 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Molecular Contrastive Learning via Faulty Negative Mitigation and Decomposed Fragment Contrast
Feb 18, 2022
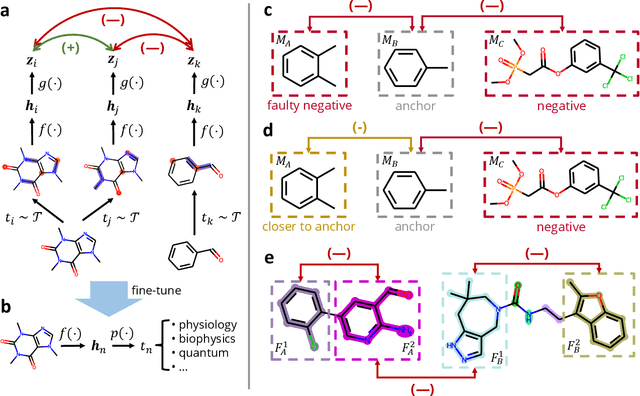
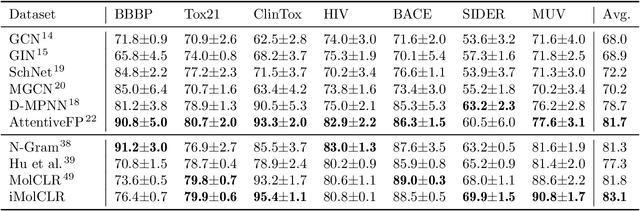
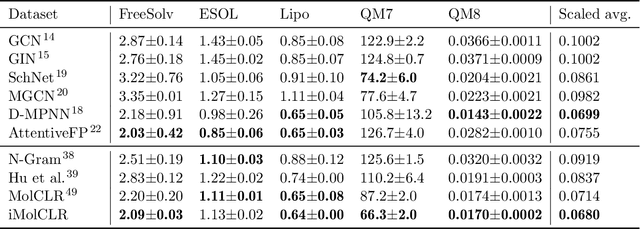
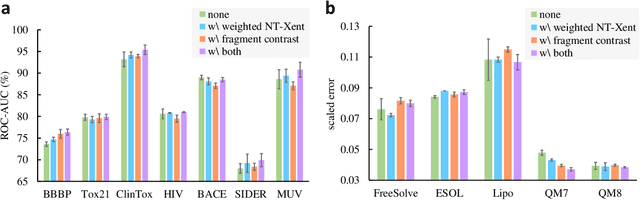
Deep learning has been a prevalence in computational chemistry and widely implemented in molecule property predictions. Recently, self-supervised learning (SSL), especially contrastive learning (CL), gathers growing attention for the potential to learn molecular representations that generalize to the gigantic chemical space. Unlike supervised learning, SSL can directly leverage large unlabeled data, which greatly reduces the effort to acquire molecular property labels through costly and time-consuming simulations or experiments. However, most molecular SSL methods borrow the insights from the machine learning community but neglect the unique cheminformatics (e.g., molecular fingerprints) and multi-level graphical structures (e.g., functional groups) of molecules. In this work, we propose iMolCLR: improvement of Molecular Contrastive Learning of Representations with graph neural networks (GNNs) in two aspects, (1) mitigating faulty negative contrastive instances via considering cheminformatics similarities between molecule pairs; (2) fragment-level contrasting between intra- and inter-molecule substructures decomposed from molecules. Experiments have shown that the proposed strategies significantly improve the performance of GNN models on various challenging molecular property predictions. In comparison to the previous CL framework, iMolCLR demonstrates an averaged 1.3% improvement of ROC-AUC on 7 classification benchmarks and an averaged 4.8% decrease of the error on 5 regression benchmarks. On most benchmarks, the generic GNN pre-trained by iMolCLR rivals or even surpasses supervised learning models with sophisticated architecture designs and engineered features. Further investigations demonstrate that representations learned through iMolCLR intrinsically embed scaffolds and functional groups that can reason molecule similarities.
