 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Subspace Change-Point Detection via Low-Rank Matrix Factorisation
Oct 08, 2021
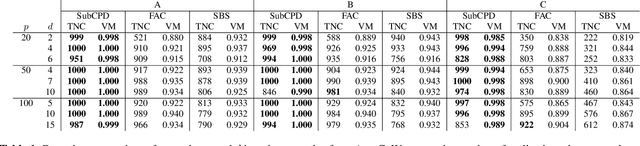

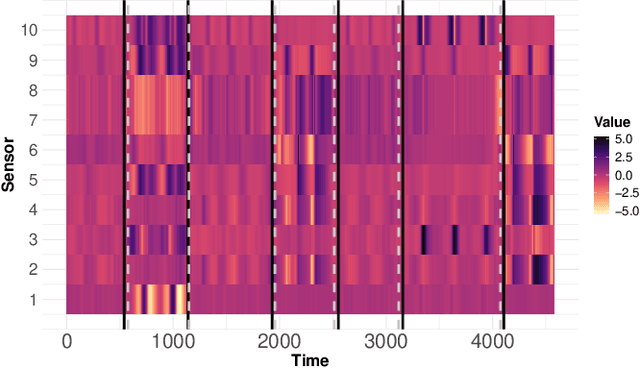
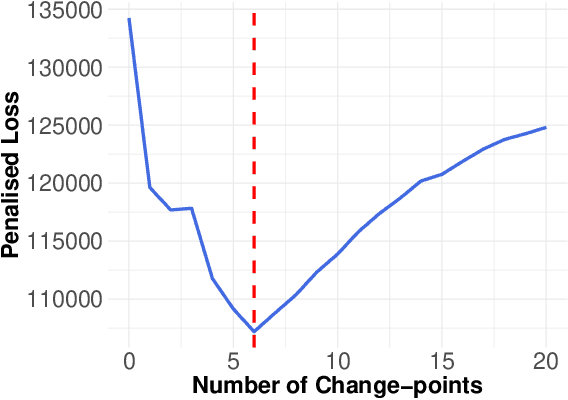
Multivariate time series can often have a large number of dimensions, whether it is due to the vast amount of collected features or due to how the data sources are processed. Frequently, the main structure of the high-dimensional time series can be well represented by a lower dimensional subspace. As vast quantities of data are being collected over long periods of time, it is reasonable to assume that the underlying subspace structure would change over time. In this work, we propose a change-point detection method based on low-rank matrix factorisation that can detect multiple changes in the underlying subspace of a multivariate time series. Experimental results on both synthetic and real data sets demonstrate the effectiveness of our approach and its advantages against various state-of-the-art methods.
Fast Server Learning Rate Tuning for Coded Federated Dropout
Jan 26, 2022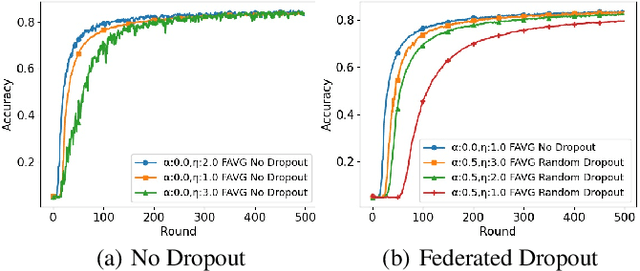
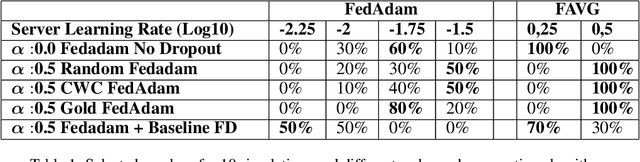
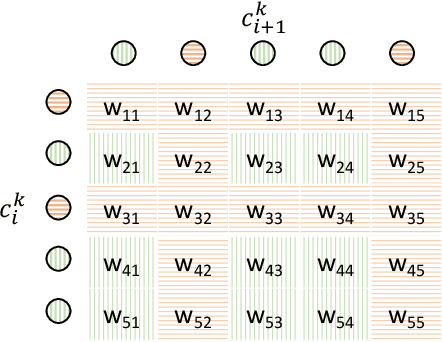
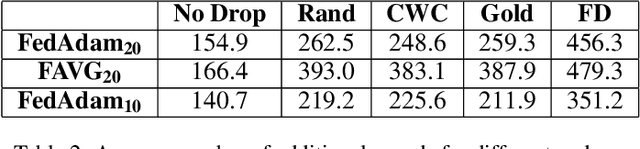
In cross-device Federated Learning (FL), clients with low computational power train a common machine model by exchanging parameters updates instead of potentially private data. Federated Dropout (FD) is a technique that improves the communication efficiency of a FL session by selecting a subset of model variables to be updated in each training round. However, FD produces considerably lower accuracy and higher convergence time compared to standard FL. In this paper, we leverage coding theory to enhance FD by allowing a different sub-model to be used at each client. We also show that by carefully tuning the server learning rate hyper-parameter, we can achieve higher training speed and up to the same final accuracy of the no dropout case. For the EMNIST dataset, our mechanism achieves 99.6 % of the final accuracy of the no dropout case while requiring 2.43x less bandwidth to achieve this accuracy level.
