 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
StandardSim: A Synthetic Dataset For Retail Environments
Feb 04, 2022

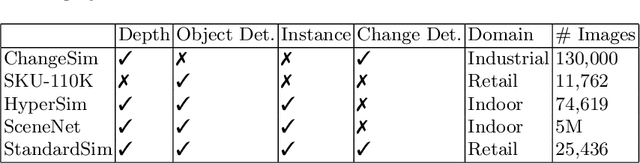

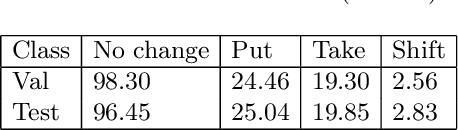
Autonomous checkout systems rely on visual and sensory inputs to carry out fine-grained scene understanding in retail environments. Retail environments present unique challenges compared to typical indoor scenes owing to the vast number of densely packed, unique yet similar objects. The problem becomes even more difficult when only RGB input is available, especially for data-hungry tasks such as instance segmentation. To address the lack of datasets for retail, we present StandardSim, a large-scale photorealistic synthetic dataset featuring annotations for semantic segmentation, instance segmentation, depth estimation, and object detection. Our dataset provides multiple views per scene, enabling multi-view representation learning. Further, we introduce a novel task central to autonomous checkout called change detection, requiring pixel-level classification of takes, puts and shifts in objects over time. We benchmark widely-used models for segmentation and depth estimation on our dataset, show that our test set constitutes a difficult benchmark compared to current smaller-scale datasets and that our training set provides models with crucial information for autonomous checkout tasks.
Systematic Literature Review: Quantum Machine Learning and its applications
Jan 11, 2022



Quantum computing is the process of performing calculations using quantum mechanics. This field studies the quantum behavior of certain subatomic particles for subsequent use in performing calculations, as well as for large-scale information processing. These capabilities can give quantum computers an advantage in terms of computational time and cost over classical computers. Nowadays, there are scientific challenges that are impossible to perform by classical computation due to computational complexity or the time the calculation would take, and quantum computation is one of the possible answers. However, current quantum devices have not yet the necessary qubits and are not fault-tolerant enough to achieve these goals. Nonetheless, there are other fields like machine learning or chemistry where quantum computation could be useful with current quantum devices. This manuscript aims to present a Systematic Literature Review of the papers published between 2017 and 2021 to identify, analyze and classify the different algorithms used in quantum machine learning and their applications. Consequently, this study identified 52 articles that used quantum machine learning techniques and algorithms. The main types of found algorithms are quantum implementations of classical machine learning algorithms, such as support vector machines or the k-nearest neighbor model, and classical deep learning algorithms, like quantum neural networks. Many articles try to solve problems currently answered by classical machine learning but using quantum devices and algorithms. Even though results are promising, quantum machine learning is far from achieving its full potential. An improvement in the quantum hardware is required since the existing quantum computers lack enough quality, speed, and scale to allow quantum computing to achieve its full potential.
Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models
Oct 21, 2019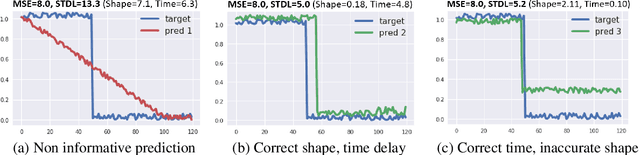
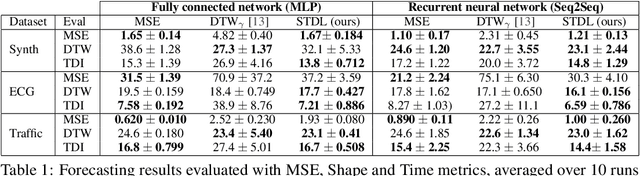
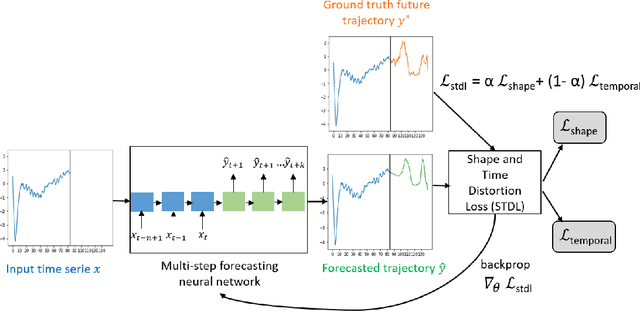
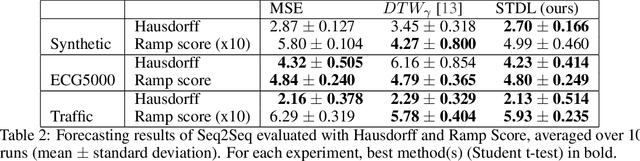
This paper addresses the problem of time series forecasting for non-stationary signals and multiple future steps prediction. To handle this challenging task, we introduce DILATE (DIstortion Loss including shApe and TimE), a new objective function for training deep neural networks. DILATE aims at accurately predicting sudden changes, and explicitly incorporates two terms supporting precise shape and temporal change detection. We introduce a differentiable loss function suitable for training deep neural nets, and provide a custom back-prop implementation for speeding up optimization. We also introduce a variant of DILATE, which provides a smooth generalization of temporally-constrained Dynamic Time Warping (DTW). Experiments carried out on various non-stationary datasets reveal the very good behaviour of DILATE compared to models trained with the standard Mean Squared Error (MSE) loss function, and also to DTW and variants. DILATE is also agnostic to the choice of the model, and we highlight its benefit for training fully connected networks as well as specialized recurrent architectures, showing its capacity to improve over state-of-the-art trajectory forecasting approaches.
Simulating Diffusion Bridges with Score Matching
Nov 14, 2021
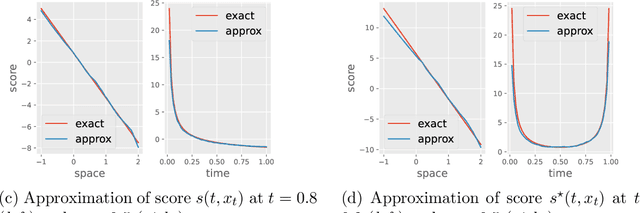
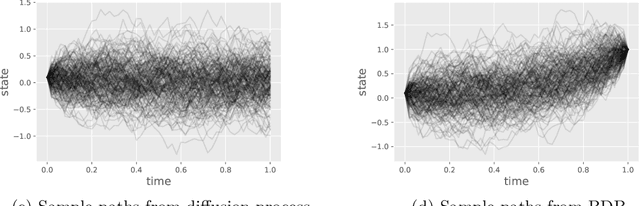
We consider the problem of simulating diffusion bridges, i.e. diffusion processes that are conditioned to initialize and terminate at two given states. Diffusion bridge simulation has applications in diverse scientific fields and plays a crucial role for statistical inference of discretely-observed diffusions. This is known to be a challenging problem that has received much attention in the last two decades. In this work, we first show that the time-reversed diffusion bridge process can be simulated if one can time-reverse the unconditioned diffusion process. We introduce a variational formulation to learn this time-reversal that relies on a score matching method to circumvent intractability. We then consider another iteration of our proposed methodology to approximate the Doob's $h$-transform defining the diffusion bridge process. As our approach is generally applicable under mild assumptions on the underlying diffusion process, it can easily be used to improve the proposal bridge process within existing methods and frameworks. We discuss algorithmic considerations and extensions, and present some numerical results.
