 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-Reference Image Restoration for Under-Display Camera of UAV
Feb 13, 2022
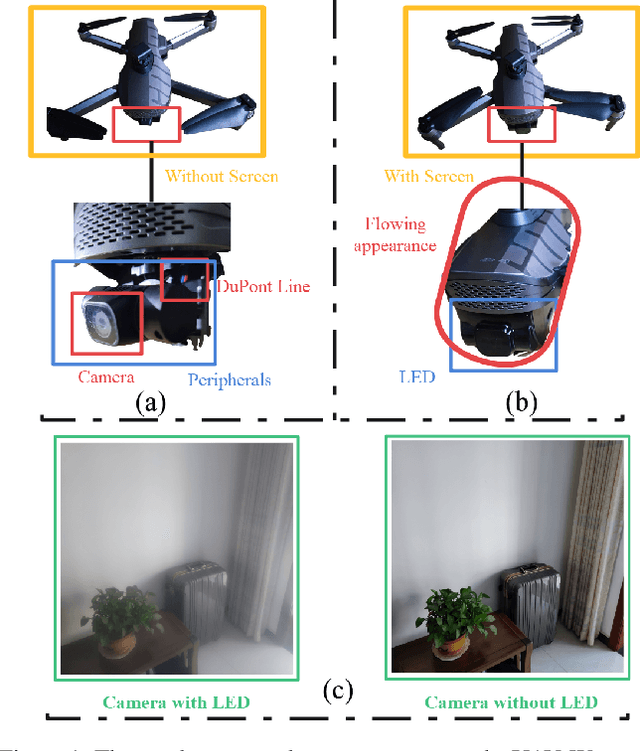
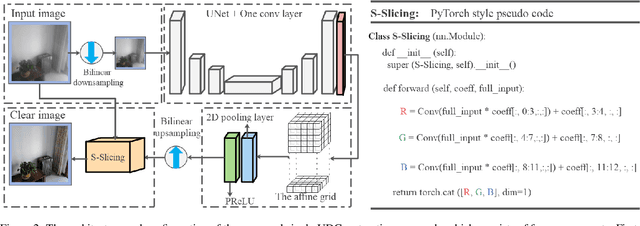


The exposed cameras of UAV can shake, shift, or even malfunction under the influence of harsh weather, while the add-on devices (Dupont lines) are very vulnerable to damage. We can place a low-cost T-OLED overlay around the camera to protect it, but this would also introduce image degradation issues. In particular, the temperature variations in the atmosphere can create mist that adsorbs to the T-OLED, which can cause secondary disasters (i.e., more severe image degradation) during the UAV's filming process. To solve the image degradation problem caused by overlaying T-OLEDs, in this paper we propose a new method to enhance the visual experience by enhancing the texture and color of images. Specifically, our method trains a lightweight network to estimate a low-rank affine grid on the input image, and then utilizes the grid to enhance the input image at block granularity. The advantages of our method are that no reference image is required and the loss function is developed from visual experience. In addition, our model can perform high-quality recovery of images of arbitrary resolution in real time. In the end, the limitations of our model and the collected datasets (including the daytime and nighttime scenes) are discussed.
