 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Coordinate in Multi-Agent Systems: A Coordinated Actor-Critic Algorithm and Finite-Time Guarantees
Oct 11, 2021
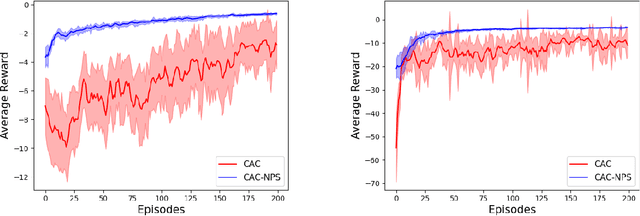
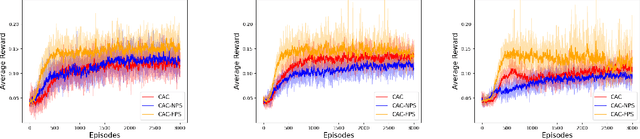
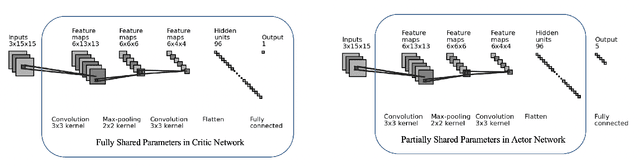
Multi-agent reinforcement learning (MARL) has attracted much research attention recently. However, unlike its single-agent counterpart, many theoretical and algorithmic aspects of MARL have not been well-understood. In this paper, we study the emergence of coordinated behavior by autonomous agents using an actor-critic (AC) algorithm. Specifically, we propose and analyze a class of coordinated actor-critic algorithms (CAC) in which individually parametrized policies have a {\it shared} part (which is jointly optimized among all agents) and a {\it personalized} part (which is only locally optimized). Such kind of {\it partially personalized} policy allows agents to learn to coordinate by leveraging peers' past experience and adapt to individual tasks. The flexibility in our design allows the proposed MARL-CAC algorithm to be used in a {\it fully decentralized} setting, where the agents can only communicate with their neighbors, as well as a {\it federated} setting, where the agents occasionally communicate with a server while optimizing their (partially personalized) local models. Theoretically, we show that under some standard regularity assumptions, the proposed MARL-CAC algorithm requires $\mathcal{O}(\epsilon^{-\frac{5}{2}})$ samples to achieve an $\epsilon$-stationary solution (defined as the solution whose squared norm of the gradient of the objective function is less than $\epsilon$). To the best of our knowledge, this work provides the first finite-sample guarantee for decentralized AC algorithm with partially personalized policies.
Deep EvoGraphNet Architecture For Time-Dependent Brain Graph Data Synthesis From a Single Timepoint
Sep 28, 2020

Learning how to predict the brain connectome (i.e. graph) development and aging is of paramount importance for charting the future of within-disorder and cross-disorder landscape of brain dysconnectivity evolution. Indeed, predicting the longitudinal (i.e., time-dependent ) brain dysconnectivity as it emerges and evolves over time from a single timepoint can help design personalized treatments for disordered patients in a very early stage. Despite its significance, evolution models of the brain graph are largely overlooked in the literature. Here, we propose EvoGraphNet, the first end-to-end geometric deep learning-powered graph-generative adversarial network (gGAN) for predicting time-dependent brain graph evolution from a single timepoint. Our EvoGraphNet architecture cascades a set of time-dependent gGANs, where each gGAN communicates its predicted brain graphs at a particular timepoint to train the next gGAN in the cascade at follow-up timepoint. Therefore, we obtain each next predicted timepoint by setting the output of each generator as the input of its successor which enables us to predict a given number of timepoints using only one single timepoint in an end- to-end fashion. At each timepoint, to better align the distribution of the predicted brain graphs with that of the ground-truth graphs, we further integrate an auxiliary Kullback-Leibler divergence loss function. To capture time-dependency between two consecutive observations, we impose an l1 loss to minimize the sparse distance between two serialized brain graphs. A series of benchmarks against variants and ablated versions of our EvoGraphNet showed that we can achieve the lowest brain graph evolution prediction error using a single baseline timepoint. Our EvoGraphNet code is available at http://github.com/basiralab/EvoGraphNet.
