 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Multi-Task Deep Learning and Model Based Control Algorithm for Autonomous Driving
Dec 16, 2021
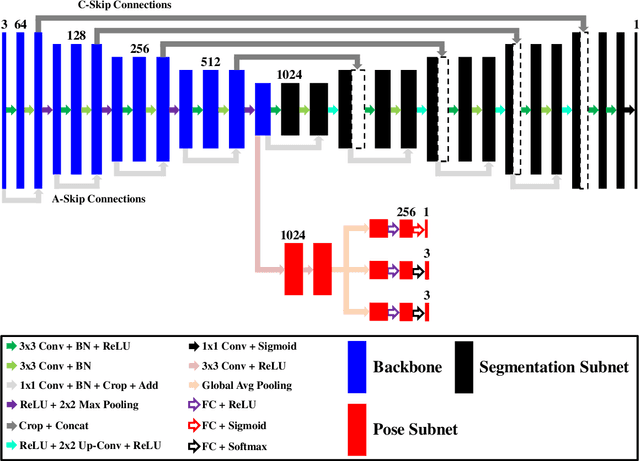
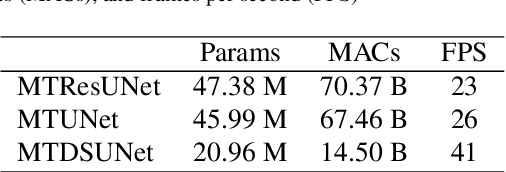


End-to-end driving with a deep learning neural network (DNN) has become a rapidly growing paradigm of autonomous driving in industry and academia. Yet safety measures and interpretability still pose challenges to this paradigm. We propose an end-to-end driving algorithm that integrates multi-task DNN, path prediction, and control models in a pipeline of data flow from sensory devices through these models to driving decisions. It provides quantitative measures to evaluate the holistic, dynamic, and real-time performance of end-to-end driving systems, and thus allows to quantify their safety and interpretability. The DNN is a modified UNet, a well known encoder-decoder neural network of semantic segmentation. It consists of one segmentation, one regression, and two classification tasks for lane segmentation, path prediction, and vehicle controls. We present three variants of the modified UNet architecture having different complexities, compare them on different tasks in four static measures for both single and multi-task (MT) architectures, and then identify the best one by two additional dynamic measures in real-time simulation. We also propose a learning- and model-based longitudinal controller using model predictive control method. With the Stanley lateral controller, our results show that MTUNet outperforms an earlier modified UNet in terms of curvature and lateral offset estimation on curvy roads at normal speed, which has been tested in a real car driving on real roads.
Graph-based Reinforcement Learning for Active Learning in Real Time: An Application in Modeling River Networks
Oct 27, 2020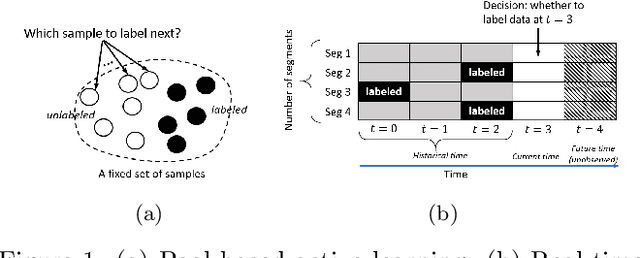
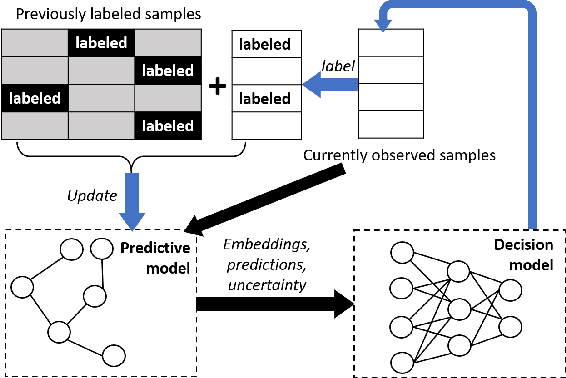
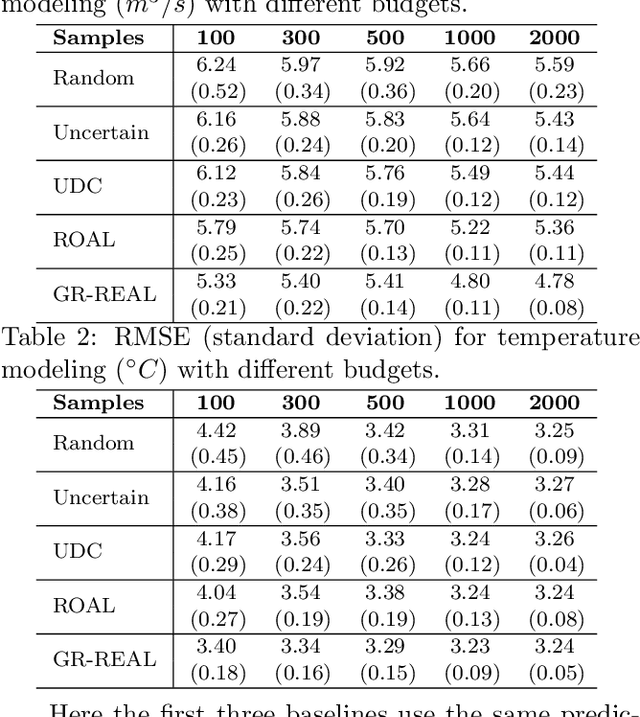
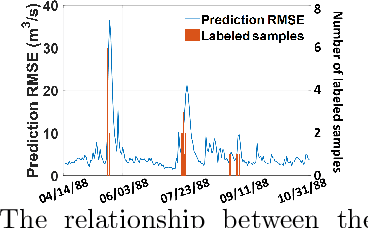
Effective training of advanced ML models requires large amounts of labeled data, which is often scarce in scientific problems given the substantial human labor and material cost to collect labeled data. This poses a challenge on determining when and where we should deploy measuring instruments (e.g., in-situ sensors) to collect labeled data efficiently. This problem differs from traditional pool-based active learning settings in that the labeling decisions