 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Label Propagation for Annotation-Efficient Nuclei Segmentation from Pathology Images
Feb 16, 2022

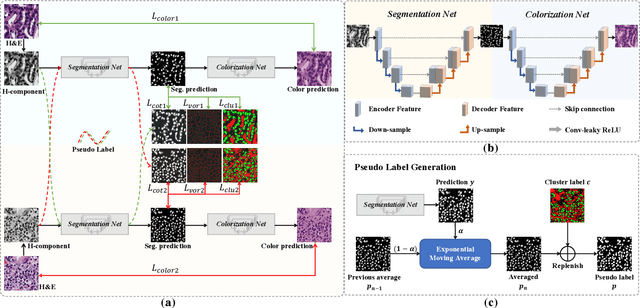
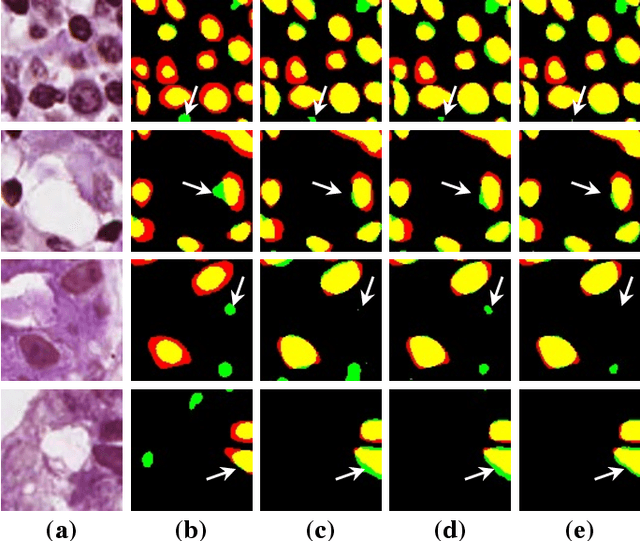

Nuclei segmentation is a crucial task for whole slide image analysis in digital pathology. Generally, the segmentation performance of fully-supervised learning heavily depends on the amount and quality of the annotated data. However, it is time-consuming and expensive for professional pathologists to provide accurate pixel-level ground truth, while it is much easier to get coarse labels such as point annotations. In this paper, we propose a weakly-supervised learning method for nuclei segmentation that only requires point annotations for training. The proposed method achieves label propagation in a coarse-to-fine manner as follows. First, coarse pixel-level labels are derived from the point annotations based on the Voronoi diagram and the k-means clustering method to avoid overfitting. Second, a co-training strategy with an exponential moving average method is designed to refine the incomplete supervision of the coarse labels. Third, a self-supervised visual representation learning method is tailored for nuclei segmentation of pathology images that transforms the hematoxylin component images into the H\&E stained images to gain better understanding of the relationship between the nuclei and cytoplasm. We comprehensively evaluate the proposed method using two public datasets. Both visual and quantitative results demonstrate the superiority of our method to the state-of-the-art methods, and its competitive performance compared to the fully-supervised methods. The source codes for implementing the experiments will be released after acceptance.
