 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Mini-Block Natural Gradient Method for Deep Neural Networks
Feb 08, 2022
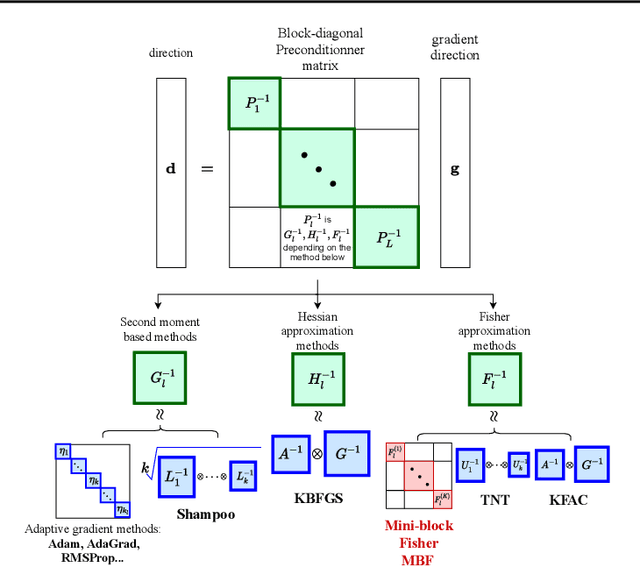
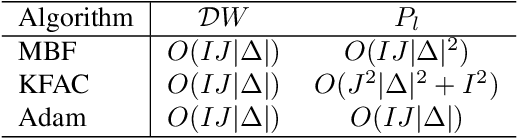
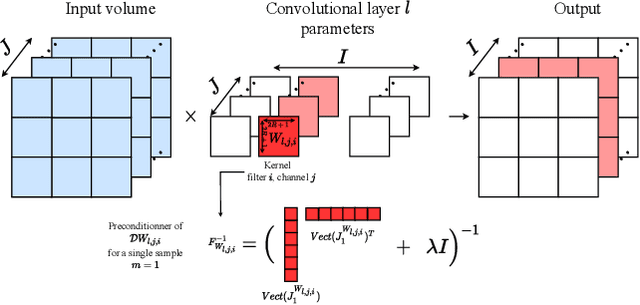

The training of deep neural networks (DNNs) is currently predominantly done using first-order methods. Some of these methods (e.g., Adam, AdaGrad, and RMSprop, and their variants) incorporate a small amount of curvature information by using a diagonal matrix to precondition the stochastic gradient. Recently, effective second-order methods, such as KFAC, K-BFGS, Shampoo, and TNT, have been developed for training DNNs, by preconditioning the stochastic gradient by layer-wise block-diagonal matrices. Here we propose and analyze the convergence of an approximate natural gradient method, mini-block Fisher (MBF), that lies in between these two classes of methods. Specifically, our method uses a block-diagonal approximation to the Fisher matrix, where for each layer in the DNN, whether it is convolutional or feed-forward and fully connected, the associated diagonal block is also block-diagonal and is composed of a large number of mini-blocks of modest size. Our novel approach utilizes the parallelism of GPUs to efficiently perform computations on the large number of matrices in each layer. Consequently, MBF's per-iteration computational cost is only slightly higher than it is for first-order methods. Finally, the performance of our proposed method is compared to that of several baseline methods, on both Auto-encoder and CNN problems, to validate its effectiveness both in terms of time efficiency and generalization power.
