 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wastewater Pipe Condition Rating Model Using K- Nearest Neighbors
Feb 22, 2022

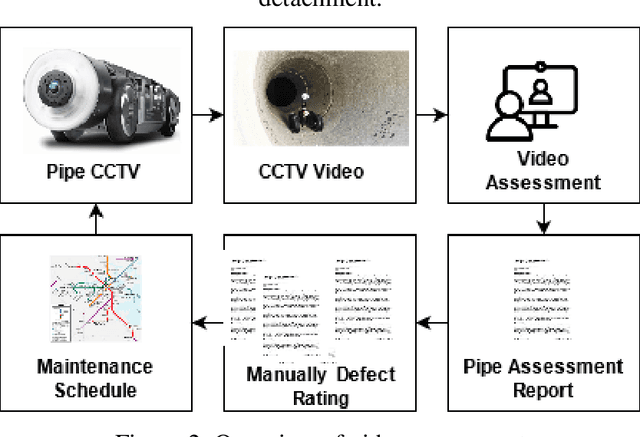
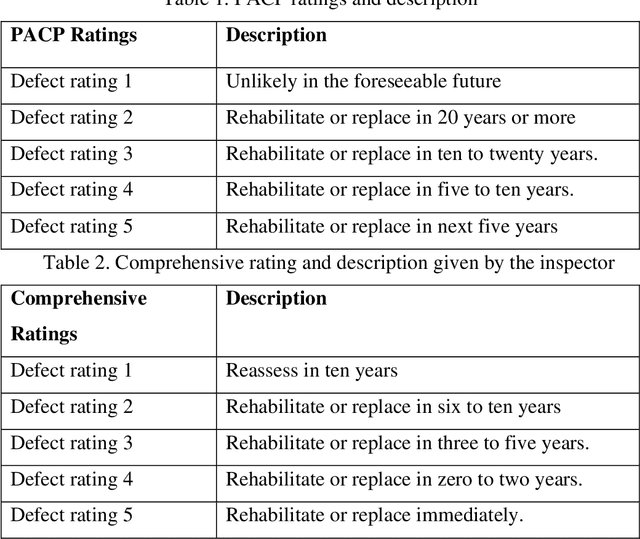
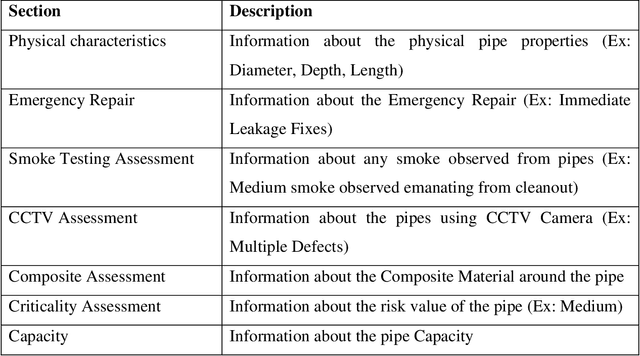
Risk-based assessment in pipe condition mainly focuses on prioritizing the most critical assets by evaluating the risk of pipe failure. This paper's goal is to classify a comprehensive pipe rating model which is obtained based on a series of pipe physical, external, and hydraulic characteristics that are identified for the proposed methodology. The traditional manual method of assessing sewage structural conditions takes a long time. By building an automated process using K-Nearest Neighbors (K-NN), this study presents an effective technique to automate the identification of the pipe defect rating using the pipe repair data. First, we performed the Shapiro Wilks Test for 1240 data from the Dept. of Engineering & Environmental Services, Shreveport, Louisiana Phase 3 with 12 variables to determine if factors could be incorporated in the final rating. We then developed a K-Nearest Neighbors model to classify the final rating from the statistically significant factors identified in Shapiro Wilks Test. This classification process allows recognizing the worst condition of wastewater pipes that need to be replaced immediately. This comprehensive model is built according to the