 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Multi-Task Deep Learning and Model Based Control Algorithm for Autonomous Driving
Dec 16, 2021
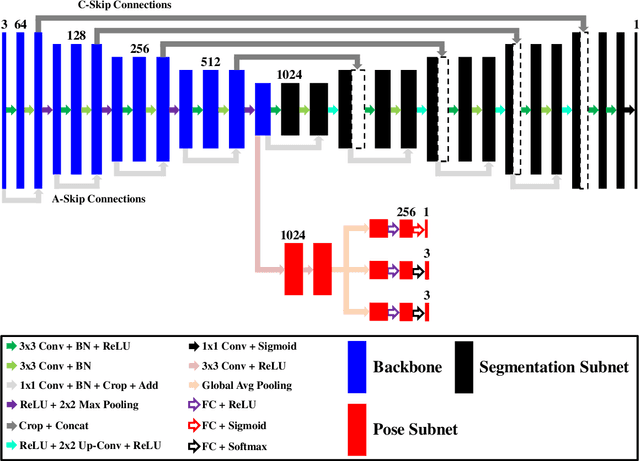
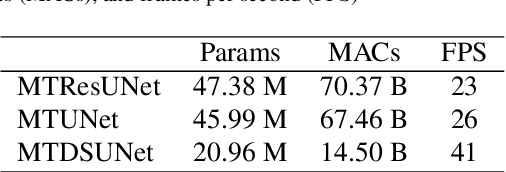


End-to-end driving with a deep learning neural network (DNN) has become a rapidly growing paradigm of autonomous driving in industry and academia. Yet safety measures and interpretability still pose challenges to this paradigm. We propose an end-to-end driving algorithm that integrates multi-task DNN, path prediction, and control models in a pipeline of data flow from sensory devices through these models to driving decisions. It provides quantitative measures to evaluate the holistic, dynamic, and real-time performance of end-to-end driving systems, and thus allows to quantify their safety and interpretability. The DNN is a modified UNet, a well known encoder-decoder neural network of semantic segmentation. It consists of one segmentation, one regression, and two classification tasks for lane segmentation, path prediction, and vehicle controls. We present three variants of the modified UNet architecture having different complexities, compare them on different tasks in four static measures for both single and multi-task (MT) architectures, and then identify the best one by two additional dynamic measures in real-time simulation. We also propose a learning- and model-based longitudinal controller using model predictive control method. With the Stanley lateral controller, our results show that MTUNet outperforms an earlier modified UNet in terms of curvature and lateral offset estimation on curvy roads at normal speed, which has been tested in a real car driving on real roads.
Learning a Shield from Catastrophic Action Effects: Never Repeat the Same Mistake
Feb 19, 2022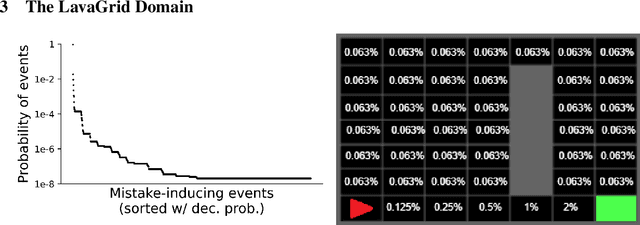
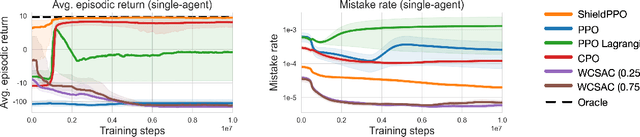
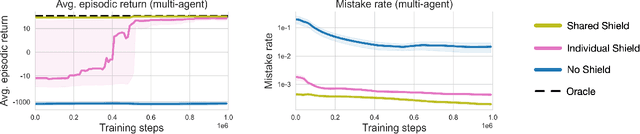
Agents that operate in an unknown environment are bound to make mistakes while learning, including, at least occasionally, some that lead to catastrophic consequences. When humans make catastrophic mistakes, they are expected to learn never to repeat them, such as a toddler who touches a hot stove and immediately learns never to do so again. In this work we consider a novel class of POMDPs, called POMDP with Catastrophic Actions (POMDP-CA) in which pairs of states and actions are labeled as catastrophic. Agents that act in a POMDP-CA do not have a priori knowledge about which (state, action) pairs are catastrophic, thus they are sure to make mistakes when trying to learn any meaningful policy. Rather, their aim is to maximize reward while never repeating mistakes. As a first step of avoiding mistake repetition, we leverage the concept of a shield which prevents agents from executing specific actions from specific states. In particular, we store catastrophic mistakes (unsafe pairs of states and actions) that agents make in a database. Agents are then forbidden to pick actions that appear in the database. This approach is especially useful in a continual learning setting, where groups of agents perform a variety of tasks over time in the same underlying environment. In this setting, a task-agnostic shield can be constructed in a way that stores mistakes made by any agent, such that once one agent in a group makes a mistake the entire group learns to never repeat that mistake. This paper introduces a variant of the PPO algorithm that utilizes this shield, called ShieldPPO, and empirically evaluates it in a controlled environment. Results indicate that ShieldPPO outperforms PPO, as well as baseline methods from the safe reinforcement learning literature, in a range of settings.