have to be made immediately after we observe the input data that come in a time series. In this paper, we develop a real-time active learning method that uses the spatial and temporal contextual information to select representative query samples in a reinforcement learning framework. To reduce the need for large training data, we further propose to transfer the policy learned from simulation data which is generated by existing physics-based models. We demonstrate the effectiveness of the proposed method by predicting streamflow and water temperature in the Delaware River Basin given a limited budget for collecting labeled data. We further study the spatial and temporal distribution of selected samples to verify the ability of this method in selecting informative samples over space and time.
CUDA-Optimized real-time rendering of a Foveated Visual System
Dec 15, 2020
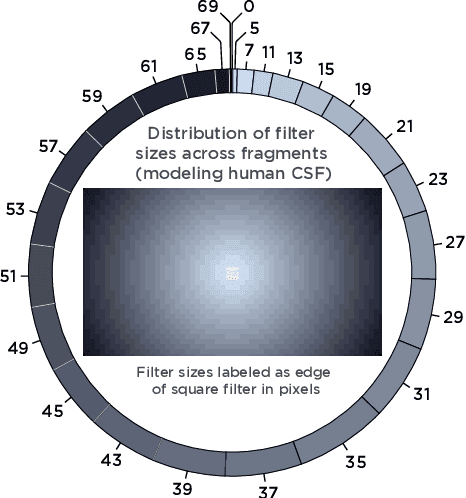
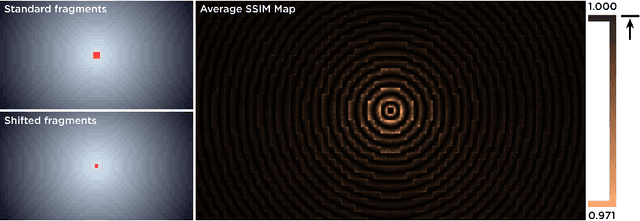
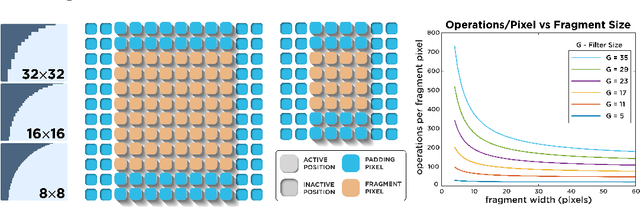
The spatially-varying field of the human visual system has recently received a resurgence of interest with the development of virtual reality (VR) and neural networks. The computational demands of high resolution rendering desired for VR can be offset by savings in the periphery, while neural networks trained with foveated input have shown perceptual gains in i.i.d and o.o.d generalization. In this paper, we present a technique that exploits the CUDA GPU architecture to efficiently generate Gaussian-based foveated images at high definition (1920x1080 px) in real-time (165 Hz), with a larger number of pooling regions than previous Gaussian-based foveation algorithms by several orders of magnitude, producing a smoothly foveated image that requires no further blending or stitching, and that can be well fit for any contrast sensitivity function. The approach described can be adapted from Gaussian blurring to any eccentricity-dependent image processing and our algorithm can meet demand for experimentation to evaluate the role of spatially-varying processing across biological and artificial agents, so that foveation can be added easily on top of existing systems rather than forcing their redesign (emulated foveated renderer). Altogether, this paper demonstrates how a GPU, with a CUDA block-wise architecture, can be employed for radially-variant rendering, with opportunities for more complex post-processing to ensure a metameric foveation scheme. Code is provided.
