 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cause-effect inference through spectral independence in linear dynamical systems: theoretical foundations
Oct 29, 2021
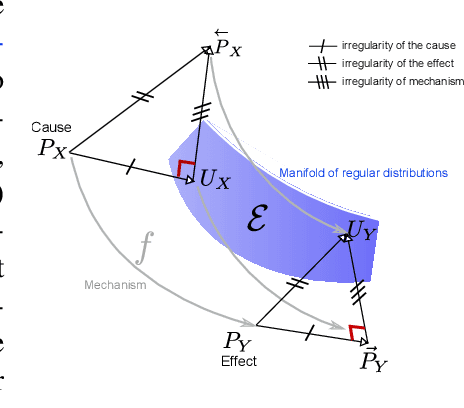
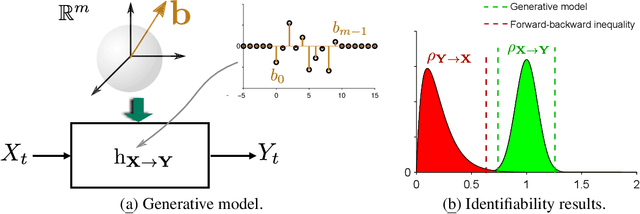
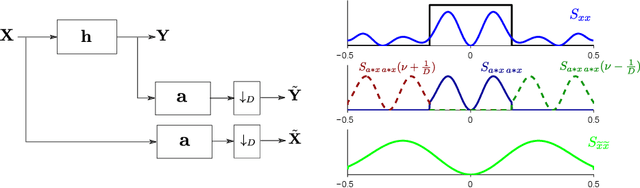
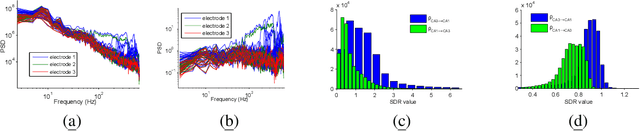
Distinguishing between cause and effect using time series observational data is a major challenge in many scientific fields. A new perspective has been provided based on the principle of Independence of Causal Mechanisms (ICM), leading to the Spectral Independence Criterion (SIC), postulating that the power spectral density (PSD) of the cause time series is uncorrelated with the squared modulus of the frequency response of the filter generating the effect. Since SIC rests on methods and assumptions in stark contrast with most causal discovery methods for time series, it raises questions regarding what theoretical grounds justify its use. In this paper, we provide answers covering several key aspects. After providing an information theoretic interpretation of SIC, we present an identifiability result that sheds light on the context for which this approach is expected to perform well. We further demonstrate the robustness of SIC to downsampling - an obstacle that can spoil Granger-based inference. Finally, an invariance perspective allows to explore the limitations of the spectral independence assumption and how to generalize it. Overall, these results support the postulate of Spectral Independence is a well grounded leading principle for causal inference based on empirical time series.
