 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating Prediction-Time Batch Normalization for Robustness under Covariate Shift
Jul 17, 2020
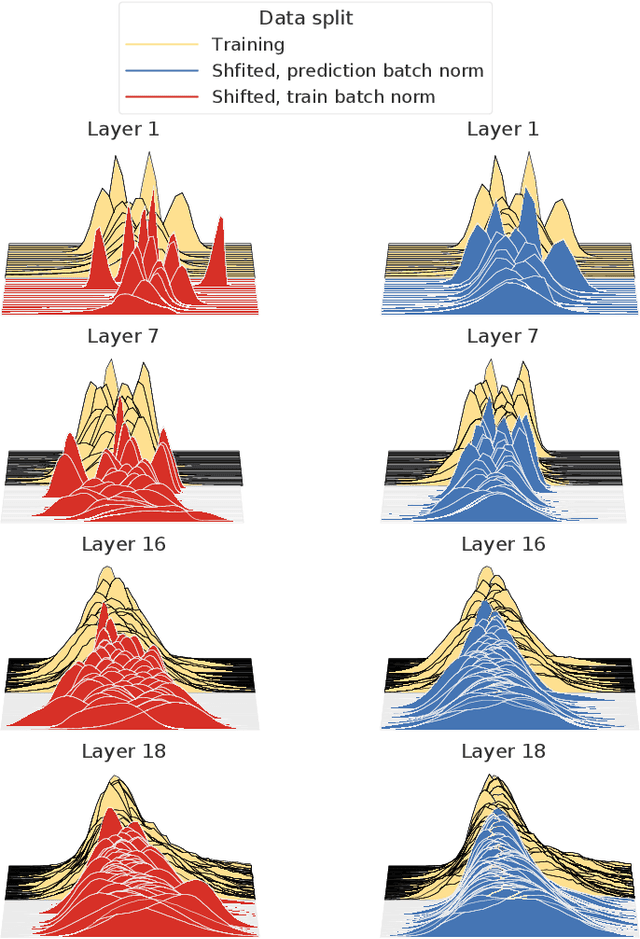
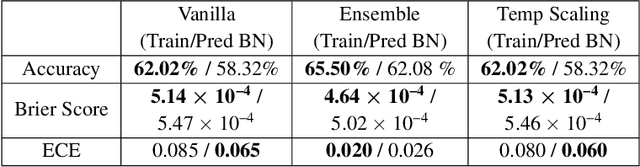
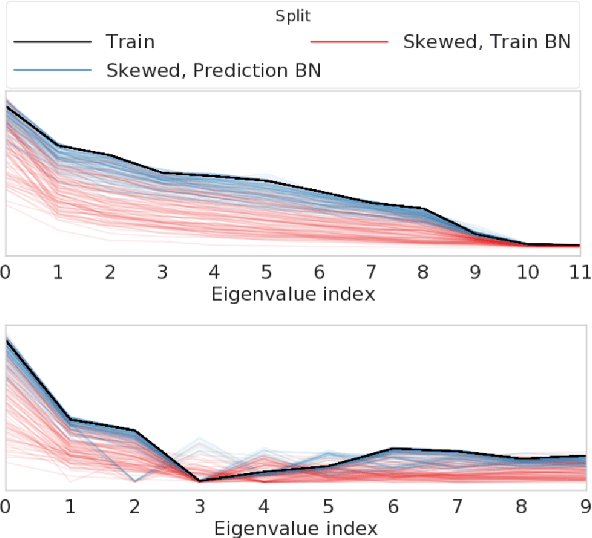
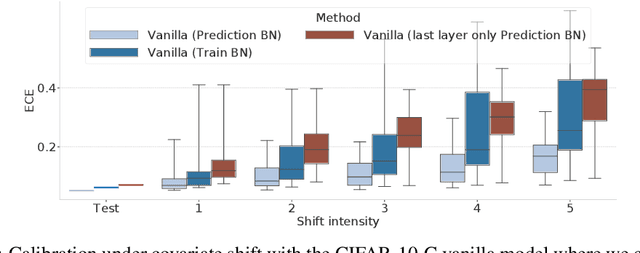
Covariate shift has been shown to sharply degrade both predictive accuracy and the calibration of uncertainty estimates for deep learning models. This is worrying, because covariate shift is prevalent in a wide range of real world deployment settings. However, in this paper, we note that frequently there exists the potential to access small unlabeled batches of the shifted data just before prediction time. This interesting observation enables a simple but surprisingly effective method which we call prediction-time batch normalization, which significantly improves model accuracy and calibration under covariate shift. Using this one line code change, we achieve state-of-the-art on recent covariate shift benchmarks and an mCE of 60.28\% on the challenging ImageNet-C dataset; to our knowledge, this is the best result for any model that does not incorporate additional data augmentation or modification of the training pipeline. We show that prediction-time batch normalization provides complementary benefits to existing state-of-the-art approaches for improving robustness (e.g. deep ensembles) and combining the two further improves performance. Our findings are supported by detailed measurements of the effect of this strategy on model behavior across rigorous ablations on various dataset modalities. However, the method has mixed results when used alongside pre-training, and does not seem to perform as well under more natural types of dataset shift, and is therefore worthy of additional study. We include links to the data in our figures to improve reproducibility, including a Python notebooks that can be run to easily modify our analysis at https://colab.research.google.com/drive/11N0wDZnMQQuLrRwRoumDCrhSaIhkqjof.
