 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ValAsp: a tool for data validation in Answer Set Programming
Feb 19, 2022

The development of complex software requires tools promoting fail-fast approaches, so that bugs and unexpected behavior can be quickly identified and fixed. Tools for data validation may save the day of computer programmers. In fact, processing invalid data is a waste of resources at best, and a drama at worst if the problem remains unnoticed and wrong results are used for business. Answer Set Programming (ASP) is not an exception, but the quest for better and better performance resulted in systems that essentially do not validate data. Even under the simplistic assumption that input/output data are eventually validated by external tools, invalid data may appear in other portions of the program, and go undetected until some other module of the designed software suddenly breaks. This paper formalizes the problem of data validation for ASP programs, introduces a language to specify data validation, and presents \textsc{valasp}, a tool to inject data validation in ordinary programs. The proposed approach promotes fail-fast techniques at coding time without imposing any lag on the deployed system if data are pretended to be valid. Validation can be specified in terms of statements using YAML, ASP and Python. Additionally, the proposed approach opens the possibility to use ASP for validating data of imperative programming languages. Under consideration for acceptance in TPLP.
Exploring Deep Reinforcement Learning-Assisted Federated Learning for Online Resource Allocation in EdgeIoT
Feb 15, 2022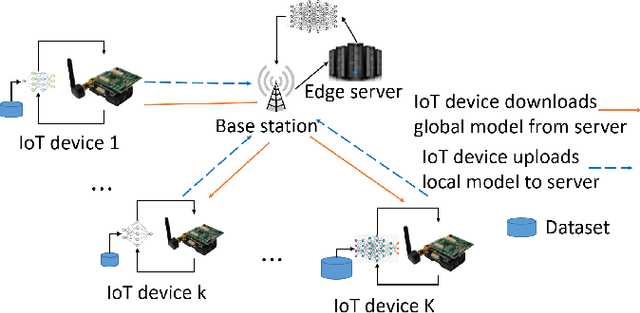
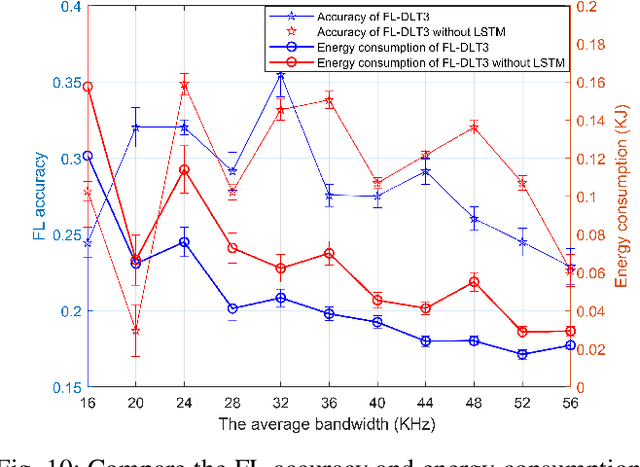
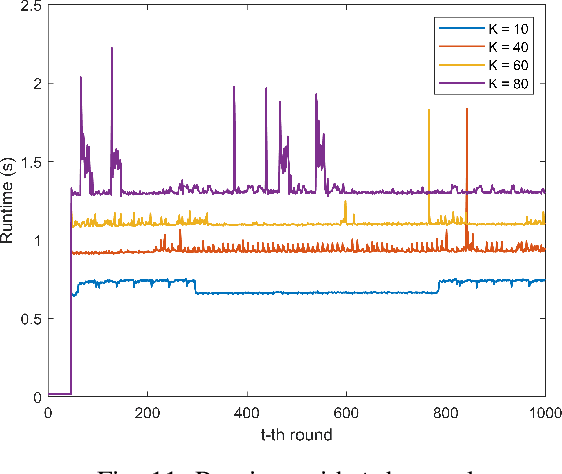
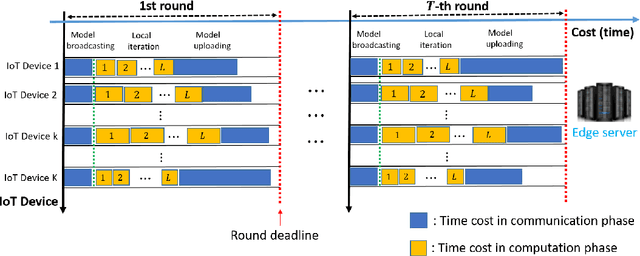
