 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dilated Continuous Random Field for Semantic Segmentation
Feb 01, 2022

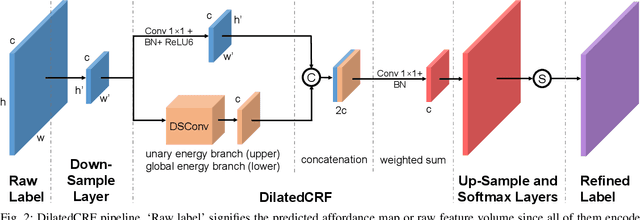
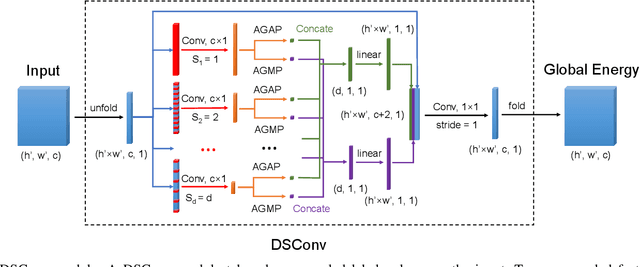
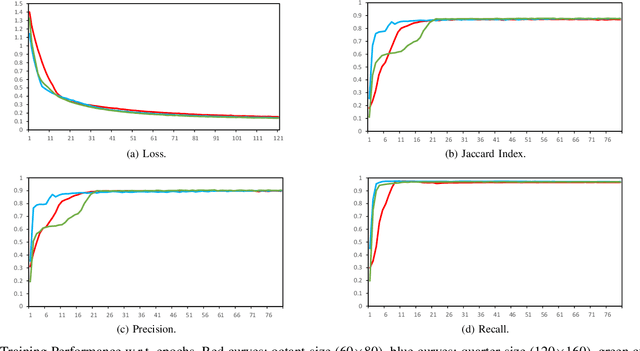
Mean field approximation methodology has laid the foundation of modern Continuous Random Field (CRF) based solutions for the refinement of semantic segmentation. In this paper, we propose to relax the hard constraint of mean field approximation - minimizing the energy term of each node from probabilistic graphical model, by a global optimization with the proposed dilated sparse convolution module (DSConv). In addition, adaptive global average-pooling and adaptive global max-pooling are implemented as replacements of fully connected layers. In order to integrate DSConv, we design an end-to-end, time-efficient DilatedCRF pipeline. The unary energy term is derived either from pre-softmax and post-softmax features, or the predicted affordance map using a conventional classifier, making it easier to implement DilatedCRF for varieties of classifiers. We also present superior experimental results of proposed approach on the suction dataset comparing to other CRF-based approaches.
FedREP: Towards Horizontal Federated Load Forecasting for Retail Energy Providers
Mar 01, 2022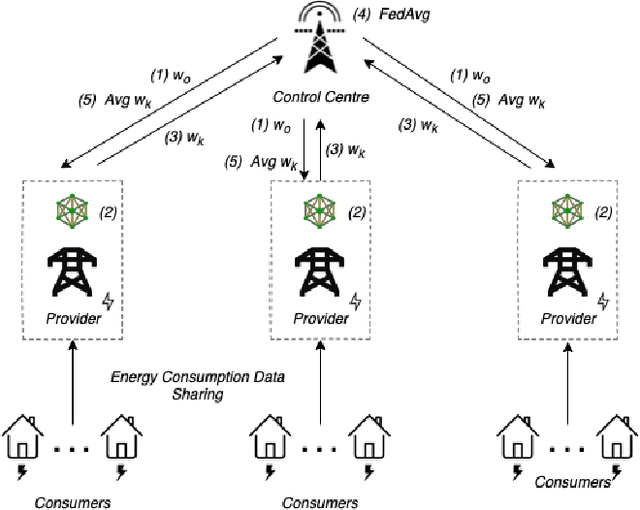
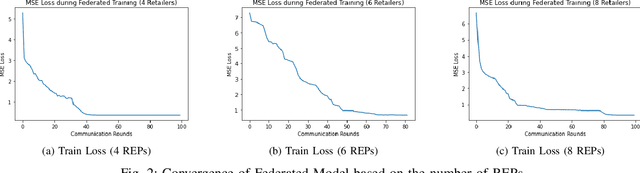
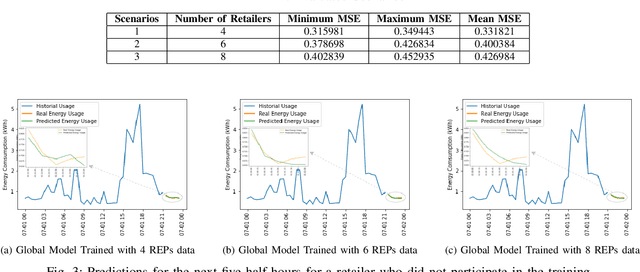
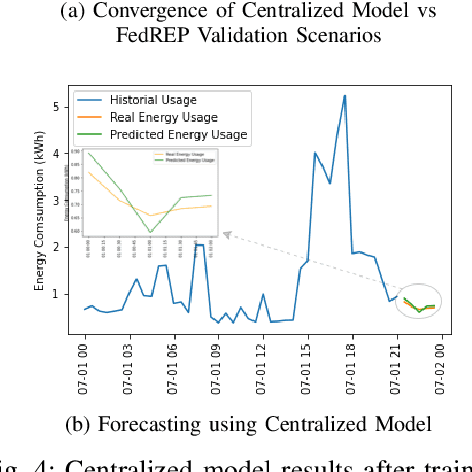
As Smart Meters are collecting and transmitting household energy consumption data to Retail Energy Providers (REP), the main challenge is to ensure the effective use of fine-grained consumer data while ensuring data privacy. In this manuscript, we tackle this challenge for energy load consumption forecasting in regards to REPs which is essential to energy demand management, load switching and infrastructure development. Specifically, we note that existing energy load forecasting is centralized, which are not scalable and most importantly, vulnerable to data privacy threats. Besides, REPs are individual market participants and liable to ensure the privacy of their own customers. To