 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Auto-X3D: Ultra-Efficient Video Understanding via Finer-Grained Neural Architecture Search
Dec 09, 2021
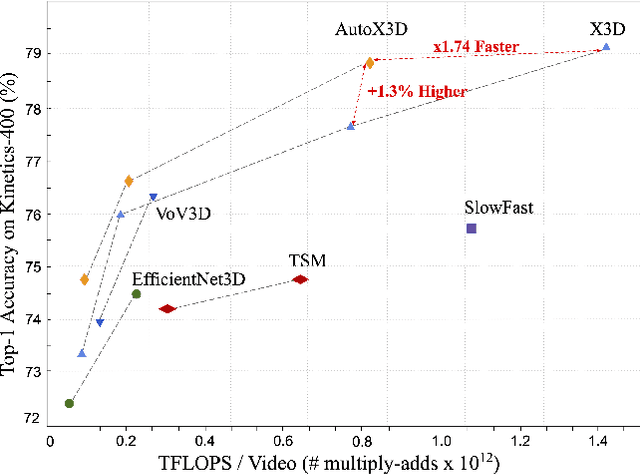

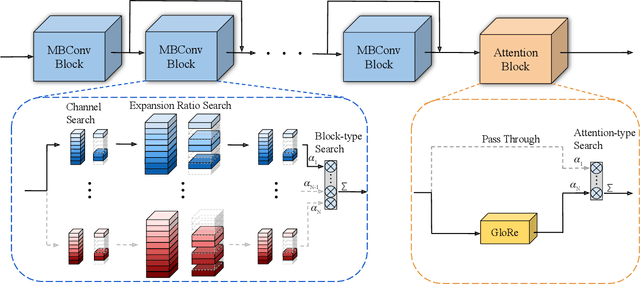
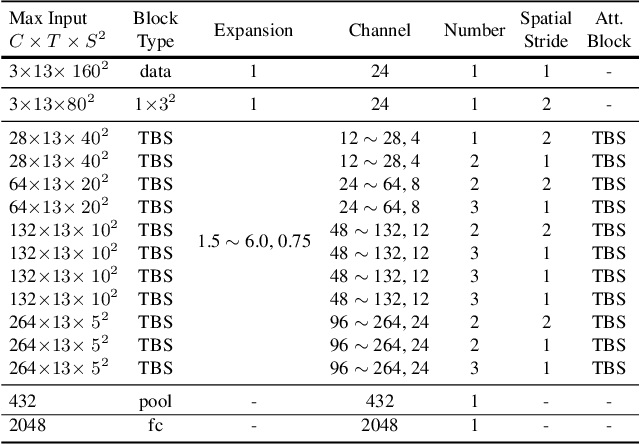
Efficient video architecture is the key to deploying video recognition systems on devices with limited computing resources. Unfortunately, existing video architectures are often computationally intensive and not suitable for such applications. The recent X3D work presents a new family of efficient video models by expanding a hand-crafted image architecture along multiple axes, such as space, time, width, and depth. Although operating in a conceptually large space, X3D searches one axis at a time, and merely explored a small set of 30 architectures in total, which does not sufficiently explore the space. This paper bypasses existing 2D architectures, and directly searched for 3D architectures in a fine-grained space, where block type, filter number, expansion ratio and attention block are jointly searched. A probabilistic neural architecture search method is adopted to efficiently search in such a large space. Evaluations on Kinetics and Something-Something-V2 benchmarks confirm our AutoX3D models outperform existing ones in accuracy up to 1.3% under similar FLOPs, and reduce the computational cost up to x1.74 when reaching similar performance.
