 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Classification on Sentence Embeddings for Legal Assistance
Feb 05, 2022
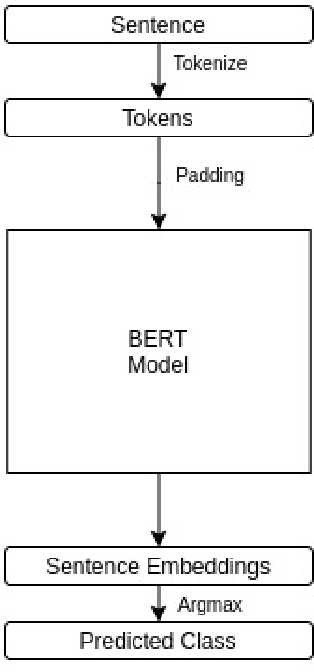
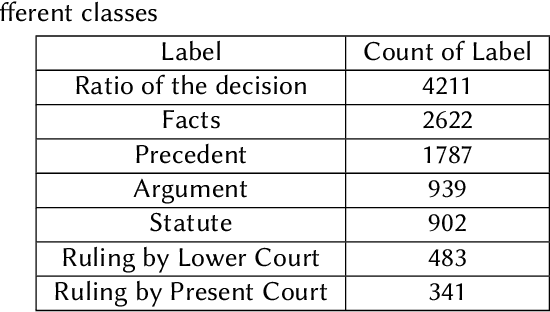
Legal proceedings take plenty of time and also cost a lot. The lawyers have to do a lot of work in order to identify the different sections of prior cases and statutes. The paper tries to solve the first tasks in AILA2021 (Artificial Intelligence for Legal Assistance) that will be held in FIRE2021 (Forum for Information Retrieval Evaluation). The task is to semantically segment the document into different assigned one of the 7 predefined labels or "rhetorical roles." The paper uses BERT to obtain the sentence embeddings from a sentence, and then a linear classifier is used to output the final prediction. The experiments show that when more weightage is assigned to the class with the highest frequency, the results are better than those when more weightage is given to the class with a lower frequency. In task 1, the team legalNLP obtained a F1 score of 0.22.
TransDARC: Transformer-based Driver Activity Recognition with Latent Space Feature Calibration
Mar 02, 2022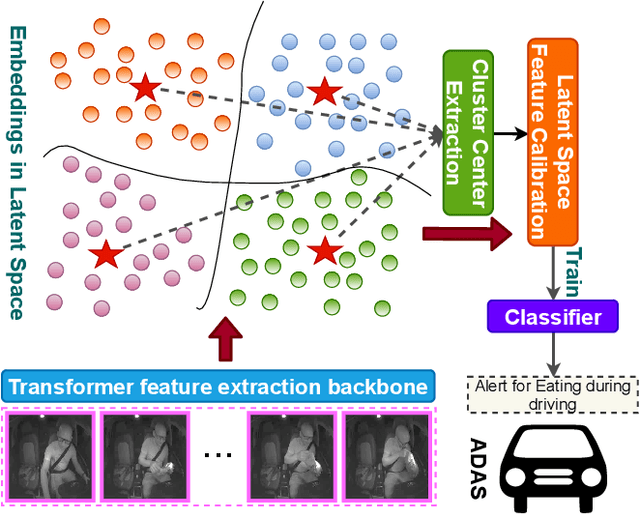
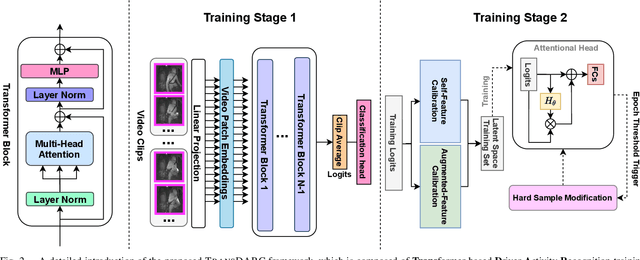
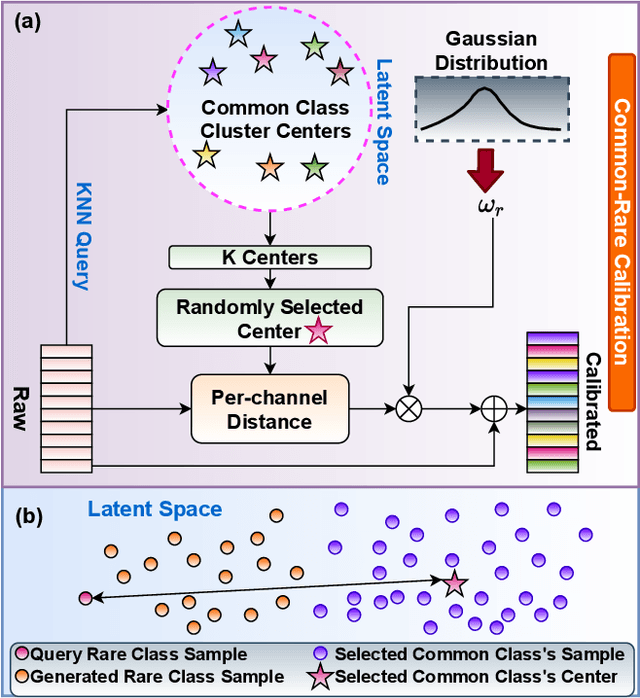
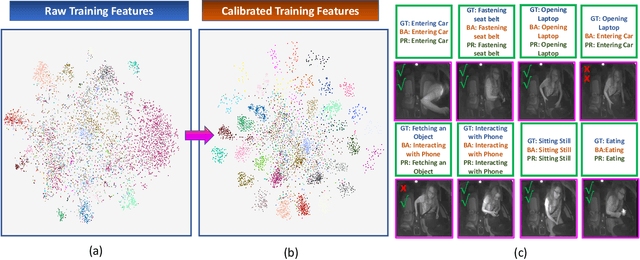
Traditional video-based human activity recognition has experienced remarkable progress linked to the rise of deep learning, but this effect was slower as it comes to the downstream task of driver behavior understanding. Understanding the situation inside the vehicle cabin is essential for Advanced Driving Assistant System (ADAS) as it enables identifying distraction, predicting driver's intent and leads to more convenient human-vehicle interaction. At the same time, driver observation systems face substantial obstacles as they need to capture different granularities of driver states, while the complexity of such secondary activities grows with the rising automation and increased driver freedom. Furthermore, a model is rarely deployed under conditions identical to the ones in the training set, as sensor placements and types vary from vehicle to vehicle, constituting a substantial obstacle for real-life deployment of data-driven models. In this work, we present a novel vision-based framework for recognizing secondary driver behaviours based on visual transformers and an additional augmented feature distribution calibration module. This module operates in the latent feature-space enriching and diversifying the training set at feature-level in order to improve generalization to novel data appearances, (e.g., sensor changes) and general feature quality. Our framework consistently leads to better recognition rates, surpassing previous state-of-the-art results of the public Drive&Act benchmark on all granularity levels. Our code will be made publicly available at https://github.com/KPeng9510/TransDARC.