Loss-analysis via Attention-scale for Physiologic Time Series
Nov 08, 2020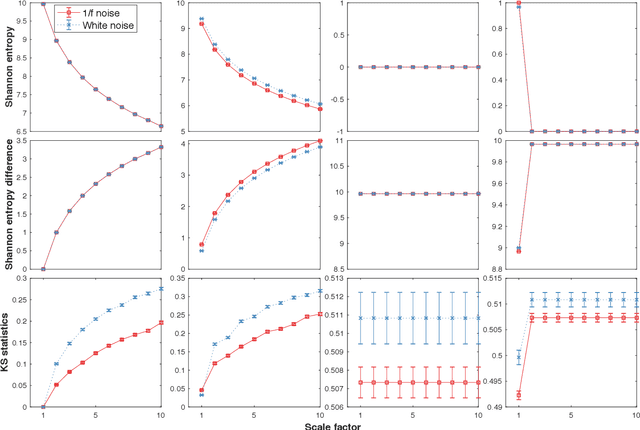
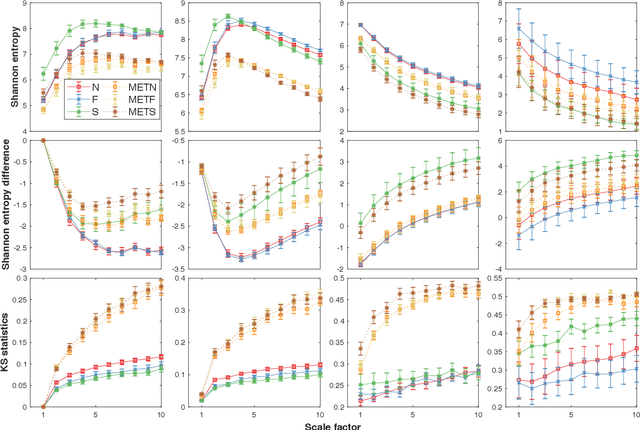
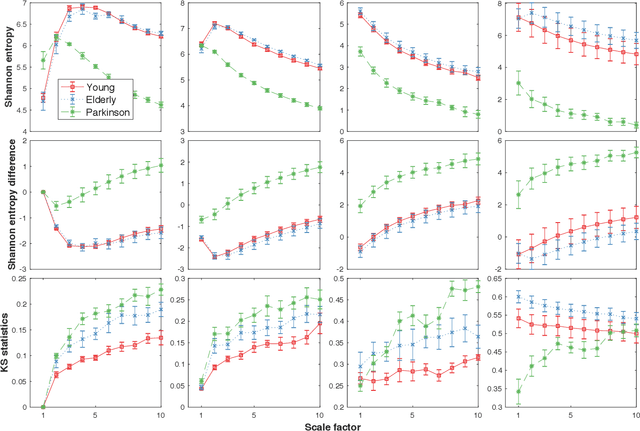
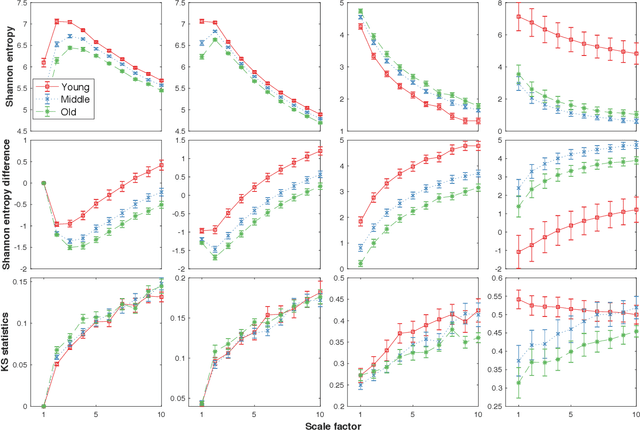
Physiologic signals have properties across multiple spatial and temporal scales, which can be shown by the complexity-analysis of the coarse-grained physiologic signals by scaling techniques such as the multiscale. Unfortunately, the results obtained from the coarse-grained signals by the multiscale may not fully reflect the properties of the original signals because there is a loss caused by scaling techniques and the same scaling technique may bring different losses to different signals. Another problem is that multiscale does not consider the key observations inherent in the signal. Here, we show a new analysis method for time series called the loss-analysis via attention-scale. We show that multiscale is a special case of attention-scale. The loss-analysis can complement to the complexity-analysis to capture aspects of the signals that are not captured using previously developed measures. This can be used to study ageing, diseases, and other physiologic phenomenon.
