 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes
Jan 22, 2022
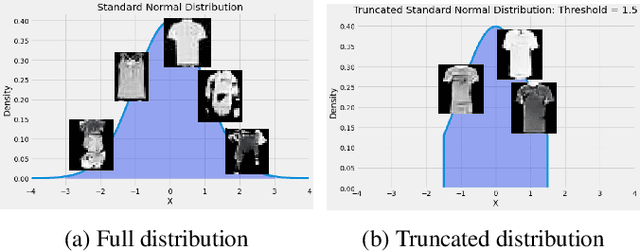
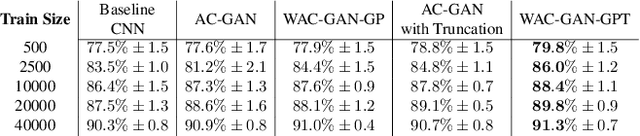
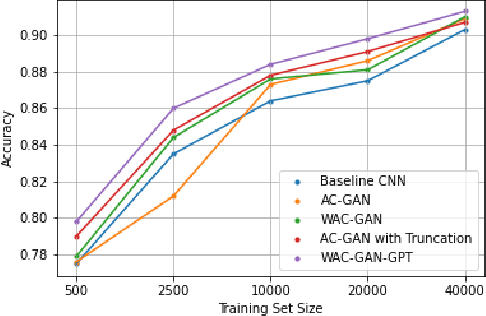
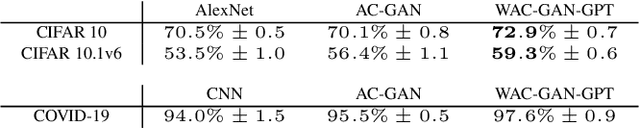
Generative Adversarial Networks (GANs) have shown promise in augmenting datasets and boosting convolutional neural networks' (CNN) performance on image classification tasks. But they introduce more hyperparameters to tune as well as the need for additional time and computational power to train supplementary to the CNN. In this work, we examine the potential for Auxiliary-Classifier GANs (AC-GANs) as a 'one-stop-shop' architecture for image classification, particularly in low data regimes. Additionally, we explore modifications to the typical AC-GAN framework, changing the generator's latent space sampling scheme and employing a Wasserstein loss with gradient penalty to stabilize the simultaneous training of image synthesis and classification. Through experiments on images of varying resolutions and complexity, we demonstrate that AC-GANs show promise in image classification, achieving competitive performance with standard CNNs. These methods can be employed as an 'all-in-one' framework with particular utility in the absence of large amounts of training data.
Regret Minimization with Performative Feedback
Feb 01, 2022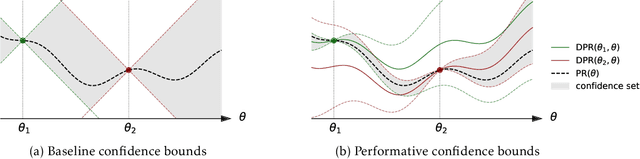
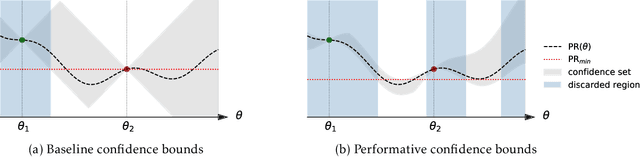
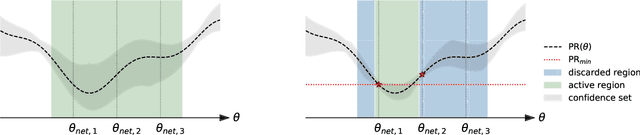
In performative prediction, the deployment of a predictive model triggers a shift in the data distribution. As these shifts are typically unknown ahead of time, the learner needs to deploy a model to get feedback about the distribution it induces. We study the problem of finding near-optimal models under performativity while maintaining low regret. On the surface, this problem might seem equivalent to a bandit problem. However, it exhibits a fundamentally richer feedback structure that we refer to as performative feedback: after every deployment, the learner receives samples from the shifted distribution rather than only bandit feedback about the reward. Our main contribution is regret bounds that scale only with the complexity of the distribution shifts and not that of the reward function. The key algorithmic idea is careful exploration of the distribution shifts that informs a novel construction of confidence bounds on the risk of unexplored models. The construction only relies on smoothness of the shifts and does not assume convexity. More broadly, our work establishes a conceptual approach for leveraging tools from the bandits literature for the purpose of regret minimization with performative feedback.
