 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Identification of Flux Rope Orientation via Neural Networks
Feb 21, 2022
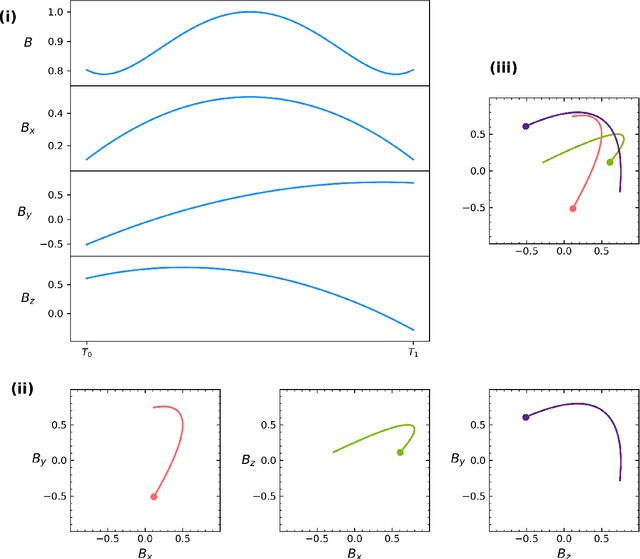

Geomagnetic disturbance forecasting is based on the identification of solar wind structures and accurate determination of their magnetic field orientation. For nowcasting activities, this is currently a tedious and manual process. Focusing on the main driver of geomagnetic disturbances, the twisted internal magnetic field of interplanetary coronal mass ejections (ICMEs), we explore a convolutional neural network's (CNN) ability to predict the embedded magnetic flux rope's orientation once it has been identified from in situ solar wind observations. Our work uses CNNs trained with magnetic field vectors from analytical flux rope data. The simulated flux ropes span many possible spacecraft trajectories and flux rope orientations. We train CNNs first with full duration flux ropes and then again with partial duration flux ropes. The former provides us with a baseline of how well CNNs can predict flux rope orientation while the latter provides insights into real-time forecasting by exploring how accuracy is affected by percentage of flux rope observed. The process of casting the physics problem as a machine learning problem is discussed as well as the impacts of different factors on prediction accuracy such as flux rope fluctuations and different neural network topologies. Finally, results from evaluating the trained network against observed ICMEs from Wind during 1995-2015 are presented.
LF-VIO: A Visual-Inertial-Odometry Framework for Large Field-of-View Cameras with Negative Plane
Feb 25, 2022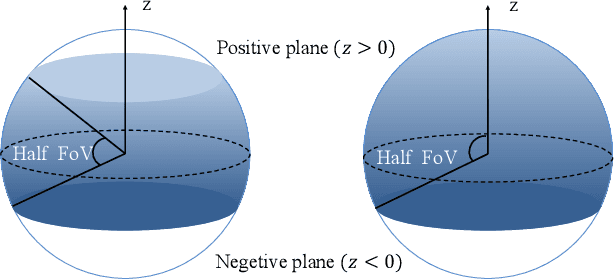
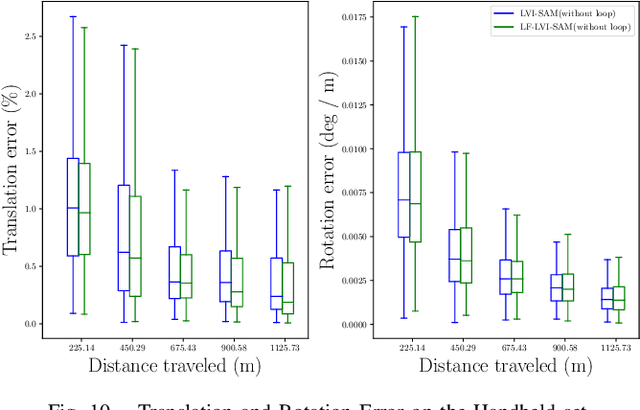
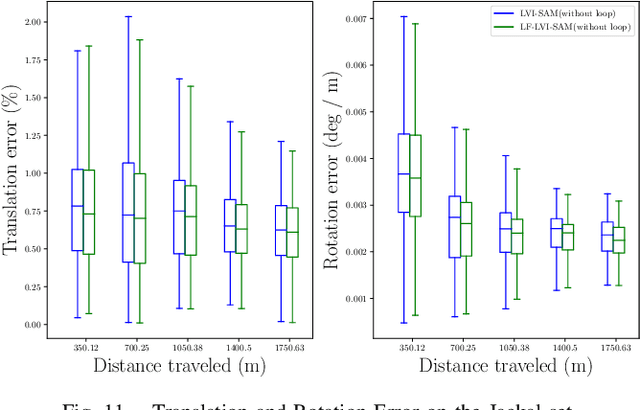

Visual-inertial-odometry has attracted extensive attention in the field of autonomous driving and robotics. The size of Field of View (FoV) plays an important role in Visual-Odometry (VO) and Visual-Inertial-Odometry (VIO), as a large FoV enables to perceive a wide range of surrounding scene elements and features. However, when the field of the camera reaches the negative half plane, one cannot simply use [u,v,1]^T to represent the image