 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Models in the Loop: Aiding Crowdworkers with Generative Annotation Assistants
Dec 16, 2021


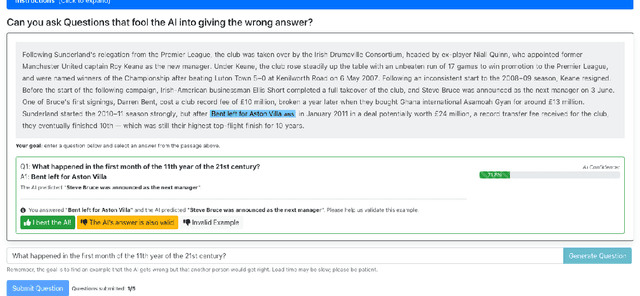

In Dynamic Adversarial Data Collection (DADC), human annotators are tasked with finding examples that models struggle to predict correctly. Models trained on DADC-collected training data have been shown to be more robust in adversarial and out-of-domain settings, and are considerably harder for humans to fool. However, DADC is more time-consuming than traditional data collection and thus more costly per example. In this work, we examine if we can maintain the advantages of DADC, without suffering the additional cost. To that end, we introduce Generative Annotation Assistants (GAAs), generator-in-the-loop models that provide real-time suggestions that annotators can either approve, modify, or reject entirely. We collect training datasets in twenty experimental settings and perform a detailed analysis of this approach for the task of extractive question answering (QA) for both standard and adversarial data collection. We demonstrate that GAAs provide significant efficiency benefits in terms of annotation speed, while leading to improved model fooling rates. In addition, we show that GAA-assisted data leads to higher downstream model performance on a variety of question answering tasks.
Systematic Literature Review: Quantum Machine Learning and its applications
Jan 11, 2022



Quantum computing is the process of performing calculations using quantum mechanics. This field studies the quantum behavior of certain subatomic particles for subsequent use in performing calculations, as well as for large-scale information processing. These capabilities can give quantum computers an advantage in terms of computational time and cost over classical computers. Nowadays, there are scientific challenges that are impossible to perform by classical computation due to computational complexity or the time the calculation would take, and quantum computation is one of the possible answers. However, current quantum devices have not yet the necessary qubits and are not fault-tolerant enough to achieve these goals. Nonetheless, there are other fields like machine learning or chemistry where quantum computation could be useful with current quantum devices. This manuscript aims to present a Systematic Literature Review of the papers published between 2017 and 2021 to identify, analyze and classify the different algorithms used in quantum machine learning and their applications. Consequently, this study identified 52 articles that used quantum machine learning techniques and algorithms. The main types of found algorithms are quantum