FAST-LIVO: Fast and Tightly-coupled Sparse-Direct LiDAR-Inertial-Visual Odometry
Mar 02, 2022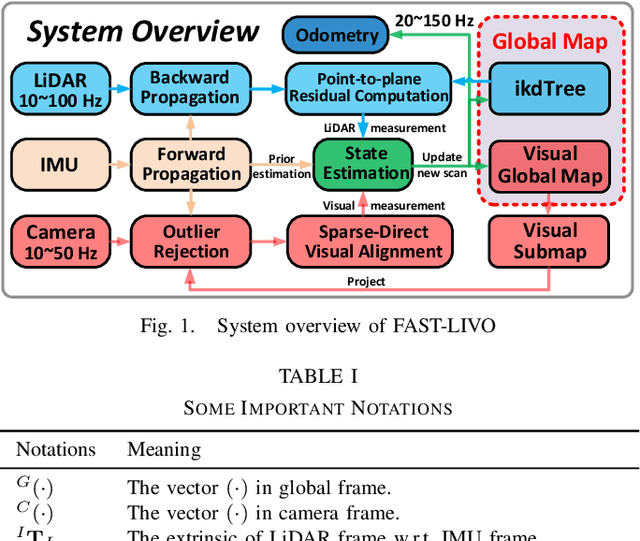
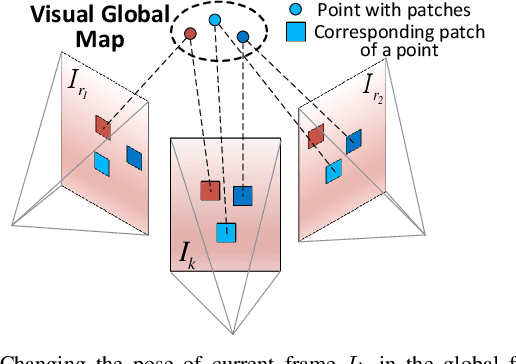
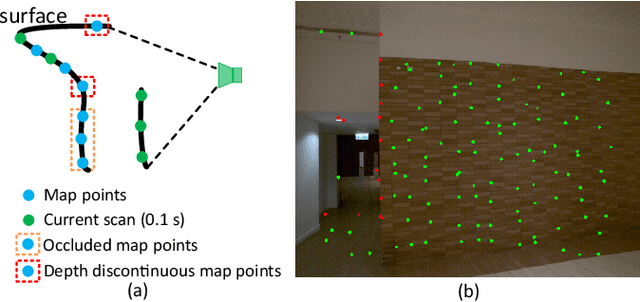
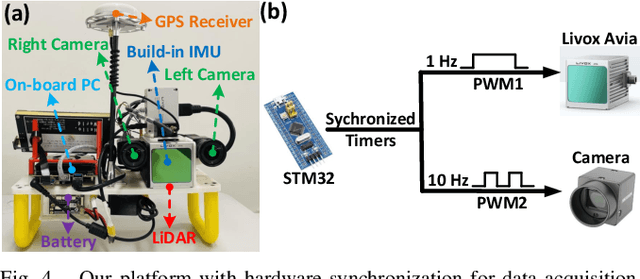
To achieve accurate and robust pose estimation in Simultaneous Localization and Mapping (SLAM) task, multi-sensor fusion is proven to be an effective solution and thus provides great potential in robotic applications. This paper proposes FAST-LIVO, a fast LiDAR-Inertial-Visual Odometry system, which builds on two tightly-coupled and direct odometry subsystems: a VIO subsystem and a LIO subsystem. The LIO subsystem registers raw points (instead of feature points on e.g., edges or planes) of a new scan to an incrementally-built point cloud map. The map points are additionally attached with image patches, which are then used in the VIO subsystem to align a new image by minimizing the direct photometric errors without extracting any visual features (e.g., ORB or FAST corner features). To further improve the VIO robustness and accuracy, a novel outlier rejection method is proposed to reject unstable map points that lie on edges or are occluded in the image view. Experiments on both open data sequences and our customized device data are conducted. The results show our proposed system outperforms other counterparts and can handle challenging environments at reduced computation cost. The system supports both multi-line spinning LiDARs and emerging solid-state LiDARs with completely different scanning patterns, and can run in real-time on both Intel and ARM processors. We open source our code and dataset of this work on Github to benefit the robotics community.