An Object Aware Hybrid U-Net for Breast Tumour Annotation
Feb 22, 2022In the clinical settings, during digital examination of histopathological slides, the pathologist annotate the slides by marking the rough boundary around the suspected tumour region. The marking or annotation is generally represented as a polygonal boundary that covers the extent of the tumour in the slide. These polygonal markings are difficult to imitate through CAD techniques since the tumour regions are heterogeneous and hence segmenting them would require exhaustive pixel wise ground truth annotation. Therefore, for CAD analysis, the ground truths are generally annotated by pathologist explicitly for research purposes. However, this kind of annotation which is generally required for semantic or instance segmentation is time consuming and tedious. In this proposed work, therefore, we have tried to imitate pathologist like annotation by segmenting tumour extents by polygonal boundaries. For polygon like annotation or segmentation, we have used Active Contours whose vertices or snake points move towards the boundary of the object of interest to find the region of minimum energy. To penalize the Active Contour we used modified U-Net architecture for learning penalization values. The proposed hybrid deep learning model fuses the modern deep learning segmentation algorithm with traditional Active Contours segmentation technique. The model is tested against both state-of-the-art semantic segmentation and hybrid models for performance evaluation against contemporary work. The results obtained show that the pathologist like annotation could be achieved by developing such hybrid models that integrate the domain knowledge through classical segmentation methods like Active Contours and global knowledge through semantic segmentation deep learning models.
Semantics through Time: Semi-supervised Segmentation of Aerial Videos with Iterative Label Propagation
Oct 02, 2020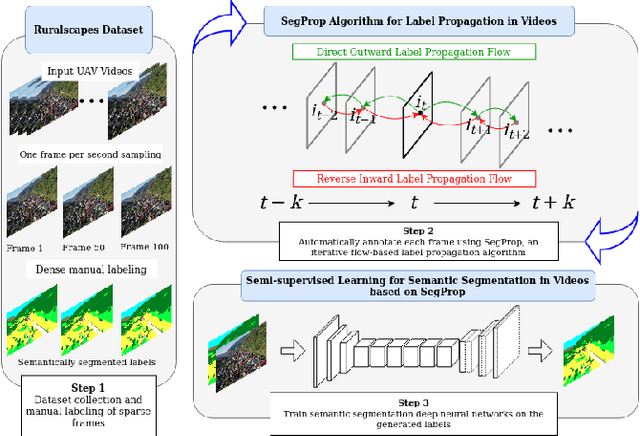
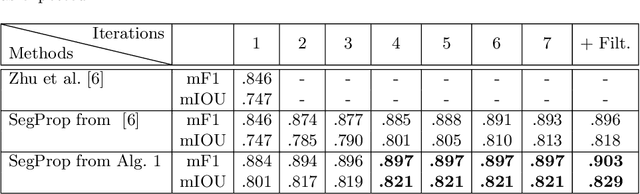
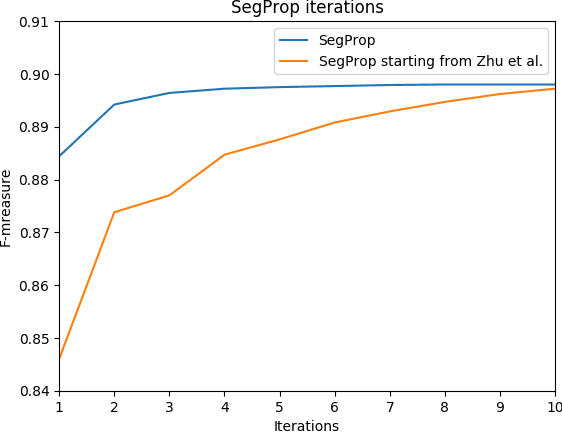

Semantic segmentation is a crucial task for robot navigation and safety. However, current supervised methods require a large amount of pixelwise annotations to yield accurate results. Labeling is a tedious and time consuming process that has hampered progress in low altitude UAV applications. This paper makes an important step towards automatic annotation by introducing SegProp, a novel iterative flow-based method, with a direct connection to spectral clustering in space and time, to propagate the semantic labels to frames that lack human annotations. The labels are further used in semi-supervised learning scenarios. Motivated by the lack of a large video aerial dataset, we also introduce Ruralscapes, a new dataset with high resolution (4K) images and manually-annotated dense labels every 50 frames - the largest of its kind, to the best of our knowledge. Our novel SegProp automatically annotates the remaining unlabeled 98% of frames with an accuracy exceeding 90% (F-measure), significantly outperforming other state-of-the-art label propagation methods. Moreover, when integrating other methods as modules inside SegProp's iterative label propagation loop, we achieve a significant boost over the baseline labels. Finally, we test SegProp in a full semi-supervised setting: we train several state-of-the-art deep neural networks on the SegProp-automatically-labeled training frames and test them on completely novel videos. We convincingly demonstrate, every time, a significant improvement over the supervised scenario.
