 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Skeleton-Based Human Activity Discovery Technique Using Particle Swarm Optimization with Gaussian Mutation
Jan 14, 2022




Human activity discovery aims to distinguish the activities performed by humans, without any prior information of what defines each activity. Most methods presented in human activity recognition are supervised, where there are labeled inputs to train the system. In reality, it is difficult to label data because of its huge volume and the variety of activities performed by humans. In this paper, a novel unsupervised approach is proposed to perform human activity discovery in 3D skeleton sequences. First, important frames are selected based on kinetic energy. Next, the displacement of joints, set of statistical, angles, and orientation features are extracted to represent the activities information. Since not all extracted features have useful information, the dimension of features is reduced using PCA. Most human activity discovery proposed are not fully unsupervised. They use pre-segmented videos before categorizing activities. To deal with this, we used the fragmented sliding time window method to segment the time series of activities with some overlapping. Then, activities are discovered by a novel hybrid particle swarm optimization with a Gaussian mutation algorithm to avoid getting stuck in the local optimum. Finally, k-means is applied to the outcome centroids to overcome the slow rate of PSO. Experiments on three datasets have been presented and the results show the proposed method has superior performance in discovering activities in all evaluation parameters compared to the other state-of-the-art methods and has increased accuracy of at least 4 % on average. The code is available here: https://github.com/parhamhadikhani/Human-Activity-Discovery-HPGMK
Noisy Neonatal Chest Sound Separation for High-Quality Heart and Lung Sounds
Jan 10, 2022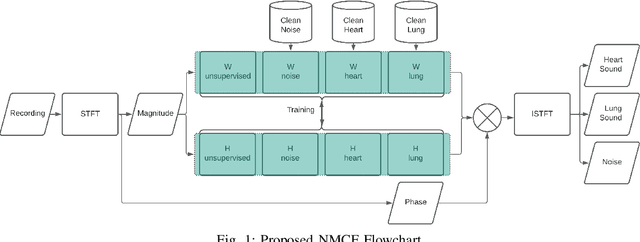
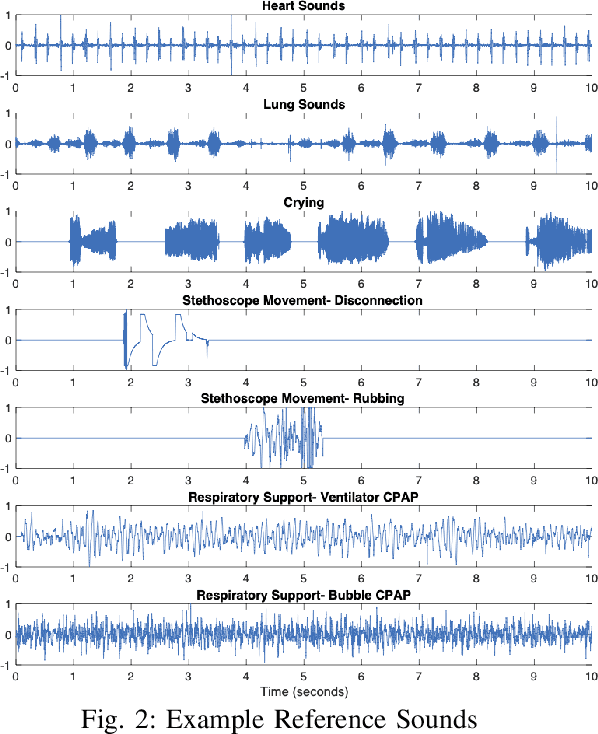
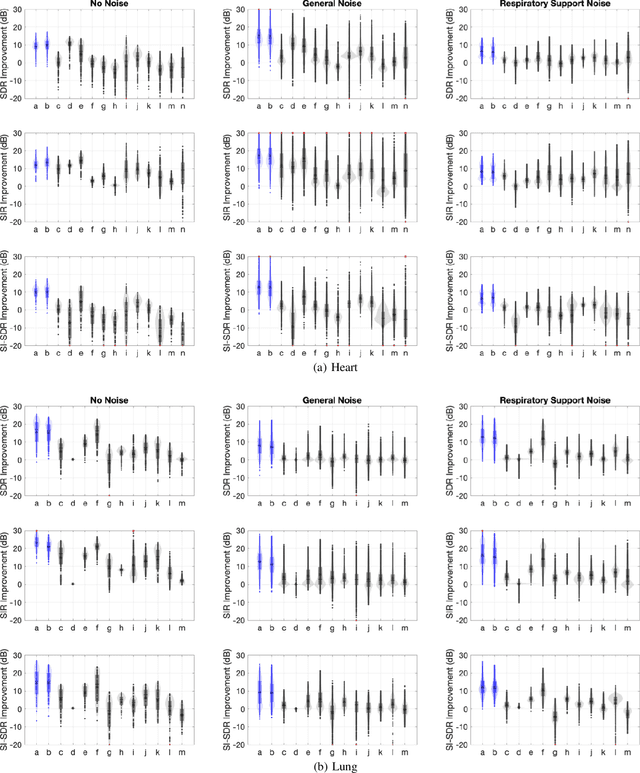
