 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LogLAB: Attention-Based Labeling of Log Data Anomalies via Weak Supervision
Nov 02, 2021
With increasing scale and complexity of cloud operations, automated detection of anomalies in monitoring data such as logs will be an essential part of managing future IT infrastructures. However, many methods based on artificial intelligence, such as supervised deep learning models, require large amounts of labeled training data to perform well. In practice, this data is rarely available because labeling log data is expensive, time-consuming, and requires a deep understanding of the underlying system. We present LogLAB, a novel modeling approach for automated labeling of log messages without requiring manual work by experts. Our method relies on estimated failure time windows provided by monitoring systems to produce precise labeled datasets in retrospect. It is based on the attention mechanism and uses a custom objective function for weak supervision deep learning techniques that accounts for imbalanced data. Our evaluation shows that LogLAB consistently outperforms nine benchmark approaches across three different datasets and maintains an F1-score of more than 0.98 even at large failure time windows.
Locally Random P-adic Alloy Codes with Channel Coding Theorems for Distributed Coded Tensors
Feb 09, 2022
Tensors, i.e., multi-linear functions, are a fundamental building block of machine learning algorithms. In order to train on large data-sets, it is common practice to distribute the computation amongst workers. However, stragglers and other faults can severely impact the performance and overall training time. A novel strategy to mitigate these failures is the use of coded computation. We introduce a new metric for analysis called the typical recovery threshold, which focuses on the most likely event and provide a novel construction of distributed coded tensor operations which are optimal with this measure. We show that our general framework encompasses many other computational schemes and metrics as a special case. In particular, we prove that the recovery threshold and the tensor rank can be recovered as a special case of the typical recovery threshold when the probability of noise, i.e., a fault, is equal to zero, thereby providing a noisy generalization of noiseless computation as a serendipitous result. Far from being a purely theoretical construction, these definitions lead us to practical random code constructions, i.e., locally random p-adic alloy codes, which are optimal with respect to the measures. We analyze experiments conducted on Amazon EC2 and establish that they are faster and more numerically stable than many other benchmark computation schemes in practice, as is predicted by theory.