Stochastic smoothing of the top-K calibrated hinge loss for deep imbalanced classification
Feb 04, 2022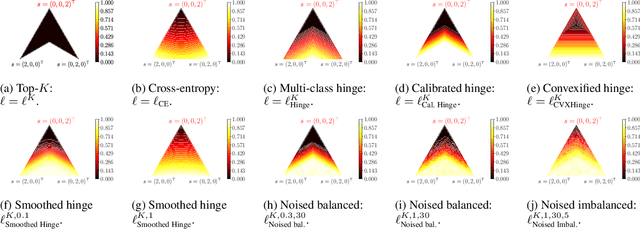

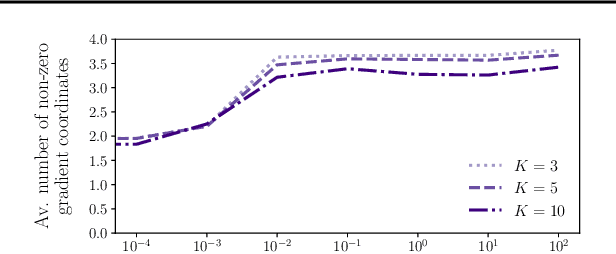

In modern classification tasks, the number of labels is getting larger and larger, as is the size of the datasets encountered in practice. As the number of classes increases, class ambiguity and class imbalance become more and more problematic to achieve high top-1 accuracy. Meanwhile, Top-K metrics (metrics allowing K guesses) have become popular, especially for performance reporting. Yet, proposing top-K losses tailored for deep learning remains a challenge, both theoretically and practically. In this paper we introduce a stochastic top-K hinge loss inspired by recent developments on top-K calibrated losses. Our proposal is based on the smoothing of the top-K operator building on the flexible "perturbed optimizer" framework. We show that our loss function performs very well in the case of balanced datasets, while benefiting from a significantly lower computational time than the state-of-the-art top-K loss function. In addition, we propose a simple variant of our loss for the imbalanced case. Experiments on a heavy-tailed dataset show that our loss function significantly outperforms other baseline loss functions.
CondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems
Dec 01, 2021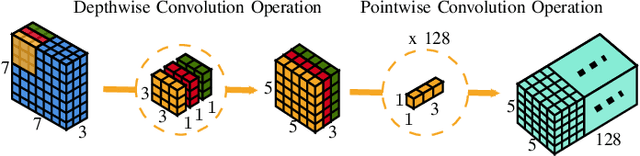
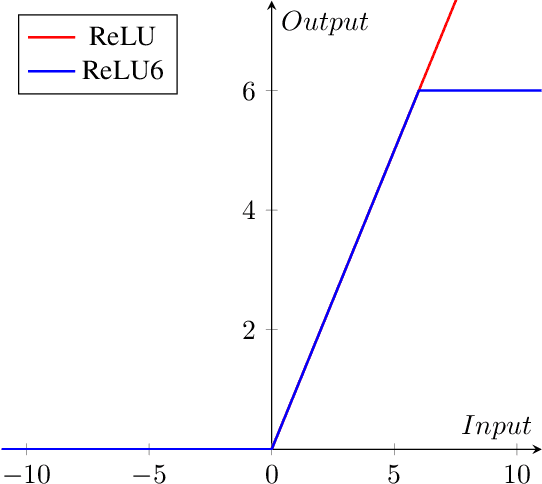
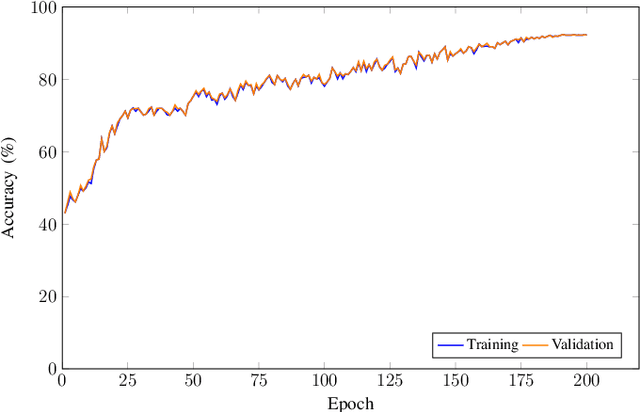

Due to the advent of modern embedded systems and mobile devices with constrained resources, there is a great demand for incredibly efficient deep neural networks for machine learning purposes. There is also a growing concern of privacy and confidentiality of user data within the general public when their data is processed and stored in an external server which has further fueled the need for developing such efficient neural networks for real-time inference on local embedded systems. The scope of our work presented in this paper is limited to image classification using a convolutional neural network. A Convolutional Neural Network (CNN) is a class of Deep Neural Network (DNN) widely used in the analysis of visual images captured by an image