 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Objective measurement of pitch extractors' responses to frequency modulated sounds and two reference pitch extraction methods for analyzing voice pitch responses to auditory stimulation
Nov 05, 2021
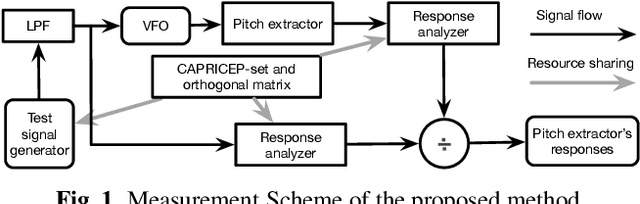
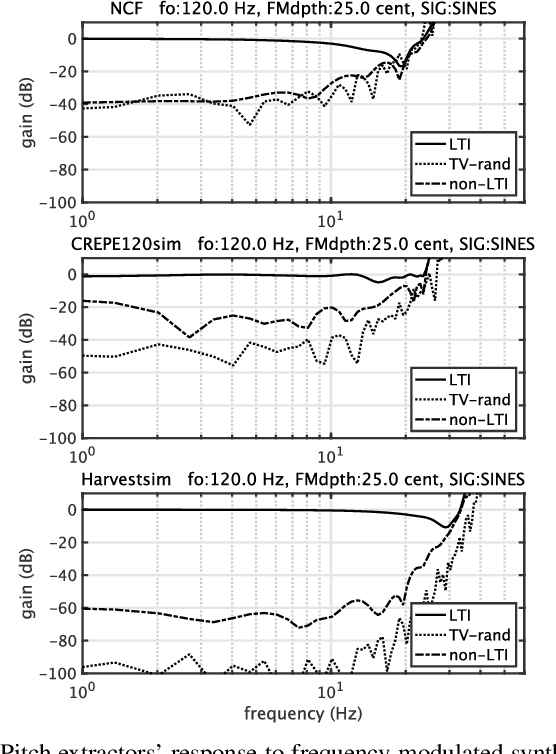
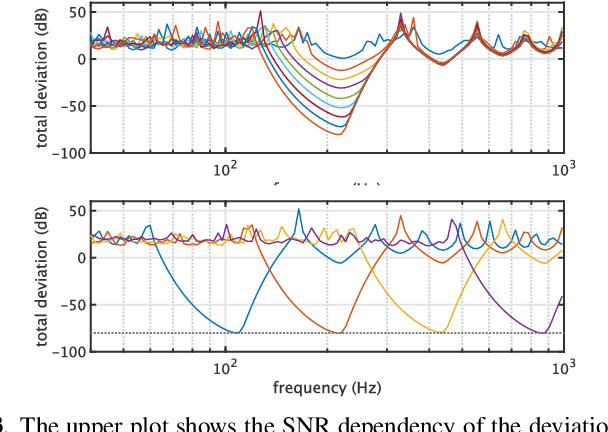
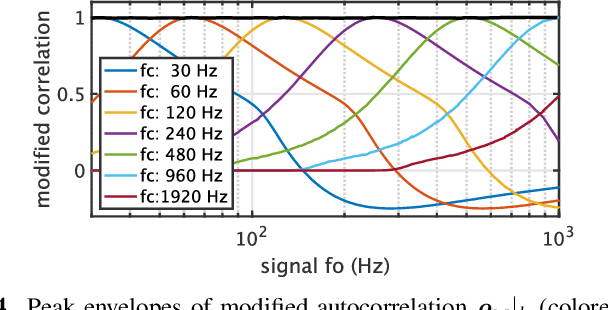
We propose an objective measurement method for pitch extractors' responses to frequency-modulated signals. The method simultaneously measures the linear and the non-linear time-invariant responses and random and time-varying responses. It uses extended time-stretched pulses combined by binary orthogonal sequences. Our recent finding of involuntary voice pitch response to auditory stimulation while voicing motivated this proposal. The involuntary voice pitch response provides means to investigate voice chain subsystems individually and objectively. This response analysis requires reliable and precise pitch extraction. We found that existing pitch extractors failed to correctly analyze signals used for auditory stimulation by using the proposed method. Therefore, we propose two reference pitch extractors based on the instantaneous frequency analysis and multi-resolution power spectrum analysis. The proposed extractors correctly analyze the test signals. We open-sourced MATLAB codes to measure pitch extractors and codes for conducting the voice pitch response experiment on our GitHub repository.