Stethoscope-recorded chest sounds provide the opportunity for remote cardio-respiratory health monitoring of neonates. However, reliable monitoring requires high-quality heart and lung sounds. This paper presents novel Non-negative Matrix Factorisation (NMF) and Non-negative Matrix Co-Factorisation (NMCF) methods for neonatal chest sound separation. To assess these methods and compare with existing single-source separation methods, an artificial mixture dataset was generated comprising of heart, lung and noise sounds. Signal-to-noise ratios were then calculated for these artificial mixtures. These methods were also tested on real-world noisy neonatal chest sounds and assessed based on vital sign estimation error and a signal quality score of 1-5 developed in our previous works. Additionally, the computational cost of all methods was assessed to determine the applicability for real-time processing. Overall, both the proposed NMF and NMCF methods outperform the next best existing method by 2.7dB to 11.6dB for the artificial dataset and 0.40 to 1.12 signal quality improvement for the real-world dataset. The median processing time for the sound separation of a 10s recording was found to be 28.3s for NMCF and 342ms for NMF. Because of stable and robust performance, we believe that our proposed methods are useful to denoise neonatal heart and lung sound in a real-world environment. Codes for proposed and existing methods can be found at: https://github.com/egrooby-monash/Heart-and-Lung-Sound-Separation.
Sparse-Push: Communication- & Energy-Efficient Decentralized Distributed Learning over Directed & Time-Varying Graphs with non-IID Datasets
Feb 12, 2021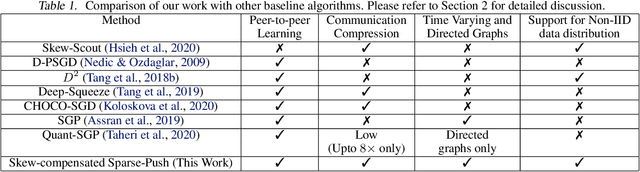
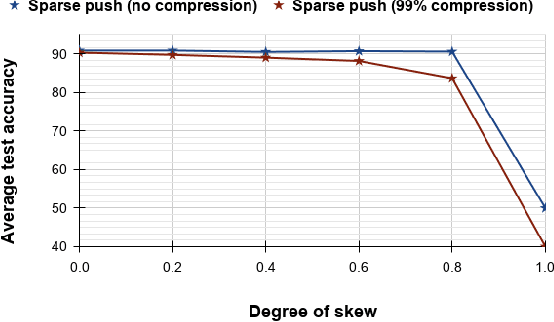
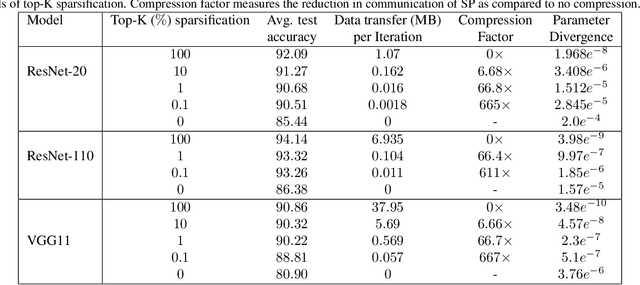
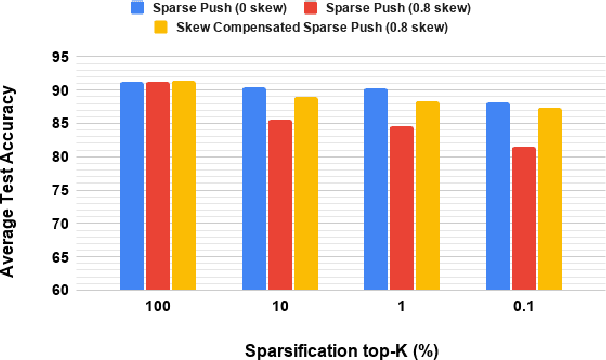
Current deep learning (DL) systems rely on a centralized computing paradigm which limits the amount of available training data, increases system latency, and adds privacy and security constraints. On-device learning, enabled by decentralized and distributed training of DL models over peer-to-peer wirelessly connected edge devices, not only alleviate the above limitations but also enable next-gen applications that need DL models to continuously