 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Prompt for Continual Learning
Dec 16, 2021
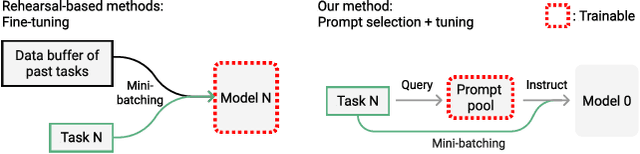
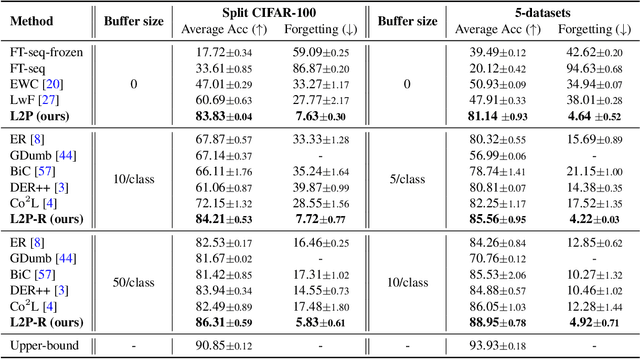
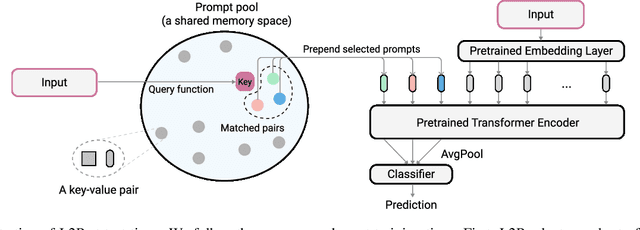
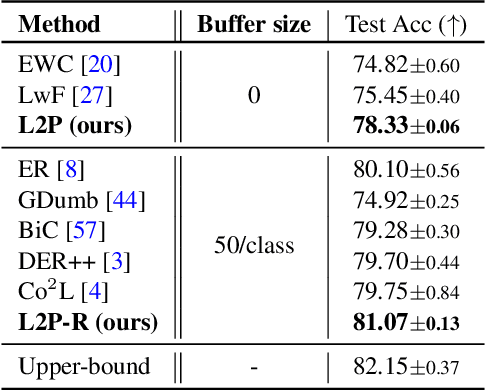
The mainstream paradigm behind continual learning has been to adapt the model parameters to non-stationary data distributions, where catastrophic forgetting is the central challenge. Typical methods rely on a rehearsal buffer or known task identity at test time to retrieve learned knowledge and address forgetting, while this work presents a new paradigm for continual learning that aims to train a more succinct memory system without accessing task identity at test time. Our method learns to dynamically prompt (L2P) a pre-trained model to learn tasks sequentially under different task transitions. In our proposed framework, prompts are small learnable parameters, which are maintained in a memory space. The objective is to optimize prompts to instruct the model prediction and explicitly manage task-invariant and task-specific knowledge while maintaining model plasticity. We conduct comprehensive experiments under popular image classification benchmarks with different challenging continual learning settings, where L2P consistently outperforms prior state-of-the-art methods. Surprisingly, L2P achieves competitive results against rehearsal-based methods even without a rehearsal buffer and is directly applicable to challenging task-agnostic continual learning. Source code is available at https://github.com/google-research/l2p.