Modulating Retroreflector Based Free Space Optical Link for UAV-to-Ground Communications
Feb 26, 2022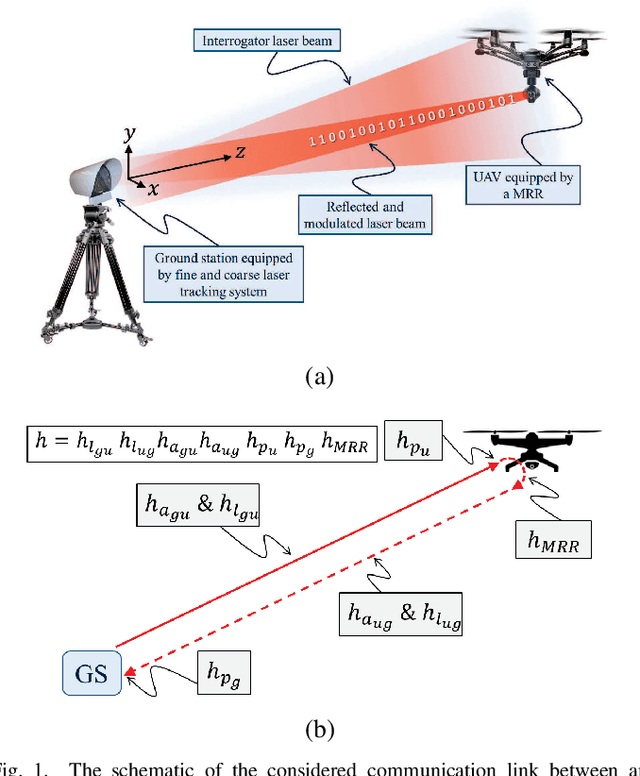
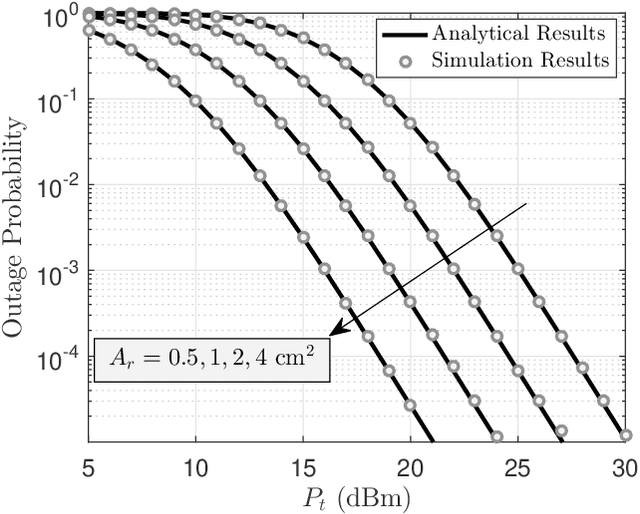
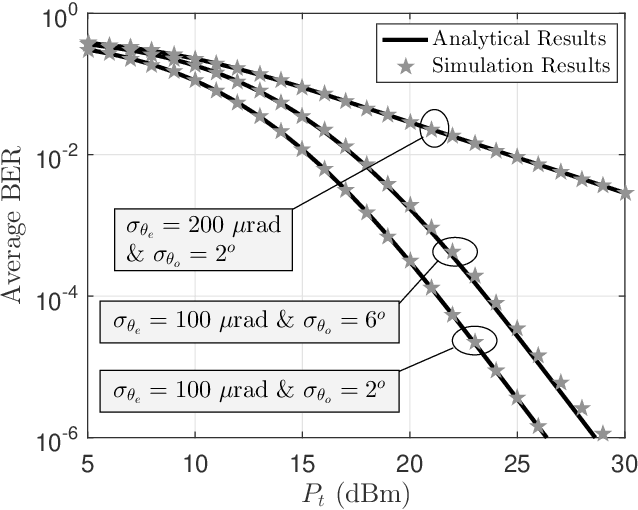
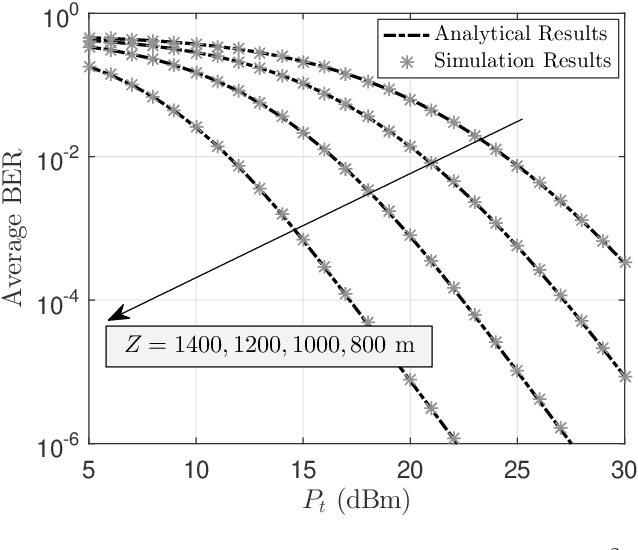
Weight reduction and low power consumption are key requirements in the next generation of unmanned aerial vehicle (UAV) networks. Employing modulating retro-reflector (MRR)-based free space optical (FSO) technology is an innovative technique for UAV-to-ground communication in order to reduce the payload weight and power consumption of UAVs which leads to increased maneuverability and flight time of UAV. In this paper, we consider an MRR-based FSO system for UAV-to-ground communication. We will show that the performance of the considered system is very sensitive to tracking errors. Therefore, to assess the benefits of MRR-based UAV deployment for FSO communications, the MRR-based UAV FSO channel is characterized by taking into account tracking system errors along with UAV's orientation fluctuations, link length, UAV's height, optical beam divergence angle, effective area of MRR, atmospheric turbulence and optical channel loss in the double-pass channels. To enable effective performance analysis, tractable and closed-form expressions are derived for probability density function of end-to-end signal to noise ratio, outage probability and bit error rate of the considered system under both weak-to-moderate and moderate-to-strong atmospheric turbulence conditions. The accuracy of the analytical expressions is verified by extensive simulations. Analytical results are then used to study the relationship between the optimal system design and tracking system errors.
