 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time series classification for varying length series
Oct 10, 2019
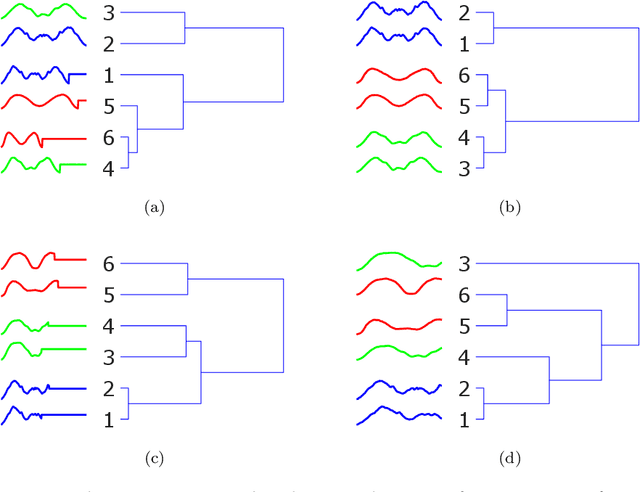
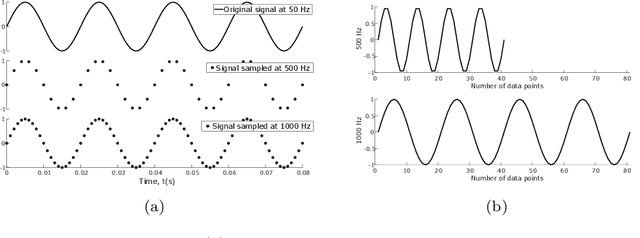
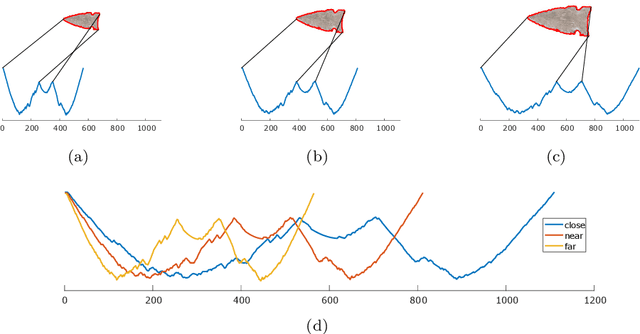
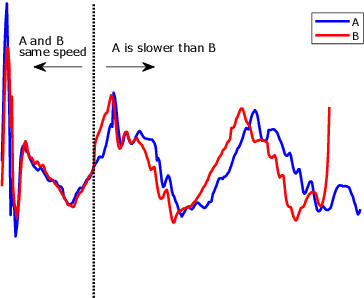
Research into time series classification has tended to focus on the case of series of uniform length. However, it is common for real-world time series data to have unequal lengths. Differing time series lengths may arise from a number of fundamentally different mechanisms. In this work, we identify and evaluate two classes of such mechanisms -- variations in sampling rate relative to the relevant signal and variations between the start and end points of one time series relative to one another. We investigate how time series generated by each of these classes of mechanism are best addressed for time series classification. We perform extensive experiments and provide practical recommendations on how variations in length should be handled in time series classification.
