 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic features of object concepts generated with GPT-3
Feb 08, 2022
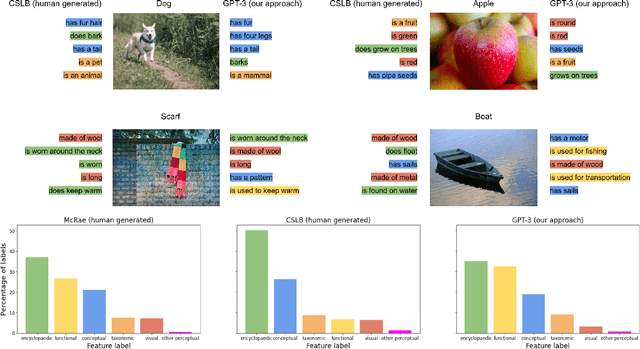

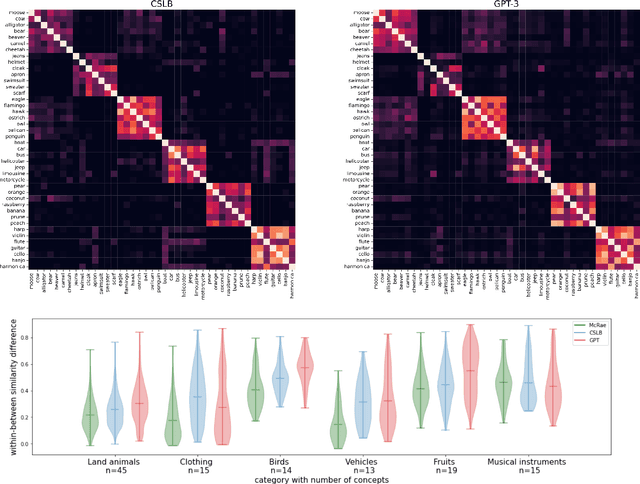
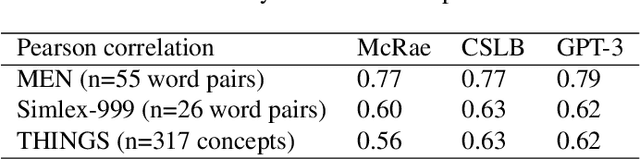
Semantic features have been playing a central role in investigating the nature of our conceptual representations. Yet the enormous time and effort required to empirically sample and norm features from human raters has restricted their use to a limited set of manually curated concepts. Given recent promising developments with transformer-based language models, here we asked whether it was possible to use such models to automatically generate meaningful lists of properties for arbitrary object concepts and whether these models would produce features similar to those found in humans. To this end, we probed a GPT-3 model to generate semantic features for 1,854 objects and compared automatically-generated features to existing human feature norms. GPT-3 generated many more features than humans, yet showed a similar distribution in the types of generated features. Generated feature norms rivaled human norms in predicting similarity, relatedness, and category membership, while variance partitioning demonstrated that these predictions were driven by similar variance in humans and GPT-3. Together, these results highlight the potential of large language models to capture important facets of human knowledge and yield a new approach for automatically generating interpretable feature sets, thus drastically expanding the potential use of semantic features in psychological and linguistic studies.