implementations of classical machine learning algorithms, such as support vector machines or the k-nearest neighbor model, and classical deep learning algorithms, like quantum neural networks. Many articles try to solve problems currently answered by classical machine learning but using quantum devices and algorithms. Even though results are promising, quantum machine learning is far from achieving its full potential. An improvement in the quantum hardware is required since the existing quantum computers lack enough quality, speed, and scale to allow quantum computing to achieve its full potential.
Provable and Efficient Continual Representation Learning
Mar 03, 2022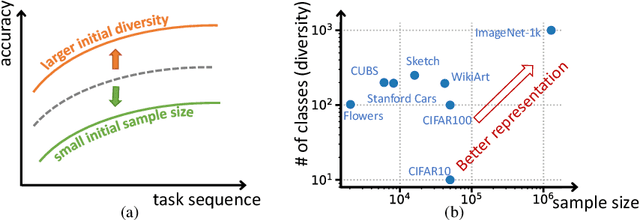
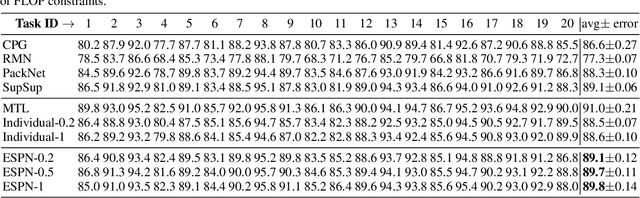
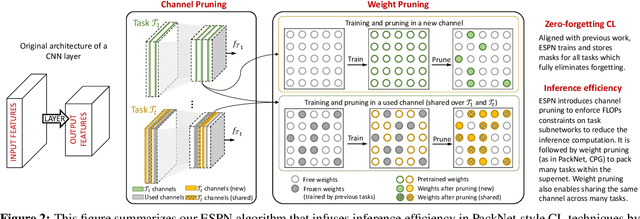
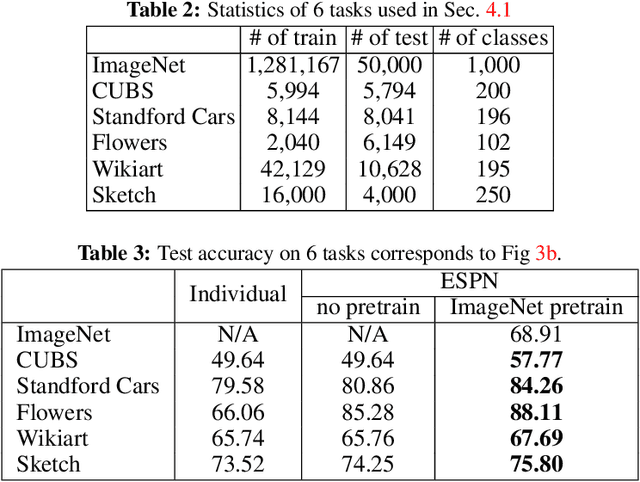
In continual learning (CL), the goal is to design models that can learn a sequence of tasks without catastrophic forgetting. While there is a rich set of techniques for CL, relatively little understanding exists on how representations built by previous tasks benefit new tasks that are added to the network. To address this, we study the problem of continual representation learning (CRL) where we learn an evolving representation as new tasks arrive. Focusing on zero-forgetting methods where tasks are embedded in subnetworks (e.g., PackNet), we first provide experiments demonstrating CRL can significantly boost sample efficiency when learning new tasks. To explain this, we establish theoretical guarantees for CRL by providing sample complexity and generalization error bounds for new tasks by formalizing the statistical benefits of previously-learned representations. Our analysis and experiments also highlight the importance of the order in which we learn the tasks. Specifically, we show that CL benefits if the initial tasks have large sample size and high "representation diversity". Diversity ensures that adding new tasks incurs small representation mismatch and can be learned with few samples while training only few additional nonzero weights. Finally, we ask whether one can ensure each task subnetwork to be efficient during inference time while retaining the benefits of representation learning. To this end, we propose an inference-efficient variation of PackNet called Efficient Sparse PackNet (ESPN) which employs joint channel & weight pruning. ESPN embeds tasks in channel-sparse subnets requiring up to 80% less FLOPs to compute while approximately retaining accuracy and is very competitive with a variety of baselines. In summary, this work takes a step towards data and compute-efficient CL with a representation learning perspective. GitHub page: https://github.com/ucr-optml/CtRL