MacLeR: Machine Learning-based Run-Time Hardware Trojan Detection in Resource-Constrained IoT Edge Devices
Nov 21, 2020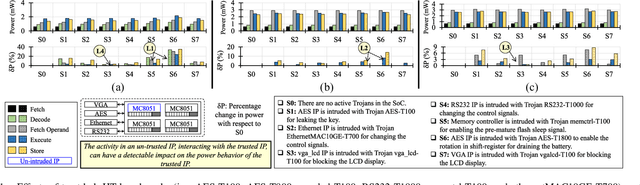
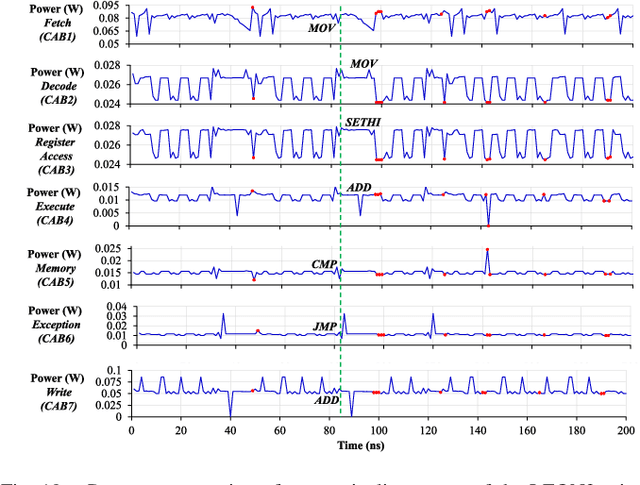
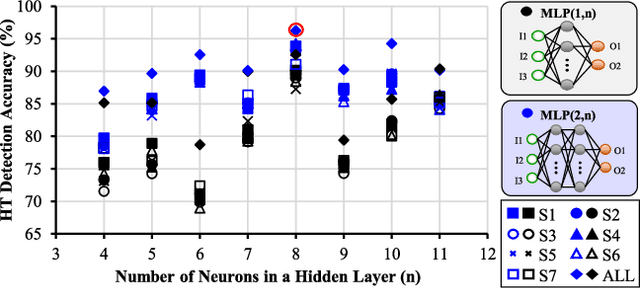
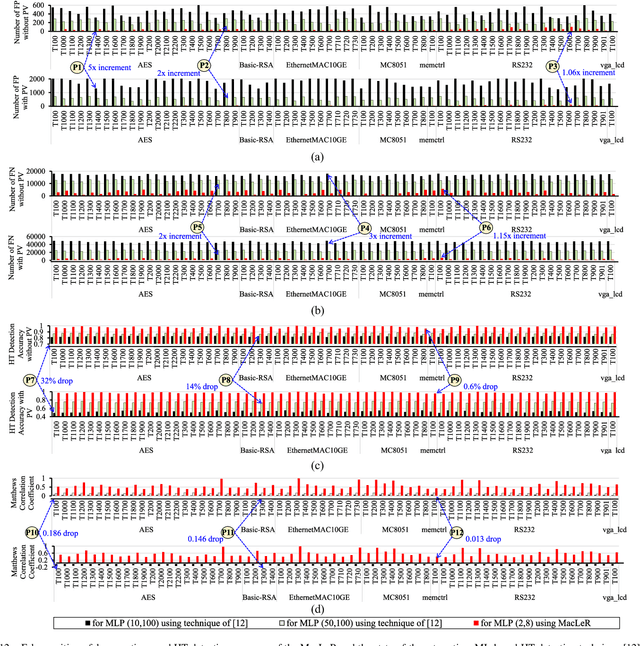
Traditional learning-based approaches for run-time Hardware Trojan detection require complex and expensive on-chip data acquisition frameworks and thus incur high area and power overhead. To address these challenges, we propose to leverage the power correlation between the executing instructions of a microprocessor to establish a machine learning-based run-time Hardware Trojan (HT) detection framework, called MacLeR. To reduce the overhead of data acquisition, we propose a single power-port current acquisition block using current sensors in time-division multiplexing, which increases accuracy while incurring reduced area overhead. We have implemented a practical solution by analyzing multiple HT benchmarks inserted in the RTL of a system-on-chip (SoC) consisting of four LEON3 processors integrated with other IPs like vga_lcd, RSA, AES, Ethernet, and memory controllers. Our experimental results show that compared to state-of-the-art HT detection techniques, MacLeR achieves 10\% better HT detection accuracy (i.e., 96.256%) while incurring a 7x reduction in area and power overhead (i.e., 0.025% of the area of the SoC and <0.07% of the power of the SoC). In addition, we also analyze the impact of process variation and aging on the extracted power profiles and the HT detection accuracy of MacLeR. Our analysis shows that variations in fine-grained power profiles due to the HTs are significantly higher compared to the variations in fine-grained