Learning Wildfire Model from Incomplete State Observations
Nov 28, 2021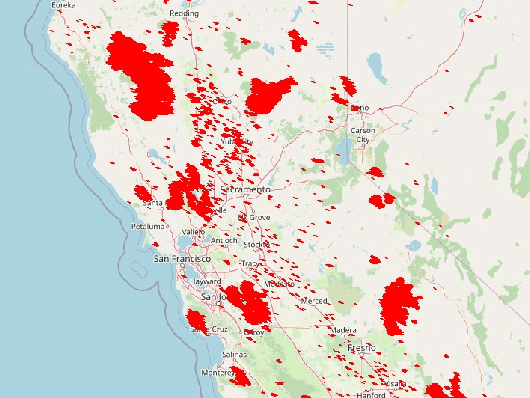
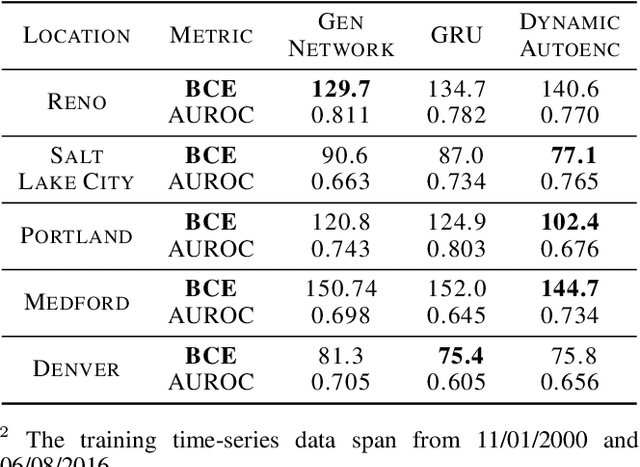
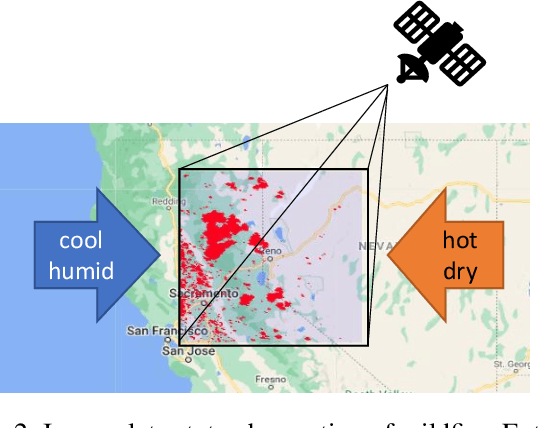
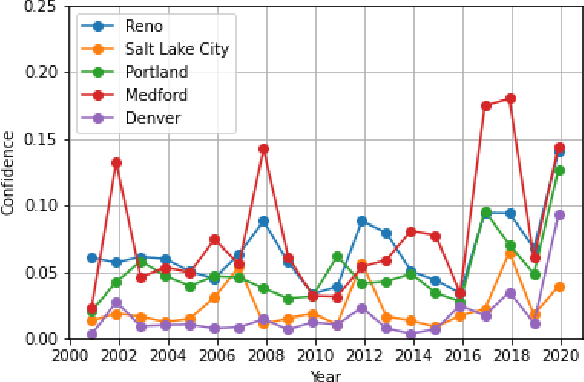
As wildfires are expected to become more frequent and severe, improved prediction models are vital to mitigating risk and allocating resources. With remote sensing data, valuable spatiotemporal statistical models can be created and used for resource management practices. In this paper, we create a dynamic model for future wildfire predictions of five locations within the western United States through a deep neural network via historical burned area and climate data. The proposed model has distinct features that address the characteristic need in prediction evaluations, including dynamic online estimation and time-series modeling. Between locations, local fire event triggers are not isolated, and there are confounding factors when local data is analyzed due to incomplete state observations. When compared to existing approaches that do not account for incomplete state observation within wildfire time-series data, on average, we are able to achieve higher prediction performances.
Low-Rank Updates of Matrix Square Roots
Jan 31, 2022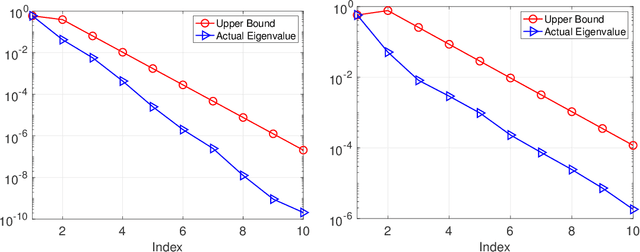


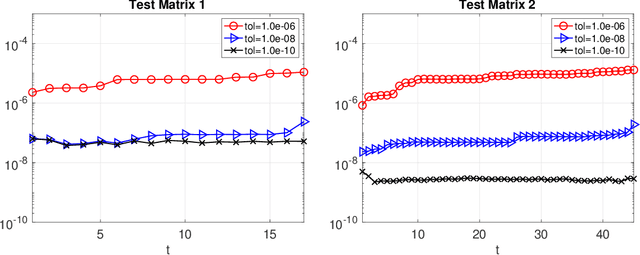
Models in which the covariance matrix has the structure of a sparse matrix plus a low rank perturbation are ubiquitous in machine learning applications. It is often desirable for learning algorithms to take advantage of such structures, avoiding costly matrix computations that often require cubic time and quadratic storage. This is often accomplished by performing operations that maintain such structures, e.g. matrix inversion via the Sherman-Morrison-Woodbury formula. In this paper we consider the matrix square root and inverse square root operations. Given a low rank perturbation to a matrix, we argue that a low-rank approximate correction to the (inverse) square root exists. We do so by establishing a geometric decay bound on the true correction's eigenvalues. We then proceed to frame the correction has the solution of an algebraic Ricatti equation, and discuss how a low-rank solution to that equation can be computed. We analyze the approximation error incurred when approximately solving the algebraic Ricatti equation, providing spectral and Frobenius norm forward and backward error bounds. Finally, we describe several applications of our algorithms, and demonstrate their utility in numerical experiments.