Path Imputation Strategies for Signature Models of Irregular Time Series
Jun 06, 2020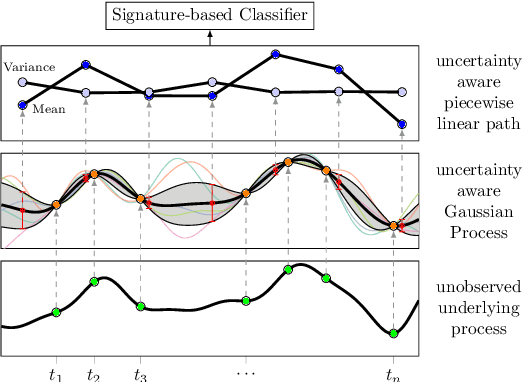
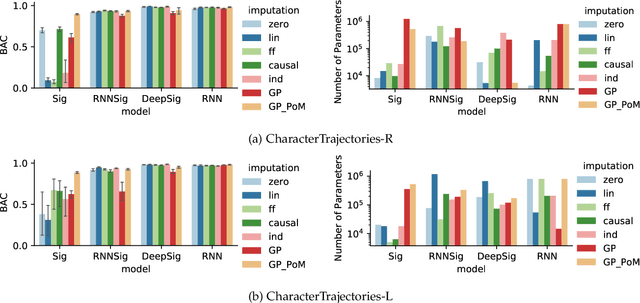
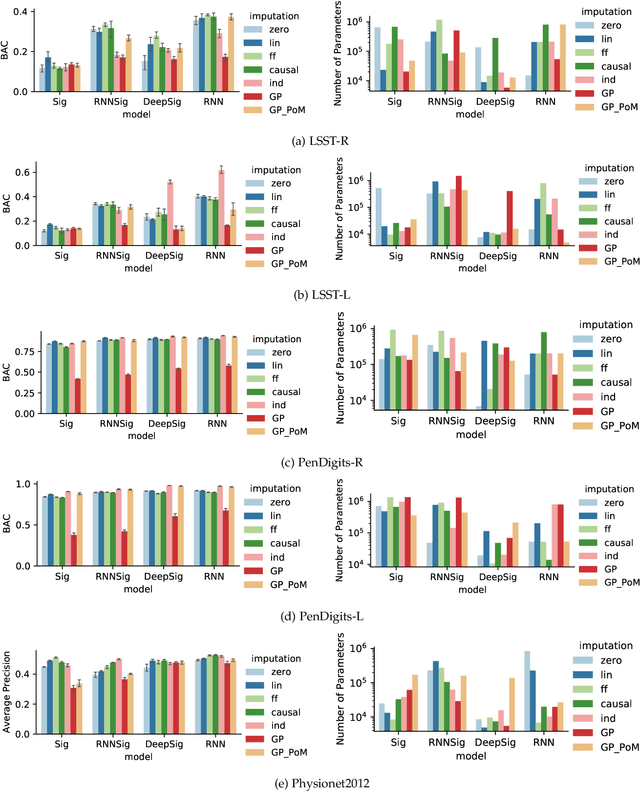
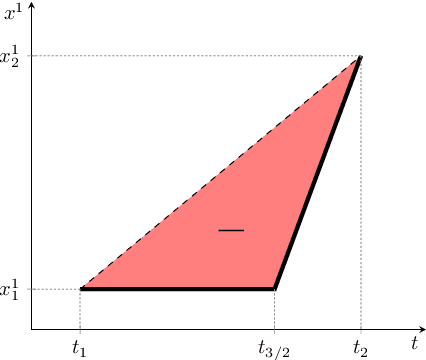
The signature transform is a 'universal nonlinearity' on the space of continuous vector-valued paths, and has received attention for use in machine learning on time series. However, real-world temporal data is typically observed at discrete points in time, and must first be transformed into a continuous path before signature techniques can be applied. We make this step explicit by characterising it as an imputation problem, and empirically assess the impact of various imputation strategies when applying signature-based neural nets to irregular time series data. For one of these strategies, Gaussian process (GP) adapters, we propose an extension~(GP-PoM) that makes uncertainty information directly available to the subsequent classifier while at the same time preventing costly Monte-Carlo (MC) sampling. In our experiments, we find that the choice of imputation drastically affects shallow signature models, whereas deeper architectures are more robust. Next, we observe that uncertainty-aware predictions (based on GP-PoM or indicator imputations) are beneficial for predictive performance, even compared to the uncertainty-aware training of conventional GP adapters. In conclusion, we have demonstrated that the path construction is indeed crucial for signature models and that our proposed strategy leads to competitive performance in general, while improving robustness of signature models in particular.
RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
Nov 12, 2020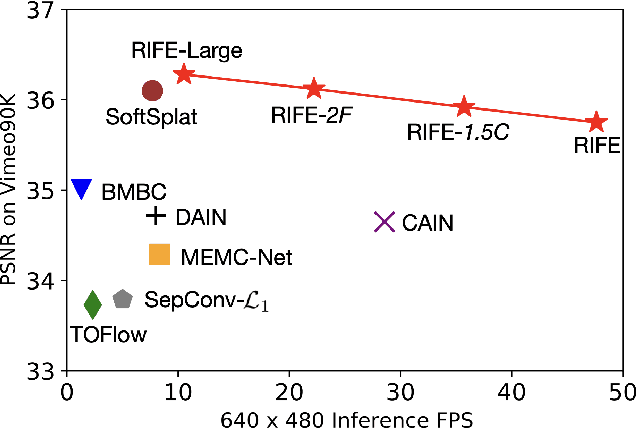

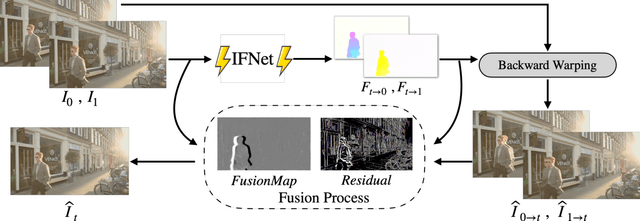
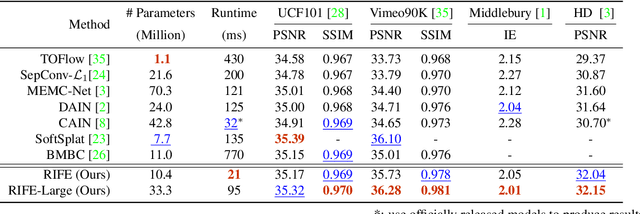
We propose a real-time intermediate flow estimation algorithm (RIFE) for video frame interpolation (VFI). Most existing methods first estimate the bi-directional optical flows, and then linearly combine them to approximate intermediate flows, leading to artifacts around motion boundaries. We design an intermediate flow model named IFNet that can directly estimate the intermediate flows from coarse to fine. We then warp the input frames according to the estimated intermediate flows and employ a fusion process to compute final results. Based on our proposed leakage distillation, RIFE can be trained end-to-end and achieve excellent performance. Experiments demonstrate that RIFE is significantly faster than existing flow-based VFI methods and achieves state-of-the-art index on several benchmarks. The code is available at https://github.com/hzwer/RIFE.