feature points anymore. To tackle this issue, we propose LF-VIO, a real-time VIO framework for cameras with extremely large FoV. We leverage a three-dimensional vector with unit length to represent feature points, and design a series of algorithms to overcome this challenge. To address the scarcity of panoramic visual odometry datasets with ground-truth location and pose, we present the PALVIO dataset, collected with a Panoramic Annular Lens (PAL) system with an entire FoV of 360x(40-120) degrees and an IMU sensor. With a comprehensive variety of experiments, the proposed LF-VIO is verified on both the established PALVIO benchmark and a public fisheye camera dataset with a FoV of 360x(0-93.5) degrees. LF-VIO outperforms state-of-the-art visual-inertial-odometry methods. Our dataset and code are made publicly available at https://github.com/flysoaryun/LF-VIO
Efficient Policy Space Response Oracles
Feb 17, 2022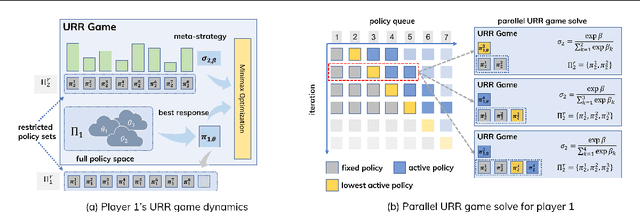
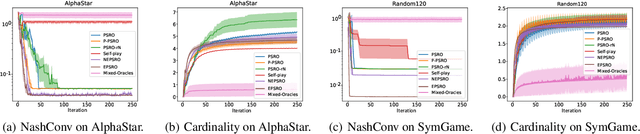
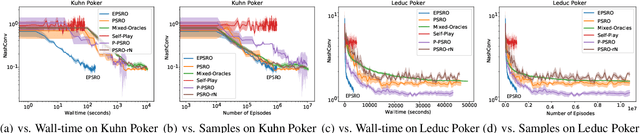
Policy Space Response Oracle method (PSRO) provides a general solution to Nash equilibrium in two-player zero-sum games but suffers from two problems: (1) the computation inefficiency due to consistently evaluating current populations by simulations; and (2) the exploration inefficiency due to learning best responses against a fixed meta-strategy at each iteration. In this work, we propose Efficient PSRO (EPSRO) that largely improves the efficiency of the above two steps. Central to our development is the newly-introduced subroutine of minimax optimization on unrestricted-restricted (URR) games. By solving URR at each step, one can evaluate the current game and compute the best response in one forward pass with no need for game simulations. Theoretically, we prove that the solution procedures of EPSRO offer a monotonic improvement on exploitability. Moreover, a desirable property of EPSRO is that it is parallelizable, this allows for efficient exploration in the policy space that induces behavioral diversity. We test EPSRO on three classes of games and report a 50x speedup in wall-time, 10x data efficiency, and similar exploitability as existing PSRO methods on Kuhn and Leduc Poker games.