address this issue, we propose a novel horizontal privacy-preserving federated learning framework for REPs energy load forecasting, namely FedREP. We consider a federated learning system consisting of a control centre and multiple retailers by enabling multiple REPs to build a common, robust machine learning model without sharing data, thus addressing critical issues such as data privacy, data security and scalability. For forecasting, we use a state-of-the-art Long Short-Term Memory (LSTM) neural network due to its ability to learn long term sequences of observations and promises of higher accuracy with time-series data while solving the vanishing gradient problem. Finally, we conduct extensive data-driven experiments using a real energy consumption dataset. Experimental results demonstrate that our proposed federated learning framework can achieve sufficient performance in terms of MSE ranging between 0.3 to 0.4 and is relatively similar to that of a centralized approach while preserving privacy and improving scalability.
Run-time Mapping of Spiking Neural Networks to Neuromorphic Hardware
Jun 11, 2020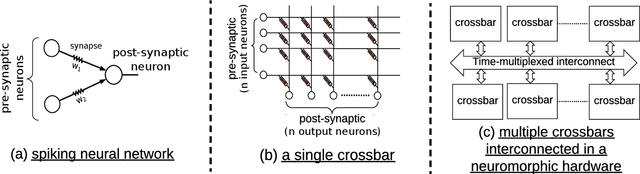
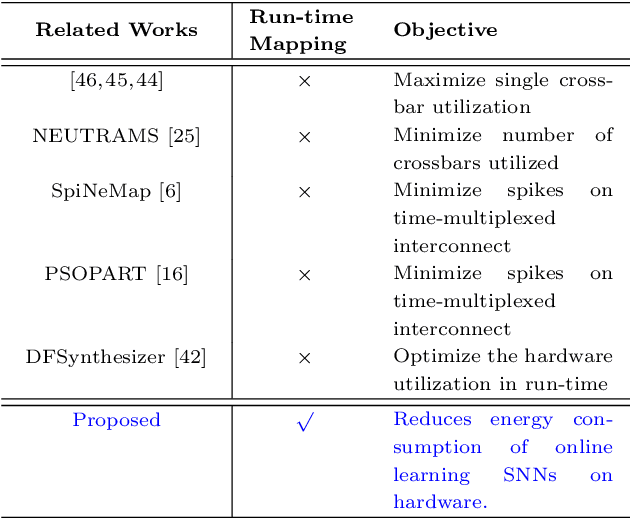
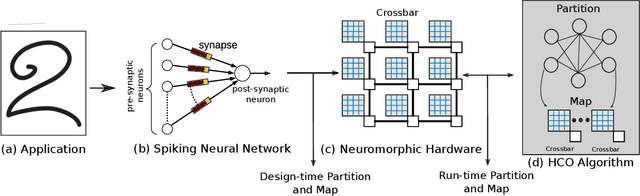
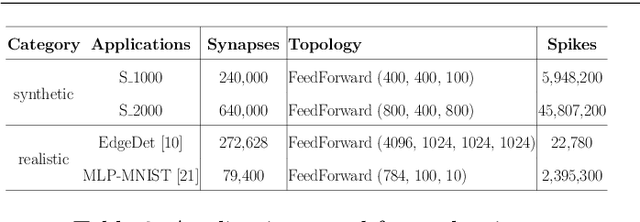
In this paper, we propose a design methodology to partition and map the neurons and synapses of online learning SNN-based applications to neuromorphic architectures at {run-time}. Our design methodology operates in two steps -- step 1 is a layer-wise greedy approach to partition SNNs into clusters of neurons and synapses incorporating the constraints of the neuromorphic architecture, and step 2 is a hill-climbing optimization algorithm that minimizes the total spikes communicated between clusters, improving energy consumption on the shared interconnect of the architecture. We conduct experiments to evaluate the feasibility of our algorithm using synthetic and realistic SNN-based applications. We demonstrate that our algorithm reduces SNN mapping time by an average 780x compared to a state-of-the-art design-time based SNN partitioning approach with only 6.25\% lower solution quality.