Relative Kinematics Estimation Using Accelerometer Measurements
Dec 14, 2021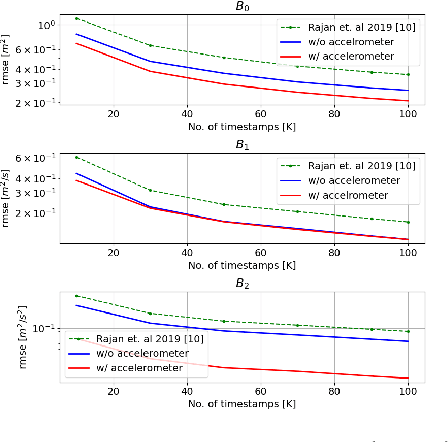
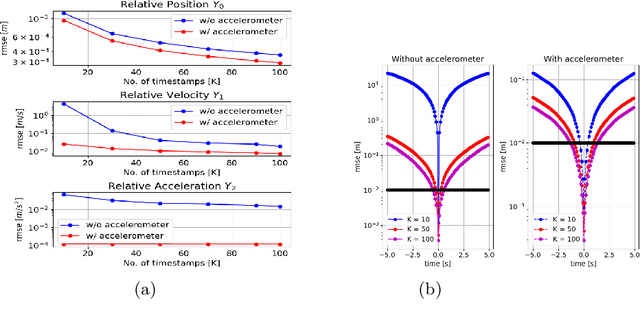
Given a network of $N$ static nodes in $D$-dimensional space and the pairwise distances between them, the challenge of estimating the coordinates of the nodes is a well-studied problem. However, for numerous application domains, the nodes are mobile and the estimation of relative kinematics (e.g., position, velocity and acceleration) is a challenge, which has received limited attention in literature. In this paper, we propose a time-varying Grammian-based data model for estimating the relative kinematics of mobile nodes with polynomial trajectories, given the time-varying pairwise distance measurements between the nodes. Furthermore, we consider a scenario where the nodes have on-board accelerometers, and extend the proposed data model to include these accelerometer measurements. We propose closed-form solutions to estimate the relative kinematics, based on the proposed data models. We conduct simulations to showcase the performance of the proposed estimators, which show improvement against state-of-the-art methods.
GAP: Differentially Private Graph Neural Networks with Aggregation Perturbation
Mar 02, 2022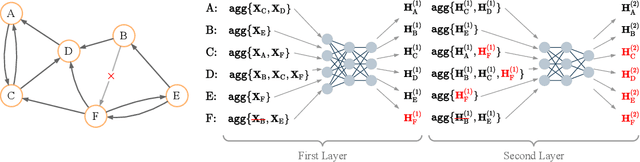

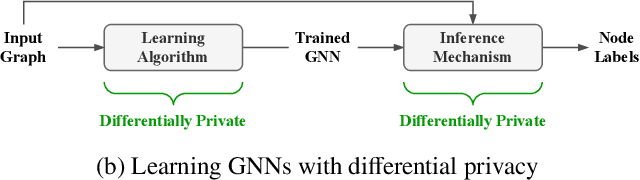
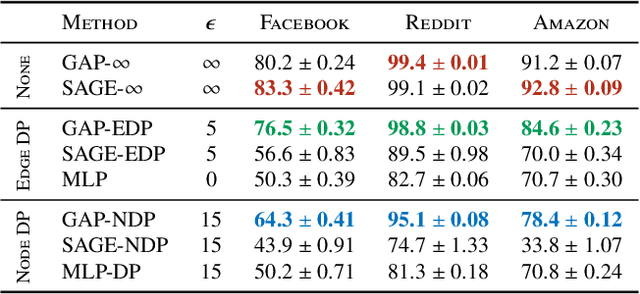
Graph Neural Networks (GNNs) are powerful models designed for graph data that learn node representation by recursively aggregating information from each node's local neighborhood. However, despite their state-of-the-art performance in predictive graph-based applications, recent studies have shown that GNNs can raise significant privacy concerns when graph data contain sensitive information. As a result, in this paper, we study the problem of learning GNNs with Differential Privacy (DP). We propose GAP, a novel differentially private GNN that safeguards the privacy of nodes and edges using aggregation perturbation, i.e., adding calibrated stochastic noise to the output of the GNN's aggregation function, which statistically obfuscates the presence of