industry-accepted and used guidelines to estimate the overall condition. Finally, for validation purposes, the proposed model is applied to a small portion of a US wastewater collection system in Shreveport, Louisiana. Keywords: Pipe rating, Shapiro Wilks Test, K-Nearest Neighbors (KNN), Failure, Risk analysis
Deep Learning based Multi-User Power Allocation and Hybrid Precoding in Massive MIMO Systems
Jan 29, 2022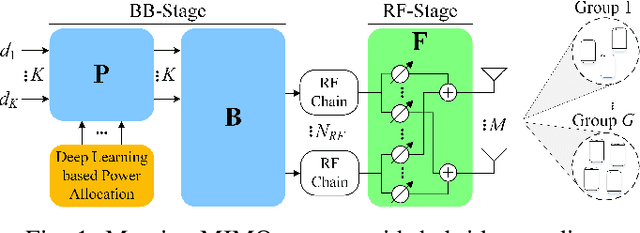
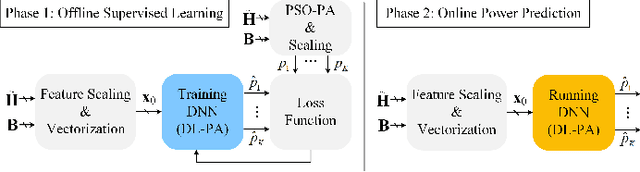
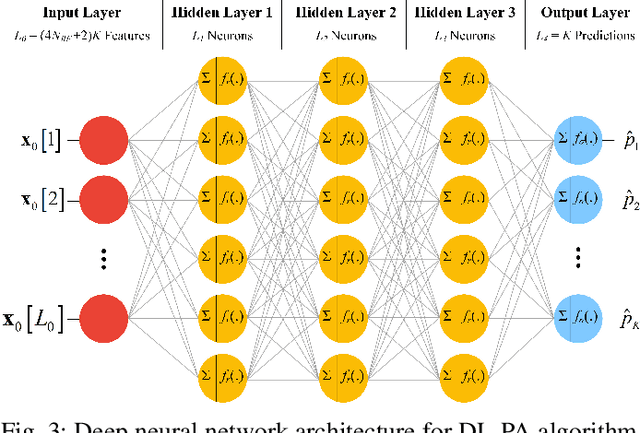
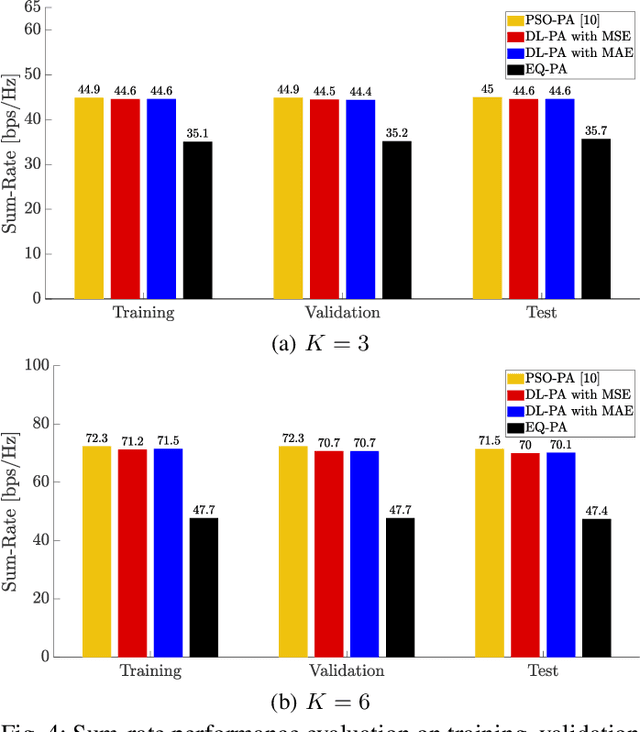
This paper proposes a deep learning based power allocation (DL-PA) and hybrid precoding technique for multiuser massive multiple-input multiple-output (MU-mMIMO) systems. We first utilize an angular-based hybrid precoding technique for reducing the number of RF chains and channel estimation overhead. Then, we develop the DL-PA algorithm via a fully-connected deep neural network (DNN). DL-PA has two phases: (i) offline supervised learning with the optimal allocated powers obtained by particle swarm optimization based PA (PSO-PA) algorithm, (ii) online power prediction by the trained DNN. In comparison to the computationally expensive PSO-PA, it is shown that DL-PA greatly reduces the runtime by 98.6%-99.9%, while closely achieving the optimal sum-rate capacity. It makes DL-PA a promising algorithm for the real-time online applications in MU-mMIMO systems.
