 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BITES: Balanced Individual Treatment Effect for Survival data
Jan 05, 2022
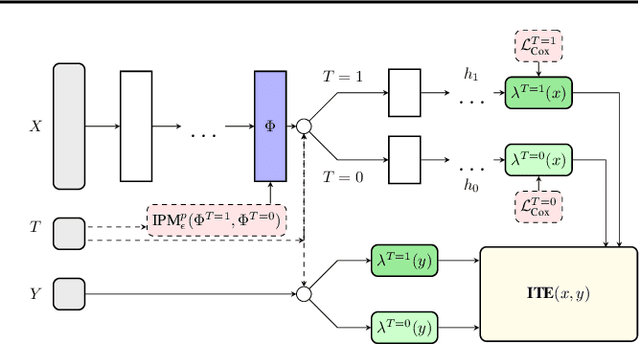
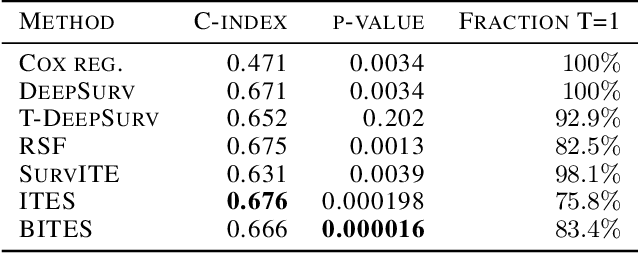
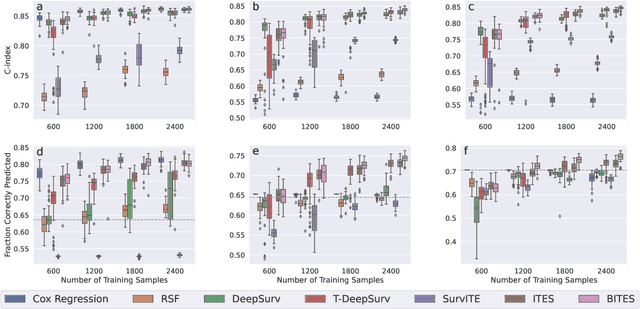
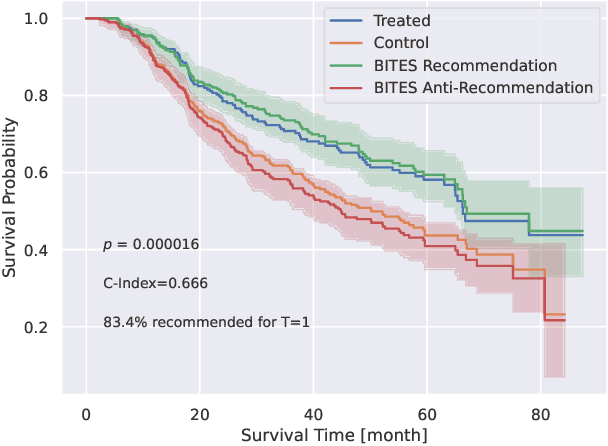
Estimating the effects of interventions on patient outcome is one of the key aspects of personalized medicine. Their inference is often challenged by the fact that the training data comprises only the outcome for the administered treatment, and not for alternative treatments (the so-called counterfactual outcomes). Several methods were suggested for this scenario based on observational data, i.e.~data where the intervention was not applied randomly, for both continuous and binary outcome variables. However, patient outcome is often recorded in terms of time-to-event data, comprising right-censored event times if an event does not occur within the observation period. Albeit their enormous importance, time-to-event data is rarely used for treatment optimization. We suggest an approach named BITES (Balanced Individual Treatment Effect for Survival data), which combines a treatment-specific semi-parametric Cox loss with a treatment-balanced deep neural network; i.e.~we regularize differences between treated and non-treated patients using Integral Probability Metrics (IPM). We show in simulation studies that this approach outperforms the state of the art. Further, we demonstrate in an application to a cohort of breast cancer patients that hormone treatment can be optimized based on six routine parameters. We successfully validated this finding in an independent cohort. BITES is provided as an easy-to-use python implementation.
