 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fourier ptychography multi-parameter neural network with composite physical priori optimization
Feb 18, 2022
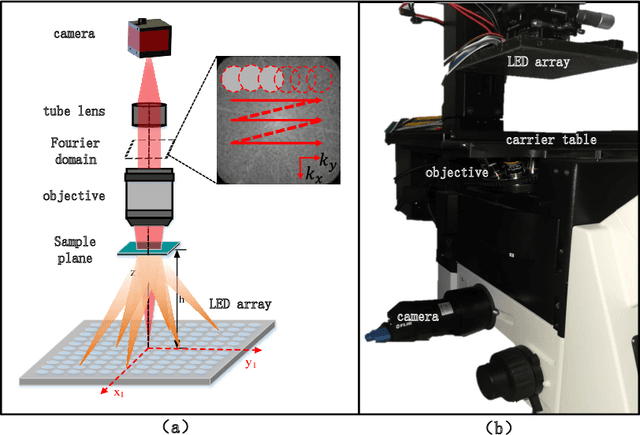
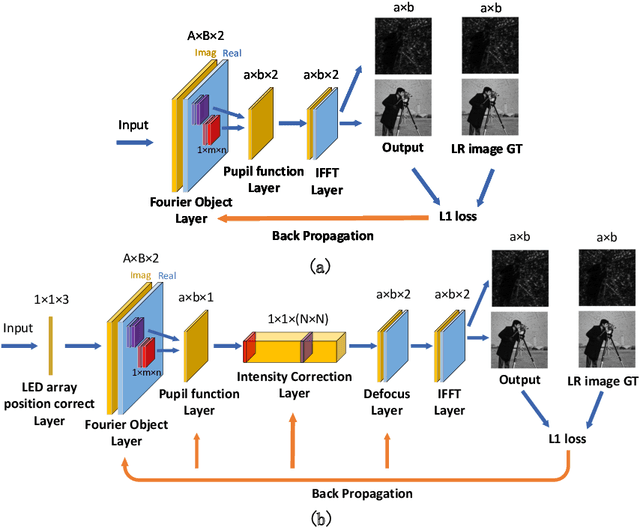
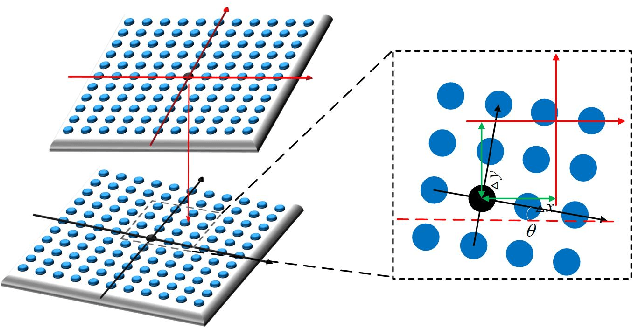
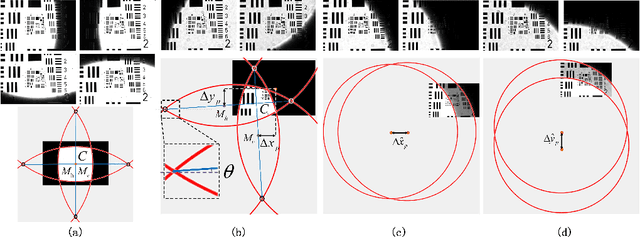
Fourier ptychography microscopy(FP) is a recently developed computational imaging approach for microscopic super-resolution imaging. By turning on each light-emitting-diode (LED) located on different position on the LED array sequentially and acquiring the corresponding images that contain different spatial frequency components, high spatial resolution and quantitative phase imaging can be achieved in the case of large field-of-view. Nevertheless, FPM has high requirements for the system construction and data acquisition processes, such as precise LEDs position, accurate focusing and appropriate exposure time, which brings many limitations to its practical applications. In this paper, inspired by artificial neural network, we propose a Fourier ptychography multi-parameter neural network (FPMN) with composite physical prior optimization. A hybrid parameter determination strategy combining physical imaging model and data-driven network training is proposed to recover the multi layers of the network corresponding to different physical parameters, including sample complex function, system pupil function, defocus distance, LED array position deviation and illumination intensity fluctuation, etc. Among these parameters, LED array position deviation is recovered based on the features of brightfield to darkfield transition low-resolution images while the others are recovered in the process of training of the neural network. The feasibility and effectiveness of FPMN are verified through simulations and actual experiments. Therefore FPMN can evidently reduce the requirement for practical applications of FPM.
Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models
Oct 24, 2019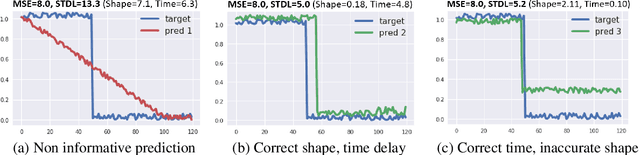
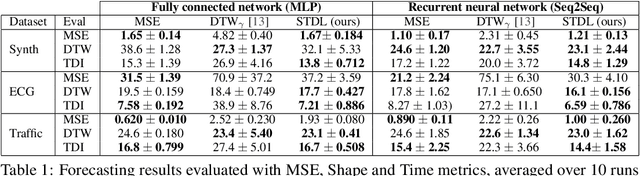
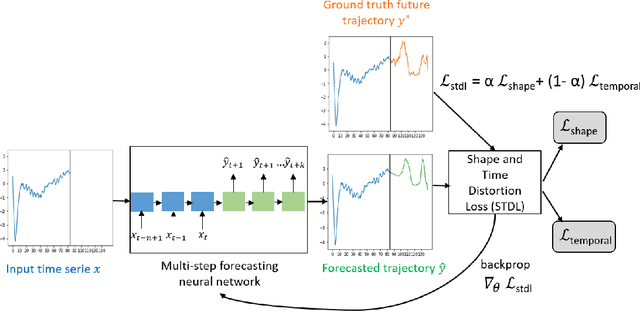
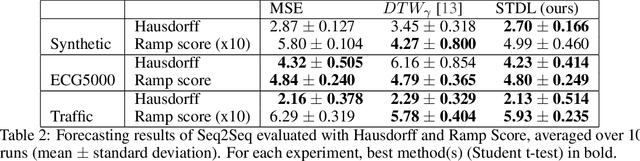
This paper addresses the problem of time series forecasting for non-stationary signals and multiple future steps prediction. To handle this challenging task, we introduce DILATE (DIstortion Loss including shApe and TimE), a new objective function for training deep neural networks. DILATE aims at accurately predicting sudden changes, and explicitly incorporates two terms supporting precise shape and temporal change detection. We introduce a differentiable loss function suitable for training deep neural nets, and provide a custom back-prop implementation for speeding up optimization. We also introduce a variant of DILATE, which provides a smooth generalization of temporally-constrained Dynamic Time Warping (DTW). Experiments carried out on various non-stationary datasets reveal the very good behaviour of DILATE compared to models trained with the standard Mean Squared Error (MSE) loss function, and also to DTW and variants. DILATE is also agnostic to the choice of the model, and we highlight its benefit for training fully connected networks as well as specialized recurrent architectures, showing its capacity to improve over state-of-the-art trajectory forecasting approaches.