Numerical Demonstration of Multiple Actuator Constraint Enforcement Algorithm for a Molten Salt Loop
Feb 04, 2022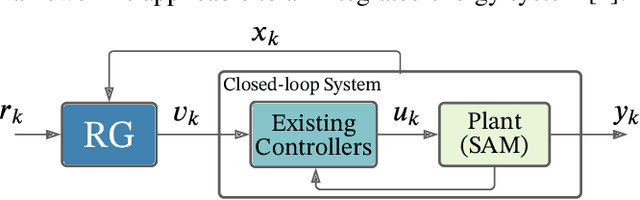
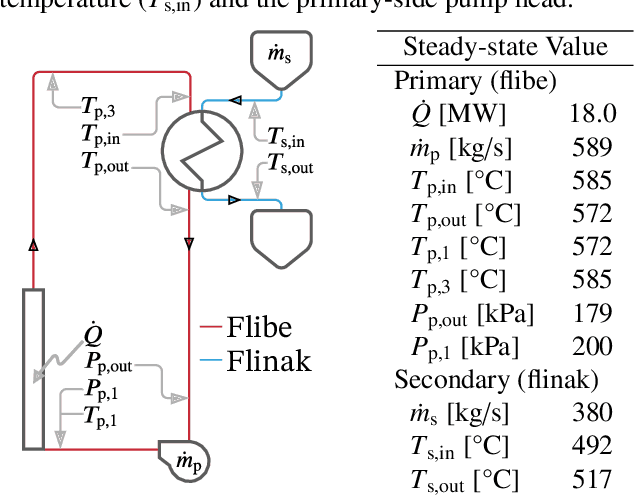
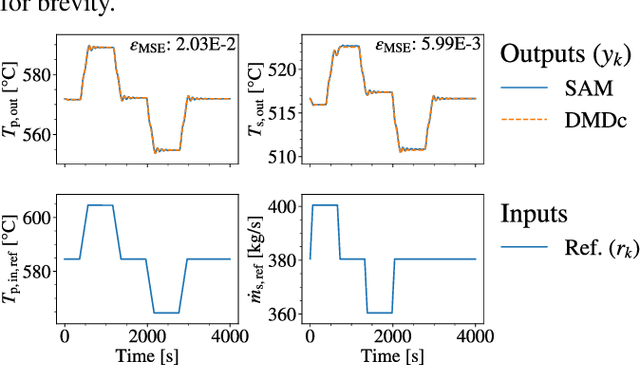
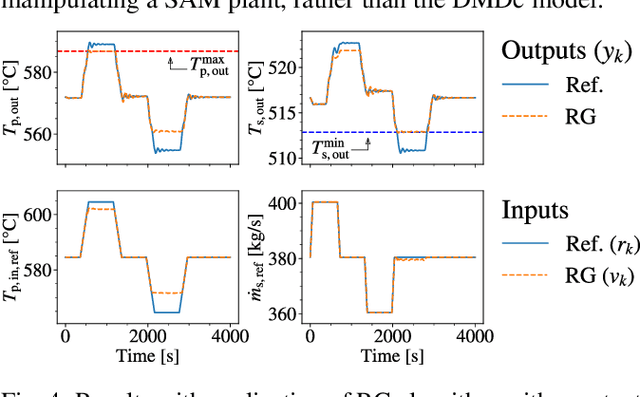
To advance the paradigm of autonomous operation for nuclear power plants, a data-driven machine learning approach to control is sought. Autonomous operation for next-generation reactor designs is anticipated to bolster safety and improve economics. However, any algorithms that are utilized need to be interpretable, adaptable, and robust. In this work, we focus on the specific problem of optimal control during autonomous operation. We will demonstrate an interpretable and adaptable data-driven machine learning approach to autonomous control of a molten salt loop. To address interpretability, we utilize a data-driven algorithm to identify system dynamics in state-space representation. To address adaptability, a control algorithm will be utilized to modify actuator setpoints while enforcing constant, and time-dependent constraints. Robustness is not addressed in this work, and is part of future work. To demonstrate the approach, we designed a numerical experiment requiring intervention to enforce constraints during a load-follow type transient.