An Overview of Backdoor Attacks Against Deep Neural Networks and Possible Defences
Nov 16, 2021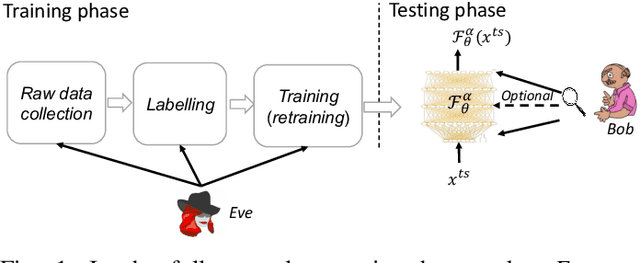
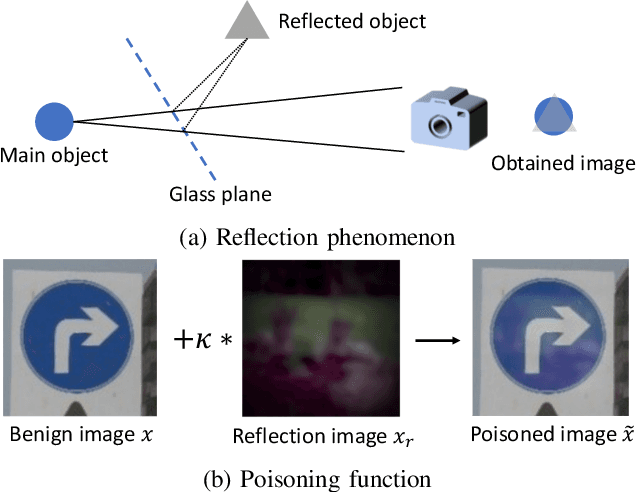
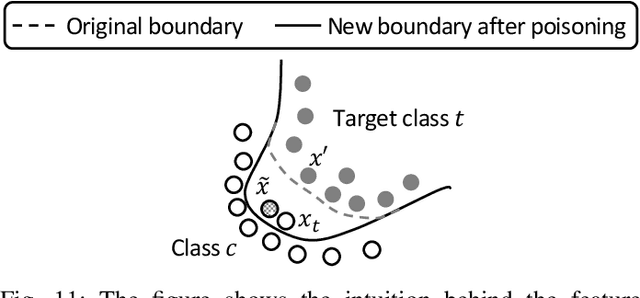
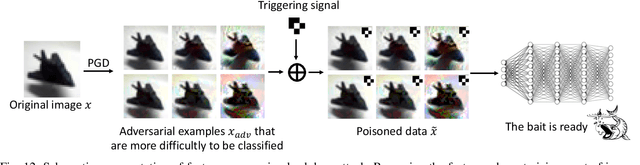
Together with impressive advances touching every aspect of our society, AI technology based on Deep Neural Networks (DNN) is bringing increasing security concerns. While attacks operating at test time have monopolised the initial attention of researchers, backdoor attacks, exploiting the possibility of corrupting DNN models by interfering with the training process, represents a further serious threat undermining the dependability of AI techniques. In a backdoor attack, the attacker corrupts the training data so to induce an erroneous behaviour at test time. Test time errors, however, are activated only in the presence of a triggering event corresponding to a properly crafted input sample. In this way, the corrupted network continues to work as expected for regular inputs, and the malicious behaviour occurs only when the attacker decides to activate the backdoor hidden within the network. In the last few years, backdoor attacks have been the subject of an intense research activity focusing on both the development of new classes of attacks, and the proposal of possible countermeasures. The goal of this overview paper is to review the works published until now, classifying the different types of attacks and defences proposed so far. The classification guiding the analysis is based on the amount of control that the attacker has on the training process, and the capability of the defender to verify the integrity of the data used for training, and to monitor the operations of the DNN at training and test time. As such, the proposed analysis is particularly suited to highlight the strengths and weaknesses of both attacks and defences with reference to the application scenarios they are operating in.
Multi-scale Sparse Representation-Based Shadow Inpainting for Retinal OCT Images
Feb 23, 2022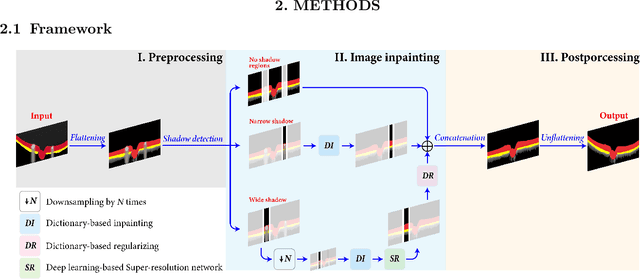


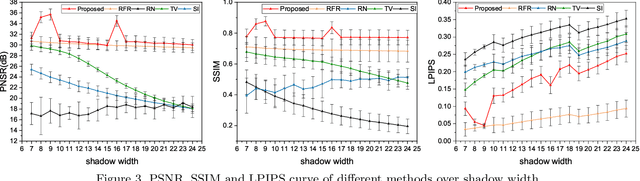
Inpainting shadowed regions cast by superficial blood vessels in retinal optical coherence tomography (OCT) images is critical for accurate and robust machine analysis and clinical diagnosis. Traditional sequence-based approaches such as propagating neighboring information to gradually fill in the missing regions are cost-effective. But they generate less satisfactory outcomes when dealing with larger missing regions and texture-rich structures. Emerging deep learning-based methods such as encoder-decoder networks have shown promising results in natural image inpainting tasks. However, they typically need a long computational time for network training in addition to the high demand on the size of datasets, which makes it difficult to be applied on often small medical datasets. To address these challenges, we propose a novel multi-scale shadow inpainting framework for OCT images by synergically applying sparse representation and deep learning: sparse representation is used to extract features from a small amount of training images for further inpainting and to regularize the image after the multi-scale image fusion, while convolutional neural network (CNN) is employed to enhance the image quality. During the image inpainting, we divide preprocessed input images into different branches based on the shadow width to harvest complementary information from different scales. Finally, a sparse representation-based regularizing module is designed to refine the generated contents after multi-scale feature aggregation. Experiments are conducted to compare our proposal versus both traditional and deep learning-based techniques on synthetic and real-world shadows. Results demonstrate that our proposed method achieves favorable image inpainting in terms of visual quality and quantitative metrics, especially when wide shadows are presented.
SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
Jan 30, 2022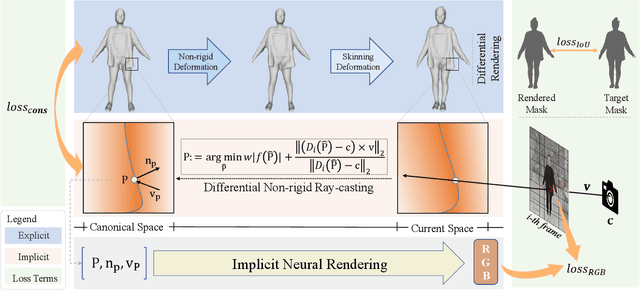
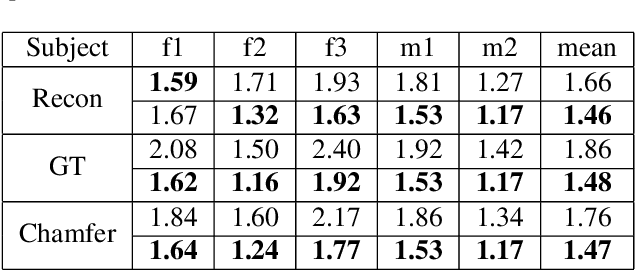
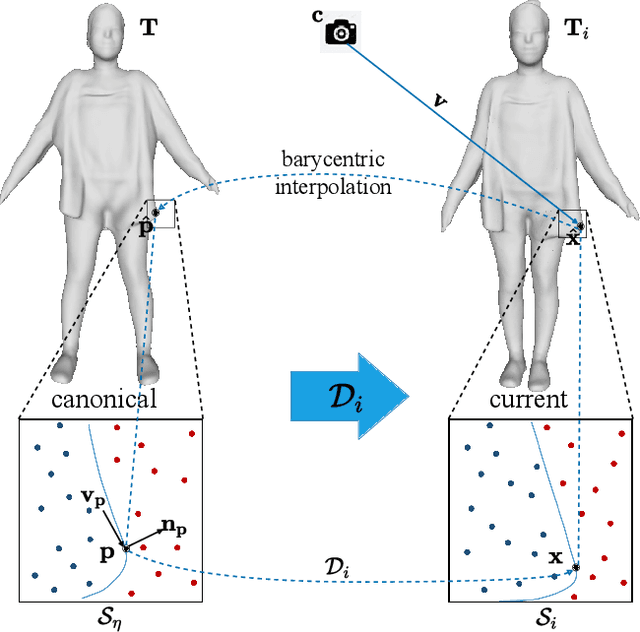

We propose SelfRecon, a clothed human body reconstruction method that combines implicit and explicit representations to recover space-time coherent geometries from a monocular self-rotating human video. Explicit methods require a predefined template mesh for a given sequence, while the template is hard to acquire for a specific subject. Meanwhile, the fixed topology limits the reconstruction accuracy and clothing types. Implicit methods support arbitrary topology and have high quality due to continuous geometric representation. However, it is difficult to integrate multi-frame information to produce a consistent registration sequence for downstream applications. We propose to combine the advantages of both representations. We utilize differential mask loss of the explicit mesh to obtain the coherent overall shape, while the details on the implicit surface are refined with the differentiable neural rendering. Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations closely. Compared with existing methods, SelfRecon can produce high-fidelity surfaces for arbitrary clothed humans with self-supervised optimization. Extensive experimental results demonstrate its effectiveness on real captured monocular videos.