Federated learning (FL) has been increasingly considered to preserve data training privacy from eavesdropping attacks in mobile edge computing-based Internet of Thing (EdgeIoT). On the one hand, the learning accuracy of FL can be improved by selecting the IoT devices with large datasets for training, which gives rise to a higher energy consumption. On the other hand, the energy consumption can be reduced by selecting the IoT devices with small datasets for FL, resulting in a falling learning accuracy. In this paper, we formulate a new resource allocation problem for EdgeIoT to balance the learning accuracy of FL and the energy consumption of the IoT device. We propose a new federated learning-enabled twin-delayed deep deterministic policy gradient (FLDLT3) framework to achieve the optimal accuracy and energy balance in a continuous domain. Furthermore, long short term memory (LSTM) is leveraged in FL-DLT3 to predict the time-varying network state while FL-DLT3 is trained to select the IoT devices and allocate the transmit power. Numerical results demonstrate that the proposed FL-DLT3 achieves fast convergence (less than 100 iterations) while the FL accuracy-to-energy consumption ratio is improved by 51.8% compared to existing state-of-the-art benchmark.
Estimating the Euclidean Quantum Propagator with Deep Generative Modelling of Feynman paths
Feb 06, 2022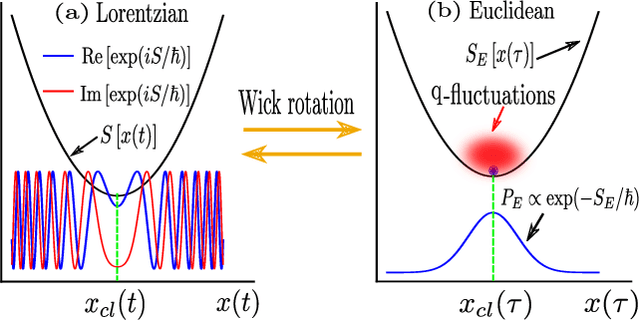
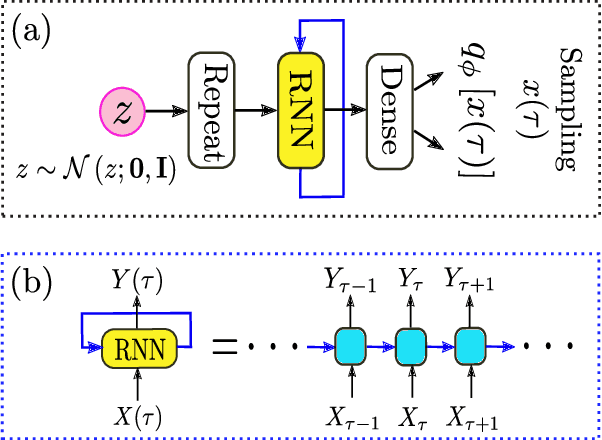
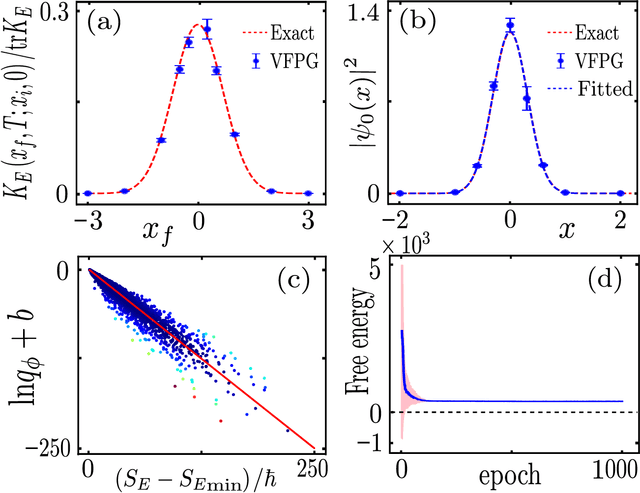
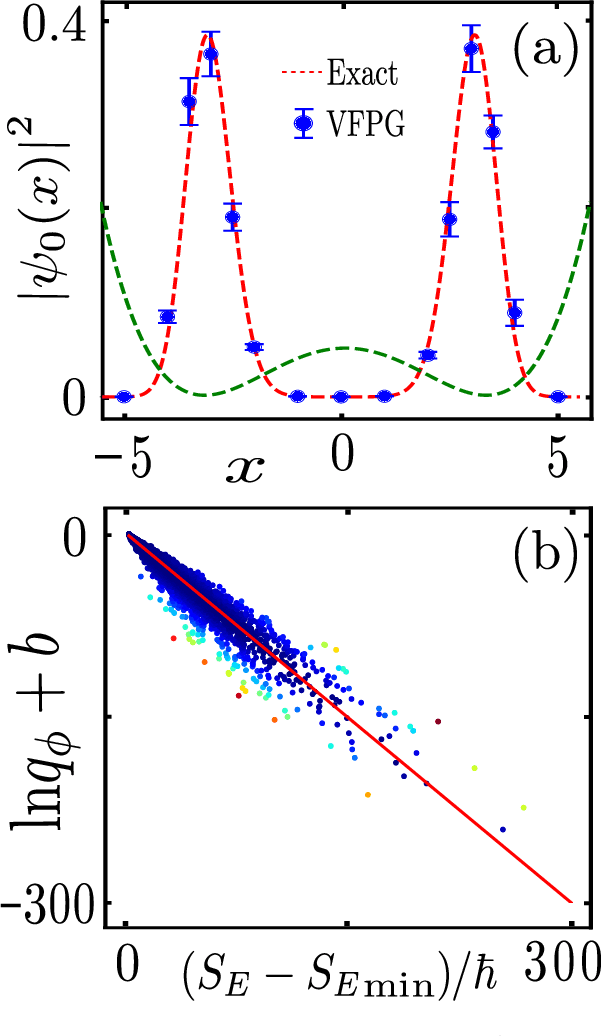
Feynman path integrals provide an elegant, classically-inspired representation for the quantum propagator and the quantum dynamics, through summing over a huge manifold of all possible paths. From computational and simulational perspectives, the ergodic tracking of the whole path manifold is a hard problem. Machine learning can help, in an efficient manner, to identify the relevant subspace and the intrinsic structure residing at a small fraction of the vast path manifold. In this work, we propose the concept of Feynman path generator, which efficiently generates Feynman paths with fixed endpoints from a (low-dimensional) latent space, by targeting a desired density of paths in the Euclidean space-time. With such path generators, the Euclidean propagator as well as the ground state wave function