NeuronFair: Interpretable White-Box Fairness Testing through Biased Neuron Identification
Dec 25, 2021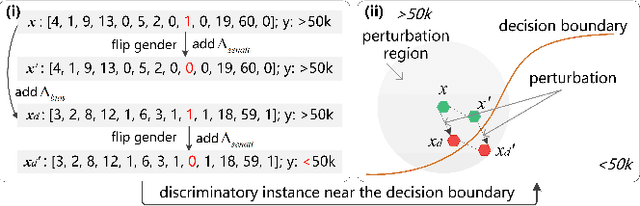
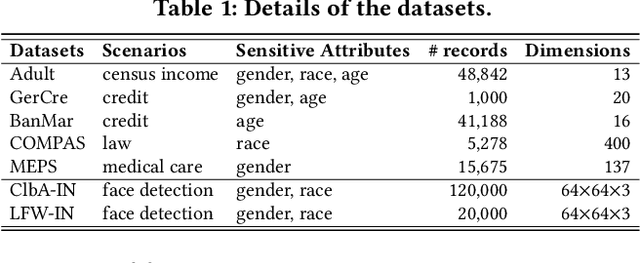
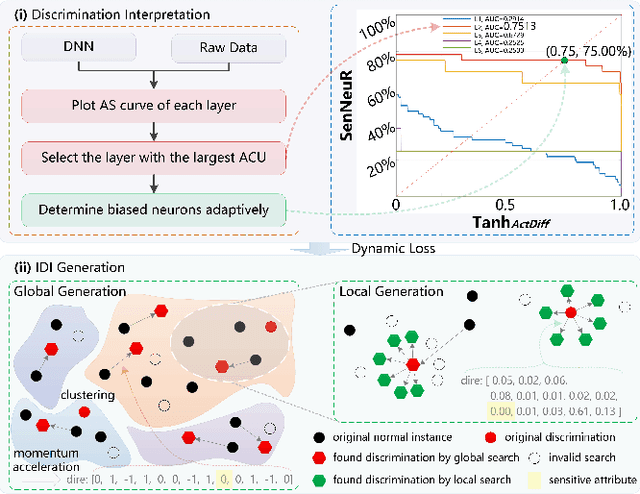
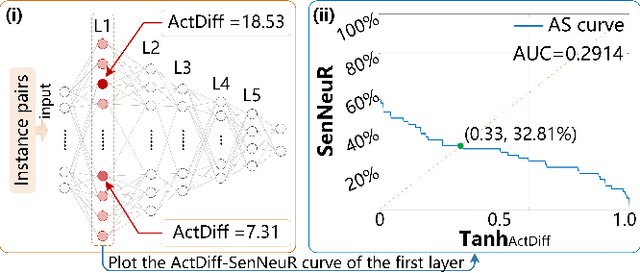
Deep neural networks (DNNs) have demonstrated their outperformance in various domains. However, it raises a social concern whether DNNs can produce reliable and fair decisions especially when they are applied to sensitive domains involving valuable resource allocation, such as education, loan, and employment. It is crucial to conduct fairness testing before DNNs are reliably deployed to such sensitive domains, i.e., generating as many instances as possible to uncover fairness violations. However, the existing testing methods are still limited from three aspects: interpretability, performance, and generalizability. To overcome the challenges, we propose NeuronFair, a new DNN fairness testing framework that differs from previous work in several key aspects: (1) interpretable - it quantitatively interprets DNNs' fairness violations for the biased decision; (2) effective - it uses the interpretation results to guide the generation of more diverse instances in less time; (3) generic - it can handle both structured and unstructured data. Extensive evaluations across 7 datasets and the corresponding DNNs demonstrate NeuronFair's superior