 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modular multi-source prediction of drug side-effects with DruGNN
Feb 15, 2022
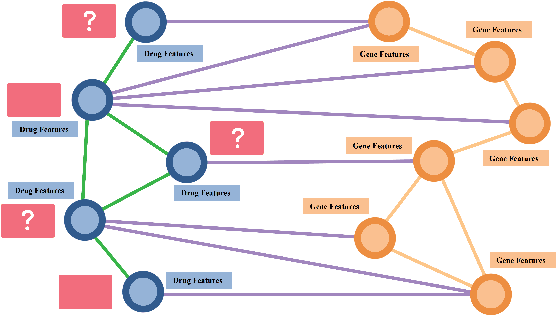
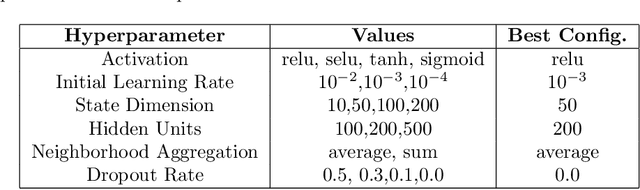
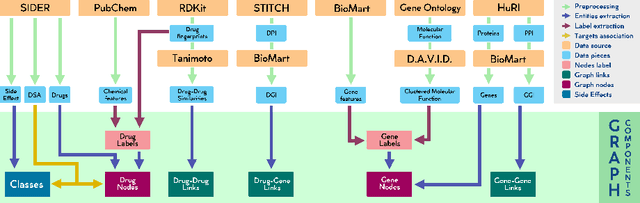

Drug Side-Effects (DSEs) have a high impact on public health, care system costs, and drug discovery processes. Predicting the probability of side-effects, before their occurrence, is fundamental to reduce this impact, in particular on drug discovery. Candidate molecules could be screened before undergoing clinical trials, reducing the costs in time, money, and health of the participants. Drug side-effects are triggered by complex biological processes involving many different entities, from drug structures to protein-protein interactions. To predict their occurrence, it is necessary to integrate data from heterogeneous sources. In this work, such heterogeneous data is integrated into a graph dataset, expressively representing the relational information between different entities, such as drug molecules and genes. The relational nature of the dataset represents an important novelty for drug side-effect predictors. Graph Neural Networks (GNNs) are exploited to predict DSEs on our dataset with very promising results. GNNs are deep learning models that can process graph-structured data, with minimal information loss, and have been applied on a wide variety of biological tasks. Our experimental results confirm the advantage of using relationships between data entities, suggesting interesting future developments in this scope. The experimentation also shows the importance of specific subsets of data in determining associations between drugs and side-effects.
Le Processus Powered Dirichlet-Hawkes comme A Priori Flexible pour Clustering Temporel de Textes
Jan 29, 2022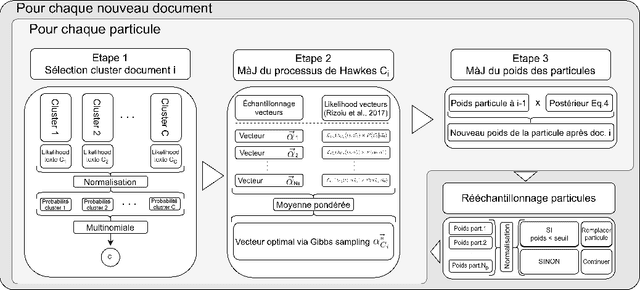
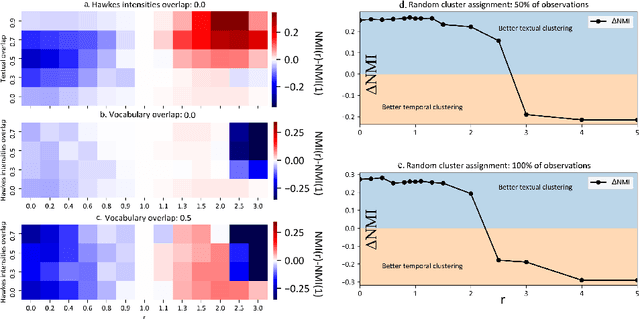
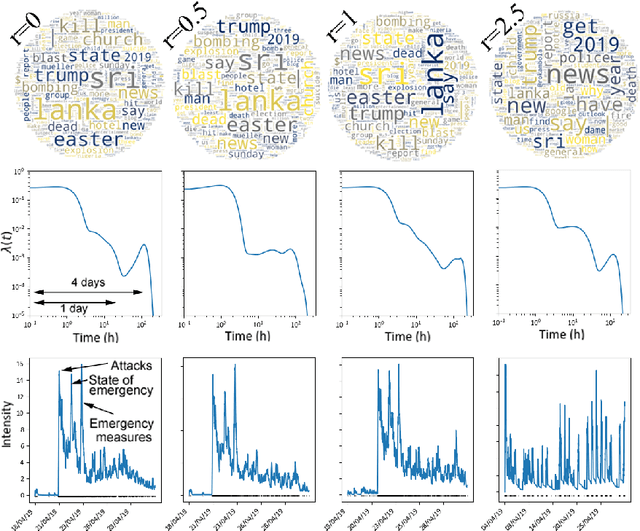
The textual content of a document and its publication date are intertwined. For example, the publication of a news article on a topic is influenced by previous publications on similar issues, according to underlying temporal dynamics. However, it can be challenging to retrieve meaningful information when textual information conveys little. Furthermore, the