Machine Learning Empowered Intelligent Data Center Networking: A Survey
Mar 01, 2022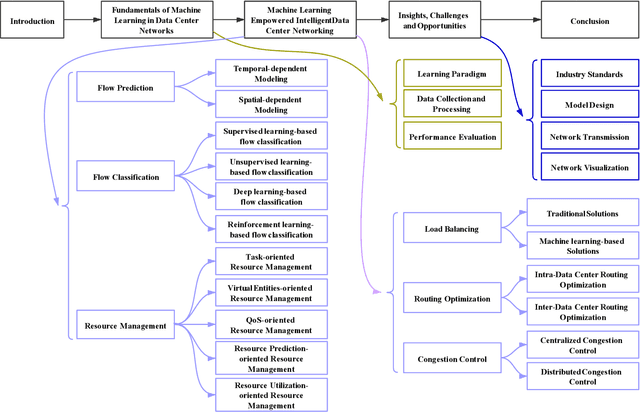
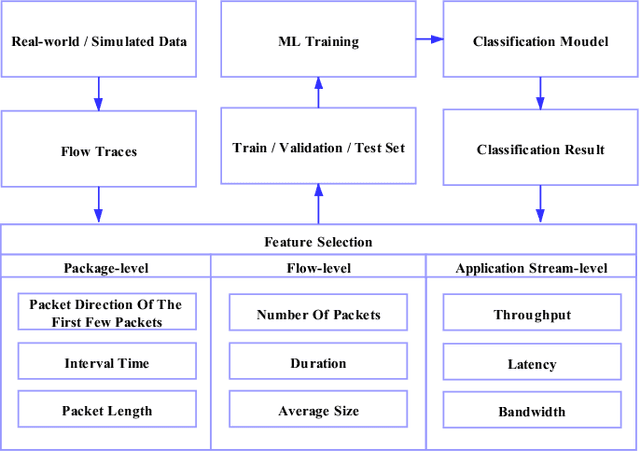
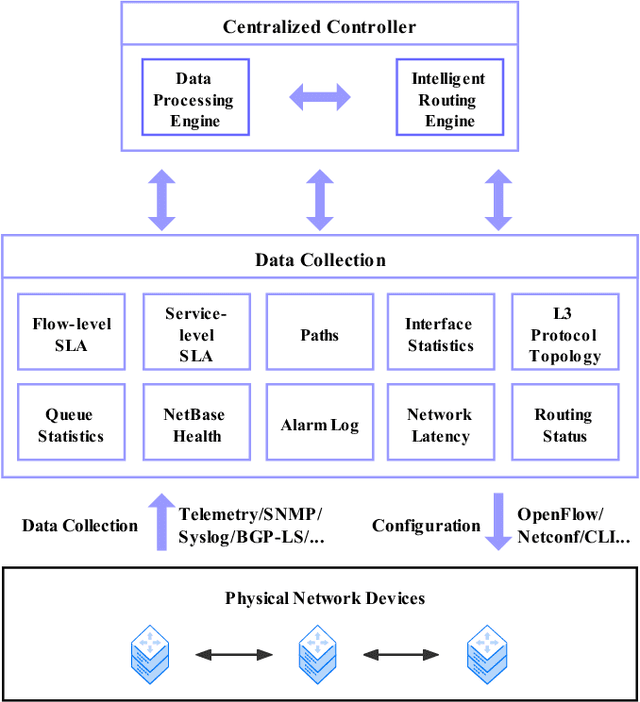
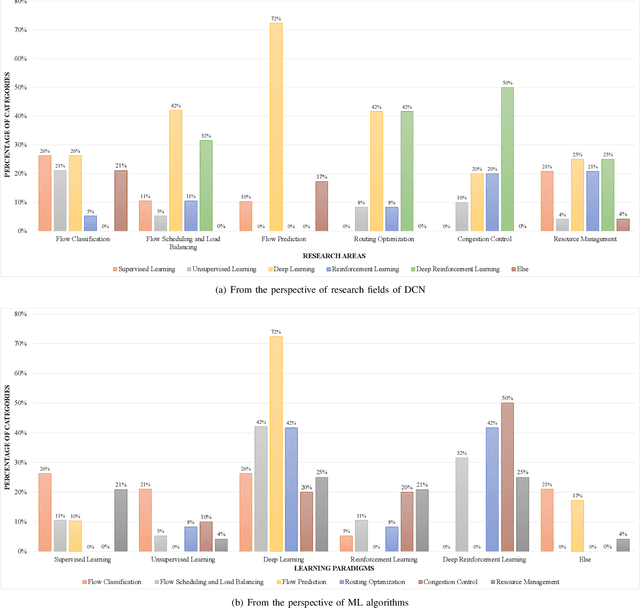
To support the needs of ever-growing cloud-based services, the number of servers and network devices in data centers is increasing exponentially, which in turn results in high complexities and difficulties in network optimization. To address these challenges, both academia and industry turn to artificial intelligence technology to realize network intelligence. To this end, a considerable number of novel and creative machine learning-based (ML-based) research works have been put forward in recent few years. Nevertheless, there are still enormous challenges faced by the intelligent optimization of data center networks (DCNs), especially in the scenario of online real-time dynamic processing of massive heterogeneous services and traffic data. To best of our knowledge, there is a lack of systematic and original comprehensively investigations with in-depth analysis on intelligent DCN. To this end, in this paper, we comprehensively investigate the application of machine learning to data center networking, and provide a general overview and in-depth analysis of the recent works, covering flow prediction, flow classification, load balancing, resource management, routing optimization, and congestion control. In order to provide a multi-dimensional and multi-perspective comparison of various solutions, we design a quality assessment criteria called REBEL-3S to impartially measure the strengths and weaknesses of these research works. Moreover, we also present unique insights into the technology evolution of the fusion of data center network and machine learning, together with some challenges and potential future research opportunities.