CAD-RADS Scoring using Deep Learning and Task-Specific Centerline Labeling
Feb 08, 2022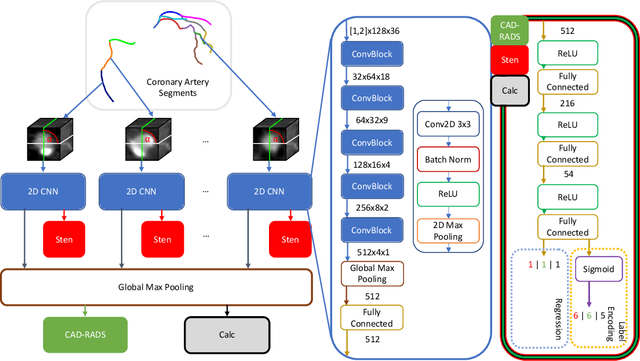
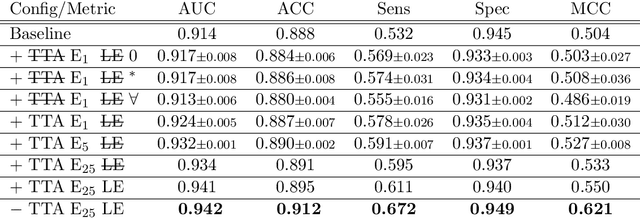
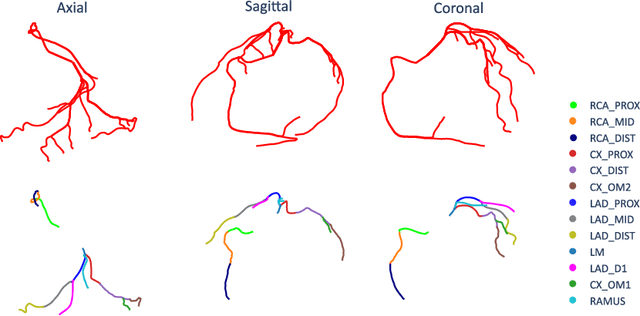
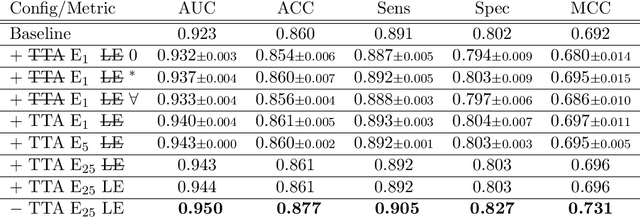
With coronary artery disease (CAD) persisting to be one of the leading causes of death worldwide, interest in supporting physicians with algorithms to speed up and improve diagnosis is high. In clinical practice, the severeness of CAD is often assessed with a coronary CT angiography (CCTA) scan and manually graded with the CAD-Reporting and Data System (CAD-RADS) score. The clinical questions this score assesses are whether patients have CAD or not (rule-out) and whether they have severe CAD or not (hold-out). In this work, we reach new state-of-the-art performance for automatic CAD-RADS scoring. We propose using severity-based label encoding, test time augmentation (TTA) and model ensembling for a task-specific deep learning architecture. Furthermore, we introduce a novel task- and model-specific, heuristic coronary segment labeling, which subdivides coronary trees into consistent parts across patients. It is fast, robust, and easy to implement. We were able to raise the previously reported area under the receiver operating characteristic curve (AUC) from 0.914 to 0.942 in the rule-out and from 0.921 to 0.950 in the hold-out task respectively.
Deep Learning for Reaction-Diffusion Glioma Growth Modelling: Towards a Fully Personalised Model?