Leveraging wisdom of the crowds to improve consensus among radiologists by real time, blinded collaborations on a digital swarm platform
Jun 26, 2021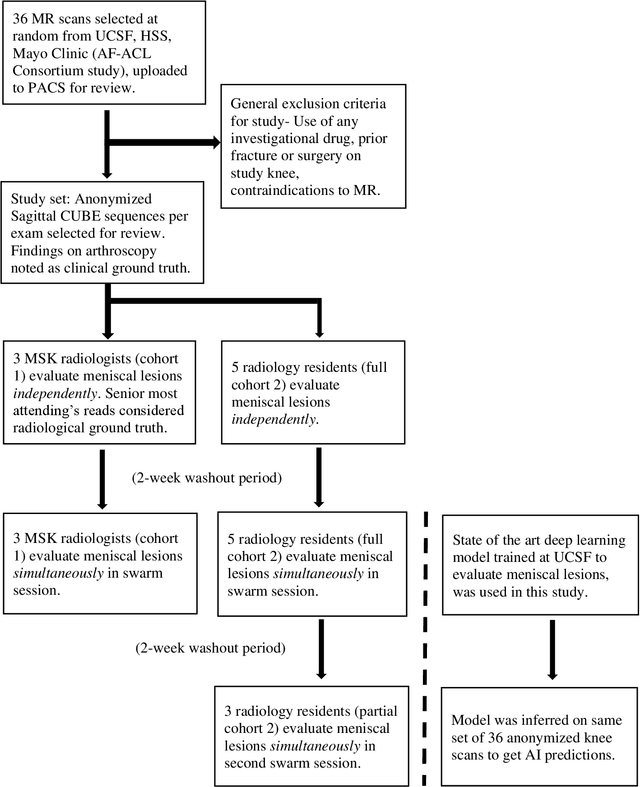
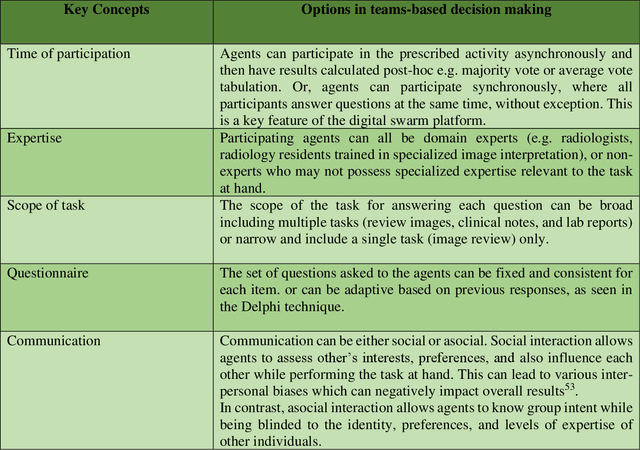
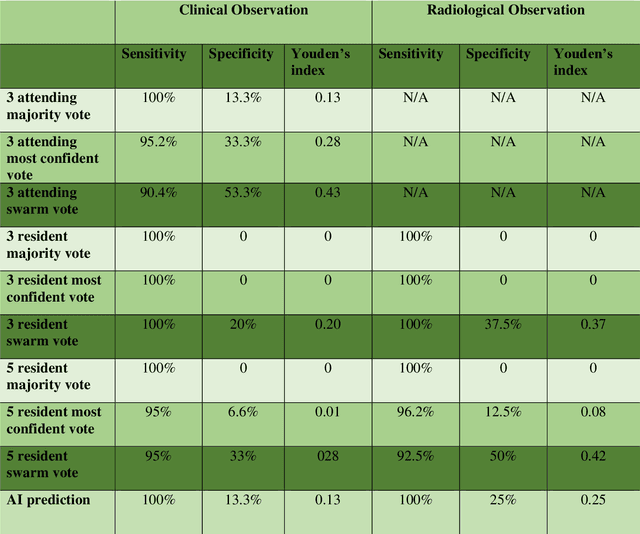
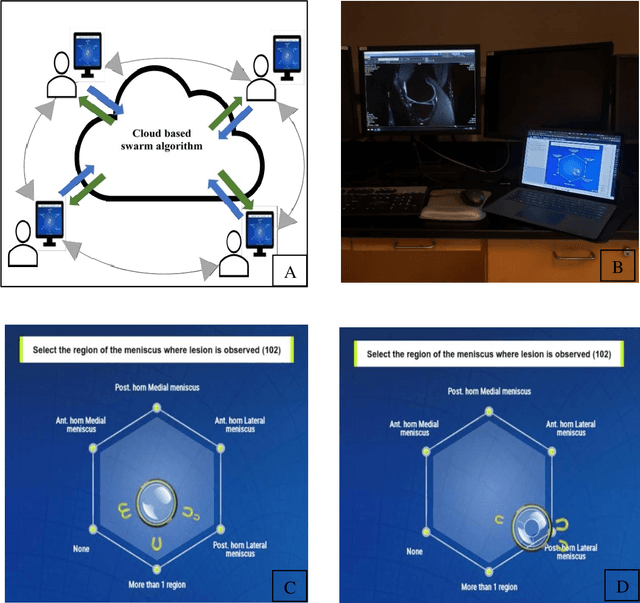
Radiologists today play a key role in making diagnostic decisions and labeling images for training A.I. algorithms. Low inter-reader reliability (IRR) can be seen between experts when interpreting challenging cases. While teams-based decisions are known to outperform individual decisions, inter-personal biases often creep up in group interactions which limit non-dominant participants from expressing true opinions. To overcome the dual problems of low consensus and inter-personal bias, we explored a solution modeled on biological swarms of bees. Two separate cohorts; three radiologists and five radiology residents collaborated on a digital swarm platform in real time and in a blinded fashion, grading meniscal lesions on knee MR exams. These consensus votes were benchmarked against clinical (arthroscopy) and radiological (senior-most radiologist) observations. The IRR of the consensus votes was compared to the IRR of the majority and most confident votes of the two cohorts.The radiologist cohort saw an improvement of 23% in IRR of swarm votes over majority vote. Similar improvement of 23% in IRR in 3-resident swarm votes over majority vote, was observed. The 5-resident swarm had an even higher improvement of 32% in IRR over majority vote. Swarm consensus votes also improved specificity by up to 50%. The swarm consensus votes outperformed individual and majority vote decisions in both the radiologists