performance. For instance, on structured datasets, it generates much more instances (~x5.84) and saves more time (with an average speedup of 534.56%) compared with the state-of-the-art methods. Besides, the instances of NeuronFair can also be leveraged to improve the fairness of the biased DNNs, which helps build more fair and trustworthy deep learning systems.
Machine Learning Based Forward Solver: An Automatic Framework in gprMax
Nov 23, 2021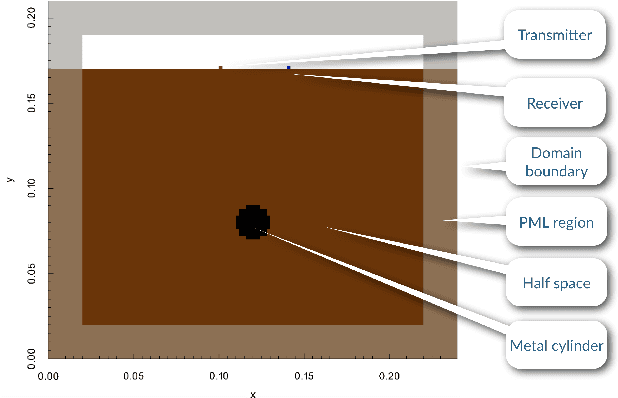
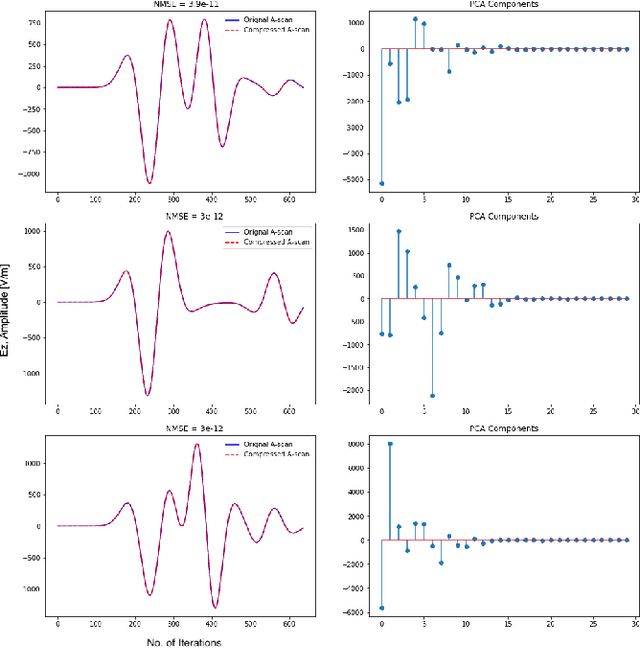
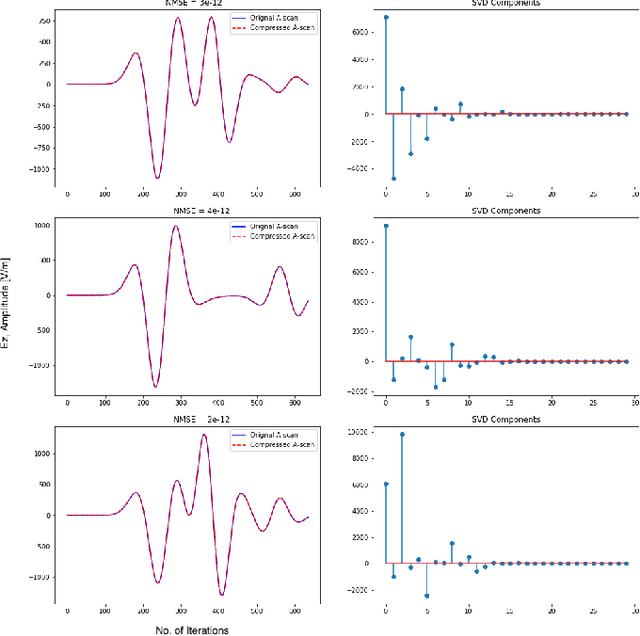
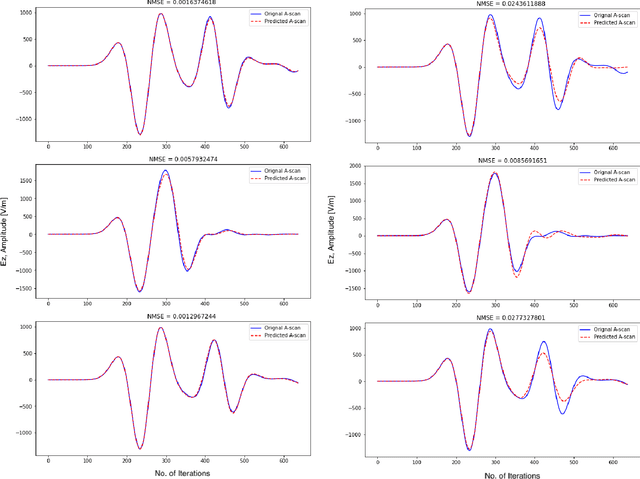
General full-wave electromagnetic solvers, such as those utilizing the finite-difference time-domain (FDTD) method, are computationally demanding for simulating practical GPR problems. We explore the performance of a near-real-time, forward modeling approach for GPR that is based on a machine learning (ML) architecture. To ease the process, we have developed a framework that is capable of generating these ML-based forward solvers automatically. The framework uses an innovative training method that combines a predictive dimensionality reduction technique and a large data set of modeled GPR responses from our FDTD simulation software, gprMax. The forward solver is parameterized for a specific GPR application, but the framework can be extended in a straightforward manner to different electromagnetic problems.
