 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Skeleton-Based Action Segmentation with Multi-Stage Spatial-Temporal Graph Convolutional Neural Networks
Feb 03, 2022
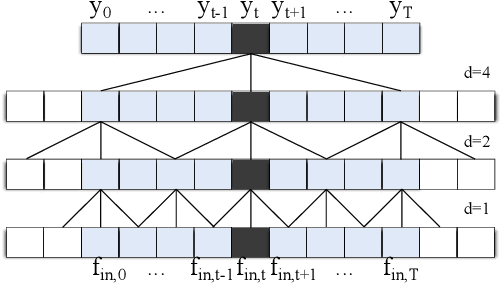
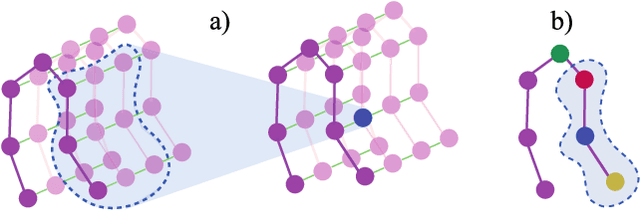
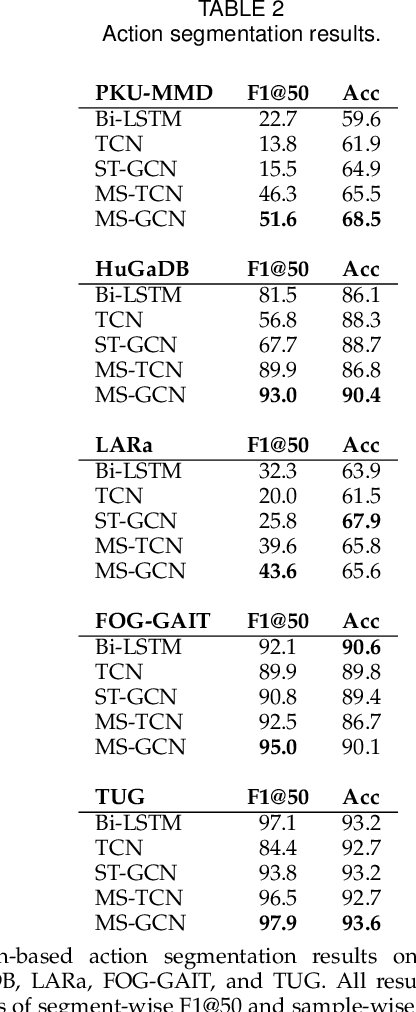
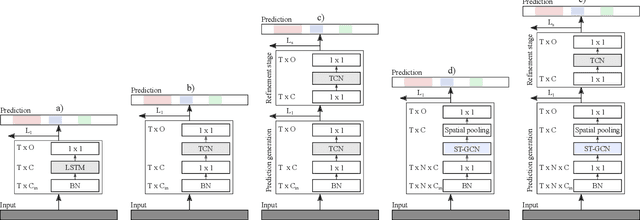
The ability to identify and temporally segment fine-grained actions in motion capture sequences is crucial for applications in human movement analysis. Motion capture is typically performed with optical or inertial measurement systems, which encode human movement as a time series of human joint locations and orientations or their higher-order representations. State-of-the-art action segmentation approaches use multiple stages of temporal convolutions. The main idea is to generate an initial prediction with several layers of temporal convolutions and refine these predictions over multiple stages, also with temporal convolutions. Although these approaches capture long-term temporal patterns, the initial predictions do not adequately consider the spatial hierarchy among the human joints. To address this limitation, we present multi-stage spatial-temporal graph convolutional neural networks (MS-GCN). Our framework decouples the architecture of the initial prediction generation stage from the refinement stages. Specifically, we replace the initial stage of temporal convolutions with spatial-temporal graph convolutions, which better exploit the spatial configuration of the joints and their temporal dynamics. Our framework was compared to four strong baselines on five tasks. Experimental results demonstrate that our framework achieves state-of-the-art performance.