Capacity Bounds under Imperfect Polarization Tracking
Dec 23, 2021
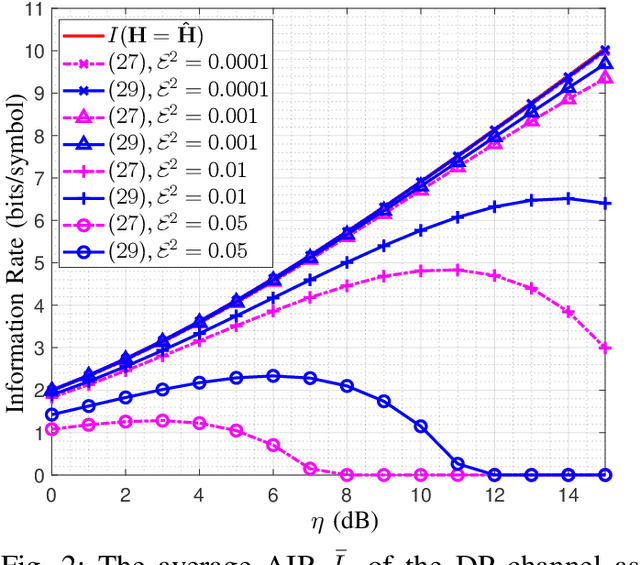
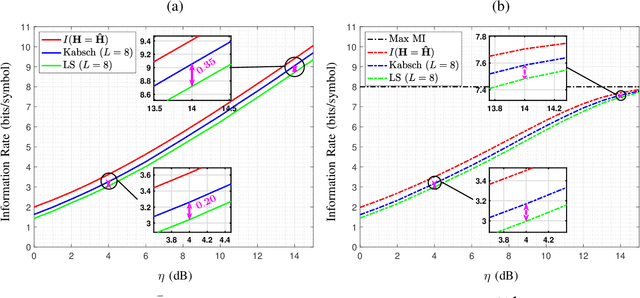
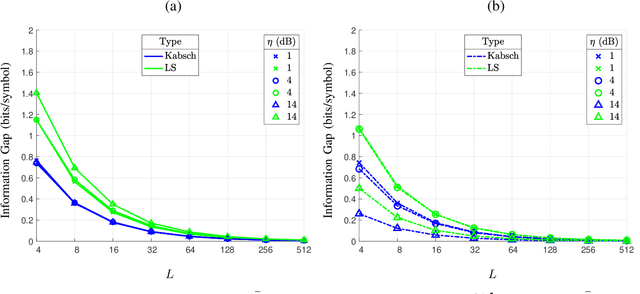
In optical fiber communication, due to the random variation of the environment, the state of polarization (SOP) fluctuates randomly with time leading to distortion and performance degradation. The memory-less SOP fluctuations can be regarded as a two-by-two random unitary matrix. In this paper, for what we believe to be the first time, the capacity of the polarization drift channel under an average power constraint with imperfect channel knowledge is characterized. An achievable information rate (AIR) is derived when imperfect channel knowledge is available and is shown to be highly dependent on the channel estimation technique. It is also shown that a tighter lower bound can be achieved when a unitary estimation of the channel is available. However, the conventional estimation algorithms do not guarantee a unitary channel estimation. Therefore, by considering the unitary constraint of the channel, a data-aided channel estimator based on the Kabsch algorithm is proposed, and its performance is numerically evaluated in terms of AIR. Monte Carlo simulations show that Kabsch outperforms the least-square error algorithm. In particular, with complex, Gaussian inputs and eight pilot symbols per block, Kabsch improves the AIR by 0:2 to 0:35 bits/symbol throughout the range of studied signal-to-noise ratios.
DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
Jan 28, 2022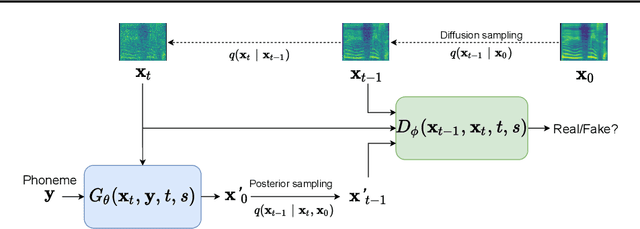
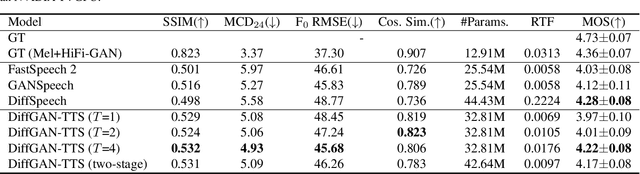
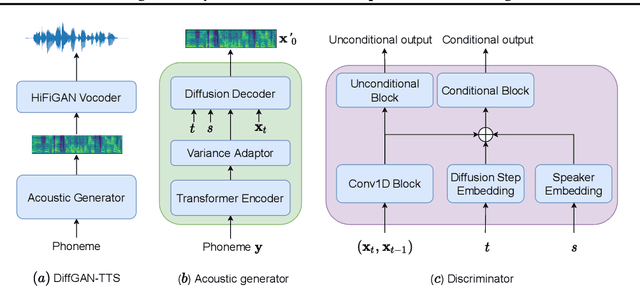
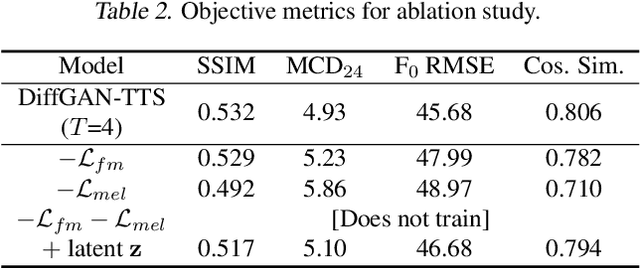