Online Active Learning with Dynamic Marginal Gain Thresholding
Jan 25, 2022
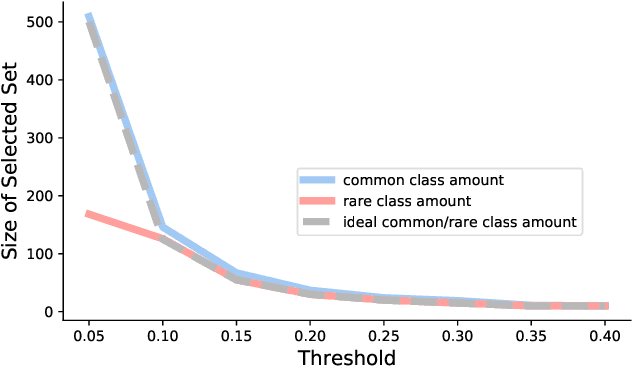
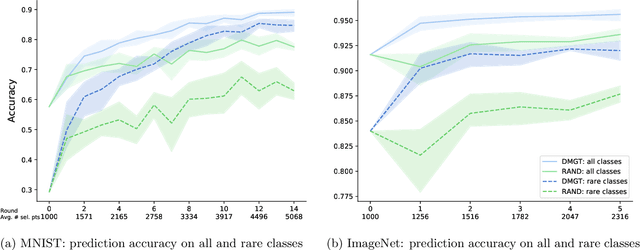
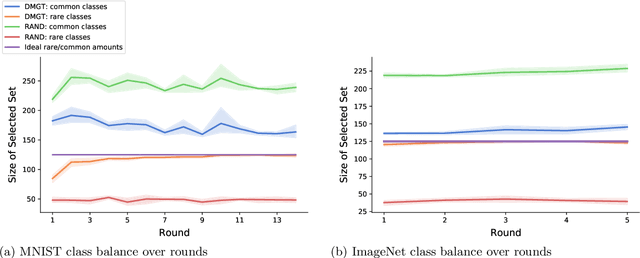
The blessing of ubiquitous data also comes with a curse: the communication, storage, and labeling of massive, mostly redundant datasets. In our work, we seek to solve the problem at its source, collecting only valuable data and throwing out the rest, via active learning. We propose an online algorithm which, given any stream of data, any assessment of its value, and any formulation of its selection cost, extracts the most valuable subset of the stream up to a constant factor while using minimal memory. Notably, our analysis also holds for the federated setting, in which multiple agents select online from individual data streams without coordination and with potentially very different appraisals of cost. One particularly important use case is selecting and labeling training sets from unlabeled collections of data that maximize the test-time performance of a given classifier. In prediction tasks on ImageNet and MNIST, we show that our selection method outperforms random selection by up to 5-20%.
Topological Machine Learning for Multivariate Time Series
Nov 27, 2019


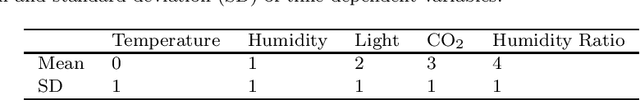
We develop a framework for analyzing multivariate time series using topological data analysis (TDA) methods. The proposed methodology involves converting the multivariate time series to point cloud data, calculating Wasserstein distances between the persistence diagrams and using the $k$-nearest neighbors algorithm ($k$-NN) for supervised machine learning. Two methods (symmetry-breaking and anchor points) are also introduced to enable TDA to better analyze data with heterogeneous features that are sensitive to translation, rotation, or choice of coordinates. We apply our methods to room occupancy detection based on 5 time-dependent variables (temperature, humidity, light, CO2 and humidity ratio). Experimental results show that topological methods are effective in predicting room occupancy during a time window.