Bayesian Learning via Neural Schrödinger-Föllmer Flows
Dec 07, 2021
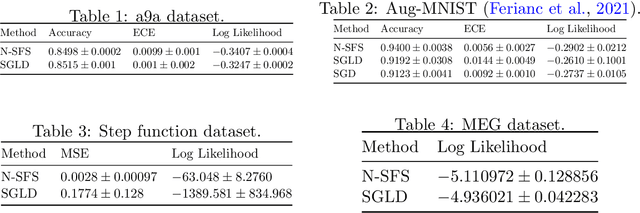
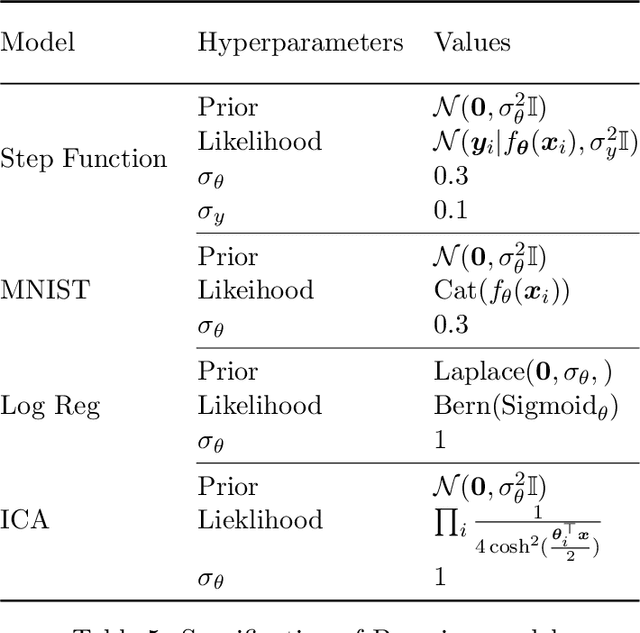
In this work we explore a new framework for approximate Bayesian inference in large datasets based on stochastic control. We advocate stochastic control as a finite time and low variance alternative to popular steady-state methods such as stochastic gradient Langevin dynamics (SGLD). Furthermore, we discuss and adapt the existing theoretical guarantees of this framework and establish connections to already existing VI routines in SDE-based models.