textual content of a document is not always correlated to its temporal dynamics. We develop a method to create clusters of textual documents according to both their content and publication time, the Powered Dirichlet-Hawkes process (PDHP). PDHP yields significantly better results than state-of-the-art models when temporal information or textual content is weakly informative. PDHP also alleviates the hypothesis that textual content and temporal dynamics are perfectly correlated. We demonstrate that PDHP generalizes previous work --such as DHP and UP. Finally, we illustrate a possible application using a real-world dataset from Reddit.
SMTNet: Hierarchical cavitation intensity recognition based on sub-main transfer network
Mar 01, 2022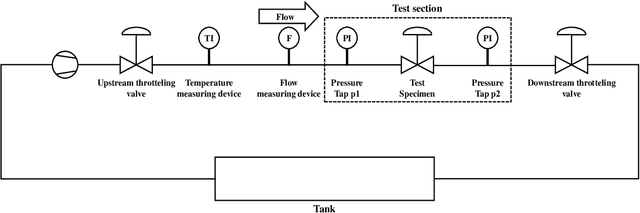

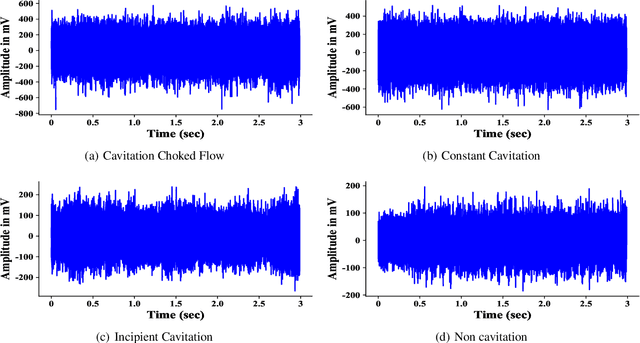
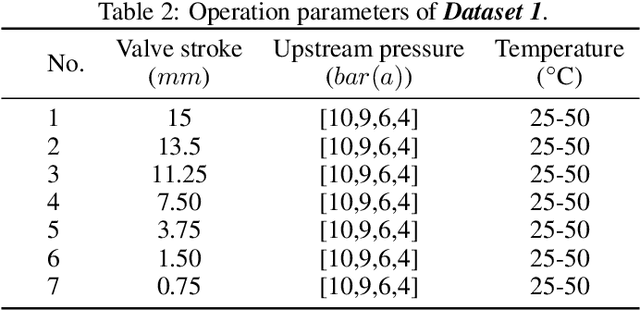
With the rapid development of smart manufacturing, data-driven machinery health management has been of growing attention. In situations where some classes are more difficult to be distinguished compared to others and where classes might be organised in a hierarchy of categories, current DL methods can not work well. In this study, a novel hierarchical cavitation intensity recognition framework using Sub-Main Transfer Network, termed SMTNet, is proposed to classify acoustic signals of valve cavitation. SMTNet model outputs multiple predictions ordered from coarse to fine along a network corresponding to a hierarchy of target cavitation states. Firstly, a data augmentation method based on Sliding Window with Fast Fourier Transform (Swin-FFT) is developed to solve few-shot problem. Secondly, a 1-D double hierarchical residual block (1-D DHRB) is presented to capture sensitive features of the frequency domain valve acoustic signals. Thirdly, hierarchical multi-label tree is proposed to assist the embedding of the semantic structure of target cavitation states into SMTNet. Fourthly, experience filtering mechanism is proposed to fully learn a prior knowledge of cavitation detection model. Finally, SMTNet has been evaluated on two cavitation datasets without noise (Dataset 1 and Dataset 2), and one cavitation dataset with real noise (Dataset 3) provided by SAMSON AG (Frankfurt). The prediction accurcies of SMTNet for