Predictive Scheduling of Collaborative Mobile Robots for Improved Crop-transport Logistics of Manually Harvested Crops
Nov 18, 2021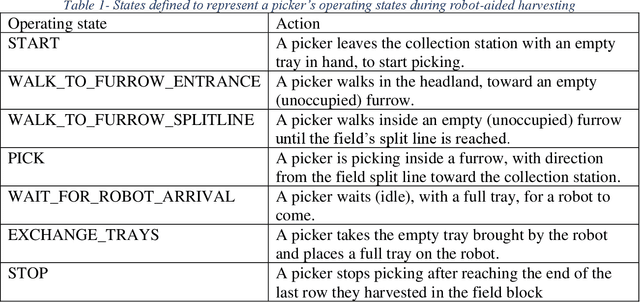

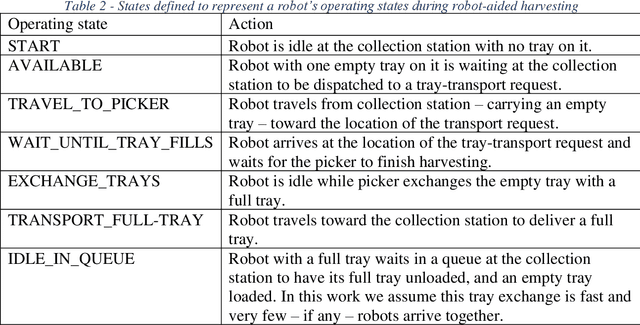
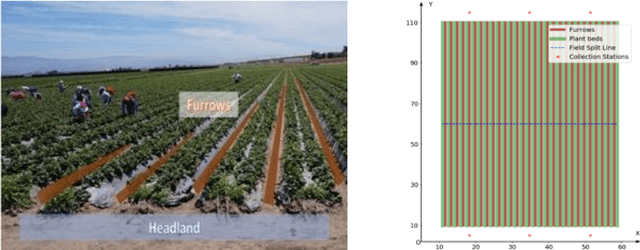
Mechanizing the manual harvesting of fresh market fruits constitutes one of the biggest challenges to the sustainability of the fruit industry. During manual harvesting of some fresh-market crops like strawberries and table grapes, pickers spend significant amounts of time walking to carry full trays to a collection station at the edge of the field. A step toward increasing harvest automation for such crops is to deploy harvest-aid collaborative robots (co-bots) that transport the empty and full trays, thus increasing harvest efficiency by reducing pickers' non-productive walking times. This work presents the development of a co-robotic harvest-aid system and its evaluation during commercial strawberry harvesting. At the heart of the system lies a predictive stochastic scheduling algorithm that minimizes the expected non-picking time, thus maximizing the harvest efficiency. During the evaluation experiments, the co-robots improved the mean harvesting efficiency by around 10% and reduced the mean non-productive time by 60%, when the robot-to-picker ratio was 1:3. The concepts developed in this work can be applied to robotic harvest-aids for other manually harvested crops that involve walking for crop transportation.