Parallel Successive Learning for Dynamic Distributed Model Training over Heterogeneous Wireless Networks
Feb 12, 2022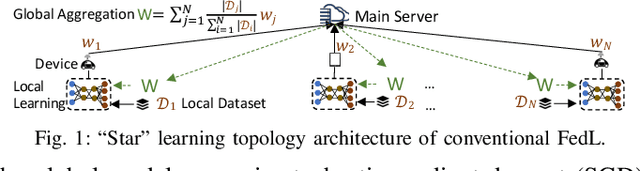
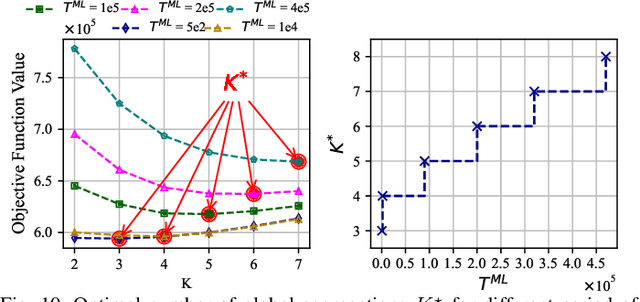
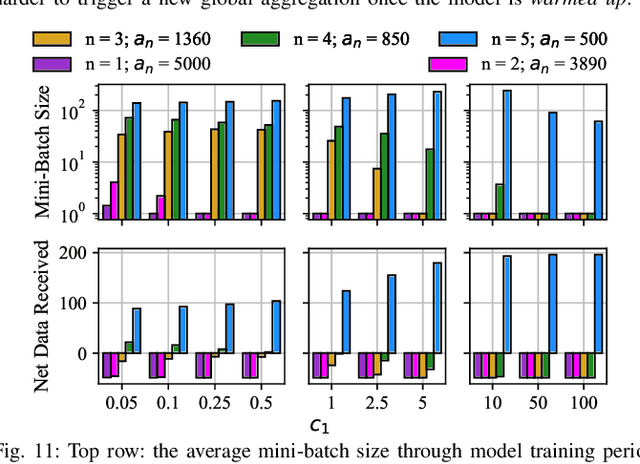
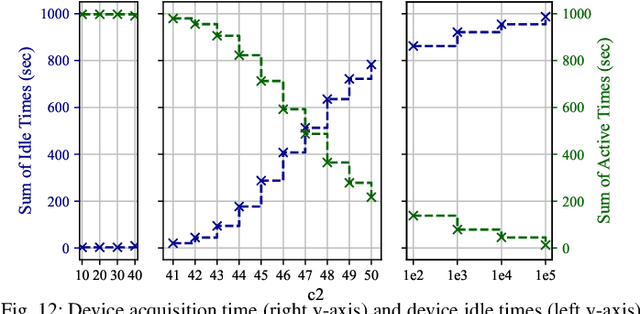
Federated learning (FedL) has emerged as a popular technique for distributing model training over a set of wireless devices, via iterative local updates (at devices) and global aggregations (at the server). In this paper, we develop parallel successive learning (PSL), which expands the FedL architecture along three dimensions: (i) Network, allowing decentralized cooperation among the devices via device-to-device (D2D) communications. (ii) Heterogeneity, interpreted at three levels: (ii-a) Learning: PSL considers heterogeneous number of stochastic gradient descent iterations with different mini-batch sizes at the devices; (ii-b) Data: PSL presumes a dynamic environment with data arrival and departure, where the distributions of local datasets evolve over time, captured via a new metric for model/concept drift. (ii-c) Device: PSL considers devices with different computation and communication capabilities. (iii) Proximity, where devices have different distances to each other and the access point. PSL considers the realistic scenario where global aggregations are conducted with idle times in-between them for resource efficiency improvements, and incorporates data dispersion and model dispersion with local model condensation into FedL. Our analysis sheds light on the notion of cold vs. warmed up models, and model inertia in distributed machine learning. We then propose network-aware dynamic model tracking to optimize the model learning vs. resource efficiency tradeoff, which we show is an NP-hard signomial programming problem. We finally solve this problem through proposing a general optimization solver. Our numerical results reveal new findings on the interdependencies between the idle times in-between the global aggregations, model/concept drift, and D2D cooperation configuration.