SWIM: Selective Write-Verify for Computing-in-Memory Neural Accelerators
Feb 17, 2022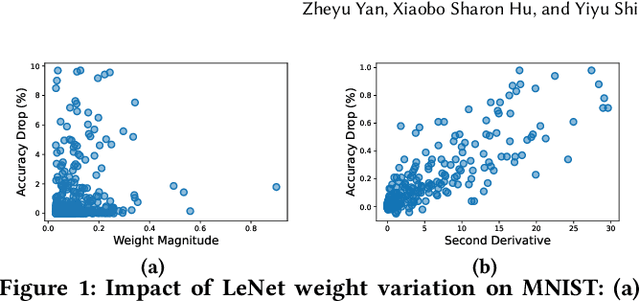
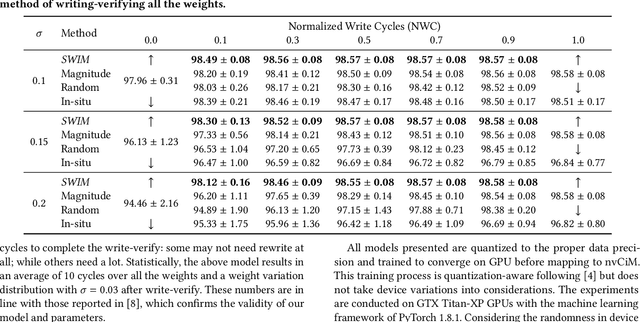
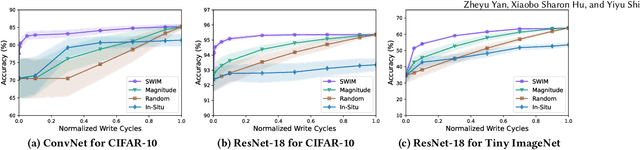
Computing-in-Memory architectures based on non-volatile emerging memories have demonstrated great potential for deep neural network (DNN) acceleration thanks to their high energy efficiency. However, these emerging devices can suffer from significant variations during the mapping process i.e., programming weights to the devices), and if left undealt with, can cause significant accuracy degradation. The non-ideality of weight mapping can be compensated by iterative programming with a write-verify scheme, i.e., reading the conductance and rewriting if necessary. In all existing works, such a practice is applied to every single weight of a DNN as it is being mapped, which requires extensive programming time. In this work, we show that it is only necessary to select a small portion of the weights for write-verify to maintain the DNN accuracy, thus achieving significant speedup. We further introduce a second derivative based technique SWIM, which only requires a single pass of forward and backpropagation, to efficiently select the weights that need write-verify. Experimental results on various DNN architectures for different datasets show that SWIM can achieve up to 10x programming speedup compared with conventional full-blown write-verify while attaining a comparable accuracy.