Artificial Neural Network for Resource Allocation in Laser-based Optical wireless Networks
Nov 27, 2021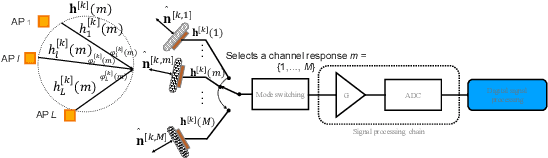
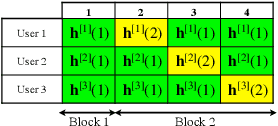
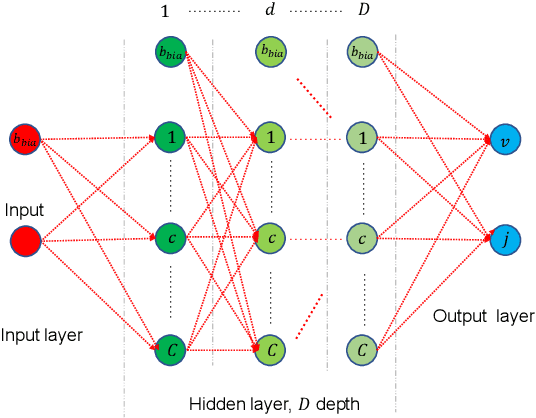
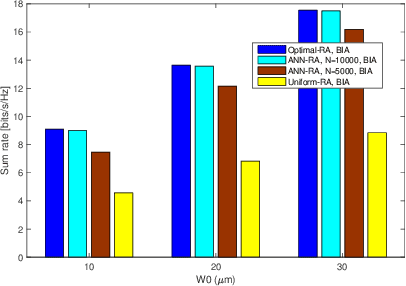
Optical wireless communication offers unprecedented communication speeds that can support the massive use of the Internet on a daily basis. In indoor environments, optical wireless networks are usually multi-user multiple-input multiple-output (MU-MIMO) systems, where a high number of optical access points (APs) is required to ensure coverage. In this work, a laser-based optical wireless network is considered for serving multiple users. Moreover, blind inference alignment (BIA) is implemented to achieve a high degree of freedom (DoF) without the need for channel state information (CSI) at transmitters, which is difficult to provide in such wireless networks. Then, an objective function is defined to allocate the resources of the network taking into consideration the requirements of users and the available resources. This optimization problem can be solved through exhaustive search or distributed algorithms. However, a practical algorithm that provides immediate solutions in real time scenarios is required. In this context, an artificial neural network (ANN) model is derived in order to obtain a sub-optimal solution with low computational time. The implementation of the ANN model involves three important steps, dataset generation, offline training, and real time application. The results show that the trained ANN model provides a significant solution close to the optimal one.
A deep learning energy method for hyperelasticity and viscoelasticity
Jan 15, 2022
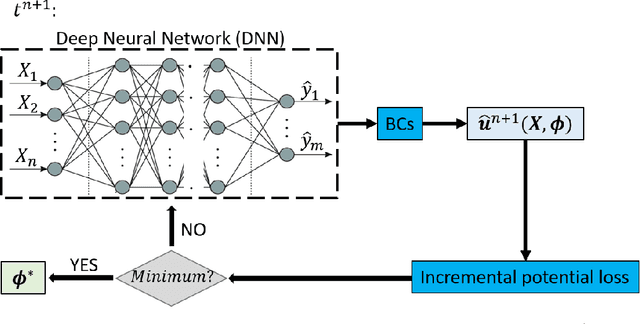
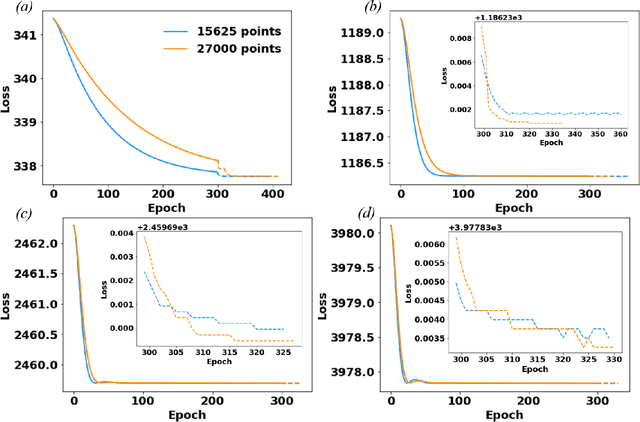
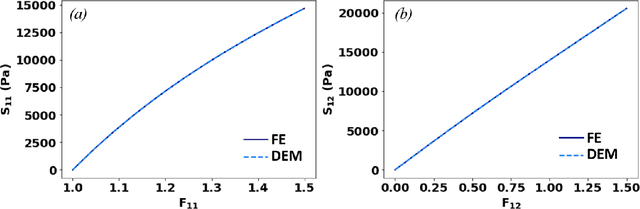
The potential energy formulation and deep learning are merged to solve partial differential equations governing the deformation in hyperelastic and viscoelastic materials. The presented deep energy method (DEM) is self-contained and meshfree. It can accurately capture the three-dimensional (3D) mechanical response without requiring any time-consuming training data generation by classical numerical methods such as the finite element method. Once the model is appropriately trained, the response can be attained almost instantly at any point in the physical domain, given its spatial coordinates. Therefore, the deep energy method is potentially a promising standalone method for solving partial differential equations describing the mechanical deformation of materials or structural systems and other physical phenomena.