Fast and Robust Registration of Partially Overlapping Point Clouds
Dec 18, 2021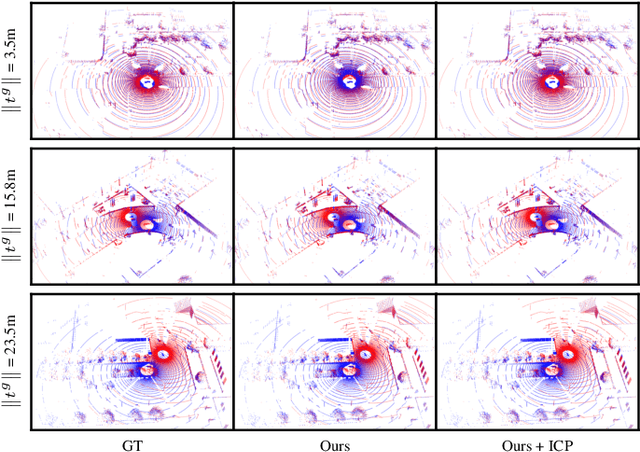

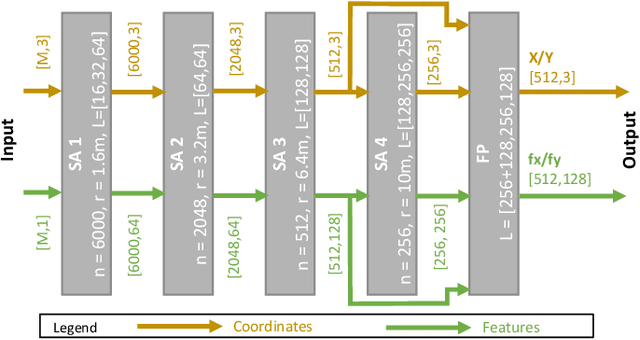
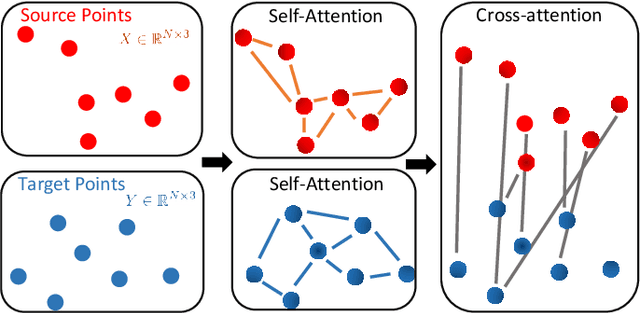
Real-time registration of partially overlapping point clouds has emerging applications in cooperative perception for autonomous vehicles and multi-agent SLAM. The relative translation between point clouds in these applications is higher than in traditional SLAM and odometry applications, which challenges the identification of correspondences and a successful registration. In this paper, we propose a novel registration method for partially overlapping point clouds where correspondences are learned using an efficient point-wise feature encoder, and refined using a graph-based attention network. This attention network exploits geometrical relationships between key points to improve the matching in point clouds with low overlap. At inference time, the relative pose transformation is obtained by robustly fitting the correspondences through sample consensus. The evaluation is performed on the KITTI dataset and a novel synthetic dataset including low-overlapping point clouds with displacements of up to 30m. The proposed method achieves on-par performance with state-of-the-art methods on the KITTI dataset, and outperforms existing methods for low overlapping point clouds. Additionally, the proposed method achieves significantly faster inference times, as low as 410ms, between 5 and 35 times faster than competing methods. Our code and dataset are available at https://github.com/eduardohenriquearnold/fastreg.