Denoising diffusion probabilistic models (DDPMs) are expressive generative models that have been used to solve a variety of speech synthesis problems. However, because of their high sampling costs, DDPMs are difficult to use in real-time speech processing applications. In this paper, we introduce DiffGAN-TTS, a novel DDPM-based text-to-speech (TTS) model achieving high-fidelity and efficient speech synthesis. DiffGAN-TTS is based on denoising diffusion generative adversarial networks (GANs), which adopt an adversarially-trained expressive model to approximate the denoising distribution. We show with multi-speaker TTS experiments that DiffGAN-TTS can generate high-fidelity speech samples within only 4 denoising steps. We present an active shallow diffusion mechanism to further speed up inference. A two-stage training scheme is proposed, with a basic TTS acoustic model trained at stage one providing valuable prior information for a DDPM trained at stage two. Our experiments show that DiffGAN-TTS can achieve high synthesis performance with only 1 denoising step.
Training invariances and the low-rank phenomenon: beyond linear networks
Jan 28, 2022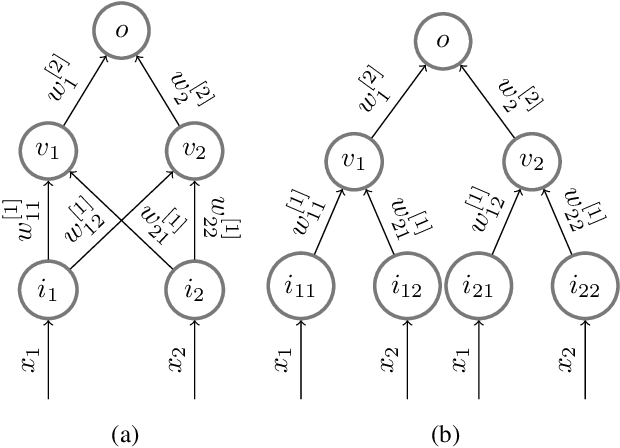
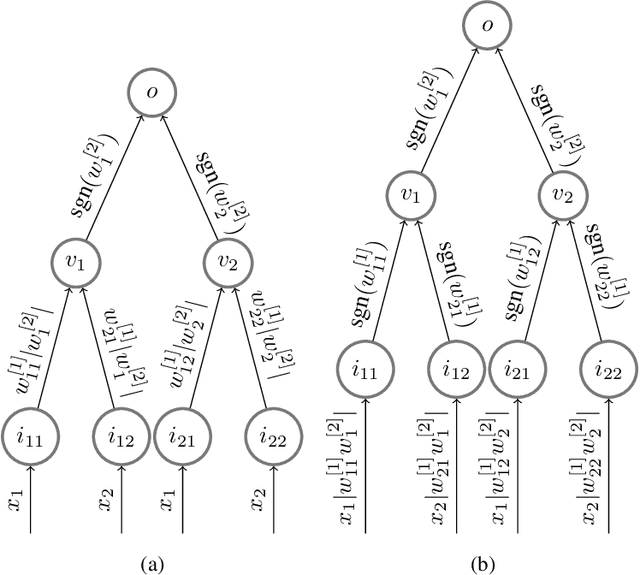
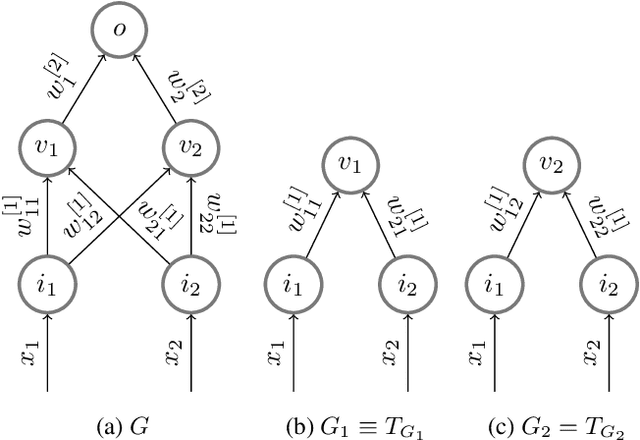
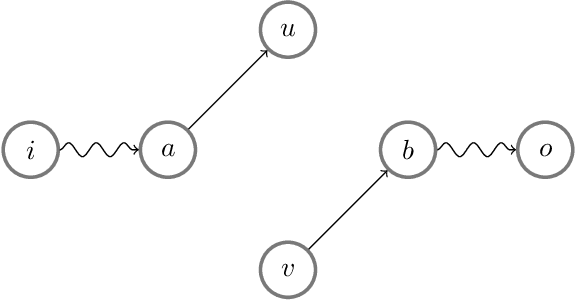
The implicit bias induced by the training of neural networks has become a topic of rigorous study. In the limit of gradient flow and gradient descent with appropriate step size, it has been shown that when one trains a deep linear network with logistic or exponential loss on linearly separable data, the weights converge to rank-$1$ matrices. In this paper, we extend this theoretical result to the much wider class of nonlinear ReLU-activated feedforward networks containing fully-connected layers and skip connections. To the best of our