Contrastive Divergence Learning is a Time Reversal Adversarial Game
Dec 09, 2020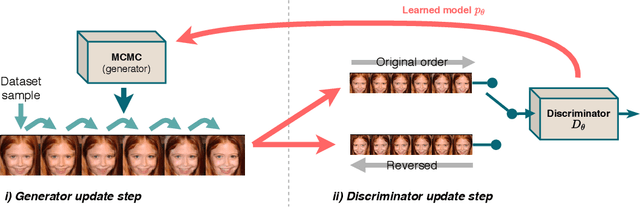
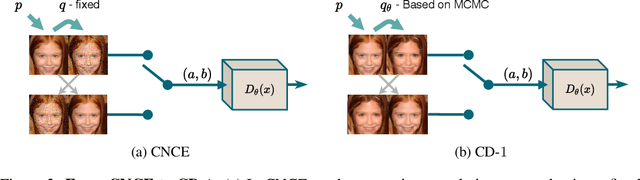
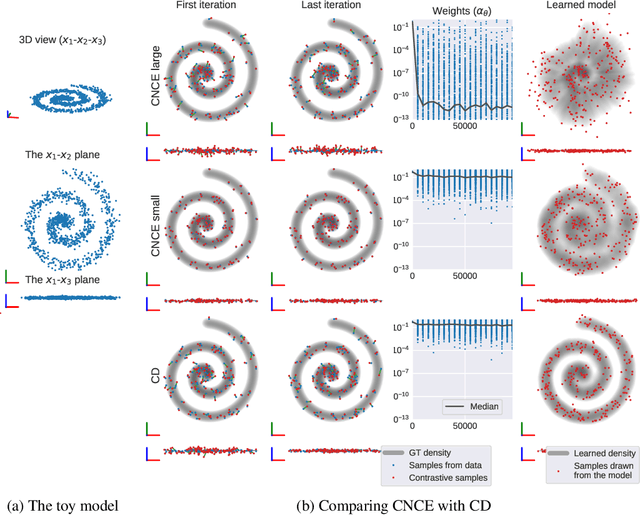
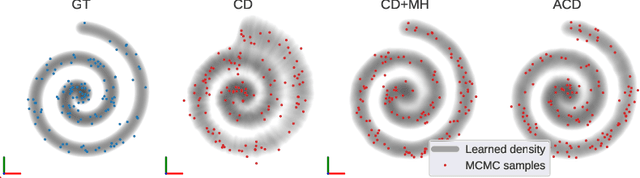
Contrastive divergence (CD) learning is a classical method for fitting unnormalized statistical models to data samples. Despite its wide-spread use, the convergence properties of this algorithm are still not well understood. The main source of difficulty is an unjustified approximation which has been used to derive the gradient of the loss. In this paper, we present an alternative derivation of CD that does not require any approximation and sheds new light on the objective that is actually being optimized by the algorithm. Specifically, we show that CD is an adversarial learning procedure, where a discriminator attempts to classify whether a Markov chain generated from the model has been time-reversed. Thus, although predating generative adversarial networks (GANs) by more than a decade, CD is, in fact, closely related to these techniques. Our derivation settles well with previous observations, which have concluded that CD's update steps cannot be expressed as the gradients of any fixed objective function. In addition, as a byproduct, our derivation reveals a simple correction that can be used as an alternative to Metropolis-Hastings rejection, which is required when the underlying Markov chain is inexact (e.g. when using Langevin dynamics with a large step).