power profiles caused by the process variations (PV) and aging effects. Moreover, our analysis demonstrates that, on average, the HT detection accuracy drop in MacLeR is less than 1% and 9% when considering only PV and PV with worst-case aging, respectively, which is ~10x less than in the case of the state-of-the-art ML-based HT detection technique.
Unified Field Theory for Deep and Recurrent Neural Networks
Dec 10, 2021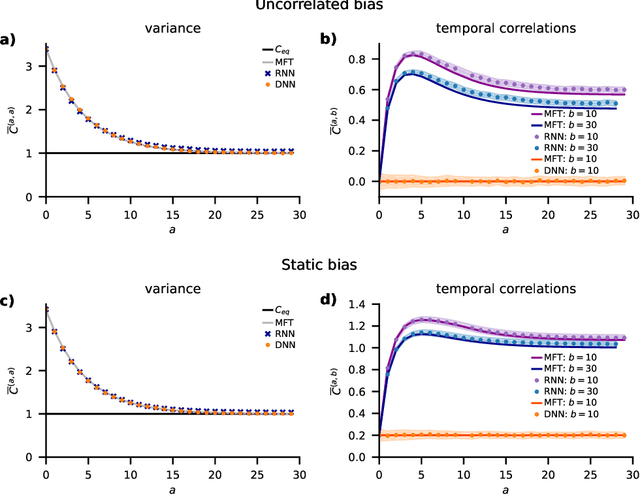

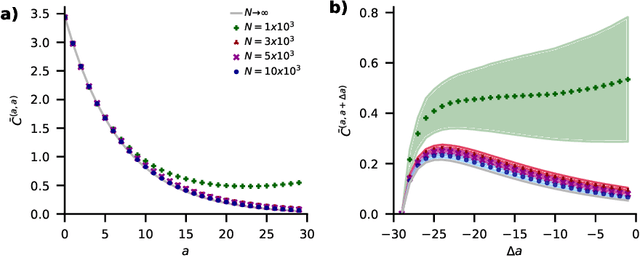
Understanding capabilities and limitations of different network architectures is of fundamental importance to machine learning. Bayesian inference on Gaussian processes has proven to be a viable approach for studying recurrent and deep networks in the limit of infinite layer width, $n\to\infty$. Here we present a unified and systematic derivation of the mean-field theory for both architectures that starts from first principles by employing established methods from statistical physics of disordered systems. The theory elucidates that while the mean-field equations are different with regard to their temporal structure, they yet yield identical Gaussian kernels when readouts are taken at a single time point or layer, respectively. Bayesian inference applied to classification then predicts identical performance and capabilities for the two architectures. Numerically, we find that convergence towards the mean-field theory is typically slower for recurrent networks than for deep networks and the convergence speed depends non-trivially on the parameters of the weight prior as well as the depth or number of time steps, respectively. Our method exposes that Gaussian processes are but the lowest order of a systematic expansion in $1/n$. The formalism thus paves the way to investigate the fundamental differences between recurrent and deep architectures at finite widths $n$.