Design choice and machine learning model performances
Jan 25, 2022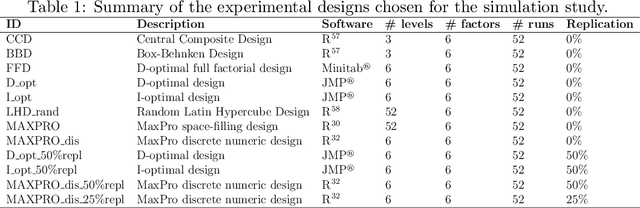
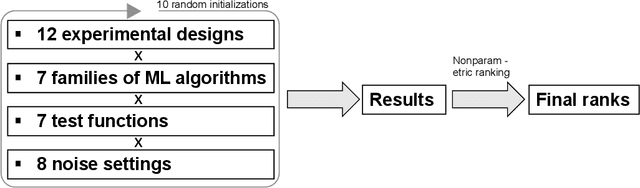

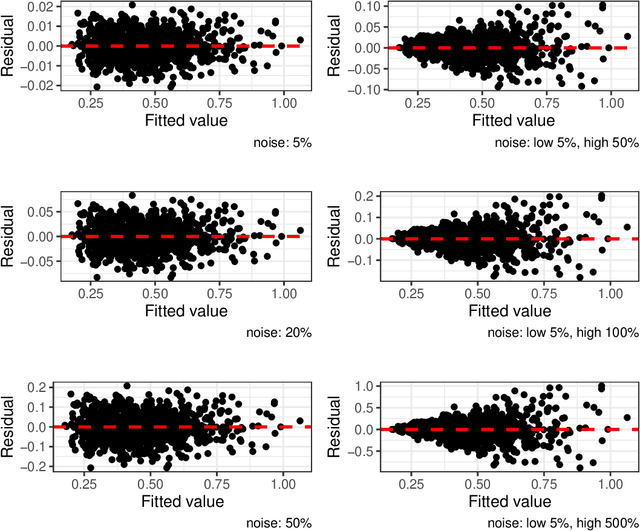
An increasing number of publications present the joint application of Design of Experiments (DOE) and machine learning (ML) as a methodology to collect and analyze data on a specific industrial phenomenon. However, the literature shows that the choice of the design for data collection and model for data analysis is often driven by incidental factors, rather than by statistical or algorithmic advantages, thus there is a lack of studies which provide guidelines on what designs and ML models to jointly use for data collection and analysis. This is the first time in the literature that a paper discusses the choice of design in relation to the ML model performances. An extensive study is conducted that considers 12 experimental designs, 7 families of predictive models, 7 test functions that emulate physical processes, and 8 noise settings, both homoscedastic and heteroscedastic. The results of the research can have an immediate impact on the work of practitioners, providing guidelines for practical applications of DOE and ML.
Higher Order Recurrent Space-Time Transformer
Apr 17, 2021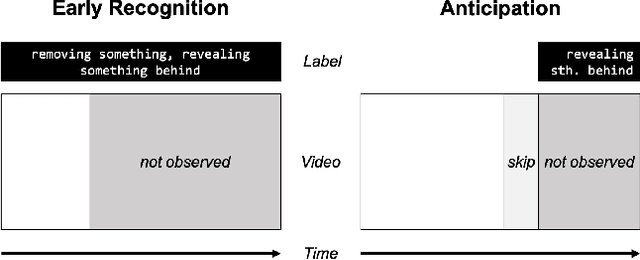
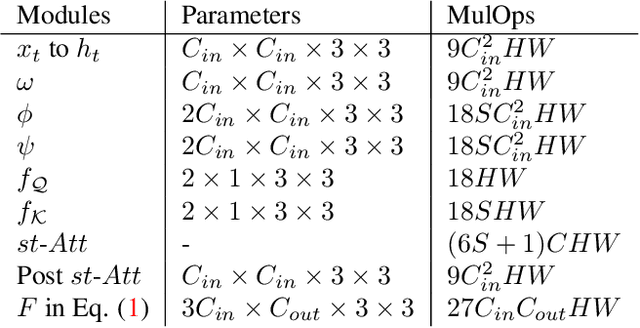
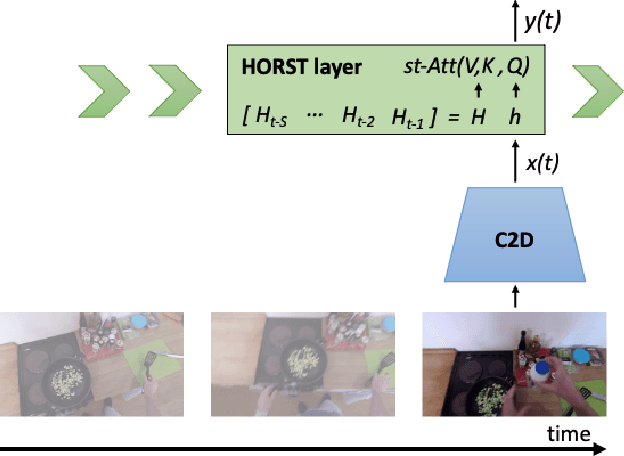

Endowing visual agents with predictive capability is a key step towards video intelligence at scale. The predominant modeling paradigm for this is sequence learning, mostly implemented through LSTMs. Feed-forward Transformer architectures have replaced recurrent model designs in ML applications of language processing and also partly in computer vision. In this paper we investigate on the competitiveness of Transformer-style architectures for video predictive tasks. To do so we propose HORST, a novel higher order recurrent layer design whose core element is a spatial-temporal decomposition of self-attention for video. HORST achieves state of the art competitive performance on Something-Something-V2 early action recognition and EPIC-Kitchens-55 action anticipation, without exploiting a task specific design. We believe this is promising evidence of causal predictive capability that we attribute to our recurrent higher order design of self-attention.