Automated generation of large-scale distribution grid models based on open data and open source software using an optimization approach
Feb 28, 2022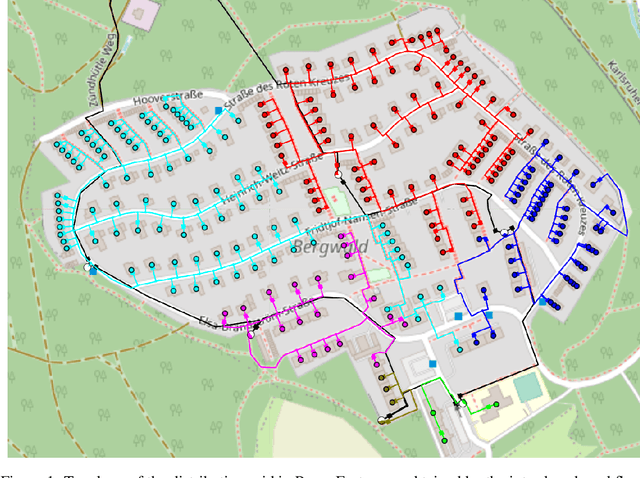
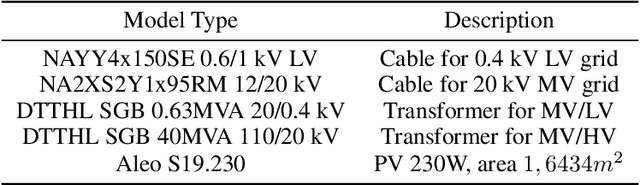
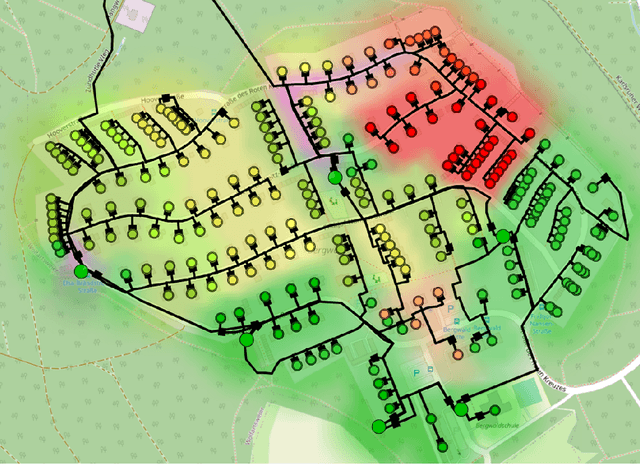
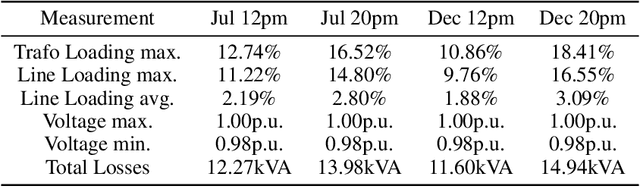
The increasing share of renewable energy sources on distribution grid level as well as the emerging active role of prosumers lead to both higher distribution grid utilization, and at the same time greater unpredictability of energy generation and consumption. This poses major problems for grid operators in view of, e.g., voltage stability and line (over)loading. Thus, detailed and comprehensive simulation models are essential for planning future distribution grid expansion in view of the expected strong electrification of society. In this context, the contribution of the present paper is a new, more refined method for automated creation of large-scale detailed distribution grid models based solely on publicly available GIS and statistical data. Utilizing the street layouts in Open Street Maps as potential cable routes, a graph representation is created and complemented by residential units that are extracted from the same data source. This graph structure is adjusted to match electrical low-voltage grid topology by solving a variation of the minimum cost flow linear optimization problem with provided data on secondary substations. In a final step, the generated grid representation is transferred to a DIgSILENT PowerFactory model with photovoltaic systems. The presented workflow uses open source software and is fully automated and scalable that allows the generation of ready-to-use distribution grid simulation models for given 20kV substation locations and additional data on residential unit properties for improved results. The performance of the developed method with respect to grid utilization is presented for a selected suburban residential area with power flow simulations for eight scenarios including current residential PV installation and a future scenario with full PV expansion. Furthermore, the suitability of the generated models for quasi-dynamic simulations is shown.