A General, Evolution-Inspired Reward Function for Social Robotics
Feb 01, 2022The field of social robotics will likely need to depart from a paradigm of designed behaviours and imitation learning and adopt modern reinforcement learning (RL) methods to enable robots to interact fluidly and efficaciously with humans. In this paper, we present the Social Reward Function as a mechanism to provide (1) a real-time, dense reward function necessary for the deployment of RL agents in social robotics, and (2) a standardised objective metric for comparing the efficacy of different social robots. The Social Reward Function is designed to closely mimic those genetically endowed social perception capabilities of humans in an effort to provide a simple, stable and culture-agnostic reward function. Presently, datasets used in social robotics are either small or significantly out-of-domain with respect to social robotics. The use of the Social Reward Function will allow larger in-domain datasets to be collected close to the behaviour policy of social robots, which will allow both further improvements to reward functions and to the behaviour policies of social robots. We believe this will be the key enabler to developing efficacious social robots in the future.
A Time-dependent SIR model for COVID-19
Feb 28, 2020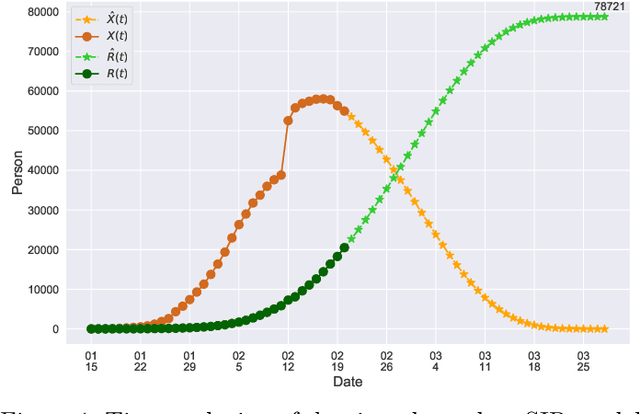
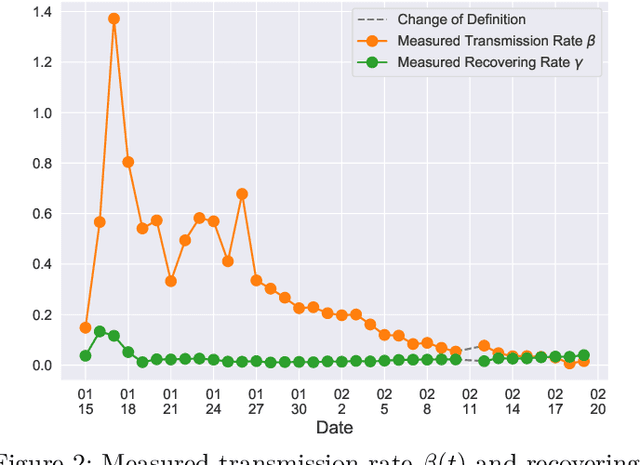
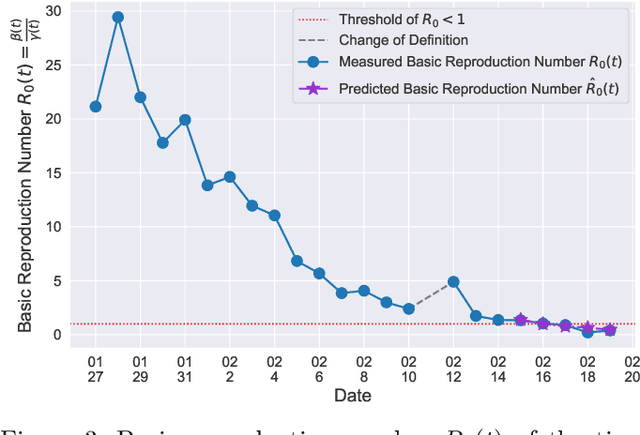
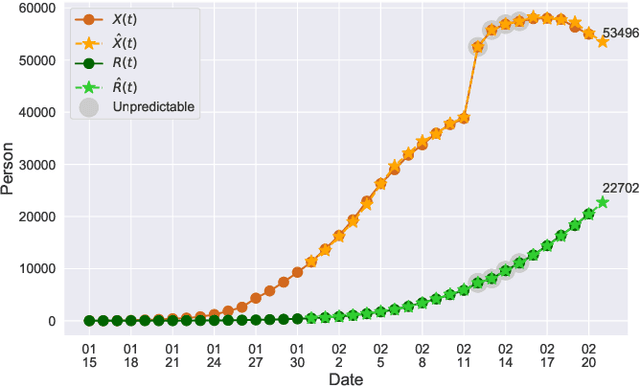
In this paper, we propose a mathematical model for analyzing and predicting the number of confirmed cases of COVID-19. Our model is a time-dependent susceptible-infected-recovered (SIR) model that tracks two time series: (i) the transmission rate at time $t$ and (ii) the recovering rate at time $t$. Our time-dependent SIR method is better than the traditional static SIR model as it can adapt to the change of contagious disease control policies such as city