Improving Behavioural Cloning with Human-Driven Dynamic Dataset Augmentation
Jan 19, 2022Behavioural cloning has been extensively used to train agents and is recognized as a fast and solid approach to teach general behaviours based on expert trajectories. Such method follows the supervised learning paradigm and it strongly depends on the distribution of the data. In our paper, we show how combining behavioural cloning with human-in-the-loop training solves some of its flaws and provides an agent task-specific corrections to overcome tricky situations while speeding up the training time and lowering the required resources. To do this, we introduce a novel approach that allows an expert to take control of the agent at any moment during a simulation and provide optimal solutions to its problematic situations. Our experiments show that this approach leads to better policies both in terms of quantitative evaluation and in human-likeliness.
A benchmark of state-of-the-art sound event detection systems evaluated on synthetic soundscapes
Feb 08, 2022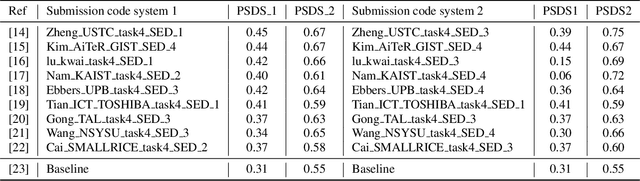
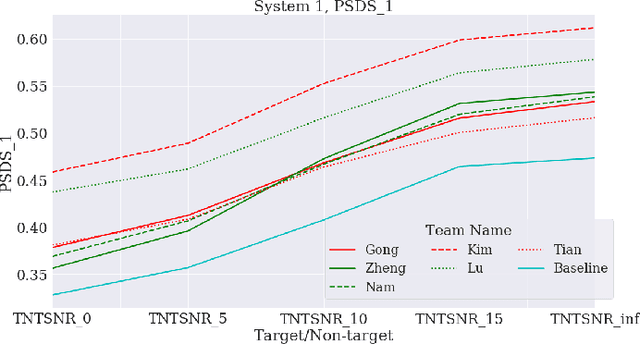
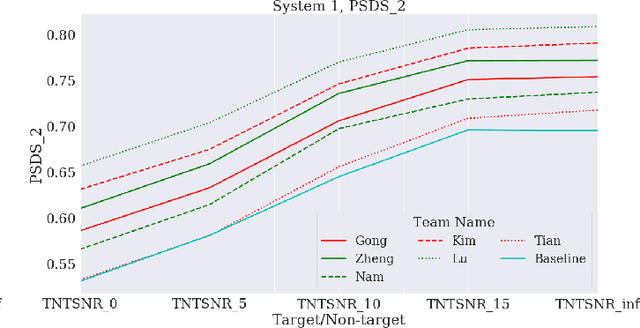
This paper proposes a benchmark of submissions to Detection and Classification Acoustic Scene and Events 2021 Challenge (DCASE) Task 4 representing a sampling of the state-of-the-art in Sound Event Detection task. The submissions are evaluated according to the two polyphonic sound detection score scenarios proposed for the DCASE 2021 Challenge Task 4, which allow to make an analysis on whether submissions are designed to perform fine-grained temporal segmentation, coarse-grained temporal segmentation, or have been designed to be polyvalent on the scenarios proposed. We study the solutions proposed by participants to analyze their robustness to varying level target to non-target signal-to-noise ratio and to temporal localization of target sound events. A last experiment is proposed in order to study the impact of non-target events on systems outputs. Results show that systems adapted to provide coarse segmentation outputs are more robust to different target to non-target signal-to-noise ratio and, with the help of specific data augmentation methods, they are more robust to time localization of the original event. Results of the last experiment display that systems tend to spuriously predict short events when non-target events are present. This is particularly true for systems that are tailored to have a fine segmentation.