Input correlations impede suppression of chaos and learning in balanced rate networks
Jan 24, 2022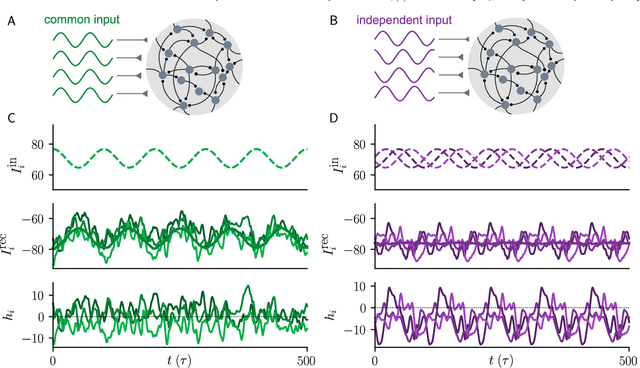
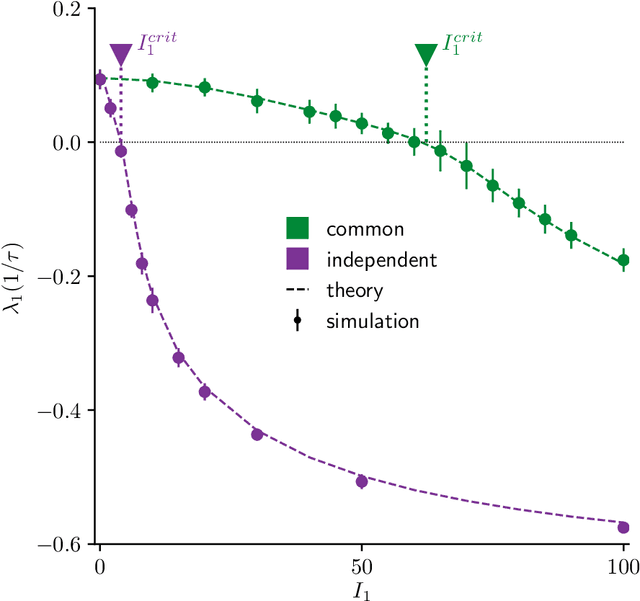
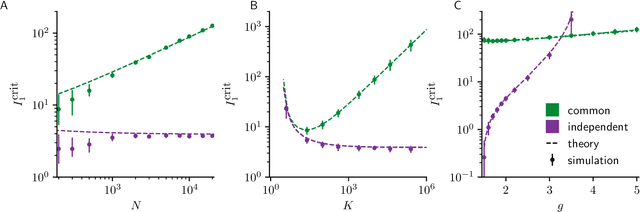
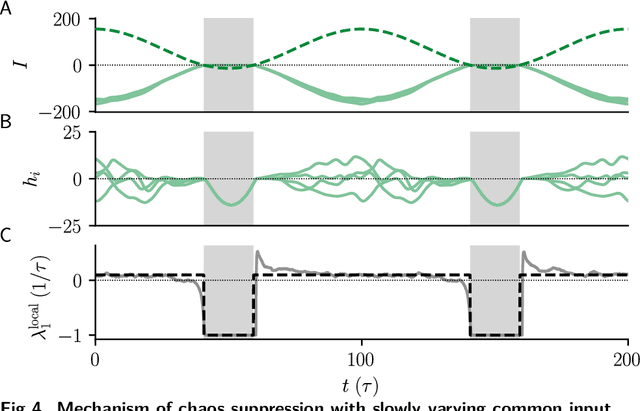
Neural circuits exhibit complex activity patterns, both spontaneously and evoked by external stimuli. Information encoding and learning in neural circuits depend on how well time-varying stimuli can control spontaneous network activity. We show that in firing-rate networks in the balanced state, external control of recurrent dynamics, i.e., the suppression of internally-generated chaotic variability, strongly depends on correlations in the input. A unique feature of balanced networks is that, because common external input is dynamically canceled by recurrent feedback, it is far easier to suppress chaos with independent inputs into each neuron than through common input. To study this phenomenon we develop a non-stationary dynamic mean-field theory that determines how the activity statistics and largest Lyapunov exponent depend on frequency and amplitude of the input, recurrent coupling strength, and network size, for both common and independent input. We also show that uncorrelated inputs facilitate learning in balanced networks.