Optimal Clustering with Bandit Feedback
Feb 09, 2022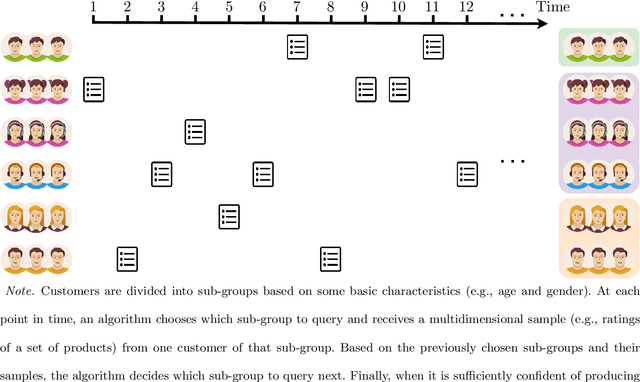
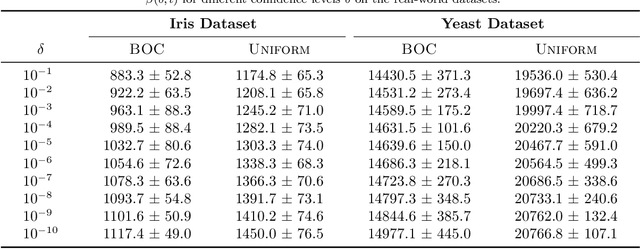
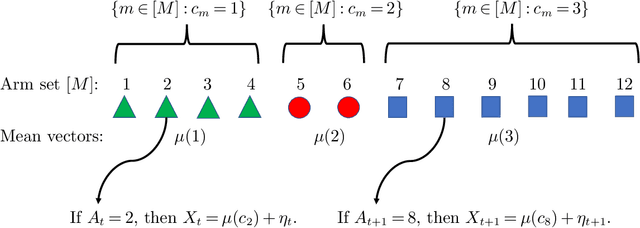
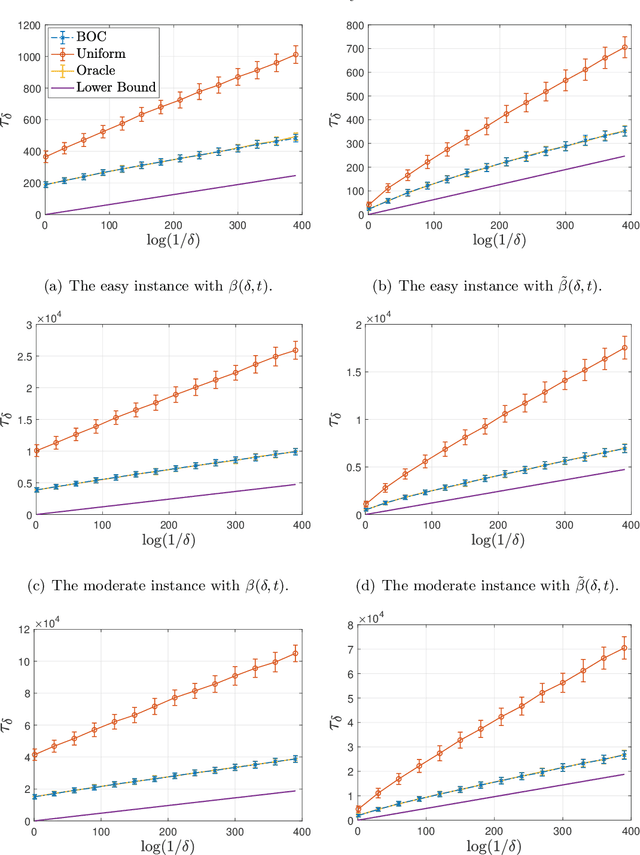
This paper considers the problem of online clustering with bandit feedback. A set of arms (or items) can be partitioned into various groups that are unknown. Within each group, the observations associated to each of the arms follow the same distribution with the same mean vector. At each time step, the agent queries or pulls an arm and obtains an independent observation from the distribution it is associated to. Subsequent pulls depend on previous ones as well as the previously obtained samples. The agent's task is to uncover the underlying partition of the arms with the least number of arm pulls and with a probability of error not exceeding a prescribed constant $\delta$. The problem proposed finds numerous applications from clustering of variants of viruses to online market segmentation. We present an instance-dependent information-theoretic lower bound on the expected sample complexity for this task, and design a computationally efficient and asymptotically optimal algorithm, namely Bandit Online Clustering (BOC). The algorithm includes a novel stopping rule for adaptive sequential testing that circumvents the need to exactly solve any NP-hard weighted clustering problem as its subroutines. We show through extensive simulations on synthetic and real-world datasets that BOC's performance matches the lower bound asymptotically, and significantly outperforms a non-adaptive baseline algorithm.