Who will Leave a Pediatric Weight Management Program and When? -- A machine learning approach for predicting attrition patterns
Feb 13, 2022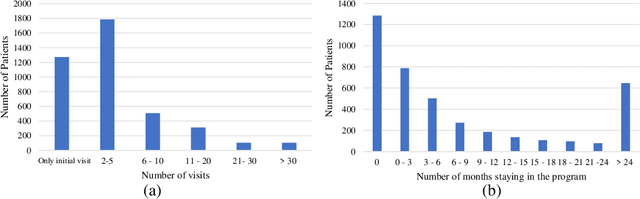
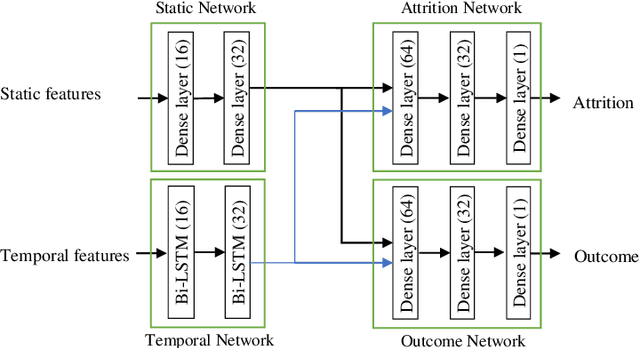
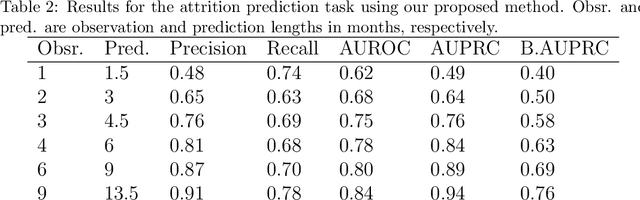
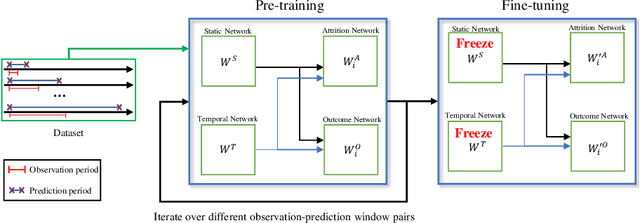
Childhood obesity is a major public health concern. Multidisciplinary pediatric weight management programs are considered standard treatment for children with obesity and severe obesity who are not able to be successfully managed in the primary care setting; however, high drop-out rates (referred to as attrition) are a major hurdle in delivering successful interventions. Predicting attrition patterns can help providers reduce the attrition rates. Previous work has mainly focused on finding static predictors of attrition using statistical analysis methods. In this study, we present a machine learning model to predict (a) the likelihood of attrition, and (b) the change in body-mass index (BMI) percentile of children, at different time points after joining a weight management program. We use a five-year dataset containing the information related to around 4,550 children that we have compiled using data from the Nemours Pediatric Weight Management program. Our models show strong prediction performance as determined by high AUROC scores across different tasks (average AUROC of 0.75 for predicting attrition, and 0.73 for predicting weight outcomes). Additionally, we report the top features predicting attrition and weight outcomes in a series of explanatory experiments.