Learning Deep Direct-Path Relative Transfer Function for Binaural Sound Source Localization
Feb 16, 2022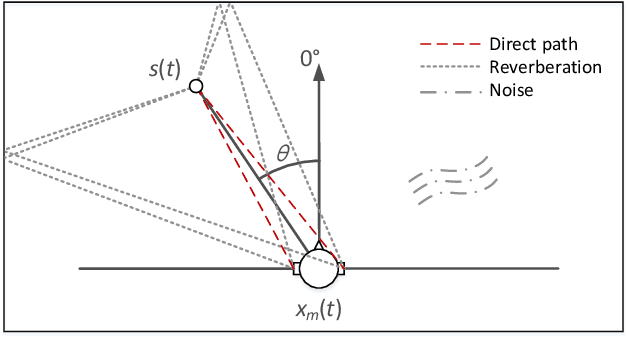
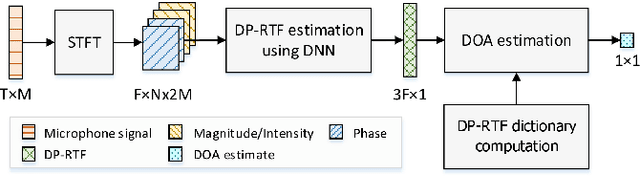
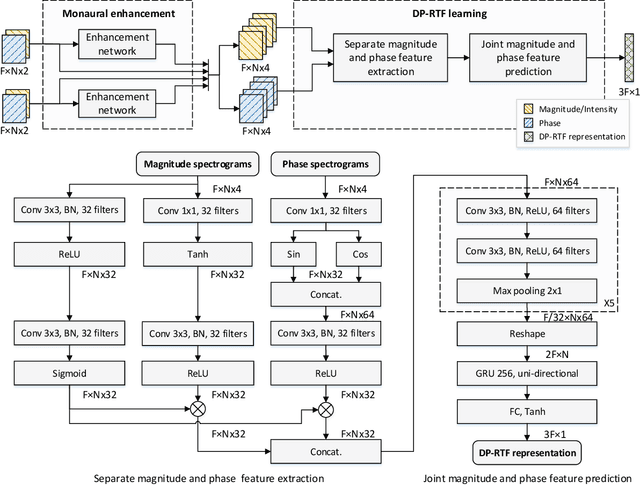
Direct-path relative transfer function (DP-RTF) refers to the ratio between the direct-path acoustic transfer functions of two microphone channels. Though DP-RTF fully encodes the sound spatial cues and serves as a reliable localization feature, it is often erroneously estimated in the presence of noise and reverberation. This paper proposes to learn DP-RTF with deep neural networks for robust binaural sound source localization. A DP-RTF learning network is designed to regress the binaural sensor signals to a real-valued representation of DP-RTF. It consists of a branched convolutional neural network module to separately extract the inter-channel magnitude and phase patterns, and a convolutional recurrent neural network module for joint feature learning. To better explore the speech spectra to aid the DP-RTF estimation, a monaural speech enhancement network is used to recover the direct-path spectrograms from the noisy ones. The enhanced spectrograms are stacked onto the noisy spectrograms to act as the input of the DP-RTF learning network. We train one unique DP-RTF learning network using many different binaural arrays to enable the generalization of DP-RTF learning across arrays. This way avoids time-consuming training data collection and network retraining for a new array, which is very useful in practical application. Experimental results on both simulated and real-world data show the effectiveness of the proposed method for direction of arrival (DOA) estimation in the noisy and reverberant environment, and a good generalization ability to unseen binaural arrays.