sensor, designed to extract information and convert it into meaningful representations for real-time inference of the input data. In this paper, we propose a neoteric variant of deep convolutional neural network architecture to ameliorate the performance of existing CNN architectures for real-time inference on embedded systems. We show that this architecture, dubbed CondenseNeXt, is remarkably efficient in comparison to the baseline neural network architecture, CondenseNet, by reducing trainable parameters and FLOPs required to train the network whilst maintaining a balance between the trained model size of less than 3.0 MB and accuracy trade-off resulting in an unprecedented computational efficiency.
DelTact: A Vision-based Tactile Sensor Using Dense Color Pattern
Feb 04, 2022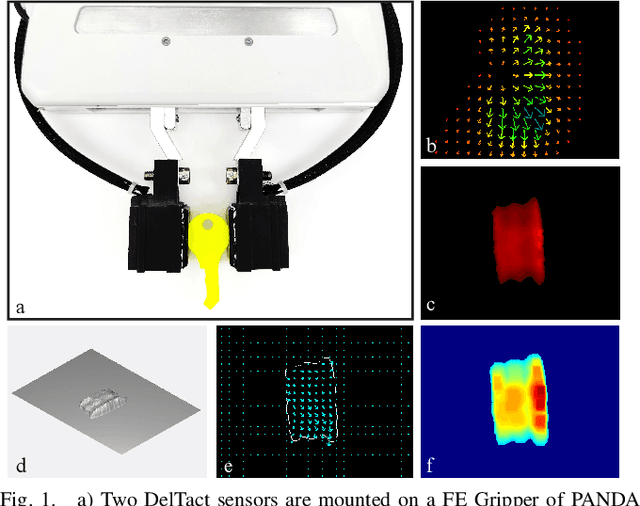
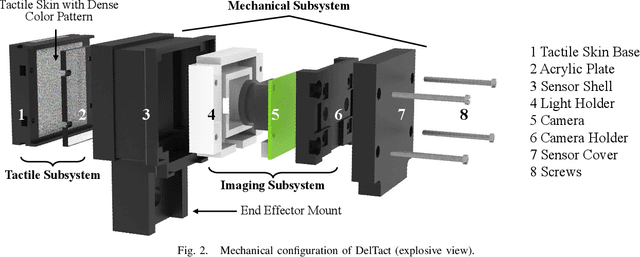

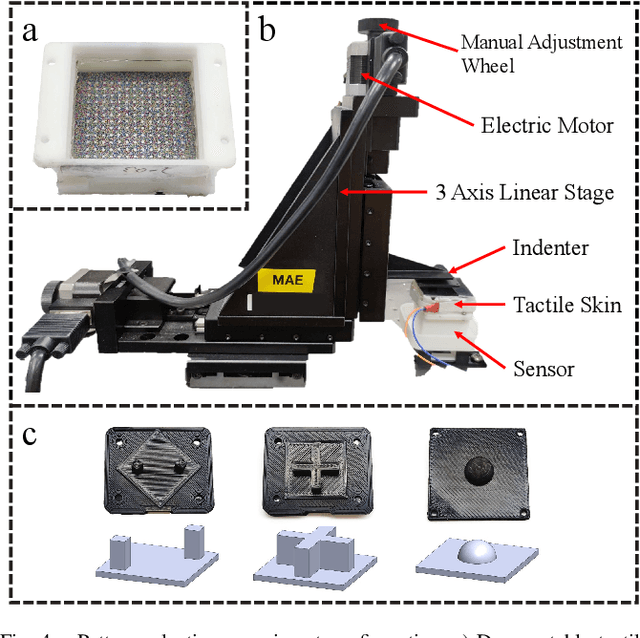
Tactile sensing is an essential perception for robots to complete dexterous tasks. As a promising tactile sensing technique, vision-based tactile sensors have been developed to improve robot manipulation performance. Here we propose a new design of our vision-based tactile sensor, DelTact, with its high-resolution sensing abilities of multiple modality surface contact information. The sensor adopts an improved dense random color pattern based on previous version, using a modular hardware architecture to achieve higher accuracy of contact deformation tracking whilst at the same time maintaining a compact and robust overall design. In particular, we optimized the color pattern generation process and selected the appropriate pattern for coordinating with a dense optical flow in a real-world experimental sensory setting using varied contact objects. A dense tactile flow was obtained from the raw image in order to determine shape and force distribution on the contact surface. This sensor can be easily integrated with a parallel gripper where experimental results using qualitative and quantitative analysis demonstrated that the sensor is capable of providing tactile measurements with high temporal and spatial resolution.
Models in the Loop: Aiding Crowdworkers with Generative Annotation Assistants
Dec 16, 2021

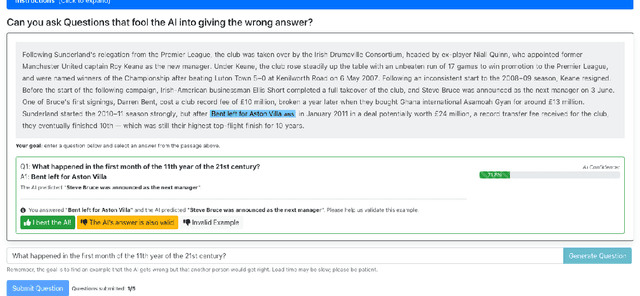