Real-Time Facial Expression Emoji Masking with Convolutional Neural Networks and Homography
Dec 24, 2020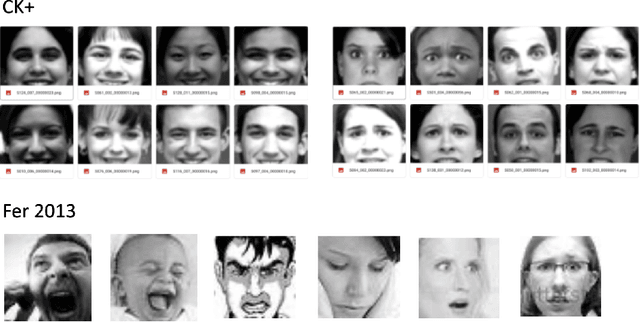



Neural network based algorithms has shown success in many applications. In image processing, Convolutional Neural Networks (CNN) can be trained to categorize facial expressions of images of human faces. In this work, we create a system that masks a student's face with a emoji of the respective emotion. Our system consists of three building blocks: face detection using Histogram of Gradients (HoG) and Support Vector Machine (SVM), facial expression categorization using CNN trained on FER2013 dataset, and finally masking the respective emoji back onto the student's face via homography estimation. (Demo: https://youtu.be/GCjtXw1y8Pw) Our results show that this pipeline is deploy-able in real-time, and is usable in educational settings.
YONO: Modeling Multiple Heterogeneous Neural Networks on Microcontrollers
Mar 08, 2022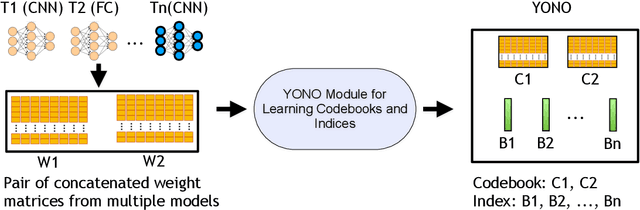
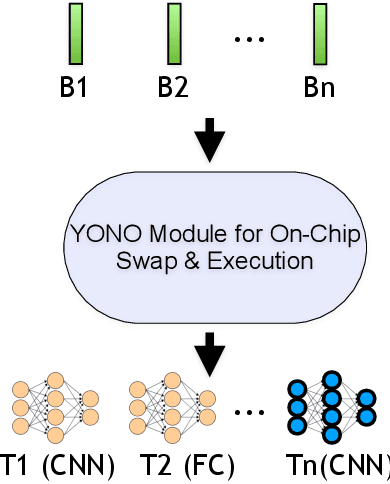

With the advancement of Deep Neural Networks (DNN) and large amounts of sensor data from Internet of Things (IoT) systems, the research community has worked to reduce the computational and resource demands of DNN to compute on low-resourced microcontrollers (MCUs). However, most of the current work in embedded deep learning focuses on solving a single task efficiently, while the multi-tasking nature and applications of IoT devices demand systems that can handle a diverse range of tasks (activity, voice, and context recognition) with input from a variety of sensors, simultaneously. In this paper, we propose YONO, a product quantization (PQ) based approach that compresses multiple heterogeneous models and enables in-memory model execution and switching for dissimilar multi-task learning on MCUs. We first adopt PQ to learn codebooks that store weights of different models. Also, we propose a novel network optimization and heuristics to maximize the compression rate and minimize the accuracy loss. Then, we develop an online component of YONO for efficient model execution and switching between multiple tasks on an MCU at run time without relying on an external storage device. YONO shows remarkable performance as it can compress multiple heterogeneous models with negligible or no loss of accuracy up to 12.37$\times$. Besides, YONO's online component enables an efficient execution (latency of 16-159 ms per operation) and reduces model loading/switching latency and energy consumption by 93.3-94.5% and 93.9-95.0%, respectively, compared to external storage access. Interestingly, YONO can compress various architectures trained with datasets that were not shown during YONO's offline codebook learning phase showing the generalizability of our method. To summarize, YONO shows great potential and opens further doors to enable multi-task learning systems on extremely resource-constrained devices.