Control of a Soft Robotic Arm Using a Piecewise Universal Joint Model
Jan 05, 2022
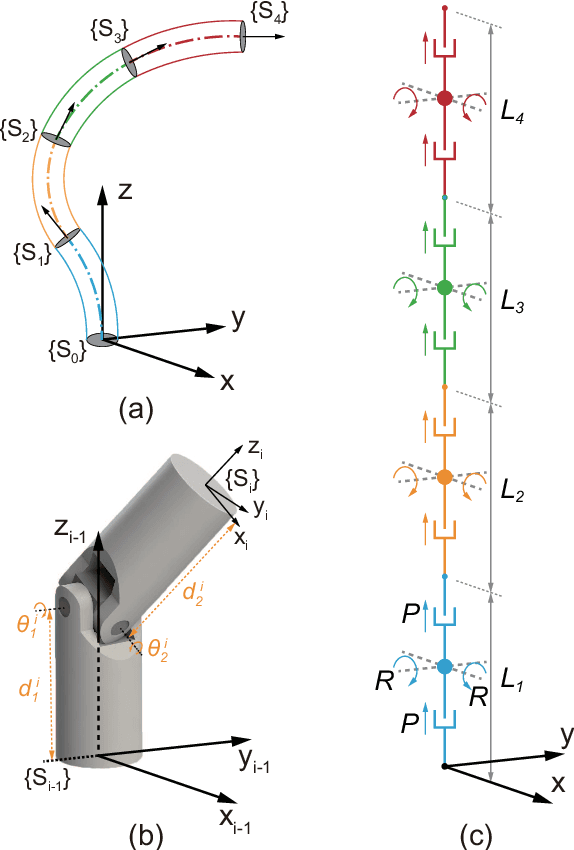


The 'infinite' passive degrees of freedom of soft robotic arms render their control especially challenging. In this paper, we leverage a previously developed model, which drawing equivalence of the soft arm to a series of universal joints, to design two closed-loop controllers: a configuration space controller for trajectory tracking and a task space controller for position control of the end effector. Extensive experiments and simulations on a four-segment soft arm attest to substantial improvement in terms of: a) superior tracking accuracy of the configuration space controller and b) reduced settling time and steady-state error of the task space controller. The task space controller is also verified to be effective in the presence of interactions between the soft arm and the environment.