Unsupervised Long-Term Person Re-Identification with Clothes Change
Feb 08, 2022
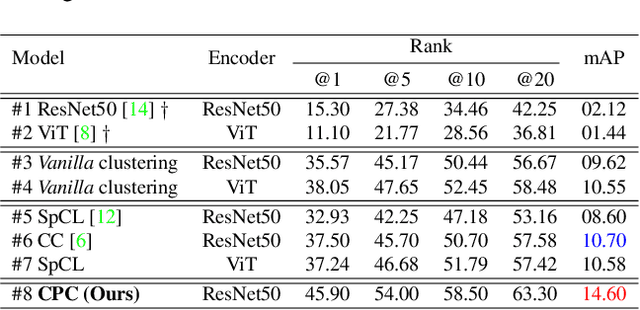
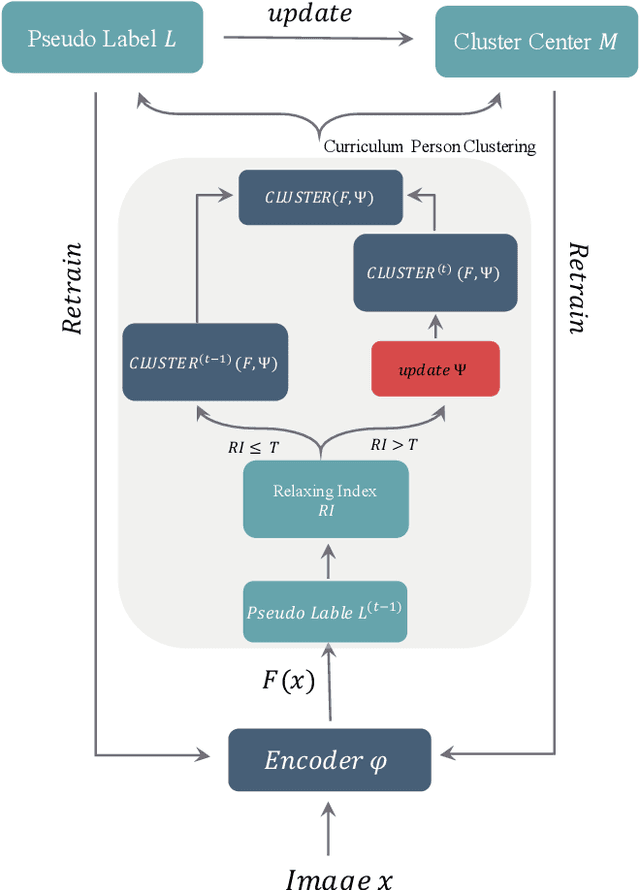
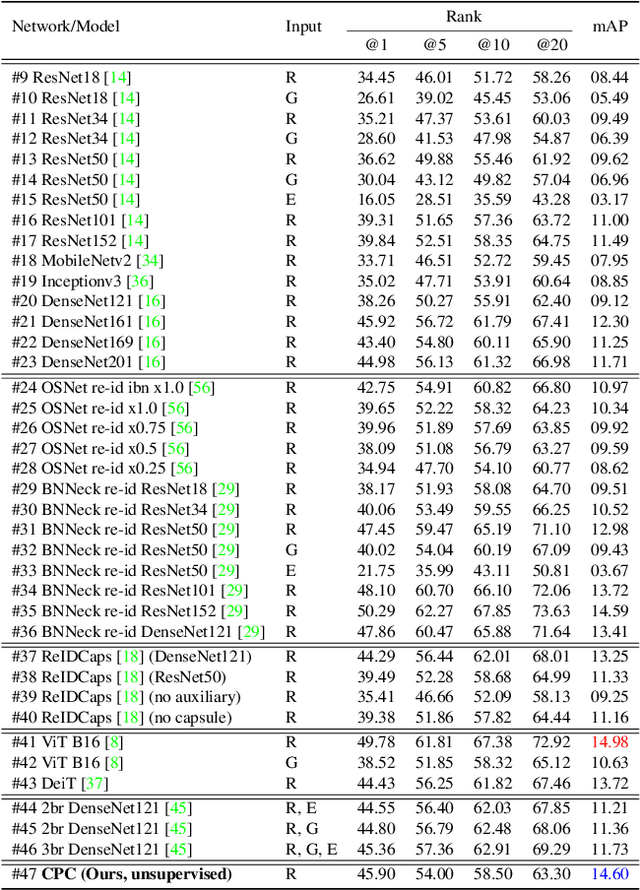
We investigate unsupervised person re-identification (Re-ID) with clothes change, a new challenging problem with more practical usability and scalability to real-world deployment. Most existing re-id methods artificially assume the clothes of every single person to be stationary across space and time. This condition is mostly valid for short-term re-id scenarios since an average person would often change the clothes even within a single day. To alleviate this assumption, several recent works have introduced the clothes change facet to re-id, with a focus on supervised learning person identity discriminative representation with invariance to clothes changes. Taking a step further towards this long-term re-id direction, we further eliminate the requirement of person identity labels, as they are significantly more expensive and more tedious to annotate in comparison to short-term person re-id datasets. Compared to conventional unsupervised short-term re-id, this new problem is drastically more challenging as different people may have similar clothes whilst the same person can wear multiple suites of clothes over different locations and times with very distinct appearance. To overcome such obstacles, we introduce a novel Curriculum Person Clustering (CPC) method that can adaptively regulate the unsupervised clustering criterion according to the clustering confidence. Experiments on three long-term person re-id datasets show that our CPC outperforms SOTA unsupervised re-id methods and even closely matches the supervised re-id models.