cavitation intensity recognition are as high as 95.32%, 97.16% and 100%, respectively. At the same time, the testing accuracies of SMTNet for cavitation detection are as high as 97.02%, 97.64% and 100%. In addition, SMTNet has also been tested for different frequencies of samples and has achieved excellent results of the highest frequency of samples of mobile phones.
Real time implementation of CTRNN and BPTT algorithm to learn on-line biped robot balance: Experiments on the standing posture
Nov 13, 2020This paper describes experimental results regarding the real time implementation of continuous time recurrent neural networks (CTRNN) and the dynamic back-propagation through time (BPTT) algorithm for the on-line learning control laws. Experiments are carried out to control the balance of a biped robot prototype in its standing posture. The neural controller is trained to compensate for external perturbations by controlling the torso's joint motions. Algorithms are embedded in the real time electronic unit of the robot. On-line learning implementations are presented in detail. The results on learning behavior and control performance demonstrate the strength and the efficiency of the proposed approach.
Runtime Monitoring and Statistical Approaches for Correlation Analysis of ECG and PPG
Jan 20, 2022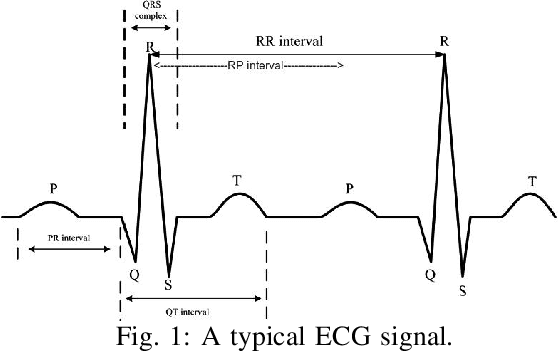
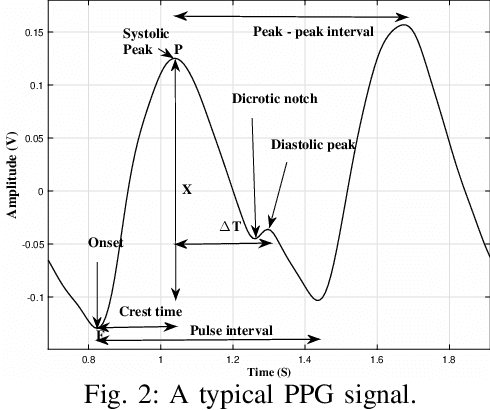
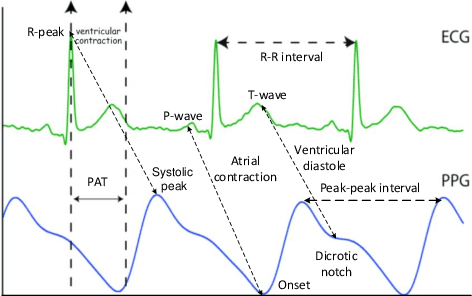
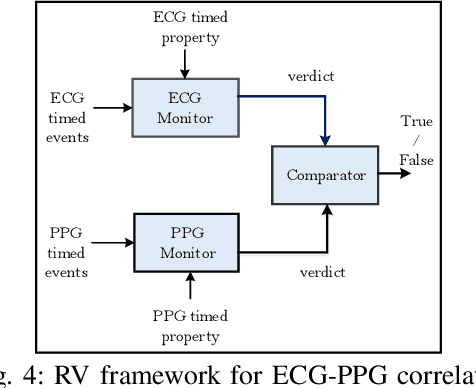
Biophysical signals such as Electrocardiogram (ECG) and Photoplethysmogram (PPG) are key to the sensing of vital parameters for wellbeing. Coincidentally, ECG and PPG are signals, which provide a "different window" into the same phenomena, namely the cardiac cycle. While they are used separately, there are no studies regarding the exact correction of the different ECG and PPG events. Such correlation would be helpful in many fronts such as sensor fusion for improved accuracy using cheaper sensors and attack detection and mitigation methods using multiple signals to enhance the robustness, for example. Considering this, we present the first approach in formally establishing the key relationships between ECG and PPG signals. We combine formal run-time monitoring with statistical analysis and regression analysis for our results.