Safe Linear Leveling Bandits
Dec 13, 2021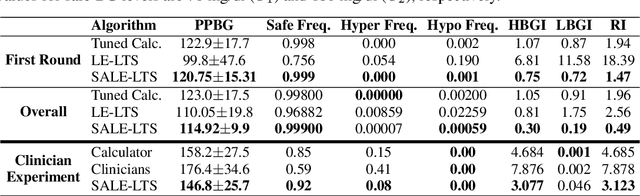
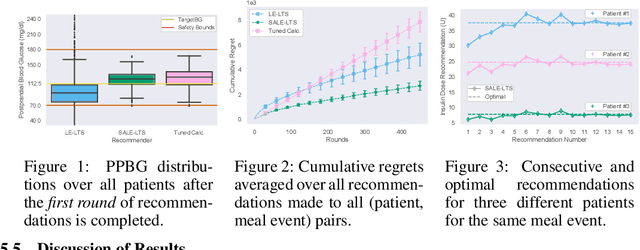
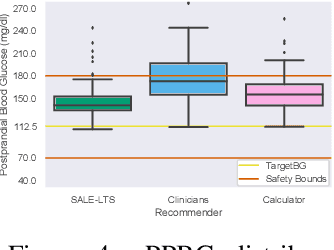
Multi-armed bandits (MAB) are extensively studied in various settings where the objective is to \textit{maximize} the actions' outcomes (i.e., rewards) over time. Since safety is crucial in many real-world problems, safe versions of MAB algorithms have also garnered considerable interest. In this work, we tackle a different critical task through the lens of \textit{linear stochastic bandits}, where the aim is to keep the actions' outcomes close to a target level while respecting a \textit{two-sided} safety constraint, which we call \textit{leveling}. Such a task is prevalent in numerous domains. Many healthcare problems, for instance, require keeping a physiological variable in a range and preferably close to a target level. The radical change in our objective necessitates a new acquisition strategy, which is at the heart of a MAB algorithm. We propose SALE-LTS: Safe Leveling via Linear Thompson Sampling algorithm, with a novel acquisition strategy to accommodate our task and show that it achieves sublinear regret with the same time and dimension dependence as previous works on the classical reward maximization problem absent any safety constraint. We demonstrate and discuss our algorithm's empirical performance in detail via thorough experiments.
Robust Gaussian Covariance Estimation in Nearly-Matrix Multiplication Time
Jun 23, 2020Robust covariance estimation is the following, well-studied problem in high dimensional statistics: given $N$ samples from a $d$-dimensional Gaussian $\mathcal{N}(\boldsymbol{0}, \Sigma)$, but where an $\varepsilon$-fraction of the samples have been arbitrarily corrupted, output $\widehat{\Sigma}$ minimizing the total variation distance between $\mathcal{N}(\boldsymbol{0}, \Sigma)$ and $\mathcal{N}(\boldsymbol{0}, \widehat{\Sigma})$. This corresponds to learning $\Sigma$ in a natural affine-invariant variant of the Frobenius norm known as the \emph{Mahalanobis norm}. Previous work of Cheng et al demonstrated an algorithm that, given $N = \Omega (d^2 / \varepsilon^2)$ samples, achieved a near-optimal error of $O(\varepsilon \log 1 / \varepsilon)$, and moreover, their algorithm ran in time $\widetilde{O}(T(N, d) \log \kappa / \mathrm{poly} (\varepsilon))$, where $T(N, d)$ is the time it takes to multiply a $d \times N$ matrix by its transpose, and $\kappa$ is the condition number of $\Sigma$. When $\varepsilon$ is relatively small, their polynomial dependence on $1/\varepsilon$ in the runtime is prohibitively large. In this paper, we demonstrate a novel algorithm that achieves the same statistical guarantees, but which runs in time $\widetilde{O} (T(N, d) \log \kappa)$. In particular, our runtime has no dependence on $\varepsilon$. When $\Sigma$ is reasonably conditioned, our runtime matches that of the fastest algorithm for covariance estimation without outliers, up to poly-logarithmic factors, showing that we can get robustness essentially "for free."