Towards Efficiently Evaluating the Robustness of Deep Neural Networks in IoT Systems: A GAN-based Method
Nov 19, 2021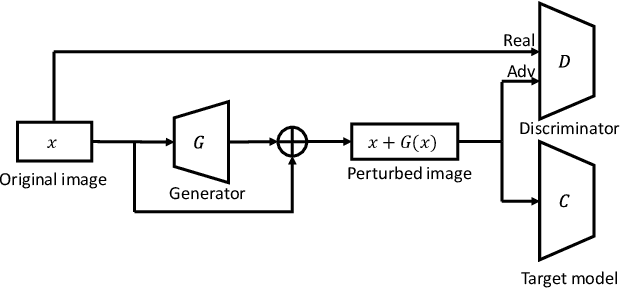
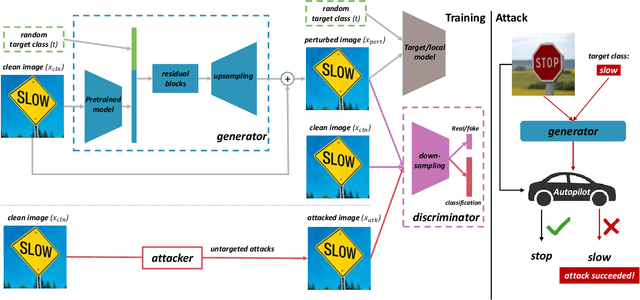

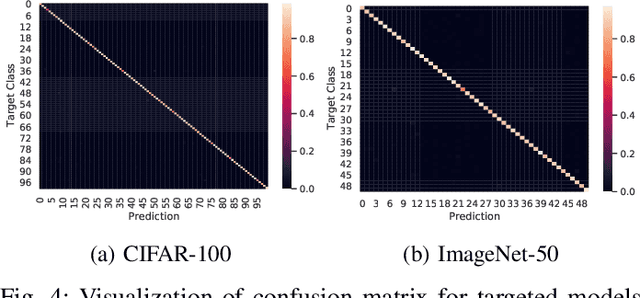
Intelligent Internet of Things (IoT) systems based on deep neural networks (DNNs) have been widely deployed in the real world. However, DNNs are found to be vulnerable to adversarial examples, which raises people's concerns about intelligent IoT systems' reliability and security. Testing and evaluating the robustness of IoT systems becomes necessary and essential. Recently various attacks and strategies have been proposed, but the efficiency problem remains unsolved properly. Existing methods are either computationally extensive or time-consuming, which is not applicable in practice. In this paper, we propose a novel framework called Attack-Inspired GAN (AI-GAN) to generate adversarial examples conditionally. Once trained, it can generate adversarial perturbations efficiently given input images and target classes. We apply AI-GAN on different datasets in white-box settings, black-box settings and targeted models protected by state-of-the-art defenses. Through extensive experiments, AI-GAN achieves high attack success rates, outperforming existing methods, and reduces generation time significantly. Moreover, for the first time, AI-GAN successfully scales to complex datasets e.g. CIFAR-100 and ImageNet, with about $90\%$ success rates among all classes.
PGCN: Progressive Graph Convolutional Networks for Spatial-Temporal Traffic Forecasting