interact and learn from their environment. However, this necessitates the development of novel training algorithms that train DL models over time-varying and directed peer-to-peer graph structures while minimizing the amount of communication between the devices and also being resilient to non-IID data distributions. In this work we propose, Sparse-Push, a communication efficient decentralized distributed training algorithm that supports training over peer-to-peer, directed, and time-varying graph topologies. The proposed algorithm enables 466x reduction in communication with only 1% degradation in performance when training various DL models such as ResNet-20 and VGG11 over the CIFAR-10 dataset. Further, we demonstrate how communication compression can lead to significant performance degradation in-case of non-IID datasets, and propose Skew-Compensated Sparse Push algorithm that recovers this performance drop while maintaining similar levels of communication compression.
A machine learning approach for forecasting hierarchical time series
May 31, 2020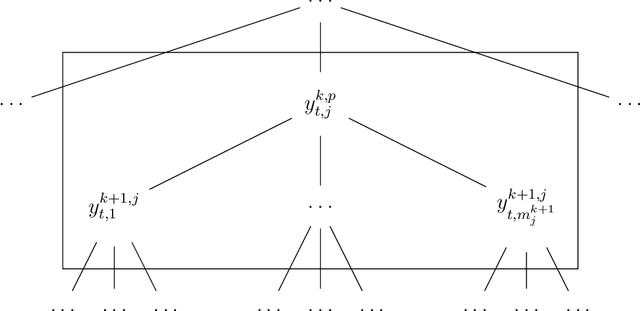

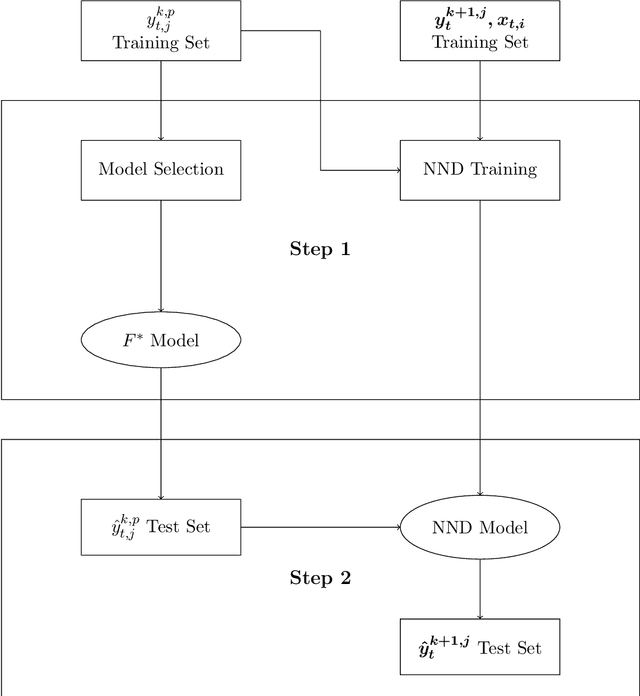

In this paper, we propose a machine learning approach for forecasting hierarchical time series. Rather than using historical or forecasted proportions, as in standard top-down approaches, we formulate the disaggregation problem as a non-linear regression problem. We propose a deep neural network that automatically learns how to distribute the top-level forecasts to the bottom level-series of the hierarchy, keeping into account the characteristics of the aggregate series and the information of the individual series. In order to evaluate the performance of the proposed method, we analyze hierarchical sales data and electricity demand data. Besides comparison with the top-down approaches, the model is compared with the bottom-up method and the optimal reconciliation method. Results demonstrate that our method does not only increase the average forecasting accuracy of the hierarchy but also addresses the need of building an automated procedure generating coherent forecasts for many time series at the same time.