Ranking with Confidence for Large Scale Comparison Data
Feb 03, 2022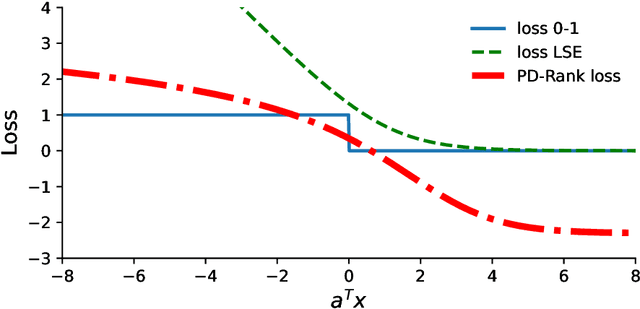
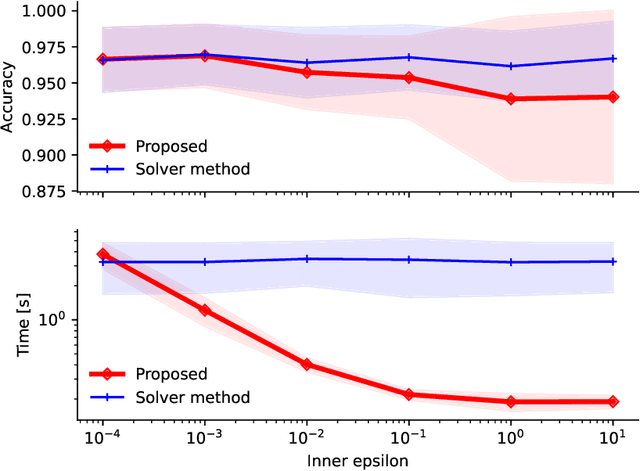
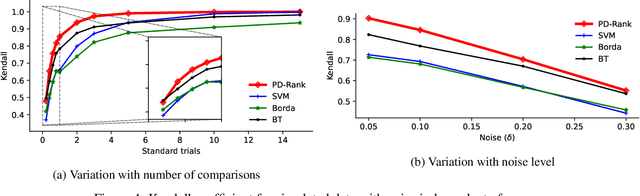
In this work, we leverage a generative data model considering comparison noise to develop a fast, precise, and informative ranking algorithm from pairwise comparisons that produces a measure of confidence on each comparison. The problem of ranking a large number of items from noisy and sparse pairwise comparison data arises in diverse applications, like ranking players in online games, document retrieval or ranking human perceptions. Although different algorithms are available, we need fast, large-scale algorithms whose accuracy degrades gracefully when the number of comparisons is too small. Fitting our proposed model entails solving a non-convex optimization problem, which we tightly approximate by a sum of quasi-convex functions and a regularization term. Resorting to an iterative reweighted minimization and the Primal-Dual Hybrid Gradient method, we obtain PD-Rank, achieving a Kendall tau 0.1 higher than all comparing methods, even for 10\% of wrong comparisons in simulated data matching our data model, and leading in accuracy if data is generated according to the Bradley-Terry model, in both cases faster by one order of magnitude, in seconds. In real data, PD-Rank requires less computational time to achieve the same Kendall tau than active learning methods.
Algorithms for Efficiently Learning Low-Rank Neural Networks
Feb 03, 2022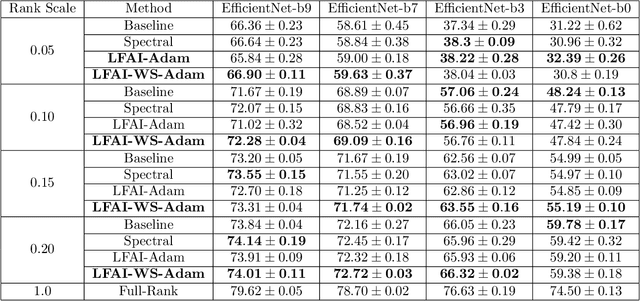

We study algorithms for learning low-rank neural networks -- networks where the weight parameters are re-parameterized by products of two low-rank matrices. First, we present a provably efficient algorithm which learns an optimal low-rank approximation to a single-hidden-layer ReLU network up to additive error $\epsilon$ with probability $\ge 1 - \delta$, given access to noiseless samples with Gaussian marginals in polynomial time and samples. Thus, we provide the first example of an algorithm which can efficiently learn a neural network up to additive error without assuming the ground truth is realizable. To solve this problem, we introduce an efficient SVD-based $\textit{Nonlinear Kernel Projection}$ algorithm for solving a nonlinear low-rank approximation problem over Gaussian space. Inspired by the efficiency of our algorithm, we propose a novel low-rank initialization framework for training low-rank $\textit{deep}$ networks, and prove that for ReLU networks, the gap between our method and existing schemes widens as the desired rank of the approximating weights decreases, or as the dimension of the inputs increases (the latter point holds when network width is superlinear in dimension). Finally, we validate our theory by training ResNet and EfficientNet models on ImageNet.