Few-shot Unsupervised Domain Adaptation for Multi-modal Cardiac Image Segmentation
Jan 28, 2022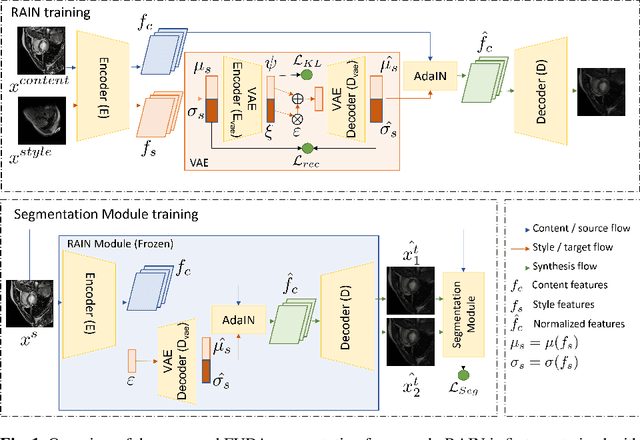
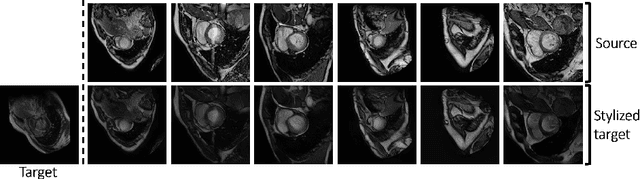

Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by using unlabeled target domain and labeled source domain data, however, in the medical domain, target domain data may not always be easily available, and acquiring new samples is generally time-consuming. This restricts the development of UDA methods for new domains. In this paper, we explore the potential of UDA in a more challenging while realistic scenario where only one unlabeled target patient sample is available. We call it Few-shot Unsupervised Domain adaptation (FUDA). We first generate target-style images from source images and explore diverse target styles from a single target patient with Random Adaptive Instance Normalization (RAIN). Then, a segmentation network is trained in a supervised manner with the generated target images. Our experiments demonstrate that FUDA improves the segmentation performance by 0.33 of Dice score on the target domain compared with the baseline, and it also gives 0.28 of Dice score improvement in a more rigorous one-shot setting. Our code is available at \url{https://github.com/MingxuanGu/Few-shot-UDA}.
Robust Gaussian Covariance Estimation in Nearly-Matrix Multiplication Time
Jun 23, 2020Robust covariance estimation is the following, well-studied problem in high dimensional statistics: given $N$ samples from a $d$-dimensional Gaussian $\mathcal{N}(\boldsymbol{0}, \Sigma)$, but where an $\varepsilon$-fraction of the samples have been arbitrarily corrupted, output $\widehat{\Sigma}$ minimizing the total variation distance between $\mathcal{N}(\boldsymbol{0}, \Sigma)$ and $\mathcal{N}(\boldsymbol{0}, \widehat{\Sigma})$. This corresponds to learning $\Sigma$ in a natural affine-invariant variant of the Frobenius norm known as the \emph{Mahalanobis norm}. Previous work of Cheng et al demonstrated an algorithm that, given $N = \Omega (d^2 / \varepsilon^2)$ samples, achieved a near-optimal error of $O(\varepsilon \log 1 / \varepsilon)$, and moreover, their algorithm ran in time $\widetilde{O}(T(N, d) \log \kappa / \mathrm{poly} (\varepsilon))$, where $T(N, d)$ is the time it takes to multiply a $d \times N$ matrix by its transpose, and $\kappa$ is the condition number of $\Sigma$. When $\varepsilon$ is relatively small, their polynomial dependence on $1/\varepsilon$ in the runtime is prohibitively large. In this paper, we demonstrate a novel algorithm that achieves the same statistical guarantees, but which runs in time $\widetilde{O} (T(N, d) \log \kappa)$. In particular, our runtime has no dependence on $\varepsilon$. When $\Sigma$ is reasonably conditioned, our runtime matches that of the fastest algorithm for covariance estimation without outliers, up to poly-logarithmic factors, showing that we can get robustness essentially "for free."