Real-time Pupil Tracking from Monocular Video for Digital Puppetry
Jun 19, 2020
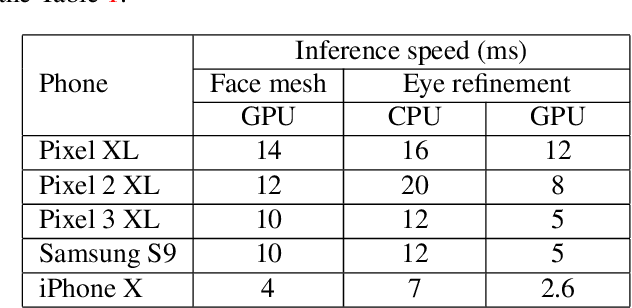
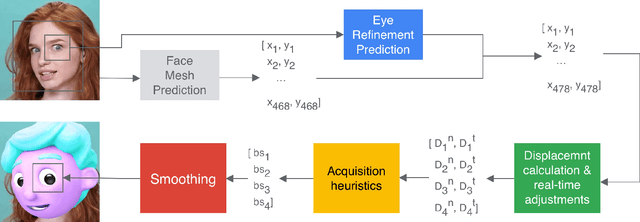
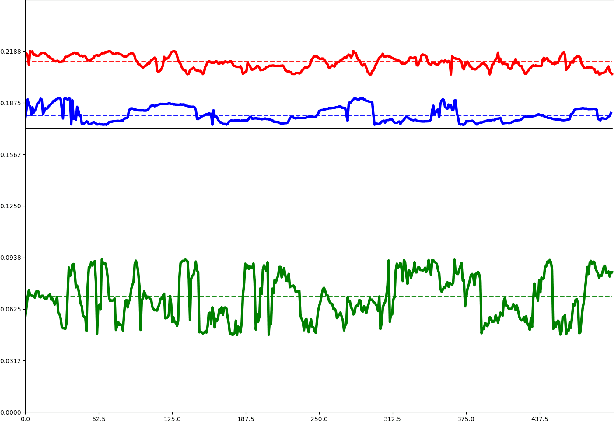
We present a simple, real-time approach for pupil tracking from live video on mobile devices. Our method extends a state-of-the-art face mesh detector with two new components: a tiny neural network that predicts positions of the pupils in 2D, and a displacement-based estimation of the pupil blend shape coefficients. Our technique can be used to accurately control the pupil movements of a virtual puppet, and lends liveliness and energy to it. The proposed approach runs at over 50 FPS on modern phones, and enables its usage in any real-time puppeteering pipeline.
Predicted Composite Signed-Distance Fields for Real-Time Motion Planning in Dynamic Environments
Aug 03, 2020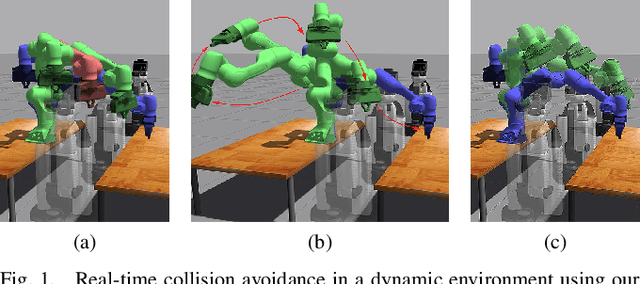
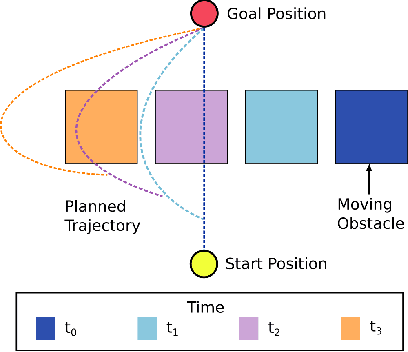
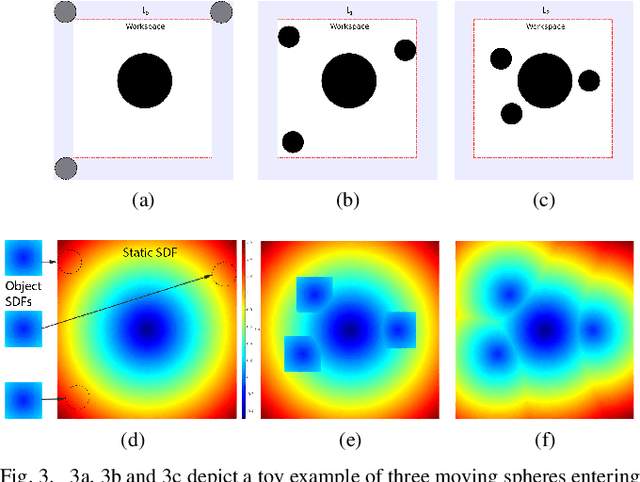
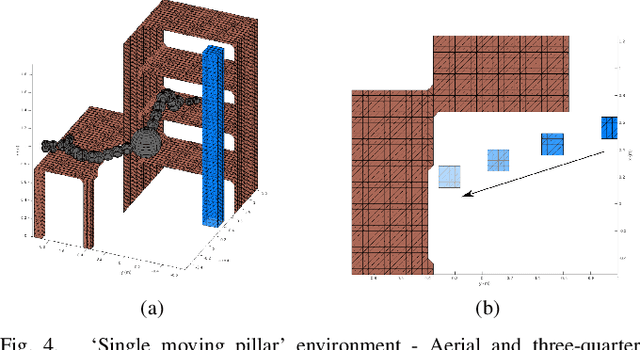
We present a novel framework for motion planning in dynamic environments that accounts for the predicted trajectories of moving objects in the scene. We explore the use of composite signed-distance fields in motion planning and detail how they can be used to generate signed-distance fields (SDFs) in real-time to incorporate predicted obstacle motions. We benchmark our approach of using composite SDFs against performing exact SDF calculations on the workspace occupancy grid. Our proposed technique generates predictions substantially faster and typically exhibits an 81--97% reduction in time for subsequent predictions. We integrate our framework with GPMP2 to demonstrate a full implementation of our approach in real-time, enabling a 7-DoF Panda arm to smoothly avoid a moving robot.