Distributed SLIDE: Enabling Training Large Neural Networks on Low Bandwidth and Simple CPU-Clusters via Model Parallelism and Sparsity
Jan 29, 2022More than 70% of cloud computing is paid for but sits idle. A large fraction of these idle compute are cheap CPUs with few cores that are not utilized during the less busy hours. This paper aims to enable those CPU cycles to train heavyweight AI models. Our goal is against mainstream frameworks, which focus on leveraging expensive specialized ultra-high bandwidth interconnect to address the communication bottleneck in distributed neural network training. This paper presents a distributed model-parallel training framework that enables training large neural networks on small CPU clusters with low Internet bandwidth. We build upon the adaptive sparse training framework introduced by the SLIDE algorithm. By carefully deploying sparsity over distributed nodes, we demonstrate several orders of magnitude faster model parallel training than Horovod, the main engine behind most commercial software. We show that with reduced communication, due to sparsity, we can train close to a billion parameter model on simple 4-16 core CPU nodes connected by basic low bandwidth interconnect. Moreover, the training time is at par with some of the best hardware accelerators.
Aladdin: Joint Atlas Building and Diffeomorphic Registration Learning with Pairwise Alignment
Feb 07, 2022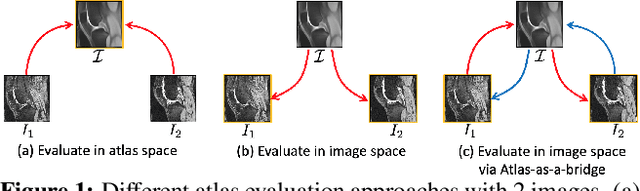
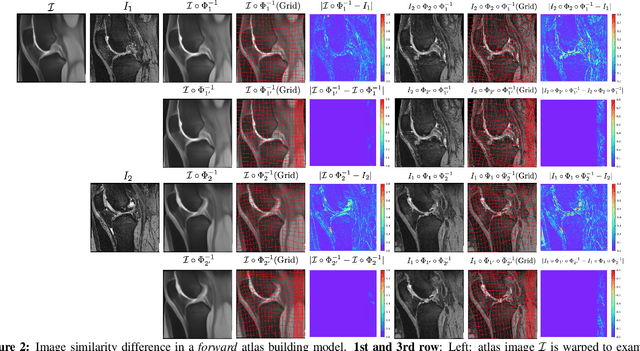
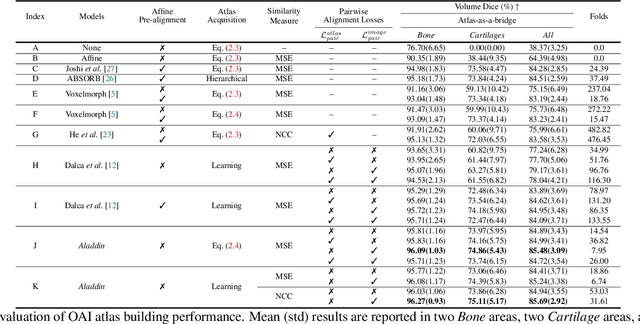
Atlas building and image registration are important tasks for medical image analysis. Once one or multiple atlases from an image population have been constructed, commonly (1) images are warped into an atlas space to study intra-subject or inter-subject variations or (2) a possibly probabilistic atlas is warped into image space to assign anatomical labels. Atlas estimation and nonparametric transformations are computationally expensive as they usually require numerical optimization. Additionally, previous approaches for atlas building often define similarity measures between a fuzzy atlas and each individual image, which may cause alignment difficulties because a fuzzy atlas does not exhibit clear anatomical structures in contrast to the individual images. This work explores using a convolutional neural network (CNN) to jointly predict the atlas and a stationary velocity field (SVF) parameterization for diffeomorphic image registration with respect to the atlas. Our approach does not require affine pre-registrations and utilizes pairwise image alignment losses to increase registration accuracy. We evaluate our model on 3D knee magnetic resonance images (MRI) from the OAI-ZIB dataset. Our results show that the proposed framework achieves better performance than other state-of-the-art image registration algorithms, allows for end-to-end training, and for fast inference at test time.