knowledge, this is the first time a low-rank phenomenon is proven rigorously for these architectures, and it reflects empirical results in the literature. The proof relies on specific local training invariances, sometimes referred to as alignment, which we show to hold for a wide set of ReLU architectures. Our proof relies on a specific decomposition of the network into a multilinear function and another ReLU network whose weights are constant under a certain parameter directional convergence.
Deep Q-Learning Market Makers in a Multi-Agent Simulated Stock Market
Dec 08, 2021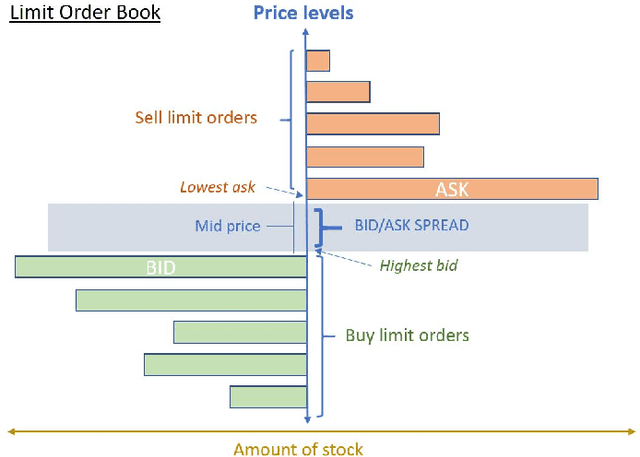
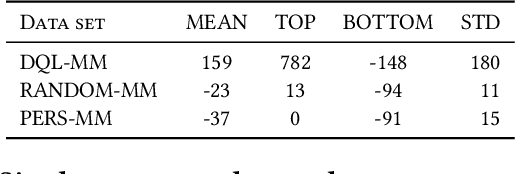
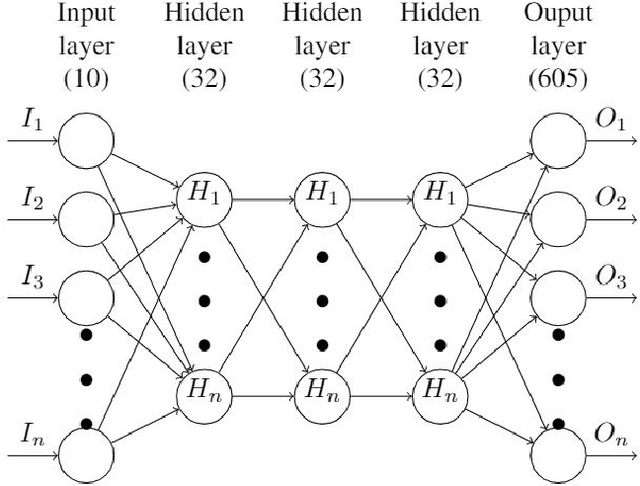
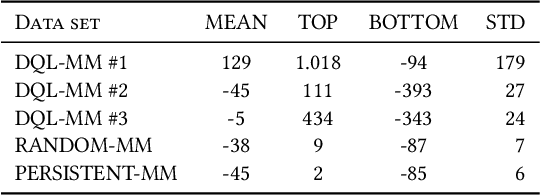
Market makers play a key role in financial markets by providing liquidity. They usually fill order books with buy and sell limit orders in order to provide traders alternative price levels to operate. This paper focuses precisely on the study of these markets makers strategies from an agent-based perspective. In particular, we propose the application of Reinforcement Learning (RL) for the creation of intelligent market markers in simulated stock markets. This research analyzes how RL market maker agents behaves in non-competitive (only one RL market maker learning at the same time) and competitive scenarios (multiple RL market markers learning at the same time), and how they adapt their strategies in a Sim2Real scope with interesting results. Furthermore, it covers the application of policy transfer between different experiments, describing the impact of competing environments on RL agents performance. RL and deep RL techniques are proven as profitable market maker approaches, leading to a better understanding of their behavior in stock markets.