Mixed-Block Neural Architecture Search for Medical Image Segmentation
Feb 23, 2022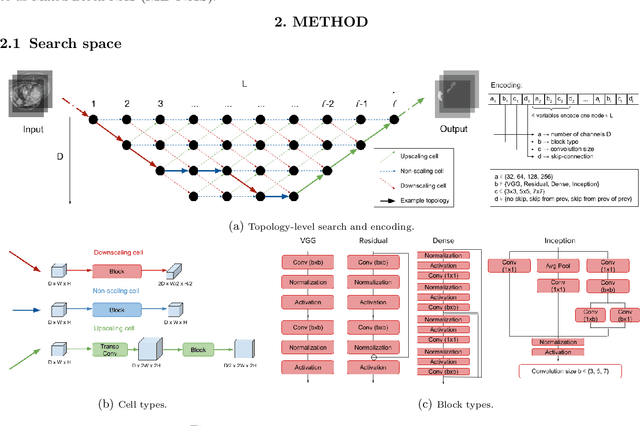
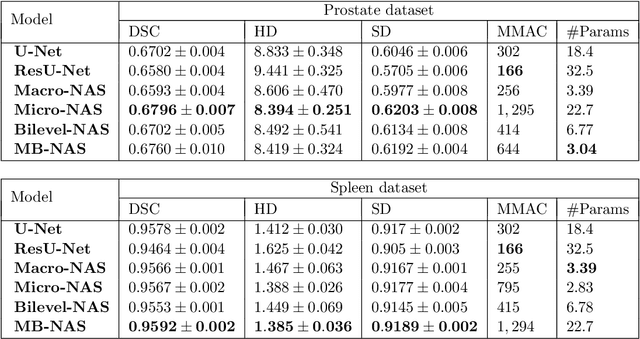
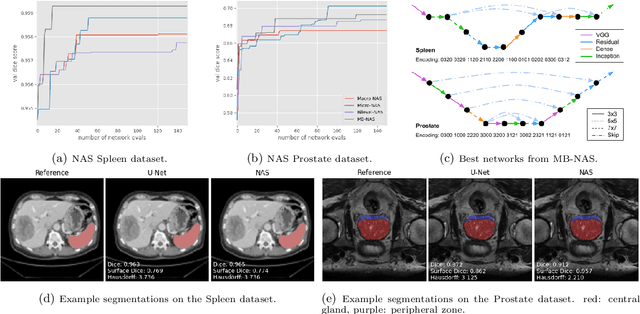
Deep Neural Networks (DNNs) have the potential for making various clinical procedures more time-efficient by automating medical image segmentation. Due to their strong, in some cases human-level, performance, they have become the standard approach in this field. The design of the best possible medical image segmentation DNNs, however, is task-specific. Neural Architecture Search (NAS), i.e., the automation of neural network design, has been shown to have the capability to outperform manually designed networks for various tasks. However, the existing NAS methods for medical image segmentation have explored a quite limited range of types of DNN architectures that can be discovered. In this work, we propose a novel NAS search space for medical image segmentation networks. This search space combines the strength of a generalised encoder-decoder structure, well known from U-Net, with network blocks that have proven to have a strong performance in image classification tasks. The search is performed by looking for the best topology of multiple cells simultaneously with the configuration of each cell within, allowing for interactions between topology and cell-level attributes. From experiments on two publicly available datasets, we find that the networks discovered by our proposed NAS method have better performance than well-known handcrafted segmentation networks, and outperform networks found with other NAS approaches that perform only topology search, and topology-level search followed by cell-level search.
RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
Nov 17, 2020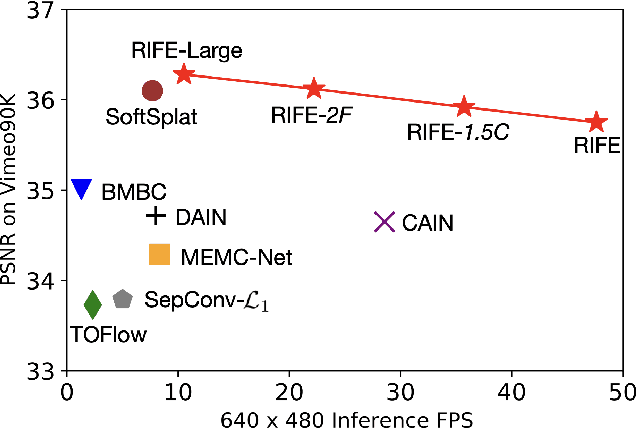

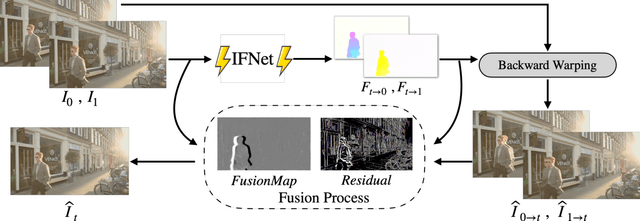
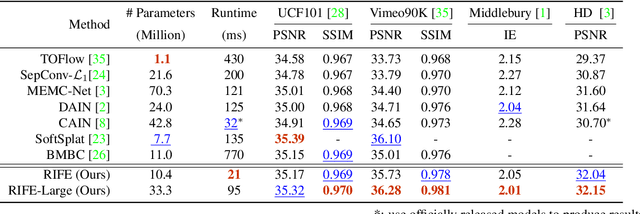
We propose RIFE, a Real-time Intermediate Flow Estimation algorithm for Video Frame Interpolation (VFI). Most existing methods first estimate the bi-directional optical flows and then linearly combine them to approximate intermediate flows, leading to artifacts on motion boundaries. RIFE uses a neural network named IFNet that can directly estimate the intermediate flows from images. With the more precise flows and our simplified fusion process, RIFE can improve interpolation quality and have much better speed. Based on our proposed leakage distillation loss, RIFE can be trained in an end-to-end fashion. Experiments demonstrate that our method is significantly faster than existing VFI methods and can achieve state-of-the-art performance on public benchmarks. The code is available at https://github.com/hzwer/arXiv2020-RIFE.
Proofs and additional experiments on Second order techniques for learning time-series with structural breaks
Dec 15, 2020
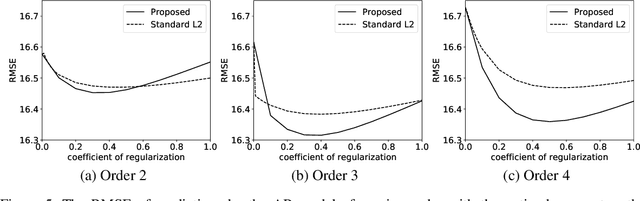
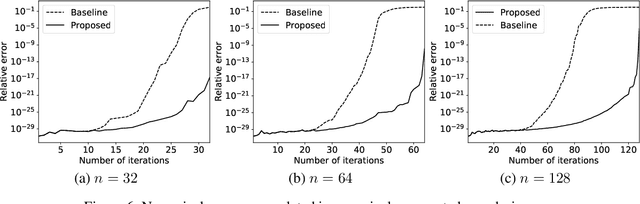
We provide complete proofs of the lemmas about the properties of the regularized loss function that is used in the second order techniques for learning time-series with structural breaks in Osogami (2021). In addition, we show experimental results that support the validity of the techniques.