Towards Predicting Fine Finger Motions from Ultrasound Images via Kinematic Representation
Feb 10, 2022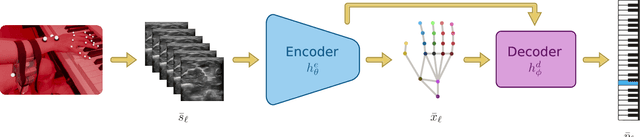
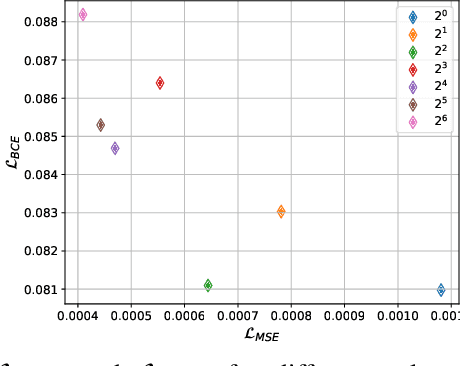

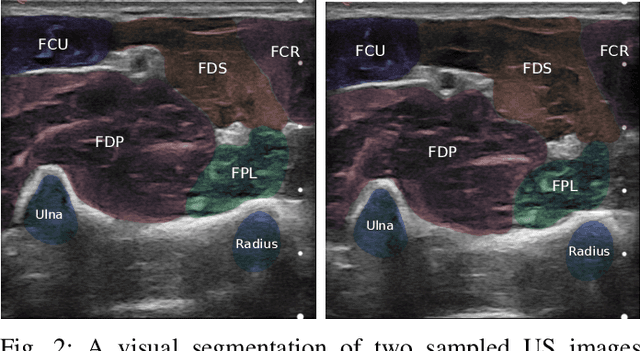
A central challenge in building robotic prostheses is the creation of a sensor-based system able to read physiological signals from the lower limb and instruct a robotic hand to perform various tasks. Existing systems typically perform discrete gestures such as pointing or grasping, by employing electromyography (EMG) or ultrasound (US) technologies to analyze the state of the muscles. In this work, we study the inference problem of identifying the activation of specific fingers from a sequence of US images when performing dexterous tasks such as keyboard typing or playing the piano. While estimating finger gestures has been done in the past by detecting prominent gestures, we are interested in classification done in the context of fine motions that evolve over time. We consider this task as an important step towards higher adoption rates of robotic prostheses among arm amputees, as it has the potential to dramatically increase functionality in performing daily tasks. Our key observation, motivating this work, is that modeling the hand as a robotic manipulator allows to encode an intermediate representation wherein US images are mapped to said configurations. Given a sequence of such learned configurations, coupled with a neural-network architecture that exploits temporal coherence, we are able to infer fine finger motions. We evaluated our method by collecting data from a group of subjects and demonstrating how our framework can be used to replay music played or text typed. To the best of our knowledge, this is the first study demonstrating these downstream tasks within an end-to-end system.