and resident cohorts. The 5-resident swarm had higher IRR than 3-resident swarm indicating positive effect of increased swarm size. The attending and resident swarms also outperformed predictions from a state-of-the-art A.I. algorithm. Utilizing a digital swarm platform improved agreement and allows participants to express judgement free intent, resulting in superior clinical performance and robust A.I. training labels.
Boundary Conditions for Linear Exit Time Gradient Trajectories Around Saddle Points: Analysis and Algorithm
Jan 07, 2021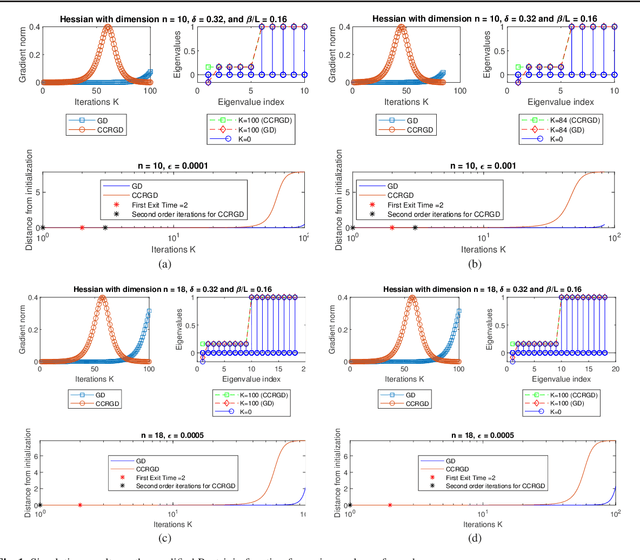
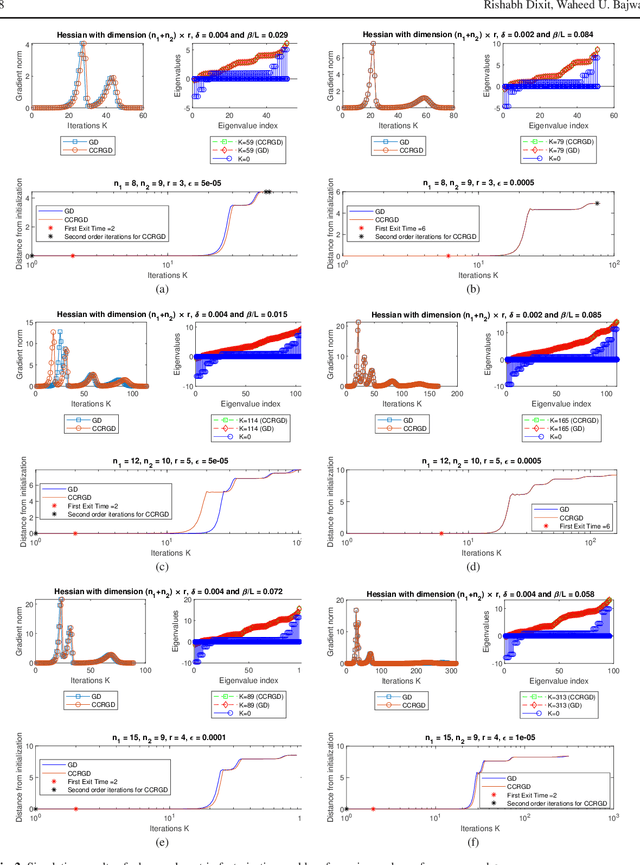
Gradient-related first-order methods have become the workhorse of large-scale numerical optimization problems. Many of these problems involve nonconvex objective functions with multiple saddle points, which necessitates an understanding of the behavior of discrete trajectories of first-order methods within the geometrical landscape of these functions. This paper concerns convergence of first-order discrete methods to a local minimum of nonconvex optimization problems that comprise strict saddle points within the geometrical landscape. To this end, it focuses on analysis of discrete gradient trajectories around saddle neighborhoods, derives sufficient conditions under which these trajectories can escape strict-saddle neighborhoods in linear time, explores the contractive and expansive dynamics of these trajectories in neighborhoods of strict-saddle points that are characterized by gradients of moderate magnitude, characterizes the non-curving nature of these trajectories, and highlights the inability of these trajectories to re-enter the neighborhoods around strict-saddle points after exiting