Reinforcement Learning based dynamic weighing of Ensemble Models for Time Series Forecasting
Aug 20, 2020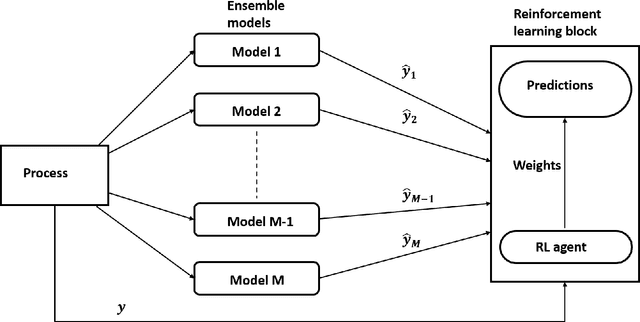
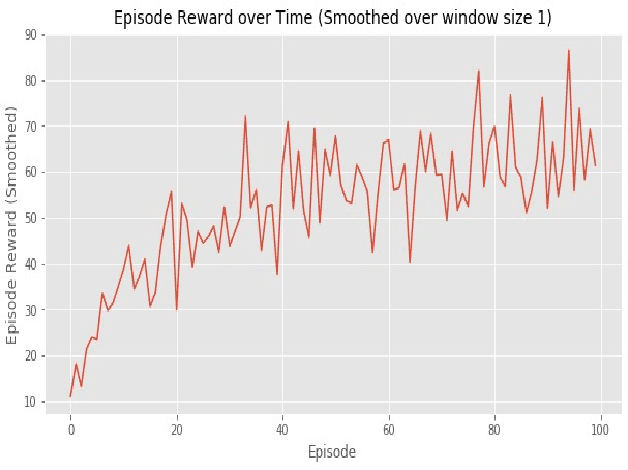
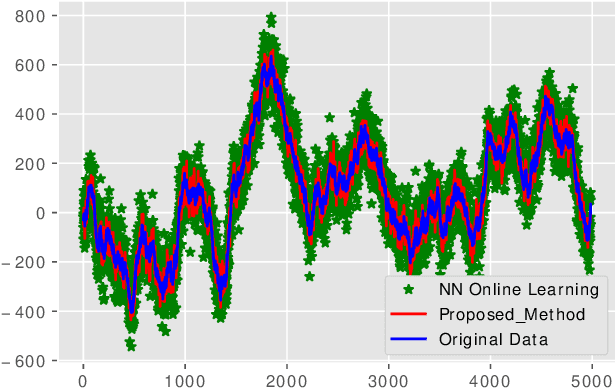
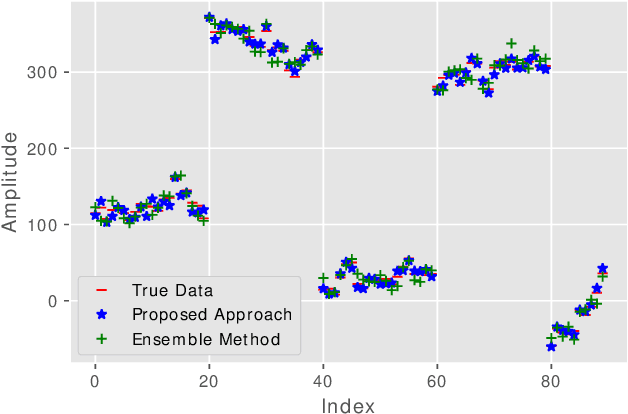
Ensemble models are powerful model building tools that are developed with a focus to improve the accuracy of model predictions. They find applications in time series forecasting in varied scenarios including but not limited to process industries, health care, and economics where a single model might not provide optimal performance. It is known that if models selected for data modelling are distinct (linear/non-linear, static/dynamic) and independent (minimally correlated models), the accuracy of the predictions is improved. Various approaches suggested in the literature to weigh the ensemble models use a static set of weights. Due to this limitation, approaches using a static set of weights for weighing ensemble models cannot capture the dynamic changes or local features of the data effectively. To address this issue, a Reinforcement Learning (RL) approach to dynamically assign and update weights of each of the models at different time instants depending on the nature of data and the individual model predictions is proposed in this work. The RL method implemented online, essentially learns to update the weights and reduce the errors as the time progresses. Simulation studies on time series data showed that the dynamic weighted approach using RL learns the weight better than existing approaches. The accuracy of the proposed method is compared with an existing approach of online Neural Network tuning quantitatively through normalized mean square error(NMSE) values.