Unifying Pairwise Interactions in Complex Dynamics
Jan 28, 2022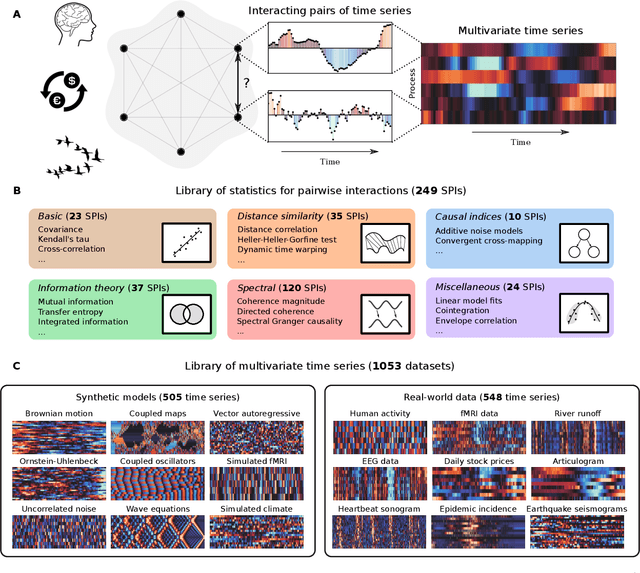
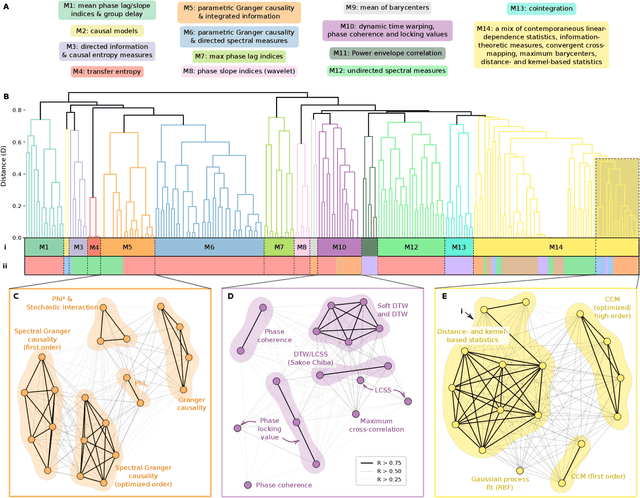
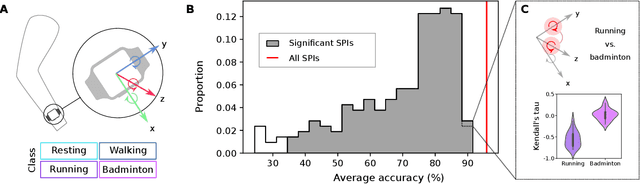
Scientists have developed hundreds of techniques to measure the interactions between pairs of processes in complex systems. But these computational methods -- from correlation coefficients to causal inference -- rely on distinct quantitative theories that remain largely disconnected. Here we introduce a library of 249 statistics for pairwise interactions and assess their behavior on 1053 multivariate time series from a wide range of real-world and model-generated systems. Our analysis highlights new commonalities between different mathematical formulations, providing a unified picture of a rich, interdisciplinary literature. We then show that leveraging many methods from across science can uncover those most suitable for addressing a given problem, yielding high accuracy and interpretable understanding. Our framework is provided in extendable open software, enabling comprehensive data-driven analysis by integrating decades of methodological advances.
