 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
To Talk or to Work: Delay Efficient Federated Learning over Mobile Edge Devices
Nov 01, 2021

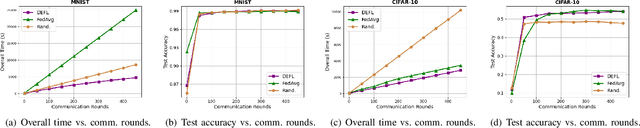
Federated learning (FL), an emerging distributed machine learning paradigm, in conflux with edge computing is a promising area with novel applications over mobile edge devices. In FL, since mobile devices collaborate to train a model based on their own data under the coordination of a central server by sharing just the model updates, training data is maintained private. However, without the central availability of data, computing nodes need to communicate the model updates often to attain convergence. Hence, the local computation time to create local model updates along with the time taken for transmitting them to and from the server result in a delay in the overall time. Furthermore, unreliable network connections may obstruct an efficient communication of these updates. To address these, in this paper, we propose a delay-efficient FL mechanism that reduces the overall time (consisting of both the computation and communication latencies) and communication rounds required for the model to converge. Exploring the impact of various parameters contributing to delay, we seek to balance the trade-off between wireless communication (to talk) and local computation (to work). We formulate a relation with overall time as an optimization problem and demonstrate the efficacy of our approach through extensive simulations.
Parameter estimation for WMTI-Watson model of white matter using encoder-decoder recurrent neural network
Mar 02, 2022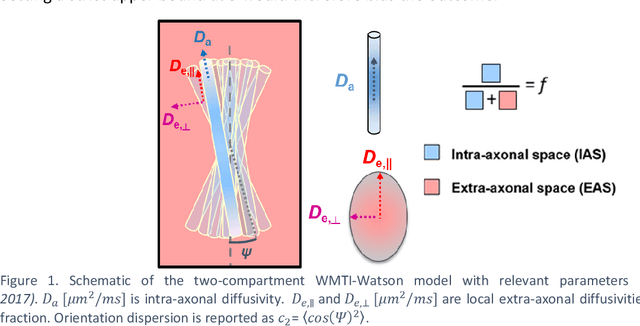

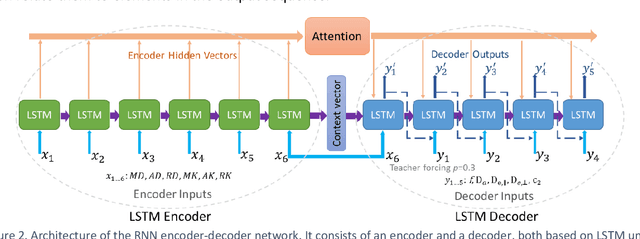
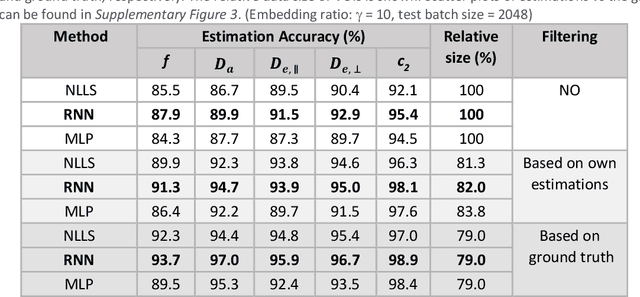
Biophysical modelling of the diffusion MRI signal provides estimates of specific microstructural tissue properties. Although nonlinear optimization such as non-linear least squares (NLLS) is the most widespread method for model estimation, it suffers from local minima and high computational cost. Deep Learning approaches are steadily replacing NL fitting, but come with the limitation that the model needs to be retrained for each acquisition protocol and noise level. The White Matter Tract Integrity (WMTI)-Watson model was proposed as an implementation of the Standard Model of diffusion in white matter that estimates model parameters from the diffusion and kurtosis tensors (DKI). Here we proposed a deep learning approach based on the encoder-decoder recurrent neural network (RNN) to increase the robustness and accelerate the parameter estimation of WMTI-Watson. We use an embedding approach to render the model insensitive to potential differences in distributions between training data and experimental data. This RNN-based solver thus has the advantage of being highly efficient in computation and more readily translatable to other datasets, irrespective of acquisition protocol and underlying parameter distributions as long as DKI was pre-computed from the data. In this study, we evaluated the performance of NLLS, the RNN-based method and a multilayer perceptron (MLP) on synthetic and in vivo datasets of rat and human brain. We showed that the proposed RNN-based fitting approach had the advantage of highly reduced computation time over NLLS (from hours to seconds), with similar accuracy and precision but improved robustness, and superior translatability to new datasets over MLP.
