 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Assessing generalisability of deep learning-based polyp detection and segmentation methods through a computer vision challenge
Feb 24, 2022
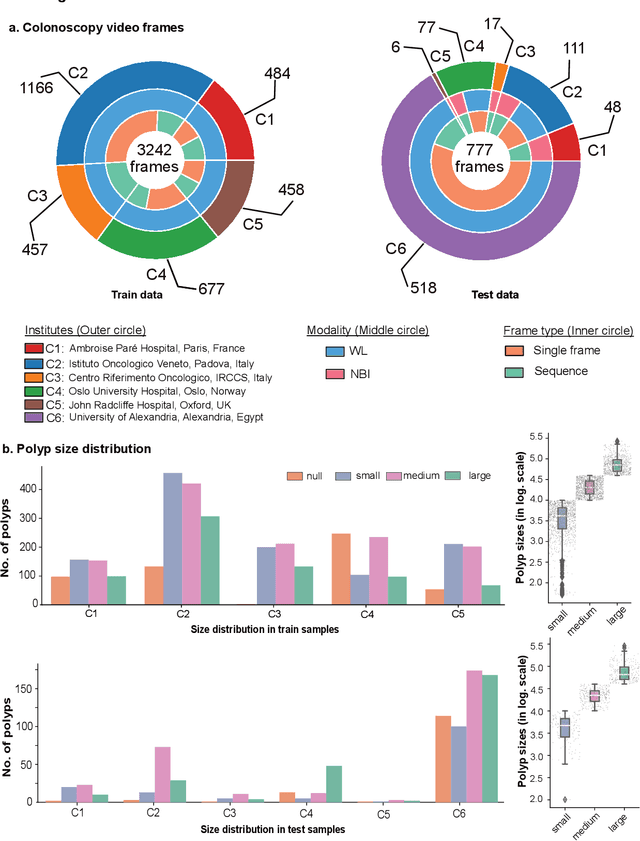
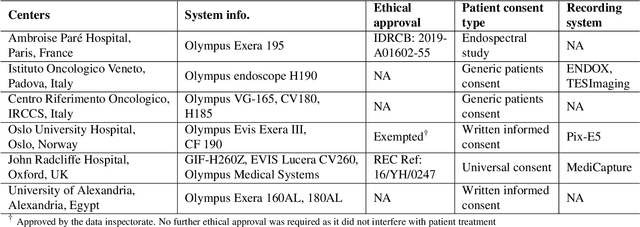
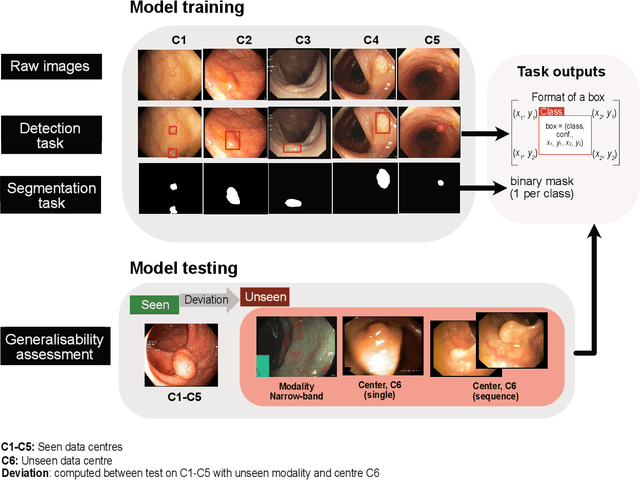
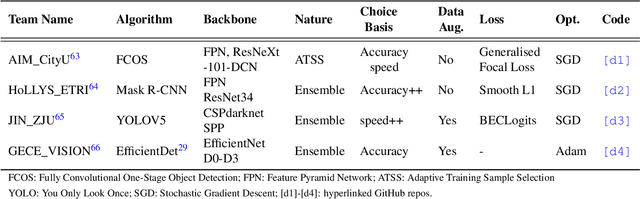
Polyps are well-known cancer precursors identified by colonoscopy. However, variability in their size, location, and surface largely affect identification, localisation, and characterisation. Moreover, colonoscopic surveillance and removal of polyps (referred to as polypectomy ) are highly operator-dependent procedures. There exist a high missed detection rate and incomplete removal of colonic polyps due to their variable nature, the difficulties to delineate the abnormality, the high recurrence rates, and the anatomical topography of the colon. There have been several developments in realising automated methods for both detection and segmentation of these polyps using machine learning. However, the major drawback in most of these methods is their ability to generalise to out-of-sample unseen datasets that come from different centres, modalities and acquisition systems. To test this hypothesis rigorously we curated a multi-centre and multi-population dataset acquired from multiple colonoscopy systems and challenged teams comprising machine learning experts to develop robust automated detection and segmentation methods as part of our crowd-sourcing Endoscopic computer vision challenge (EndoCV) 2021. In this paper, we analyse the detection results of the four top (among seven) teams and the segmentation results of the five top teams (among 16). Our analyses demonstrate that the top-ranking teams concentrated on accuracy (i.e., accuracy > 80% on overall Dice score on different validation sets) over real-time performance required for clinical applicability. We further dissect the methods and provide an experiment-based hypothesis that reveals the need for improved generalisability to tackle diversity present in multi-centre datasets.