Design of Tight Minimum-Sidelobe Windows by Riemannian Newton's Method
Nov 02, 2021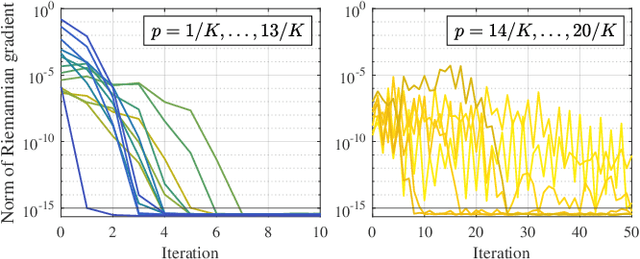
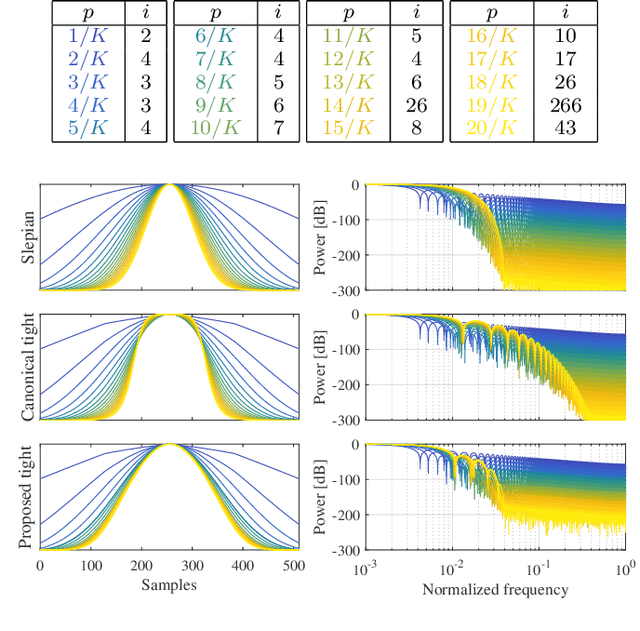
The short-time Fourier transform (STFT), or the discrete Gabor transform (DGT), has been extensively used in signal analysis and processing. Their properties are characterized by a window function, and hence window design is a significant topic up to date. For signal processing, designing a pair of analysis and synthesis windows is important because results of processing in the time-frequency domain are affected by both of them. A tight window is a special window that can perfectly reconstruct a signal by using it for both analysis and synthesis. It is known to make time-frequency-domain processing robust to error, and therefore designing a better tight window is desired. In this paper, we propose a method of designing tight windows that minimize the sidelobe energy. It is formulated as an optimization problem on an oblique manifold, and a Riemannian Newton algorithm on this manifold is derived to efficiently obtain a solution.
Sublinear Time Numerical Linear Algebra for Structured Matrices
Dec 12, 2019We show how to solve a number of problems in numerical linear algebra, such as least squares regression, $\ell_p$-regression for any $p \geq 1$, low rank approximation, and kernel regression, in time $T(A) \poly(\log(nd))$, where for a given input matrix $A \in \mathbb{R}^{n \times d}$, $T(A)$ is the time needed to compute $A\cdot y$ for an arbitrary vector $y \in \mathbb{R}^d$. Since $T(A) \leq O(\nnz(A))$, where $\nnz(A)$ denotes the number of non-zero entries of $A$, the time is no worse, up to polylogarithmic factors, as all of the recent advances for such problems that run in input-sparsity time. However, for many applications, $T(A)$ can be much smaller than $\nnz(A)$, yielding significantly sublinear time algorithms. For example, in the overconstrained $(1+\epsilon)$-approximate polynomial interpolation problem, $A$ is a Vandermonde matrix and $T(A) = O(n \log n)$; in this case our running time is $n \cdot \poly(\log n) + \poly(d/\epsilon)$ and we recover the results of \cite{avron2013sketching} as a special case. For overconstrained autoregression, which is a common problem arising in dynamical systems, $T(A) = O(n \log n)$, and we immediately obtain $n \cdot \poly(\log n) + \poly(d/\epsilon)$ time. For kernel autoregression, we significantly improve the running time of prior algorithms for general kernels. For the important case of autoregression with the polynomial kernel and arbitrary target vector $b\in\mathbb{R}^n$, we obtain even faster algorithms. Our algorithms show that, perhaps surprisingly, most of these optimization problems do not require much more time than that of a polylogarithmic number of matrix-vector multiplications.
DBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement
Feb 16, 2022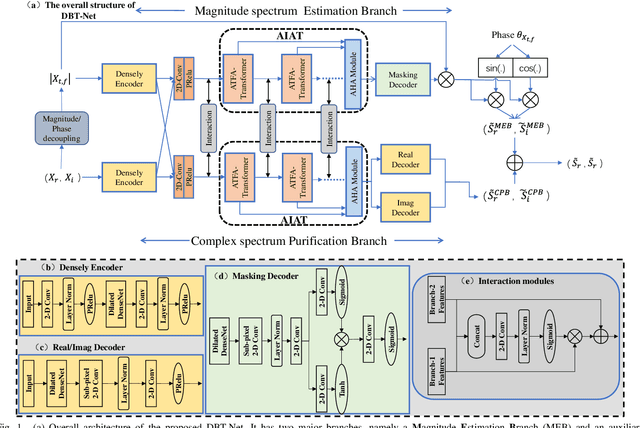
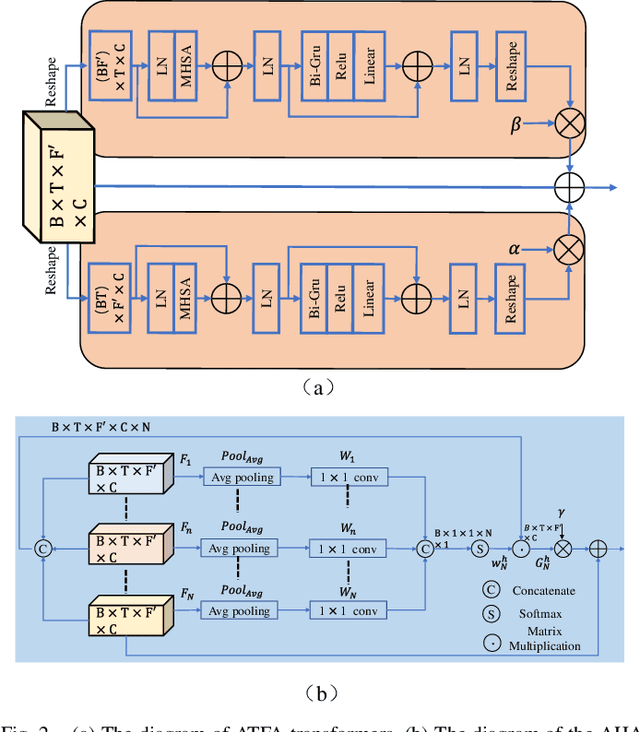
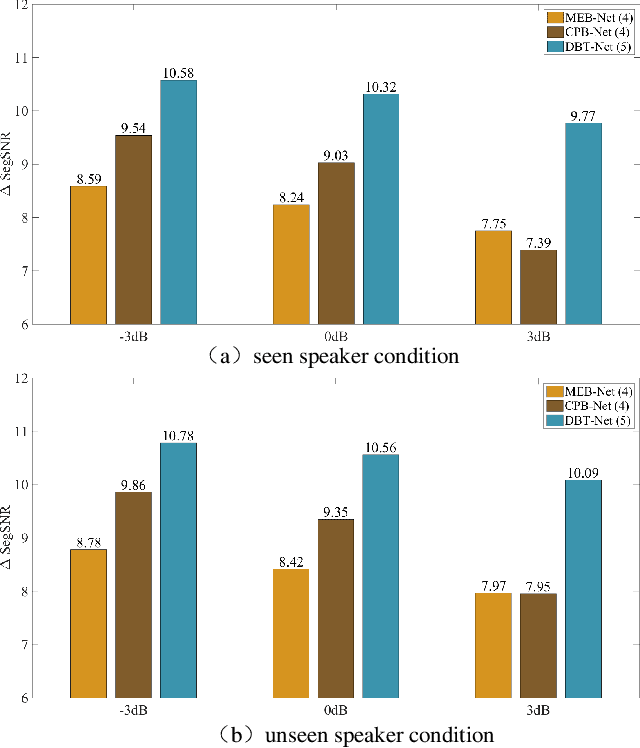
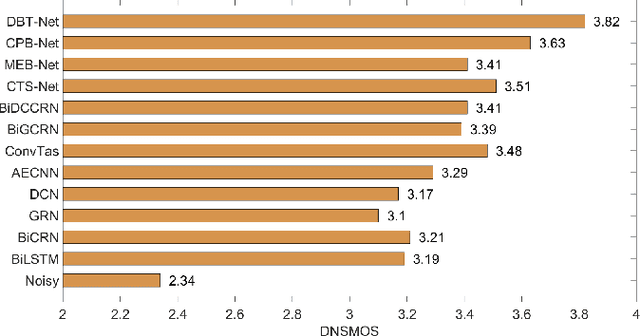
The decoupling-style concept begins to ignite in the speech enhancement area, which decouples the original complex spectrum estimation task into multiple easier sub-tasks (i.e., magnitude and phase), resulting in better performance and easier interpretability. In this paper, we propose a dual-branch federative magnitude and phase estimation framework, dubbed DBT-Net, for monaural speech enhancement, which aims at recovering the coarse- and fine-grained regions of the overall spectrum in parallel. From the complementary perspective, the magnitude estimation branch is designed to filter out dominant noise components in the magnitude domain, while the complex spectrum purification branch is elaborately designed to inpaint the missing spectral details and implicitly estimate the phase information in the complex domain. To facilitate the information flow between each branch, interaction modules are introduced to leverage features learned from one branch, so as to suppress the undesired parts and recover the missing components of the other branch. Instead of adopting the conventional RNNs and temporal convolutional networks for sequence modeling, we propose a novel attention-in-attention transformer-based network within each branch for better feature learning. More specially, it is composed of several adaptive spectro-temporal attention transformer-based modules and an adaptive hierarchical attention module, aiming to capture long-term time-frequency dependencies and further aggregate intermediate hierarchical contextual information. Comprehensive evaluations on the WSJ0-SI84 + DNS-Challenge and VoiceBank + DEMAND dataset demonstrate that the proposed approach consistently outperforms previous advanced systems and yields state-of-the-art performance in terms of speech quality and intelligibility.