Reinforcement Learning based dynamic weighing of Ensemble Models for Time Series Forecasting
Aug 20, 2020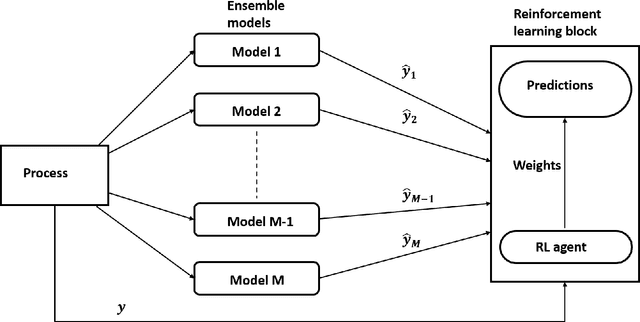
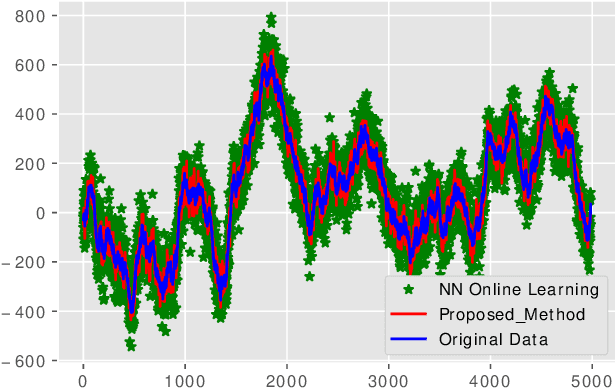
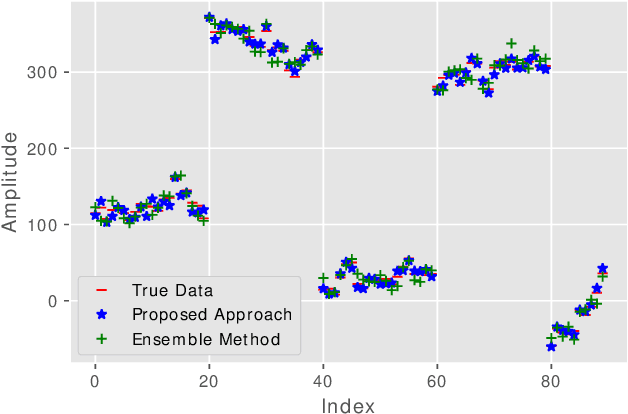
Ensemble models are powerful model building tools that are developed with a focus to improve the accuracy of model predictions. They find applications in time series forecasting in varied scenarios including but not limited to process industries, health care, and economics where a single model might not provide optimal performance. It is known that if models selected for data modelling are distinct (linear/non-linear, static/dynamic) and independent (minimally correlated models), the accuracy of the predictions is improved. Various approaches suggested in the literature to weigh the ensemble models use a static set of weights. Due to this limitation, approaches using a static set of weights for weighing ensemble models cannot capture the dynamic changes or local features of the data effectively. To address this issue, a Reinforcement Learning (RL) approach to dynamically assign and update weights of each of the models at different time instants depending on the nature of data and the individual model predictions is proposed in this work. The RL method implemented online, essentially learns to update the weights and reduce the errors as the time progresses. Simulation studies on time series data showed that the dynamic weighted approach using RL learns the weight better than existing approaches. The accuracy of the proposed method is compared with an existing approach of online Neural Network tuning quantitatively through normalized mean square error(NMSE) values.
BLINC: Lightweight Bimodal Learning for Low-Complexity VVC Intra Coding
Jan 19, 2022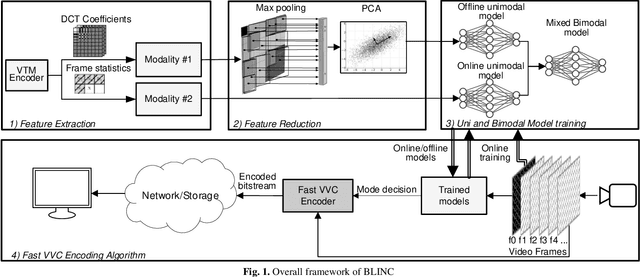

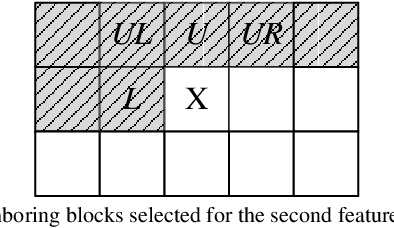
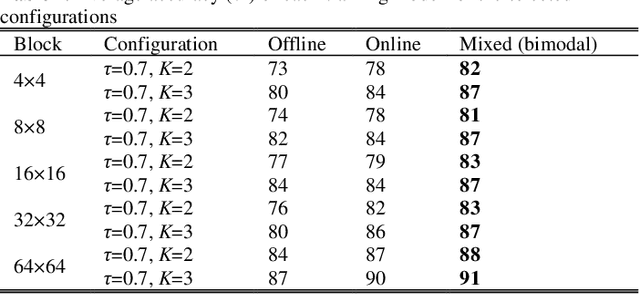
The latest video coding standard, Versatile Video Coding (VVC), achieves almost twice coding efficiency compared to its predecessor, the High Efficiency Video Coding (HEVC). However, achieving this efficiency (for intra coding) requires 31x computational complexity compared to HEVC, making it challenging for low power and real-time applications. This paper, proposes a novel machine learning approach that jointly and separately employs two modalities of features, to simplify