them. Based on these insights and analyses, the paper then proposes a simple variant of the vanilla gradient descent algorithm, termed Curvature Conditioned Regularized Gradient Descent (CCRGD) algorithm, which utilizes a check for an initial boundary condition to ensure its trajectories can escape strict-saddle neighborhoods in linear time. Convergence analysis of the CCRGD algorithm, which includes its rate of convergence to a local minimum within a geometrical landscape that has a maximum number of strict-saddle points, is also presented in the paper. Numerical experiments are then provided on a test function as well as a low-rank matrix factorization problem to evaluate the efficacy of the proposed algorithm.
Subspace Change-Point Detection via Low-Rank Matrix Factorisation
Oct 08, 2021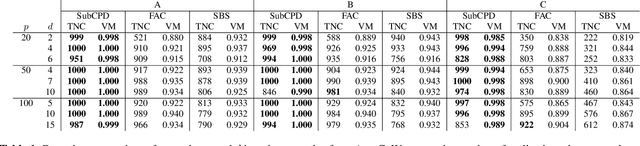

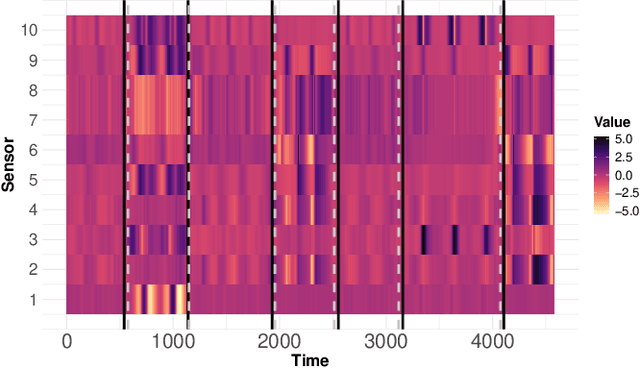
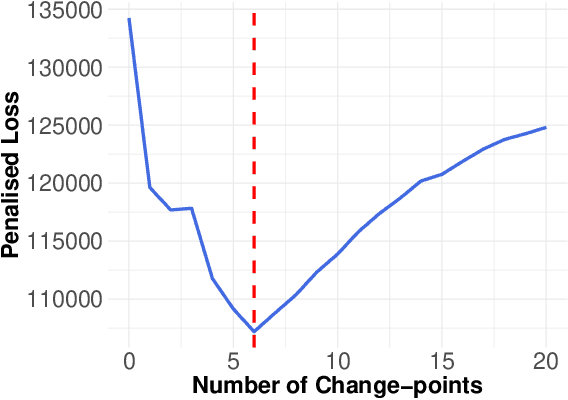
Multivariate time series can often have a large number of dimensions, whether it is due to the vast amount of collected features or due to how the data sources are processed. Frequently, the main structure of the high-dimensional time series can be well represented by a lower dimensional subspace. As vast quantities of data are being collected over long periods of time, it is reasonable to assume that the underlying subspace structure would change over time. In this work, we propose a change-point detection method based on low-rank matrix factorisation that can detect multiple changes in the underlying subspace of a multivariate time series. Experimental results on both synthetic and real data sets demonstrate the effectiveness of our approach and its advantages against various state-of-the-art methods.