lockdowns. Moreover, it is also more robust than the direct estimation of the number of confirmed cases, as a sudden change of the definition of the number of confirmed cases might result in a spike of the number of new cases. Using the data set provided by the National Health Commission of the People's Republic of China (NHC) [2], we show that the one-day prediction errors for the numbers of confirmed cases are less than $3\%$ except the day when the definition of the number of confirmed cases is changed. Also, the turning point, defined as the day that the transmission rate is less than the recovering rate, is predicted to be Feb. 17, 2020. After that day, the basic reproduction number, known as the $R_0(t)$ value, is less than $1$ if the current contagious disease control policies are maintained in China. In that case, the total number of confirmed cases is predicted to be less than $80,000$ cases in China under our deterministic model.
Analysis of Evolutionary Algorithms on Fitness Function with Time-linkage Property
Apr 29, 2020In real-world applications, many optimization problems have the time-linkage property, that is, the objective function value relies on the current solution as well as the historical solutions. Although the rigorous theoretical analysis on evolutionary algorithms has rapidly developed in recent two decades, it remains an open problem to theoretically understand the behaviors of evolutionary algorithms on time-linkage problems. This paper takes the first step to rigorously analyze evolutionary algorithms for time-linkage functions. Based on the basic OneMax function, we propose a time-linkage function where the first bit value of the last time step is integrated but has a different preference from the current first bit. We prove that with probability $1-o(1)$, randomized local search and $(1+1)$ EA cannot find the optimum, and with probability $1-o(1)$, $(\mu+1)$ EA is able to reach the optimum.