Time series classification for varying length series
Oct 10, 2019
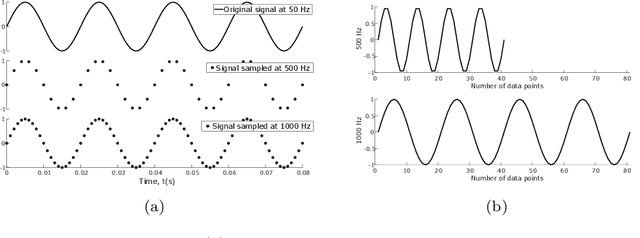
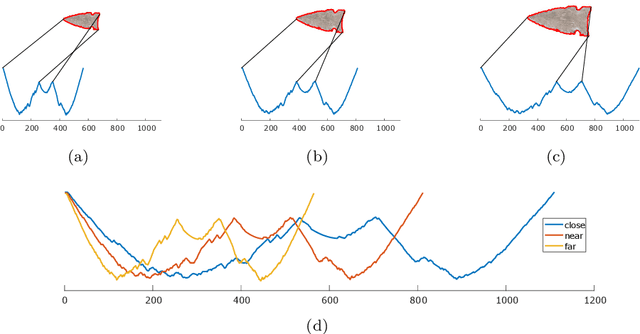
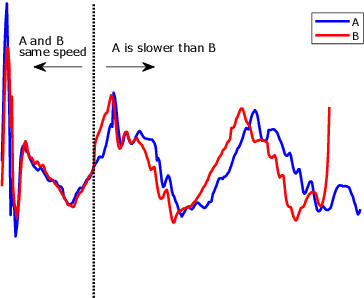
Research into time series classification has tended to focus on the case of series of uniform length. However, it is common for real-world time series data to have unequal lengths. Differing time series lengths may arise from a number of fundamentally different mechanisms. In this work, we identify and evaluate two classes of such mechanisms -- variations in sampling rate relative to the relevant signal and variations between the start and end points of one time series relative to one another. We investigate how time series generated by each of these classes of mechanism are best addressed for time series classification. We perform extensive experiments and provide practical recommendations on how variations in length should be handled in time series classification.
SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
Jan 30, 2022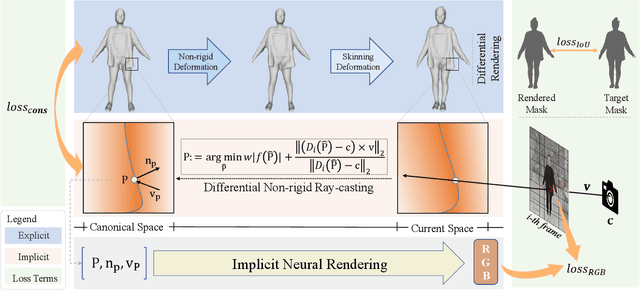
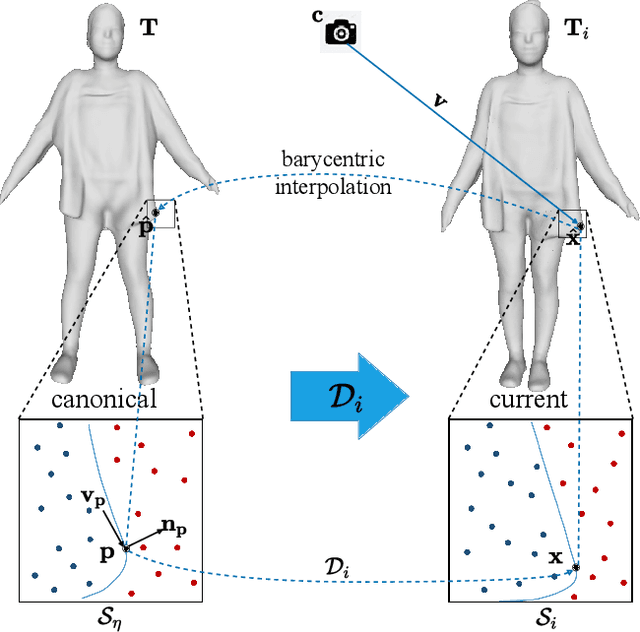

We propose SelfRecon, a clothed human body reconstruction method that combines implicit and explicit representations to recover space-time coherent geometries from a monocular self-rotating human video. Explicit methods require a predefined template mesh for a given sequence, while the template is hard to acquire for a specific subject. Meanwhile, the fixed topology limits the reconstruction accuracy and clothing types. Implicit methods support arbitrary topology and have high quality due to continuous geometric representation. However, it is difficult to integrate multi-frame information to produce a consistent registration sequence for downstream applications. We propose to combine the advantages of both representations. We utilize differential mask loss of the explicit mesh to obtain the coherent overall shape, while the details on the implicit surface are refined with the differentiable neural rendering. Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations closely. Compared with existing methods, SelfRecon can produce high-fidelity surfaces for arbitrary clothed humans with self-supervised optimization. Extensive experimental results demonstrate its effectiveness on real captured monocular videos.