A Multi-channel Training Method Boost the Performance
Dec 27, 2021
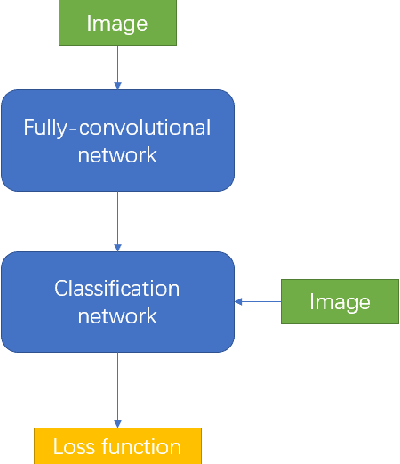
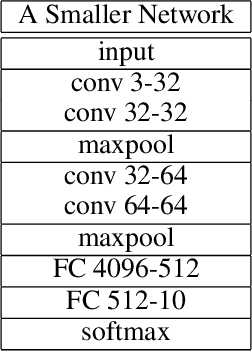
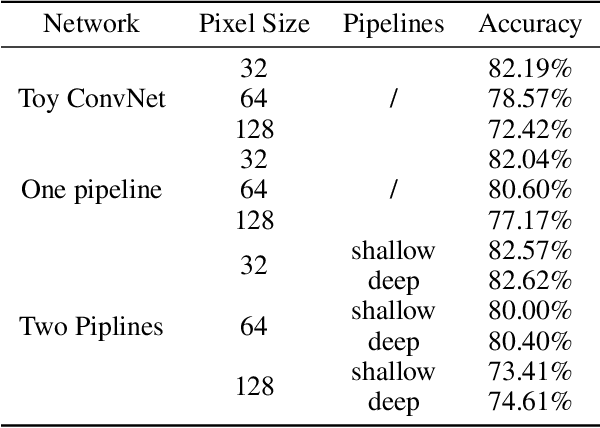
Deep convolutional neural network has made huge revolution and shown its superior performance on computer vision tasks such as classification and segmentation. Recent years, researches devote much effort to scaling down size of network while maintaining its ability, to adapt to the limited memory on embedded systems like mobile phone. In this paper, we propose a multi-channel training procedure which can highly facilitate the performance and robust of the target network. The proposed procedure contains two sets of networks and two information pipelines which can work independently hinge on the computation ability of the embedded platform, while in the mean time, the classification accuracy is also admirably enhanced.
SEFR: A Fast Linear-Time Classifier for Ultra-Low Power Devices
Jun 08, 2020
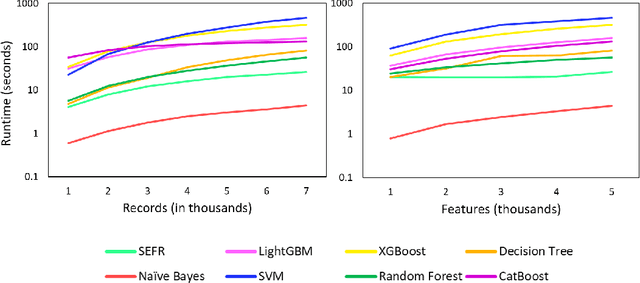
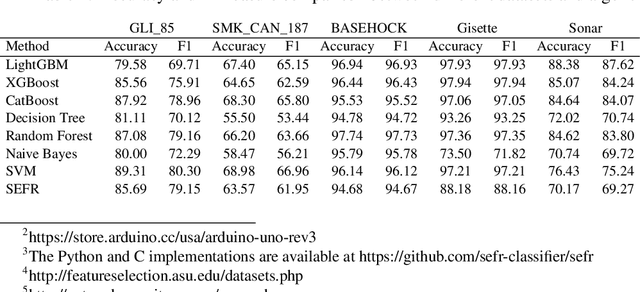
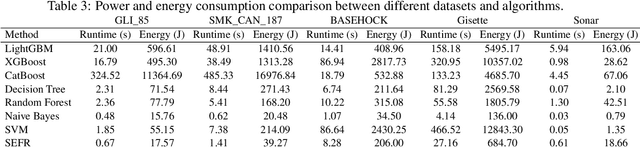
One of the fundamental challenges for running machine learning algorithms on battery-powered devices is the time and energy needed for computation, as these devices have constraints on resources. There are energy-efficient classifier algorithms, but their accuracy is often sacrificed for resource efficiency. Here, we propose an ultra-low power binary classifier, SEFR, with linear time complexity, both in the training and the testing phases. The SEFR method runs by creating a hyperplane to separate two classes. The weights of this hyperplane are calculated using normalization, and then the bias is computed based on the weights. SEFR is comparable to state-of-the-art classifiers in terms of classification accuracy, but its execution time and energy consumption are 11.02% and 8.67% of the average of state-of-the-art and baseline classifiers. The energy and memory consumption of SEFR is very insignificant, and it even can perform both train and test phases on microcontrollers. We have implemented SEFR on Arduino Uno, and on a dataset with 100 records and 100 features, the training time is 195 milliseconds, and testing for 100 records with 100 features takes 0.73 milliseconds. To the best of our knowledge, this is the first multipurpose algorithm specifically devised for learning on ultra-low power devices.