Full-Duplex Non-Coherent Communications for Massive MIMO Systems with Analog Beamforming
Jan 29, 2022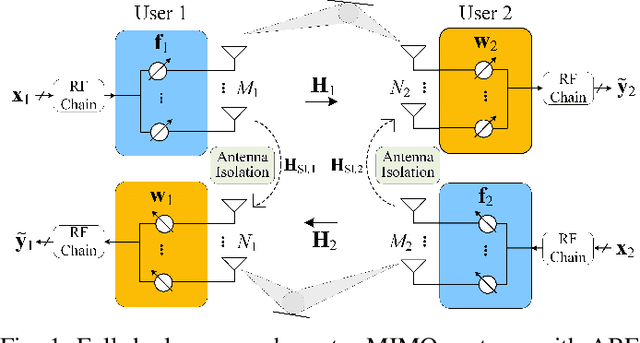
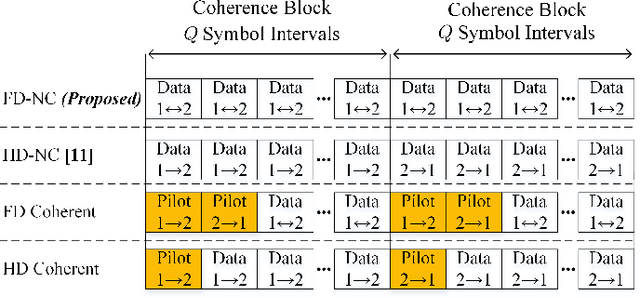
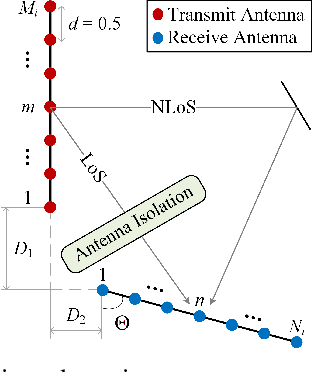
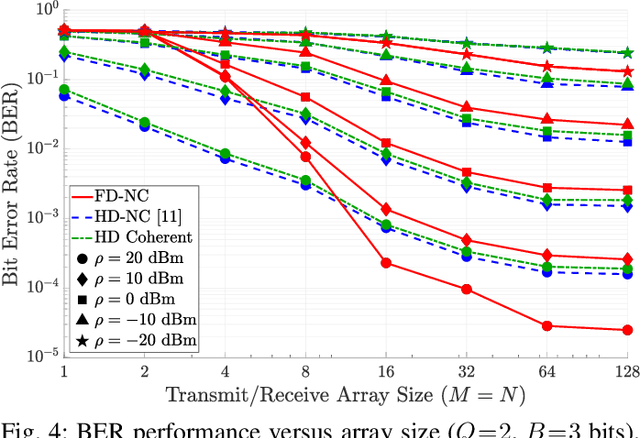
In this paper, a novel full-duplex non-coherent (FD-NC) transmission scheme is developed for massive multiple-input multiple-output (mMIMO) systems using analog beamforming (ABF). We propose to use a structured Grassmannian constellation for the non-coherent communications that does not require channel estimation. Then, we design the transmit and receive ABF via the slow time-varying angle-of-departure (AoD) and angle-of-arrival (AoA) information, respectively. The ABF design targets maximizing the intended signal power while suppressing the strong self-interference (SI) occurred in the FD transmission. Also, the proposed ABF technique only needs a single transmit and receive RF chain to support large antenna arrays, thus, it reduces hardware cost/complexity in the mMIMO systems. It is shown that the proposed FD-NC offers a great improvement in bit error rate (BER) in comparison to both half-duplex non-coherent (HD-NC) and HD coherent schemes. We also observe that the proposed FD-NC both reduces the error floor resulted from the residual SI in FD transmission, and provides lower BER compared to the FD coherent transmission.