Internal language model estimation through explicit context vector learning for attention-based encoder-decoder ASR
Jan 26, 2022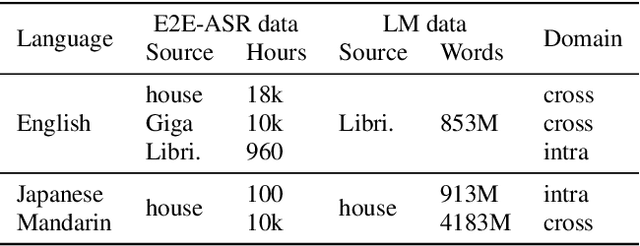
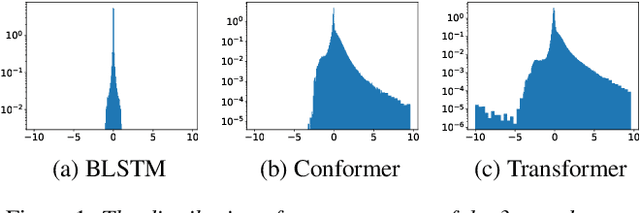
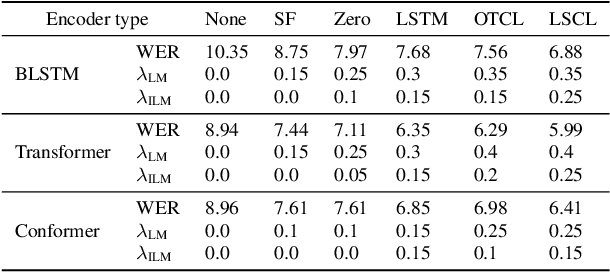

An end-to-end (E2E) speech recognition model implicitly learns a biased internal language model (ILM) during training. To fused an external LM during inference, the scores produced by the biased ILM need to be estimated and subtracted. In this paper we propose two novel approaches to estimate the biased ILM based on Listen-Attend-Spell (LAS) models. The simpler method is to replace the context vector of the LAS decoder at every time step with a learnable vector. The other more advanced method is to use a simple feed-forward network to directly map query vectors to context vectors, making the generation of the context vectors independent of the LAS encoder. Both the learnable vector and the mapping network are trained on the transcriptions of the training data to minimize the perplexity while all the other parameters of the LAS model is fixed. Experiments show that the ILMs estimated by the proposed methods achieve the lowest perplexity. In addition, they also significantly outperform the shallow fusion method and two previously proposed Internal Language Model Estimation (ILME) approaches on multiple datasets.
Imposing Temporal Consistency on Deep Monocular Body Shape and Pose Estimation
Feb 08, 2022Accurate and temporally consistent modeling of human bodies is essential for a wide range of applications, including character animation, understanding human social behavior and AR/VR interfaces. Capturing human motion accurately from a monocular image sequence is still challenging and the modeling quality is strongly influenced by the temporal consistency of the captured body motion. Our work presents an elegant solution for the integration of temporal constraints in the fitting process. This does not only increase temporal consistency but also robustness during the optimization. In detail, we derive parameters of a sequence of body models, representing shape and motion of a person, including jaw poses, facial expressions, and finger poses. We optimize these parameters over the complete image sequence, fitting one consistent body shape while imposing temporal consistency on the body motion, assuming linear body joint trajectories over a short time. Our approach enables the derivation of realistic 3D body models from image sequences, including facial expression and articulated hands. In extensive experiments, we show that our approach results in accurately estimated body shape and motion, also for challenging movements and poses. Further, we apply it to the special application of sign language analysis, where accurate and temporal consistent motion modelling is essential, and show that the approach is well-suited for this kind of application.