Efficient Policy Space Response Oracles
Feb 09, 2022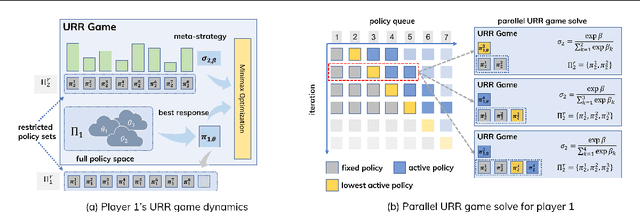
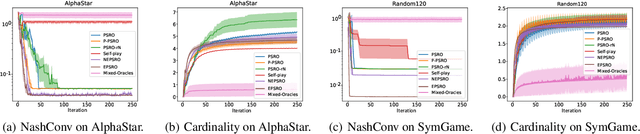
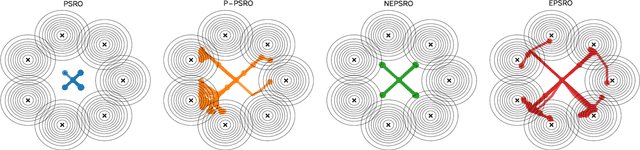
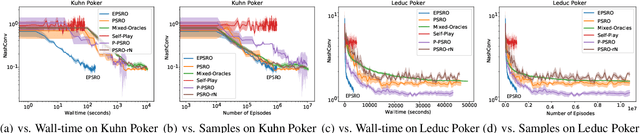
Policy Space Response Oracle method (PSRO) provides a general solution to Nash equilibrium in two-player zero-sum games but suffers from two problems: (1) the computation inefficiency due to consistently evaluating current populations by simulations; and (2) the exploration inefficiency due to learning best responses against a fixed meta-strategy at each iteration. In this work, we propose Efficient PSRO (EPSRO) that largely improves the efficiency of the above two steps. Central to our development is the newly-introduced subroutine of minimax optimization on unrestricted-restricted (URR) games. By solving URR at each step, one can evaluate the current game and compute the best response in one forward pass with no need for game simulations. Theoretically, we prove that the solution procedures of EPSRO offer a monotonic improvement on exploitability. Moreover, a desirable property of EPSRO is that it is parallelizable, this allows for efficient exploration in the policy space that induces behavioral diversity. We test EPSRO on three classes of games and report a 50x speedup in wall-time, 10x data efficiency, and similar exploitability as existing PSRO methods on Kuhn and Leduc Poker games.
Parametric t-Stochastic Neighbor Embedding With Quantum Neural Network
Feb 09, 2022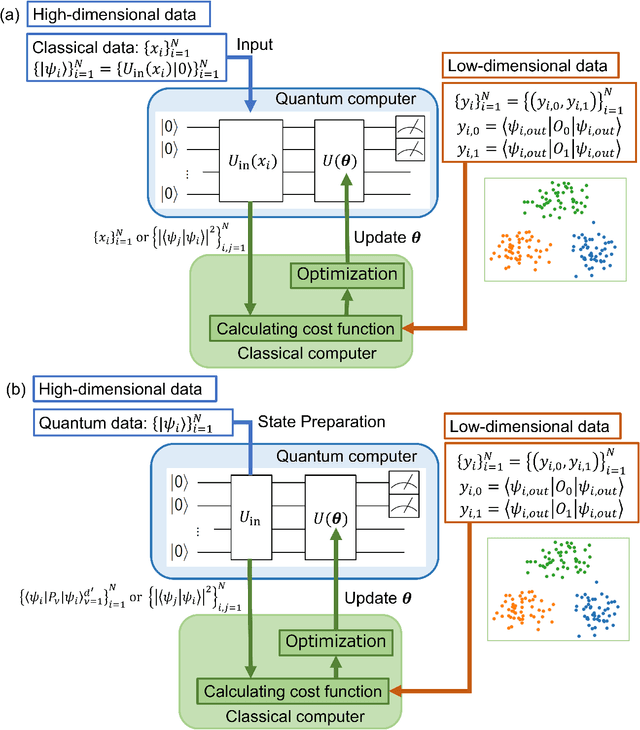
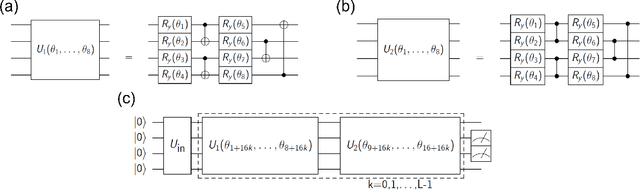
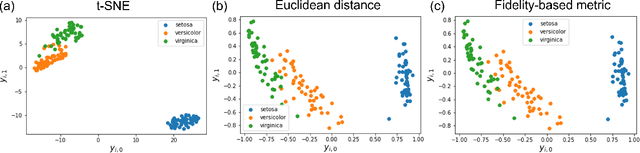
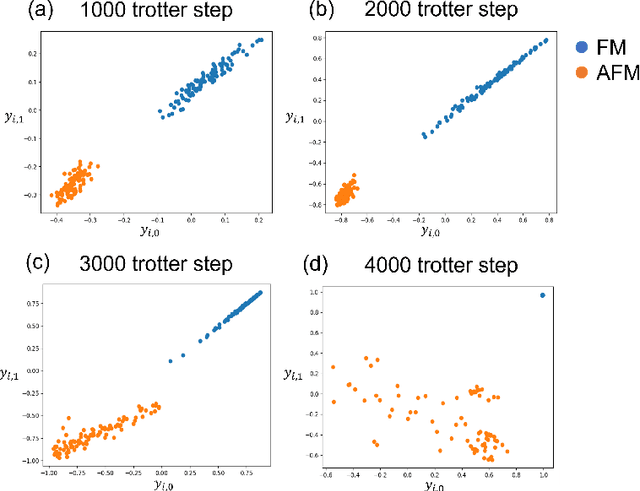
t-Stochastic Neighbor Embedding (t-SNE) is a non-parametric data visualization method in classical machine learning. It maps the data from the high-dimensional space into a low-dimensional space, especially a two-dimensional plane, while maintaining the relationship, or similarities, between the surrounding points. In t-SNE, the initial position of the low-dimensional