Playing against no-regret players
Feb 16, 2022In increasingly different contexts, it happens that a human player has to interact with artificial players who make decisions following decision-making algorithms. How should the human player play against these algorithms to maximize his utility? Does anything change if he faces one or more artificial players? The main goal of the paper is to answer these two questions. Consider n-player games in normal form repeated over time, where we call the human player optimizer, and the (n -- 1) artificial players, learners. We assume that learners play no-regret algorithms, a class of algorithms widely used in online learning and decision-making. In these games, we consider the concept of Stackelberg equilibrium. In a recent paper, Deng, Schneider, and Sivan have shown that in a 2-player game the optimizer can always guarantee an expected cumulative utility of at least the Stackelberg value per round. In our first result, we show, with counterexamples, that this result is no longer true if the optimizer has to face more than one player. Therefore, we generalize the definition of Stackelberg equilibrium introducing the concept of correlated Stackelberg equilibrium. Finally, in the main result, we prove that the optimizer can guarantee at least the correlated Stackelberg value per round. Moreover, using a version of the strong law of large numbers, we show that our result is also true almost surely for the optimizer utility instead of the optimizer's expected utility.
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 20, 2021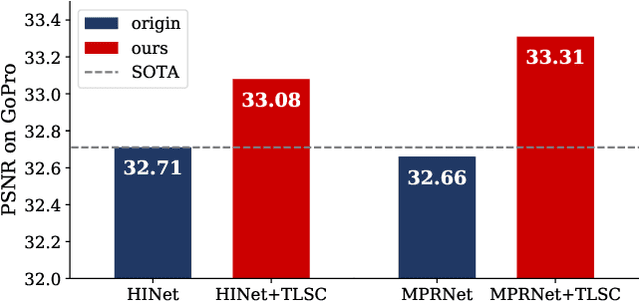
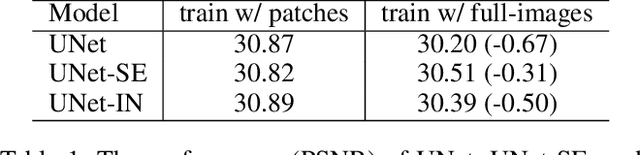
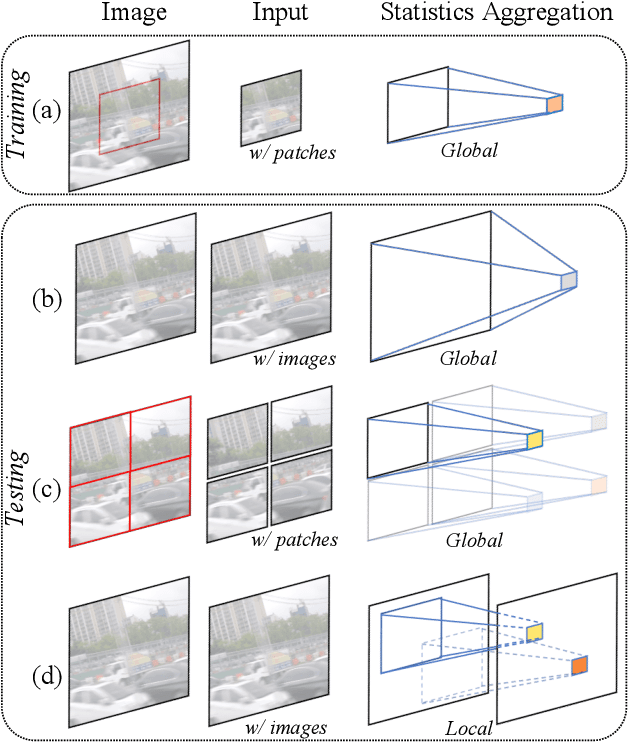
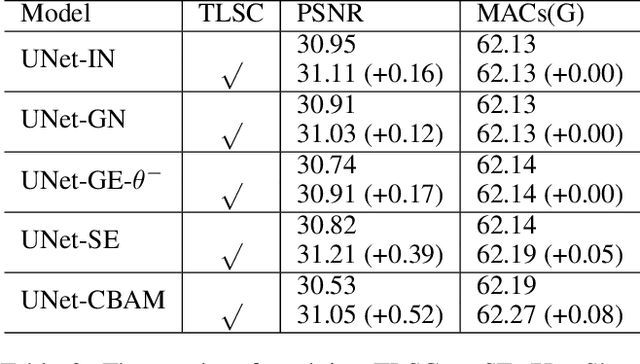
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
Blockchain Framework for Artificial Intelligence Computation
Feb 23, 2022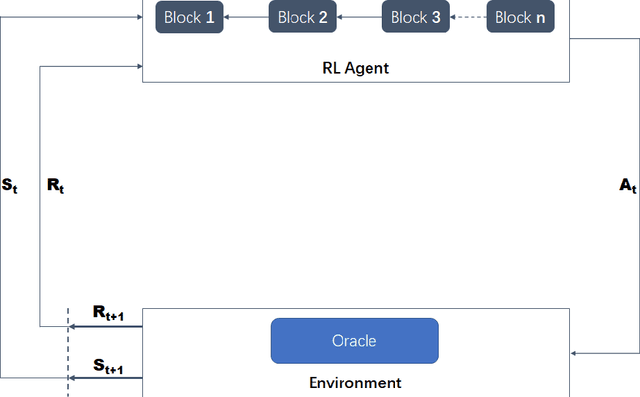