High-recall causal discovery for autocorrelated time series with latent confounders
Jul 03, 2020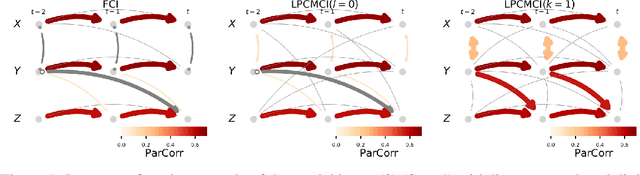
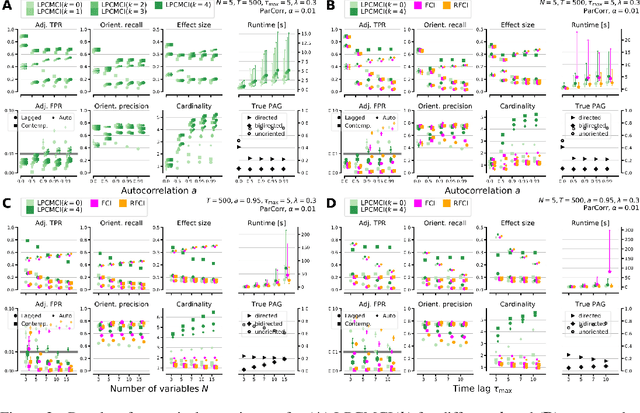
We present a new method for linear and nonlinear, lagged and contemporaneous constraint-based causal discovery from observational time series in the presence of latent confounders. We show that existing causal discovery methods such as FCI and variants suffer from low recall in the autocorrelated time series case and identify low effect size of conditional independence tests as the main reason. Information-theoretical arguments show that effect size can often be increased if causal parents are included in the conditioning sets. To identify parents early on, we suggest an iterative procedure that utilizes novel orientation rules to determine ancestral relationships already during the edge removal phase. We prove that the method is order-independent, and sound and complete in the oracle case. Extensive simulation studies for different numbers of variables, time lags, sample sizes, and further cases demonstrate that our method indeed achieves much higher recall than existing methods while keeping false positives at the desired level. This performance gain grows with stronger autocorrelation. Our method also covers causal discovery for non-time series data as a special case. We provide Python code for all methods involved in the simulation studies.
Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval
Apr 01, 2021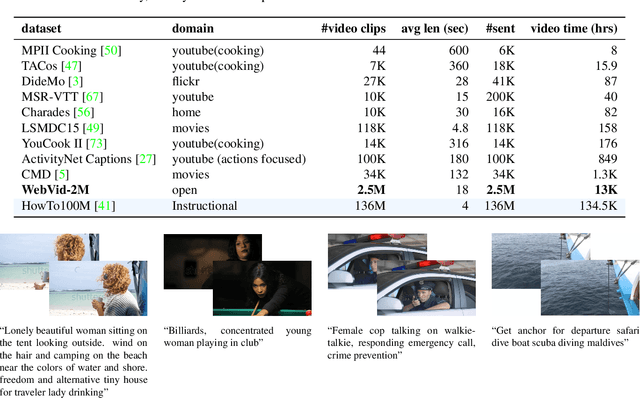
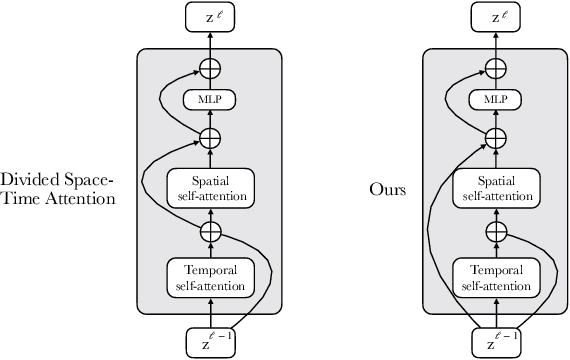
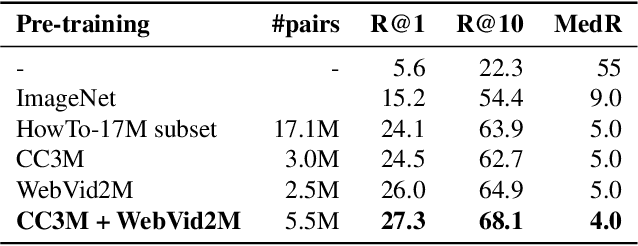
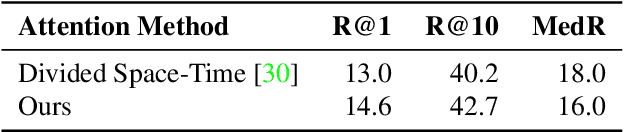
Our objective in this work is video-text retrieval - in particular a joint embedding that enables efficient text-to-video retrieval. The challenges in this area include the design of the visual architecture and the nature of the training data, in that the available large scale video-text training datasets, such as HowTo100M, are noisy and hence competitive performance is achieved only at scale through large amounts of compute. We address both these challenges in this paper. We propose an end-to-end trainable model that is designed to take advantage of both large-scale image and video captioning datasets. Our model is an adaptation and extension of the recent ViT and Timesformer architectures, and consists of attention in both space and time. The model is flexible and can be trained on both image and video text datasets, either independently or in conjunction. It is trained with a curriculum learning schedule that begins by treating images as 'frozen' snapshots of video, and then gradually learns to attend to increasing temporal context when trained on video datasets. We also provide a new video-text pretraining dataset WebVid-2M, comprised of over two million videos with weak captions scraped from the internet. Despite training on datasets that are an order of magnitude smaller, we show that this approach yields state-of-the-art results on standard downstream video-retrieval benchmarks including MSR-VTT, MSVD, DiDeMo and LSMDC.
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 08, 2022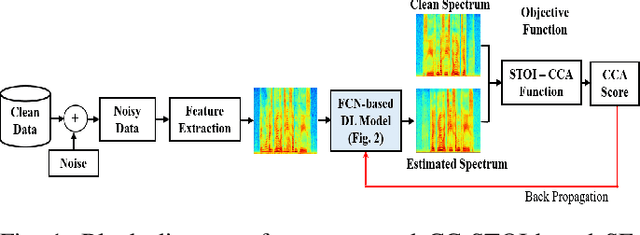
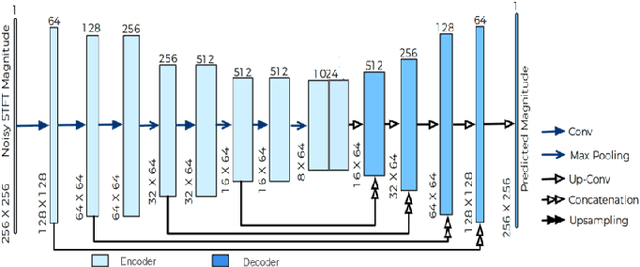
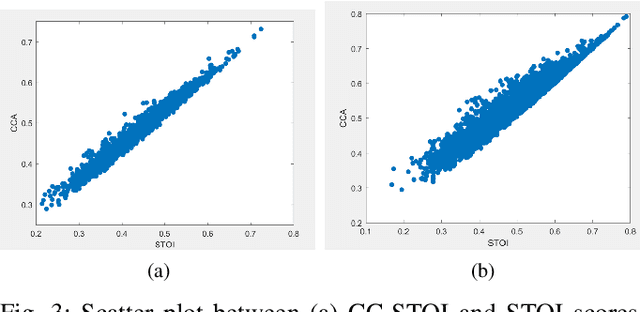
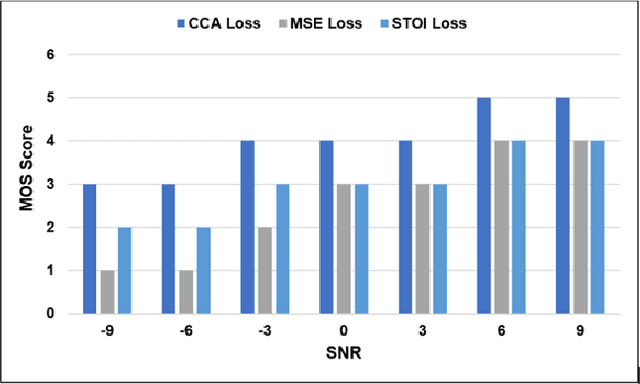
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
Pattern Recognition and Event Detection on IoT Data-streams