Multi-cell Non-coherent Over-the-Air Computation for Federated Edge Learning
Feb 01, 2022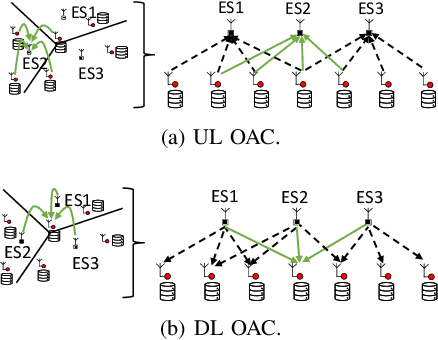
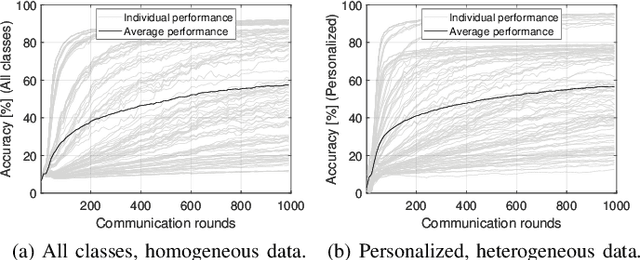
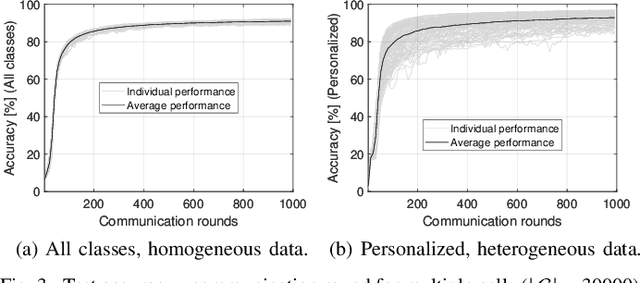
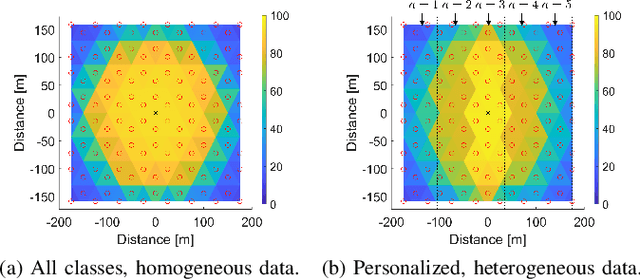
In this paper, we propose a framework where over-the-air computation (OAC) occurs in both uplink (UL) and downlink (DL), sequentially, in a multi-cell environment to address the latency and the scalability issues of federated edge learning (FEEL). To eliminate the channel state information (CSI) at the edge devices (EDs) and edge servers (ESs) and relax the time-synchronization requirement for the OAC, we use a non-coherent computation scheme, i.e., frequency-shift keying (FSK)-based majority vote (MV) (FSK-MV). With the proposed framework, multiple ESs function as the aggregation nodes in the UL and each ES determines the MVs independently. After the ESs broadcast the detected MVs, the EDs determine the sign of the gradient through another OAC in the DL. Hence, inter-cell interference is exploited for the OAC. In this study, we prove the convergence of the non-convex optimization problem for the FEEL with the proposed OAC framework. We also numerically evaluate the efficacy of the proposed method by comparing the test accuracy in both multi-cell and single-cell scenarios for both homogeneous and heterogeneous data distributions.