the intra coding decision. First a set of features are extracted that use the existing DCT core of VVC, to assess the texture characteristics, and forms the first modality of data. This produces high quality features with almost no overhead. The distribution of intra modes at the neighboring blocks is also used to form the second modality of data, which provides statistical information about the frame. Second, a two-step feature reduction method is designed that reduces the size of feature set, such that a lightweight model with a limited number of parameters can be used to learn the intra mode decision task. Third, three separate training strategies are proposed (1) an offline training strategy using the first (single) modality of data, (2) an online training strategy that uses the second (single) modality, and (3) a mixed online-offline strategy that uses bimodal learning. Finally, a low-complexity encoding algorithms is proposed based on the proposed learning strategies. Extensive experimental results show that the proposed methods can reduce up to 24% of encoding time, with a negligible loss of coding efficiency. Moreover, it is demonstrated how a bimodal learning strategy can boost the performance of learning. Lastly, the proposed method has a very low computational overhead (0.2%), and uses existing components of a VVC encoder, which makes it much more practical compared to competing solutions.
Real-time Non-line-of-Sight imaging of dynamic scenes
Oct 24, 2020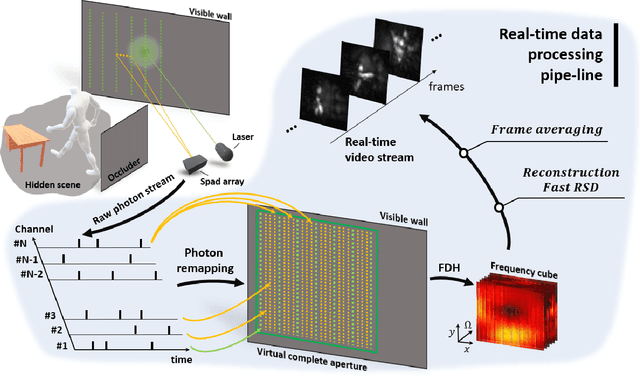
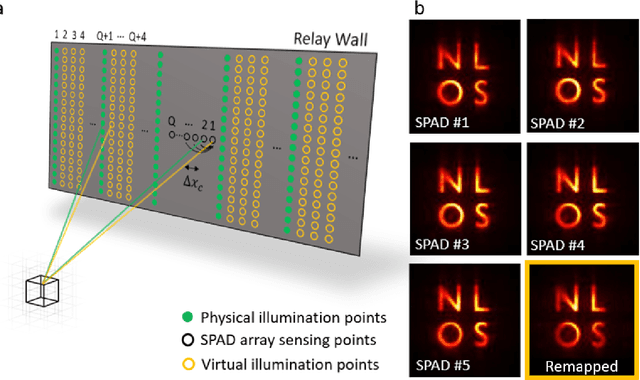
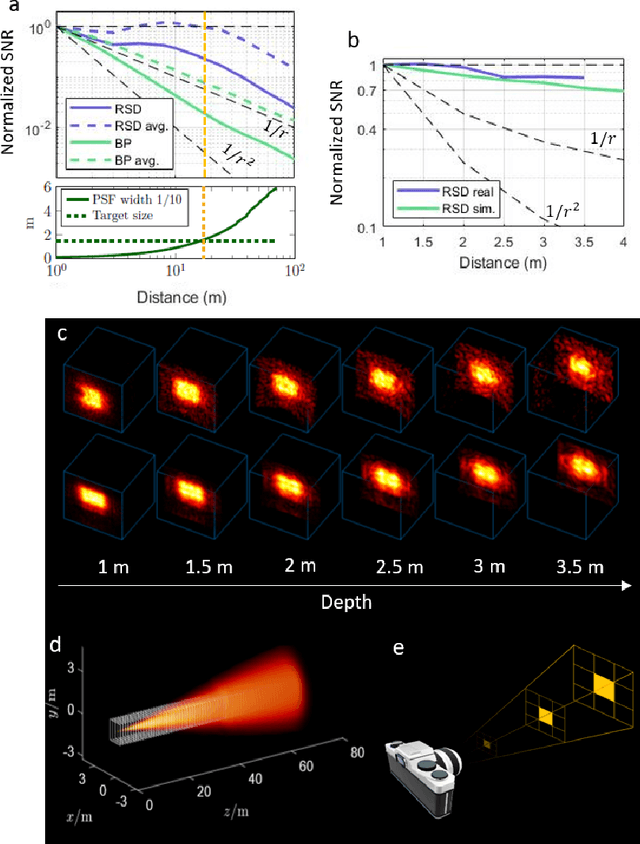

Non-Line-of-Sight (NLOS) imaging aims at recovering the 3D geometry of objects that are hidden from the direct line of sight. In the past, this method has suffered from the weak available multibounce signal limiting scene size, capture speed, and reconstruction quality. While algorithms capable of reconstructing scenes at several frames per second have been demonstrated, real-time NLOS video has only been demonstrated for retro-reflective objects where the NLOS signal strength is enhanced by 4 orders of magnitude or more. Furthermore, it has also been noted that the signal-to-noise ratio of reconstructions in NLOS methods drops quickly with distance and past reconstructions, therefore, have been limited to small scenes with depths of few meters. Actual models of noise and resolution