A benchmark of state-of-the-art sound event detection systems evaluated on synthetic soundscapes
Feb 08, 2022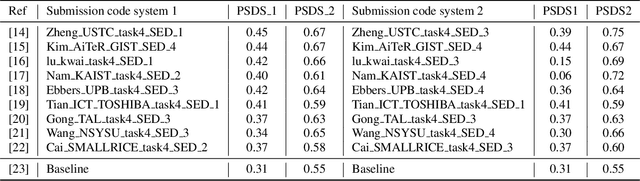
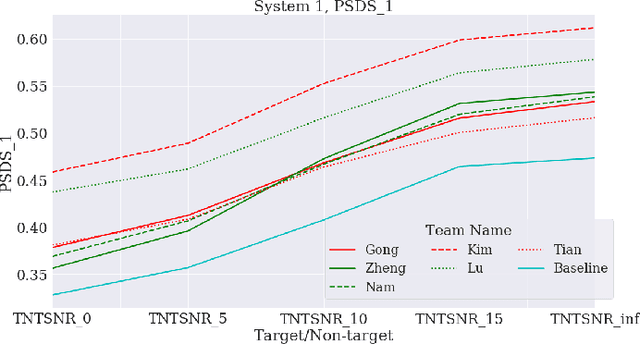
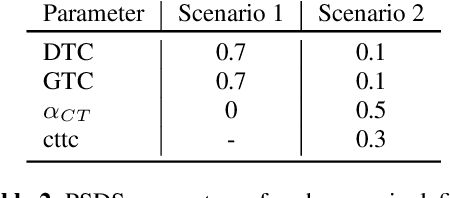
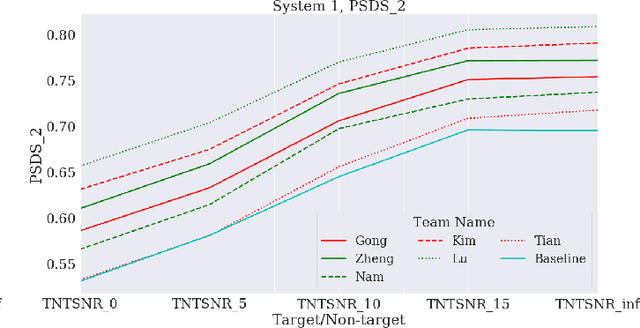
This paper proposes a benchmark of submissions to Detection and Classification Acoustic Scene and Events 2021 Challenge (DCASE) Task 4 representing a sampling of the state-of-the-art in Sound Event Detection task. The submissions are evaluated according to the two polyphonic sound detection score scenarios proposed for the DCASE 2021 Challenge Task 4, which allow to make an analysis on whether submissions are designed to perform fine-grained temporal segmentation, coarse-grained temporal segmentation, or have been designed to be polyvalent on the scenarios proposed. We study the solutions proposed by participants to analyze their robustness to varying level target to non-target signal-to-noise ratio and to temporal localization of target sound events. A last experiment is proposed in order to study the impact of non-target events on systems outputs. Results show that systems adapted to provide coarse segmentation outputs are more robust to different target to non-target signal-to-noise ratio and, with the help of specific data augmentation methods, they are more robust to time localization of the original event. Results of the last experiment display that systems tend to spuriously predict short events when non-target events are present. This is particularly true for systems that are tailored to have a fine segmentation.