Sparse-Push: Communication- & Energy-Efficient Decentralized Distributed Learning over Directed & Time-Varying Graphs with non-IID Datasets
Feb 10, 2021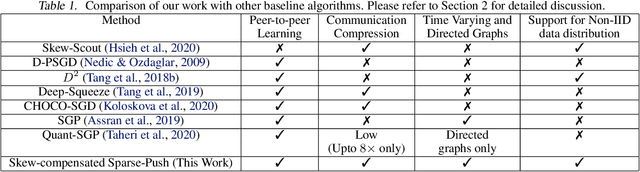
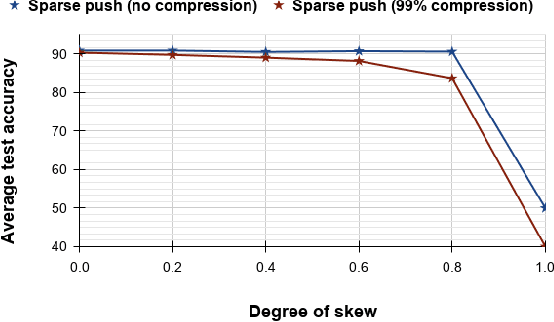
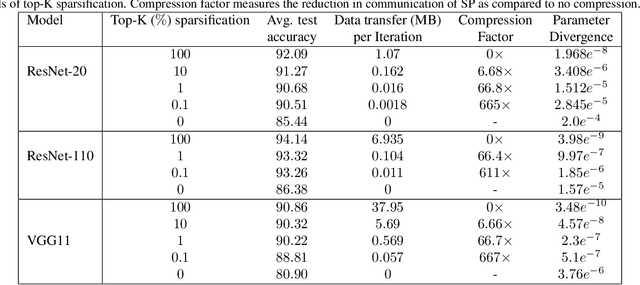
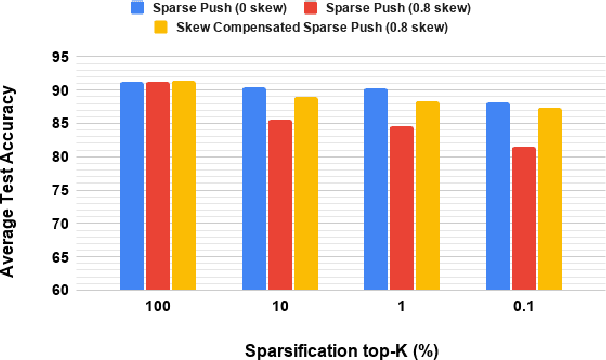
Current deep learning (DL) systems rely on a centralized computing paradigm which limits the amount of available training data, increases system latency, and adds privacy and security constraints. On-device learning, enabled by decentralized and distributed training of DL models over peer-to-peer wirelessly connected edge devices, not only alleviate the above limitations but also enable next-gen applications that need DL models to continuously interact and learn from their environment. However, this necessitates the development of novel training algorithms that train DL models over time-varying and directed peer-to-peer graph structures while minimizing the amount of communication between the devices and also being resilient to non-IID data distributions. In this work we propose, Sparse-Push, a communication efficient decentralized distributed training algorithm that supports training over peer-to-peer, directed, and time-varying graph topologies. The proposed algorithm enables 466x reduction in communication with only 1% degradation in performance when training various DL models such as ResNet-20 and VGG11 over the CIFAR-10 dataset. Further, we demonstrate how communication compression can lead to significant performance degradation in-case of non-IID datasets, and propose Skew-Compensated Sparse Push algorithm that recovers this performance drop while maintaining similar levels of communication compression.
Dual Domain Waveform Design for Joint Communication and Sensing Systems
Nov 24, 2021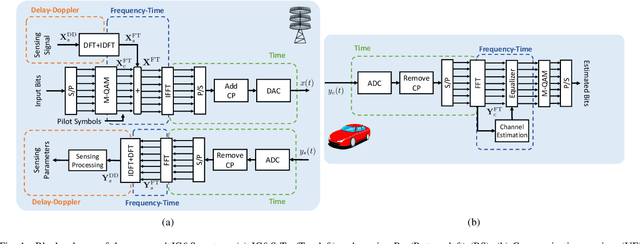
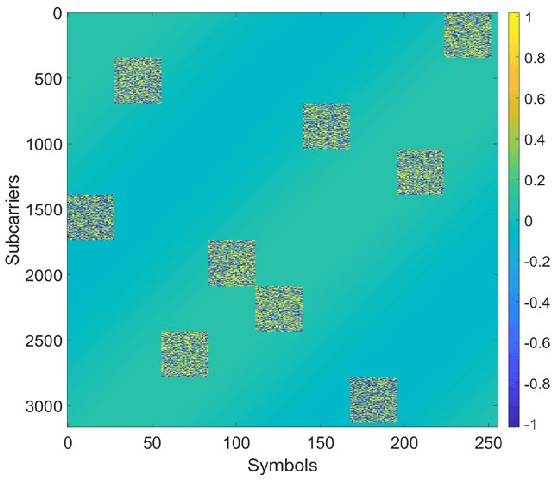
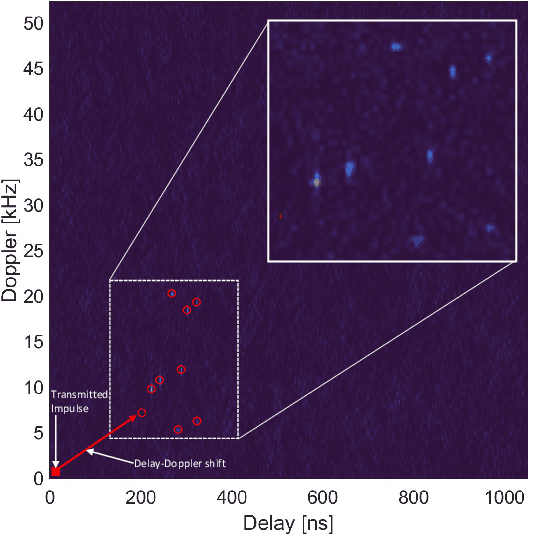
The evolution of wireless communication systems towards millimeter-wave ($30-100$ GHz) and sub-THz ($>100$ GHz) frequency bands highlighted the need for accurate and fast beam management and a proactive link-blockage prediction in high-mobility scenarios. Joint Communication and Sensing (JC\&S) systems aim at equipping communication terminals with sensing capabilities using the same time/frequency/space communication