in the scene have been simplistic, ignoring many of the complexities of the problem. We show that SPAD (Single-Photon Avalanche Diode) array detectors with a total of just 28 pixels combined with a specifically extended Phasor Field reconstruction algorithm can reconstruct live real-time videos of non-retro-reflective NLOS scenes. We provide an analysis of the Signal-to-Noise-Ratio (SNR) of our reconstructions and show that for our method it is possible to reconstruct the scene such that SNR, motion blur, angular resolution, and depth resolution are all independent of scene size suggesting that reconstruction of very large scenes may be possible. In the future, the light efficiency for NLOS imaging systems can be improved further by adding more pixels to the sensor array.
Multi-modal unsupervised brain image registration using edge maps
Feb 22, 2022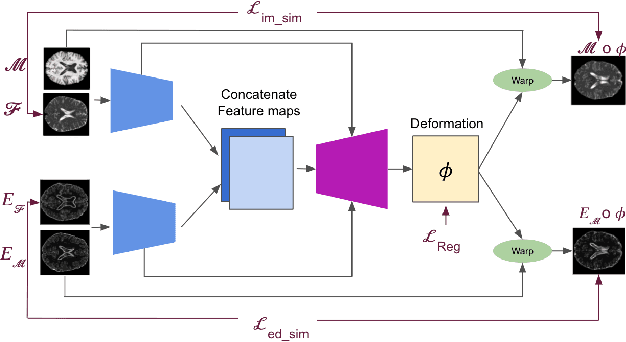
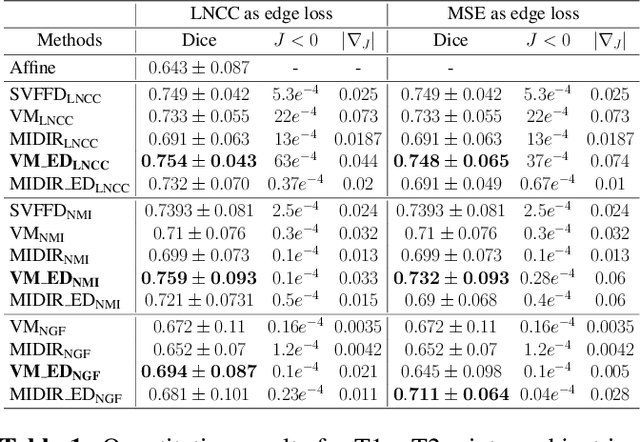


Diffeomorphic deformable multi-modal image registration is a challenging task which aims to bring images acquired by different modalities to the same coordinate space and at the same time to preserve the topology and the invertibility of the transformation. Recent research has focused on leveraging deep learning approaches for this task as these have been shown to achieve competitive registration accuracy while being computationally more efficient than traditional iterative registration methods. In this work, we propose a simple yet effective unsupervised deep learning-based {\em multi-modal} image registration approach that benefits from auxiliary information coming from the gradient magnitude of the image, i.e. the image edges, during the training. The intuition behind this is that image locations with a strong gradient are assumed to denote a transition of tissues, which are locations of high information value able to act as a geometry constraint. The task is similar to using segmentation maps to drive the training, but the edge maps are easier and faster to acquire and do not require annotations. We evaluate our approach in the context of registering multi-modal (T1w to T2w) magnetic resonance (MR) brain images of different subjects using three different loss functions that are said to assist multi-modal registration, showing that in all cases the auxiliary information leads to better results without compromising the runtime.