Mar 02, 2022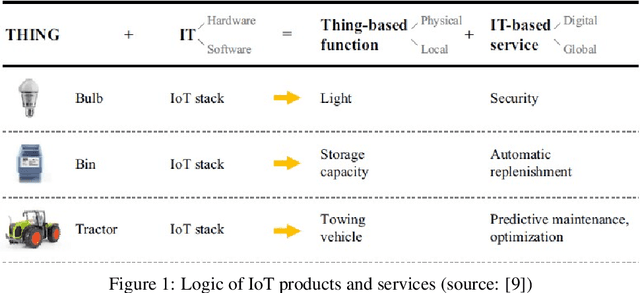
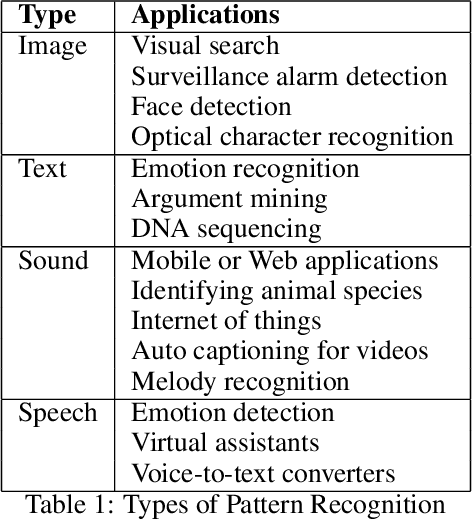

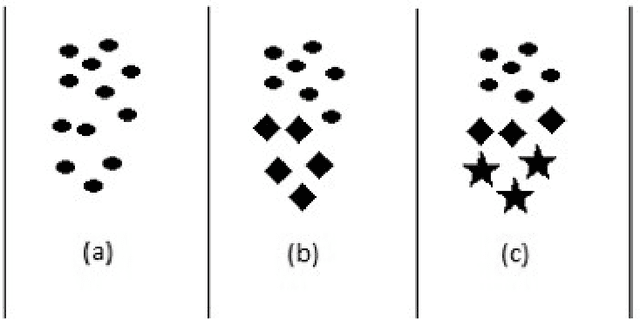
Big data streams are possibly one of the most essential underlying notions. However, data streams are often challenging to handle owing to their rapid pace and limited information lifetime. It is difficult to collect and communicate stream samples while storing, transmitting and computing a function across the whole stream or even a large segment of it. In answer to this research issue, many streaming-specific solutions were developed. Stream techniques imply a limited capacity of one or more resources such as computing power and memory, as well as time or accuracy limits. Reservoir sampling algorithms choose and store results that are probabilistically significant. A weighted random sampling approach using a generalised sampling algorithmic framework to detect unique events is the key research goal of this work. Briefly, a gradually developed estimate of the joint stream distribution across all feasible components keeps k stream elements judged representative for the full stream. Once estimate confidence is high, k samples are chosen evenly. The complexity is O(min(k,n-k)), where n is the number of items inspected. Due to the fact that events are usually considered outliers, it is sufficient to extract element patterns and push them to an alternate version of k-means as proposed here. The suggested technique calculates the sum of squared errors (SSE) for each cluster, and this is utilised not only as a measure of convergence, but also as a quantification and an indirect assessment of the element distribution's approximation accuracy. This clustering enables for the detection of outliers in the stream based on their distance from the usual event centroids. The findings reveal that weighted sampling and res-means outperform typical approaches for stream event identification. Detected events are shown as knowledge graphs, along with typical clusters of events.