Online Information-Aware Motion Planning with Inertial Parameter Learning for Robotic Free-Flyers
Dec 11, 2021
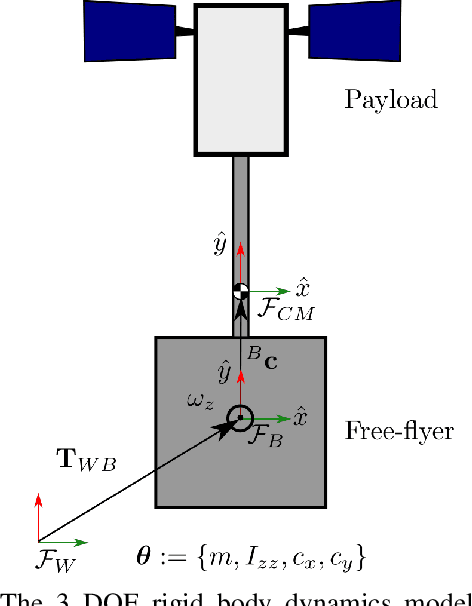
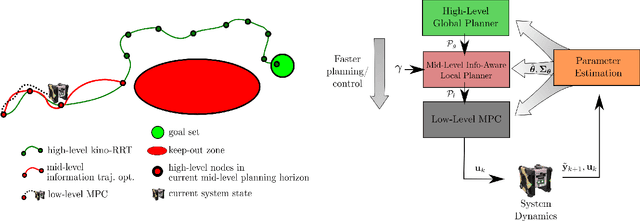

Space free-flyers like the Astrobee robots currently operating aboard the International Space Station must operate with inherent system uncertainties. Parametric uncertainties like mass and moment of inertia are especially important to quantify in these safety-critical space systems and can change in scenarios such as on-orbit cargo movement, where unknown grappled payloads significantly change the system dynamics. Cautiously learning these uncertainties en route can potentially avoid time- and fuel-consuming pure system identification maneuvers. Recognizing this, this work proposes RATTLE, an online information-aware motion planning algorithm that explicitly weights parametric model-learning coupled with real-time replanning capability that can take advantage of improved system models. The method consists of a two-tiered (global and local) planner, a low-level model predictive controller, and an online parameter estimator that produces estimates of the robot's inertial properties for more informed control and replanning on-the-fly; all levels of the planning and control feature online update-able models. Simulation results of RATTLE for the Astrobee free-flyer grappling an uncertain payload are presented alongside results of a hardware demonstration showcasing the ability to explicitly encourage model parametric learning while achieving otherwise useful motion.