Adaptive Model Predictive Control of Wheeled Mobile Robots
Jan 03, 2022
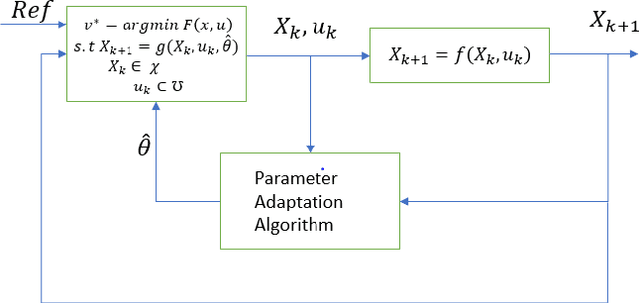
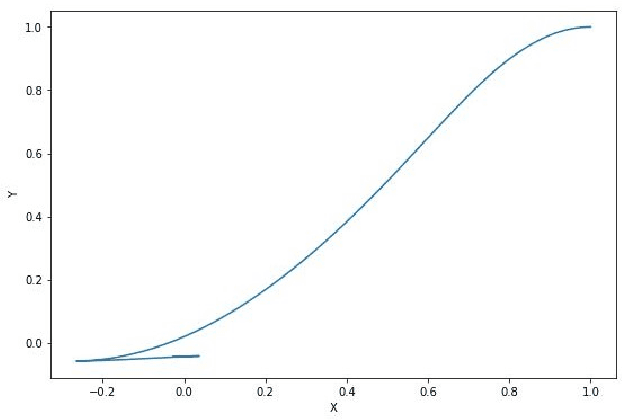
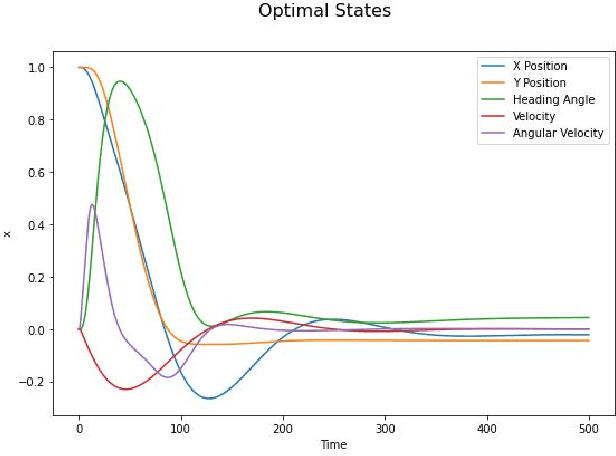
In this paper, a control algorithm for guiding a two wheeled mobile robot with unknown inertia to a desired point and orientation using an Adaptive Model Predictive Control (AMPC) framework is presented. The two wheeled mobile robot is modeled as a knife edge or a skate with nonholonomic kinematic constraints and the dynamical equations are derived using the Lagrangian approach. The inputs at every time instant are obtained from Model Predictive Control (MPC) with a set of nominal parameters which are updated using a recursive least squares algorithm. The efficacy of the algorithm is demonstrated through numerical simulations at the end of the paper.
On Theoretical Complexity and Boolean Satisfiability
Dec 22, 2021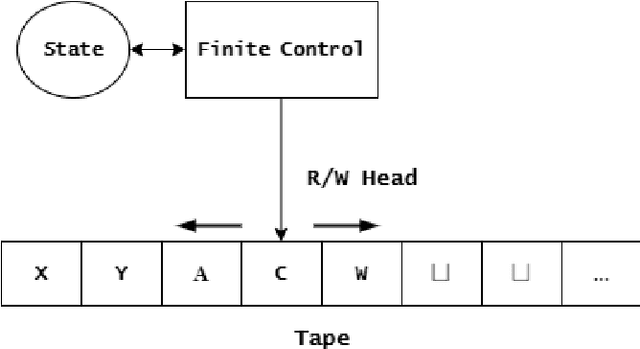

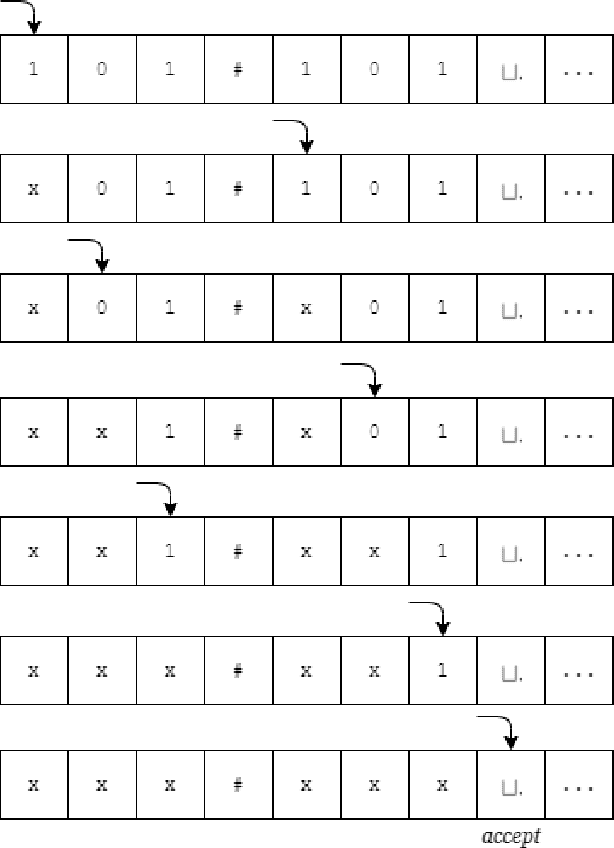

Theoretical complexity is a vital subfield of computer science that enables us to mathematically investigate computation and answer many interesting queries about the nature of computational problems. It provides theoretical tools to assess time and space requirements of computations along with assessing the difficultly of problems - classifying them accordingly. It also garners at its core one of the most important problems in mathematics, namely, the $\textbf{P