Improvements to short-term weather prediction with recurrent-convolutional networks
Nov 11, 2021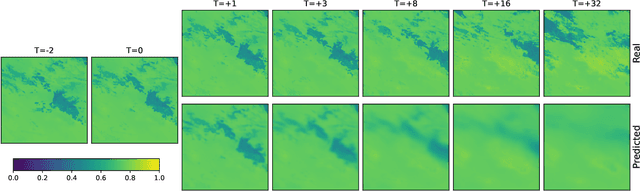

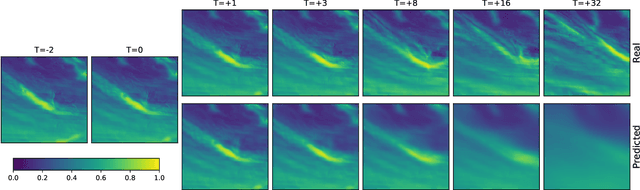
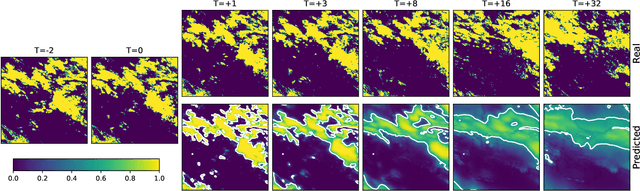
The Weather4cast 2021 competition gave the participants a task of predicting the time evolution of two-dimensional fields of satellite-based meteorological data. This paper describes the author's efforts, after initial success in the first stage of the competition, to improve the model further in the second stage. The improvements consisted of a shallower model variant that is competitive against the deeper version, adoption of the AdaBelief optimizer, improved handling of one of the predicted variables where the training set was found not to represent the validation set well, and ensembling multiple models to improve the results further. The largest quantitative improvements to the competition metrics can be attributed to the increased amount of training data available in the second stage of the competition, followed by the effects of model ensembling. Qualitative results show that the model can predict the time evolution of the fields, including the motion of the fields over time, starting with sharp predictions for the immediate future and blurring of the outputs in later frames to account for the increased uncertainty.
A Robust Phased Elimination Algorithm for Corruption-Tolerant Gaussian Process Bandits
Feb 03, 2022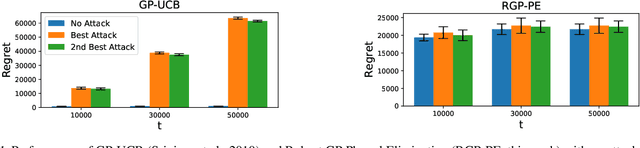

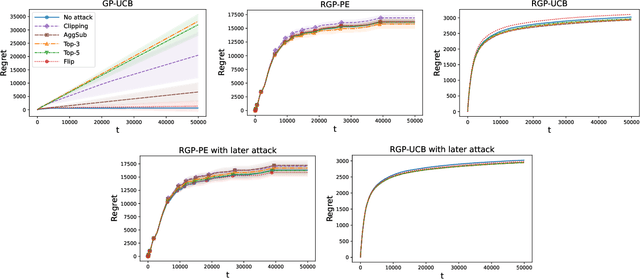
We consider the sequential optimization of an unknown, continuous, and expensive to evaluate reward function, from noisy and adversarially corrupted observed rewards. When the corruption attacks are subject to a suitable budget $C$ and the function lives in a Reproducing Kernel Hilbert Space (RKHS), the problem can be posed as corrupted Gaussian process (GP) bandit optimization. We propose a novel robust elimination-type algorithm that runs in epochs, combines exploration with infrequent switching to select a small subset of actions, and plays each action for multiple time instants. Our algorithm, Robust GP Phased Elimination (RGP-PE), successfully balances robustness to corruptions with exploration and exploitation such that its performance degrades minimally in the presence (or absence) of adversarial corruptions. When $T$ is the number of samples and $\gamma_T$ is the maximal information gain, the corruption-dependent term in our regret bound is $O(C \gamma_T^{3/2})$, which is significantly tighter than the existing $O(C \sqrt{T \gamma_T})$ for several commonly-considered kernels. We perform the first empirical study of robustness in the corrupted GP bandit setting, and show that our algorithm is robust against a variety of adversarial attacks.