AlertTrap: A study on object detection in remote insects trap monitoring system using on-the-edge deep learning platform
Dec 26, 2021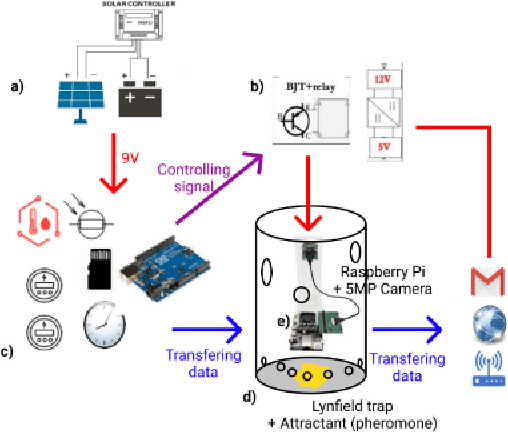
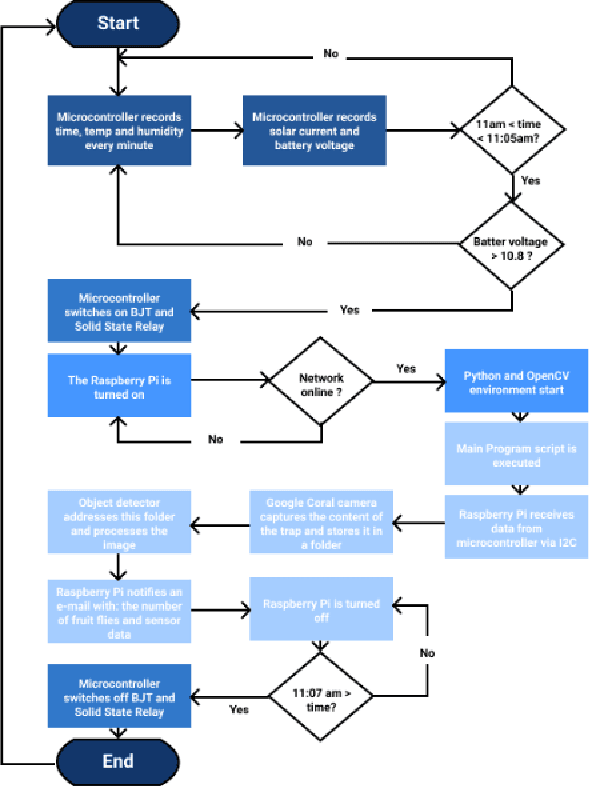


Fruit flies are one of the most harmful insect species to fruit yields. In AlertTrap, implementation of SSD architecture with different state-of-the-art backbone feature extractors such as MobileNetV1 and MobileNetV2 appear to be potential solutions for the real-time detection problem. SSD-MobileNetV1 and SSD-MobileNetV2 perform well and result in AP@0.5 of 0.957 and 1.0 respectively. YOLOv4-tiny outperforms the SSD family with 1.0 in AP@0.5; however, its throughput velocity is slightly slower.