Audio-Driven Talking Face Video Generation with Dynamic Convolution Kernels
Jan 16, 2022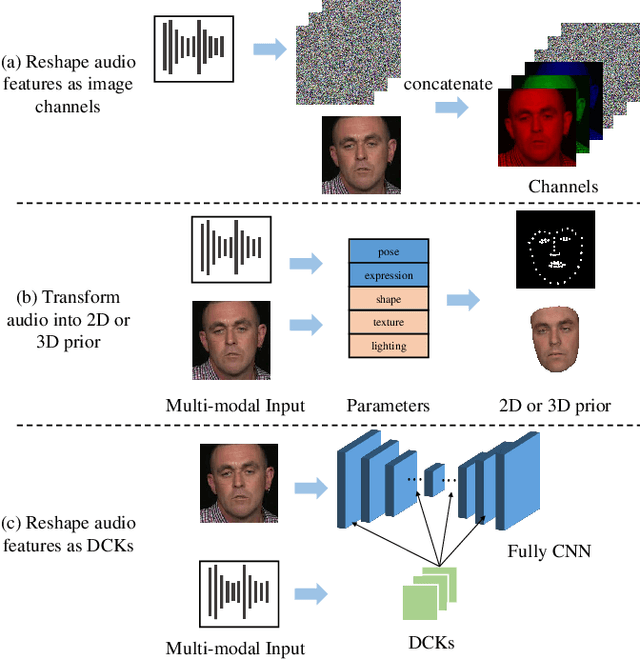
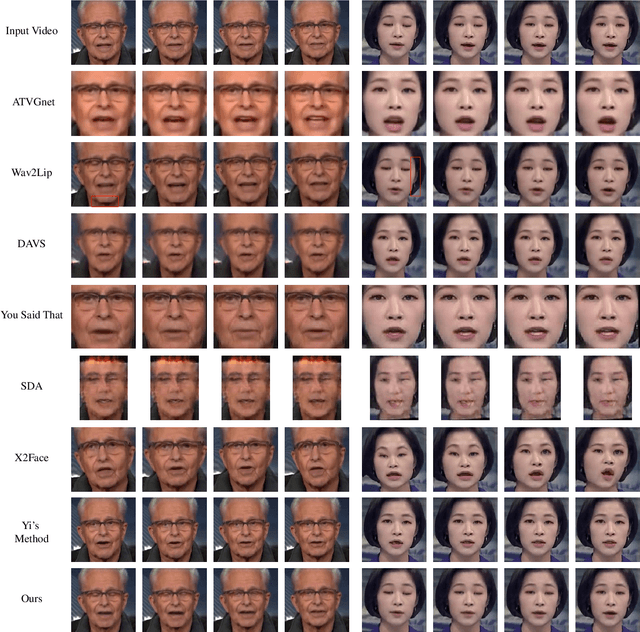
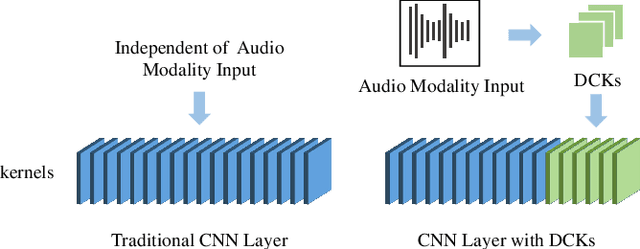
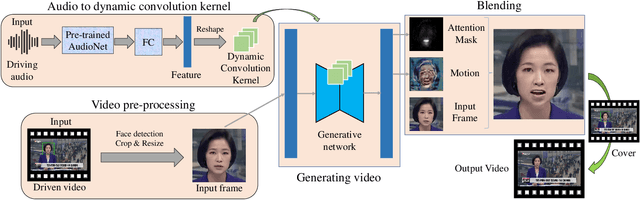
In this paper, we present a dynamic convolution kernel (DCK) strategy for convolutional neural networks. Using a fully convolutional network with the proposed DCKs, high-quality talking-face video can be generated from multi-modal sources (i.e., unmatched audio and video) in real time, and our trained model is robust to different identities, head postures, and input audios. Our proposed DCKs are specially designed for audio-driven talking face video generation, leading to a simple yet effective end-to-end system. We also provide a theoretical analysis to interpret why DCKs work. Experimental results show that our method can generate high-quality talking-face video with background at 60 fps. Comparison and evaluation between our method and the state-of-the-art methods demonstrate the superiority of our method.
Topological Machine Learning for Multivariate Time Series
Nov 27, 2019


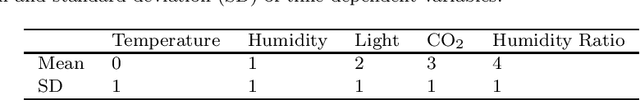
We develop a framework for analyzing multivariate time series using topological data analysis (TDA) methods. The proposed methodology involves converting the multivariate time series to point cloud data, calculating Wasserstein distances between the persistence diagrams and using the $k$-nearest neighbors algorithm ($k$-NN) for supervised machine learning. Two methods (symmetry-breaking and anchor points) are also introduced to enable TDA to better analyze data with heterogeneous features that are sensitive to translation, rotation, or choice of coordinates. We apply our methods to room occupancy detection based on 5 time-dependent variables (temperature, humidity, light, CO2 and humidity ratio). Experimental results show that topological methods are effective in predicting room occupancy during a time window.