Diffractive deep neural network based adaptive optics scheme for vortex beam in oceanic turbulence
Feb 06, 2022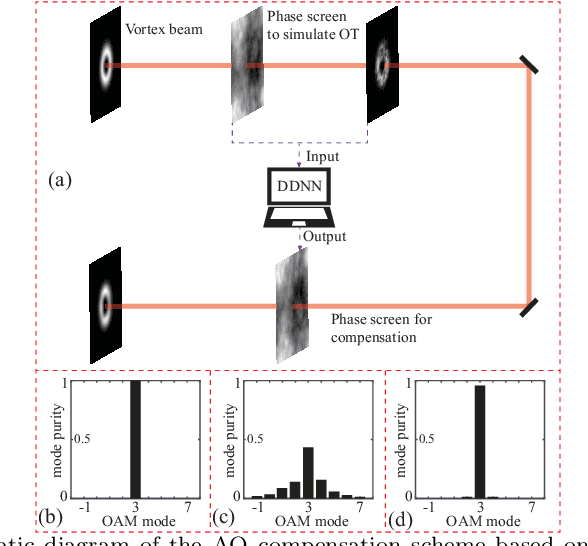

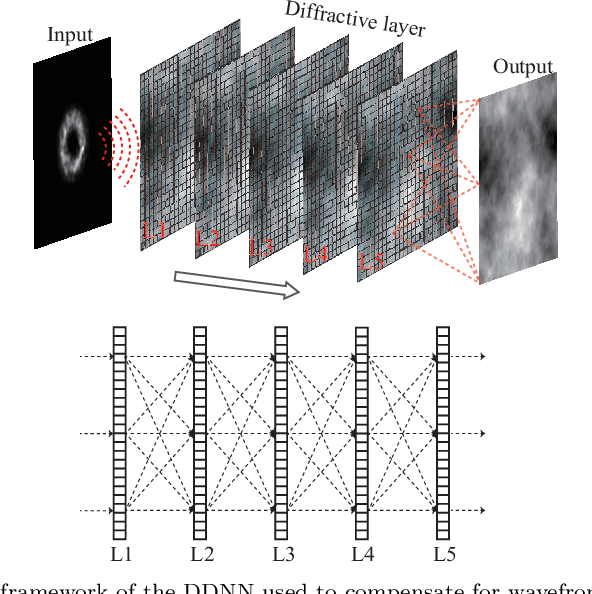
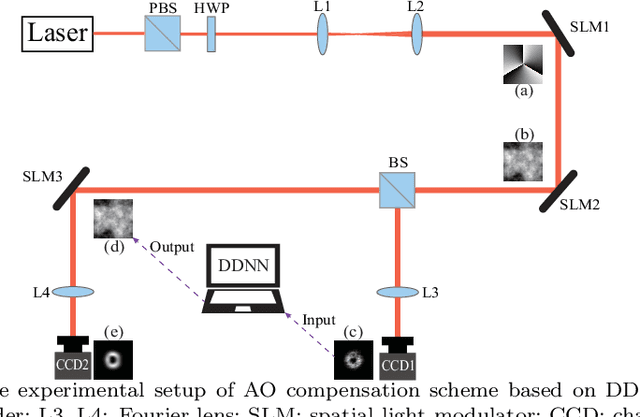
Vortex beam carrying orbital angular momentum (OAM) is disturbed by oceanic turbulence (OT) when propagating in underwater wireless optical communication (UWOC) system. Adaptive optics (AO) is used to compensate for distortion and improve the performance of the UWOC system. In this work, we propose a diffractive deep neural network (DDNN) based AO scheme to compensate for the distortion caused by OT, where the DDNN is trained to obtain the mapping between the distortion intensity distribution of the vortex beam and its corresponding phase screen representating OT. The intensity pattern of the distorted vortex beam obtained in the experiment is input to the DDNN model, and the predicted phase screen can be used to compensate the distortion in real time. The experiment results show that the proposed scheme can extract quickly the characteristics of the intensity pattern of the distorted vortex beam, and output accurately the predicted phase screen. The mode purity of the compensated vortex beam is significantly improved, even with a strong OT. Our scheme may provide a new avenue for AO techniques, and is expected to promote the communication quality of UWOC system.
Online Learning of Trellis Diagram Using Neural Network for Robust Detection and Decoding
Feb 22, 2022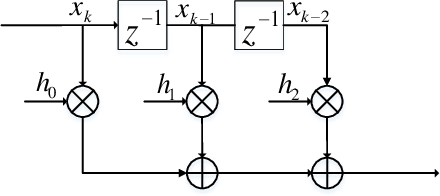
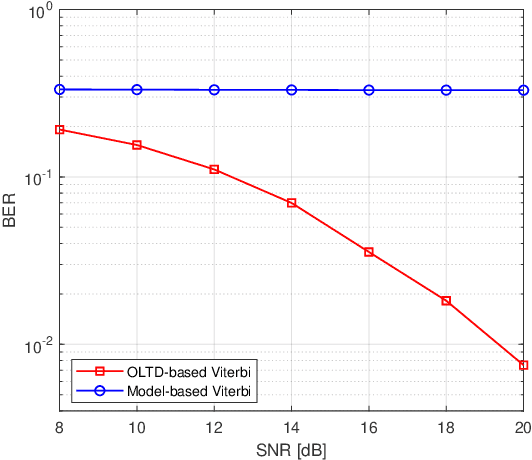
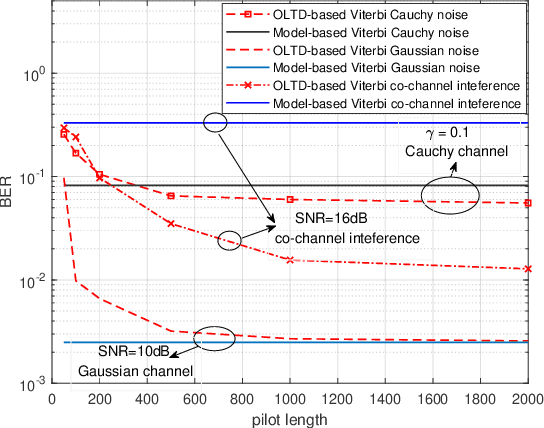
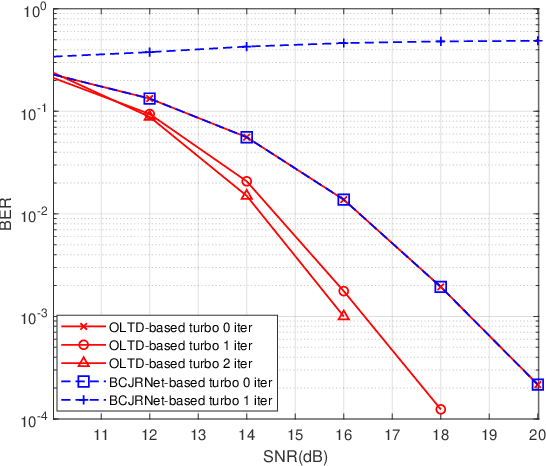