resources to solve, or alleviate, the aforementioned issues. For an efficient implementation, a suitable waveform design that combines communication and sensing capabilities is of utmost importance. This paper proposes a novel dual-domain waveform design approach that superimposes onto the Frequency-Time (FT) domain both the legacy orthogonal frequency division multiplexing modulation scheme and a sensing signal, purposely designed in the Delay-Doppler (DD) domain. The power of the two signals is properly allocated in FT and DD domains, respectively, to reduce their mutual interference and optimize both communication and sensing tasks. Numerical results show the effectiveness of the proposed JC\&S waveform design approach, yielding target communication and sensing performance with a full time-frequency resource sharing.
Sign Language Recognition System using TensorFlow Object Detection API
Jan 05, 2022
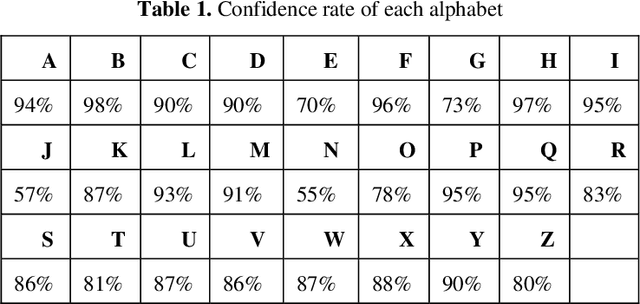


Communication is defined as the act of sharing or exchanging information, ideas or feelings. To establish communication between two people, both of them are required to have knowledge and understanding of a common language. But in the case of deaf and dumb people, the means of communication are different. Deaf is the inability to hear and dumb is the inability to speak. They communicate using sign language among themselves and with normal people but normal people do not take seriously the importance of sign language. Not everyone possesses the knowledge and understanding of sign language which makes communication difficult between a normal person and a deaf and dumb person. To overcome this barrier, one can build a model based on machine learning. A model can be trained to recognize different gestures of sign language and translate them into English. This will help a lot of people in communicating and conversing with deaf and dumb people. The existing Indian Sing Language Recognition systems are designed using machine learning algorithms with single and double-handed gestures but they are not real-time. In this paper, we propose a method to create an Indian Sign Language dataset using a webcam and then using transfer learning, train a TensorFlow model to create a real-time Sign Language Recognition system. The system achieves a good level of accuracy even with a limited size dataset.