Input correlations impede suppression of chaos and learning in balanced rate networks
Jan 24, 2022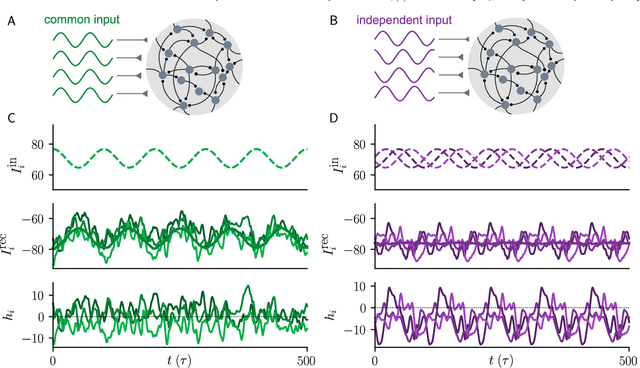
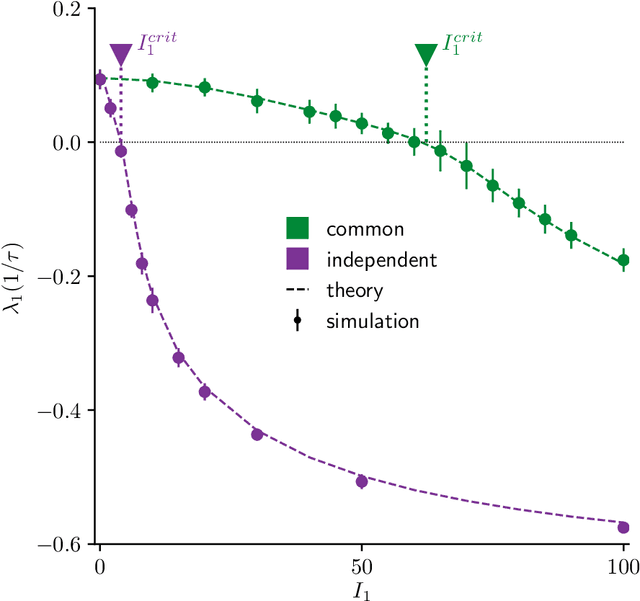
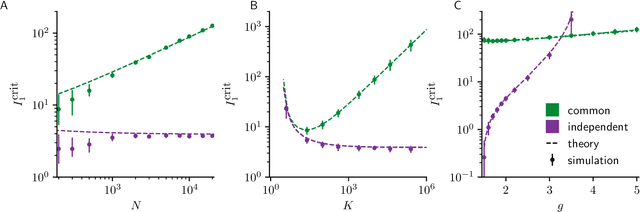
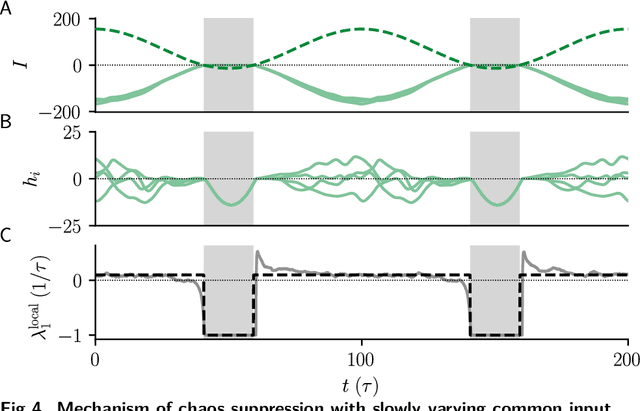
Neural circuits exhibit complex activity patterns, both spontaneously and evoked by external stimuli. Information encoding and learning in neural circuits depend on how well time-varying stimuli can control spontaneous network activity. We show that in firing-rate networks in the balanced state, external control of recurrent dynamics, i.e., the suppression of internally-generated chaotic variability, strongly depends on correlations in the input. A unique feature of balanced networks is that, because common external input is dynamically canceled by recurrent feedback, it is far easier to suppress chaos with independent inputs into each neuron than through common input. To study this phenomenon we develop a non-stationary dynamic mean-field theory that determines how the activity statistics and largest Lyapunov exponent depend on frequency and amplitude of the input, recurrent coupling strength, and network size, for both common and independent input. We also show that uncorrelated inputs facilitate learning in balanced networks.