TATTOOED: A Robust Deep Neural Network Watermarking Scheme based on Spread-Spectrum Channel Coding
Feb 12, 2022
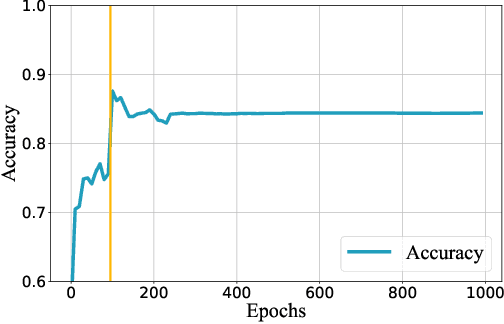
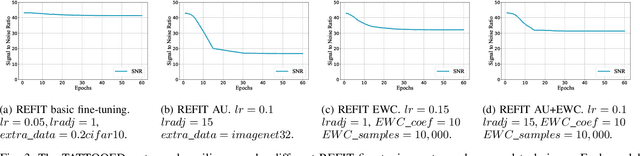
The proliferation of deep learning applications in several areas has led to the rapid adoption of such solutions from an ever-growing number of institutions and companies. The deep neural network (DNN) models developed by these entities are often trained on proprietary data. They require powerful computational resources, with the resulting DNN models being incorporated in the company's work pipeline or provided as a service. Being trained on proprietary information, these models provide a competitive edge for the owner company. At the same time, these models can be attractive to competitors (or malicious entities), which can employ state-of-the-art security attacks to steal and use these models for their benefit. As these attacks are hard to prevent, it becomes imperative to have mechanisms that enable an affected entity to verify the ownership of a DNN with high confidence. This paper presents TATTOOED, a robust and efficient DNN watermarking technique based on spread-spectrum channel coding. TATTOOED has a negligible effect on the performance of the DNN model and requires as little as one iteration to watermark a DNN model. We extensively evaluate TATTOOED against several state-of-the-art mechanisms used to remove watermarks from DNNs. Our results show that TATTOOED is robust to such removal techniques even in extreme scenarios. For example, if the removal techniques such as fine-tuning and parameter pruning change as much as 99\% of the model parameters, the TATTOOED watermark is still present in full in the DNN model, and ensures ownership verification.
On the Mitigation of Read Disturbances in Neuromorphic Inference Hardware
Jan 27, 2022
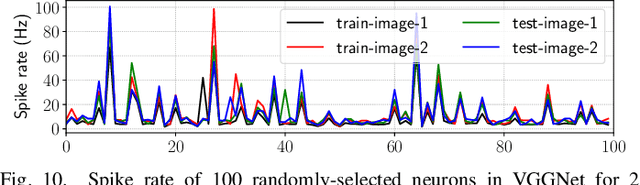
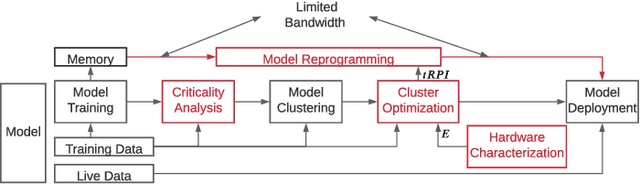
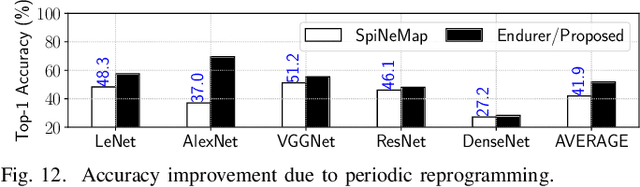
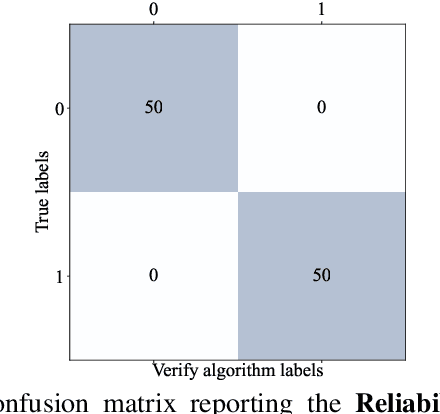
Non-Volatile Memory (NVM) cells are used in neuromorphic hardware to store model parameters, which are programmed as resistance states. NVMs suffer from the read disturb issue, where the programmed resistance state drifts upon repeated access of a cell during inference. Resistance drifts can lower the inference accuracy. To address this, it is necessary to periodically reprogram model parameters (a high overhead operation). We study read disturb failures of an NVM cell. Our analysis show both a strong dependency on model characteristics such as synaptic activation and criticality, and on the voltage used to read resistance states during inference. We propose a system software framework to incorporate such dependencies in programming model parameters on NVM cells of a neuromorphic hardware. Our framework consists of a convex optimization formulation which aims to implement synaptic weights that have more activations and are critical, i.e., those that have high impact on accuracy on NVM cells that are exposed to lower voltages during inference. In this way, we increase the time interval between two consecutive reprogramming of model parameters. We evaluate our system software with many emerging inference models on a neuromorphic hardware simulator and show a significant reduction in the system overhead.