In Dynamic Adversarial Data Collection (DADC), human annotators are tasked with finding examples that models struggle to predict correctly. Models trained on DADC-collected training data have been shown to be more robust in adversarial and out-of-domain settings, and are considerably harder for humans to fool. However, DADC is more time-consuming than traditional data collection and thus more costly per example. In this work, we examine if we can maintain the advantages of DADC, without suffering the additional cost. To that end, we introduce Generative Annotation Assistants (GAAs), generator-in-the-loop models that provide real-time suggestions that annotators can either approve, modify, or reject entirely. We collect training datasets in twenty experimental settings and perform a detailed analysis of this approach for the task of extractive question answering (QA) for both standard and adversarial data collection. We demonstrate that GAAs provide significant efficiency benefits in terms of annotation speed, while leading to improved model fooling rates. In addition, we show that GAA-assisted data leads to higher downstream model performance on a variety of question answering tasks.
Ptychopy: GPU framework for ptychographic data analysis
Jan 24, 2022X-ray ptychography imaging at synchrotron facilities like the Advanced Photon Source (APS) involves controlling instrument hardwares to collect a set of diffraction patterns from overlapping coherent illumination spots on extended samples, managing data storage, reconstructing ptychographic images from acquired diffraction patterns, and providing the visualization of results and feedback. In addition to the complicated workflow, ptychography instrument could produce up to several TB's of data per second that is needed to be processed in real time. This brings up the need to develop a high performance, robust and user friendly processing software package for ptychographic data analysis. In this paper we present a software framework which provides functionality of visualization, work flow control, and data reconstruction. To accelerate the computation and large datasets process, the data reconstruction part is implemented with three algorithms, ePIE, DM and LSQML using CUDA-C on GPU.