Learning to Liquidate Forex: Optimal Stopping via Adaptive Top-K Regression
Feb 25, 2022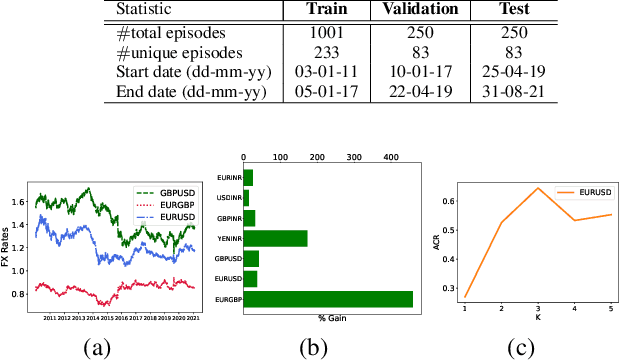
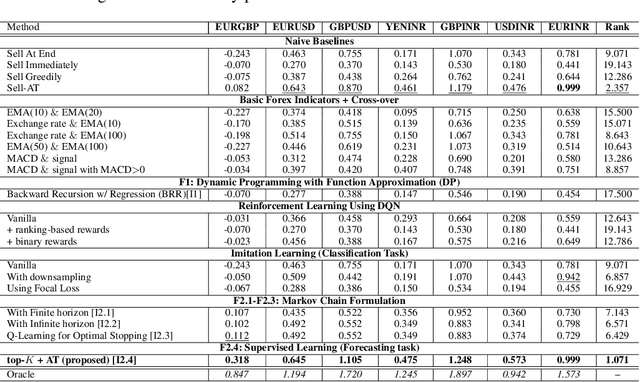
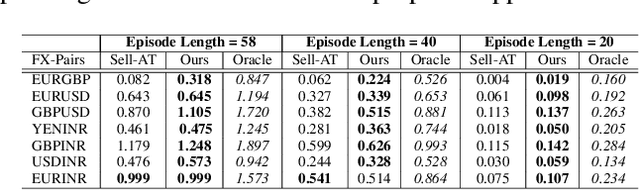
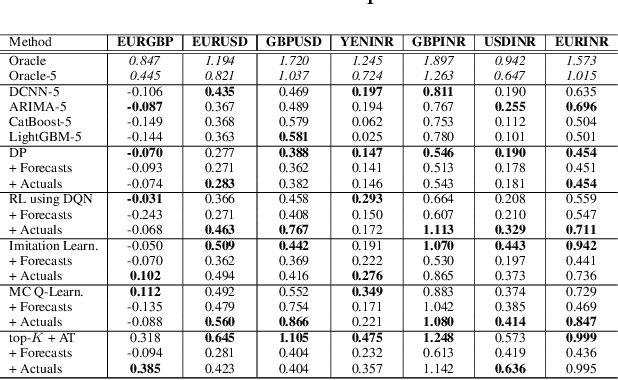
We consider learning a trading agent acting on behalf of the treasury of a firm earning revenue in a foreign currency (FC) and incurring expenses in the home currency (HC). The goal of the agent is to maximize the expected HC at the end of the trading episode by deciding to hold or sell the FC at each time step in the trading episode. We pose this as an optimization problem, and consider a broad spectrum of approaches with the learning component ranging from supervised to imitation to reinforcement learning. We observe that most of the approaches considered struggle to improve upon simple heuristic baselines. We identify two key aspects of the problem that render standard solutions ineffective - i) while good forecasts of future FX rates can be highly effective in guiding good decisions, forecasting FX rates is difficult, and erroneous estimates tend to degrade the performance of trading agents instead of improving it, ii) the inherent non-stationary nature of FX rates renders a fixed decision-threshold highly ineffective. To address these problems, we propose a novel supervised learning approach that learns to forecast the top-K future FX rates instead of forecasting all the future FX rates, and bases the hold-versus-sell decision on the forecasts (e.g. hold if future FX rate is higher than current FX rate, sell otherwise). Furthermore, to handle the non-stationarity in the FX rates data which poses challenges to the i.i.d. assumption in supervised learning methods, we propose to adaptively learn decision-thresholds based on recent historical episodes. Through extensive empirical evaluation, we show that our approach is the only approach which is able to consistently improve upon a simple heuristic baseline. Further experiments show the inefficacy of state-of-the-art statistical and deep-learning-based forecasting methods as they degrade the performance of the trading agent.
IDP-Z3: a reasoning engine for FO(.)