can be estimated efficiently for a generic potential energy. Our work leads to a fresh approach for calculating the quantum propagator, paves the way toward generative modelling of Feynman paths, and may also provide a future new perspective to understand the quantum-classical correspondence through deep learning.
Bird Species Classification And Acoustic Features Selection Based on Distributed Neural Network with Two Stage Windowing of Short-Term Features
Jan 01, 2022
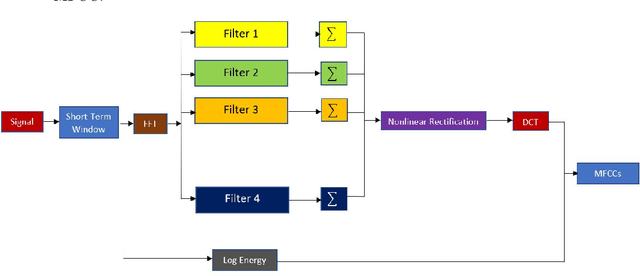
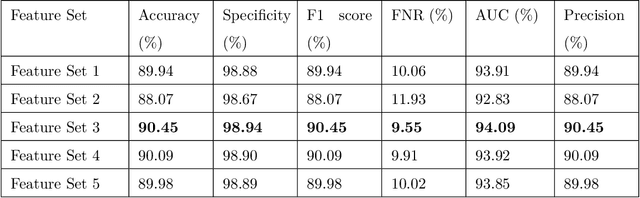
Identification of bird species from audio records is one of the challenging tasks due to the existence of multiple species in the same recording, noise in the background, and long-term recording. Besides, choosing a proper acoustic feature from audio recording for bird species classification is another problem. In this paper, a hybrid method is represented comprising both traditional signal processing and a deep learning-based approach to classify bird species from audio recordings of diverse sources and types. Besides, a detailed study with 34 different features helps to select the proper feature set for classification and analysis in real-time applications. Moreover, the proposed deep neural network uses both acoustic and temporal feature learning. The proposed method starts with detecting voice activity from the raw signal, followed by extracting short-term features from the processed recording using 50 ms (with 25ms overlapping) time windows. Later, the short-term features are reshaped using second stage (non-overlapping) windowing to be trained through a distributed 2D Convolutional Neural Network (CNN) that forwards the output features to a Long and Short Term Memory (LSTM) Network. Then a final dense layer classifies the bird species. For the 10 class classifier, the highest accuracy achieved was 90.45\% for a feature set consisting of 13 Mel Frequency Cepstral Coefficients (MFCCs) and 12 Chroma Vectors. The corresponding specificity and AUC scores are 98.94\% and 94.09\%, respectively.