Croesus: Multi-Stage Processing and Transactions for Video-Analytics in Edge-Cloud Systems
Dec 31, 2021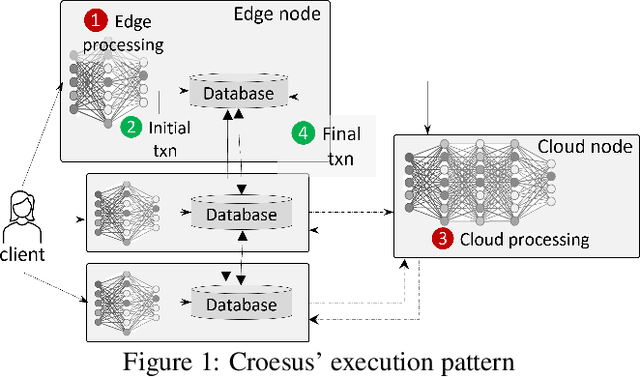
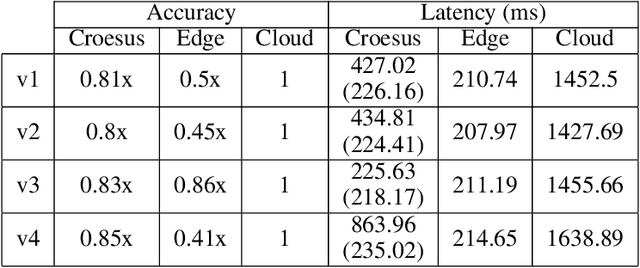
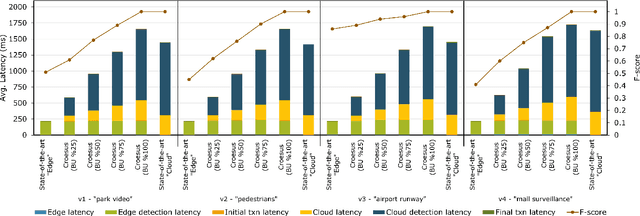
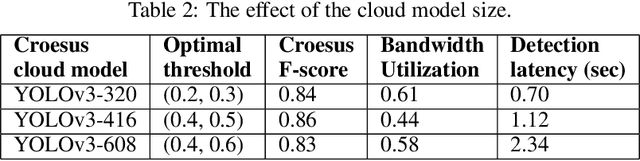
Emerging edge applications require both a fast response latency and complex processing. This is infeasible without expensive hardware that can process complex operations -- such as object detection -- within a short time. Many approach this problem by addressing the complexity of the models -- via model compression, pruning and quantization -- or compressing the input. In this paper, we propose a different perspective when addressing the performance challenges. Croesus is a multi-stage approach to edge-cloud systems that provides the ability to find the balance between accuracy and performance. Croesus consists of two stages (that can be generalized to multiple stages): an initial and a final stage. The initial stage performs the computation in real-time using approximate/best-effort computation at the edge. The final stage performs the full computation at the cloud, and uses the results to correct any errors made at the initial stage. In this paper, we demonstrate the implications of such an approach on a video analytics use-case and show how multi-stage processing yields a better balance between accuracy and performance. Moreover, we study the safety of multi-stage transactions via two proposals: multi-stage serializability (MS-SR) and multi-stage invariant confluence with Apologies (MS-IA).
Robustly-reliable learners under poisoning attacks
Mar 08, 2022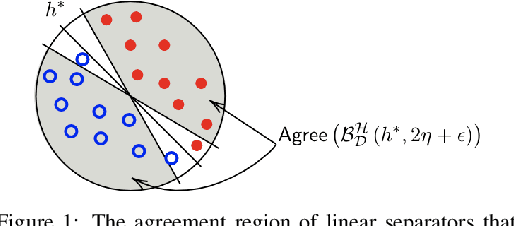
Data poisoning attacks, in which an adversary corrupts a training set with the goal of inducing specific desired mistakes, have raised substantial concern: even just the possibility of such an attack can make a user no longer trust the results of a learning system. In this work, we show how to achieve strong robustness guarantees in the face of such attacks across multiple axes. We provide robustly-reliable predictions, in which the predicted label is guaranteed to be correct so long as the adversary has not exceeded a given corruption budget, even in the presence of instance targeted attacks, where the adversary knows the test example in advance and aims to cause a specific failure on that example. Our guarantees are substantially stronger than those in prior approaches, which were only able to provide certificates that the prediction of the learning algorithm does not change, as opposed to certifying that the prediction is correct, as we are able to achieve in our work. Remarkably, we provide a complete characterization of learnability in this setting, in particular, nearly-tight matching upper and lower bounds on the region that can be certified, as well as efficient algorithms for computing this region given an ERM oracle. Moreover, for the case of linear separators over logconcave distributions, we provide efficient truly polynomial time algorithms (i.e., non-oracle algorithms) for such robustly-reliable predictions. We also extend these results to the active setting where the algorithm adaptively asks for labels of specific informative examples, and the difficulty is that the adversary might even be adaptive to this interaction, as well as to the agnostic learning setting where there is no perfect classifier even over the uncorrupted data.