This paper studies machine learning-assisted maximum likelihood (ML) and maximum a posteriori (MAP) receivers for a communication system with memory, which can be modelled by a trellis diagram. The prerequisite of the ML/MAP receiver is to obtain the likelihood of the received samples under different state transitions of the trellis diagram, which relies on the channel state information (CSI) and the distribution of the channel noise. We propose to learn the trellis diagram real-time using an artificial neural network (ANN) trained by a pilot sequence. This approach, termed as the online learning of trellis diagram (OLTD), requires neither the CSI nor statistics of the noise, and can be incorporated into the classic Viterbi and the BCJR algorithm. %Compared with the state-of-the-art ViterbiNet and BCJRNet algorithms in the literature, it It is shown to significantly outperform the model-based methods in non-Gaussian channels. It requires much less training overhead than the state-of-the-art methods, and hence is more feasible for real implementations. As an illustrative example, the OLTD-based BCJR is applied to a Bluetooth low energy (BLE) receiver trained only by a 256-sample pilot sequence. Moreover, the OLTD-based BCJR can accommodate for turbo equalization, while the state-of-the-art BCJRNet/ViterbiNet cannot. As an interesting by-product, we propose an enhancement to the BLE standard by introducing a bit interleaver to its physical layer; the resultant improvement of the receiver sensitivity can make it a better fit for some Internet of Things (IoT) communications.
Trying to Outrun Causality with Machine Learning: Limitations of Model Explainability Techniques for Identifying Predictive Variables
Feb 25, 2022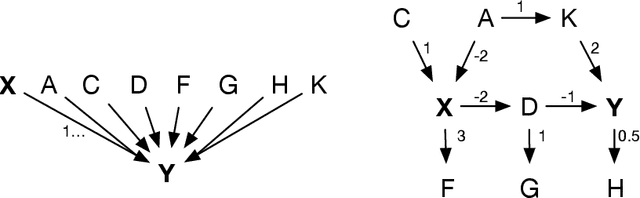
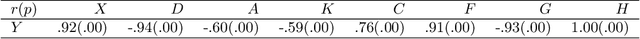
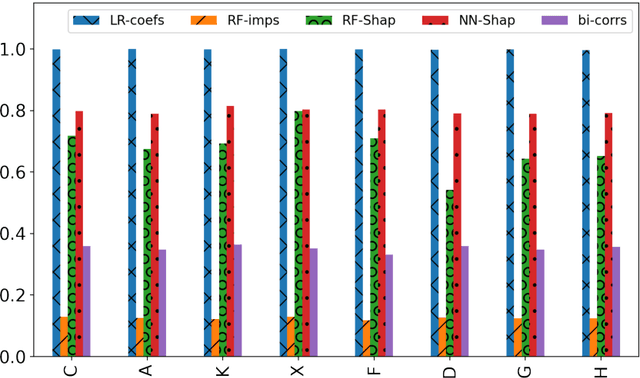
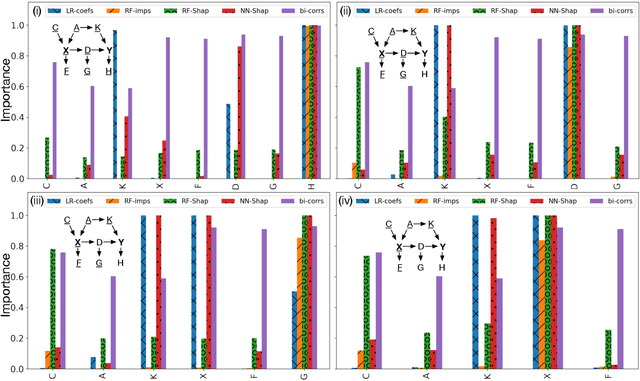