Le Processus Powered Dirichlet-Hawkes comme A Priori Flexible pour Clustering Temporel de Textes
Jan 29, 2022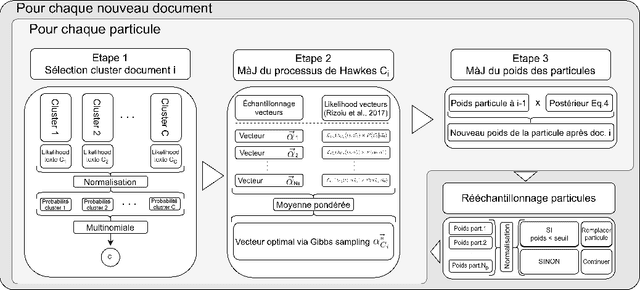
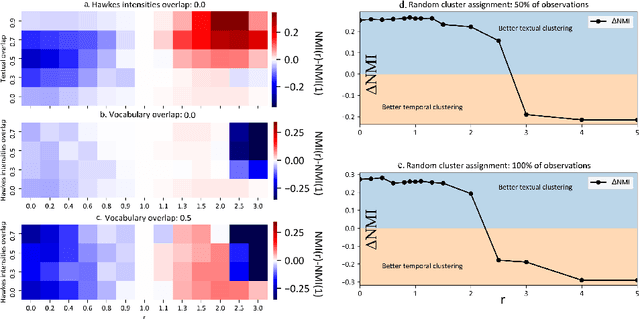
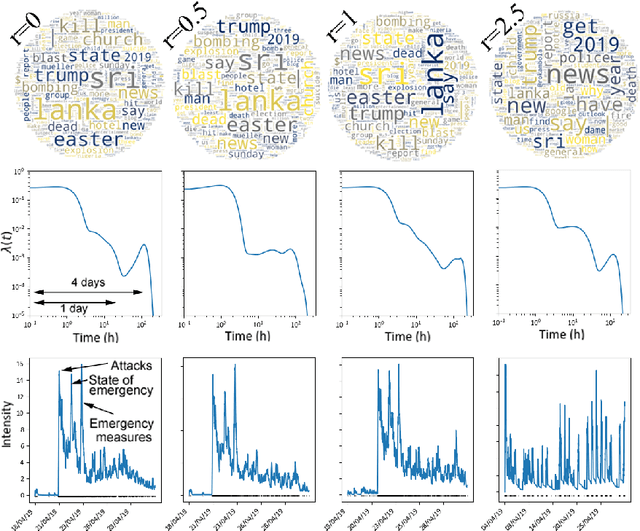
The textual content of a document and its publication date are intertwined. For example, the publication of a news article on a topic is influenced by previous publications on similar issues, according to underlying temporal dynamics. However, it can be challenging to retrieve meaningful information when textual information conveys little. Furthermore, the textual content of a document is not always correlated to its temporal dynamics. We develop a method to create clusters of textual documents according to both their content and publication time, the Powered Dirichlet-Hawkes process (PDHP). PDHP yields significantly better results than state-of-the-art models when temporal information or textual content is weakly informative. PDHP also alleviates the hypothesis that textual content and temporal dynamics are perfectly correlated. We demonstrate that PDHP generalizes previous work --such as DHP and UP. Finally, we illustrate a possible application using a real-world dataset from Reddit.