Parameter estimation for WMTI-Watson model of white matter using encoder-decoder recurrent neural network
Mar 02, 2022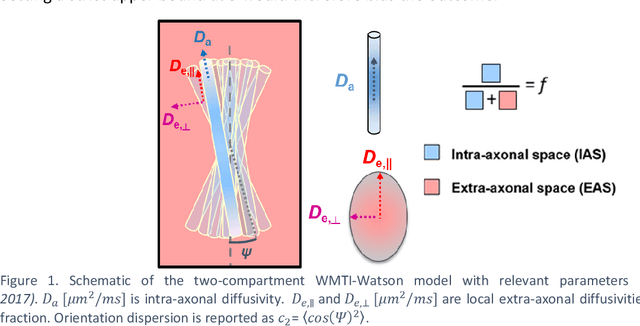

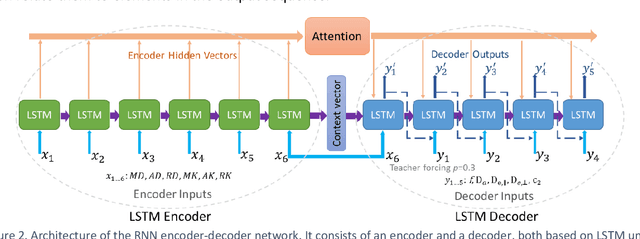
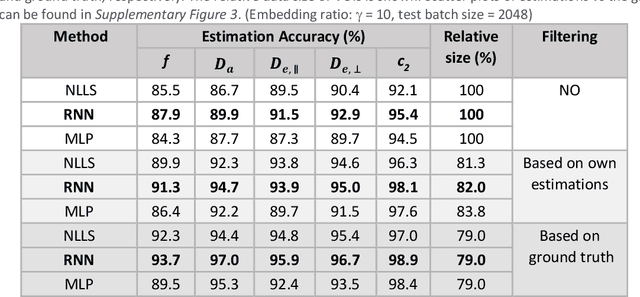
Biophysical modelling of the diffusion MRI signal provides estimates of specific microstructural tissue properties. Although nonlinear optimization such as non-linear least squares (NLLS) is the most widespread method for model estimation, it suffers from local minima and high computational cost. Deep Learning approaches are steadily replacing NL fitting, but come with the limitation that the model needs to be retrained for each acquisition protocol and noise level. The White Matter Tract Integrity (WMTI)-Watson model was proposed as an implementation of the Standard Model of diffusion in white matter that estimates model parameters from the diffusion and kurtosis tensors (DKI). Here we proposed a deep learning approach based on the encoder-decoder recurrent neural network (RNN) to increase the robustness and accelerate the parameter estimation of WMTI-Watson. We use an embedding approach to render the model insensitive to potential differences in distributions between training data and experimental data. This RNN-based solver thus has the advantage of being highly efficient in computation and more readily translatable to other datasets, irrespective of acquisition protocol and underlying parameter distributions as long as DKI was pre-computed from the data. In this study, we evaluated the performance of NLLS, the RNN-based method and a multilayer perceptron (MLP) on synthetic and in vivo datasets of rat and human brain. We showed that the proposed RNN-based fitting approach had the advantage of highly reduced computation time over NLLS (from hours to seconds), with similar accuracy and precision but improved robustness, and superior translatability to new datasets over MLP.