Neural Datalog Through Time: Informed Temporal Modeling via Logical Specification
Jun 30, 2020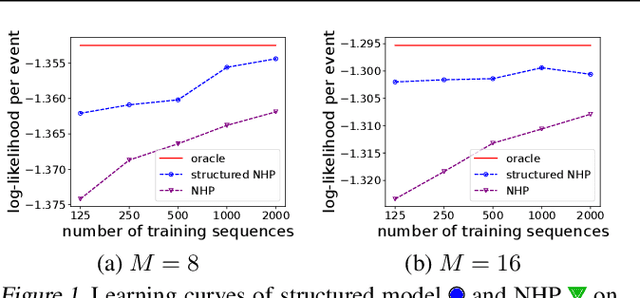
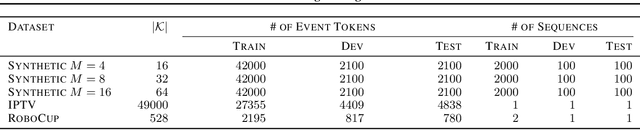
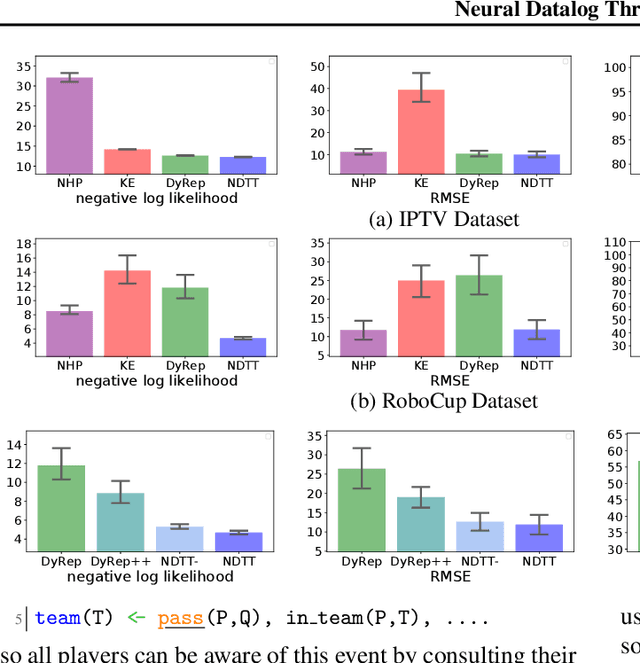
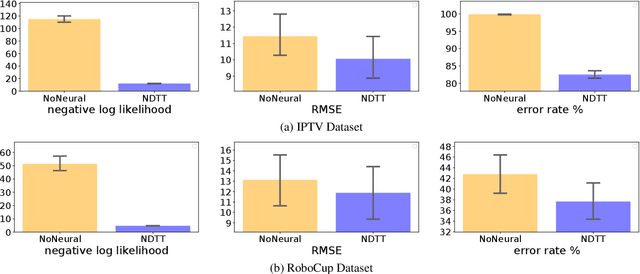
Learning how to predict future events from patterns of past events is difficult when the set of possible event types is large. Training an unrestricted neural model might overfit to spurious patterns. To exploit domain-specific knowledge of how past events might affect an event's present probability, we propose using a temporal deductive database to track structured facts over time. Rules serve to prove facts from other facts and from past events. Each fact has a time-varying state---a vector computed by a neural net whose topology is determined by the fact's provenance, including its experience of past events. The possible event types at any time are given by special facts, whose probabilities are neurally modeled alongside their states. In both synthetic and real-world domains, we show that neural probabilistic models derived from concise Datalog programs improve prediction by encoding appropriate domain knowledge in their architecture.