Learning with distributional inverters
Dec 23, 2021We generalize the "indirect learning" technique of Furst et. al., 1991 to reduce from learning a concept class over a samplable distribution $\mu$ to learning the same concept class over the uniform distribution. The reduction succeeds when the sampler for $\mu$ is both contained in the target concept class and efficiently invertible in the sense of Impagliazzo & Luby, 1989. We give two applications. - We show that AC0[q] is learnable over any succinctly-described product distribution. AC0[q] is the class of constant-depth Boolean circuits of polynomial size with AND, OR, NOT, and counting modulo $q$ gates of unbounded fanins. Our algorithm runs in randomized quasi-polynomial time and uses membership queries. - If there is a strongly useful natural property in the sense of Razborov & Rudich 1997 -- an efficient algorithm that can distinguish between random strings and strings of non-trivial circuit complexity -- then general polynomial-sized Boolean circuits are learnable over any efficiently samplable distribution in randomized polynomial time, given membership queries to the target function
Deep Time-Delay Reservoir Computing: Dynamics and Memory Capacity
Jun 11, 2020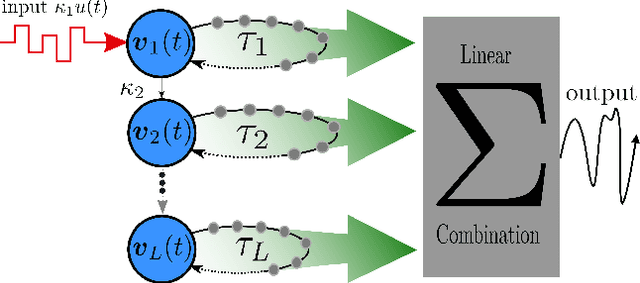
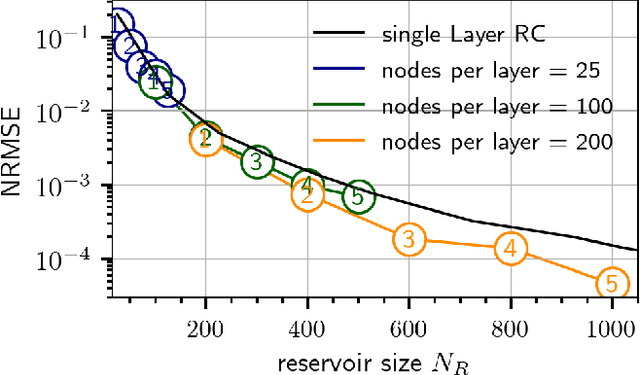
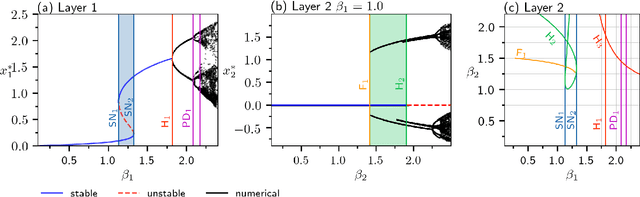
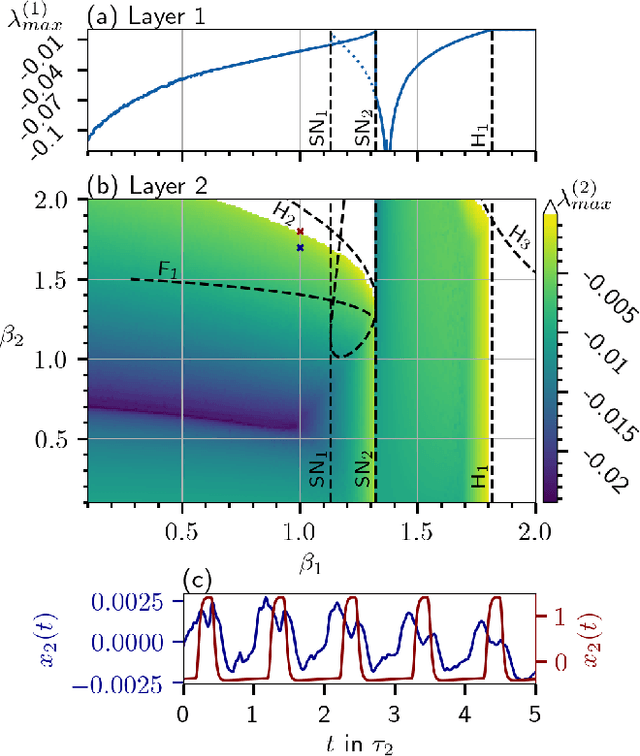
The Deep Time-Delay Reservoir Computing concept utilizes unidirectionally connected systems with time-delays for supervised learning. We present how the dynamical properties of a deep Ikeda-based reservoir are related to its memory capacity (MC) and how that can be used for optimization. In particular, we analyze bifurcations of the corresponding autonomous system and compute conditional Lyapunov