MSCFNet: A Lightweight Network With Multi-Scale Context Fusion for Real-Time Semantic Segmentation
Mar 24, 2021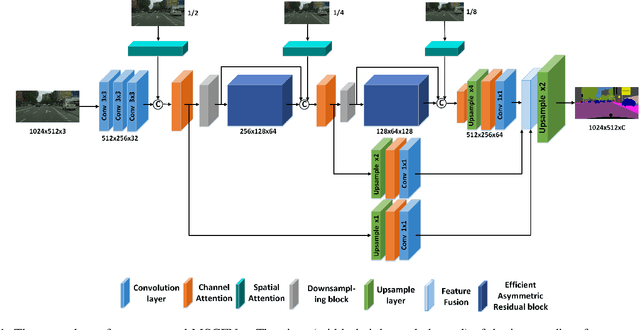
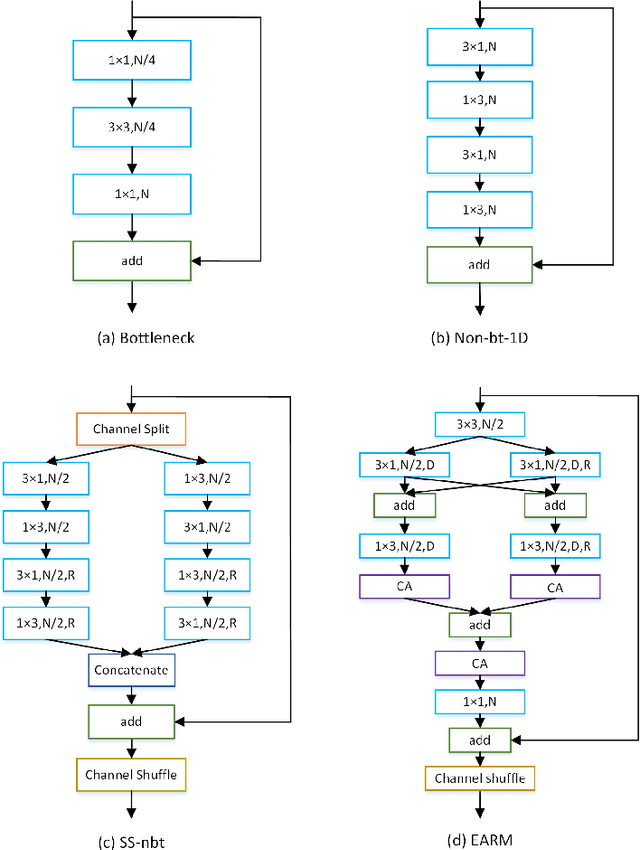
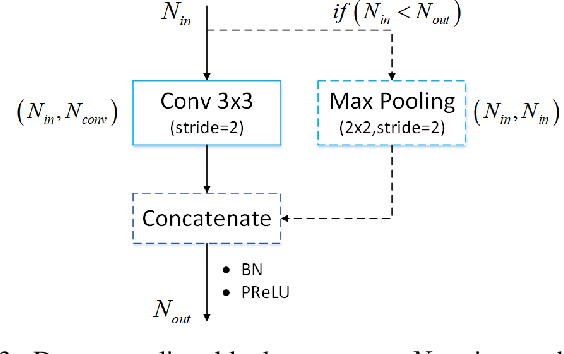
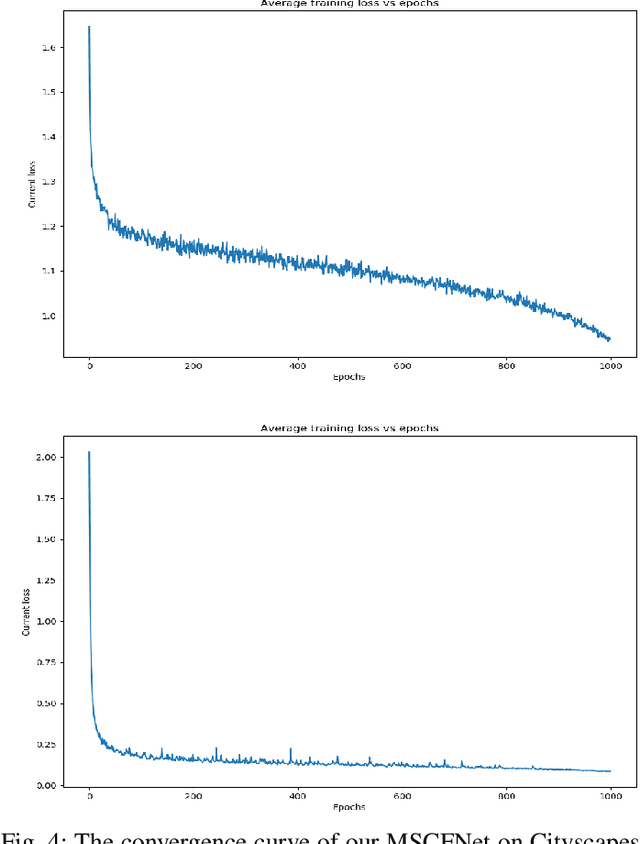
In recent years, how to strike a good trade-off between accuracy and inference speed has become the core issue for real-time semantic segmentation applications, which plays a vital role in real-world scenarios such as autonomous driving systems and drones. In this study, we devise a novel lightweight network using a multi-scale context fusion (MSCFNet) scheme, which explores an asymmetric encoder-decoder architecture to dispose this problem. More specifically, the encoder adopts some developed efficient asymmetric residual (EAR) modules, which are composed of factorization depth-wise convolution and dilation convolution. Meanwhile, instead of complicated computation, simple deconvolution is applied in the decoder to further reduce the amount of parameters while still maintaining high segmentation accuracy. Also, MSCFNet has branches with efficient attention modules from different stages of the network to well capture multi-scale contextual information. Then we combine them before the final classification to enhance the expression of the features and improve the segmentation efficiency. Comprehensive experiments on challenging datasets have demonstrated that the proposed MSCFNet, which contains only 1.15M parameters, achieves 71.9\% Mean IoU on the Cityscapes testing dataset and can run at over 50 FPS on a single Titan XP GPU configuration.