Benchmarking Robustness of 3D Point Cloud Recognition Against Common Corruptions
Jan 28, 2022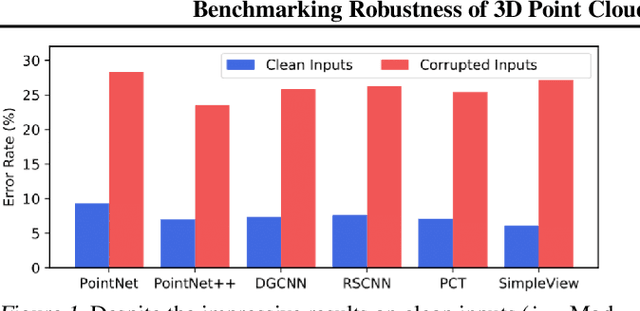
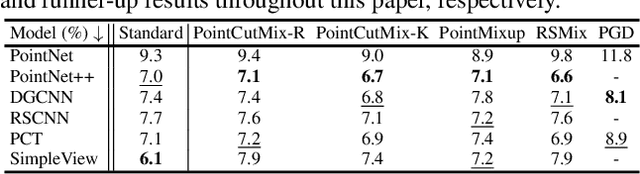
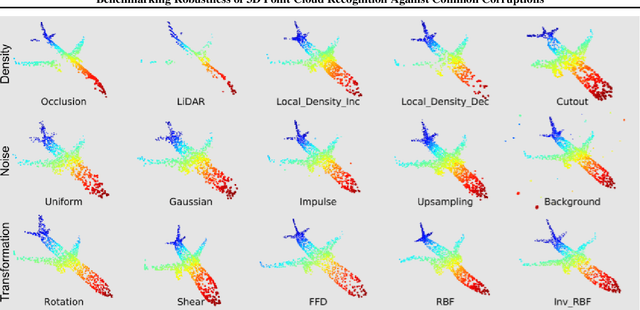

Deep neural networks on 3D point cloud data have been widely used in the real world, especially in safety-critical applications. However, their robustness against corruptions is less studied. In this paper, we present ModelNet40-C, the first comprehensive benchmark on 3D point cloud corruption robustness, consisting of 15 common and realistic corruptions. Our evaluation shows a significant gap between the performances on ModelNet40 and ModelNet40-C for state-of-the-art (SOTA) models. To reduce the gap, we propose a simple but effective method by combining PointCutMix-R and TENT after evaluating a wide range of augmentation and test-time adaptation strategies. We identify a number of critical insights for future studies on corruption robustness in point cloud recognition. For instance, we unveil that Transformer-based architectures with proper training recipes achieve the strongest robustness. We hope our in-depth analysis will motivate the development of robust training strategies or architecture designs in the 3D point cloud domain. Our codebase and dataset are included in https://github.com/jiachens/ModelNet40-C
A Private and Computationally-Efficient Estimator for Unbounded Gaussians
Nov 08, 2021
We give the first polynomial-time, polynomial-sample, differentially private estimator for the mean and covariance of an arbitrary Gaussian distribution $\mathcal{N}(\mu,\Sigma)$ in $\mathbb{R}^d$. All previous estimators are either nonconstructive, with unbounded running time, or require the user to specify a priori bounds on the parameters $\mu$ and $\Sigma$. The primary new technical tool in our algorithm is a new differentially private preconditioner that takes samples from an arbitrary Gaussian $\mathcal{N}(0,\Sigma)$ and returns a matrix $A$ such that $A \Sigma A^T$ has constant condition number.