Feb 11, 2022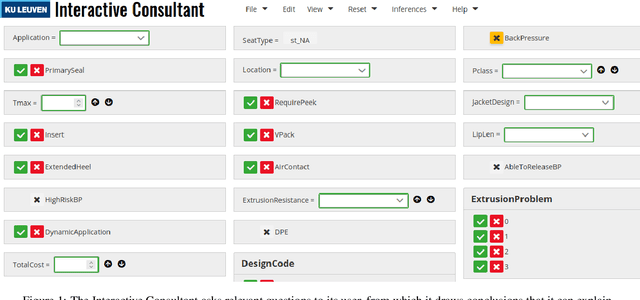



An important sign of intelligence is the capacity to apply a body of knowledge to a particular situation in order to not only derive new knowledge, but also to determine relevant questions or provide explanations. Developing interactive systems capable of performing such a variety of reasoning tasks for the benefits of its users has proved difficult, notably for performance and/or development cost reasons. Still, recently, a reasoning engine, called IDP3, has been used to build such systems, but it lacked support for arithmetic operations, seriously limiting its usefulness. We have developed a new reasoning engine, IDP-Z3, that removes this limitation, and we put it to the test in four knowledge-intensive industrial use cases. This paper describes FO(.) (aka FO-dot), the language used to represent knowledge in the IDP3 and IDP-Z3 system. It then describes the generic reasoning tasks that IDP-Z3 can perform, and how we used them to build a generic user interface, called the Interactive Consultant. Finally, it reports on the four use cases. In these four use cases, the interactive applications based on IDP-Z3 were capable of intelligent behavior of value to users, while having a low development cost (typically 10 days) and an acceptable response time (typically below 3 seconds). Performance could be further improved, in particular for problems on larger domains.
Cause-effect inference through spectral independence in linear dynamical systems: theoretical foundations
Oct 29, 2021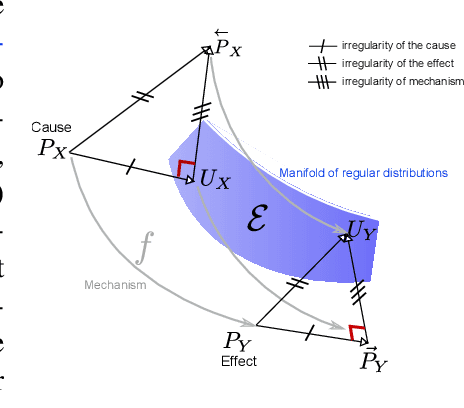
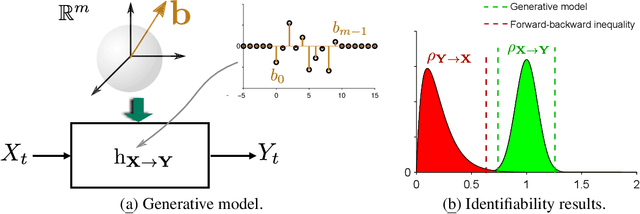
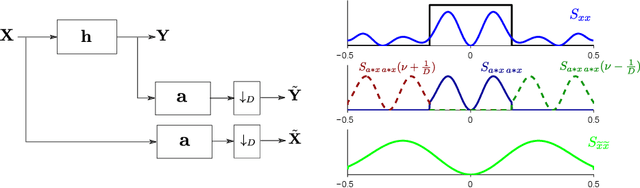
Distinguishing between cause and effect using time series observational data is a major challenge in many scientific fields. A new perspective has been provided based on the principle of Independence of Causal Mechanisms (ICM), leading to the Spectral Independence Criterion (SIC), postulating that the power spectral density (PSD) of the cause time series is uncorrelated with the squared modulus of the frequency response of the filter generating the effect. Since SIC rests on methods and assumptions in stark contrast with most causal discovery methods for time series, it raises questions regarding what theoretical grounds justify its use. In this paper, we provide answers covering several key aspects. After providing an information theoretic interpretation of SIC, we present an identifiability result that sheds light on the context for which this approach is expected to perform well. We further demonstrate the robustness of SIC to downsampling - an obstacle that can spoil Granger-based inference. Finally, an invariance perspective allows to explore the limitations of the spectral independence assumption and how to generalize it. Overall, these results support the postulate of Spectral Independence is a well grounded leading principle for causal inference based on empirical time series.