Online Auction-Based Incentive Mechanism Design for Horizontal Federated Learning with Budget Constraint
Jan 22, 2022



Federated learning makes it possible for all parties with data isolation to train the model collaboratively and efficiently while satisfying privacy protection. To obtain a high-quality model, an incentive mechanism is necessary to motivate more high-quality workers with data and computing power. The existing incentive mechanisms are applied in offline scenarios, where the task publisher collects all bids and selects workers before the task. However, it is practical that different workers arrive online in different orders before or during the task. Therefore, we propose a reverse auction-based online incentive mechanism for horizontal federated learning with budget constraint. Workers submit bids when they arrive online. The task publisher with a limited budget leverages the information of the arrived workers to decide on whether to select the new worker. Theoretical analysis proves that our mechanism satisfies budget feasibility, computational efficiency, individual rationality, consumer sovereignty, time truthfulness, and cost truthfulness with a sufficient budget. The experimental results show that our online mechanism is efficient and can obtain high-quality models.
Hallucinated Neural Radiance Fields in the Wild
Dec 01, 2021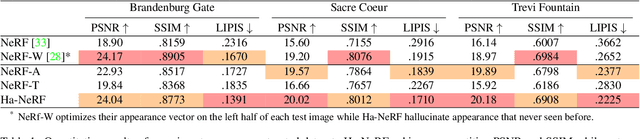
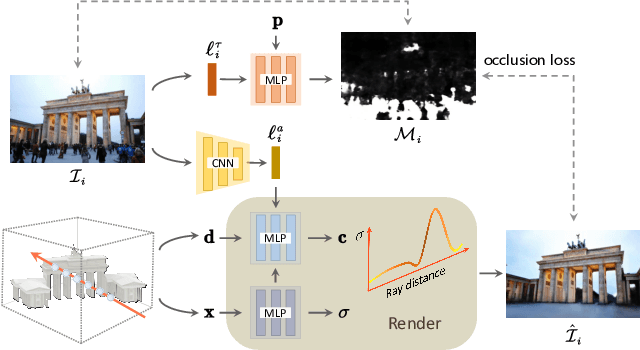
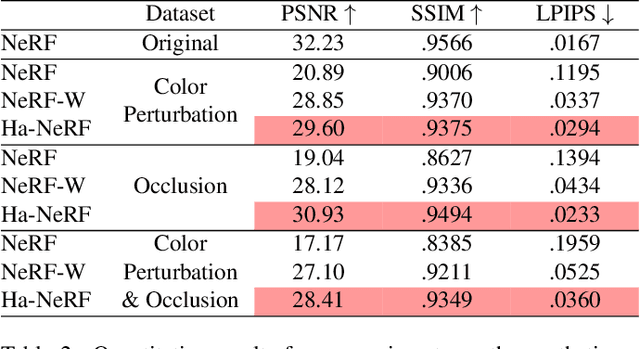
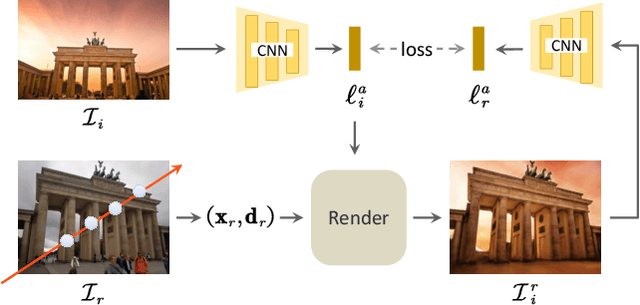
Neural Radiance Fields (NeRF) has recently gained popularity for its impressive novel view synthesis ability. This paper studies the problem of hallucinated NeRF: i.e. recovering a realistic NeRF at a different time of day from a group of tourism images. Existing solutions adopt NeRF with a controllable appearance embedding to render novel views under various conditions, but cannot render view-consistent images with an unseen appearance. To solve this problem, we present an end-to-end framework for constructing a hallucinated NeRF, dubbed as Ha-NeRF. Specifically, we propose an appearance hallucination module to handle time-varying appearances and transfer them to novel views. Considering the complex occlusions of tourism images, an anti-occlusion module is introduced to decompose the static subjects for visibility accurately. Experimental results on synthetic data and real tourism photo collections demonstrate that our method can not only hallucinate the desired appearances, but also render occlusion-free images from different views. The project and supplementary materials are available at https://rover-xingyu.github.io/Ha-NeRF/.