Structure-Exploiting Newton-Type Method for Optimal Control of Switched Systems
Dec 20, 2021
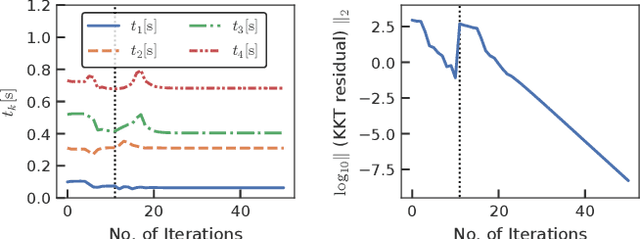
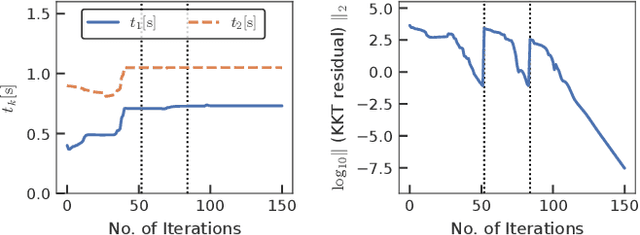
This study proposes an efficient Newton-type method for the optimal control of switched systems under a given mode sequence. A mesh-refinement-based approach is utilized to discretize continuous-time optimal control problems (OCPs) and formulate a nonlinear program (NLP), which guarantees the local convergence of a Newton-type method. A dedicated structure-exploiting algorithm (Riccati recursion) is proposed to perform a Newton-type method for the NLP efficiently because its sparsity structure is different from a standard OCP. The proposed method computes each Newton step with linear time-complexity for the total number of discretization grids as the standard Riccati recursion algorithm. Additionally, the computation is always successful if the solution is sufficiently close to a local minimum. Conversely, general quadratic programming (QP) solvers cannot accomplish this because the Hessian matrix is inherently indefinite. Moreover, a modification on the reduced Hessian matrix is proposed using the nature of the Riccati recursion algorithm as the dynamic programming for a QP subproblem to enhance the convergence. A numerical comparison is conducted with off-the-shelf NLP solvers, which demonstrates that the proposed method is up to two orders of magnitude faster. Whole-body optimal control of quadrupedal gaits is also demonstrated and shows that the proposed method can achieve the whole-body model predictive control (MPC) of robotic systems with rigid contacts.
Unsupervised Anomaly Detection in 3D Brain MRI using Deep Learning with Multi-Task Brain Age Prediction
Jan 31, 2022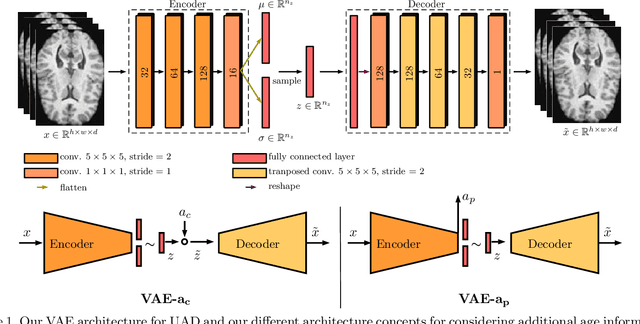

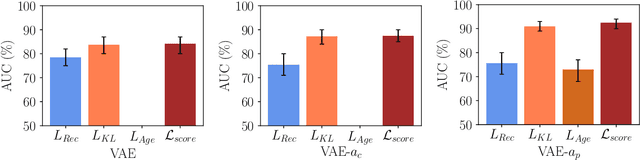
Lesion detection in brain Magnetic Resonance Images (MRIs) remains a challenging task. MRIs are typically read and interpreted by domain experts, which is a tedious and time-consuming process. Recently, unsupervised anomaly detection (UAD) in brain MRI with deep learning has shown promising results to provide a quick, initial assessment. So far, these methods only rely on the visual appearance of healthy brain anatomy for anomaly detection. Another biomarker for abnormal brain development is the deviation between the brain age and the chronological age, which is unexplored in combination with UAD. We propose deep learning for UAD in 3D brain MRI considering additional age information. We analyze the value of age information during training, as an additional anomaly score, and systematically study several architecture concepts. Based on our analysis, we propose a novel deep learning approach for UAD with multi-task age prediction. We use clinical T1-weighted MRIs of 1735 healthy subjects and the publicly available BraTs 2019 data set for our study. Our novel approach significantly improves UAD performance with an AUC of 92.60% compared to an AUC-score of 84.37% using previous approaches without age information.