Deep Learning-based Anomaly Detection on X-ray Images of Fuel Cell Electrodes
Feb 15, 2022
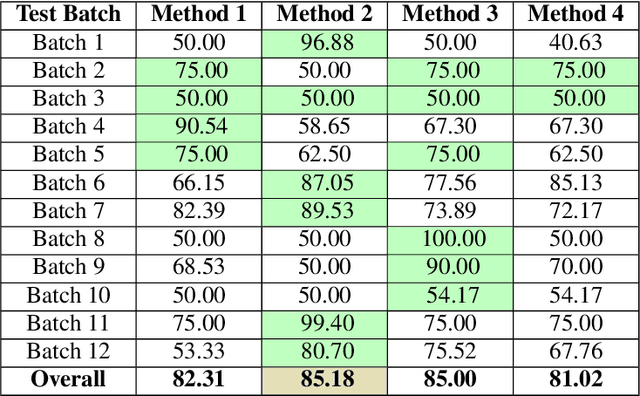

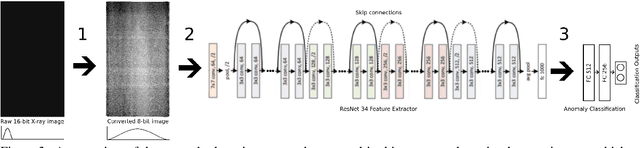
Anomaly detection in X-ray images has been an active and lasting research area in the last decades, especially in the domain of medical X-ray images. For this work, we created a real-world labeled anomaly dataset, consisting of 16-bit X-ray image data of fuel cell electrodes coated with a platinum catalyst solution and perform anomaly detection on the dataset using a deep learning approach. The dataset contains a diverse set of anomalies with 11 identified common anomalies where the electrodes contain e.g. scratches, bubbles, smudges etc. We experiment with 16-bit image to 8-bit image conversion methods to utilize pre-trained Convolutional Neural Networks as feature extractors (transfer learning) and find that we achieve the best performance by maximizing the contrasts globally across the dataset during the 16-bit to 8-bit conversion, through histogram equalization. We group the fuel cell electrodes with anomalies into a single class called abnormal and the normal fuel cell electrodes into a class called normal, thereby abstracting the anomaly detection problem into a binary classification problem. We achieve a balanced accuracy of 85.18\%. The anomaly detection is used by the company, Serenergy, for optimizing the time spend on the quality control of the fuel cell electrodes
* 10 pages, 9 figures, VISAPP2022
Unified Physical Threat Monitoring System Aided by Virtual Building Simulation
Mar 01, 2022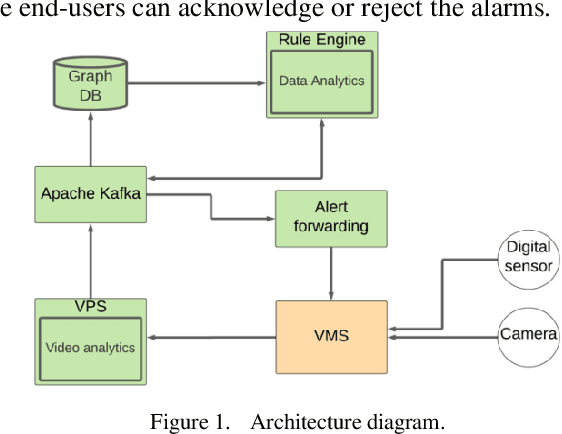

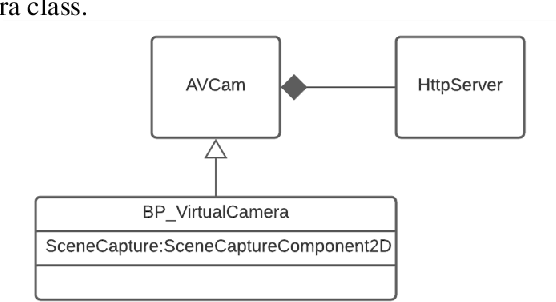
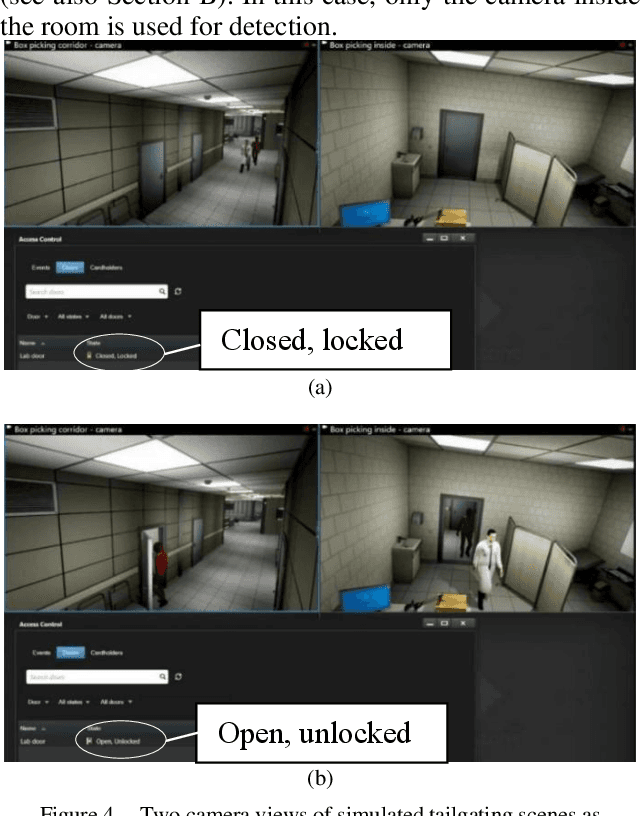