Graph Neural Networks with Dynamic and Static Representations for Social Recommendation
Jan 26, 2022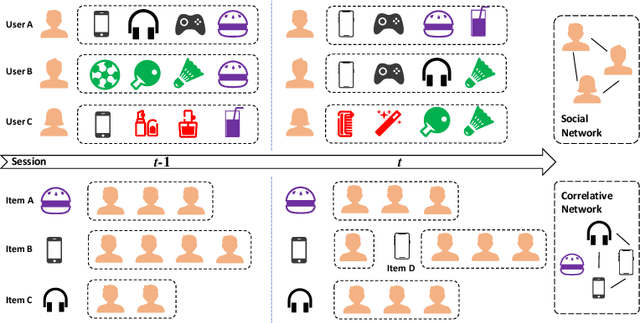
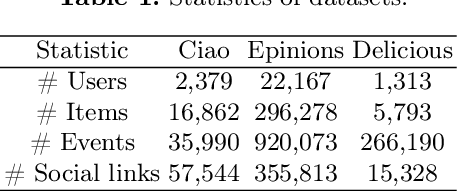
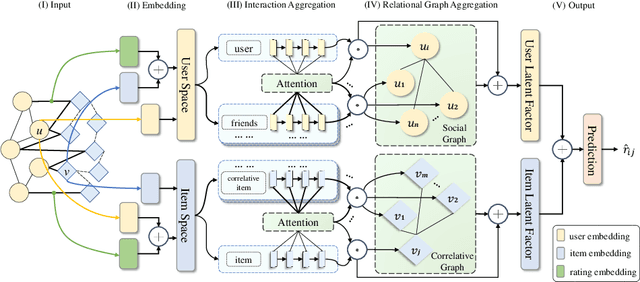
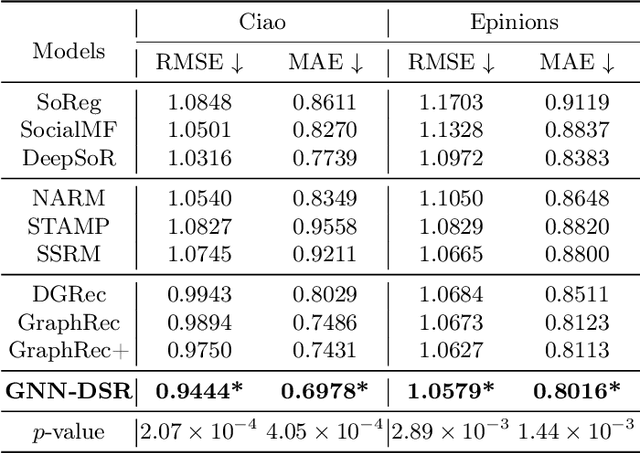
Recommender systems based on graph neural networks receive increasing research interest due to their excellent ability to learn a variety of side information including social networks. However, previous works usually focus on modeling users, not much attention is paid to items. Moreover, the possible changes in the attraction of items over time, which is like the dynamic interest of users are rarely considered, and neither do the correlations among items. To overcome these limitations, this paper proposes graph neural networks with dynamic and static representations for social recommendation (GNN-DSR), which considers both dynamic and static representations of users and items and incorporates their relational influence. GNN-DSR models the short-term dynamic and long-term static interactional representations of the user's interest and the item's attraction, respectively. Furthermore, the attention mechanism is used to aggregate the social influence of users on the target user and the correlative items' influence on a given item. The final latent factors of user and item are combined to make a prediction. Experiments on three real-world recommender system datasets validate the effectiveness of GNN-DSR.