Who will Leave a Pediatric Weight Management Program and When? -- A machine learning approach for predicting attrition patterns
Feb 03, 2022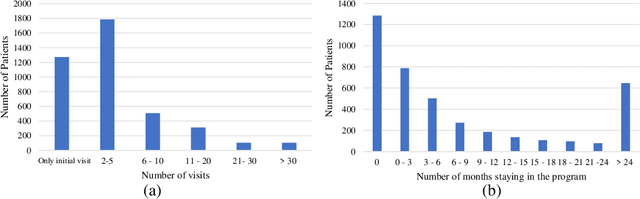
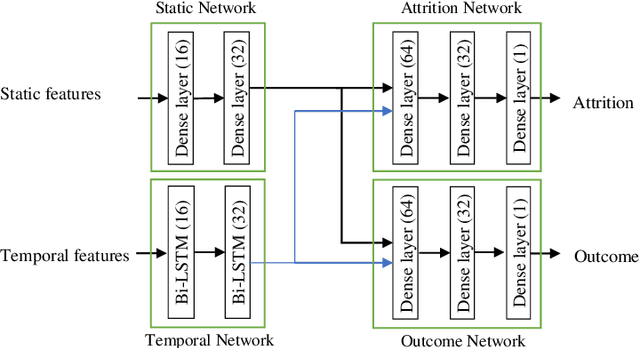
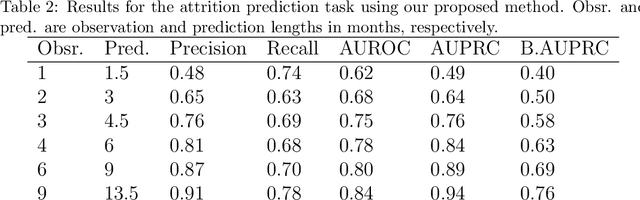
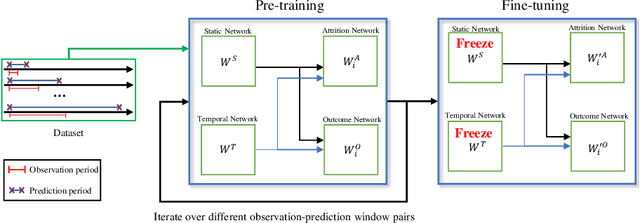
Childhood obesity is a major public health concern. Multidisciplinary pediatric weight management programs are considered standard treatment for children with obesity and severe obesity who are not able to be successfully managed in the primary care setting; however, high drop-out rates (referred to as attrition) are a major hurdle in delivering successful interventions. Predicting attrition patterns can help providers reduce the attrition rates. Previous work has mainly focused on finding static predictors of attrition using statistical analysis methods. In this study, we present a machine learning model to predict (a) the likelihood of attrition, and (b) the change in body-mass index (BMI) percentile of children, at different time points after joining a weight management program. We use a five-year dataset containing the information related to around 4,550 children that we have compiled using data from the Nemours Pediatric Weight Management program. Our models show strong prediction performance as determined by high AUROC scores across different tasks (average AUROC of 0.75 for predicting attrition, and 0.73 for predicting weight outcomes). Additionally, we report the top features predicting attrition and weight outcomes in a series of explanatory experiments.