vs. NP}$ millennium problem. In essence, this problem asks whether solution and verification reside on two different levels of difficulty. In this thesis, we introduce some of the most central concepts in the Theory of Computing, giving an overview of how computation can be abstracted using Turing machines. Further, we introduce the two most famous problem complexity classes $\textbf{P}$ and $\textbf{NP}$ along with the relationship between them. In addition, we explicate the concept of problem reduction and how it is an essential tool for making hardness comparisons between different problems. Later, we present the problem of Boolean Satisfiability (SAT) which lies at the center of NP-complete problems. We then explore some of its tractable as well as intractable variants such as Horn-SAT and 3-SAT, respectively. Last but not least, we establish polynomial-time reductions from 3-SAT to some of the famous NP-complete graph problems, namely, Clique Finding, Hamiltonian Cycle Finding, and 3-Coloring.
Dual-CLVSA: a Novel Deep Learning Approach to Predict Financial Markets with Sentiment Measurements
Jan 27, 2022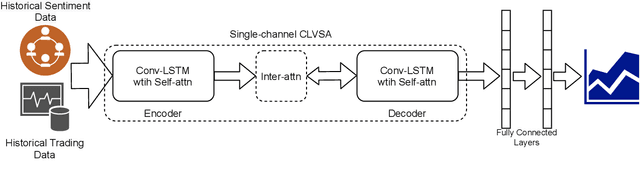
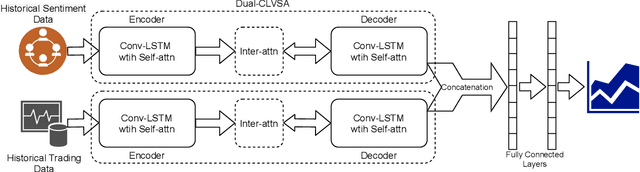
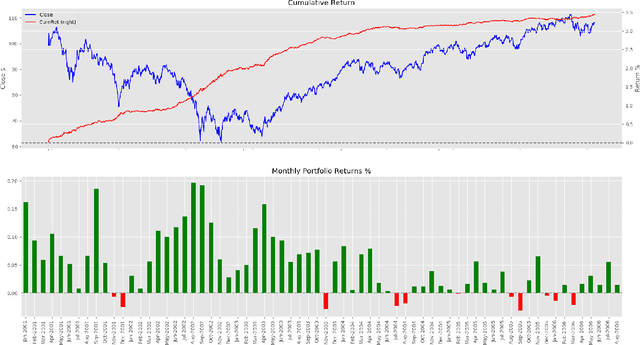
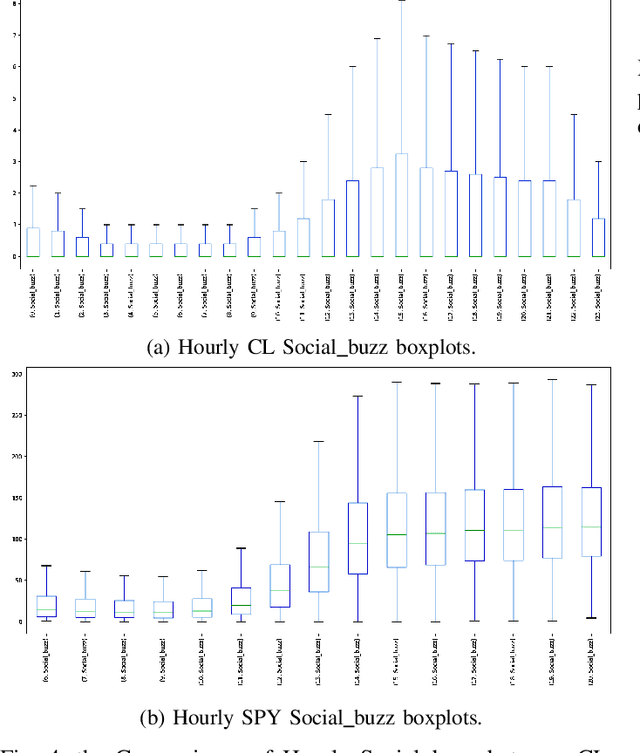