Every time I fire a conversational designer, the performance of the dialog system goes down
Sep 27, 2021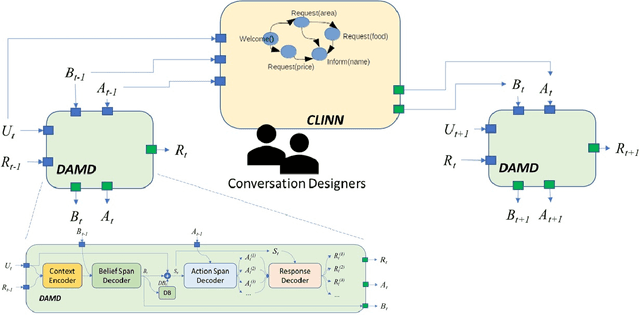
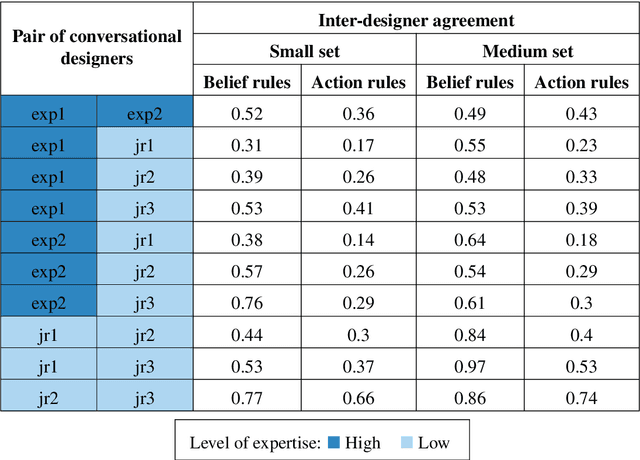
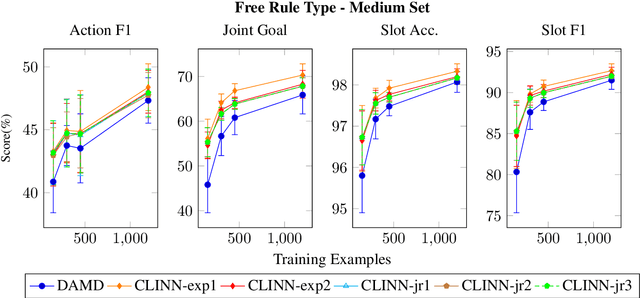
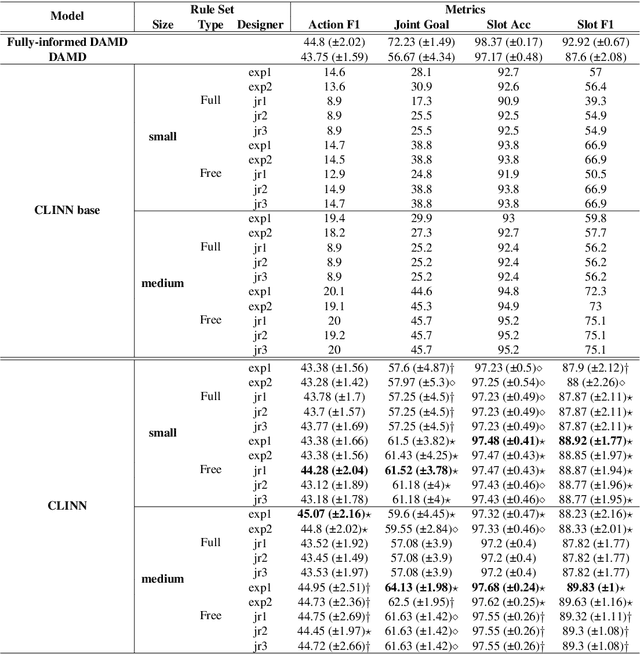
Incorporating explicit domain knowledge into neural-based task-oriented dialogue systems is an effective way to reduce the need of large sets of annotated dialogues. In this paper, we investigate how the use of explicit domain knowledge of conversational designers affects the performance of neural-based dialogue systems. To support this investigation, we propose the Conversational-Logic-Injection-in-Neural-Network system (CLINN) where explicit knowledge is coded in semi-logical rules. By using CLINN, we evaluated semi-logical rules produced by a team of differently skilled conversational designers. We experimented with the Restaurant topic of the MultiWOZ dataset. Results show that external knowledge is extremely important for reducing the need of annotated examples for conversational systems. In fact, rules from conversational designers used in CLINN significantly outperform a state-of-the-art neural-based dialogue system.