Machine Learning explainability techniques have been proposed as a means of `explaining' or interrogating a model in order to understand why a particular decision or prediction has been made. Such an ability is especially important at a time when machine learning is being used to automate decision processes which concern sensitive factors and legal outcomes. Indeed, it is even a requirement according to EU law. Furthermore, researchers concerned with imposing overly restrictive functional form (e.g., as would be the case in a linear regression) may be motivated to use machine learning algorithms in conjunction with explainability techniques, as part of exploratory research, with the goal of identifying important variables which are associated with an outcome of interest. For example, epidemiologists might be interested in identifying `risk factors' - i.e. factors which affect recovery from disease - by using random forests and assessing variable relevance using importance measures. However, and as we demonstrate, machine learning algorithms are not as flexible as they might seem, and are instead incredibly sensitive to the underling causal structure in the data. The consequences of this are that predictors which are, in fact, critical to a causal system and highly correlated with the outcome, may nonetheless be deemed by explainability techniques to be unrelated/unimportant/unpredictive of the outcome. Rather than this being a limitation of explainability techniques per se, we show that it is rather a consequence of the mathematical implications of regression, and the interaction of these implications with the associated conditional independencies of the underlying causal structure. We provide some alternative recommendations for researchers wanting to explore the data for important variables.
Time your hedge with Deep Reinforcement Learning
Sep 16, 2020
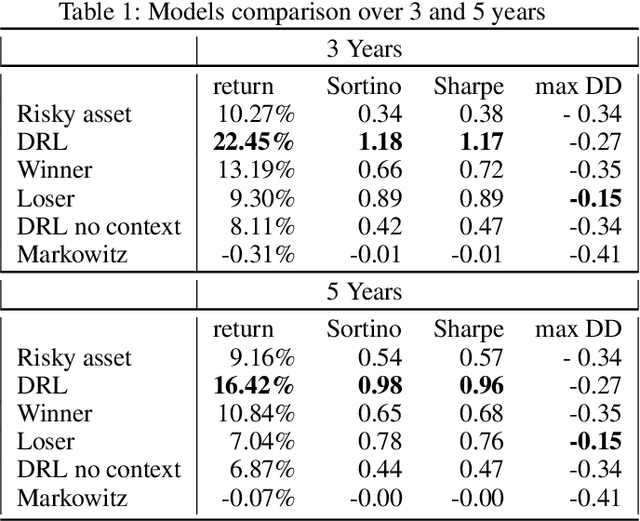
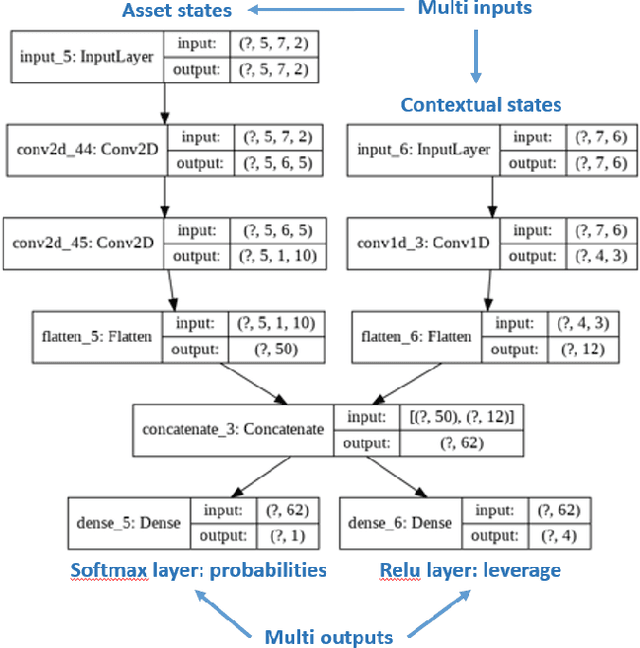
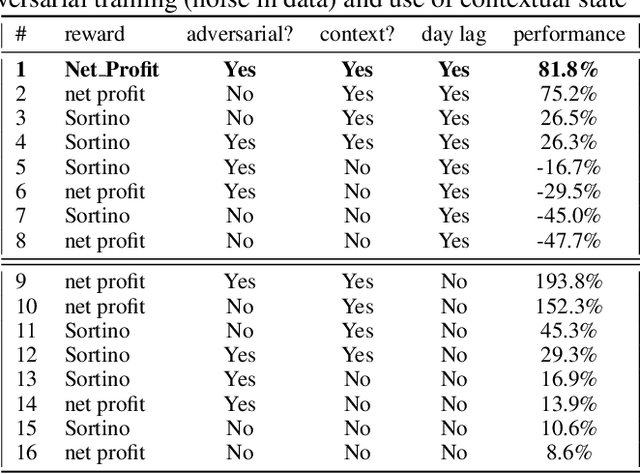