Safe Online Convex Optimization with Unknown Linear Safety Constraints
Nov 14, 2021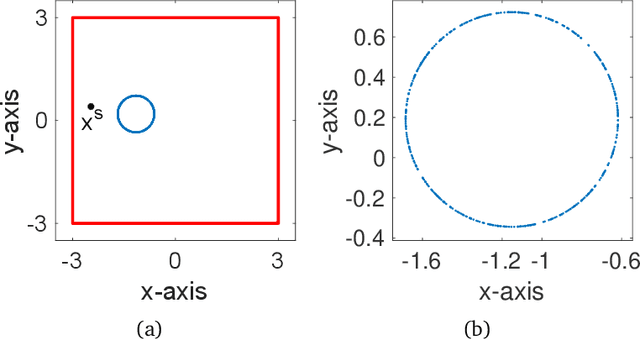
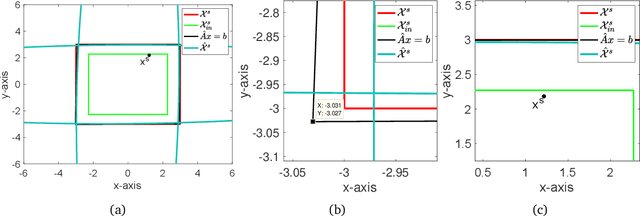
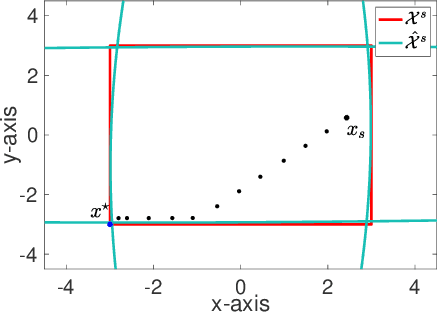
We study the problem of safe online convex optimization, where the action at each time step must satisfy a set of linear safety constraints. The goal is to select a sequence of actions to minimize the regret without violating the safety constraints at any time step (with high probability). The parameters that specify the linear safety constraints are unknown to the algorithm. The algorithm has access to only the noisy observations of constraints for the chosen actions. We propose an algorithm, called the {Safe Online Projected Gradient Descent} (SO-PGD) algorithm, to address this problem. We show that, under the assumption of the availability of a safe baseline action, the SO-PGD algorithm achieves a regret $O(T^{2/3})$. While there are many algorithms for online convex optimization (OCO) problems with safety constraints available in the literature, they allow constraint violations during learning/optimization, and the focus has been on characterizing the cumulative constraint violations. To the best of our knowledge, ours is the first work that provides an algorithm with provable guarantees on the regret, without violating the linear safety constraints (with high probability) at any time step.
Effect of Human Involvement on Work Performance and Fluency in Human-Robot Collaboration for Recycling
Jan 20, 2022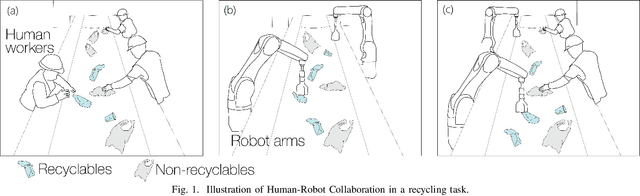


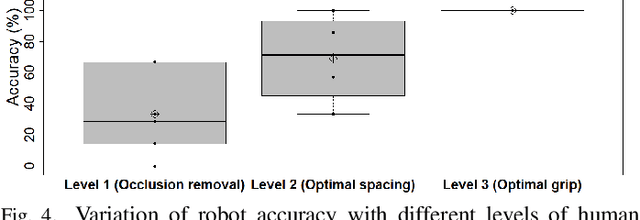
Human-robot collaboration has significant potential in recycling due to the wide variation in the composition of recyclable products. Six participants performed a recyclable item sorting task collaborating with a robot arm equipped with a vision system. The effect of three different levels of human involvement or assistance to the robot (Level 1- occlusion removal; Level 2- optimal spacing; Level 3- optimal grip) on performance metrics such as robot accuracy, task time and subjective fluency were assessed. Results showed that human involvement had a remarkable impact on the robot's accuracy, which increased with human involvement level. Mean accuracy values were 33.3% for Level 1, 69% for Level 2 and 100% for Level 3. The results imply that for sorting processes involving diverse materials that vary in size, shape, and composition, human assistance could improve the robot's accuracy to a significant extent while also being cost-effective.