RamanNet: A generalized neural network architecture for Raman Spectrum Analysis
Jan 20, 2022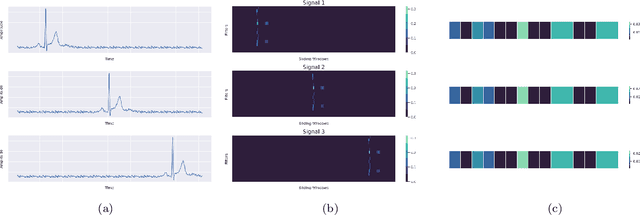
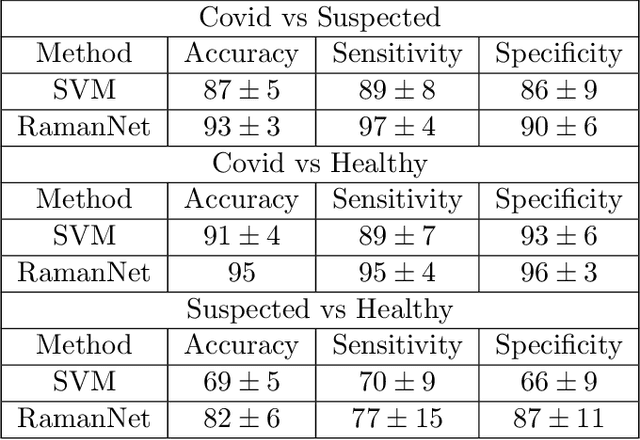
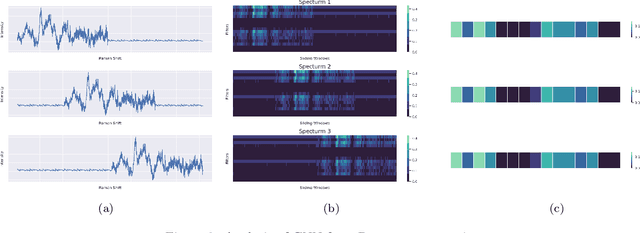

Raman spectroscopy provides a vibrational profile of the molecules and thus can be used to uniquely identify different kind of materials. This sort of fingerprinting molecules has thus led to widespread application of Raman spectrum in various fields like medical dignostics, forensics, mineralogy, bacteriology and virology etc. Despite the recent rise in Raman spectra data volume, there has not been any significant effort in developing generalized machine learning methods for Raman spectra analysis. We examine, experiment and evaluate existing methods and conjecture that neither current sequential models nor traditional machine learning models are satisfactorily sufficient to analyze Raman spectra. Both has their perks and pitfalls, therefore we attempt to mix the best of both worlds and propose a novel network architecture RamanNet. RamanNet is immune to invariance property in CNN and at the same time better than traditional machine learning models for the inclusion of sparse connectivity. Our experiments on 4 public datasets demonstrate superior performance over the much complex state-of-the-art methods and thus RamanNet has the potential to become the defacto standard in Raman spectra data analysis
Latency-Aware Multi-antenna SWIPT System with Battery-Constrained Receivers
Dec 10, 2021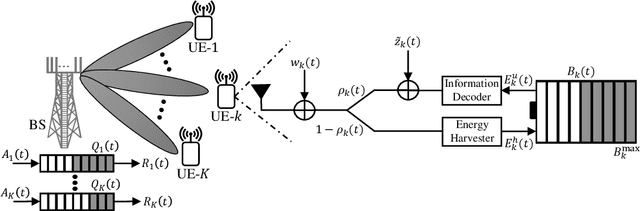
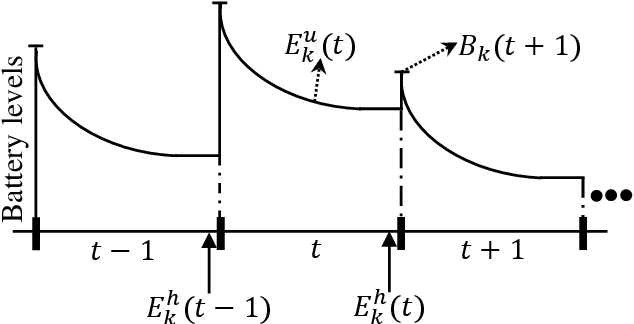