exponents, which measure the generalized synchronization between the input and the layer dynamics. We show how the MC is related to the systems distance to bifurcations or magnitude of the conditional Lyapunov exponent. The interplay of different dynamical regimes leads to a adjustable distribution between linear and nonlinear MC. Furthermore, numerical simulations show resonances between clock cycle and delays of the layers in all degrees of the MC. Contrary to MC losses in a single-layer reservoirs, these resonances can boost separate degrees of the MC and can be used, e.g., to design a system with maximum linear MC. Accordingly, we present two configurations that empower either high nonlinear MC or long time linear MC.
Active Sensing for Communications by Learning
Dec 08, 2021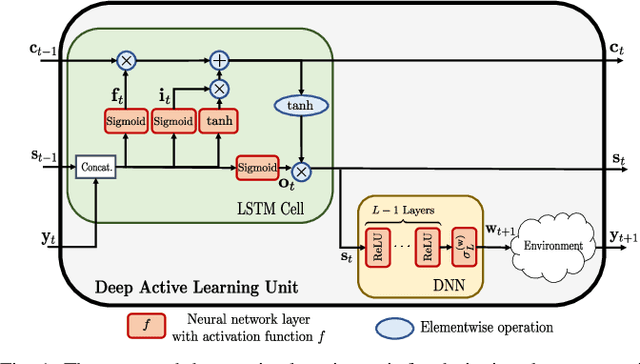
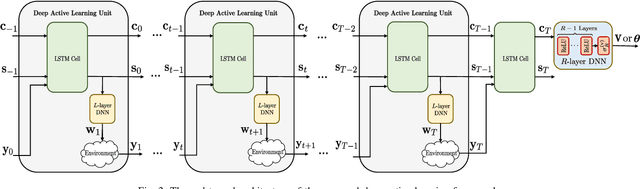
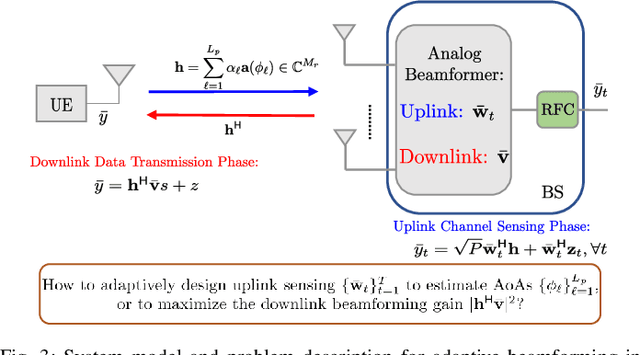
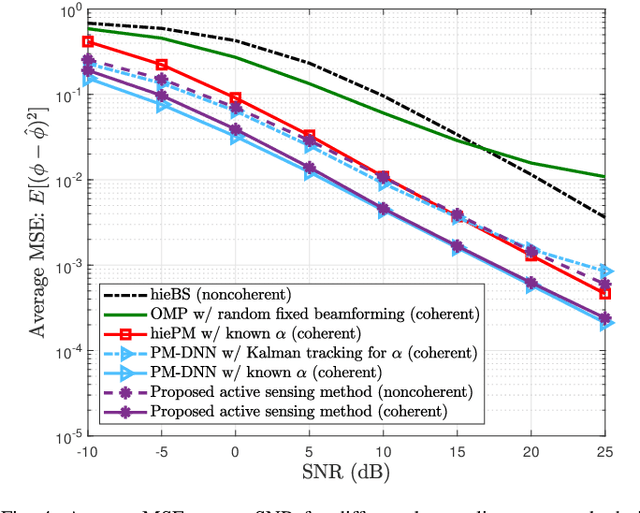
This paper proposes a deep learning approach to a class of active sensing problems in wireless communications in which an agent sequentially interacts with an environment over a predetermined number of time frames to gather information in order to perform a sensing or actuation task for maximizing some utility function. In such an active learning setting, the agent needs to design an adaptive sensing strategy sequentially based on the observations made so far. To tackle such a challenging problem in which the dimension of historical observations increases over time, we propose to use a long short-term memory (LSTM) network to exploit the temporal correlations in the sequence of observations and to map each observation to a fixed-size state information vector. We then use a deep neural network (DNN) to map the LSTM state at each time frame to