Approaches and Applications of Early Classification of Time Series: A Review
May 06, 2020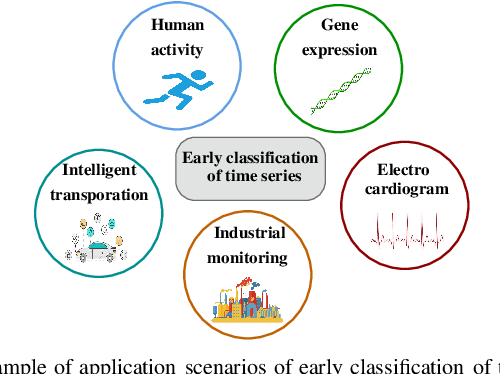
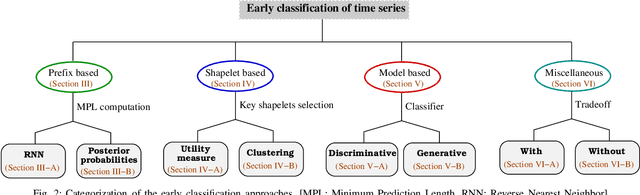
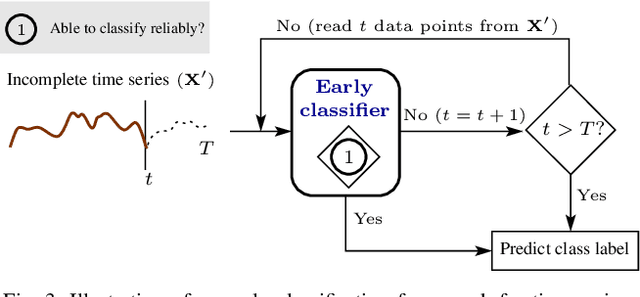
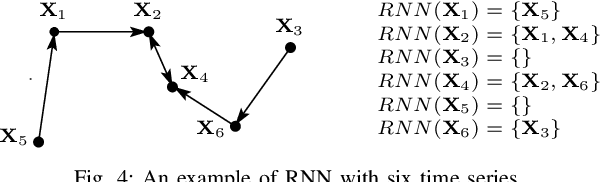
Early classification of time series has been extensively studied for minimizing class prediction delay in time-sensitive applications such as healthcare and finance. A primary task of an early classification approach is to classify an incomplete time series as soon as possible with some desired level of accuracy. Recent years have witnessed several approaches for early classification of time series. As most of the approaches have solved the early classification problem with different aspects, it becomes very important to make a thorough review of the existing solutions to know the current status of the area. These solutions have demonstrated reasonable performance in a wide range of applications including human activity recognition, gene expression based health diagnostic, industrial monitoring, and so on. In this paper, we present a systematic review of current literature on early classification approaches for both univariate and multivariate time series. We divide various existing approaches into four exclusive categories based on their proposed solution strategies. The four categories include prefix based, shapelet based, model based, and miscellaneous approaches. The authors also discuss the applications of early classification in many areas including industrial monitoring, intelligent transportation, and medical. Finally, we provide a quick summary of the current literature with future research directions.