DRS-LIP: Linear Inverted Pendulum Model for Legged Locomotion on Dynamic Rigid Surfaces
Jan 31, 2022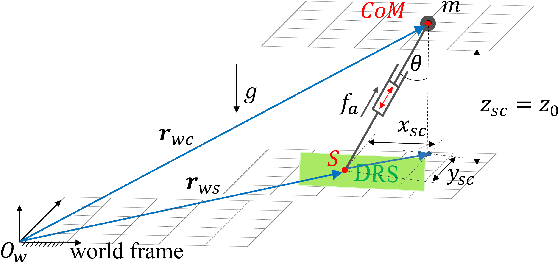
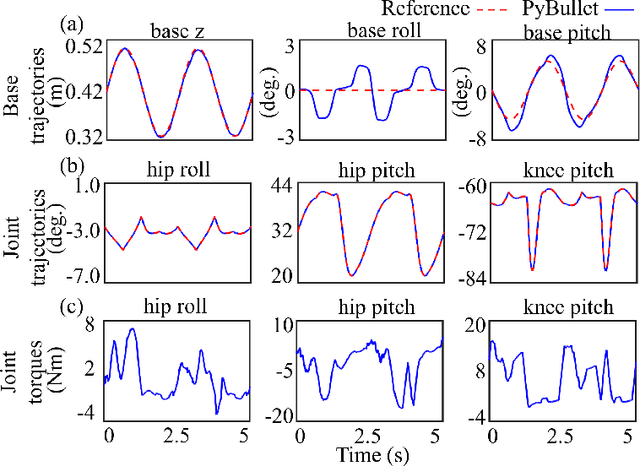
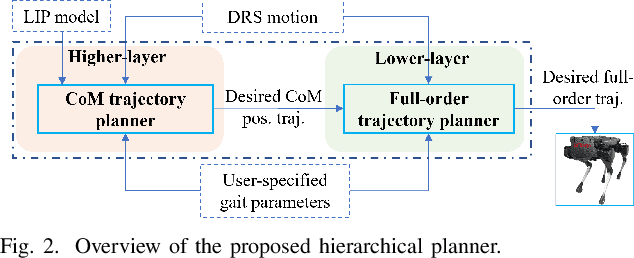
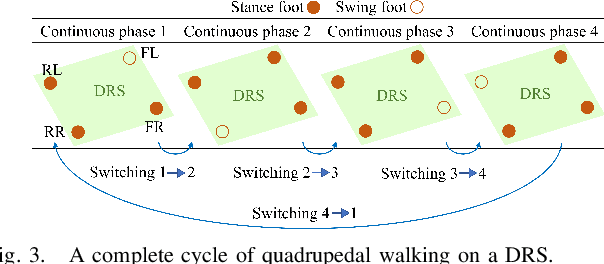
Legged robot locomotion on a dynamic rigid surface (i.e., a rigid surface moving in the inertial frame) involves complex full-order dynamics that is high-dimensional, nonlinear, and time-varying. Towards deriving an analytically tractable dynamic model, this study theoretically extends the reduced-order linear inverted pendulum (LIP) model from legged locomotion on a stationary surface to locomotion on a dynamic rigid surface (DRS). The resulting model is herein termed as DRS-LIP. Furthermore, this study introduces an approximate analytical solution of the proposed DRS-LIP that is computationally efficient with high accuracy. To illustrate the practical uses of the analytical results, they are used to develop a hierarchical planning framework that efficiently generates physically feasible trajectories for DRS locomotion. The effectiveness of the proposed theoretical results and motion planner is demonstrated both through simulations and experimentally on a Laikago quadrupedal robot that walks on a rocking treadmill.
Teaching Networks to Solve Optimization Problems
Feb 08, 2022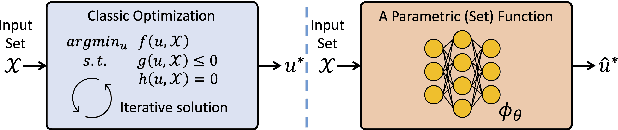
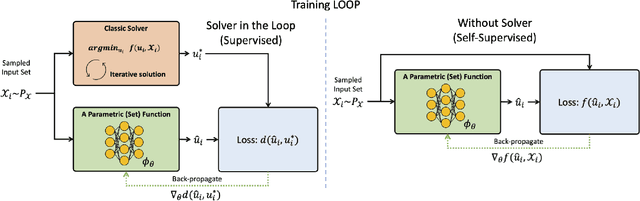
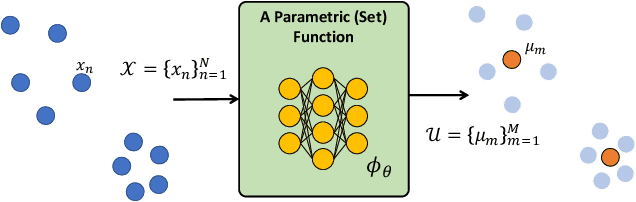
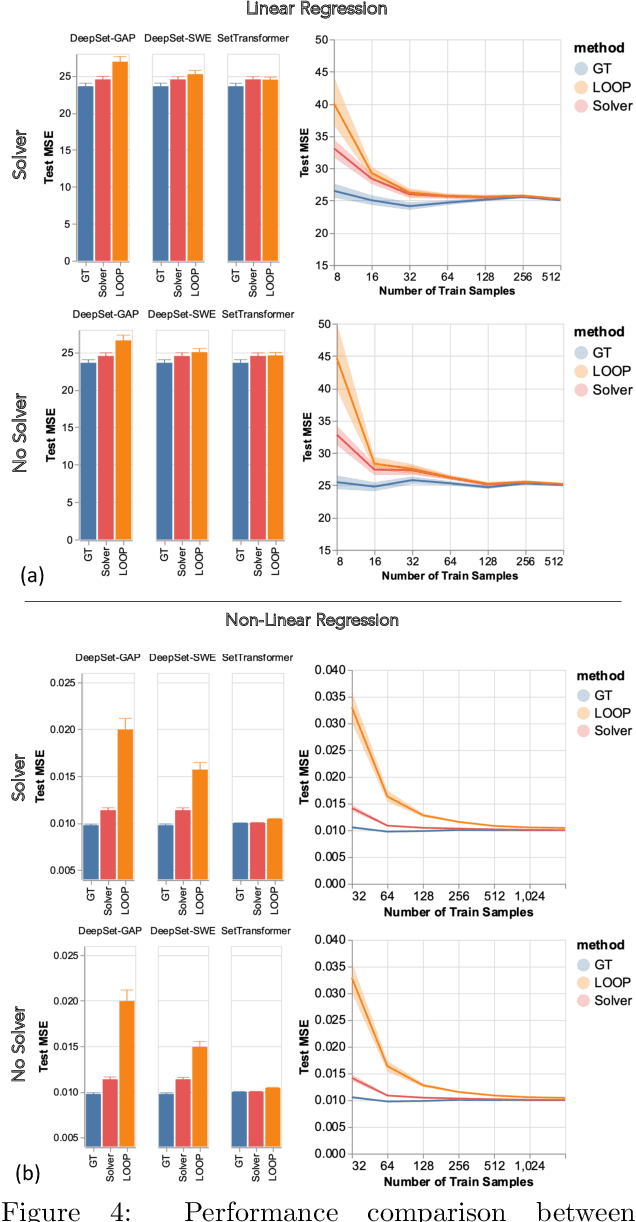