Deconstructing Distributions: A Pointwise Framework of Learning
Feb 20, 2022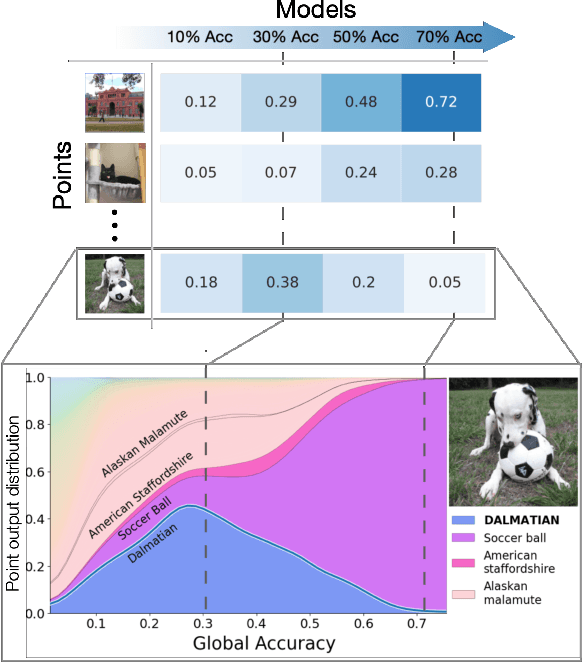

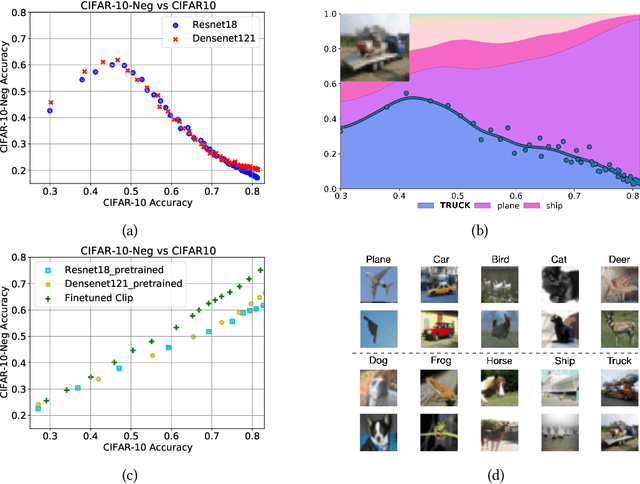

In machine learning, we traditionally evaluate the performance of a single model, averaged over a collection of test inputs. In this work, we propose a new approach: we measure the performance of a collection of models when evaluated on a $\textit{single input point}$. Specifically, we study a point's $\textit{profile}$: the relationship between models' average performance on the test distribution and their pointwise performance on this individual point. We find that profiles can yield new insights into the structure of both models and data -- in and out-of-distribution. For example, we empirically show that real data distributions consist of points with qualitatively different profiles. On one hand, there are "compatible" points with strong correlation between the pointwise and average performance. On the other hand, there are points with weak and even $\textit{negative}$ correlation: cases where improving overall model accuracy actually $\textit{hurts}$ performance on these inputs. We prove that these experimental observations are inconsistent with the predictions of several simplified models of learning proposed in prior work. As an application, we use profiles to construct a dataset we call CIFAR-10-NEG: a subset of CINIC-10 such that for standard models, accuracy on CIFAR-10-NEG is $\textit{negatively correlated}$ with accuracy on CIFAR-10 test. This illustrates, for the first time, an OOD dataset that completely inverts "accuracy-on-the-line" (Miller, Taori, Raghunathan, Sagawa, Koh, Shankar, Liang, Carmon, and Schmidt 2021)