Highly sensitive fire alarm system based on cellulose paper with low temperature response and wireless signal conversion
Dec 28, 2021
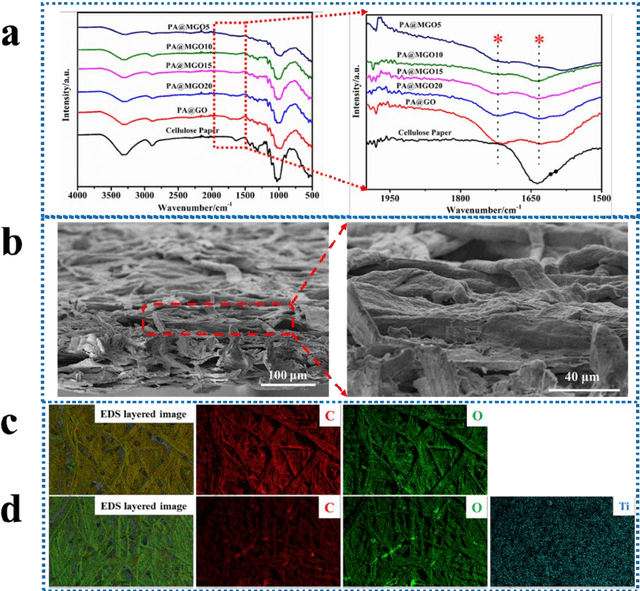
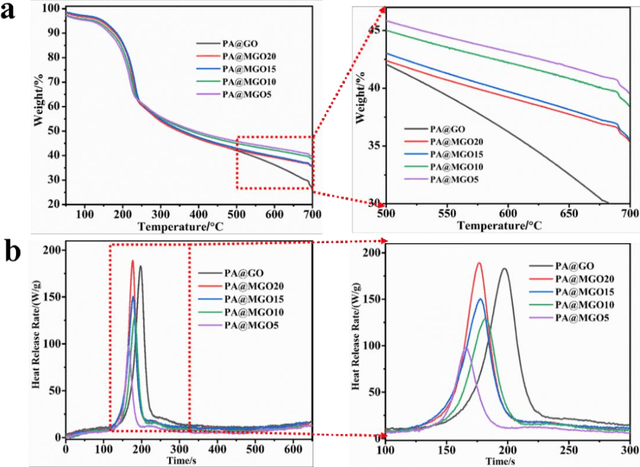
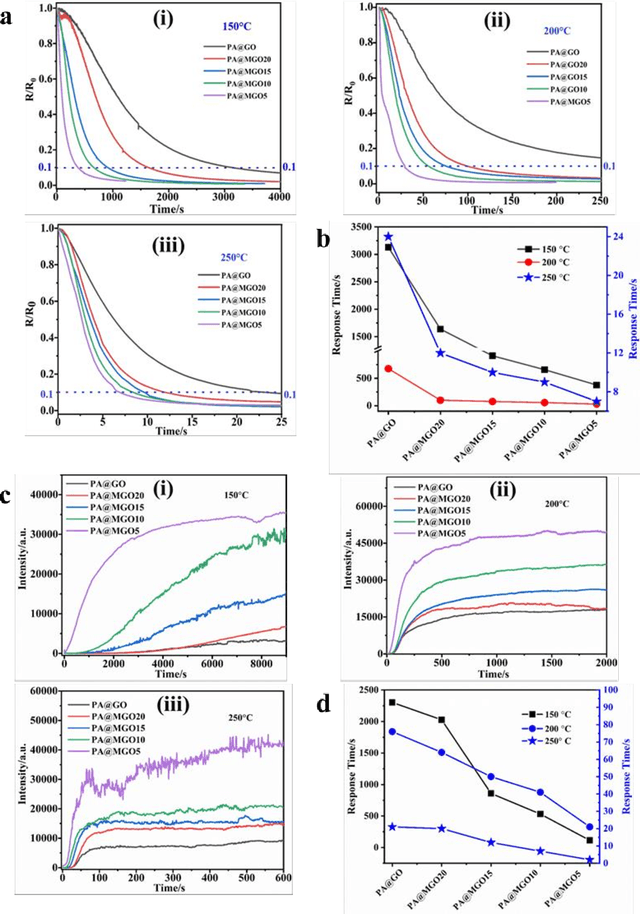
Highly sensitive smart sensors for early fire detection with remote warning capabilities are urgently required to improve the fire safety of combustible materials in diverse applications. The highly-sensitive fire alarm can detect fire situation within a short time quickly when a fire disaster is about to occur, which is conducive to achieve fire tuned. Herein, a novel fire alarm is designed by using flame-retardant cellulose paper loaded with graphene oxide (GO) and two-dimensional titanium carbide (Ti3C2, MXene). Owing to the excellent temperature dependent electrical resistance switching effect of GO, it acts as an electrical insulator at room temperature and becomes electrically conductive at high temperature. During a fire incident, the partial oxygen-containing groups on GO will undergo complete removal, which results in the conductivity transformation.Besides the use of GO feature, this work also introduces conductive MXene to enhance fire detection speed and warning at low temperature, especially below 300 {\deg}C. The designed flame-retardant fire alarm is sensitive enough to detect fire incident, showing a response time of 2 s at 250 {\deg}C, which is calculated by a novel and quantifiable technique. More importantly, the designed fire alarm sensor is coupled to a wireless communication interface to conveniently transmit fire signal remotely. Therefore, when an abnormal temperature is detected, the signal is wirelessly transmitted to a liquid crystal display (LCD) screen when displays a message such as "FIRE DANGER". The designed smart fire alarm paper is promising for use as a smart wallpaper for interior house decoration and other applications requiring early fire detection and warning.