Feb 18, 2022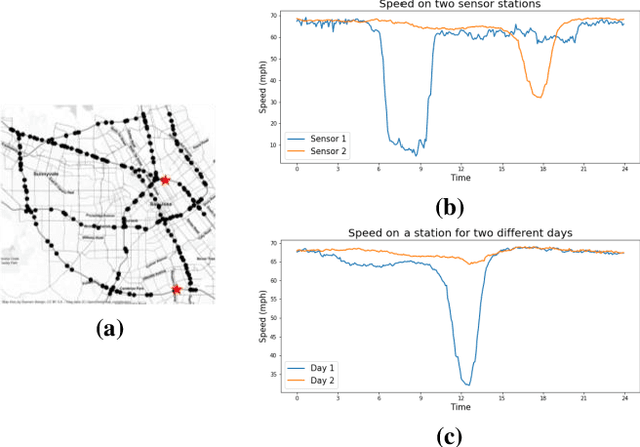
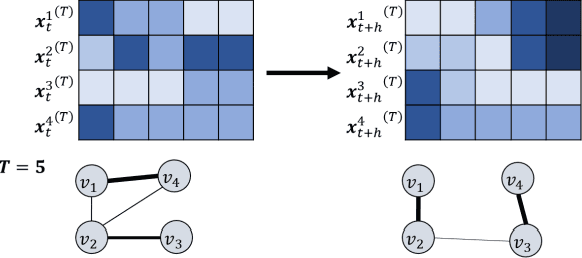
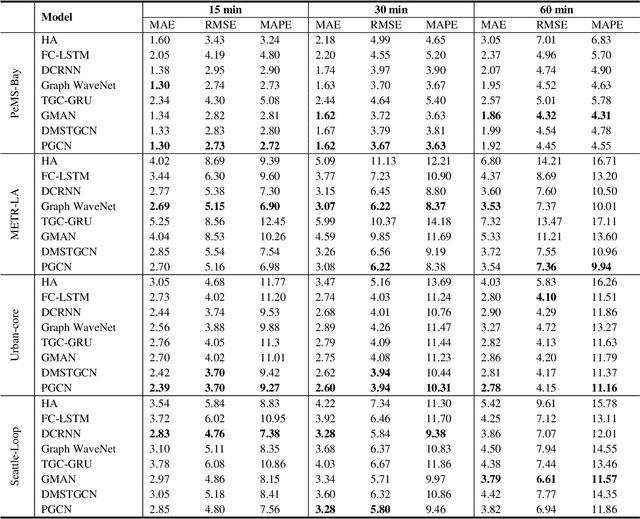
The complex spatial-temporal correlations in transportation networks make the traffic forecasting problem challenging. Since transportation system inherently possesses graph structures, much research efforts have been put with graph neural networks. Recently, constructing adaptive graphs to the data has shown promising results over the models relying on a single static graph structure. However, the graph adaptations are applied during the training phases, and do not reflect the data used during the testing phases. Such shortcomings can be problematic especially in traffic forecasting since the traffic data often suffers from the unexpected changes and irregularities in the time series. In this study, we propose a novel traffic forecasting framework called Progressive Graph Convolutional Network (PGCN). PGCN constructs a set of graphs by progressively adapting to input data during the training and the testing phases. Specifically, we implemented the model to construct progressive adjacency matrices by learning trend similarities among graph nodes. Then, the model is combined with the dilated causal convolution and gated activation unit to extract temporal features. With residual and skip connections, PGCN performs the traffic prediction. When applied to four real-world traffic datasets of diverse geometric nature, the proposed model achieves state-of-the-art performance with consistency in all datasets. We conclude that the ability of PGCN to progressively adapt to input data enables the model to generalize in different study sites with robustness.