The Lifecycle of a Statistical Model: Model Failure Detection, Identification, and Refitting
Feb 08, 2022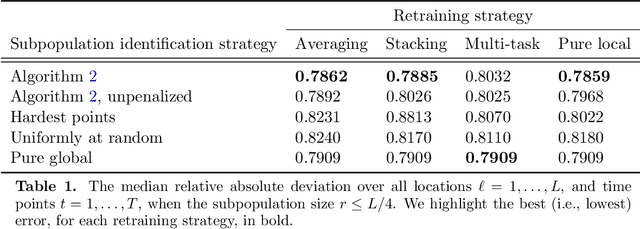
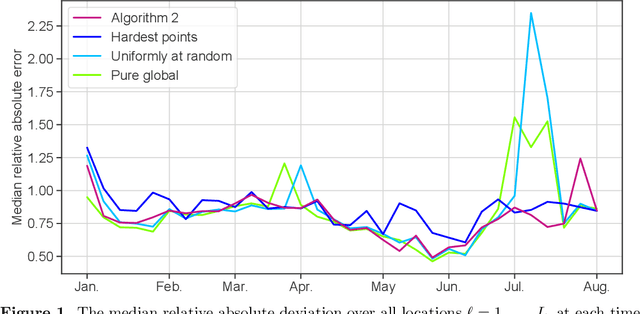
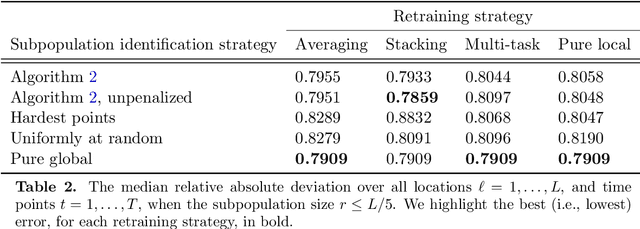
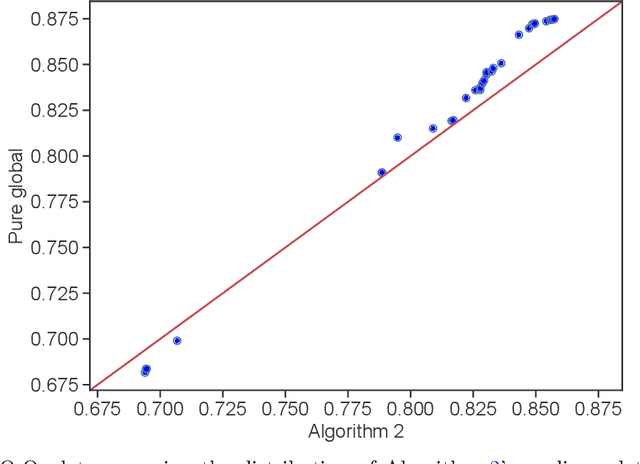
The statistical machine learning community has demonstrated considerable resourcefulness over the years in developing highly expressive tools for estimation, prediction, and inference. The bedrock assumptions underlying these developments are that the data comes from a fixed population and displays little heterogeneity. But reality is significantly more complex: statistical models now routinely fail when released into real-world systems and scientific applications, where such assumptions rarely hold. Consequently, we pursue a different path in this paper vis-a-vis the well-worn trail of developing new methodology for estimation and prediction. In this paper, we develop tools and theory for detecting and identifying regions of the covariate space (subpopulations) where model performance has begun to degrade, and study intervening to fix these failures through refitting. We present empirical results with three real-world data sets -- including a time series involving forecasting the incidence of COVID-19 -- showing that our methodology generates interpretable results, is useful for tracking model performance, and can boost model performance through refitting. We complement these empirical results with theory proving that our methodology is minimax optimal for recovering anomalous subpopulations as well as refitting to improve accuracy in a structured normal means setting.