Nov 26, 2021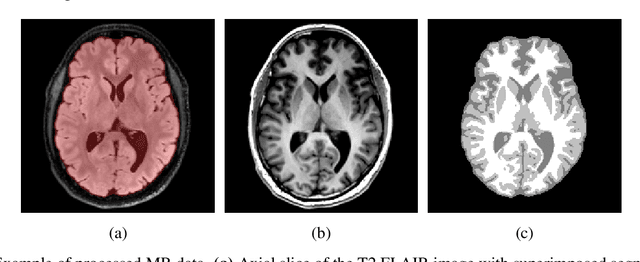
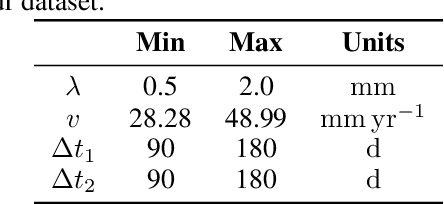
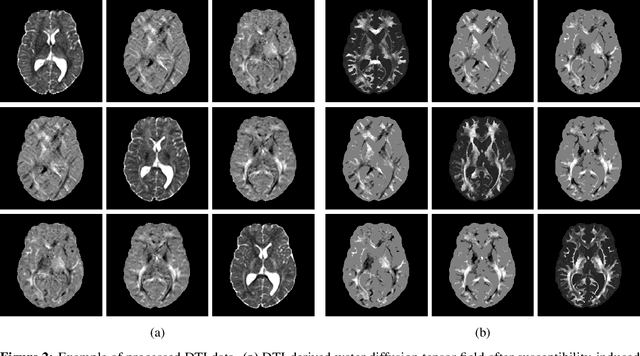

Reaction-diffusion models have been proposed for decades to capture the growth of gliomas, the most common primary brain tumours. However, severe limitations regarding the estimation of the initial conditions and parameter values of such models have restrained their clinical use as a personalised tool. In this work, we investigate the ability of deep convolutional neural networks (DCNNs) to address the pitfalls commonly encountered in the field. Based on 1,200 synthetic tumours grown over real brain geometries derived from magnetic resonance (MR) data of 6 healthy subjects, we demonstrate the ability of DCNNs to reconstruct a whole tumour cell density distribution from only two imaging contours at a single time point. With an additional imaging contour extracted at a prior time point, we also demonstrate the ability of DCNNs to accurately estimate the individual diffusivity and proliferation parameters of the model. From this knowledge, the spatio-temporal evolution of the tumour cell density distribution at later time points can ultimately be precisely captured using the model. We finally show the applicability of our approach to MR data of a real glioblastoma patient. This approach may open the perspective of a clinical application of reaction-diffusion growth models for tumour prognosis and treatment planning.
Achieving Real-Time Execution of 3D Convolutional Neural Networks on Mobile Devices
Jul 20, 2020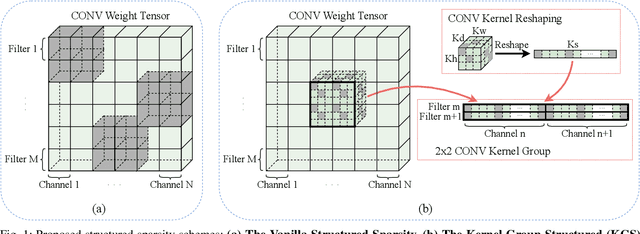
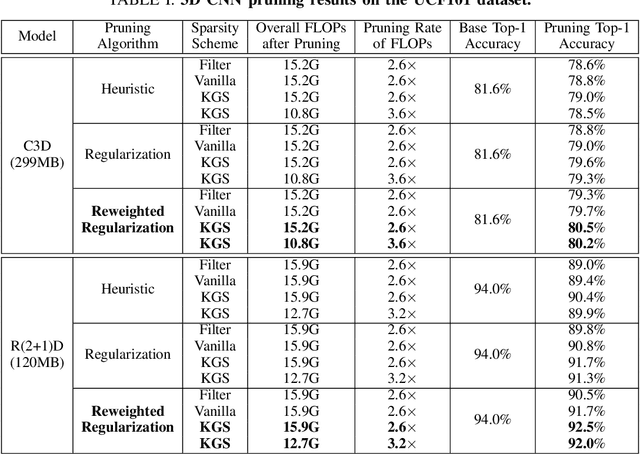
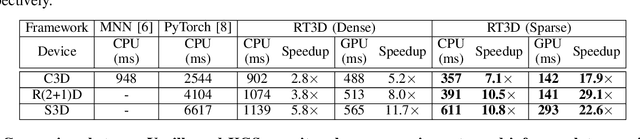

Mobile devices are becoming an important carrier for deep learning tasks, as they are being equipped with powerful, high-end mobile CPUs and GPUs. However, it is still a challenging task to execute 3D Convolutional Neural Networks (CNNs) targeting for real-time performance, besides high inference accuracy. The reason is more complex model structure and higher model dimensionality overwhelm the available computation/storage resources on mobile devices. A natural way may be turning to deep learning weight pruning techniques. However, the direct generalization of existing 2D CNN weight pruning methods to 3D CNNs is not ideal for fully exploiting mobile parallelism while achieving high inference accuracy. This paper proposes RT3D, a model compression and mobile acceleration framework for 3D CNNs, seamlessly integrating neural network weight pruning and compiler code generation techniques. We propose and investigate two structured sparsity schemes i.e., the vanilla structured sparsity and kernel group structured (KGS) sparsity that are mobile acceleration friendly. The vanilla sparsity removes whole kernel groups, while KGS sparsity is a more fine-grained structured sparsity that enjoys higher flexibility while exploiting full on-device parallelism. We propose a reweighted regularization pruning algorithm to achieve the proposed sparsity schemes. The inference time speedup due to sparsity is approaching the pruning rate of the whole model FLOPs (floating point operations). RT3D demonstrates up to 29.1$\times$ speedup in end-to-end inference time comparing with current mobile frameworks supporting 3D CNNs, with moderate 1%-1.5% accuracy loss. The end-to-end inference time for 16 video frames could be within 150 ms, when executing representative C3D and R(2+1)D models on a cellphone. For the first time, real-time execution of 3D CNNs is achieved on off-the-shelf mobiles.