Adjoint-aided inference of Gaussian process driven differential equations
Feb 09, 2022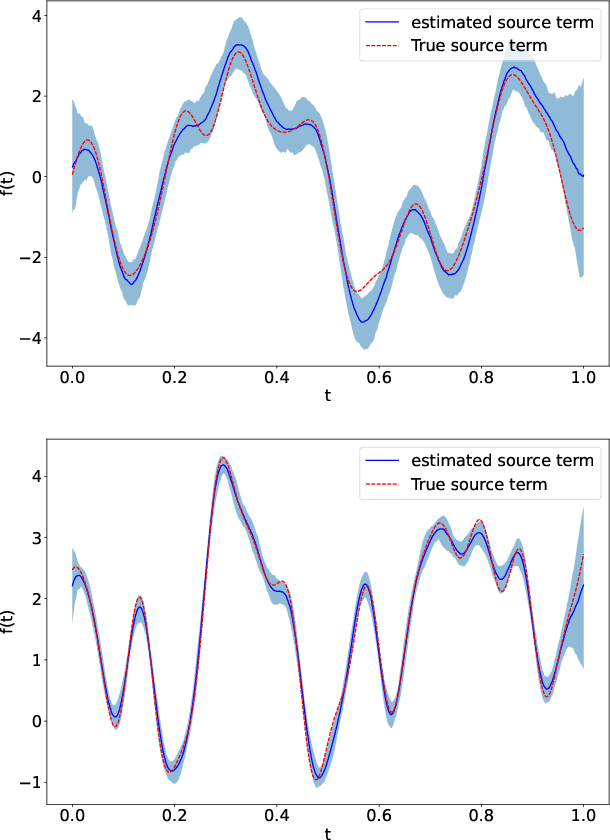
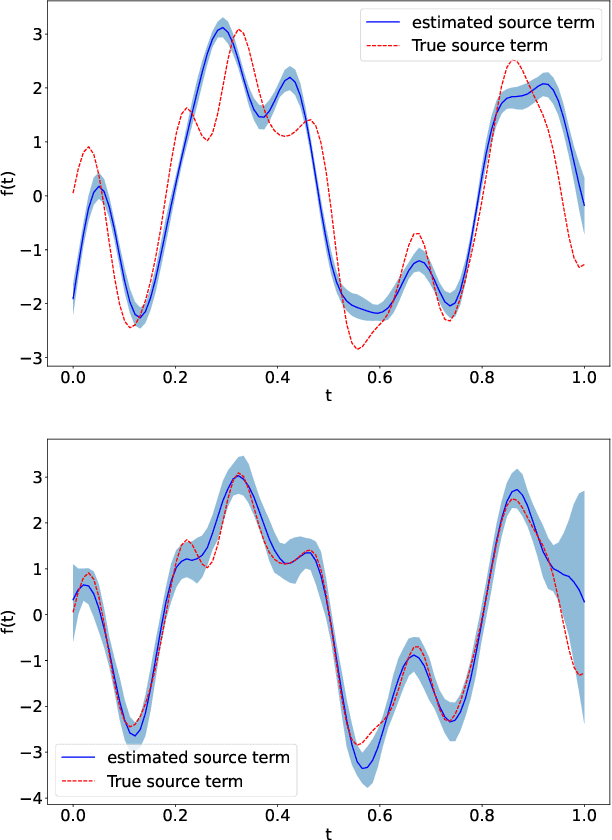
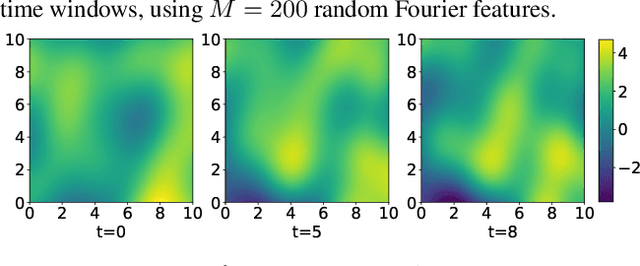
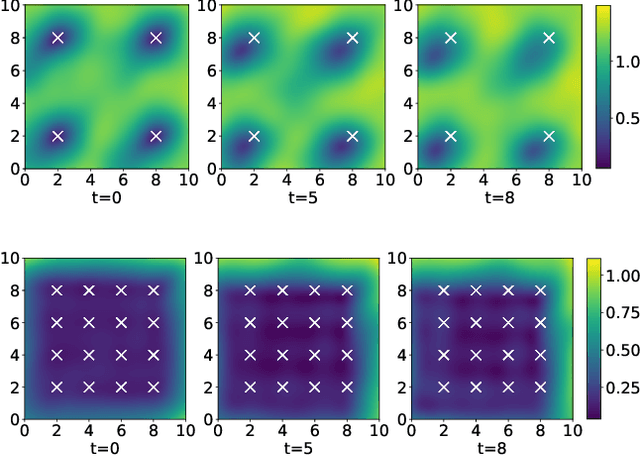
Linear systems occur throughout engineering and the sciences, most notably as differential equations. In many cases the forcing function for the system is unknown, and interest lies in using noisy observations of the system to infer the forcing, as well as other unknown parameters. In differential equations, the forcing function is an unknown function of the independent variables (typically time and space), and can be modelled as a Gaussian process (GP). In this paper we show how the adjoint of a linear system can be used to efficiently infer forcing functions modelled as GPs, after using a truncated basis expansion of the GP kernel. We show how exact conjugate Bayesian inference for the truncated GP can be achieved, in many cases with substantially lower computation than would be required using MCMC methods. We demonstrate the approach on systems of both ordinary and partial differential equations, and by testing on synthetic data, show that the basis expansion approach approximates well the true forcing with a modest number of basis vectors. Finally, we show how to infer point estimates for the non-linear model parameters, such as the kernel length-scales, using Bayesian optimisation.