Online Learning in Periodic Zero-Sum Games
Nov 05, 2021
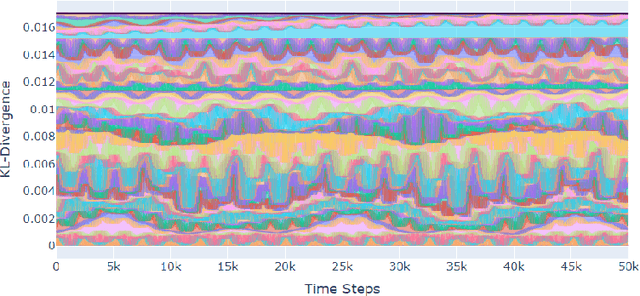

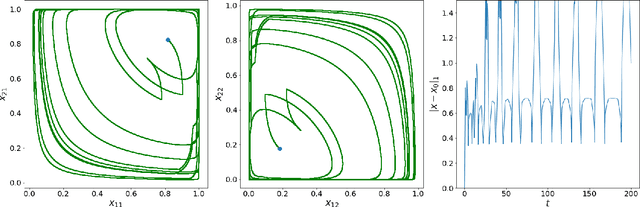
A seminal result in game theory is von Neumann's minmax theorem, which states that zero-sum games admit an essentially unique equilibrium solution. Classical learning results build on this theorem to show that online no-regret dynamics converge to an equilibrium in a time-average sense in zero-sum games. In the past several years, a key research direction has focused on characterizing the day-to-day behavior of such dynamics. General results in this direction show that broad classes of online learning dynamics are cyclic, and formally Poincar\'{e} recurrent, in zero-sum games. We analyze the robustness of these online learning behaviors in the case of periodic zero-sum games with a time-invariant equilibrium. This model generalizes the usual repeated game formulation while also being a realistic and natural model of a repeated competition between players that depends on exogenous environmental variations such as time-of-day effects, week-to-week trends, and seasonality. Interestingly, time-average convergence may fail even in the simplest such settings, in spite of the equilibrium being fixed. In contrast, using novel analysis methods, we show that Poincar\'{e} recurrence provably generalizes despite the complex, non-autonomous nature of these dynamical systems.
Conditional Imitation Learning for Multi-Agent Games
Jan 05, 2022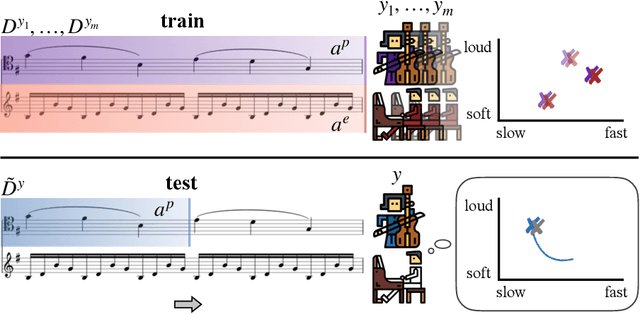
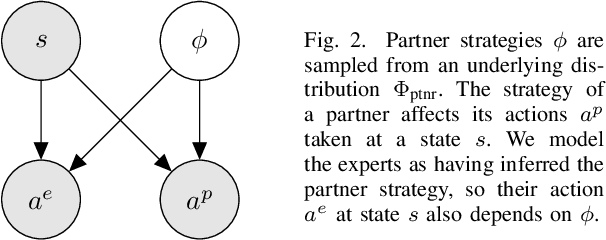
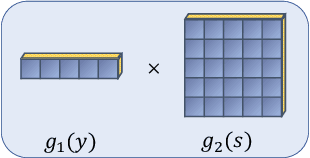
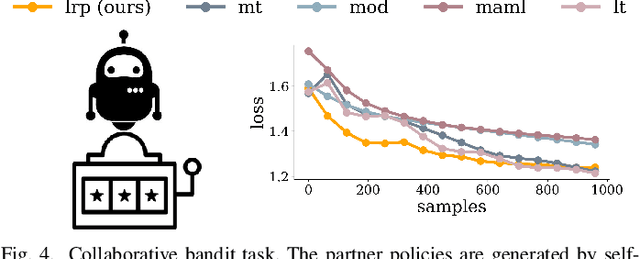
While advances in multi-agent learning have enabled the training of increasingly complex agents, most existing techniques produce a final policy that is not designed to adapt to a new partner's strategy. However, we would like our AI agents to adjust their strategy based on the strategies of those around them. In this work, we study the problem of conditional multi-agent imitation learning, where we have access to joint trajectory demonstrations at training time, and we must interact with and adapt to new partners at test time. This setting is challenging because we must infer a new partner's strategy and adapt our policy to that strategy, all without knowledge of the environment reward or dynamics. We formalize this problem of conditional multi-agent imitation learning, and propose a novel approach to address the difficulties of scalability and data scarcity. Our key insight is that variations across partners in multi-agent games are often highly structured, and can be represented via a low-rank subspace. Leveraging tools from tensor decomposition, our model learns a low-rank subspace over ego and partner agent strategies, then infers and adapts to a new partner strategy by interpolating in the subspace. We experiments with a mix of collaborative tasks, including bandits, particle, and Hanabi environments. Additionally, we test our conditional policies against real human partners in a user study on the Overcooked game. Our model adapts better to new partners compared to baselines, and robustly handles diverse settings ranging from discrete/continuous actions and static/online evaluation with AI/human partners.
