-Raman).