Conformal prediction for the design problem
Feb 10, 2022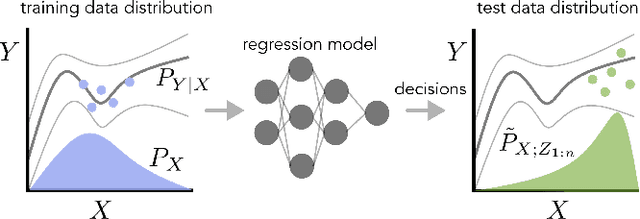
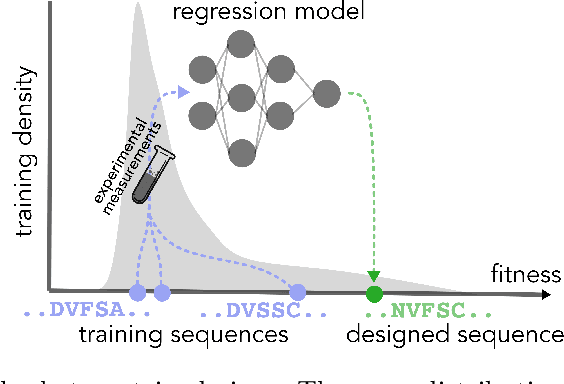
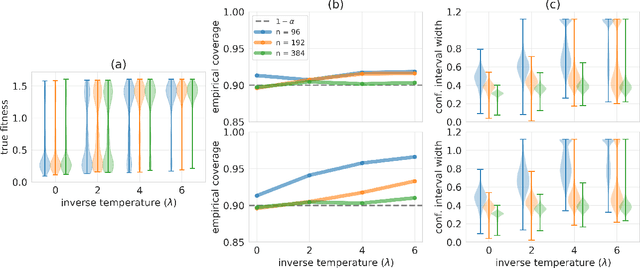
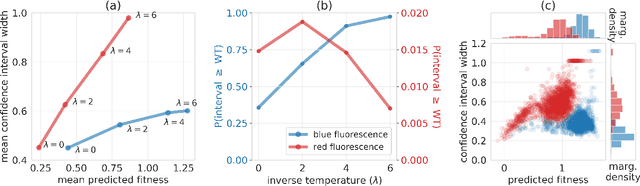
In many real-world deployments of machine learning, we use a prediction algorithm to choose what data to test next. For example, in the protein design problem, we have a regression model that predicts some real-valued property of a protein sequence, which we use to propose new sequences believed to exhibit higher property values than observed in the training data. Since validating designed sequences in the wet lab is typically costly, it is important to know how much we can trust the model's predictions. In such settings, however, there is a distinct type of distribution shift between the training and test data: one where the training and test data are statistically dependent, as the latter is chosen based on the former. Consequently, the model's error on the test data -- that is, the designed sequences -- has some non-trivial relationship with its error on the training data. Herein, we introduce a method to quantify predictive uncertainty in such settings. We do so by constructing confidence sets for predictions that account for the dependence between the training and test data. The confidence sets we construct have finite-sample guarantees that hold for any prediction algorithm, even when a trained model chooses the test-time input distribution. As a motivating use case, we demonstrate how our method quantifies uncertainty for the predicted fitness of designed protein using real data sets.