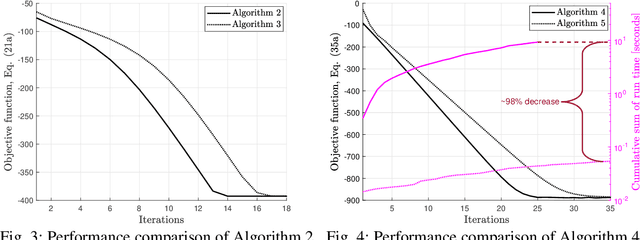
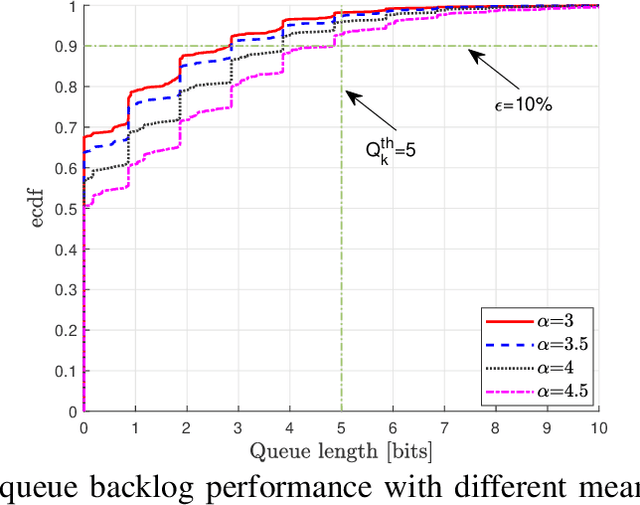
Power splitting (PS) based simultaneous wireless information and power transfer (SWIPT) is considered in a multi-user multiple-input-single-output broadcast scenario. Specifically, we focus on jointly configuring the transmit beamforming vectors and receive PS ratios to minimize the total transmit energy of the base station under the user-specific latency and energy harvesting (EH) requirements. The battery depletion phenomenon is avoided by preemptively incorporating information regarding the receivers' battery state and EH fluctuations into the resource allocation design. The resulting time-average sum-power minimization problem is temporally correlated, non-convex (including mutually coupled latency-battery queue dynamics), and in general intractable. We use the Lyapunov optimization framework and derive a dynamic control algorithm to transform the original problem into a sequence of deterministic and independent subproblems, which are then solved via two alternative approaches: i) semidefinite relaxation combined with fractional programming, and ii) successive convex approximation. Furthermore, we design a low-complexity closed-form iterative algorithm exploiting the Karush-Kuhn-Tucker optimality conditions for a specific scenario with delay bounded batteryless receivers. Numerical results provide insights on the robustness of the proposed design to realize an energy-efficient SWIPT system while ensuring latency and EH requirements in a time dynamic mobile access network.