Leveraging machine learning to optimize the optimization process is an emerging field which holds the promise to bypass the fundamental computational bottleneck caused by traditional iterative solvers in critical applications requiring near-real-time optimization. The majority of existing approaches focus on learning data-driven optimizers that lead to fewer iterations in solving an optimization. In this paper, we take a different approach and propose to replace the iterative solvers altogether with a trainable parametric set function that outputs the optimal arguments/parameters of an optimization problem in a single feed-forward. We denote our method as, Learning to Optimize the Optimization Process (LOOP). We show the feasibility of learning such parametric (set) functions to solve various classic optimization problems, including linear/nonlinear regression, principal component analysis, transport-based core-set, and quadratic programming in supply management applications. In addition, we propose two alternative approaches for learning such parametric functions, with and without a solver in the-LOOP. Finally, we demonstrate the effectiveness of our proposed approach through various numerical experiments.
MPF6D: Masked Pyramid Fusion 6D Pose Estimation
Nov 17, 2021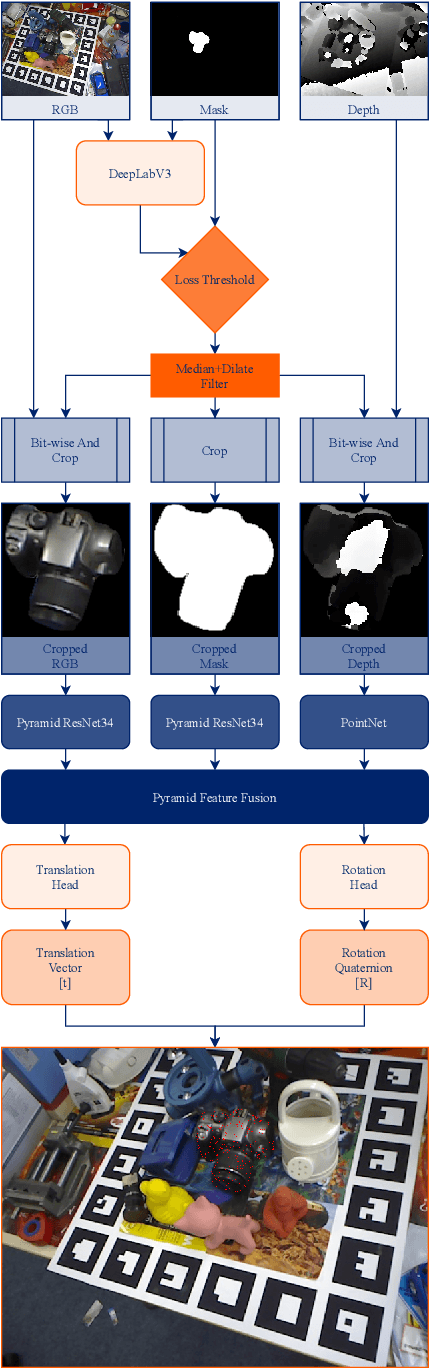
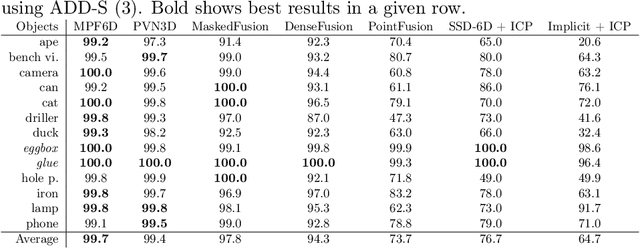
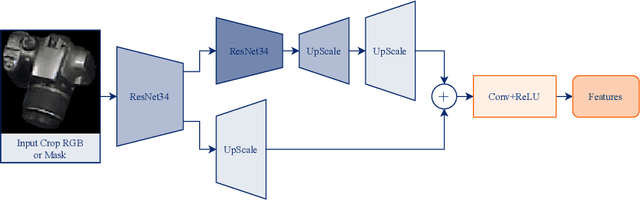
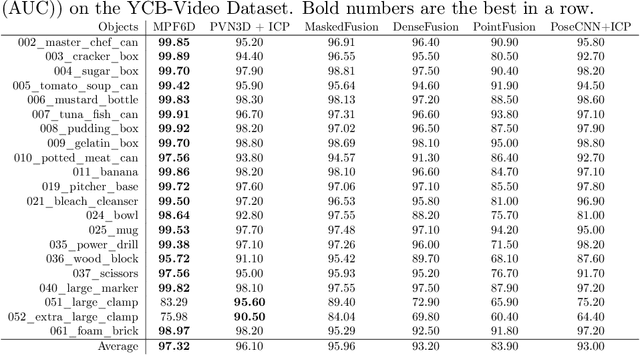
Object pose estimation has multiple important applications, such as robotic grasping and augmented reality. We present a new method to estimate the 6D pose of objects that improves upon the accuracy of current proposals and can still be used in real-time. Our method uses RGB-D data as input to segment objects and estimate their pose. It uses a