A Group-Equivariant Autoencoder for Identifying Spontaneously Broken Symmetries in the Ising Model
Feb 13, 2022
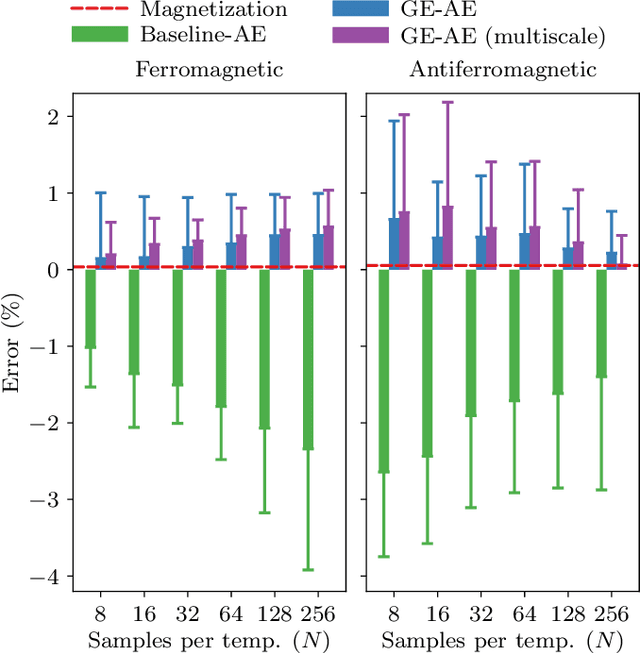
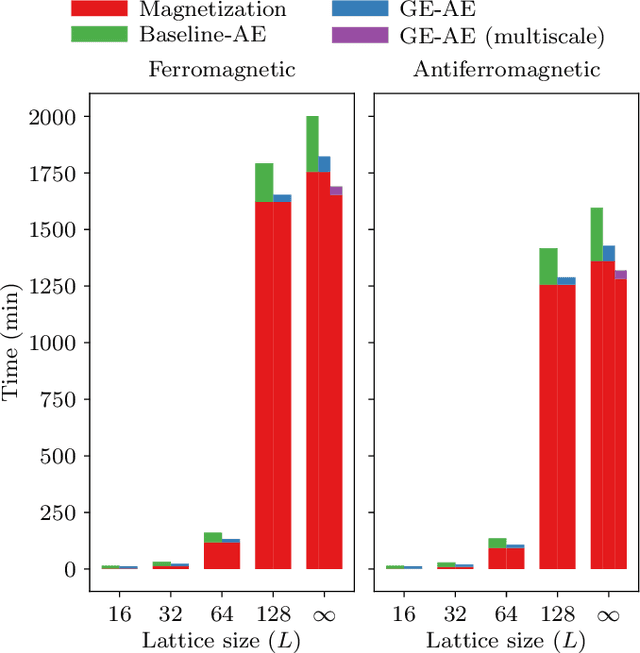
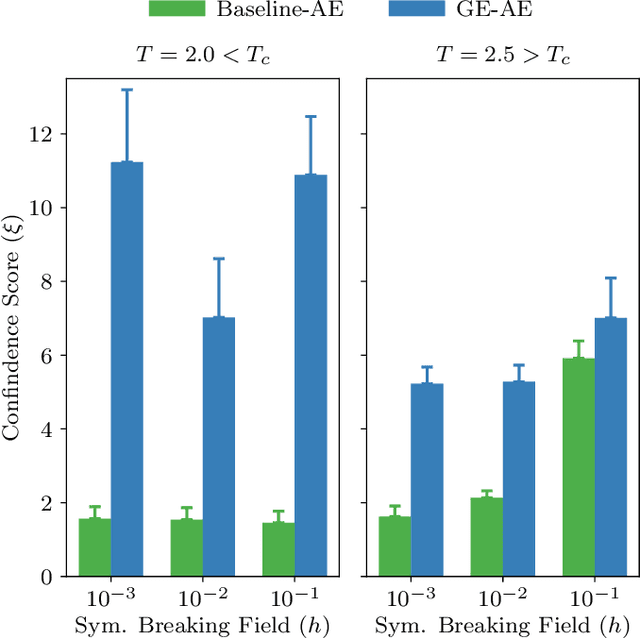
We introduce the group-equivariant autoencoder (GE-autoencoder) -- a novel deep neural network method that locates phase boundaries in the Ising universality class by determining which symmetries of the Hamiltonian are broken at each temperature. The encoder network of the GE-autoencoder models the order parameter observable associated with the phase transition. The parameters of the GE-autoencoder are constrained such that the encoder is invariant to the subgroup of symmetries that never break; this results in a dramatic reduction in the number of free parameters such that the GE-autoencoder size is independent of the system size. The loss function of the GE-autoencoder includes regularization terms that enforce equivariance to the remaining quotient group of symmetries. We test the GE-autoencoder method on the 2D classical ferromagnetic and antiferromagnetic Ising models, finding that the GE-autoencoder (1) accurately determines which symmetries are broken at each temperature, and (2) estimates the critical temperature with greater accuracy and time-efficiency than a symmetry-agnostic autoencoder, once finite-size scaling analysis is taken into account.