Adjoint-aided inference of Gaussian process driven differential equations
Feb 09, 2022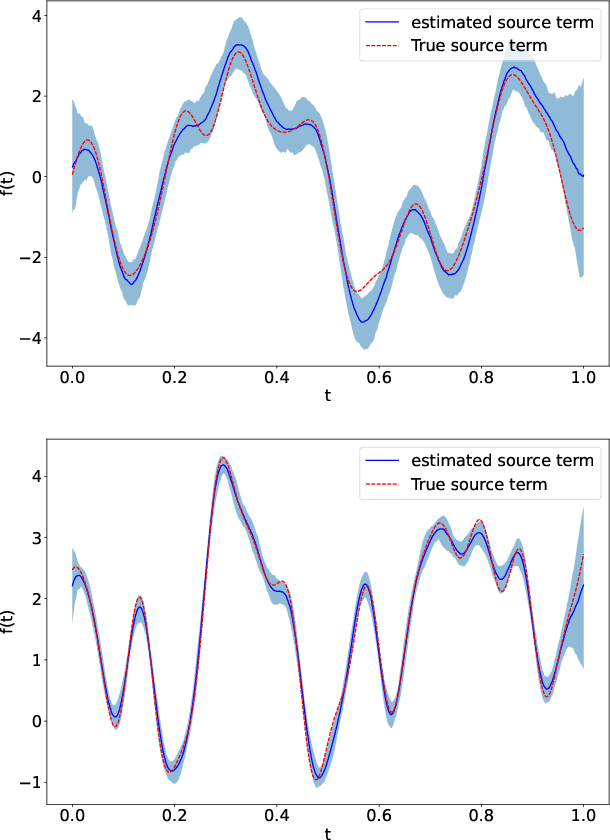
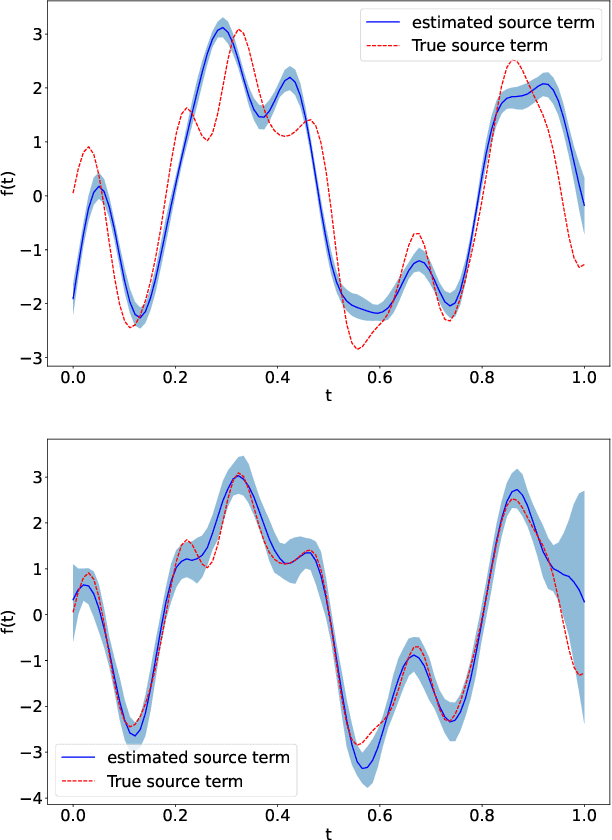
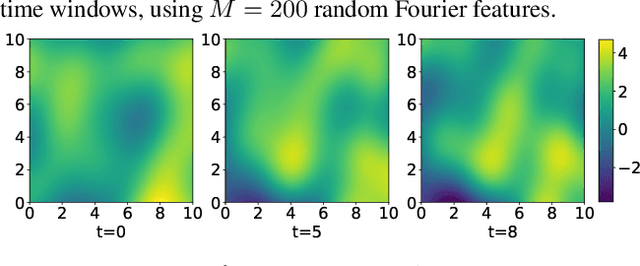
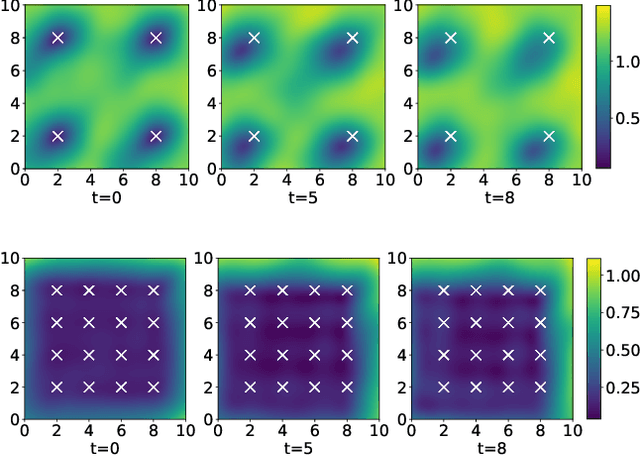
Linear systems occur throughout engineering and the sciences, most notably as differential equations. In many cases the forcing function for the system is unknown, and interest lies in using noisy observations of the system to infer the forcing, as well as other unknown parameters. In differential equations, the forcing function is an unknown function of the independent variables (typically time and space), and can be modelled as a Gaussian process (GP). In this paper we show how the adjoint of a linear system can be used to efficiently infer forcing functions modelled as GPs, after using a truncated basis expansion of the GP kernel. We show how exact conjugate Bayesian inference for the truncated GP can be achieved, in many cases with substantially lower computation than would be required using MCMC methods. We demonstrate the approach on systems of both ordinary and partial differential equations, and by testing on synthetic data, show that the basis expansion approach approximates well the true forcing with a modest number of basis vectors. Finally, we show how to infer point estimates for the non-linear model parameters, such as the kernel length-scales, using Bayesian optimisation.