A Convergent ADMM Framework for Efficient Neural Network Training
Dec 22, 2021
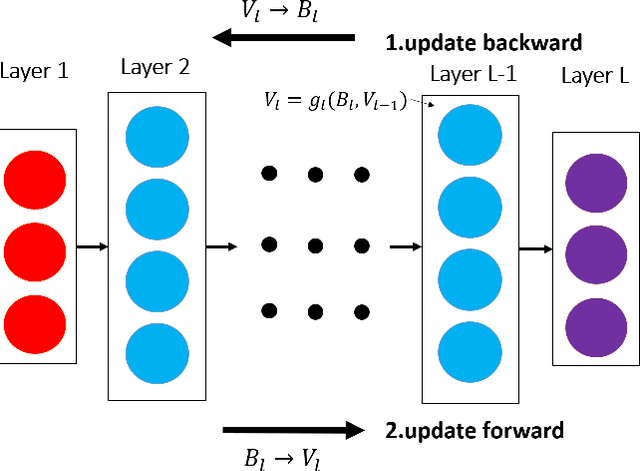

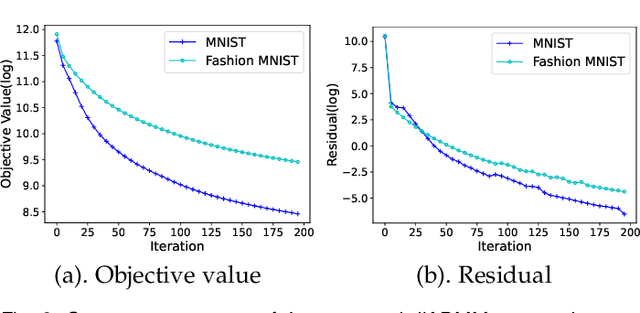
As a well-known optimization framework, the Alternating Direction Method of Multipliers (ADMM) has achieved tremendous success in many classification and regression applications. Recently, it has attracted the attention of deep learning researchers and is considered to be a potential substitute to Gradient Descent (GD). However, as an emerging domain, several challenges remain unsolved, including 1) The lack of global convergence guarantees, 2) Slow convergence towards solutions, and 3) Cubic time complexity with regard to feature dimensions. In this paper, we propose a novel optimization framework to solve a general neural network training problem via ADMM (dlADMM) to address these challenges simultaneously. Specifically, the parameters in each layer are updated backward and then forward so that parameter information in each layer is exchanged efficiently. When the dlADMM is applied to specific architectures, the time complexity of subproblems is reduced from cubic to quadratic via a dedicated algorithm design utilizing quadratic approximations and backtracking techniques. Last but not least, we provide the first proof of convergence to a critical point sublinearly for an ADMM-type method (dlADMM) under mild conditions. Experiments on seven benchmark datasets demonstrate the convergence, efficiency, and effectiveness of our proposed dlADMM algorithm.