Expert Aggregation for Financial Forecasting
Dec 01, 2021
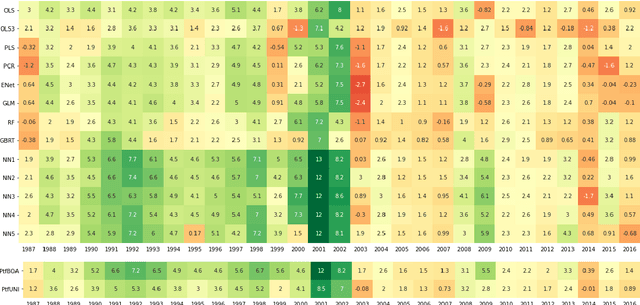
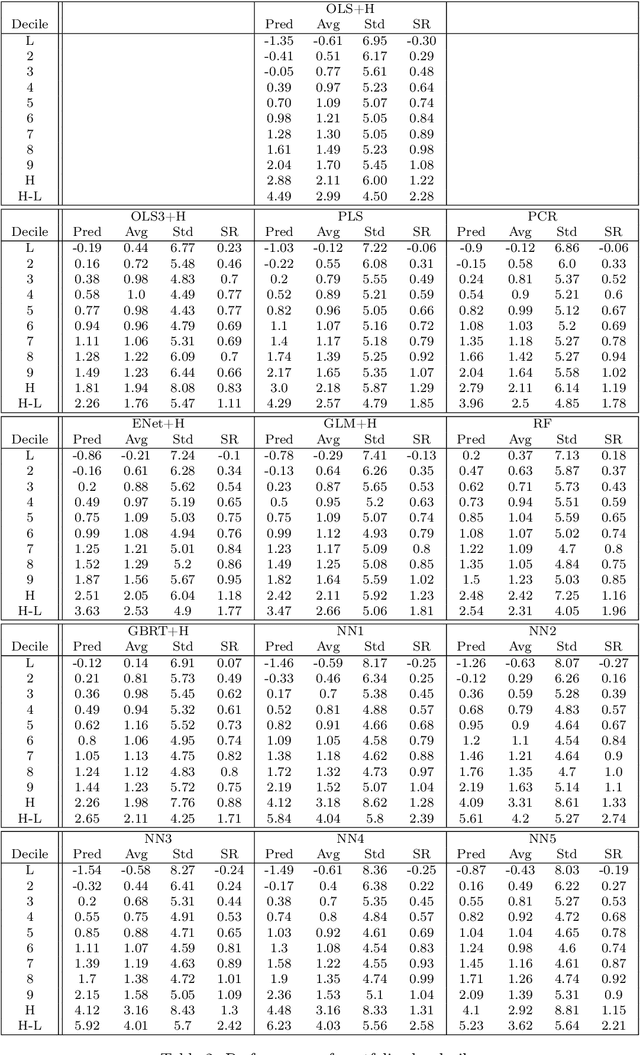
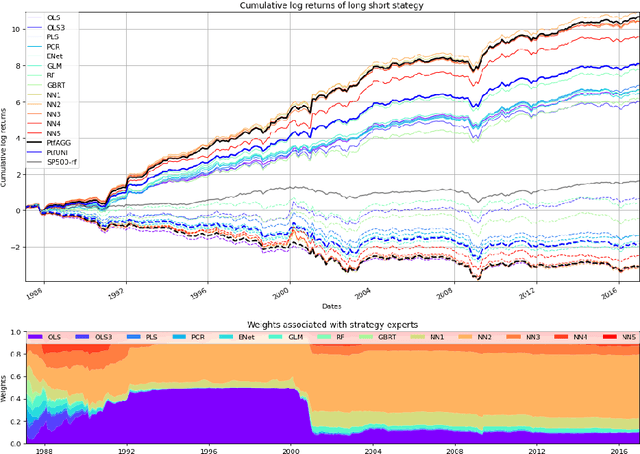
Machine learning algorithms dedicated to financial time series forecasting have gained a lot of interest over the last few years. One difficulty lies in the choice between several algorithms, as their estimation accuracy may be unstable through time. In this paper, we propose to apply an online aggregation-based forecasting model combining several machine learning techniques to build a portfolio which dynamically adapts itself to market conditions. We apply this aggregation technique to the construction of a long-short-portfolio of individual stocks ranked on their financial characteristics and we demonstrate how aggregation outperforms single algorithms both in terms of performances and of stability.