With increasing physical threats in recent years targeted at critical infrastructures, it is crucial to establish a reliable threat monitoring system integrating video surveillance and digital sensors based on cutting-edge technologies. A physical threat monitoring solution unifying the floorplan, cameras, and sensors for smart buildings has been set up in our study. Computer vision and deep learning models are used for video streams analysis. When a threat is detected by a rule engine based on the real-time analysis results combining with feedback from related digital sensors, an alert is sent to the Video Management System so that human operators can take further action. A physical threat monitoring system typically needs to address complex and even destructive incidents, such as fire, which is unrealistic to simulate in real life. Restrictions imposed during the Covid-19 pandemic and privacy concerns have added to the challenges. Our study utilises the Unreal Engine to simulate some typical suspicious and intrusion scenes with photorealistic qualities in the context of a virtual building. Add-on programs are implemented to transfer the video stream from virtual PTZ cameras to the Milestone Video Management System and enable users to control those cameras from the graphic client application. Virtual sensors such as fire alarms, temperature sensors and door access controls are implemented similarly, fulfilling the same programmatic VMS interface as real-life sensors. Thanks to this simulation system's extensibility and repeatability, we have consolidated this unified physical threat monitoring system and verified its effectiveness and user-friendliness. Both the simulated Unreal scenes and the software add-ons developed during this study are highly modulated and thereby are ready for reuse in future projects in this area.