Benchmarking Online Sequence-to-Sequence and Character-based Handwriting Recognition from IMU-Enhanced Pens
Feb 14, 2022Handwriting is one of the most frequently occurring patterns in everyday life and with it come challenging applications such as handwriting recognition (HWR), writer identification, and signature verification. In contrast to offline HWR that only uses spatial information (i.e., images), online HWR (OnHWR) uses richer spatio-temporal information (i.e., trajectory data or inertial data). While there exist many offline HWR datasets, there is only little data available for the development of OnHWR methods as it requires hardware-integrated pens. This paper presents data and benchmark models for real-time sequence-to-sequence (seq2seq) learning and single character-based recognition. Our data is recorded by a sensor-enhanced ballpoint pen, yielding sensor data streams from triaxial accelerometers, a gyroscope, a magnetometer and a force sensor at 100Hz. We propose a variety of datasets including equations and words for both the writer-dependent and writer-independent tasks. We provide an evaluation benchmark for seq2seq and single character-based HWR using recurrent and temporal convolutional networks and Transformers combined with a connectionist temporal classification (CTC) loss and cross entropy losses. Our methods do not resort to language or lexicon models.
SEED: Sound Event Early Detection via Evidential Uncertainty
Feb 05, 2022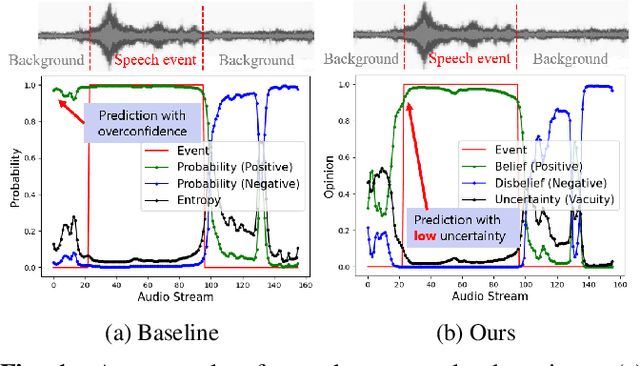

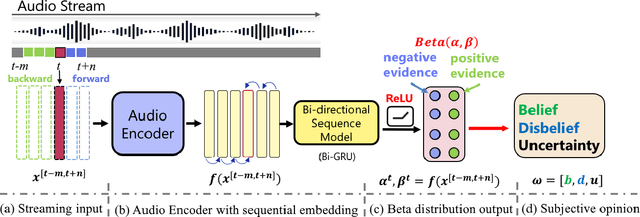
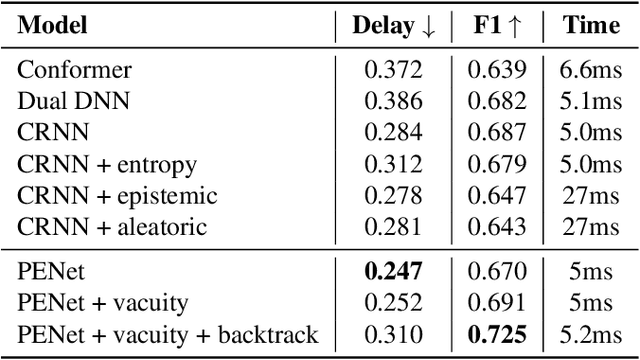
Sound Event Early Detection (SEED) is an essential task in recognizing the acoustic environments and soundscapes. However, most of the existing methods focus on the offline sound event detection, which suffers from the over-confidence issue of early-stage event detection and usually yield unreliable results. To solve the problem, we propose a novel Polyphonic Evidential Neural Network (PENet) to model the evidential uncertainty of the class probability with Beta distribution. Specifically, we use a Beta distribution to model the distribution of class probabilities, and the evidential uncertainty enriches uncertainty representation with evidence information, which plays a central role in reliable prediction. To further improve the event detection performance, we design the backtrack inference method that utilizes both the forward and backward audio features of an ongoing event. Experiments on the DESED database show that the proposed method can simultaneously improve 13.0\% and 3.8\% in time delay and detection F1 score compared to the state-of-the-art methods.
Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress
Oct 08, 2020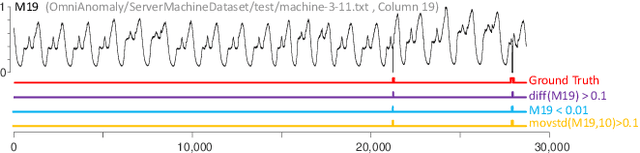
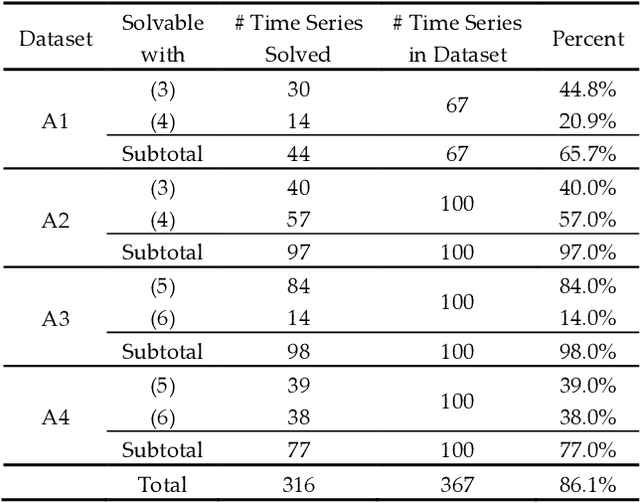
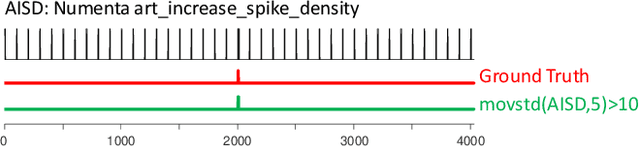
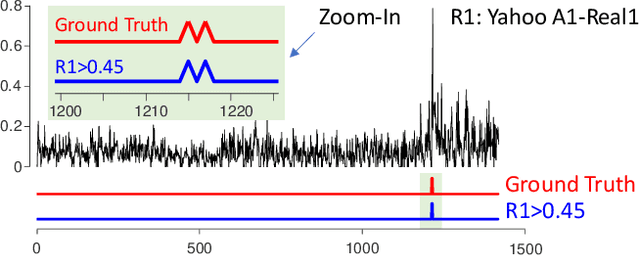
Time series anomaly detection has been a perennially important topic in data science, with papers dating back to the 1950s. However, in recent years there has been an explosion of interest in this topic, much of it driven by the success of deep learning in other domains and for other time series tasks. Most of these papers test on one or more of a handful of popular benchmark datasets, created by Yahoo, Numenta, NASA, etc. In this work we make a surprising claim. The majority of the individual exemplars in these datasets suffer from one or more of four flaws. Because of these four flaws, we believe that many published comparisons of anomaly detection algorithms may be unreliable, and more importantly, much of the apparent progress in recent years may be illusionary. In addition to demonstrating these claims, with this paper we introduce the UCR Time Series Anomaly Datasets. We believe that this resource will perform a similar role as the UCR Time Series Classification Archive, by providing the community with a benchmark that allows meaningful comparisons between approaches and a meaningful gauge of overall progress.
Recurrent Neural Networks for Dynamical Systems: Applications to Ordinary Differential Equations, Collective Motion, and Hydrological Modeling
Feb 14, 2022

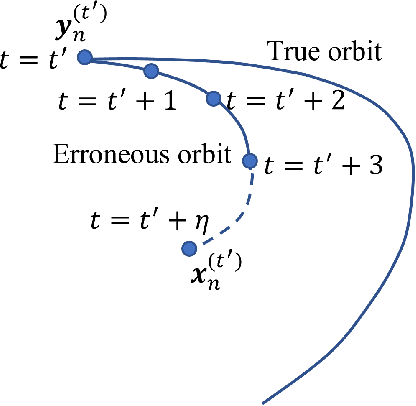

Classical methods of solving spatiotemporal dynamical systems include statistical approaches such as autoregressive integrated moving average, which assume linear and stationary relationships between systems' previous outputs. Development and implementation of linear methods are relatively simple, but they often do not capture non-linear relationships in the data. Thus, artificial neural networks (ANNs) are receiving attention from researchers in analyzing and forecasting dynamical systems. Recurrent neural networks (RNN), derived from feed-forward ANNs, use internal memory to process variable-length sequences of inputs. This allows RNNs to applicable for finding solutions for a vast variety of problems in spatiotemporal dynamical systems. Thus, in this paper, we utilize RNNs to treat some specific issues associated with dynamical systems. Specifically, we analyze the performance of RNNs applied to three tasks: reconstruction of correct Lorenz solutions for a system with a formulation error, reconstruction of corrupted collective motion trajectories, and forecasting of streamflow time series possessing spikes, representing three fields, namely, ordinary differential equations, collective motion, and hydrological modeling, respectively. We train and test RNNs uniquely in each task to demonstrate the broad applicability of RNNs in reconstruction and forecasting the dynamics of dynamical systems.