Towards a consistent interpretation of AIOps models
Feb 04, 2022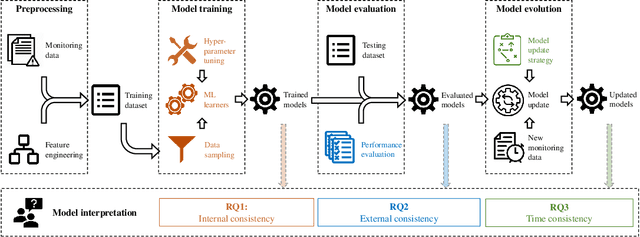


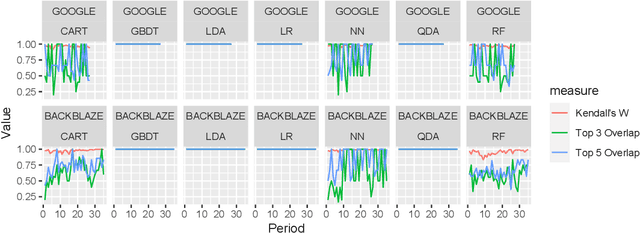
Artificial Intelligence for IT Operations (AIOps) has been adopted in organizations in various tasks, including interpreting models to identify indicators of service failures. To avoid misleading practitioners, AIOps model interpretations should be consistent (i.e., different AIOps models on the same task agree with one another on feature importance). However, many AIOps studies violate established practices in the machine learning community when deriving interpretations, such as interpreting models with suboptimal performance, though the impact of such violations on the interpretation consistency has not been studied. In this paper, we investigate the consistency of AIOps model interpretation along three dimensions: internal consistency, external consistency, and time consistency. We conduct a case study on two AIOps tasks: predicting Google cluster job failures, and Backblaze hard drive failures. We find that the randomness from learners, hyperparameter tuning, and data sampling should be controlled to generate consistent interpretations. AIOps models with AUCs greater than 0.75 yield more consistent interpretation compared to low-performing models. Finally, AIOps models that are constructed with the Sliding Window or Full History approaches have the most consistent interpretation with the trends presented in the entire datasets. Our study provides valuable guidelines for practitioners to derive consistent AIOps model interpretation.