Optimization-based Trajectory Tracking Approach for Multi-rotor Aerial Vehicles in Unknown Environments
Feb 12, 2022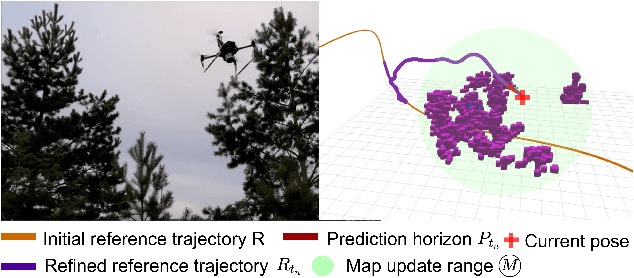
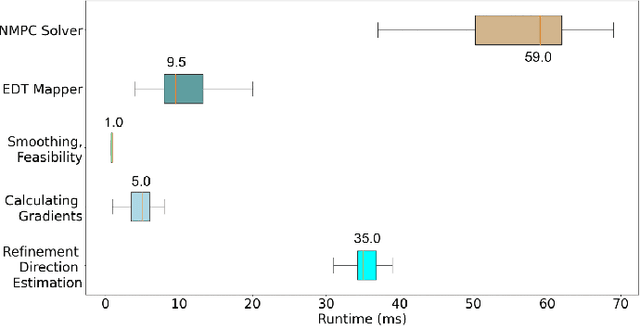
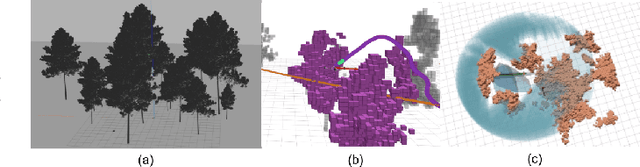
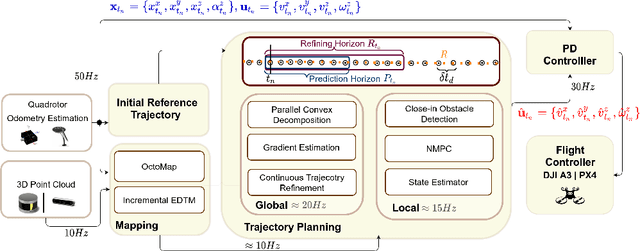
The goal of this paper is to develop a continuous optimization-based refinement of the reference trajectory to 'push it out' of the obstacle-occupied space in the global phase for Multi-rotor Aerial Vehicles in unknown environments. Our proposed approach comprises two planners: a global planner and a local planner. The global planner refines the initial reference trajectory when the trajectory goes either through an obstacle or near an obstacle and lets the local planner calculate a near-optimal control policy. The global planner comprises two convex programming approaches: the first one helps to refine the reference trajectory, and the second one helps to recover the reference trajectory if the first approach fails to refine. The global planner mainly focuses on real-time performance and obstacles avoidance, whereas the proposed formulation of the constrained nonlinear model predictive control-based local planner ensures safety, dynamic feasibility, and the reference trajectory tracking accuracy for low-speed maneuvers, provided that local and global planners have mean computation times 0.06s (15Hz) and 0.05s (20Hz), respectively, on an NVIDIA Jetson Xavier NX computer. The results of our experiment confirmed that, in cluttered environments, the proposed approach outperformed three other approaches: sampling-based pathfinding followed by trajectory generation, a local planner, and graph-based pathfinding followed by trajectory generation.