Critical Checkpoints for Evaluating Defence Models Against Adversarial Attack and Robustness
Feb 18, 2022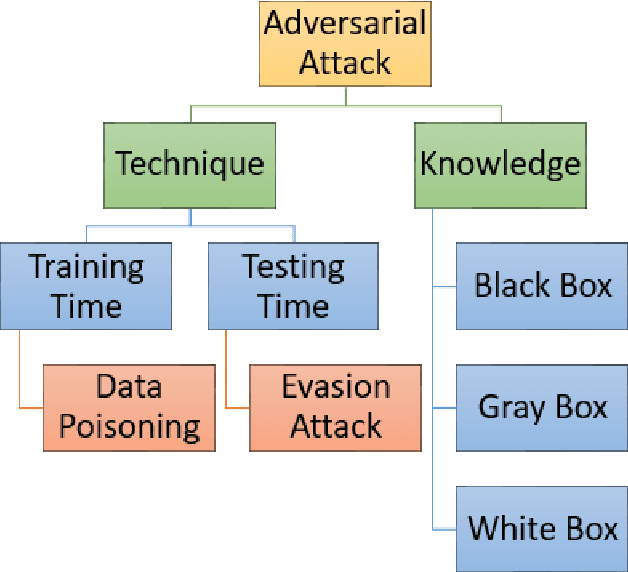
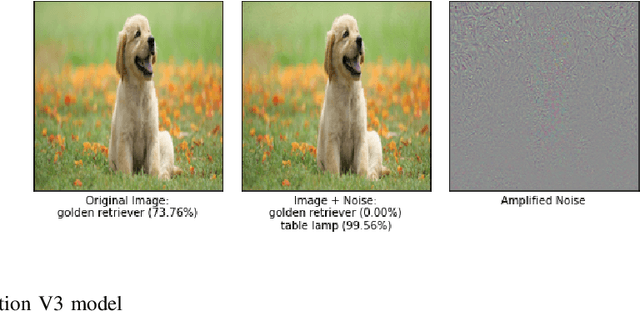

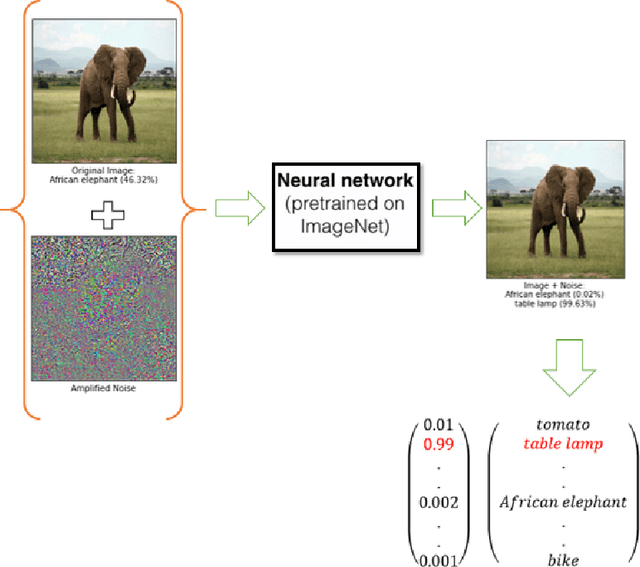
From past couple of years there is a cycle of researchers proposing a defence model for adversaries in machine learning which is arguably defensible to most of the existing attacks in restricted condition (they evaluate on some bounded inputs or datasets). And then shortly another set of researcher finding the vulnerabilities in that defence model and breaking it by proposing a stronger attack model. Some common flaws are been noticed in the past defence models that were broken in very short time. Defence models being broken so easily is a point of concern as decision of many crucial activities are taken with the help of machine learning models. So there is an utter need of some defence checkpoints that any researcher should keep in mind while evaluating the soundness of technique and declaring it to be decent defence technique. In this paper, we have suggested few checkpoints that should be taken into consideration while building and evaluating the soundness of defence models. All these points are recommended after observing why some past defence models failed and how some model remained adamant and proved their soundness against some of the very strong attacks.