Statistical and Spatio-temporal Hand Gesture Features for Sign Language Recognition using the Leap Motion Sensor
Feb 22, 2022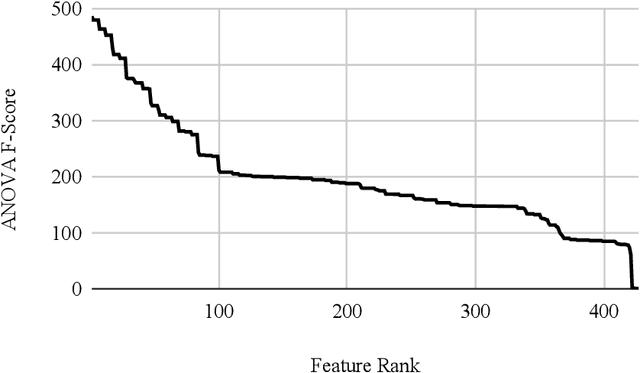
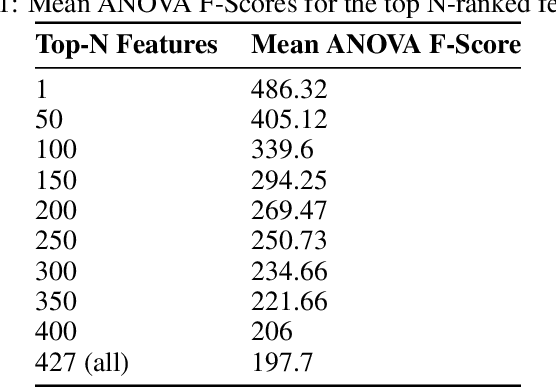
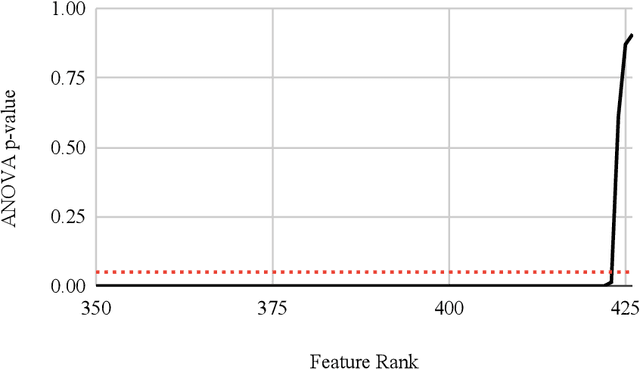
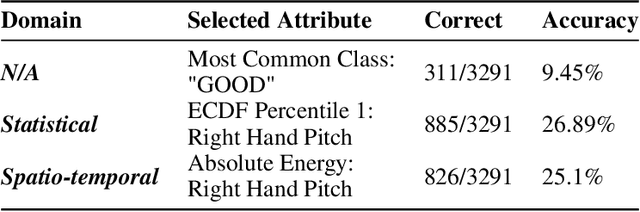
In modern society, people should not be identified based on their disability, rather, it is environments that can disable people with impairments. Improvements to automatic Sign Language Recognition (SLR) will lead to more enabling environments via digital technology. Many state-of-the-art approaches to SLR focus on the classification of static hand gestures, but communication is a temporal activity, which is reflected by many of the dynamic gestures present. Given this, temporal information during the delivery of a gesture is not often considered within SLR. The experiments in this work consider the problem of SL gesture recognition regarding how dynamic gestures change during their delivery, and this study aims to explore how single types of features as well as mixed features affect the classification ability of a machine learning model. 18 common gestures recorded via a Leap Motion Controller sensor provide a complex classification problem. Two sets of features are extracted from a 0.6 second time window, statistical descriptors and spatio-temporal attributes. Features from each set are compared by their ANOVA F-Scores and p-values, arranged into bins grown by 10 features per step to a limit of the 250 highest-ranked features. Results show that the best statistical model selected 240 features and scored 85.96% accuracy, the best spatio-temporal model selected 230 features and scored 80.98%, and the best mixed-feature model selected 240 features from each set leading to a classification accuracy of 86.75%. When all three sets of results are compared (146 individual machine learning models), the overall distribution shows that the minimum results are increased when inputs are any number of mixed features compared to any number of either of the two single sets of features.