Joint IRS Location and Size Optimization in Multi-IRS Aided Two-Way Full-Duplex Communication Systems
Feb 23, 2022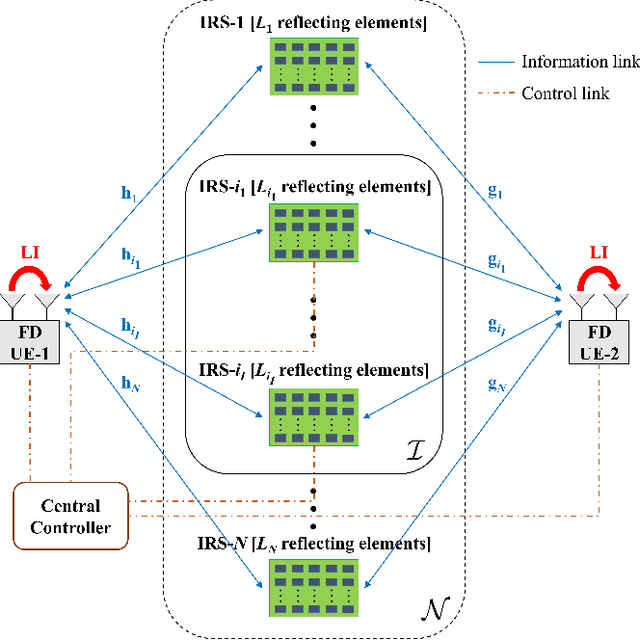
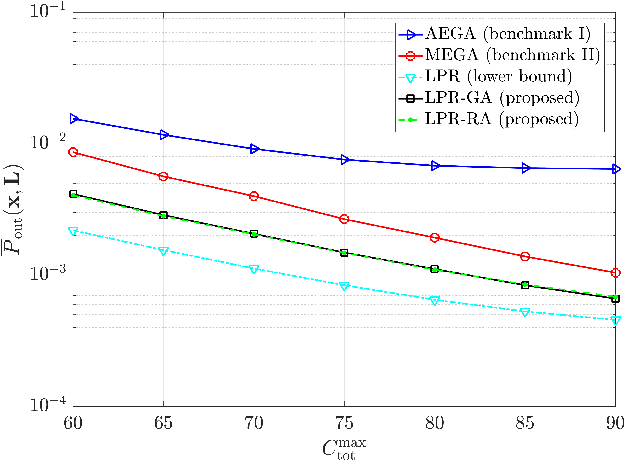
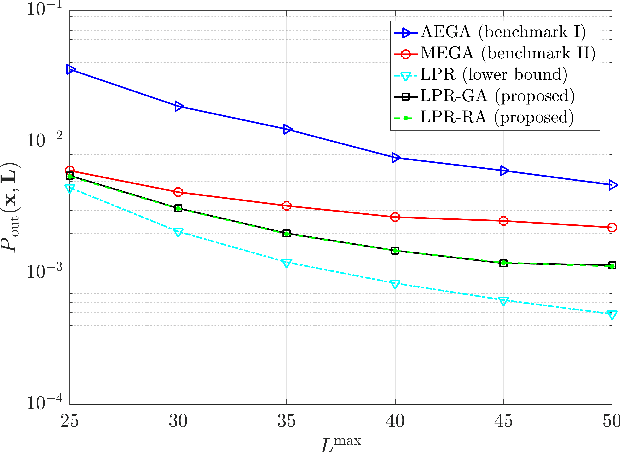
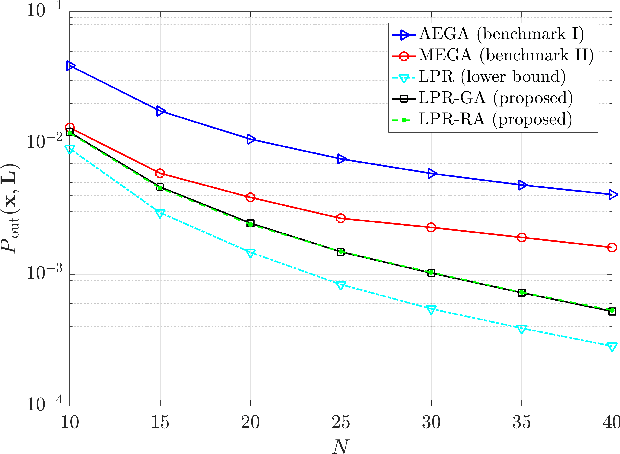
Intelligent reflecting surfaces (IRSs) have emerged as a promising wireless technology for the dynamic configuration and control of electromagnetic waves, thus creating a smart (programmable) radio environment. In this context, we study a multi-IRS assisted two-way communication system consisting of two users that employ full-duplex (FD) technology. More specifically, we deal with the joint IRS location and size (i.e., the number of reflecting elements) optimization in order to minimize an upper bound of system outage probability under various constraints, namely, minimum and maximum number of reflecting elements per IRS, maximum number of installed IRSs, maximum total number of reflecting elements (implicit bound on the signaling overhead) as well as maximum total IRS installation cost. First, the problem is formulated as a discrete optimization problem and, then, a theoretical proof of its NP-hardness is given. Moreover, we provide a lower bound on the optimum value by solving a linear-programming relaxation (LPR) problem. Subsequently, we design two polynomial-time algorithms, a deterministic greedy algorithm and a randomized approximation algorithm, based on the LPR solution. The former is a heuristic method that always computes a feasible solution for which (a posteriori) performance guarantee can be provided. The latter achieves an approximate solution, using randomized rounding, with provable (a priori) probabilistic guarantees on the performance. Furthermore, extensive numerical simulations demonstrate the superiority of the proposed algorithms compared to the baseline schemes. Finally, useful conclusions regarding the comparison between FD and conventional half-duplex (HD) systems are also drawn.