Can an asset manager plan the optimal timing for her/his hedging strategies given market conditions? The standard approach based on Markowitz or other more or less sophisticated financial rules aims to find the best portfolio allocation thanks to forecasted expected returns and risk but fails to fully relate market conditions to hedging strategies decision. In contrast, Deep Reinforcement Learning (DRL) can tackle this challenge by creating a dynamic dependency between market information and hedging strategies allocation decisions. In this paper, we present a realistic and augmented DRL framework that: (i) uses additional contextual information to decide an action, (ii) has a one period lag between observations and actions to account for one day lag turnover of common asset managers to rebalance their hedge, (iii) is fully tested in terms of stability and robustness thanks to a repetitive train test method called anchored walk forward training, similar in spirit to k fold cross validation for time series and (iv) allows managing leverage of our hedging strategy. Our experiment for an augmented asset manager interested in sizing and timing his hedges shows that our approach achieves superior returns and lower risk.
Machine Learning for Genomic Data
Nov 15, 2021
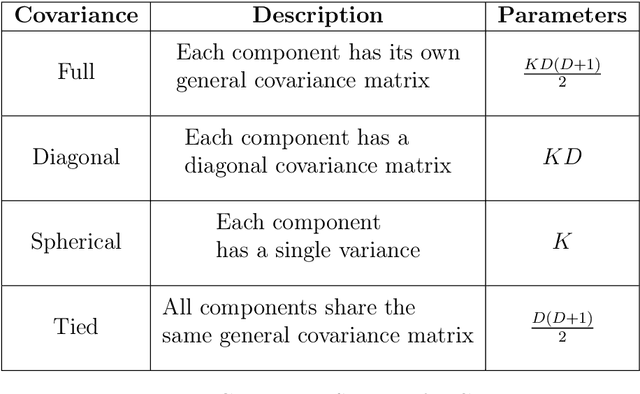
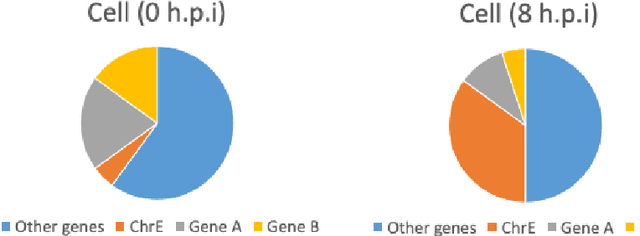

This report explores the application of machine learning techniques on short timeseries gene expression data. Although standard machine learning algorithms work well on longer time-series', they often fail to find meaningful insights from fewer timepoints. In this report, we explore model-based clustering techniques. We combine popular unsupervised learning techniques like K-Means, Gaussian Mixture Models, Bayesian Networks, Hidden Markov Models with the well-known Expectation Maximization algorithm. K-Means and Gaussian Mixture Models are fairly standard, while Hidden Markov Model and Bayesian Networks clustering are more novel ideas that suit time-series gene expression data.