Integrated Multiscale Domain Adaptive YOLO
Feb 10, 2022
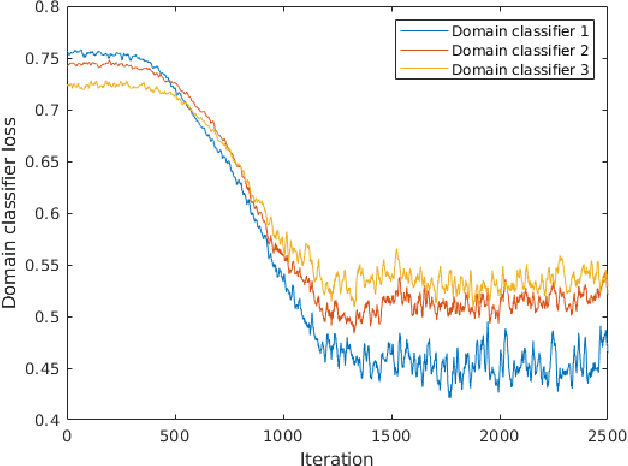
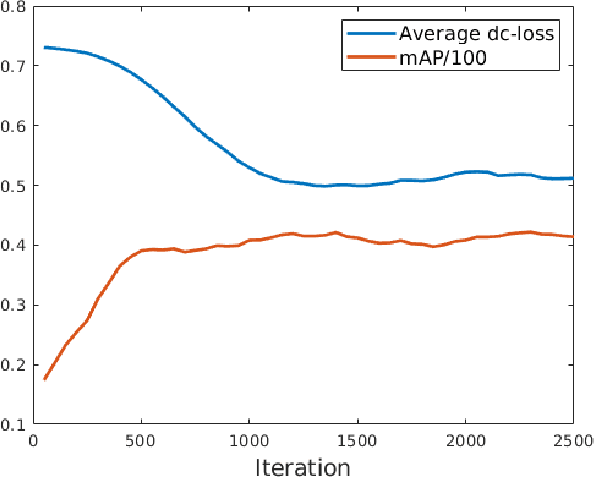
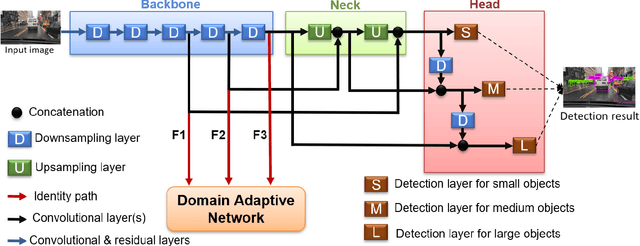
The area of domain adaptation has been instrumental in addressing the domain shift problem encountered by many applications. This problem arises due to the difference between the distributions of source data used for training in comparison with target data used during realistic testing scenarios. In this paper, we introduce a novel MultiScale Domain Adaptive YOLO (MS-DAYOLO) framework that employs multiple domain adaptation paths and corresponding domain classifiers at different scales of the recently introduced YOLOv4 object detector. Building on our baseline multiscale DAYOLO framework, we introduce three novel deep learning architectures for a Domain Adaptation Network (DAN) that generates domain-invariant features. In particular, we propose a Progressive Feature Reduction (PFR), a Unified Classifier (UC), and an Integrated architecture. We train and test our proposed DAN architectures in conjunction with YOLOv4 using popular datasets. Our experiments show significant improvements in object detection performance when training YOLOv4 using the proposed MS-DAYOLO architectures and when tested on target data for autonomous driving applications. Moreover, MS-DAYOLO framework achieves an order of magnitude real-time speed improvement relative to Faster R-CNN solutions while providing comparable object detection performance.