High Quality Streaming Speech Synthesis with Low, Sentence-Length-Independent Latency
Nov 17, 2021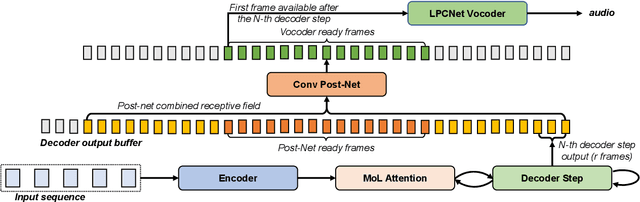
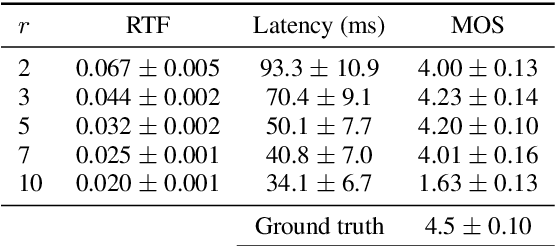
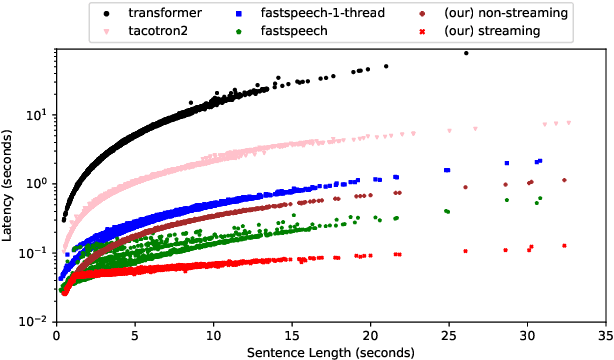
This paper presents an end-to-end text-to-speech system with low latency on a CPU, suitable for real-time applications. The system is composed of an autoregressive attention-based sequence-to-sequence acoustic model and the LPCNet vocoder for waveform generation. An acoustic model architecture that adopts modules from both the Tacotron 1 and 2 models is proposed, while stability is ensured by using a recently proposed purely location-based attention mechanism, suitable for arbitrary sentence length generation. During inference, the decoder is unrolled and acoustic feature generation is performed in a streaming manner, allowing for a nearly constant latency which is independent from the sentence length. Experimental results show that the acoustic model can produce feature sequences with minimal latency about 31 times faster than real-time on a computer CPU and 6.5 times on a mobile CPU, enabling it to meet the conditions required for real-time applications on both devices. The full end-to-end system can generate almost natural quality speech, which is verified by listening tests.
Leveraging wisdom of the crowds to improve consensus among radiologists by real time, blinded collaborations on a digital swarm platform
Jun 26, 2021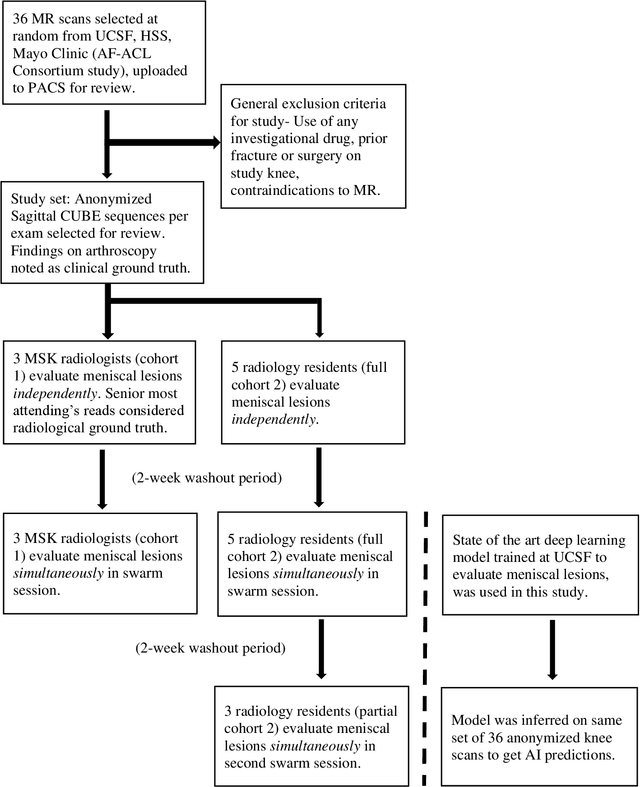
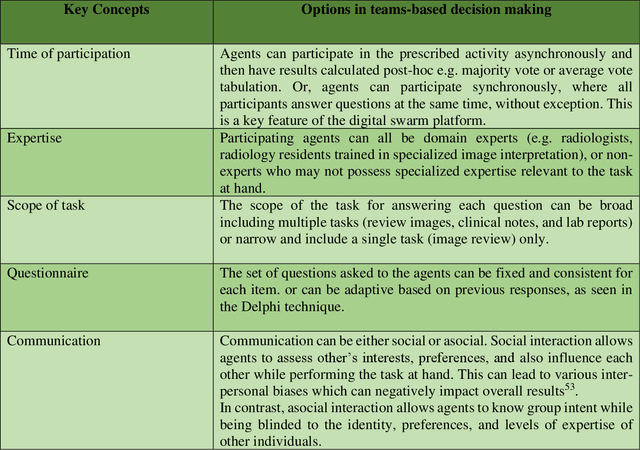
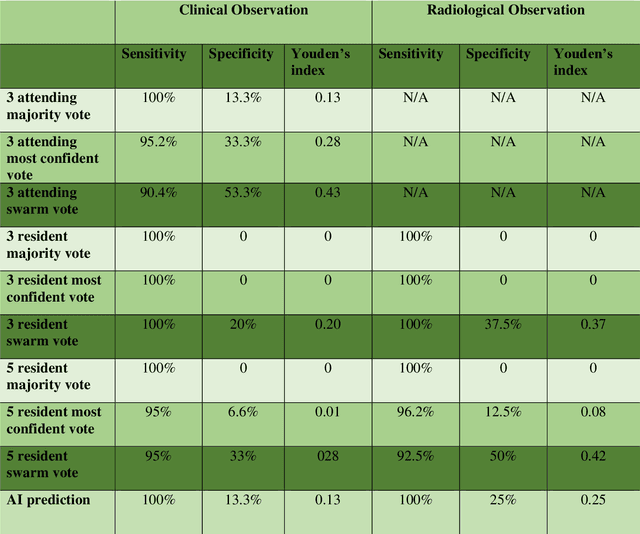
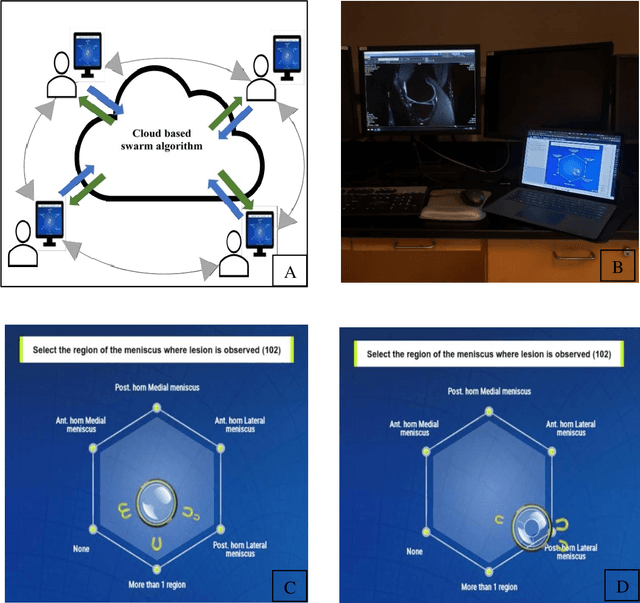