A Strong Baseline for Weekly Time Series Forecasting
Oct 16, 2020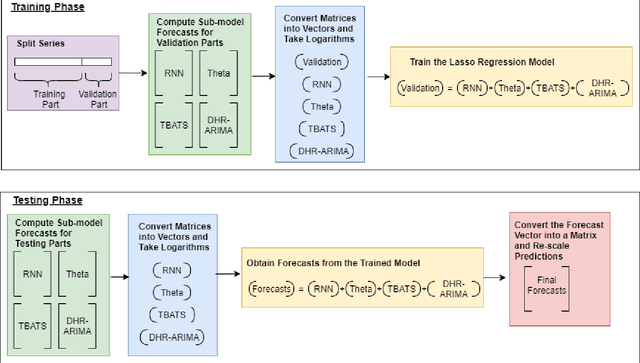

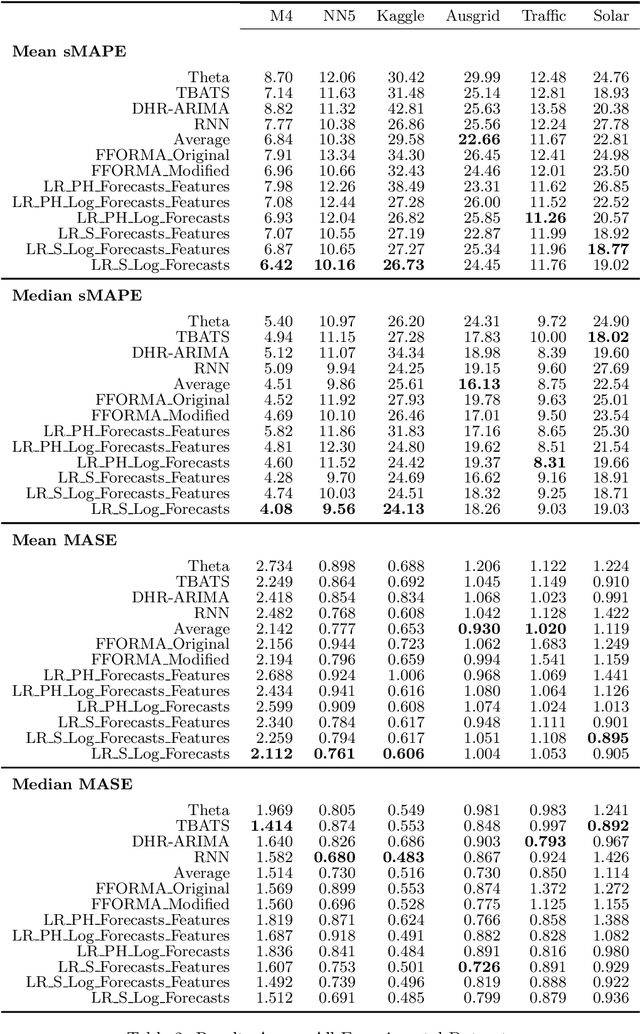
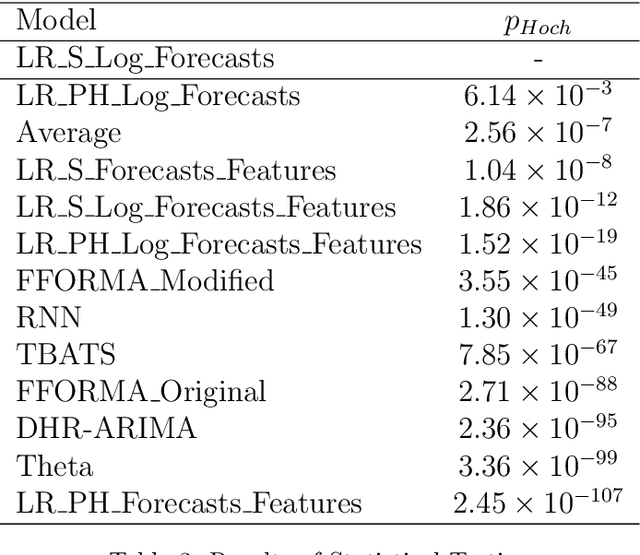
Many businesses and industries require accurate forecasts for weekly time series nowadays. The forecasting literature however does not currently provide easy-to-use, automatic, reproducible and accurate approaches dedicated to this task. We propose a forecasting method that can be used as a strong baseline in this domain, leveraging state-of-the-art forecasting techniques, forecast combination, and global modelling. Our approach uses four base forecasting models specifically suitable for forecasting weekly data: a global Recurrent Neural Network model, Theta, Trigonometric Box-Cox ARMA Trend Seasonal (TBATS), and Dynamic Harmonic Regression ARIMA (DHR-ARIMA). Those are then optimally combined using a lasso regression stacking approach. We evaluate the performance of our method against a set of state-of-the-art weekly forecasting models on six datasets. Across four evaluation metrics, we show that our method consistently outperforms the benchmark methods by a considerable margin with statistical significance. In particular, our model can produce the most accurate forecasts, in terms of mean sMAPE, for the M4 weekly dataset.