Design-Bench: Benchmarks for Data-Driven Offline Model-Based Optimization
Feb 17, 2022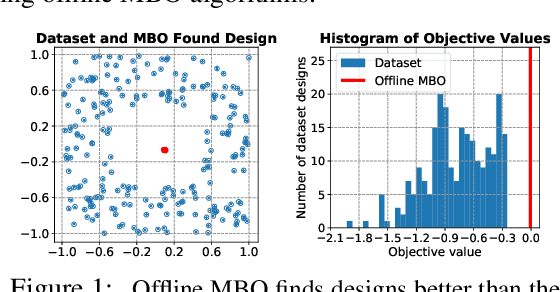
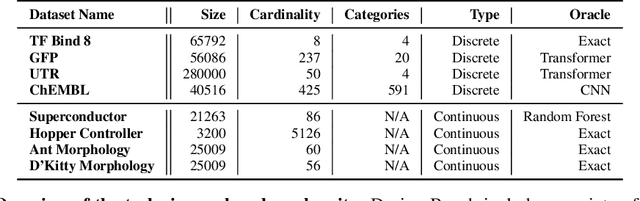
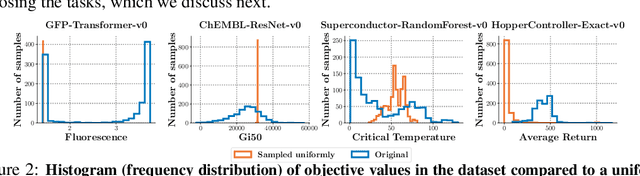
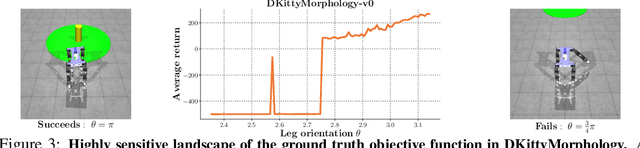
Black-box model-based optimization (MBO) problems, where the goal is to find a design input that maximizes an unknown objective function, are ubiquitous in a wide range of domains, such as the design of proteins, DNA sequences, aircraft, and robots. Solving model-based optimization problems typically requires actively querying the unknown objective function on design proposals, which means physically building the candidate molecule, aircraft, or robot, testing it, and storing the result. This process can be expensive and time consuming, and one might instead prefer to optimize for the best design using only the data one already has. This setting -- called offline MBO -- poses substantial and different algorithmic challenges than more commonly studied online techniques. A number of recent works have demonstrated success with offline MBO for high-dimensional optimization problems using high-capacity deep neural networks. However, the lack of standardized benchmarks in this emerging field is making progress difficult to track. To address this, we present Design-Bench, a benchmark for offline MBO with a unified evaluation protocol and reference implementations of recent methods. Our benchmark includes a suite of diverse and realistic tasks derived from real-world optimization problems in biology, materials science, and robotics that present distinct challenges for offline MBO. Our benchmark and reference implementations are released at github.com/rail-berkeley/design-bench and github.com/rail-berkeley/design-baselines.
Unified Characterization and Precoding for Non-Stationary Channels
Feb 08, 2022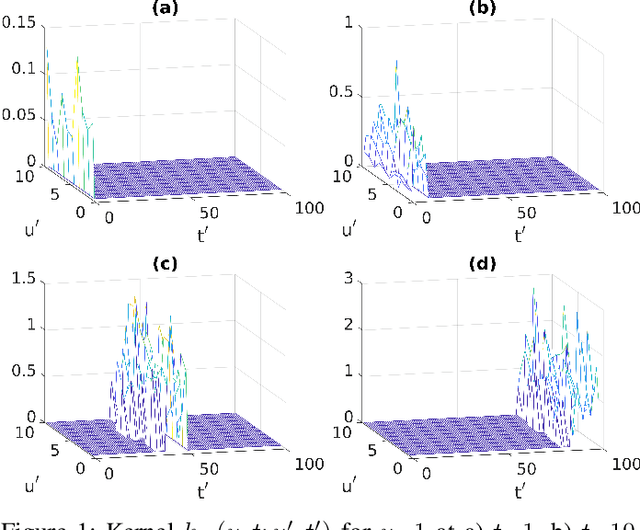
Modern wireless channels are increasingly dense and mobile making the channel highly non-stationary. The time-varying distribution and the existence of joint interference across multiple degrees of freedom (e.g., users, antennas, frequency and symbols) in such channels render conventional precoding sub-optimal in practice, and have led to historically poor characterization of their statistics. The core of our work is the derivation of a high-order generalization of Mercer's Theorem to decompose the non-stationary channel into constituent fading sub-channels (2-D eigenfunctions) that are jointly orthogonal across its degrees of freedom. Consequently, transmitting these eigenfunctions with optimally derived coefficients eventually mitigates any interference across these dimensions and forms the foundation of the proposed joint spatio-temporal precoding. The precoded symbols directly reconstruct the data symbols at the receiver upon demodulation, thereby significantly reducing its computational burden, by alleviating the need for any complementary decoding. These eigenfunctions are paramount to extracting the second-order channel statistics, and therefore completely characterize the underlying channel. Theory and simulations show that such precoding leads to ${>}10^4{\times}$ BER improvement (at 20dB) over existing methods for non-stationary channels.