Playing against no-regret players
Feb 16, 2022In increasingly different contexts, it happens that a human player has to interact with artificial players who make decisions following decision-making algorithms. How should the human player play against these algorithms to maximize his utility? Does anything change if he faces one or more artificial players? The main goal of the paper is to answer these two questions. Consider n-player games in normal form repeated over time, where we call the human player optimizer, and the (n -- 1) artificial players, learners. We assume that learners play no-regret algorithms, a class of algorithms widely used in online learning and decision-making. In these games, we consider the concept of Stackelberg equilibrium. In a recent paper, Deng, Schneider, and Sivan have shown that in a 2-player game the optimizer can always guarantee an expected cumulative utility of at least the Stackelberg value per round. In our first result, we show, with counterexamples, that this result is no longer true if the optimizer has to face more than one player. Therefore, we generalize the definition of Stackelberg equilibrium introducing the concept of correlated Stackelberg equilibrium. Finally, in the main result, we prove that the optimizer can guarantee at least the correlated Stackelberg value per round. Moreover, using a version of the strong law of large numbers, we show that our result is also true almost surely for the optimizer utility instead of the optimizer's expected utility.
PONI: Potential Functions for ObjectGoal Navigation with Interaction-free Learning
Jan 25, 2022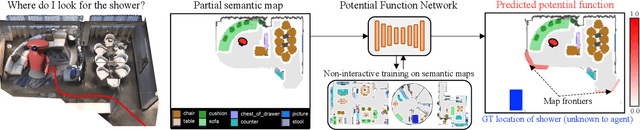
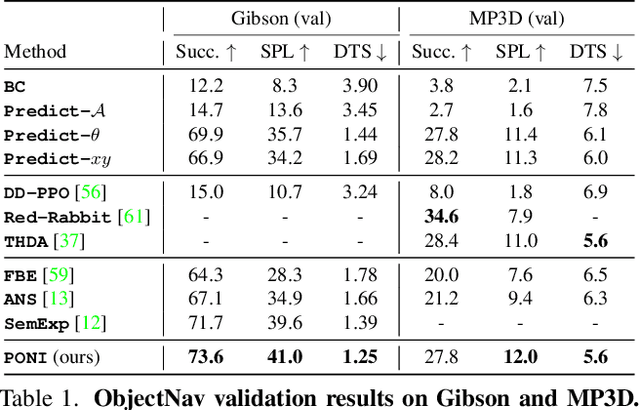
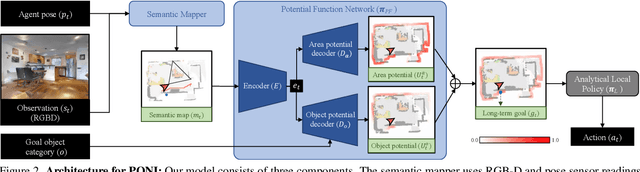
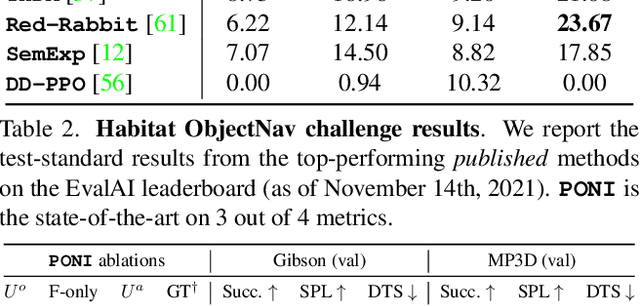
State-of-the-art approaches to ObjectGoal navigation rely on reinforcement learning and typically require significant computational resources and time for learning. We propose Potential functions for ObjectGoal Navigation with Interaction-free learning (PONI), a modular approach that disentangles the skills of `where to look?' for an object and `how to navigate to (x, y)?'. Our key insight is that `where to look?' can be treated purely as a perception problem, and learned without environment interactions. To address this, we propose a network that predicts two complementary potential functions conditioned on a semantic map and uses them to decide where to look for an unseen object. We train the potential function network using supervised learning on a passive dataset of top-down semantic maps, and integrate it into a modular framework to perform ObjectGoal navigation. Experiments on Gibson and Matterport3D demonstrate that our method achieves the state-of-the-art for ObjectGoal navigation while incurring up to 1,600x less computational cost for training.