data is randomly determined, and the visualization is achieved by moving the low-dimensional data to minimize a cost function. Its variant called parametric t-SNE uses neural networks for this mapping. In this paper, we propose to use quantum neural networks for parametric t-SNE to reflect the characteristics of high-dimensional quantum data on low-dimensional data. We use fidelity-based metrics instead of Euclidean distance in calculating high-dimensional data similarity. We visualize both classical (Iris dataset) and quantum (time-depending Hamiltonian dynamics) data for classification tasks. Since this method allows us to represent a quantum dataset in a higher dimensional Hilbert space by a quantum dataset in a lower dimension while keeping their similarity, the proposed method can also be used to compress quantum data for further quantum machine learning.
Effective Training Strategies for Deep-learning-based Precipitation Nowcasting and Estimation
Feb 17, 2022
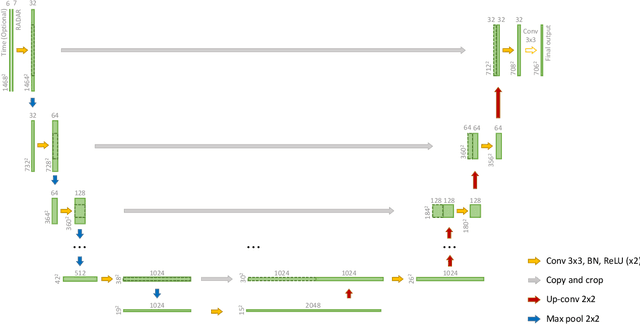
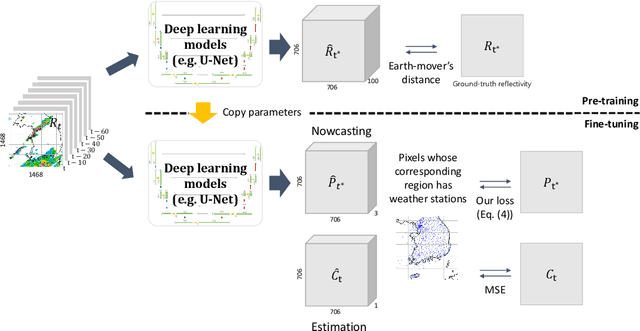
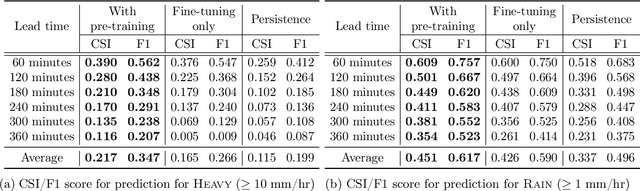
Deep learning has been successfully applied to precipitation nowcasting. In this work, we propose a pre-training scheme and a new loss function for improving deep-learning-based nowcasting. First, we adapt U-Net, a widely-used deep-learning model, for the two problems of interest here: precipitation nowcasting and precipitation estimation from radar images. We formulate the former as a classification problem with three precipitation intervals and the latter as a regression problem. For these tasks, we propose to pre-train the model to predict radar images in the near future without requiring ground-truth precipitation, and we also propose the use of a new loss function for fine-tuning to mitigate the class imbalance problem. We demonstrate the effectiveness of our approach using radar images and precipitation datasets collected from South Korea over seven years. It is highlighted that our pre-training scheme and new