the design of the next measurement step. Finally, we employ another DNN to map the final LSTM state to the desired solution. We investigate the performance of the proposed framework for adaptive channel sensing problems in wireless communications. In particular, we consider the adaptive beamforming problem for mmWave beam alignment and the adaptive reconfigurable intelligent surface sensing problem for reflection alignment. Numerical results demonstrate that the proposed deep active sensing strategy outperforms the existing adaptive or nonadaptive sensing schemes.
BLOOM-Net: Blockwise Optimization for Masking Networks Toward Scalable and Efficient Speech Enhancement
Nov 17, 2021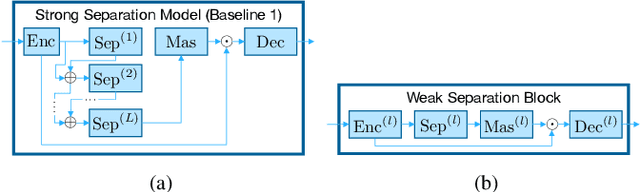
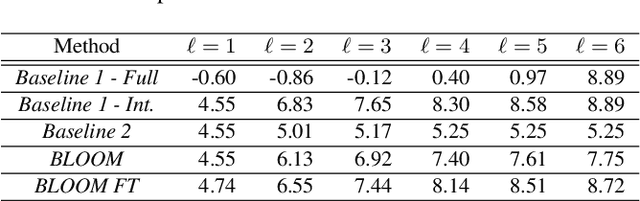
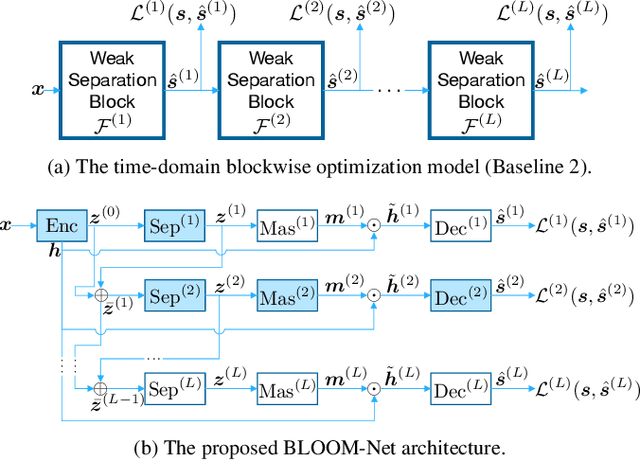

In this paper, we present a blockwise optimization method for masking-based networks (BLOOM-Net) for training scalable speech enhancement networks. Here, we design our network with a residual learning scheme and train the internal separator blocks sequentially to obtain a scalable masking-based deep neural network for speech enhancement. Its scalability lets it adjust the run-time complexity based on the test-time resource constraints: once deployed, the model can alter its complexity dynamically depending on the test time environment. To this end, we modularize our models in that they can flexibly accommodate varying needs for enhancement performance and constraints on the resources, incurring minimal memory or training overhead due to the added scalability. Our experiments on speech enhancement demonstrate that the proposed blockwise optimization method achieves the desired scalability with only a slight performance degradation compared to corresponding models trained end-to-end.