neural network with multiple heads, one head estimates the object classification and generates the mask, the second estimates the values of the translation vector and the last head estimates the values of the quaternion that represents the rotation of the object. These heads leverage a pyramid architecture used during feature extraction and feature fusion. Our method can be used in real-time with its low inference time of 0.12 seconds and has high accuracy. With this combination of fast inference and good accuracy it is possible to use our method in robotic pick and place tasks and/or augmented reality applications.
Adaptive Sampling to Estimate Quantiles for Guiding Physical Sampling
Jan 25, 2022
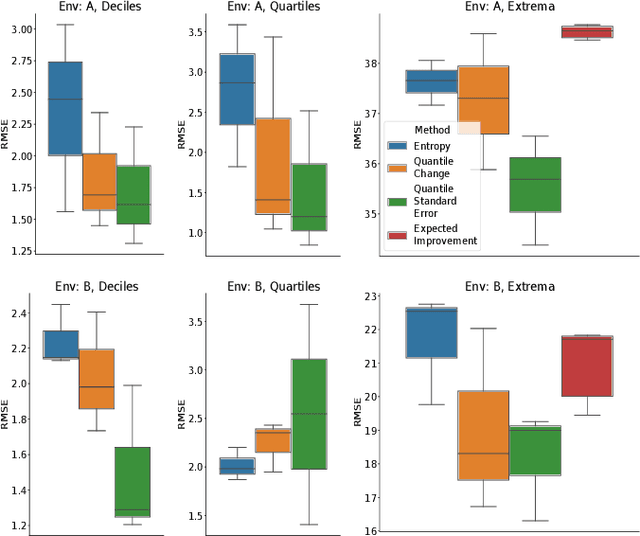
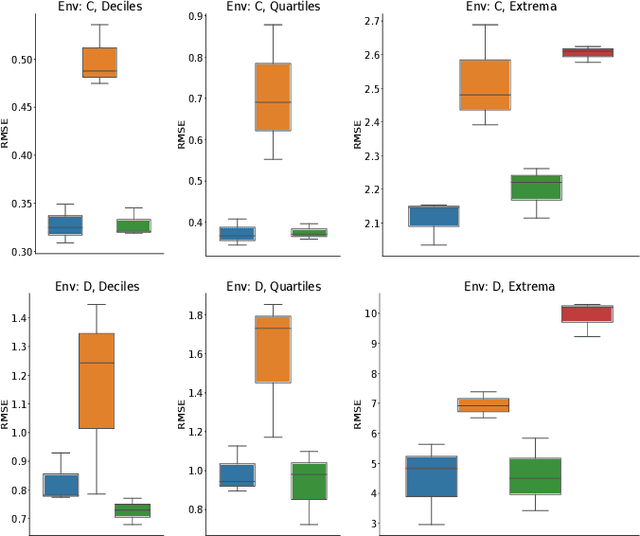
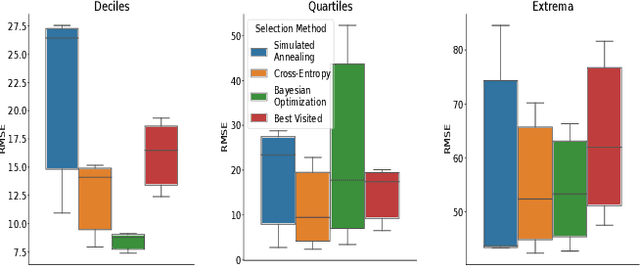
Scientists interested in studying natural phenomena often take physical samples for later analysis at locations specified by expert heuristics. Instead, we propose to guide scientists' physical sampling by using a robot to perform an adaptive sampling survey to find locations to suggest that correspond to the quantile values of pre-specified quantiles of interest. We develop a robot planner using novel objective functions to improve the estimates of the quantile values over time and an approach to find locations which correspond to the quantile values. We demonstrate our approach on two different sampling tasks in simulation using previously collected aquatic data and validate it in a field trial. Our approach outperforms objectives that maximize spatial coverage or find extrema in planning and is able to localize the quantile spatial locations.