loss function improve the critical success index (CSI) of nowcasting of heavy rainfall (at least 10 mm/hr) by up to 95.7% and 43.6%, respectively, at a 5-hr lead time. We also demonstrate that our approach reduces the precipitation estimation error by up to 10.7%, compared to the conventional approach, for light rainfall (between 1 and 10 mm/hr). Lastly, we report the sensitivity of our approach to different resolutions and a detailed analysis of four cases of heavy rainfall.
Oracle-Efficient Online Learning for Beyond Worst-Case Adversaries
Feb 17, 2022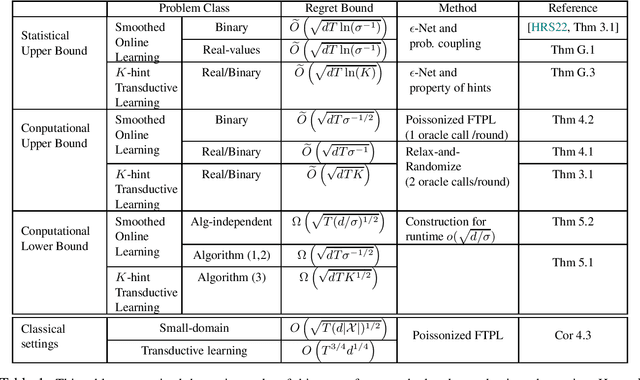
In this paper, we study oracle-efficient algorithms for beyond worst-case analysis of online learning. We focus on two settings. First, the smoothed analysis setting of [RST11, HRS12] where an adversary is constrained to generating samples from distributions whose density is upper bounded by $1/\sigma$ times the uniform density. Second, the setting of $K$-hint transductive learning, where the learner is given access to $K$ hints per time step that are guaranteed to include the true instance. We give the first known oracle-efficient algorithms for both settings that depend only on the VC dimension of the class and parameters $\sigma$ and $K$ that capture the power of the adversary. In particular, we achieve oracle-efficient regret bounds of $ O ( \sqrt{T (d / \sigma )^{1/2} } ) $ and $ O ( \sqrt{T d K } )$ respectively for these setting. For the smoothed analysis setting, our results give the first oracle-efficient algorithm for online learning with smoothed adversaries [HRS21]. This contrasts the computational separation between online learning with worst-case adversaries and offline learning established by [HK16]. Our algorithms also imply improved bounds for worst-case setting with small domains. In particular, we give an oracle-efficient algorithm with regret of $O ( \sqrt{T(d \vert{\mathcal{X}}\vert ) ^{1/2} })$, which is a refinement of the earlier $O ( \sqrt{T\vert{\mathcal{X} } \vert })$ bound by [DS16].