Skeleton-Based Action Segmentation with Multi-Stage Spatial-Temporal Graph Convolutional Neural Networks
Feb 03, 2022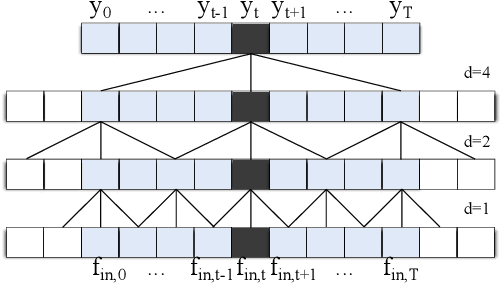
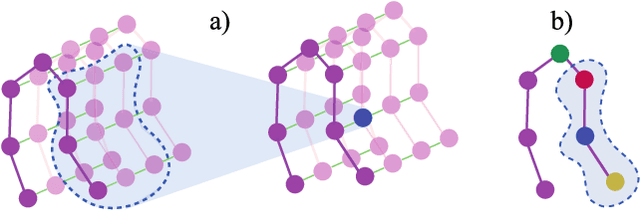
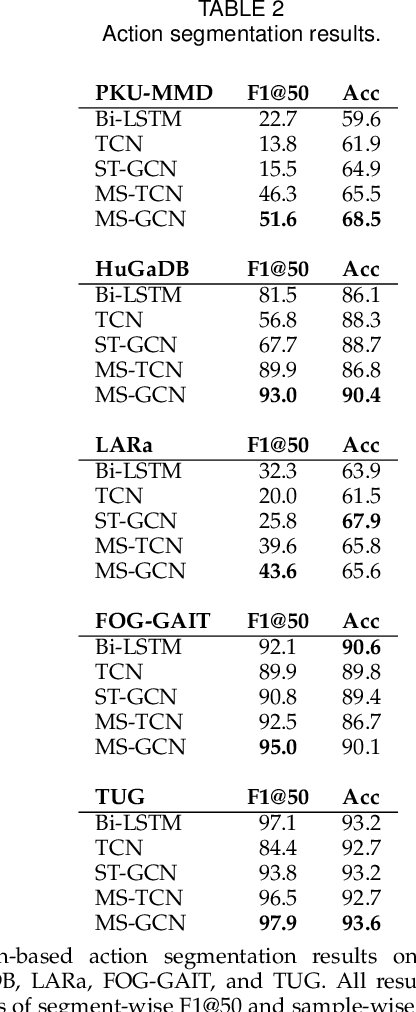
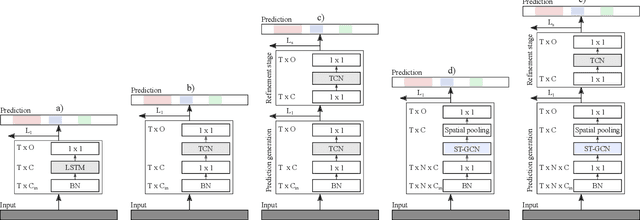
The ability to identify and temporally segment fine-grained actions in motion capture sequences is crucial for applications in human movement analysis. Motion capture is typically performed with optical or inertial measurement systems, which encode human movement as a time series of human joint locations and orientations or their higher-order representations. State-of-the-art action segmentation approaches use multiple stages of temporal convolutions. The main idea is to generate an initial prediction with several layers of temporal convolutions and refine these predictions over multiple stages, also with temporal convolutions. Although these approaches capture long-term temporal patterns, the initial predictions do not adequately consider the spatial hierarchy among the human joints. To address this limitation, we present multi-stage spatial-temporal graph convolutional neural networks (MS-GCN). Our framework decouples the architecture of the initial prediction generation stage from the refinement stages. Specifically, we replace the initial stage of temporal convolutions with spatial-temporal graph convolutions, which better exploit the spatial configuration of the joints and their temporal dynamics. Our framework was compared to four strong baselines on five tasks. Experimental results demonstrate that our framework achieves state-of-the-art performance.