Loss-analysis via Attention-scale for Physiologic Time Series
Oct 23, 2020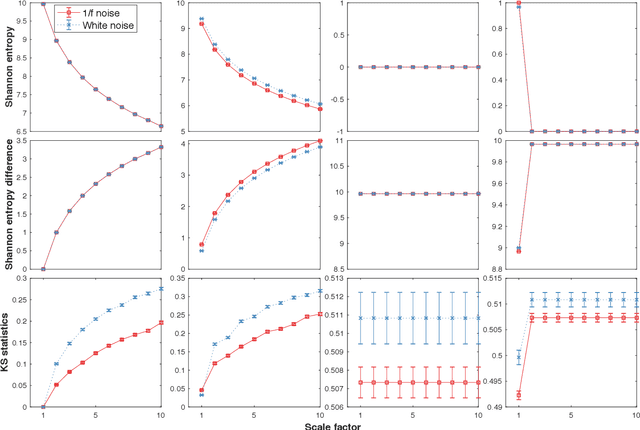
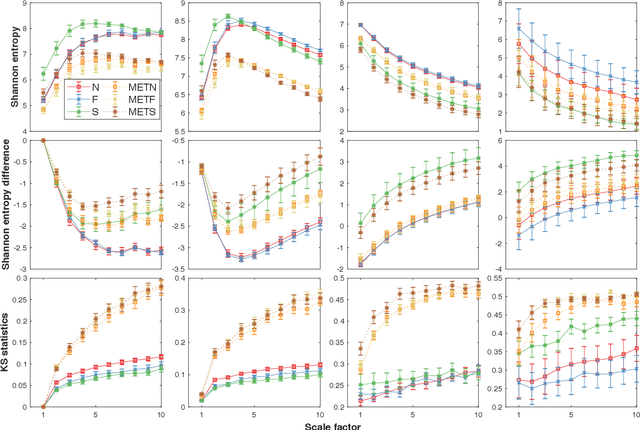
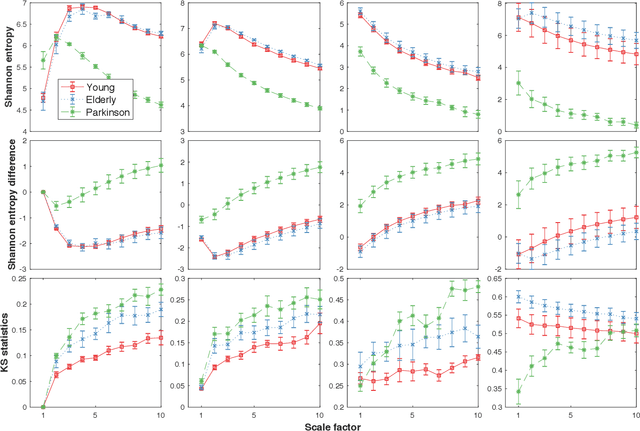
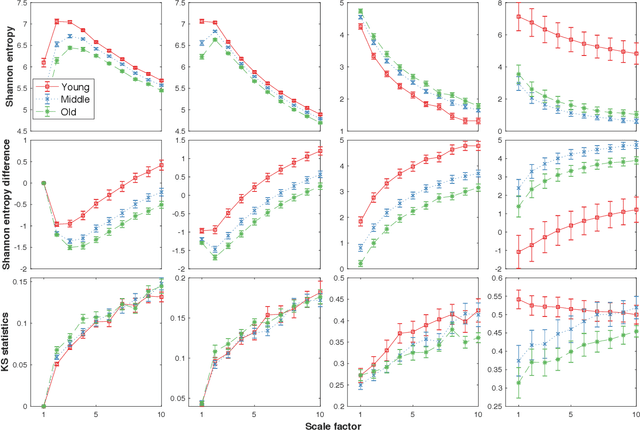
Physiologic signals have properties across multiple spatial and temporal scales, which can be shown by the complexity-analysis of the coarse-grained physiologic signals by scaling techniques such as the multiscale. Unfortunately, the results obtained from the coarse-grained signals by the multiscale may not fully reflect the properties of the original signals because there is a loss caused by scaling techniques and the same scaling technique may bring different losses to different signals. Another problem is that multiscale does not consider the key observations inherent in the signal. Here, we show a new analysis method for time series called the loss-analysis via attention-scale. We show that multiscale is a special case of attention-scale. The loss-analysis can complement to the complexity-analysis to capture aspects of the signals that are not captured using previously developed measures. This can be used to study ageing, diseases, and other physiologic phenomenon.