Learning Swarm Interaction Dynamics from Density Evolution
Dec 05, 2021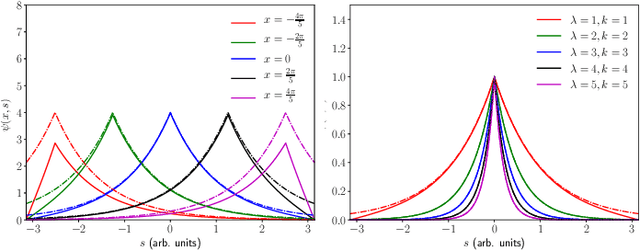
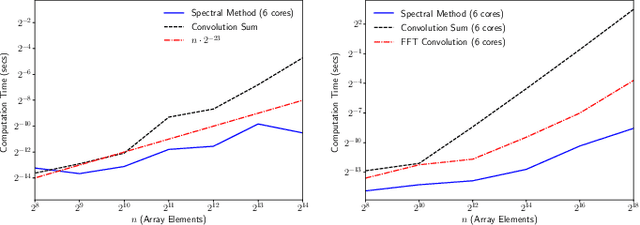
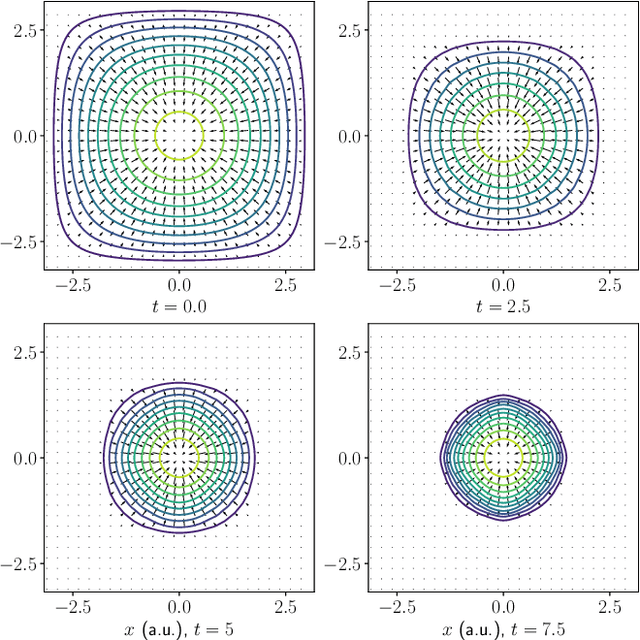
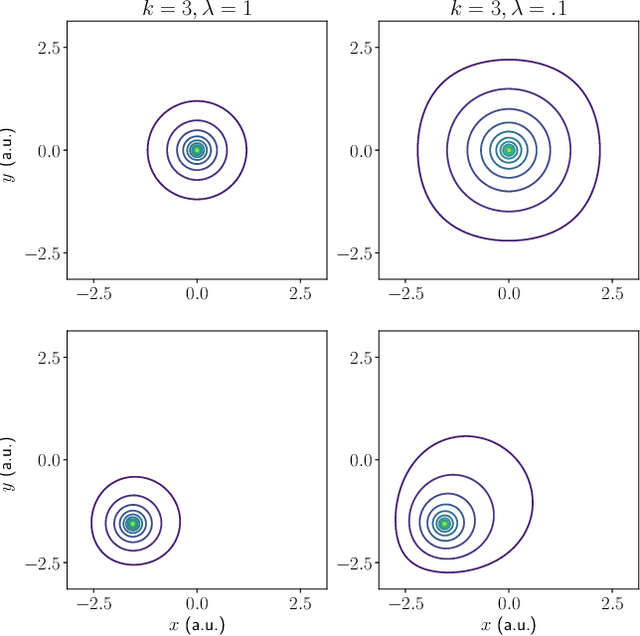
We consider the problem of understanding the coordinated movements of biological or artificial swarms. In this regard, we propose a learning scheme to estimate the coordination laws of the interacting agents from observations of the swarm's density over time. We describe the dynamics of the swarm based on pairwise interactions according to a Cucker-Smale flocking model, and express the swarm's density evolution as the solution to a system of mean-field hydrodynamic equations. We propose a new family of parametric functions to model the pairwise interactions, which allows for the mean-field macroscopic system of integro-differential equations to be efficiently solved as an augmented system of PDEs. Finally, we incorporate the augmented system in an iterative optimization scheme to learn the dynamics of the interacting agents from observations of the swarm's density evolution over time. The results of this work can offer an alternative approach to study how animal flocks coordinate, create new control schemes for large networked systems, and serve as a central part of defense mechanisms against adversarial drone attacks.