Fourier ptychography multi-parameter neural network with composite physical priori optimization
Feb 18, 2022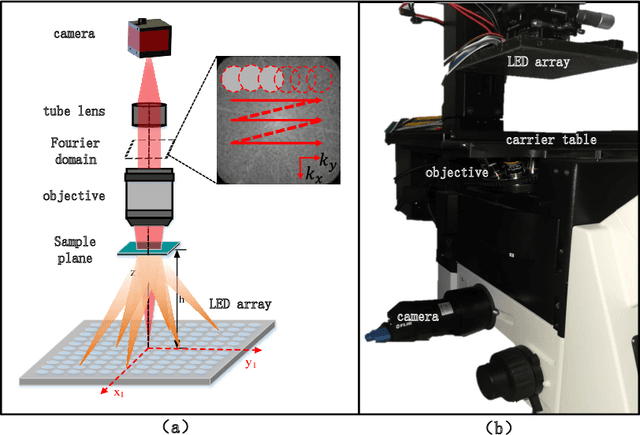
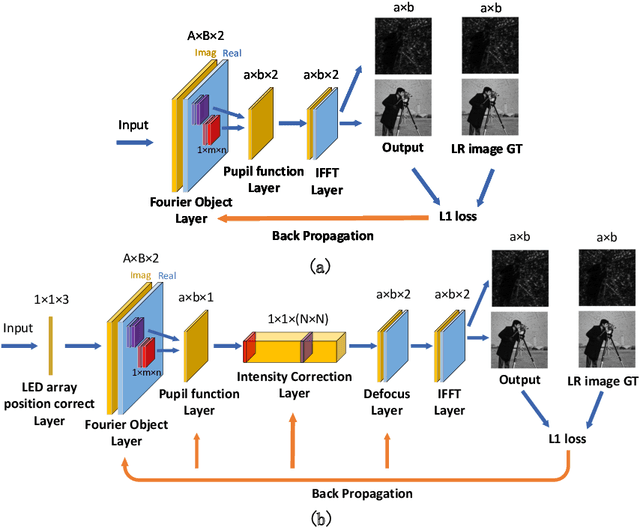
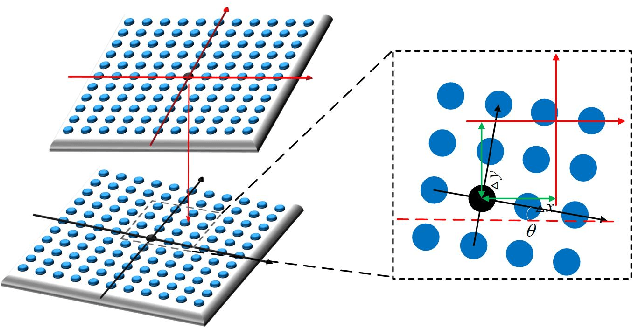
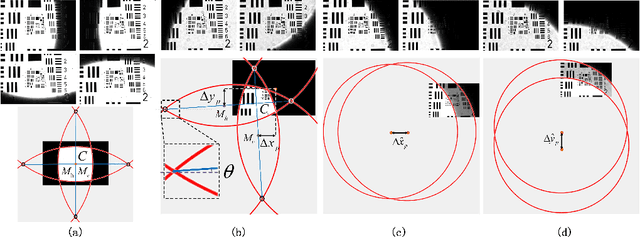
Fourier ptychography microscopy(FP) is a recently developed computational imaging approach for microscopic super-resolution imaging. By turning on each light-emitting-diode (LED) located on different position on the LED array sequentially and acquiring the corresponding images that contain different spatial frequency components, high spatial resolution and quantitative phase imaging can be achieved in the case of large field-of-view. Nevertheless, FPM has high requirements for the system construction and data acquisition processes, such as precise LEDs position, accurate focusing and appropriate exposure time, which brings many limitations to its practical applications. In this paper, inspired by artificial neural network, we propose a Fourier ptychography multi-parameter neural network (FPMN) with composite physical prior optimization. A hybrid parameter determination strategy combining physical imaging model and data-driven network training is proposed to recover the multi layers of the network corresponding to different physical parameters, including sample complex function, system pupil function, defocus distance, LED array position deviation and illumination intensity fluctuation, etc. Among these parameters, LED array position deviation is recovered based on the features of brightfield to darkfield transition low-resolution images while the others are recovered in the process of training of the neural network. The feasibility and effectiveness of FPMN are verified through simulations and actual experiments. Therefore FPMN can evidently reduce the requirement for practical applications of FPM.