It is a challenging task to predict financial markets. The complexity of this task is mainly due to the interaction between financial markets and market participants, who are not able to keep rational all the time, and often affected by emotions such as fear and ecstasy. Based on the state-of-the-art approach particularly for financial market predictions, a hybrid convolutional LSTM Based variational sequence-to-sequence model with attention (CLVSA), we propose a novel deep learning approach, named dual-CLVSA, to predict financial market movement with both trading data and the corresponding social sentiment measurements, each through a separate sequence-to-sequence channel. We evaluate the performance of our approach with backtesting on historical trading data of SPDR SP 500 Trust ETF over eight years. The experiment results show that dual-CLVSA can effectively fuse the two types of data, and verify that sentiment measurements are not only informative for financial market predictions, but they also contain extra profitable features to boost the performance of our predicting system.
Generative Adversarial Network (GAN) and Enhanced Root Mean Square Error (ERMSE): Deep Learning for Stock Price Movement Prediction
Nov 30, 2021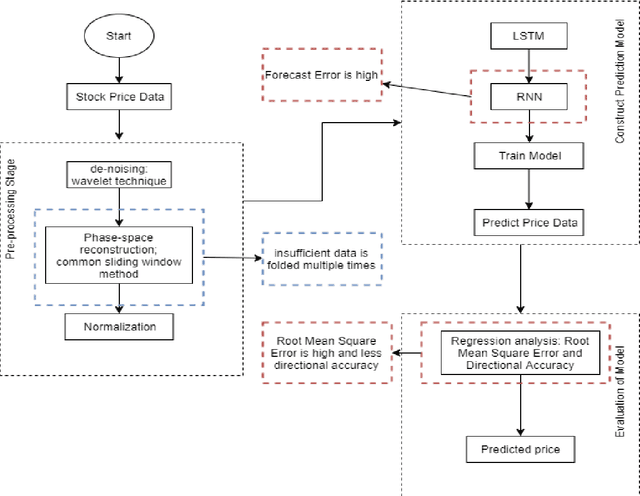
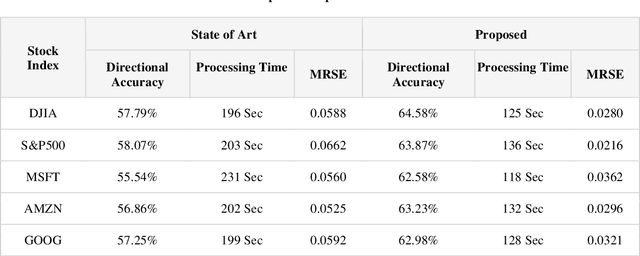
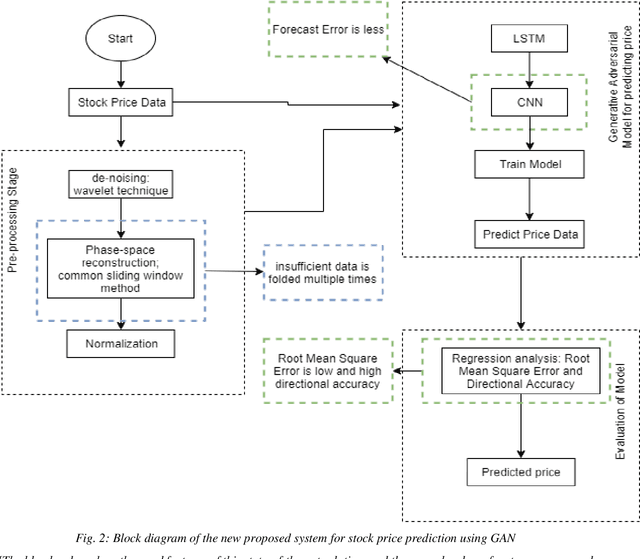
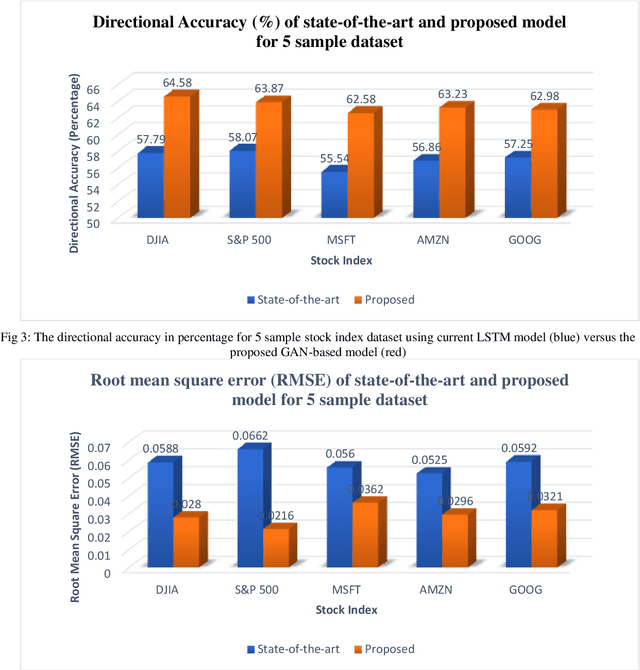
The prediction of stock price movement direction is significant in financial circles and academic. Stock price contains complex, incomplete, and fuzzy information which makes it an extremely difficult task to predict its development trend. Predicting and analysing financial data is a nonlinear, time-dependent problem. With rapid development in machine learning and deep learning, this task can be performed more effectively by a purposely designed network. This paper aims to improve prediction accuracy and minimizing forecasting error loss through deep learning architecture by using Generative Adversarial Networks. It was proposed a generic model consisting of Phase-space Reconstruction (PSR) method for reconstructing price series and Generative Adversarial Network (GAN) which is a combination of two neural networks which are Long Short-Term Memory (LSTM) as Generative model and Convolutional Neural Network (CNN) as Discriminative model for adversarial training to forecast the stock market. LSTM will generate new instances based on historical basic indicators information and then CNN will estimate whether the data is predicted by LSTM or is real. It was found that the Generative Adversarial Network (GAN) has performed well on the enhanced root mean square error to LSTM, as it was 4.35% more accurate in predicting the direction and reduced processing time and RMSE by 78 secs and 0.029, respectively. This study provides a better result in the accuracy of the stock index. It seems that the proposed system concentrates on minimizing the root mean square error and processing time and improving the direction prediction accuracy, and provides a better result in the accuracy of the stock index.