Flexible learning of quantum states with generative query neural networks
Feb 14, 2022
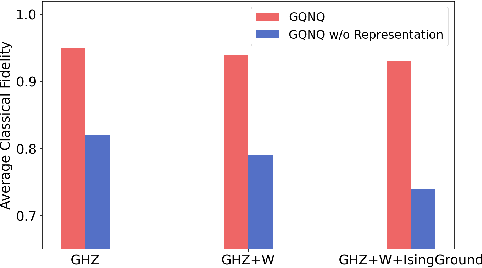
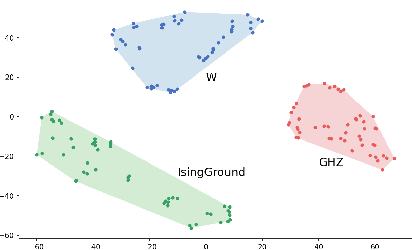
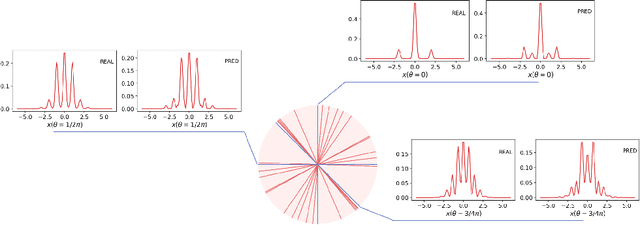
Deep neural networks are a powerful tool for characterizing quantum states. In this task, neural networks are typically trained with measurement data gathered from the quantum state to be characterized. But is it possible to train a neural network in a general-purpose way, which makes it applicable to multiple unknown quantum states? Here we show that learning across multiple quantum states and different measurement settings can be achieved by a generative query neural network, a type of neural network originally used in the classical domain for learning 3D scenes from 2D pictures. Our network can be trained offline with classically simulated data, and later be used to characterize unknown quantum states from real experimental data. With little guidance of quantum physics, the network builds its own data-driven representation of quantum states, and then uses it to predict the outcome probabilities of requested quantum measurements on the states of interest. This approach can be applied to state learning scenarios where quantum measurement settings are not informationally complete and predictions must be given in real time, as experimental data become available, as well as to adversarial scenarios where measurement choices and prediction requests are designed to expose learning inaccuracies. The internal representation produced by the network can be used for other tasks beyond state characterization, including clustering of states and prediction of physical properties. The features of our method are illustrated on many-qubit ground states of Ising model and continuous-variable non-Gaussian states.
Non-Stationary Dueling Bandits
Feb 02, 2022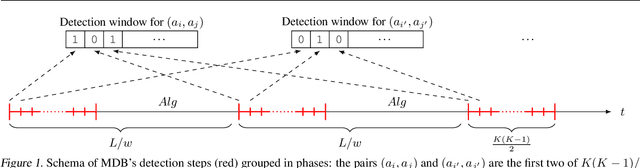
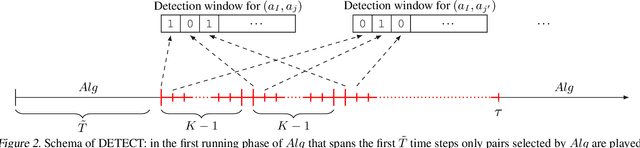


We study the non-stationary dueling bandits problem with $K$ arms, where the time horizon $T$ consists of $M$ stationary segments, each of which is associated with its own preference matrix. The learner repeatedly selects a pair of arms and observes a binary preference between them as feedback. To minimize the accumulated regret, the learner needs to pick the Condorcet winner of each stationary segment as often as possible, despite preference matrices and segment lengths being unknown. We propose the $\mathrm{Beat\, the\, Winner\, Reset}$ algorithm and prove a bound on its expected binary weak regret in the stationary case, which tightens the bound of current state-of-art algorithms. We also show a regret bound for the non-stationary case, without requiring knowledge of $M$ or $T$. We further propose and analyze two meta-algorithms, $\mathrm{DETECT}$ for weak regret and $\mathrm{Monitored\, Dueling\, Bandits}$ for strong regret, both based on a detection-window approach that can incorporate any dueling bandit algorithm as a black-box algorithm. Finally, we prove a worst-case lower bound for expected weak regret in the non-stationary case.