MaskBot: Real-time Robotic Projection Mapping with Head Motion Tracking
Nov 07, 2020
The projection mapping systems on the human face is limited by the latency and the movement of the users. The area of the projection is restricted by the position of the projectors and the cameras. We are introducing MaskBot, a real-time projection mapping system operated by a 6 Degrees of Freedom (DoF) collaborative robot. The collaborative robot locates the projector and camera in normal position to the face of the user to increase the projection area and to reduce the latency of the system. A webcam is used to detect the face and to sense the robot-user distance to modify the projection size and orientation. MaskBot projects different images on the face of the user, such as face modifications, make-up, and logos. In contrast to the existing methods, the presented system is the first that introduces a robotic projection mapping. One of the prospective applications is to acquire a dataset of adversarial images to challenge face detection DNN systems, such as Face ID.
LEAPMood: Light and Efficient Architecture to Predict Mood with Genetic Algorithm driven Hyperparameter Tuning
Feb 08, 2022
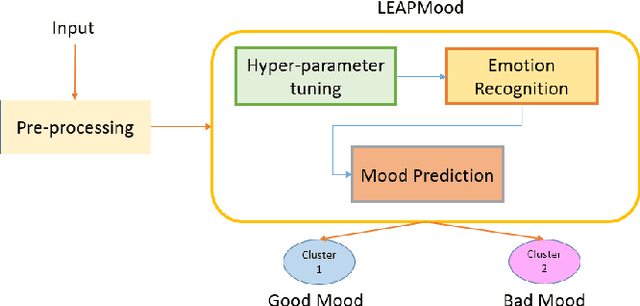
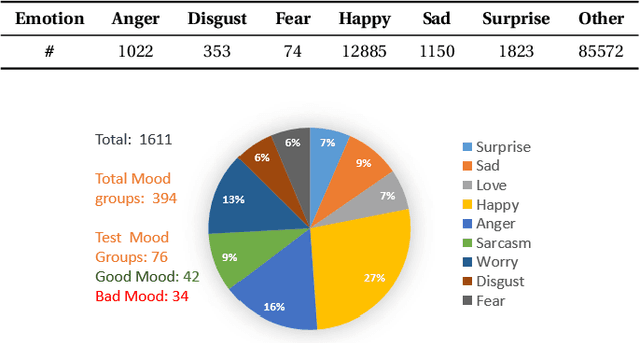
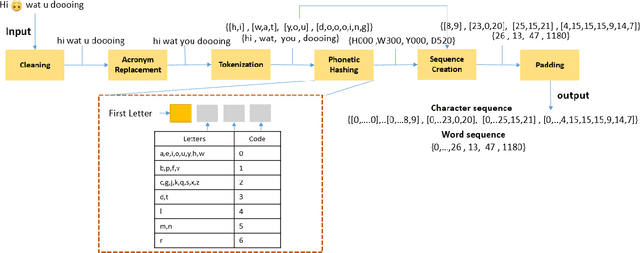
Accurate and automatic detection of mood serves as a building block for use cases like user profiling which in turn power applications such as advertising, recommendation systems, and many more. One primary source indicative of an individual's mood is textual data. While there has been extensive research on emotion recognition, the field of mood prediction has been barely explored. In addition, very little work is done in the area of on-device inferencing, which is highly important from the user privacy point of view. In this paper, we propose for the first time, an on-device deep learning approach for mood prediction from textual data, LEAPMood. We use a novel on-device deployment-focused objective function for hyperparameter tuning based on the Genetic Algorithm (GA) and optimize the parameters concerning both performance and size. LEAPMood consists of Emotion Recognition in Conversion (ERC) as the first building block followed by mood prediction using K-means clustering. We show that using a combination of character embedding, phonetic hashing, and attention along with Conditional Random Fields (CRF), results in a performance closely comparable to that of the current State-Of-the-Art with a significant reduction in model size (> 90%) for the task of ERC. We achieve a Micro F1 score of 62.05% with a memory footprint of a mere 1.67MB on the DailyDialog dataset. Furthermore, we curate a dataset for the task of mood prediction achieving a Macro F1-score of 72.12% with LEAPMood.