Exploring Low-Cost Transformer Model Compression for Large-Scale Commercial Reply Suggestions
Nov 27, 2021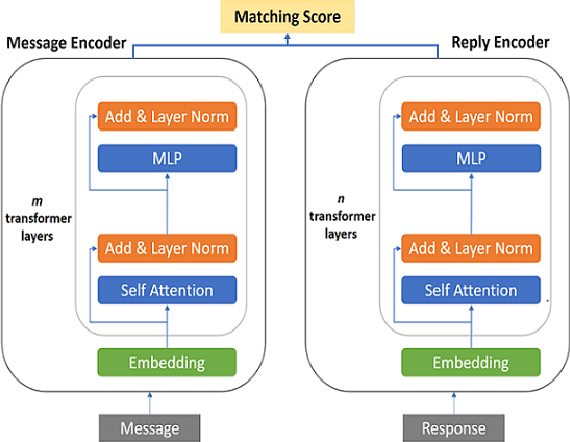
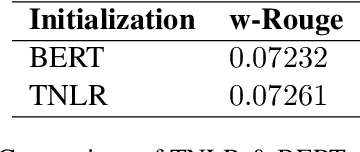
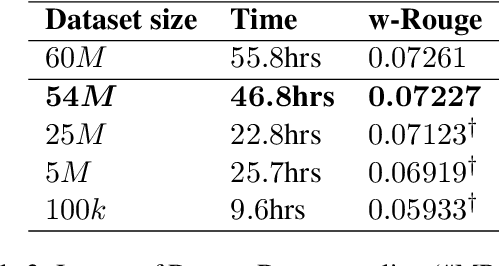
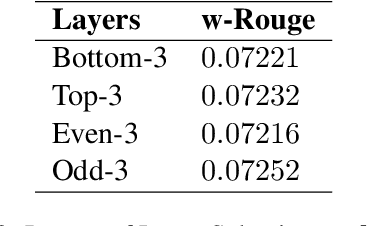
Fine-tuning pre-trained language models improves the quality of commercial reply suggestion systems, but at the cost of unsustainable training times. Popular training time reduction approaches are resource intensive, thus we explore low-cost model compression techniques like Layer Dropping and Layer Freezing. We demonstrate the efficacy of these techniques in large-data scenarios, enabling the training time reduction for a commercial email reply suggestion system by 42%, without affecting the model relevance or user engagement. We further study the robustness of these techniques to pre-trained model and dataset size ablation, and share several insights and recommendations for commercial applications.
Bellman Meets Hawkes: Model-Based Reinforcement Learning via Temporal Point Processes
Jan 29, 2022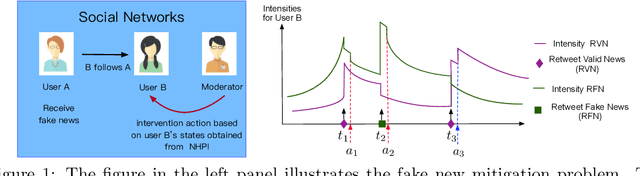
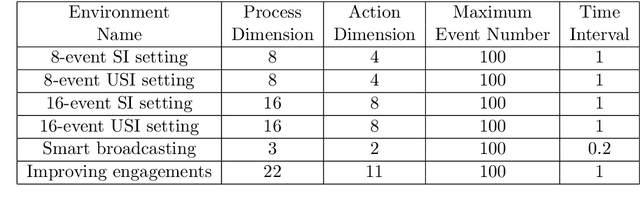
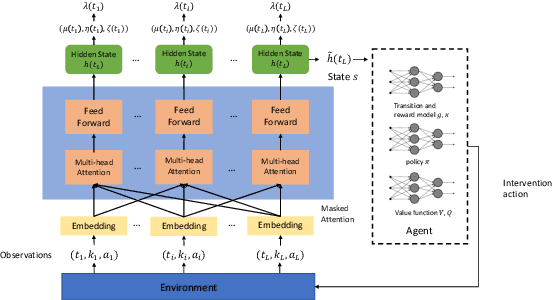
We consider a sequential decision making problem where the agent faces the environment characterized by the stochastic discrete events and seeks an optimal intervention policy such that its long-term reward is maximized. This problem exists ubiquitously in social media, finance and health informatics but is rarely investigated by the conventional research in reinforcement learning. To this end, we present a novel framework of the model-based reinforcement learning where the agent's actions and observations are asynchronous stochastic discrete events occurring in continuous-time. We model the dynamics of the environment by Hawkes process with external intervention control term and develop an algorithm to embed such process in the Bellman equation which guides the direction of the value gradient. We demonstrate the superiority of our method in both synthetic simulator and real-world problem.