A Time-dependent SIR model for COVID-19
Feb 28, 2020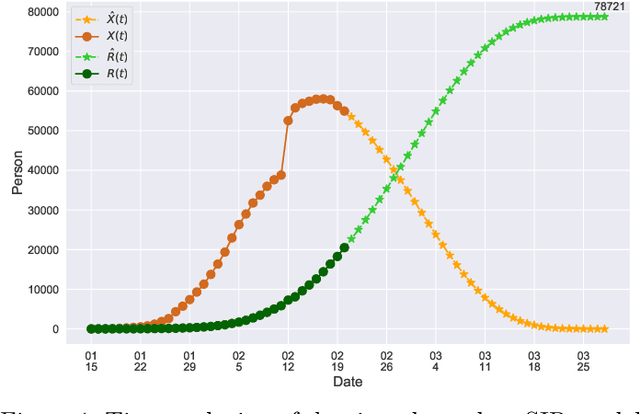
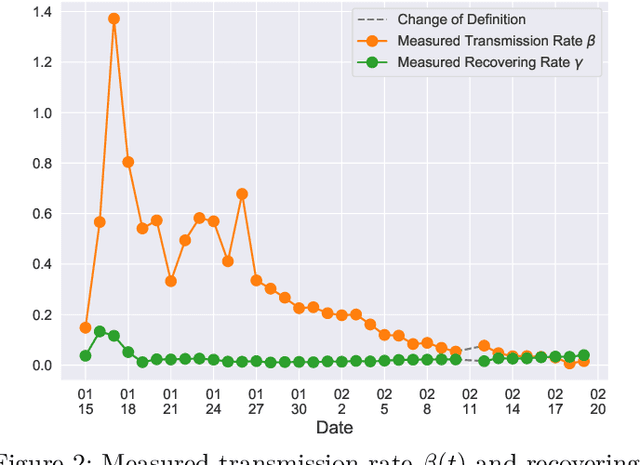
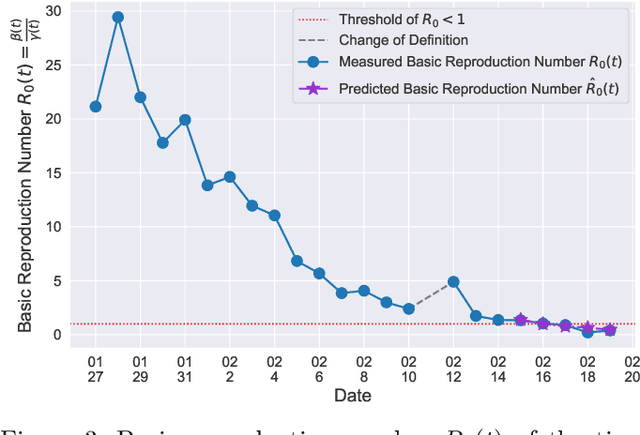
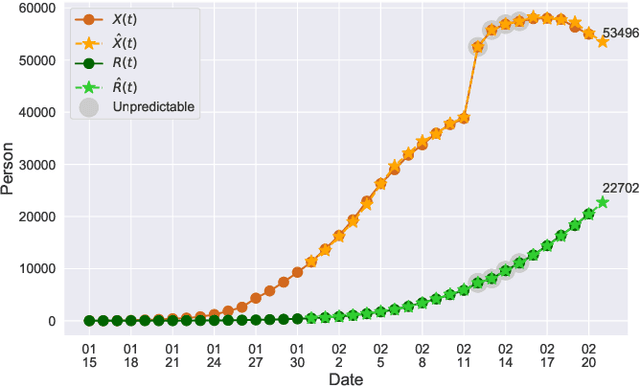
In this paper, we propose a mathematical model for analyzing and predicting the number of confirmed cases of COVID-19. Our model is a time-dependent susceptible-infected-recovered (SIR) model that tracks two time series: (i) the transmission rate at time $t$ and (ii) the recovering rate at time $t$. Our time-dependent SIR method is better than the traditional static SIR model as it can adapt to the change of contagious disease control policies such as city lockdowns. Moreover, it is also more robust than the direct estimation of the number of confirmed cases, as a sudden change of the definition of the number of confirmed cases might result in a spike of the number of new cases. Using the data set provided by the National Health Commission of the People's Republic of China (NHC) [2], we show that the one-day prediction errors for the numbers of confirmed cases are less than $3\%$ except the day when the definition of the number of confirmed cases is changed. Also, the turning point, defined as the day that the transmission rate is less than the recovering rate, is predicted to be Feb. 17, 2020. After that day, the basic reproduction number, known as the $R_0(t)$ value, is less than $1$ if the current contagious disease control policies are maintained in China. In that case, the total number of confirmed cases is predicted to be less than $80,000$ cases in China under our deterministic model.