Runtime Monitoring and Statistical Approaches for Correlation Analysis of ECG and PPG
Jan 20, 2022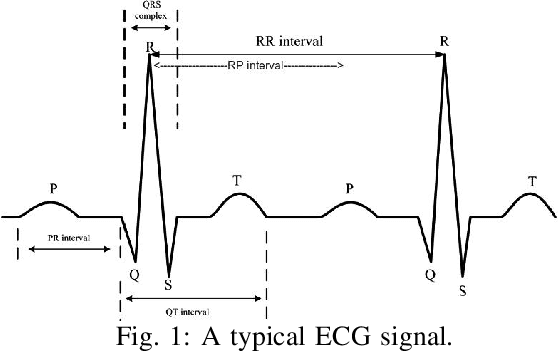
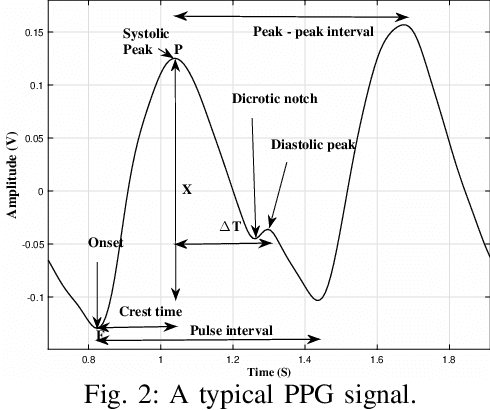
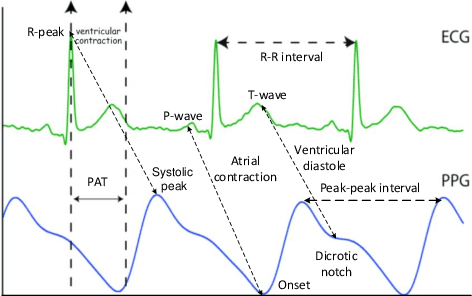
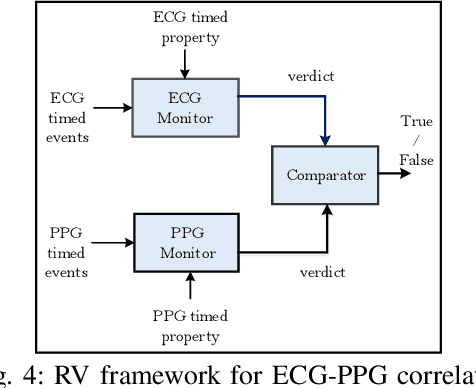
Biophysical signals such as Electrocardiogram (ECG) and Photoplethysmogram (PPG) are key to the sensing of vital parameters for wellbeing. Coincidentally, ECG and PPG are signals, which provide a "different window" into the same phenomena, namely the cardiac cycle. While they are used separately, there are no studies regarding the exact correction of the different ECG and PPG events. Such correlation would be helpful in many fronts such as sensor fusion for improved accuracy using cheaper sensors and attack detection and mitigation methods using multiple signals to enhance the robustness, for example. Considering this, we present the first approach in formally establishing the key relationships between ECG and PPG signals. We combine formal run-time monitoring with statistical analysis and regression analysis for our results.
Achieving Real-Time Execution of 3D Convolutional Neural Networks on Mobile Devices
Jul 20, 2020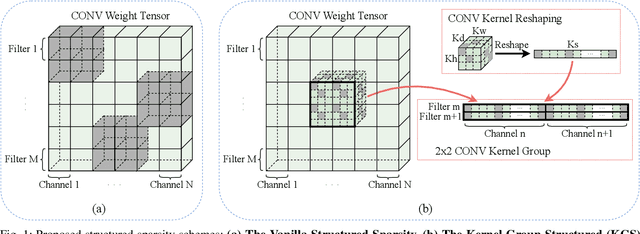
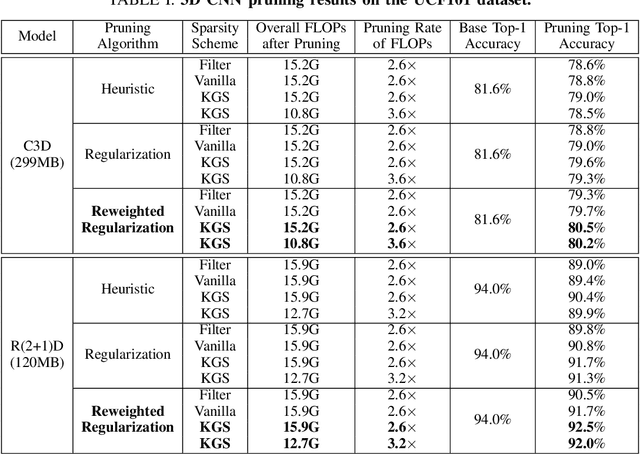
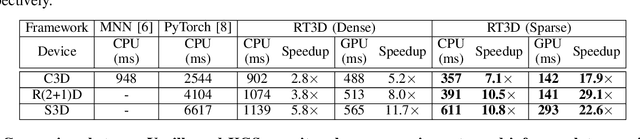

Mobile devices are becoming an important carrier for deep learning tasks, as they are being equipped with powerful, high-end mobile CPUs and GPUs. However, it is still a challenging task to execute 3D Convolutional Neural Networks (CNNs) targeting for real-time performance, besides high inference accuracy. The reason is more complex model structure and higher model dimensionality overwhelm the available computation/storage resources on mobile devices. A natural way may be turning to deep learning weight pruning techniques. However, the direct generalization of existing 2D CNN weight pruning methods to 3D CNNs is not ideal for fully exploiting mobile parallelism while achieving high inference accuracy. This paper proposes RT3D, a model compression and mobile acceleration framework for 3D CNNs, seamlessly integrating neural network weight pruning and compiler code generation techniques. We propose and investigate two structured sparsity schemes i.e., the vanilla structured sparsity and kernel group structured (KGS) sparsity that are mobile acceleration friendly. The vanilla sparsity removes whole kernel groups, while