Iterative Self Knowledge Distillation -- From Pothole Classification to Fine-Grained and COVID Recognition
Feb 04, 2022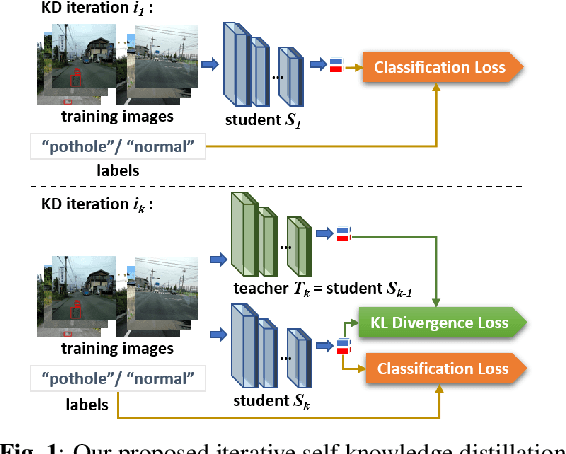
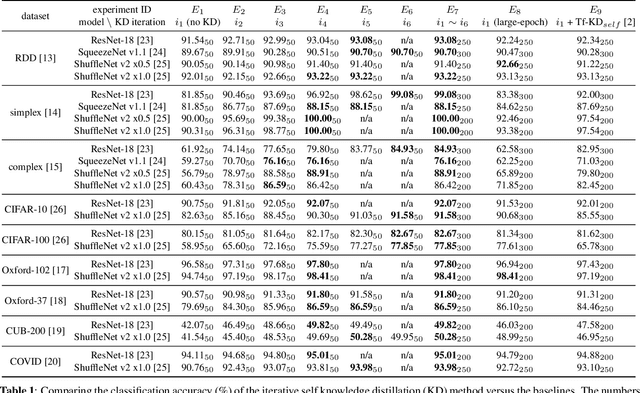
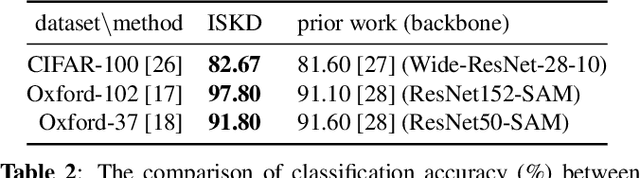
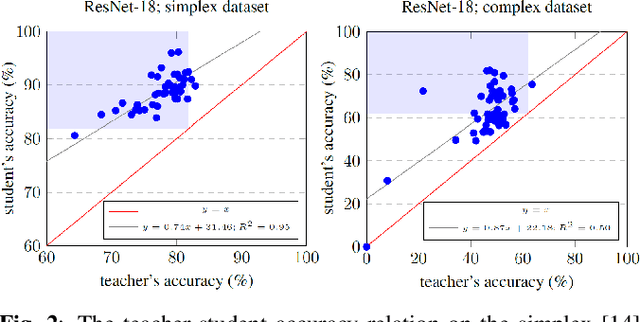
Pothole classification has become an important task for road inspection vehicles to save drivers from potential car accidents and repair bills. Given the limited computational power and fixed number of training epochs, we propose iterative self knowledge distillation (ISKD) to train lightweight pothole classifiers. Designed to improve both the teacher and student models over time in knowledge distillation, ISKD outperforms the state-of-the-art self knowledge distillation method on three pothole classification datasets across four lightweight network architectures, which supports that self knowledge distillation should be done iteratively instead of just once. The accuracy relation between the teacher and student models shows that the student model can still benefit from a moderately trained teacher model. Implying that better teacher models generally produce better student models, our results justify the design of ISKD. In addition to pothole classification, we also demonstrate the efficacy of ISKD on six additional datasets associated with generic classification, fine-grained classification, and medical imaging application, which supports that ISKD can serve as a general-purpose performance booster without the need of a given teacher model and extra trainable parameters.