Non-Coherent MIMO-OFDM Uplink empowered by the Spatial Diversity in Reflecting Surfaces
Feb 04, 2022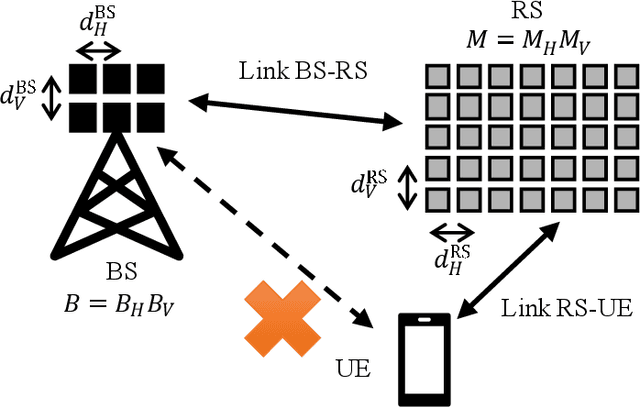
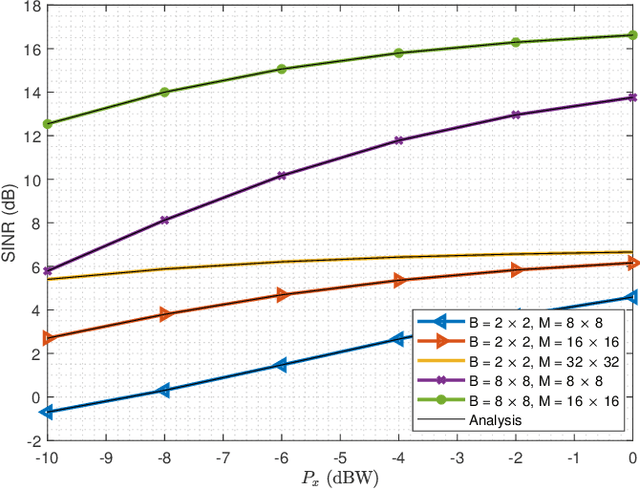
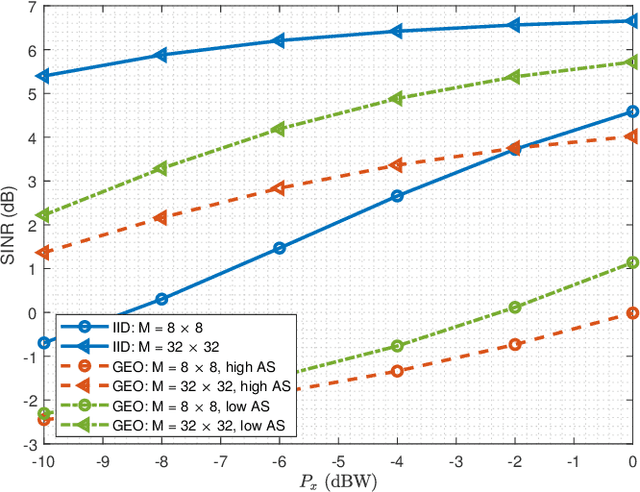
Reflecting Surfaces (RSs) are being lately envisioned as an energy efficient solution capable of enhancing the signal coverage in cases where obstacles block the direct communication from Base Stations (BSs), especially at high frequency bands due to attenuation loss increase. In the current literature, wireless communications via RSs are exclusively based on traditional coherent demodulation, which necessitates the estimation of accurate Channel State Information (CSI). However, this requirement results in an increased overhead, especially in time-varying channels, which reduces the resources that can be used for data communication. In this paper, we consider the uplink between a single-antenna user and a multi-antenna BS and present a novel RS-empowered Orthogonal Frequency Division Multiplexing (OFDM) communication system based on the differential phase shift keying, which is suitable for high noise and/or mobility scenarios. As a benchmark, analytical expressions for the Signal-to-Interference and Noise Ratio (SINR) of the proposed system are presented. Our extensive simulation results verify the accuracy of the presented analysis and showcase the performance and superiority of the proposed system over coherent demodulation.