FMD-cGAN: Fast Motion Deblurring using Conditional Generative Adversarial Networks
Nov 30, 2021
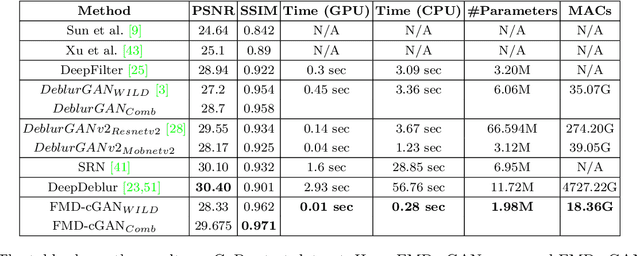


In this paper, we present a Fast Motion Deblurring-Conditional Generative Adversarial Network (FMD-cGAN) that helps in blind motion deblurring of a single image. FMD-cGAN delivers impressive structural similarity and visual appearance after deblurring an image. Like other deep neural network architectures, GANs also suffer from large model size (parameters) and computations. It is not easy to deploy the model on resource constraint devices such as mobile and robotics. With the help of MobileNet based architecture that consists of depthwise separable convolution, we reduce the model size and inference time, without losing the quality of the images. More specifically, we reduce the model size by 3-60x compare to the nearest competitor. The resulting compressed Deblurring cGAN faster than its closest competitors and even qualitative and quantitative results outperform various recently proposed state-of-the-art blind motion deblurring models. We can also use our model for real-time image deblurring tasks. The current experiment on the standard datasets shows the effectiveness of the proposed method.
Self-consistent Gradient-like Eigen Decomposition in Solving Schrödinger Equations
Feb 03, 2022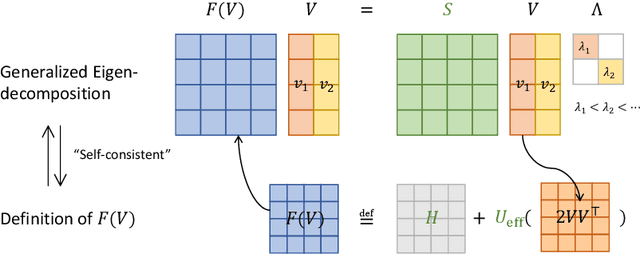

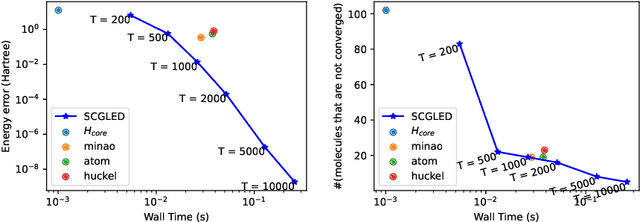
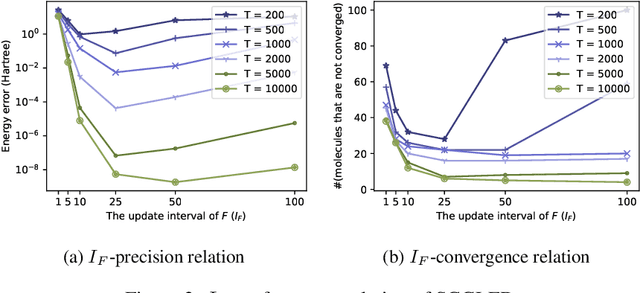
The Schr\"odinger equation is at the heart of modern quantum mechanics. Since exact solutions of the ground state are typically intractable, standard approaches approximate Schr\"odinger equation as forms of nonlinear generalized eigenvalue problems $F(V)V = SV\Lambda$ in which $F(V)$, the matrix to be decomposed, is a function of its own top-$k$ smallest eigenvectors $V$, leading to a "self-consistency problem". Traditional iterative methods heavily rely on high-quality initial guesses of $V$ generated via domain-specific heuristics methods based on quantum mechanics. In this work, we eliminate such a need for domain-specific heuristics by presenting a novel framework, Self-consistent Gradient-like Eigen Decomposition (SCGLED) that regards $F(V)$ as a special "online data generator", thus allows gradient-like eigendecomposition methods in streaming $k$-PCA to approach the self-consistency of the equation from scratch in an iterative way similar to online learning. With several critical numerical improvements, SCGLED is robust to initial guesses, free of quantum-mechanism-based heuristics designs, and neat in implementation. Our experiments show that it not only can simply replace traditional heuristics-based initial guess methods with large performance advantage (achieved averagely 25x more precise than the best baseline in similar wall time), but also is capable of finding highly precise solutions independently without any traditional iterative methods.