ItôWave: Itô Stochastic Differential Equation Is All You Need For Wave Generation
Jan 29, 2022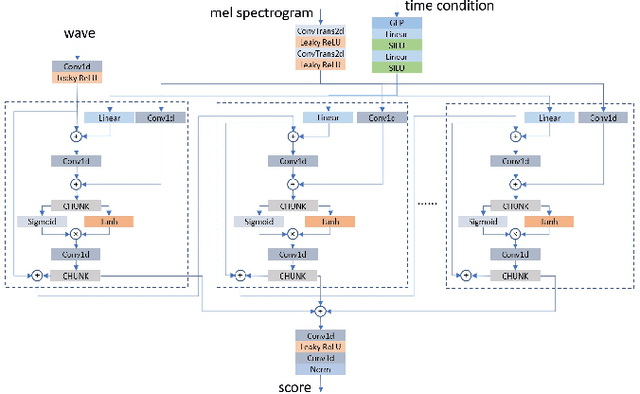
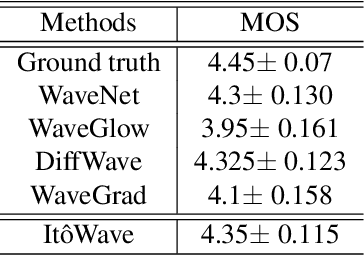
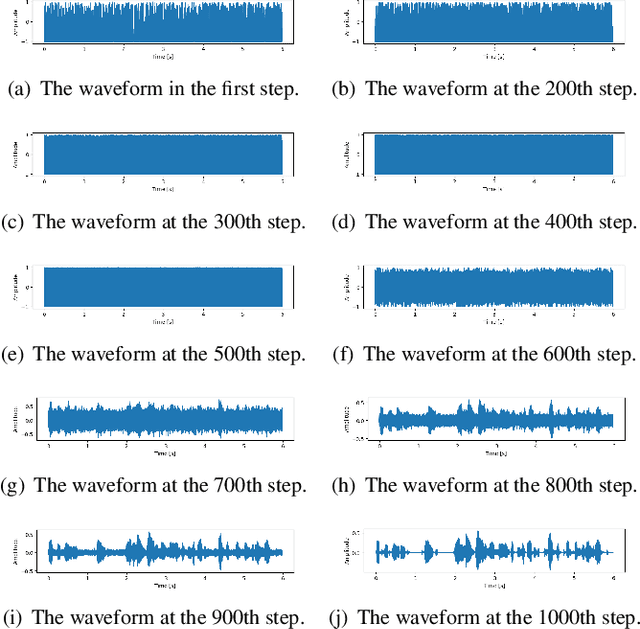
In this paper, we propose a vocoder based on a pair of forward and reverse-time linear stochastic differential equations (SDE). The solutions of this SDE pair are two stochastic processes, one of which turns the distribution of wave, that we want to generate, into a simple and tractable distribution. The other is the generation procedure that turns this tractable simple signal into the target wave. The model is called It\^oWave. It\^oWave use the Wiener process as a driver to gradually subtract the excess signal from the noise signal to generate realistic corresponding meaningful audio respectively, under the conditional inputs of original mel spectrogram. The results of the experiment show that the mean opinion scores (MOS) of It\^oWave can exceed the current state-of-the-art (SOTA) methods, and reached 4.35$\pm$0.115. The generated audio samples are available online\footnotemark[2].