Radiologists today play a key role in making diagnostic decisions and labeling images for training A.I. algorithms. Low inter-reader reliability (IRR) can be seen between experts when interpreting challenging cases. While teams-based decisions are known to outperform individual decisions, inter-personal biases often creep up in group interactions which limit non-dominant participants from expressing true opinions. To overcome the dual problems of low consensus and inter-personal bias, we explored a solution modeled on biological swarms of bees. Two separate cohorts; three radiologists and five radiology residents collaborated on a digital swarm platform in real time and in a blinded fashion, grading meniscal lesions on knee MR exams. These consensus votes were benchmarked against clinical (arthroscopy) and radiological (senior-most radiologist) observations. The IRR of the consensus votes was compared to the IRR of the majority and most confident votes of the two cohorts.The radiologist cohort saw an improvement of 23% in IRR of swarm votes over majority vote. Similar improvement of 23% in IRR in 3-resident swarm votes over majority vote, was observed. The 5-resident swarm had an even higher improvement of 32% in IRR over majority vote. Swarm consensus votes also improved specificity by up to 50%. The swarm consensus votes outperformed individual and majority vote decisions in both the radiologists and resident cohorts. The 5-resident swarm had higher IRR than 3-resident swarm indicating positive effect of increased swarm size. The attending and resident swarms also outperformed predictions from a state-of-the-art A.I. algorithm. Utilizing a digital swarm platform improved agreement and allows participants to express judgement free intent, resulting in superior clinical performance and robust A.I. training labels.