Analysis of Evolutionary Algorithms on Fitness Function with Time-linkage Property
Apr 29, 2020In real-world applications, many optimization problems have the time-linkage property, that is, the objective function value relies on the current solution as well as the historical solutions. Although the rigorous theoretical analysis on evolutionary algorithms has rapidly developed in recent two decades, it remains an open problem to theoretically understand the behaviors of evolutionary algorithms on time-linkage problems. This paper takes the first step to rigorously analyze evolutionary algorithms for time-linkage functions. Based on the basic OneMax function, we propose a time-linkage function where the first bit value of the last time step is integrated but has a different preference from the current first bit. We prove that with probability $1-o(1)$, randomized local search and $(1+1)$ EA cannot find the optimum, and with probability $1-o(1)$, $(\mu+1)$ EA is able to reach the optimum.
Using Deep Learning to Bootstrap Abstractions for Hierarchical Robot Planning
Feb 02, 2022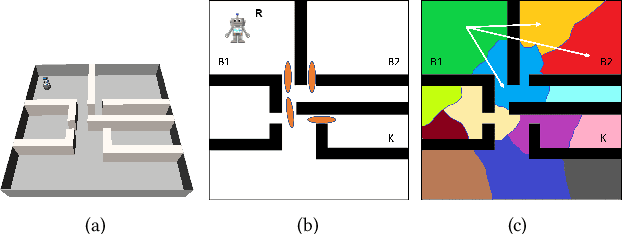
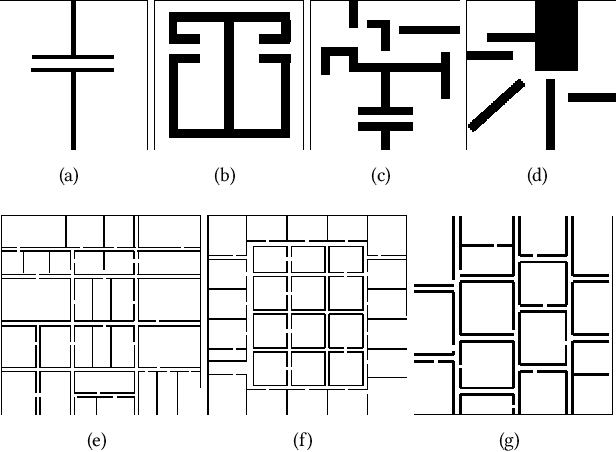
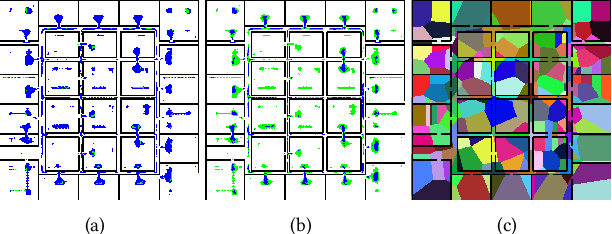
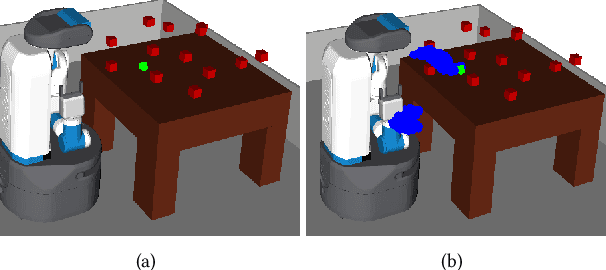
This paper addresses the problem of learning abstractions that boost robot planning performance while providing strong guarantees of reliability. Although state-of-the-art hierarchical robot planning algorithms allow robots to efficiently compute long-horizon motion plans for achieving user desired tasks, these methods typically rely upon environment-dependent state and action abstractions that need to be hand-designed by experts. We present a new approach for bootstrapping the entire hierarchical planning process. It shows how abstract states and actions for new environments can be computed automatically using the critical regions predicted by a deep neural-network with an auto-generated robot specific architecture. It uses the learned abstractions in a novel multi-source bi-directional hierarchical robot planning algorithm that is sound and probabilistically complete. An extensive empirical evaluation on twenty different settings using holonomic and non-holonomic robots shows that (a) the learned abstractions provide the information necessary for efficient multi-source hierarchical planning; and that (b) this approach of learning abstraction and planning outperforms state-of-the-art baselines by nearly a factor of ten in terms of planning time on test environments not seen during training.