Augmenting Neural Networks with Priors on Function Values
Feb 10, 2022



The need for function estimation in label-limited settings is common in the natural sciences. At the same time, prior knowledge of function values is often available in these domains. For example, data-free biophysics-based models can be informative on protein properties, while quantum-based computations can be informative on small molecule properties. How can we coherently leverage such prior knowledge to help improve a neural network model that is quite accurate in some regions of input space -- typically near the training data -- but wildly wrong in other regions? Bayesian neural networks (BNN) enable the user to specify prior information only on the neural network weights, not directly on the function values. Moreover, there is in general no clear mapping between these. Herein, we tackle this problem by developing an approach to augment BNNs with prior information on the function values themselves. Our probabilistic approach yields predictions that rely more heavily on the prior information when the epistemic uncertainty is large, and more heavily on the neural network when the epistemic uncertainty is small.
Machine Learning in Heterogeneous Porous Materials
Feb 04, 2022

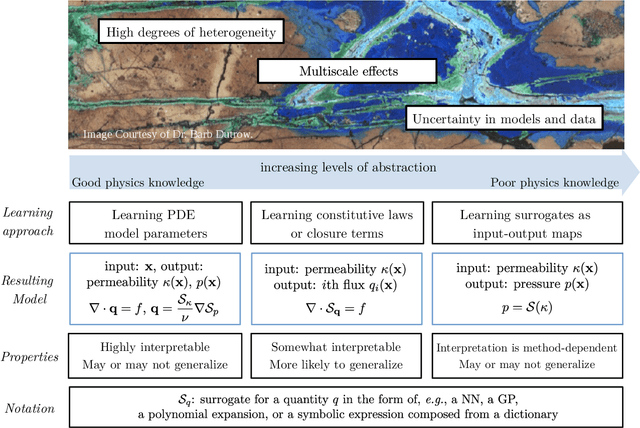
The "Workshop on Machine learning in heterogeneous porous materials" brought together international scientific communities of applied mathematics, porous media, and material sciences with experts in the areas of heterogeneous materials, machine learning (ML) and applied mathematics to identify how ML can advance materials research. Within the scope of ML and materials research, the goal of the workshop was to discuss the state-of-the-art in each community, promote crosstalk and accelerate multi-disciplinary collaborative research, and identify challenges and opportunities. As the end result, four topic areas were identified: ML in predicting materials properties, and discovery and design of novel materials, ML in porous and fractured media and time-dependent phenomena, Multi-scale modeling in heterogeneous porous materials via ML, and Discovery of materials constitutive laws and new governing equations. This workshop was part of the AmeriMech Symposium series sponsored by the National Academies of Sciences, Engineering and Medicine and the U.S. National Committee on Theoretical and Applied Mechanics.
Gaussian Imagination in Bandit Learning
Jan 30, 2022
Assuming distributions are Gaussian often facilitates computations that are otherwise intractable. We study the performance of an agent that attains a bounded information ratio with respect to a bandit environment with a Gaussian prior distribution and a Gaussian likelihood function when applied instead to a Bernoulli bandit. Relative to an information-theoretic bound on the Bayesian regret the agent would incur when interacting with the Gaussian bandit, we bound the increase in regret when the agent interacts with the Bernoulli bandit. If the Gaussian prior distribution and likelihood function are sufficiently diffuse, this increase grows at a rate which is at most linear in the square-root of the time horizon, and thus the per-timestep increase vanishes. Our results formalize the folklore that so-called Bayesian agents remain effective when instantiated with diffuse misspecified distributions.