Evaluation and Comparison of Deep Learning Methods for Pavement Crack Identification with Visual Images
Dec 20, 2021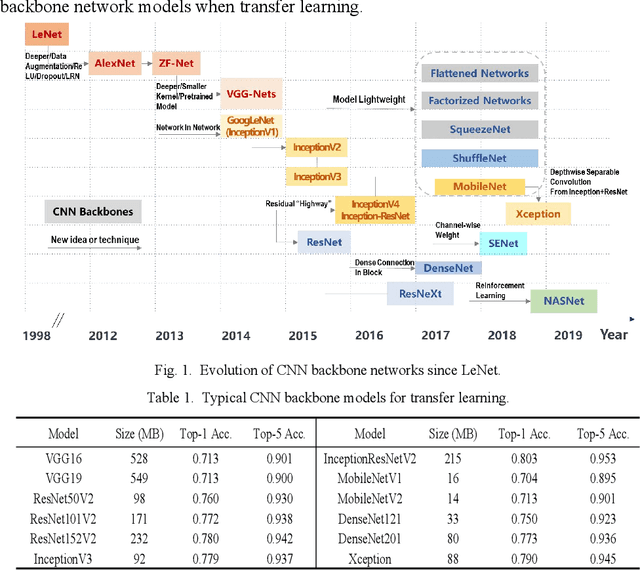
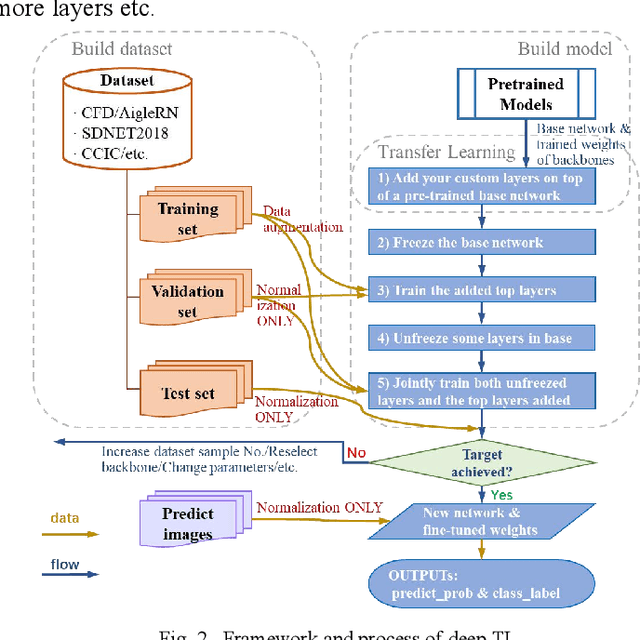

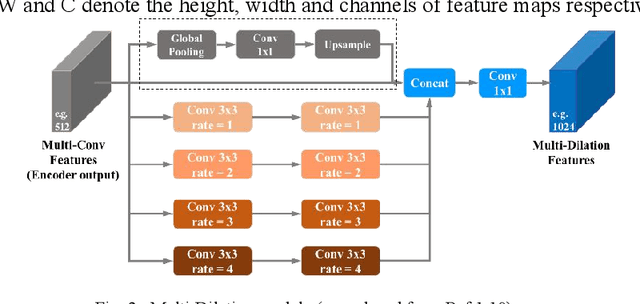
Compared with contact detection techniques, pavement crack identification with visual images via deep learning algorithms has the advantages of not being limited by the material of object to be detected, fast speed and low cost. The fundamental frameworks and typical model architectures of transfer learning (TL), encoder-decoder (ED), generative adversarial networks (GAN), and their common modules were first reviewed, and then the evolution of convolutional neural network (CNN) backbone models and GAN models were summarized. The crack classification, segmentation performance, and effect were tested on the SDNET2018 and CFD public data sets. In the aspect of patch sample classification, the fine-tuned TL models can be equivalent to or even slightly better than the ED models in accuracy, and the predicting time is faster; In the aspect of accurate crack location, both ED and GAN algorithms can achieve pixel-level segmentation and is expected to be detected in real time on low computing power platform. Furthermore, a weakly supervised learning framework of combined TL-SSGAN and its performance enhancement measures are proposed, which can maintain comparable crack identification performance with that of the supervised learning, while greatly reducing the number of labeled samples required.