KGS sparsity is a more fine-grained structured sparsity that enjoys higher flexibility while exploiting full on-device parallelism. We propose a reweighted regularization pruning algorithm to achieve the proposed sparsity schemes. The inference time speedup due to sparsity is approaching the pruning rate of the whole model FLOPs (floating point operations). RT3D demonstrates up to 29.1$\times$ speedup in end-to-end inference time comparing with current mobile frameworks supporting 3D CNNs, with moderate 1%-1.5% accuracy loss. The end-to-end inference time for 16 video frames could be within 150 ms, when executing representative C3D and R(2+1)D models on a cellphone. For the first time, real-time execution of 3D CNNs is achieved on off-the-shelf mobiles.
Modular multi-source prediction of drug side-effects with DruGNN
Feb 15, 2022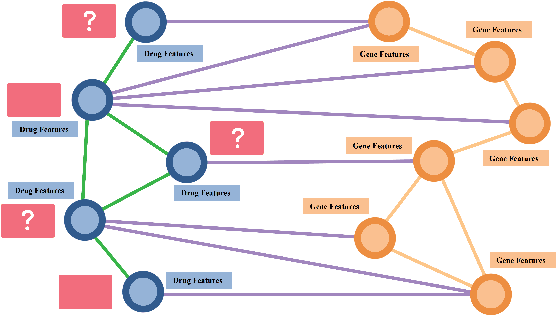
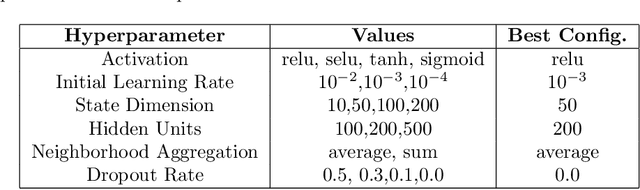
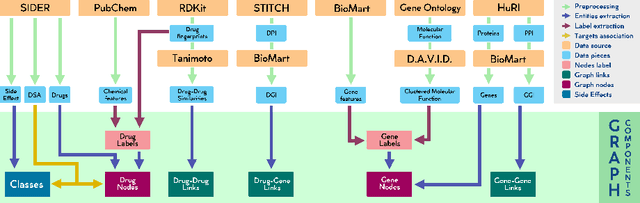

Drug Side-Effects (DSEs) have a high impact on public health, care system costs, and drug discovery processes. Predicting the probability of side-effects, before their occurrence, is fundamental to reduce this impact, in particular on drug discovery. Candidate molecules could be screened before undergoing clinical trials, reducing the costs in time, money, and health of the participants. Drug side-effects are triggered by complex biological processes involving many different entities, from drug structures to protein-protein interactions. To predict their occurrence, it is necessary to integrate data from heterogeneous sources. In this work, such heterogeneous data is integrated into a graph dataset, expressively representing the relational information between different entities, such as drug molecules and genes. The relational nature of the dataset represents an important novelty for drug side-effect predictors. Graph Neural Networks (GNNs) are exploited to predict DSEs on our dataset with very promising results. GNNs are deep learning models that can process graph-structured data, with minimal information loss, and have been applied on a wide variety of biological tasks. Our experimental results confirm the advantage of using relationships between data entities, suggesting interesting future developments in this scope. The experimentation also shows the importance of specific subsets of data in determining associations between drugs and side-effects.