Optimal reservoir computers for forecasting systems of nonlinear dynamics
Feb 09, 2022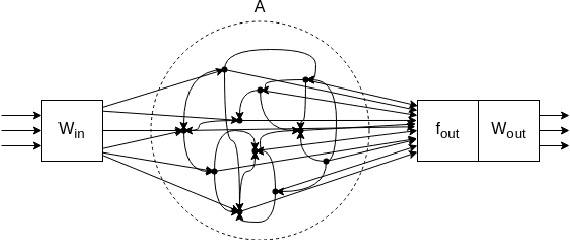
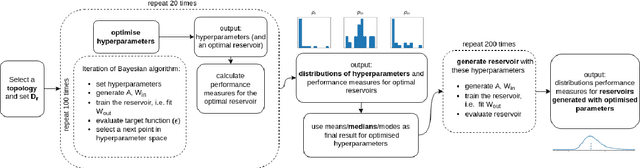
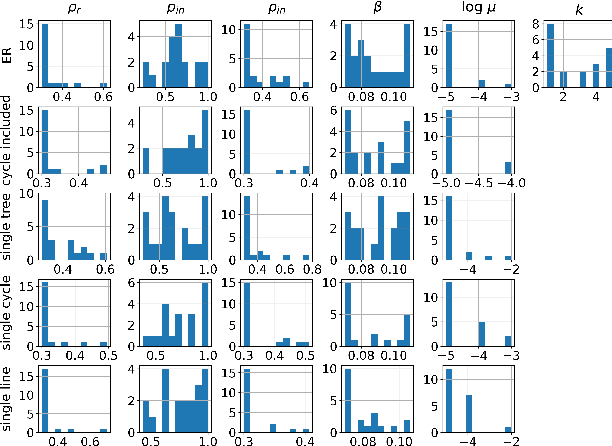
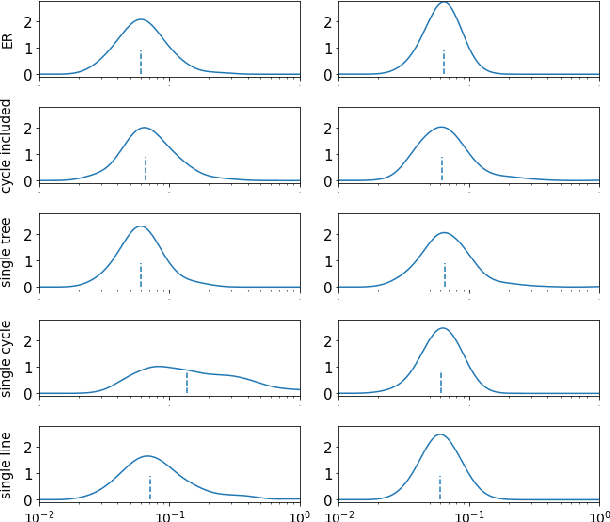
Prediction and analysis of systems of nonlinear dynamics is crucial in many applications. Here, we study characteristics and optimization of reservoir computing, a machine learning technique that has gained attention as a suitable method for this task. By systematically applying Bayesian optimization on reservoirs we show that reservoirs of low connectivity perform better than or as well as those of high connectivity in forecasting noiseless Lorenz and coupled Wilson-Cowan systems. We also show that, unexpectedly, computationally effective reservoirs of unconnected nodes (RUN) outperform reservoirs of linked network topologies in predicting these systems. In the presence of noise, reservoirs of linked nodes perform only slightly better than RUNs. In contrast to previously reported results, we find that the topology of linked reservoirs has no significance in the performance of system prediction. Based on our findings, we give a procedure for designing optimal reservoir computers (RC) for forecasting dynamical systems. This work paves way for computationally effective RCs applicable to real-time prediction of signals measured on systems of nonlinear dynamics such as EEG or MEG signals measured on a brain.