A probabilistic model for fast-to-evaluate 2D crack path prediction in heterogeneous materials
Dec 27, 2021


This paper is devoted to the construction of a new fast-to-evaluate model for the prediction of 2D crack paths in concrete-like microstructures. The model generates piecewise linear cracks paths with segmentation points selected using a Markov chain model. The Markov chain kernel involves local indicators of mechanical interest and its parameters are learnt from numerical full-field 2D simulations of craking using a cohesive-volumetric finite element solver called XPER. The resulting model exhibits a drastic improvement of CPU time in comparison to simulations from XPER.
Point Cloud Compression for Efficient Data Broadcasting: A Performance Comparison
Feb 01, 2022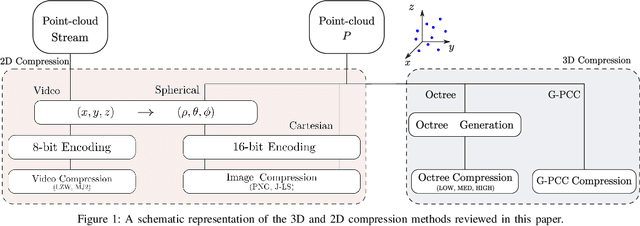
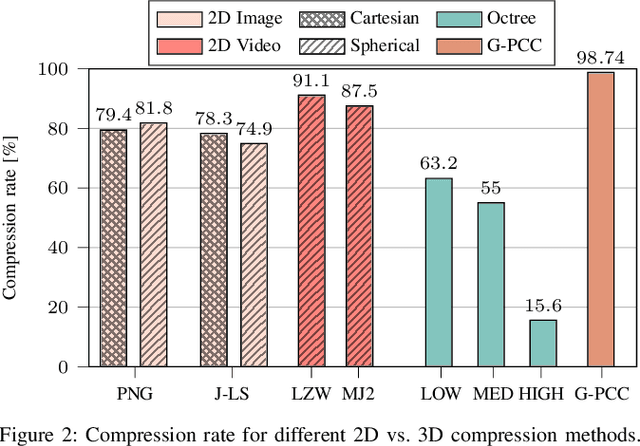
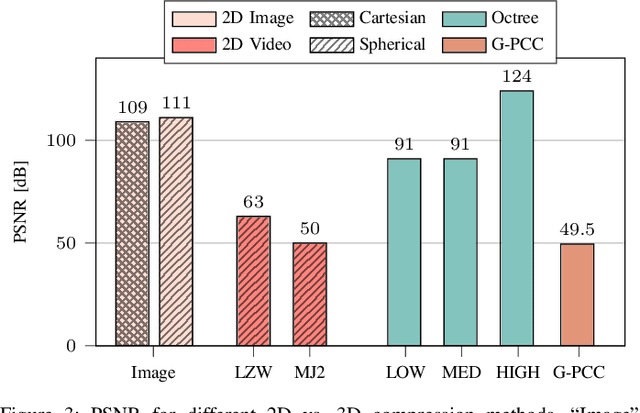
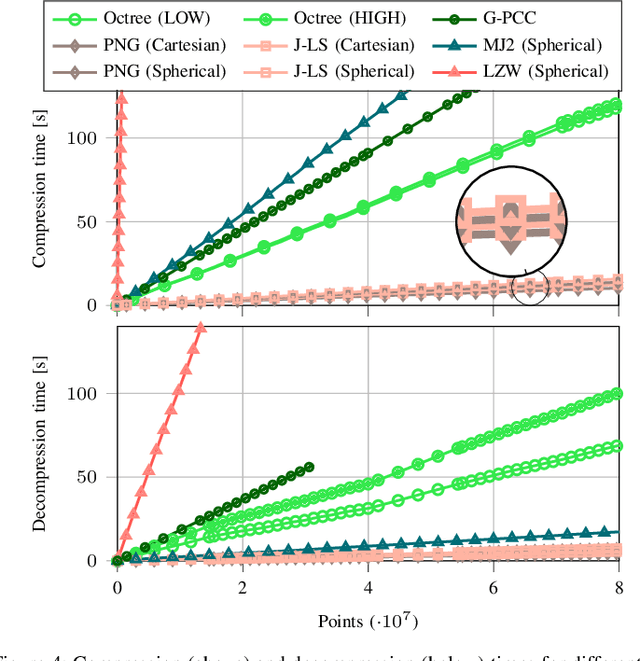
The worldwide commercialization of fifth generation (5G) wireless networks and the exciting possibilities offered by connected and autonomous vehicles (CAVs) are pushing toward the deployment of heterogeneous sensors for tracking dynamic objects in the automotive environment. Among them, Light Detection and Ranging (LiDAR) sensors are witnessing a surge in popularity as their application to vehicular networks seem particularly promising. LiDARs can indeed produce a three-dimensional (3D) mapping of the surrounding environment, which can be used for object detection, recognition, and topography. These data are encoded as a point cloud which, when transmitted, may pose significant challenges to the communication systems as it can easily congest the wireless channel. Along these lines, this paper investigates how to compress point clouds in