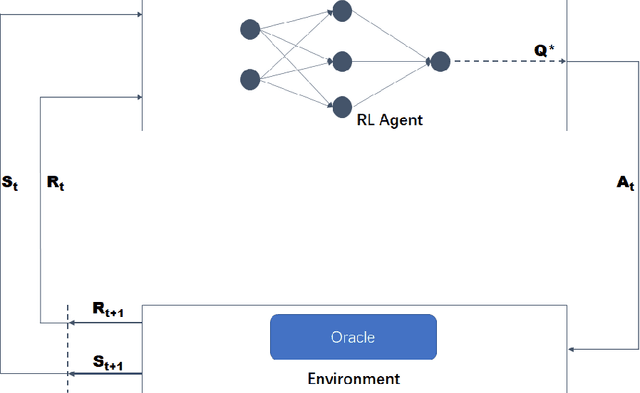
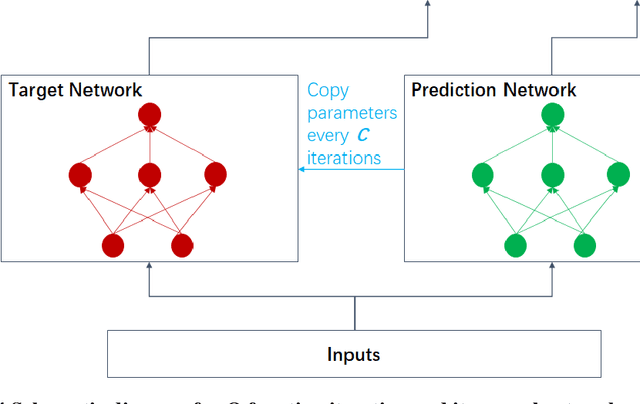
Blockchain is an essentially distributed database recording all transactions or digital events among participating parties. Each transaction in the records is approved and verified by consensus of the participants in the system that requires solving a hard mathematical puzzle, which is known as proof-of-work. To make the approved records immutable, the mathematical puzzle is not trivial to solve and therefore consumes substantial computing resources. However, it is energy-wasteful to have many computational nodes installed in the blockchain competing to approve the records by just solving a meaningless puzzle. Here, we pose proof-of-work as a reinforcement-learning problem by modeling the blockchain growing as a Markov decision process, in which a learning agent makes an optimal decision over the environment's state, whereas a new block is added and verified. Specifically, we design the block verification and consensus mechanism as a deep reinforcement-learning iteration process. As a result, our method utilizes the determination of state transition and the randomness of action selection of a Markov decision process, as well as the computational complexity of a deep neural network, collectively to make the blocks not easy to recompute and to preserve the order of transactions, while the blockchain nodes are exploited to train the same deep neural network with different data samples (state-action pairs) in parallel, allowing the model to experience multiple episodes across computing nodes but at one time. Our method is used to design the next generation of public blockchain networks, which has the potential not only to spare computational resources for industrial applications but also to encourage data sharing and AI model design for common problems.
* 10 pages, 4 figures