FSM: FBS Set Management, An energy efficient multi-drone 3D trajectory approach in cellular networks
Feb 08, 2022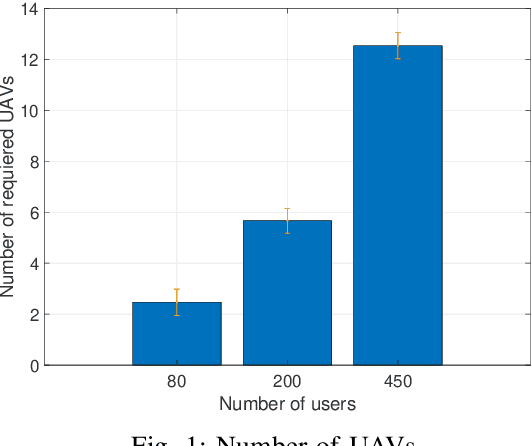
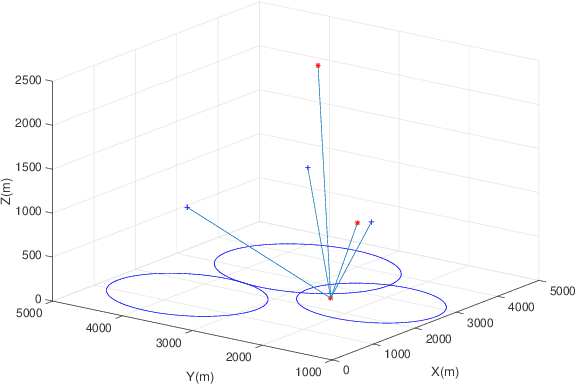
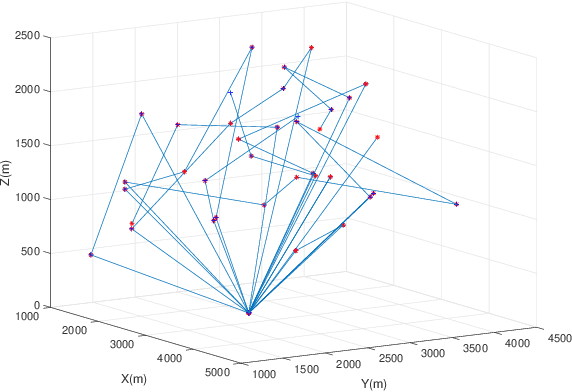
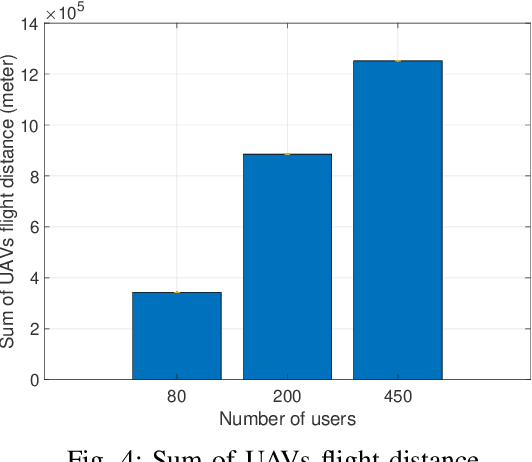
In this paper, we consider a cellular network demand in an urban area. We aim to cover users and serve their required data rate in a period of time using a 5G cellular network. The type of considered UAV in this scenario is The Scout B- 330 UAV helicopter which can fly up to 3 km height. In these scenarios, to find the most proper trajectory of UAVs, we first must find the best positions of UAVs in different snapshots. We consider orthogonal frequency reuse to avoid interference between UAVs in the network. We also consider the number of communication channels constraint in intra cellular network. To find the optimum position of UAVs in each snapshot. We consider Non-Line of Sight (NLoS) path loss in these scenarios and aim to cover all users in each snapshot. To find the optimum trajectory of UAVs, we propose a mathematical model based on transportation problem to minimize the total distance tracked by UAVs. In each step we solve the proposed mathematical model for transiting UAVs between two snapshots. We also consider that users can be placed in different altitudes an their positions follows the Poison Point Process distribution and their mobility follows the random way point. The UAVs battery and flight limitations are also considered. To tackle the energy problem we introduce the Drone Cell Off (DCO) approach to avoid losing energy in idle hover mode.