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 20, 2021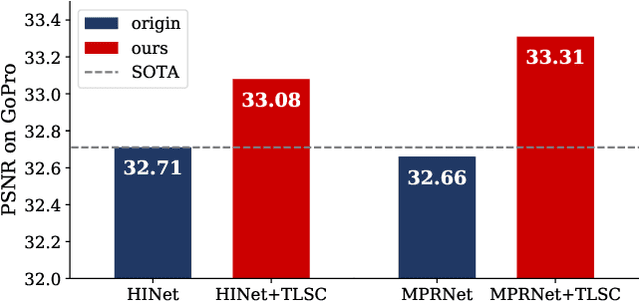
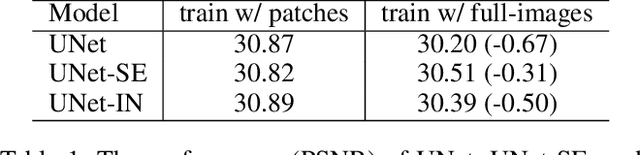
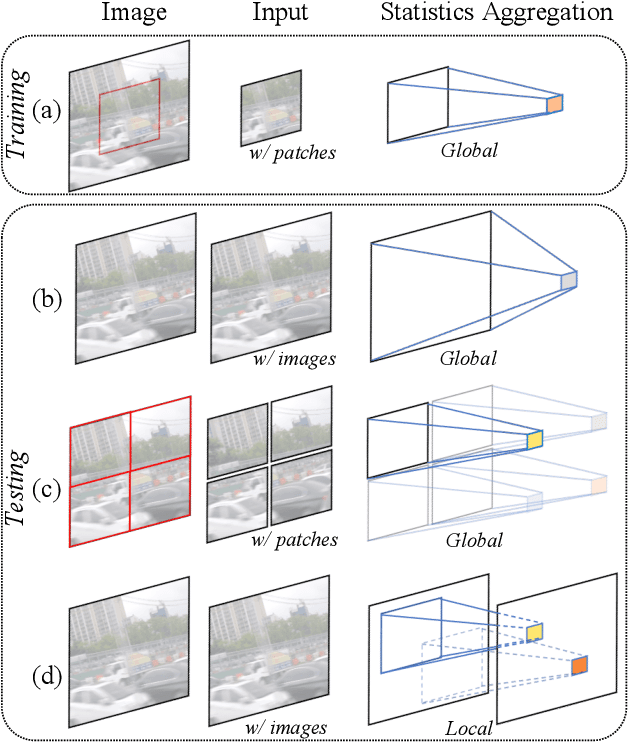
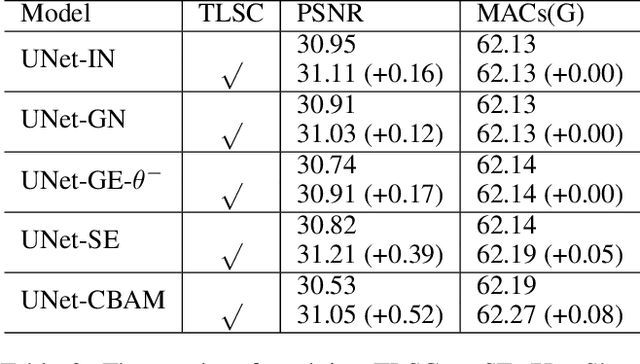
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
Attention-Based Vandalism Detection in OpenStreetMap
Jan 25, 2022
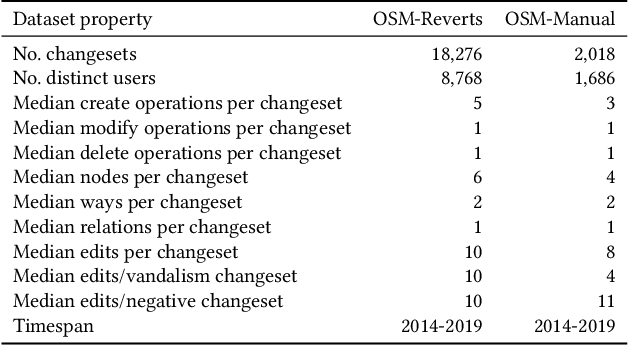
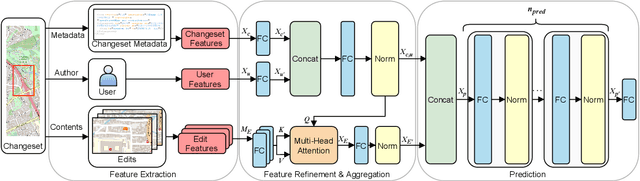
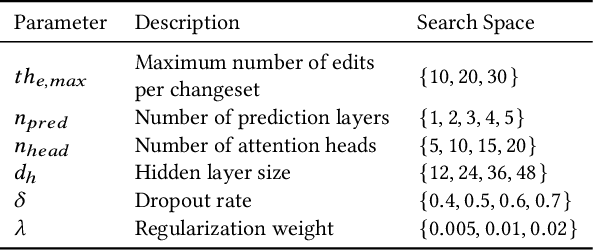
OpenStreetMap (OSM), a collaborative, crowdsourced Web map, is a unique source of openly available worldwide map data, increasingly adopted in Web applications. Vandalism detection is a critical task to support trust and maintain OSM transparency. This task is remarkably challenging due to the large scale of the dataset, the sheer number of contributors, various vandalism forms, and the lack of annotated data. This paper presents Ovid - a novel attention-based method for vandalism detection in OSM. Ovid relies on a novel neural architecture that adopts a multi-head attention mechanism to summarize information indicating vandalism from OSM changesets effectively. To facilitate automated vandalism detection, we introduce a set of original features that capture changeset, user, and edit information. Furthermore, we extract a dataset of real-world vandalism incidents from the OSM edit history for the first time and provide this dataset as open data. Our evaluation conducted on real-world vandalism data demonstrates the effectiveness of Ovid.