FamilySeer: Towards Optimized Tensor Codes by Exploiting Computation Subgraph Similarity
Jan 01, 2022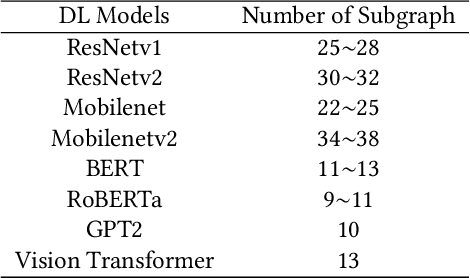
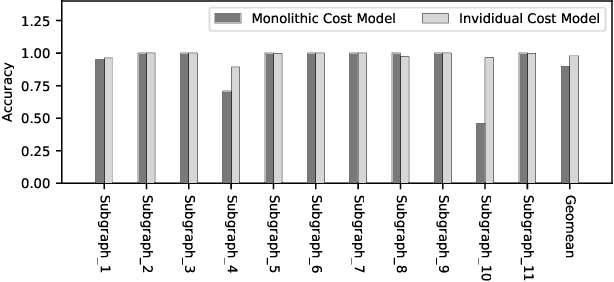
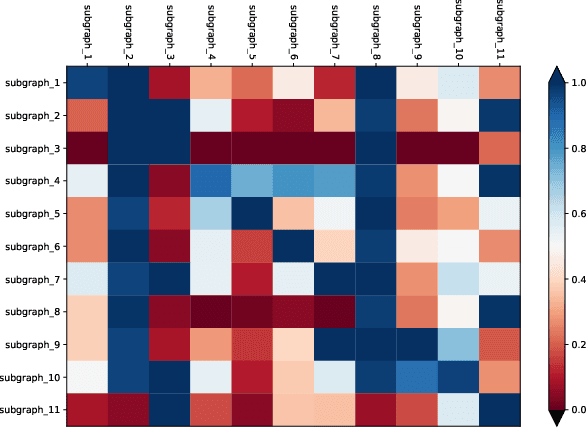

Deploying various deep learning (DL) models efficiently has boosted the research on DL compilers. The difficulty of generating optimized tensor codes drives DL compiler to ask for the auto-tuning approaches, and the increasing demands require increasing auto-tuning efficiency and quality. Currently, the DL compilers partition the input DL models into several subgraphs and leverage the auto-tuning to find the optimal tensor codes of these subgraphs. However, existing auto-tuning approaches usually regard subgraphs as individual ones and overlook the similarities across them, and thus fail to exploit better tensor codes under limited time budgets. We propose FamilySeer, an auto-tuning framework for DL compilers that can generate better tensor codes even with limited time budgets. FamilySeer exploits the similarities and differences among subgraphs can organize them into subgraph families, where the tuning of one subgraph can also improve other subgraphs within the same family. The cost model of each family gets more purified training samples generated by the family and becomes more accurate so that the costly measurements on real hardware can be replaced with the lightweight estimation through cost model. Our experiments show that FamilySeer can generate model codes with the same code performance more efficiently than state-of-the-art auto-tuning frameworks.