Sublinear Time Numerical Linear Algebra for Structured Matrices
Dec 12, 2019We show how to solve a number of problems in numerical linear algebra, such as least squares regression, $\ell_p$-regression for any $p \geq 1$, low rank approximation, and kernel regression, in time $T(A) \poly(\log(nd))$, where for a given input matrix $A \in \mathbb{R}^{n \times d}$, $T(A)$ is the time needed to compute $A\cdot y$ for an arbitrary vector $y \in \mathbb{R}^d$. Since $T(A) \leq O(\nnz(A))$, where $\nnz(A)$ denotes the number of non-zero entries of $A$, the time is no worse, up to polylogarithmic factors, as all of the recent advances for such problems that run in input-sparsity time. However, for many applications, $T(A)$ can be much smaller than $\nnz(A)$, yielding significantly sublinear time algorithms. For example, in the overconstrained $(1+\epsilon)$-approximate polynomial interpolation problem, $A$ is a Vandermonde matrix and $T(A) = O(n \log n)$; in this case our running time is $n \cdot \poly(\log n) + \poly(d/\epsilon)$ and we recover the results of \cite{avron2013sketching} as a special case. For overconstrained autoregression, which is a common problem arising in dynamical systems, $T(A) = O(n \log n)$, and we immediately obtain $n \cdot \poly(\log n) + \poly(d/\epsilon)$ time. For kernel autoregression, we significantly improve the running time of prior algorithms for general kernels. For the important case of autoregression with the polynomial kernel and arbitrary target vector $b\in\mathbb{R}^n$, we obtain even faster algorithms. Our algorithms show that, perhaps surprisingly, most of these optimization problems do not require much more time than that of a polylogarithmic number of matrix-vector multiplications.
Dynamic Review-based Recommenders
Oct 27, 2021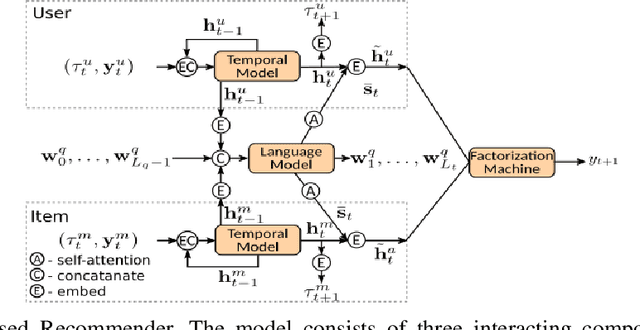
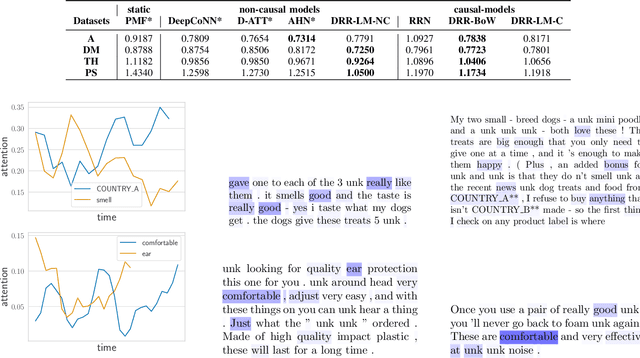
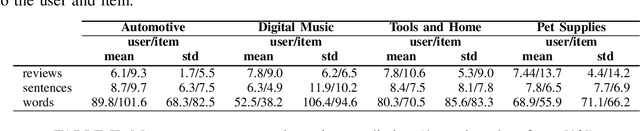
Just as user preferences change with time, item reviews also reflect those same preference changes. In a nutshell, if one is to sequentially incorporate review content knowledge into recommender systems, one is naturally led to dynamical models of text. In the present work we leverage the known power of reviews to enhance rating predictions in a way that (i) respects the causality of review generation and (ii) includes, in a bidirectional fashion, the ability of ratings to inform language review models and vice-versa, language representations that help predict ratings end-to-end. Moreover, our representations are time-interval aware and thus yield a continuous-time representation of the dynamics. We provide experiments on real-world datasets and show that our methodology is able to outperform several state-of-the-art models. Source code for all models can be found at [1].