Per-Link Parallel and Distributed Hybrid Beamforming for Multi-Cell Massive MIMO Millimeter Wave Full Duplex
Jan 03, 2022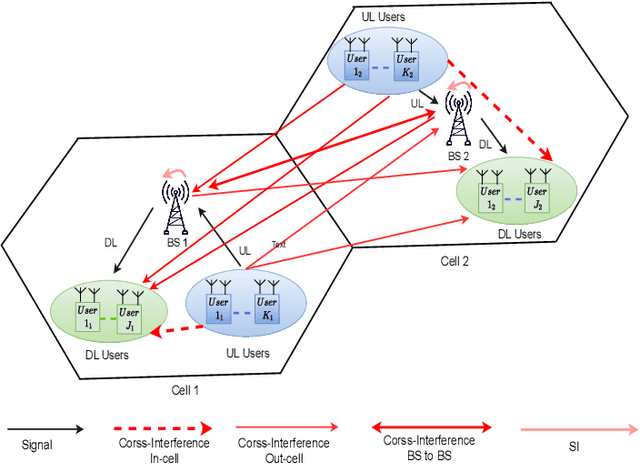
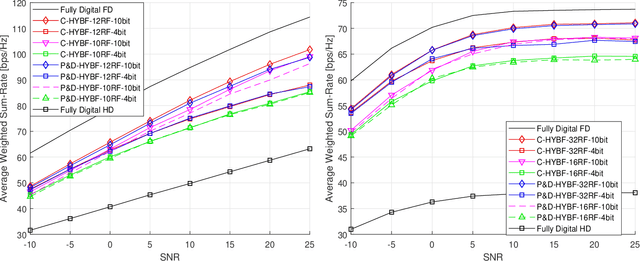
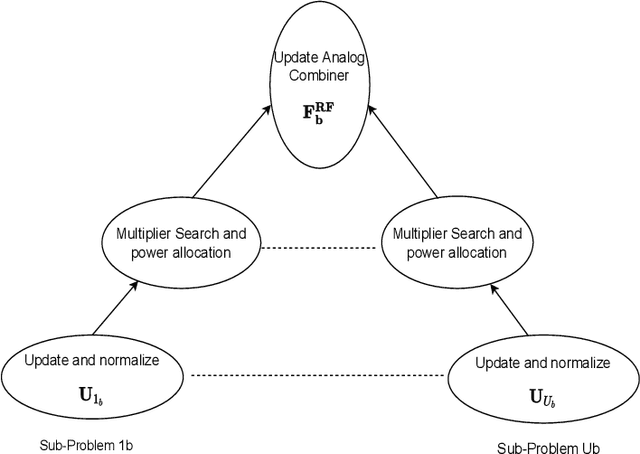
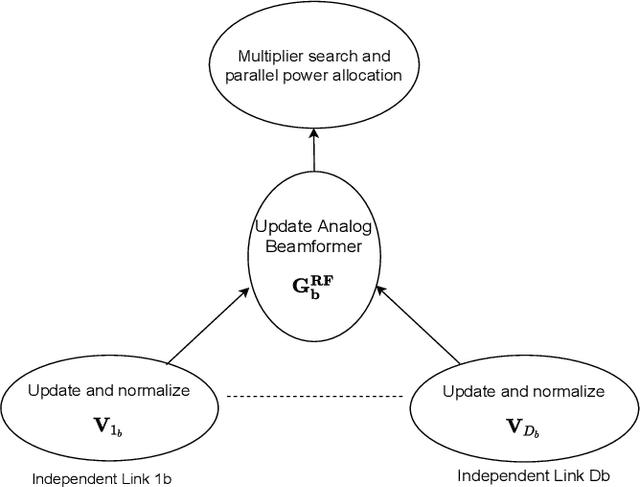
This paper presents two novel hybrid beamforming (HYBF) designs for a multi-cell massive multiple-input-multiple-output (mMIMO) millimeter wave (mmWave) full duplex (FD) system under limited dynamic range (LDR). Firstly, we present a novel centralized HYBF (C-HYBF) scheme based on alternating optimization. In general, the complexity of C-HYBF schemes scales quadratically as a function of the number of users and cells, which may limit their scalability. Moreover, they require significant communication overhead to transfer complete channel state information (CSI) to the central node every channel coherence time for optimization. The central node also requires very high computational power to jointly optimize many variables for the uplink (UL) and downlink (DL) users for FD. To overcome these drawbacks, we propose a very low-complexity and scalable cooperative per-link parallel and distributed (P$\&$D)-HYBF scheme. It allows each mmWave FD base station (BS) to update the beamformers for its users in a distributed fashion and independently in parallel on different computational processors. The complexity of P$\&$D-HYBF scales only linearly as the network size grows, making it desirable for the next generation of large and dense mmWave FD networks. Simulation results show that both designs significantly outperform the fully digital half duplex (HD) system with only a few radio-frequency (RF) chains, achieve similar performance, and the P$\&$D-HYBF design requires considerably less execution time.