Functional Mixtures-of-Experts
Feb 04, 2022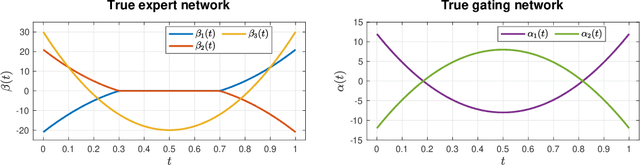
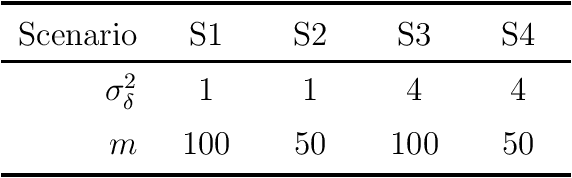
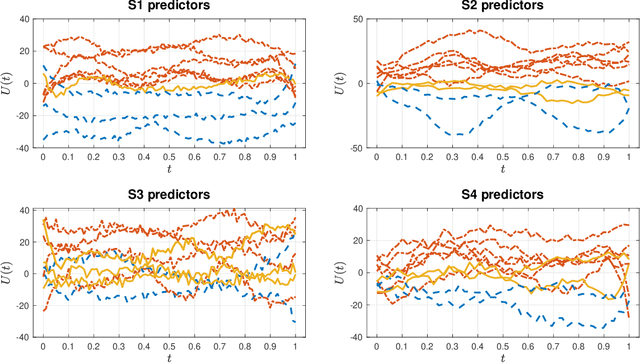
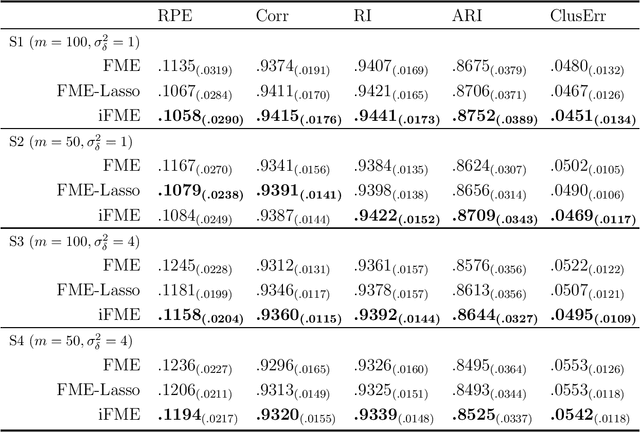
We consider the statistical analysis of heterogeneous data for clustering and prediction purposes, in situations where the observations include functions, typically time series. We extend the modeling with Mixtures-of-Experts (ME), as a framework of choice in modeling heterogeneity in data for prediction and clustering with vectorial observations, to this functional data analysis context. We first present a new family of functional ME (FME) models, in which the predictors are potentially noisy observations, from entire functions, and the data generating process of the pair predictor and the real response, is governed by a hidden discrete variable representing an unknown partition, leading to complex situations to which the standard ME framework is not adapted. Second, we provide sparse and interpretable functional representations of the FME models, thanks to Lasso-like regularizations, notably on the derivatives of the underlying functional parameters of the model, projected onto a set of continuous basis functions. We develop dedicated expectation--maximization algorithms for Lasso-like regularized maximum-likelihood parameter estimation strategies, to encourage sparse and interpretable solutions. The proposed FME models and the developed EM-Lasso algorithms are studied in simulated scenarios and in applications to two real data sets, and the obtained results demonstrate their performance in accurately capturing complex nonlinear relationships between the response and the functional predictor, and in clustering.