CLS: Cross Labeling Supervision for Semi-Supervised Learning
Feb 17, 2022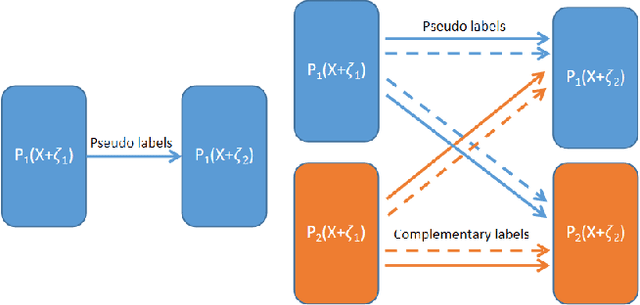
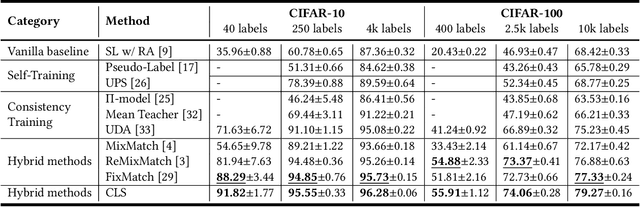
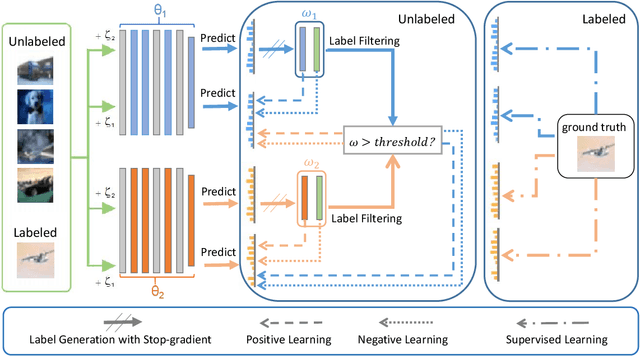
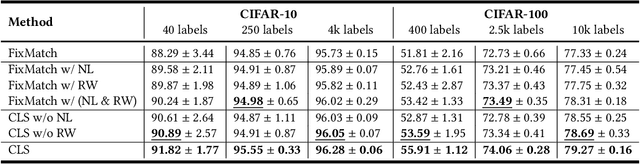
It is well known that the success of deep neural networks is greatly attributed to large-scale labeled datasets. However, it can be extremely time-consuming and laborious to collect sufficient high-quality labeled data in most practical applications. Semi-supervised learning (SSL) provides an effective solution to reduce the cost of labeling by simultaneously leveraging both labeled and unlabeled data. In this work, we present Cross Labeling Supervision (CLS), a framework that generalizes the typical pseudo-labeling process. Based on FixMatch, where a pseudo label is generated from a weakly-augmented sample to teach the prediction on a strong augmentation of the same input sample, CLS allows the creation of both pseudo and complementary labels to support both positive and negative learning. To mitigate the confirmation bias of self-labeling and boost the tolerance to false labels, two different initialized networks with the same structure are trained simultaneously. Each network utilizes high-confidence labels from the other network as additional supervision signals. During the label generation phase, adaptive sample weights are assigned to artificial labels according to their prediction confidence. The sample weight plays two roles: quantify the generated labels' quality and reduce the disruption of inaccurate labels on network training. Experimental results on the semi-supervised classification task show that our framework outperforms existing approaches by large margins on the CIFAR-10 and CIFAR-100 datasets.