Utilizing Out-Domain Datasets to Enhance Multi-Task Citation Analysis
Feb 22, 2022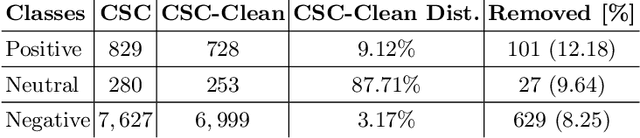
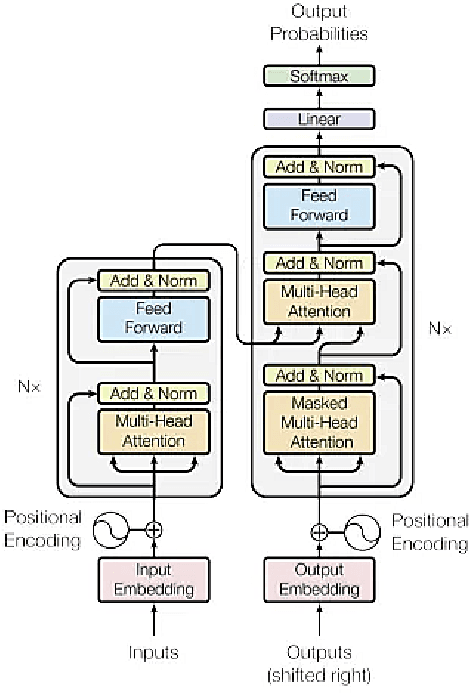
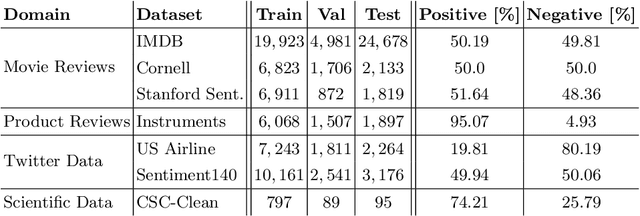
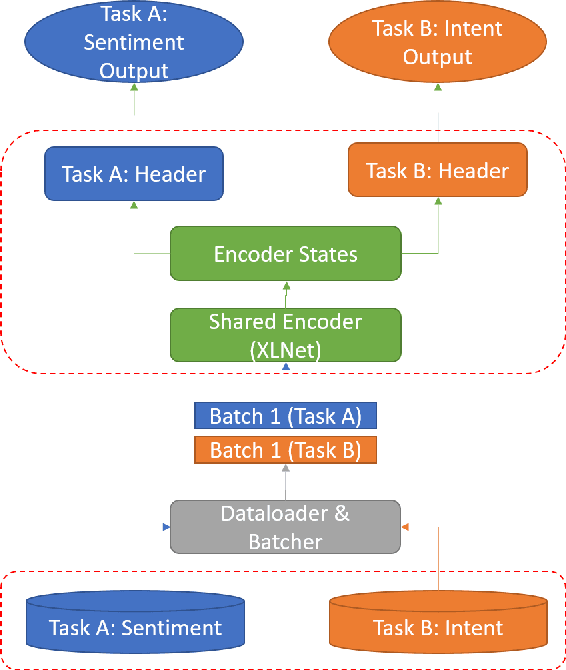
Citations are generally analyzed using only quantitative measures while excluding qualitative aspects such as sentiment and intent. However, qualitative aspects provide deeper insights into the impact of a scientific research artifact and make it possible to focus on relevant literature free from bias associated with quantitative aspects. Therefore, it is possible to rank and categorize papers based on their sentiment and intent. For this purpose, larger citation sentiment datasets are required. However, from a time and cost perspective, curating a large citation sentiment dataset is a challenging task. Particularly, citation sentiment analysis suffers from both data scarcity and tremendous costs for dataset annotation. To overcome the bottleneck of data scarcity in the citation analysis domain we explore the impact of out-domain data during training to enhance the model performance. Our results emphasize the use of different scheduling methods based on the use case. We empirically found that a model trained using sequential data scheduling is more suitable for domain-specific usecases. Conversely, shuffled data feeding achieves better performance on a cross-domain task. Based on our findings, we propose an end-to-end trainable multi-task model that covers the sentiment and intent analysis that utilizes out-domain datasets to overcome the data scarcity.