TimeAutoML: Autonomous Representation Learning for Multivariate Irregularly Sampled Time Series
Oct 04, 2020
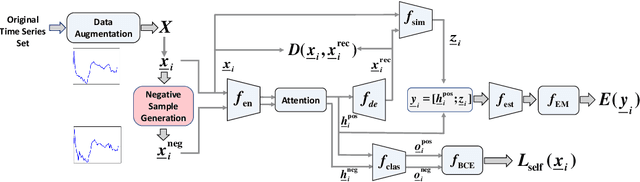
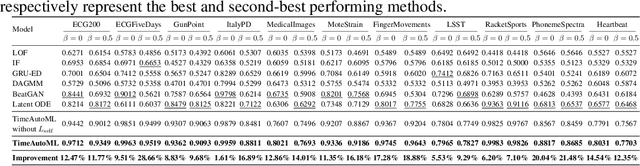
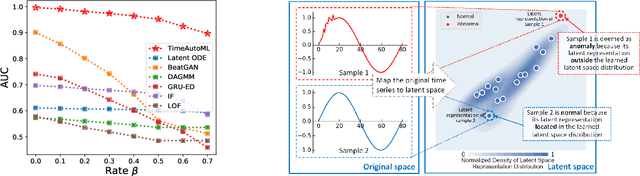
Multivariate time series (MTS) data are becoming increasingly ubiquitous in diverse domains, e.g., IoT systems, health informatics, and 5G networks. To obtain an effective representation of MTS data, it is not only essential to consider unpredictable dynamics and highly variable lengths of these data but also important to address the irregularities in the sampling rates of MTS. Existing parametric approaches rely on manual hyperparameter tuning and may cost a huge amount of labor effort. Therefore, it is desirable to learn the representation automatically and efficiently. To this end, we propose an autonomous representation learning approach for multivariate time series (TimeAutoML) with irregular sampling rates and variable lengths. As opposed to previous works, we first present a representation learning pipeline in which the configuration and hyperparameter optimization are fully automatic and can be tailored for various tasks, e.g., anomaly detection, clustering, etc. Next, a negative sample generation approach and an auxiliary classification task are developed and integrated within TimeAutoML to enhance its representation capability. Extensive empirical studies on real-world datasets demonstrate that the proposed TimeAutoML outperforms competing approaches on various tasks by a large margin. In fact, it achieves the best anomaly detection performance among all comparison algorithms on 78 out of all 85 UCR datasets, acquiring up to 20% performance improvement in terms of AUC score.
StandardSim: A Synthetic Dataset For Retail Environments
Feb 04, 2022
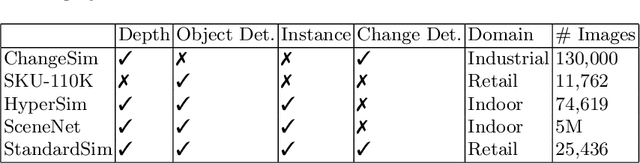

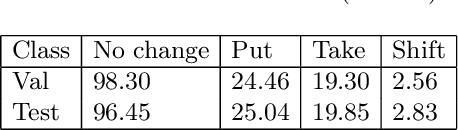
Autonomous checkout systems rely on visual and sensory inputs to carry out fine-grained scene understanding in retail environments. Retail environments present unique challenges compared to typical indoor scenes owing to the vast number of densely packed, unique yet similar objects. The problem becomes even more difficult when only RGB input is available, especially for data-hungry tasks such as instance segmentation. To address the lack of datasets for retail, we present StandardSim, a large-scale photorealistic synthetic dataset featuring annotations for semantic segmentation, instance segmentation, depth estimation, and object detection. Our dataset provides multiple views per scene, enabling multi-view representation learning. Further, we introduce a novel task central to autonomous checkout called change detection, requiring pixel-level classification of takes, puts and shifts in objects over time. We benchmark widely-used models for segmentation and depth estimation on our dataset, show that our test set constitutes a difficult benchmark compared to current smaller-scale datasets and that our training set provides models with crucial information for autonomous checkout tasks.