Assessing generalisability of deep learning-based polyp detection and segmentation methods through a computer vision challenge
Feb 24, 2022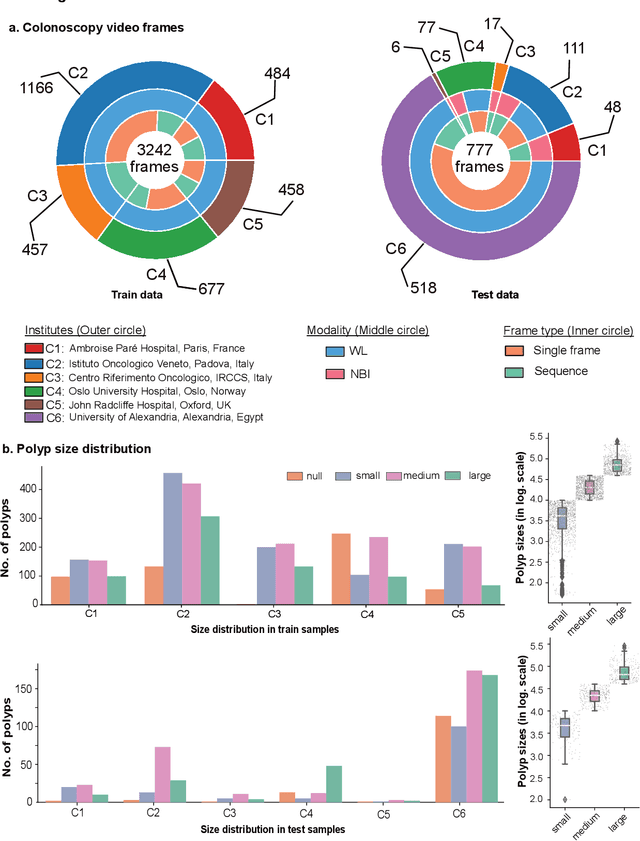
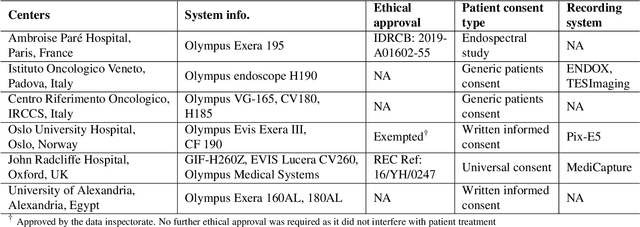
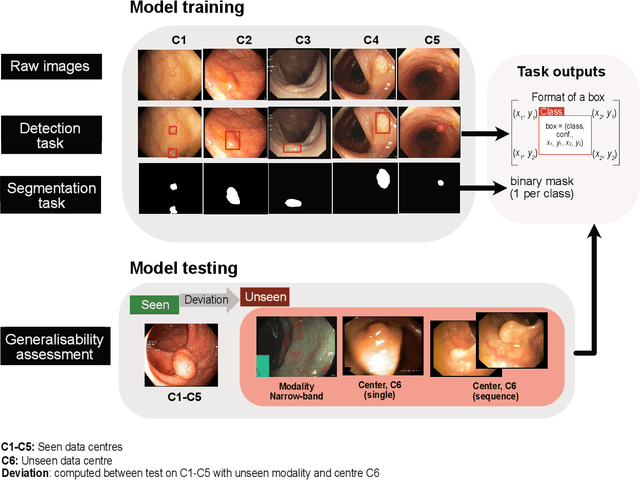
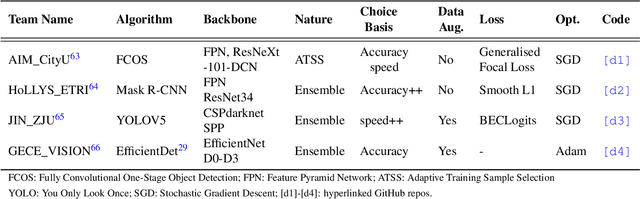
Polyps are well-known cancer precursors identified by colonoscopy. However, variability in their size, location, and surface largely affect identification, localisation, and characterisation. Moreover, colonoscopic surveillance and removal of polyps (referred to as polypectomy ) are highly operator-dependent procedures. There exist a high missed detection rate and incomplete removal of colonic polyps due to their variable nature, the difficulties to delineate the abnormality, the high recurrence rates, and the anatomical topography of the colon. There have been several developments in realising automated methods for both detection and segmentation of these polyps using machine learning. However, the major drawback in most of these methods is their ability to generalise to out-of-sample unseen datasets that come from different centres, modalities and acquisition systems. To test this hypothesis rigorously we curated a multi-centre and multi-population dataset acquired from multiple colonoscopy systems and challenged teams comprising machine learning experts to develop robust automated detection and segmentation methods as part of our crowd-sourcing Endoscopic computer vision challenge (EndoCV) 2021. In this paper, we analyse the detection results of the four top (among seven) teams and the segmentation results of the five top teams (among 16). Our analyses demonstrate that the top-ranking teams concentrated on accuracy (i.e., accuracy > 80% on overall Dice score on different validation sets) over real-time performance required for clinical applicability. We further dissect the methods and provide an experiment-based hypothesis that reveals the need for improved generalisability to tackle diversity present in multi-centre datasets.