Learning Proximal Operators to Discover Multiple Optima
Jan 28, 2022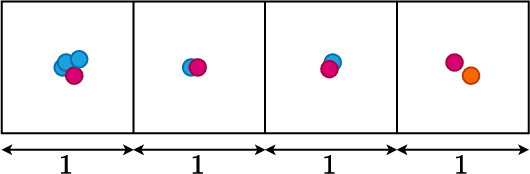
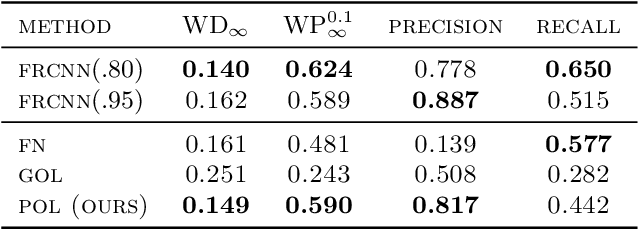

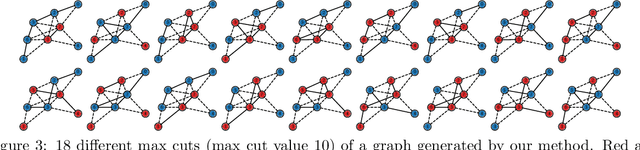
Finding multiple solutions of non-convex optimization problems is a ubiquitous yet challenging task. Typical existing solutions either apply single-solution optimization methods from multiple random initial guesses or search in the vicinity of found solutions using ad hoc heuristics. We present an end-to-end method to learn the proximal operator across a family of non-convex problems, which can then be used to recover multiple solutions for unseen problems at test time. Our method only requires access to the objectives without needing the supervision of ground truth solutions. Notably, the added proximal regularization term elevates the convexity of our formulation: by applying recent theoretical results, we show that for weakly-convex objectives and under mild regularity conditions, training of the proximal operator converges globally in the over-parameterized setting. We further present a benchmark for multi-solution optimization including a wide range of applications and evaluate our method to demonstrate its effectiveness.
Recursive Two-Step Lookahead Expected Payoff for Time-Dependent Bayesian Optimization
Jun 14, 2020

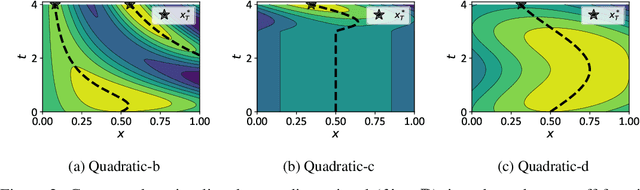

We propose a novel Bayesian method to solve the maximization of a time-dependent expensive-to-evaluate oracle. We are interested in the decision that maximizes the oracle at a finite time horizon, when relatively few noisy evaluations can be performed before the horizon. Our recursive, two-step lookahead expected payoff ($\texttt{r2LEY}$) acquisition function makes nonmyopic decisions at every stage by maximizing the estimated expected value of the oracle at the horizon. $\texttt{r2LEY}$ circumvents the evaluation of the expensive multistep (more than two steps) lookahead acquisition function by recursively optimizing a two-step lookahead acquisition function at every stage; unbiased estimators of this latter function and its gradient are utilized for efficient optimization. $\texttt{r2LEY}$ is shown to exhibit natural exploration properties far from the time horizon, enabling accurate emulation of the oracle, which is exploited in the final decision made at the horizon. To demonstrate the utility of $\texttt{r2LEY}$, we compare it with time-dependent extensions of popular myopic acquisition functions via both synthetic and real-world datasets.