Data splitting improves statistical performance in overparametrized regimes
Oct 21, 2021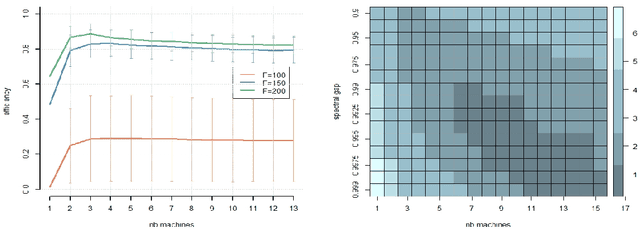
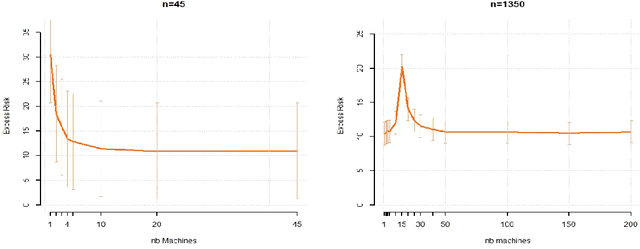
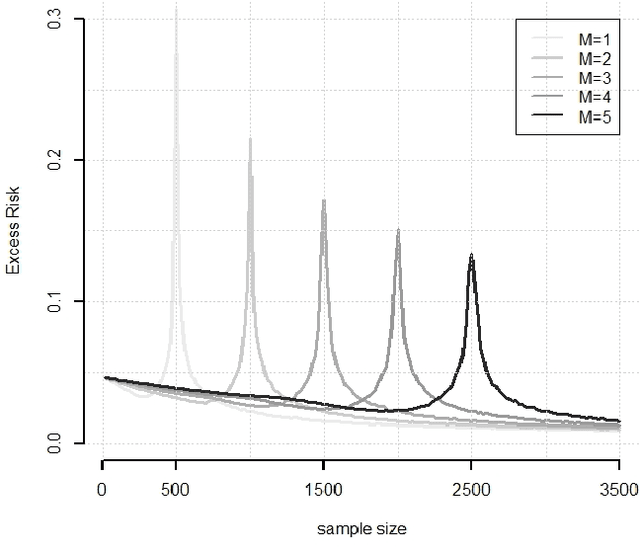
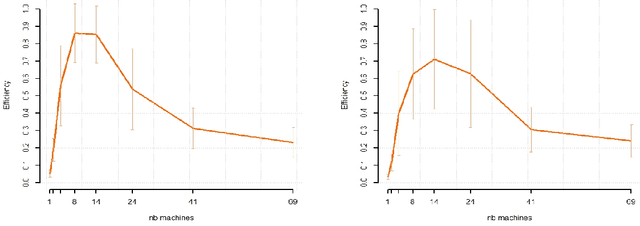
While large training datasets generally offer improvement in model performance, the training process becomes computationally expensive and time consuming. Distributed learning is a common strategy to reduce the overall training time by exploiting multiple computing devices. Recently, it has been observed in the single machine setting that overparametrization is essential for benign overfitting in ridgeless regression in Hilbert spaces. We show that in this regime, data splitting has a regularizing effect, hence improving statistical performance and computational complexity at the same time. We further provide a unified framework that allows to analyze both the finite and infinite dimensional setting. We numerically demonstrate the effect of different model parameters.
Distributed SLIDE: Enabling Training Large Neural Networks on Low Bandwidth and Simple CPU-Clusters via Model Parallelism and Sparsity
Jan 29, 2022More than 70% of cloud computing is paid for but sits idle. A large fraction of these idle compute are cheap CPUs with few cores that are not utilized during the less busy hours. This paper aims to enable those CPU cycles to train heavyweight AI models. Our goal is against mainstream frameworks, which focus on leveraging expensive specialized ultra-high bandwidth interconnect to address the communication bottleneck in distributed neural network training. This paper presents a distributed model-parallel training framework that enables training large neural networks on small CPU clusters with low Internet bandwidth. We build upon the adaptive sparse training framework introduced by the SLIDE algorithm. By carefully deploying sparsity over distributed nodes, we demonstrate several orders of magnitude faster model parallel training than Horovod, the main engine behind most commercial software. We show that with reduced communication, due to sparsity, we can train close to a billion parameter model on simple 4-16 core CPU nodes connected by basic low bandwidth interconnect. Moreover, the training time is at par with some of the best hardware accelerators.