a fast and efficient way. Both 2D- and a 3D-oriented approaches are considered, and the performance of the corresponding techniques is analyzed in terms of (de)compression time, efficiency, and quality of the decompressed frame compared to the original. We demonstrate that, thanks to the matrix form in which LiDAR frames are saved, compression methods that are typically applied for 2D images give equivalent results, if not better, than those specifically designed for 3D point clouds.
Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes
Jan 22, 2022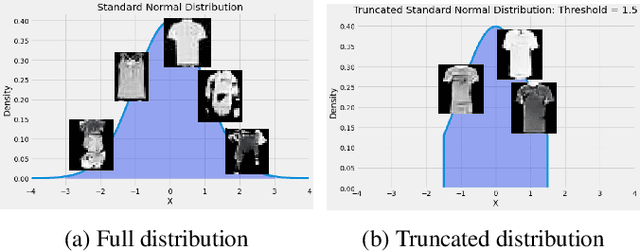
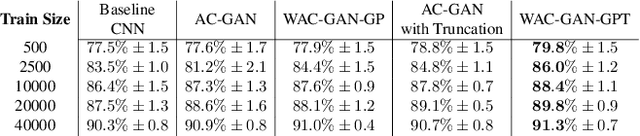
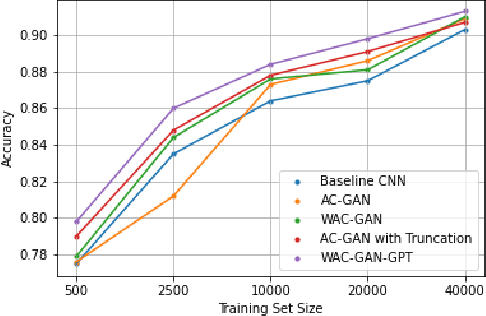
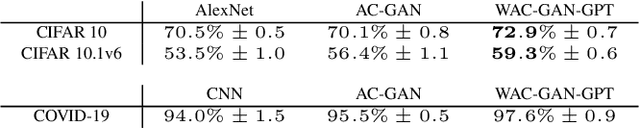
Generative Adversarial Networks (GANs) have shown promise in augmenting datasets and boosting convolutional neural networks' (CNN) performance on image classification tasks. But they introduce more hyperparameters to tune as well as the need for additional time and computational power to train supplementary to the CNN. In this work, we examine the potential for Auxiliary-Classifier GANs (AC-GANs) as a 'one-stop-shop' architecture for image classification, particularly in low data regimes. Additionally, we explore modifications to the typical AC-GAN framework, changing the generator's latent space sampling scheme and employing a Wasserstein loss with gradient penalty to stabilize the simultaneous training of image synthesis and classification. Through experiments on images of varying resolutions and complexity, we demonstrate that AC-GANs show promise in image classification, achieving competitive performance with standard CNNs. These methods can be employed as an 'all-in-one' framework with particular utility in the absence of large amounts of training data.