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Dec 20, 2021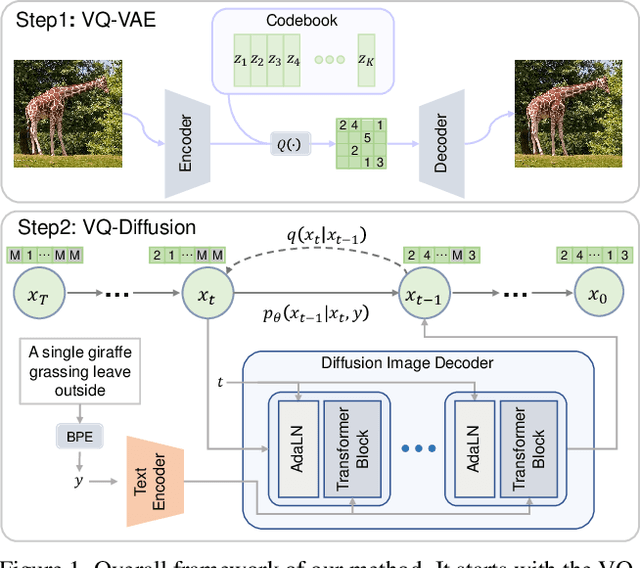
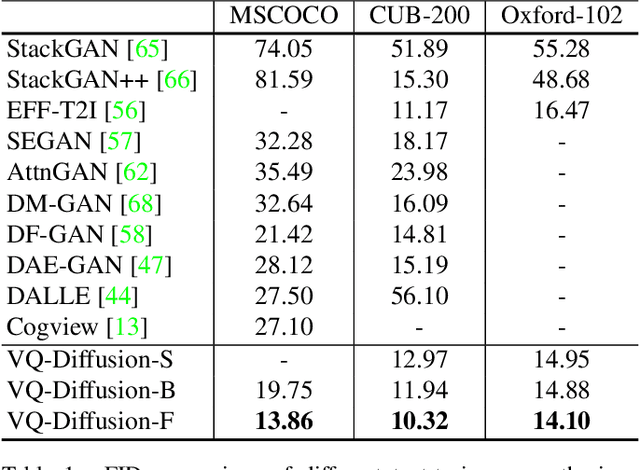

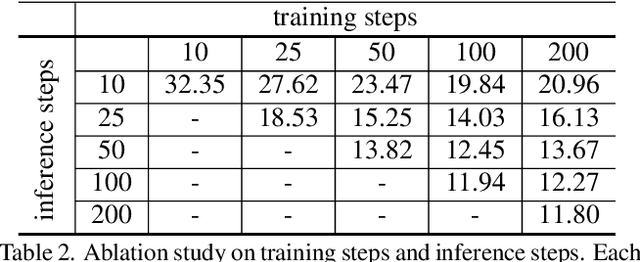
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
Systolic-CNN: An OpenCL-defined Scalable Run-time-flexible FPGA Accelerator Architecture for Accelerating Convolutional Neural Network Inference in Cloud/Edge Computing
Dec 06, 2020This paper presents Systolic-CNN, an OpenCL-defined scalable, run-time-flexible FPGA accelerator architecture, optimized for accelerating the inference of various convolutional neural networks (CNNs) in multi-tenancy cloud/edge computing. The existing OpenCL-defined FPGA accelerators for CNN inference are insufficient due to limited flexibility for supporting multiple CNN models at run time and poor scalability resulting in underutilized FPGA resources and limited computational parallelism. Systolic-CNN adopts a highly pipelined and paralleled 1-D systolic array architecture, which efficiently explores both spatial and temporal parallelism for accelerating CNN inference on FPGAs. Systolic-CNN is highly scalable and parameterized, which can be easily adapted by users to achieve up to 100% utilization of the coarse-grained computation resources (i.e., DSP blocks) for a given FPGA. Systolic-CNN is also run-time-flexible in the context of multi-tenancy cloud/edge computing, which can be time-shared to accelerate a variety of CNN models at run time without the need of recompiling the FPGA kernel hardware nor reprogramming the FPGA. The experiment results based on an Intel Arria/Stratix 10 GX FPGA Development board show that the optimized single-precision implementation of Systolic-CNN can achieve an average inference latency of 7ms/2ms, 84ms/33ms, 202ms/73ms, 1615ms/873ms, and 900ms/498ms per image for accelerating AlexNet, ResNet-50, ResNet-152, RetinaNet, and Light-weight RetinaNet, respectively. Codes are available at https://github.com/PSCLab-ASU/Systolic-CNN.