Motion Puzzle: Arbitrary Motion Style Transfer by Body Part
Feb 10, 2022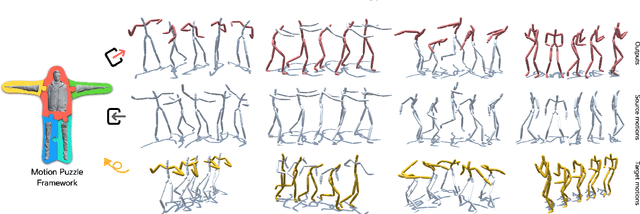
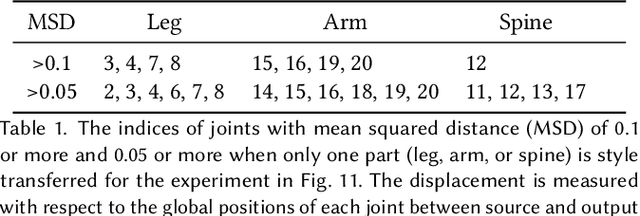
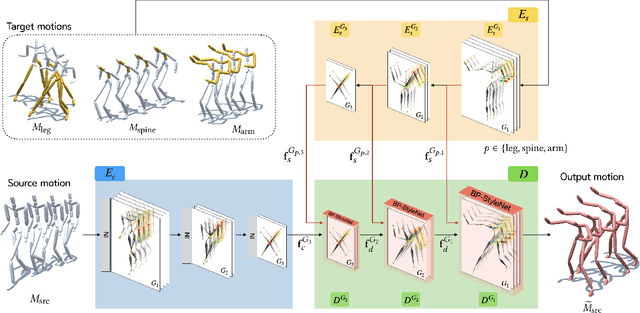

This paper presents Motion Puzzle, a novel motion style transfer network that advances the state-of-the-art in several important respects. The Motion Puzzle is the first that can control the motion style of individual body parts, allowing for local style editing and significantly increasing the range of stylized motions. Designed to keep the human's kinematic structure, our framework extracts style features from multiple style motions for different body parts and transfers them locally to the target body parts. Another major advantage is that it can transfer both global and local traits of motion style by integrating the adaptive instance normalization and attention modules while keeping the skeleton topology. Thus, it can capture styles exhibited by dynamic movements, such as flapping and staggering, significantly better than previous work. In addition, our framework allows for arbitrary motion style transfer without datasets with style labeling or motion pairing, making many publicly available motion datasets available for training. Our framework can be easily integrated with motion generation frameworks to create many applications, such as real-time motion transfer. We demonstrate the advantages of our framework with a number of examples and comparisons with previous work.
* 16 pages
Learning Infinite-Horizon Average-Reward Markov Decision Processes with Constraints
Jan 31, 2022We study regret minimization for infinite-horizon average-reward Markov Decision Processes (MDPs) under cost constraints. We start by designing a policy optimization algorithm with carefully designed action-value estimator and bonus term, and show that for ergodic MDPs, our algorithm ensures $\widetilde{O}(\sqrt{T})$ regret and constant constraint violation, where $T$ is the total number of time steps. This strictly improves over the algorithm of (Singh et al., 2020), whose regret and constraint violation are both $\widetilde{O}(T^{2/3})$. Next, we consider the most general class of weakly communicating MDPs. Through a finite-horizon approximation, we develop another algorithm with $\widetilde{O}(T^{2/3})$ regret and constraint violation, which can be further improved to $\widetilde{O}(\sqrt{T})$ via a simple modification, albeit making the algorithm computationally inefficient. As far as we know, these are the first set of provable algorithms for weakly communicating MDPs with cost constraints.