Grammar-Based Grounded Lexicon Learning
Feb 17, 2022
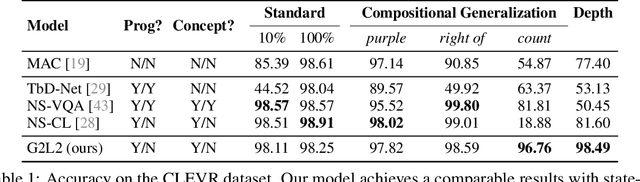
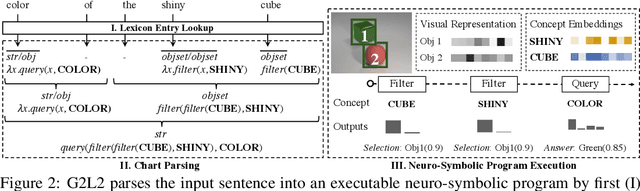
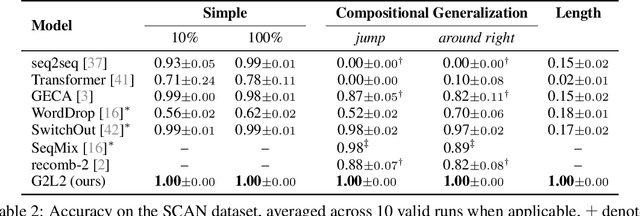
We present Grammar-Based Grounded Lexicon Learning (G2L2), a lexicalist approach toward learning a compositional and grounded meaning representation of language from grounded data, such as paired images and texts. At the core of G2L2 is a collection of lexicon entries, which map each word to a tuple of a syntactic type and a neuro-symbolic semantic program. For example, the word shiny has a syntactic type of adjective; its neuro-symbolic semantic program has the symbolic form {\lambda}x. filter(x, SHINY), where the concept SHINY is associated with a neural network embedding, which will be used to classify shiny objects. Given an input sentence, G2L2 first looks up the lexicon entries associated with each token. It then derives the meaning of the sentence as an executable neuro-symbolic program by composing lexical meanings based on syntax. The recovered meaning programs can be executed on grounded inputs. To facilitate learning in an exponentially-growing compositional space, we introduce a joint parsing and expected execution algorithm, which does local marginalization over derivations to reduce the training time. We evaluate G2L2 on two domains: visual reasoning and language-driven navigation. Results show that G2L2 can generalize from small amounts of data to novel compositions of words.