Data-Consistent Local Superresolution for Medical Imaging
Feb 22, 2022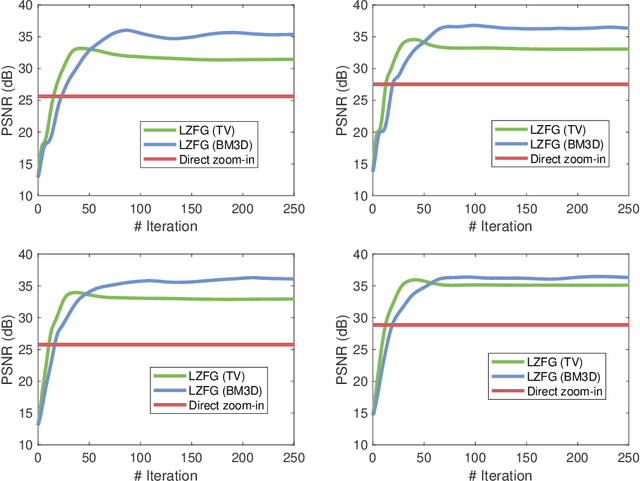
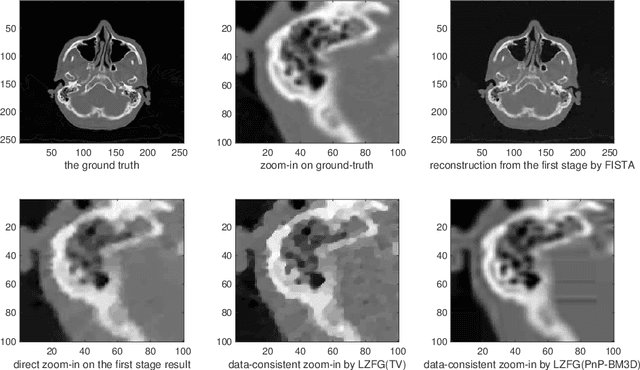
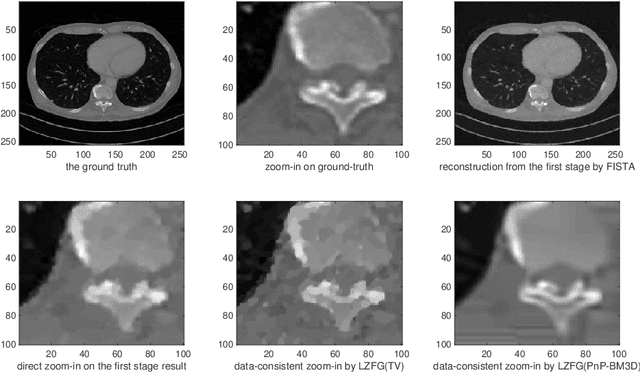

In this work we propose a new paradigm of iterative model-based reconstruction algorithms for providing real-time solution for zooming-in and refining a region of interest in medical and clinical tomographic (such as CT/MRI/PET, etc) images. This algorithmic framework is tailor for a clinical need in medical imaging practice, that after a reconstruction of the full tomographic image, the clinician may believe that some critical parts of the image are not clear enough, and may wish to see clearer these regions-of-interest. A naive approach (which is highly not recommended) would be performing the global reconstruction of a higher resolution image, which has two major limitations: firstly, it is computationally inefficient, and secondly, the image regularization is still applied globally which may over-smooth some local regions. Furthermore if one wish to fine-tune the regularization parameter for local parts, it would be computationally infeasible in practice for the case of using global reconstruction. Our new iterative approaches for such tasks are based on jointly utilizing the measurement information, efficient upsampling/downsampling across image spaces, and locally adjusted image prior for efficient and high-quality post-processing. The numerical results in low-dose X-ray CT image local zoom-in demonstrate the effectiveness of our approach.
Don't Be So Dense: Sparse-to-Sparse GAN Training Without Sacrificing Performance
Mar 05, 2022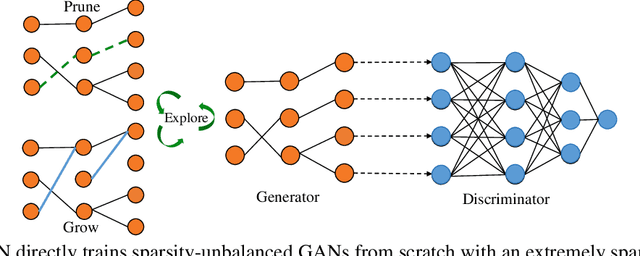
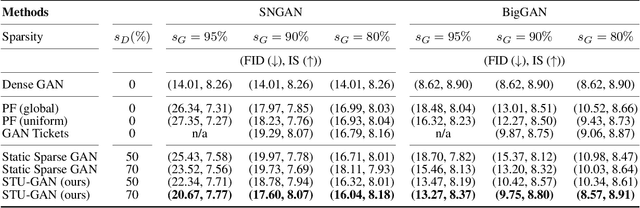
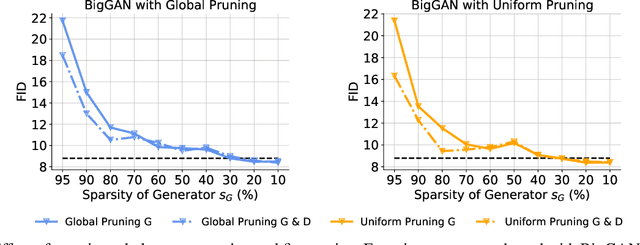
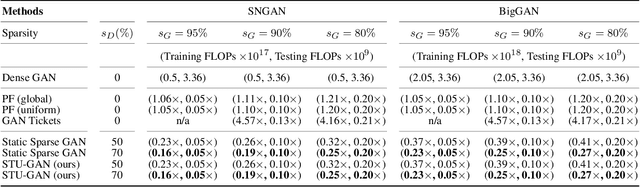
Generative adversarial networks (GANs) have received an upsurging interest since being proposed due to the high quality of the generated data. While achieving increasingly impressive results, the resource demands associated with the large model size hinders the usage of GANs in resource-limited scenarios. For inference, the existing model compression techniques can reduce the model complexity with comparable performance. However, the training efficiency of GANs has less been explored due to the fragile training process of GANs. In this paper, we, for the first time, explore the possibility of directly training sparse GAN from scratch without involving any dense or pre-training steps. Even more unconventionally, our proposed method enables directly training sparse unbalanced GANs with an extremely sparse generator from scratch. Instead of training full GANs, we start with sparse GANs and dynamically explore the parameter space spanned over the generator throughout training. Such a sparse-to-sparse training procedure enhances the capacity of the highly sparse generator progressively while sticking to a fixed small parameter budget with appealing training and inference efficiency gains. Extensive experiments with modern GAN architectures validate the effectiveness of our method. Our sparsified GANs, trained from scratch in one single run, are able to outperform the ones learned by expensive iterative pruning and re-training. Perhaps most importantly, we find instead of inheriting parameters from expensive pre-trained GANs, directly training sparse GANs from scratch can be a much more efficient solution. For example, only training with a 80% sparse generator and a 70% sparse discriminator, our method can achieve even better performance than the dense BigGAN.