Systematic Literature Review: Quantum Machine Learning and its applications
Jan 11, 2022



Quantum computing is the process of performing calculations using quantum mechanics. This field studies the quantum behavior of certain subatomic particles for subsequent use in performing calculations, as well as for large-scale information processing. These capabilities can give quantum computers an advantage in terms of computational time and cost over classical computers. Nowadays, there are scientific challenges that are impossible to perform by classical computation due to computational complexity or the time the calculation would take, and quantum computation is one of the possible answers. However, current quantum devices have not yet the necessary qubits and are not fault-tolerant enough to achieve these goals. Nonetheless, there are other fields like machine learning or chemistry where quantum computation could be useful with current quantum devices. This manuscript aims to present a Systematic Literature Review of the papers published between 2017 and 2021 to identify, analyze and classify the different algorithms used in quantum machine learning and their applications. Consequently, this study identified 52 articles that used quantum machine learning techniques and algorithms. The main types of found algorithms are quantum implementations of classical machine learning algorithms, such as support vector machines or the k-nearest neighbor model, and classical deep learning algorithms, like quantum neural networks. Many articles try to solve problems currently answered by classical machine learning but using quantum devices and algorithms. Even though results are promising, quantum machine learning is far from achieving its full potential. An improvement in the quantum hardware is required since the existing quantum computers lack enough quality, speed, and scale to allow quantum computing to achieve its full potential.
Making the most of your day: online learning for optimal allocation of time
Feb 16, 2021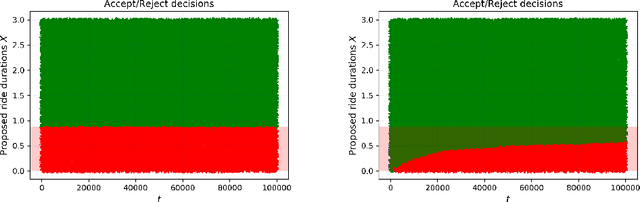
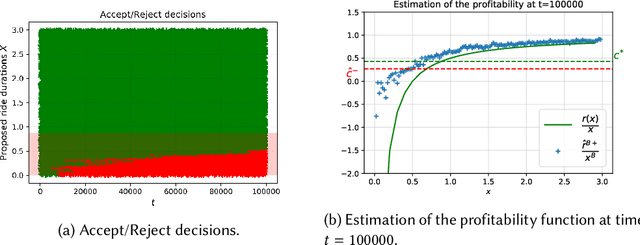
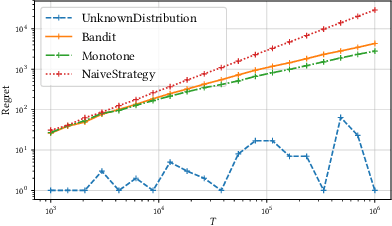
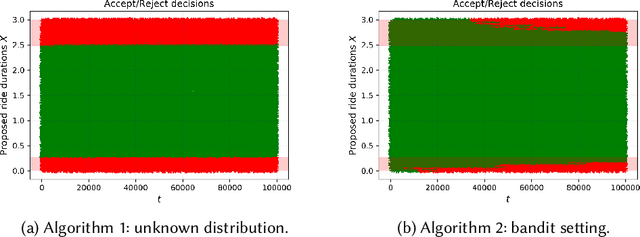
We study online learning for optimal allocation when the resource to be allocated is time. Examples of possible applications include a driver filling a day with rides, a landlord renting an estate, etc. Following our initial motivation, a driver receives ride proposals sequentially according to a Poisson process and can either accept or reject a proposed ride. If she accepts the proposal, she is busy for the duration of the ride and obtains a reward that depends on the ride duration. If she rejects it, she remains on hold until a new ride proposal arrives. We study the regret incurred by the driver first when she knows her reward function but does not know the distribution of the ride duration, and then when she does not know her reward function, either. Faster rates are finally obtained by adding structural assumptions on the distribution of rides or on the reward function. This natural setting bears similarities with contextual (one-armed) bandits, but with the crucial difference that the normalized reward associated to a context depends on the whole distribution of contexts.