a single edge (edge-level privacy) or a single node and all its adjacent edges (node-level privacy). To circumvent the accumulation of privacy cost at every forward pass of the model, we tailor the GNN architecture to the specifics of private learning. In particular, we first precompute private aggregations by recursively applying neighborhood aggregation and perturbing the output of each aggregation step. Then, we privately train a deep neural network on the resulting perturbed aggregations for any node-wise classification task. A major advantage of GAP over previous approaches is that we guarantee edge-level and node-level DP not only for training, but also at inference time with no additional costs beyond the training's privacy budget. We theoretically analyze the formal privacy guarantees of GAP using R\'enyi DP. Empirical experiments conducted over three real-world graph datasets demonstrate that GAP achieves a favorable privacy-accuracy trade-off and significantly outperforms existing approaches.
RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
Nov 17, 2020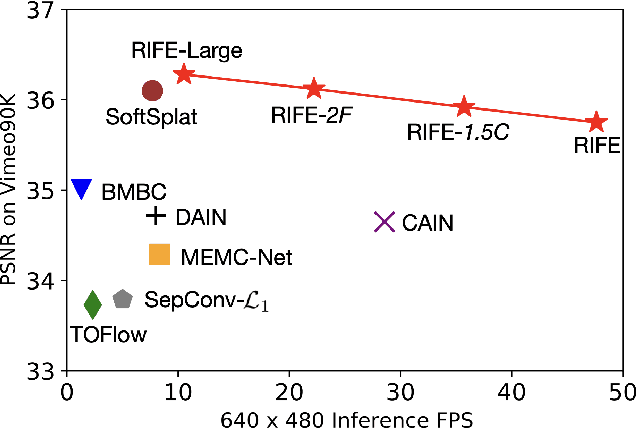

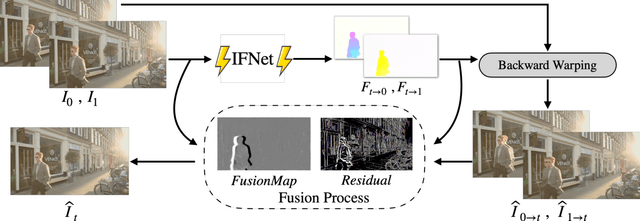
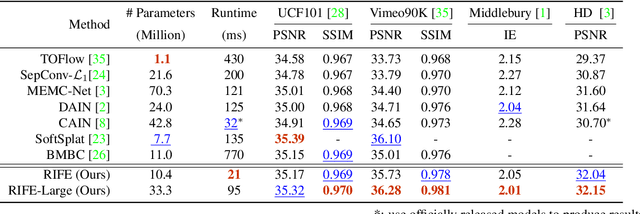
We propose RIFE, a Real-time Intermediate Flow Estimation algorithm for Video Frame Interpolation (VFI). Most existing methods first estimate the bi-directional optical flows and then linearly combine them to approximate intermediate flows, leading to artifacts on motion boundaries. RIFE uses a neural network named IFNet that can directly estimate the intermediate flows from images. With the more precise flows and our simplified fusion process, RIFE can improve interpolation quality and have much better speed. Based on our proposed leakage distillation loss, RIFE can be trained in an end-to-end fashion. Experiments demonstrate that our method is significantly faster than existing VFI methods and can achieve state-of-the-art performance on public benchmarks. The code is available at https://github.com/hzwer/arXiv2020-RIFE.
Proofs and additional experiments on Second order techniques for learning time-series with structural breaks
Dec 15, 2020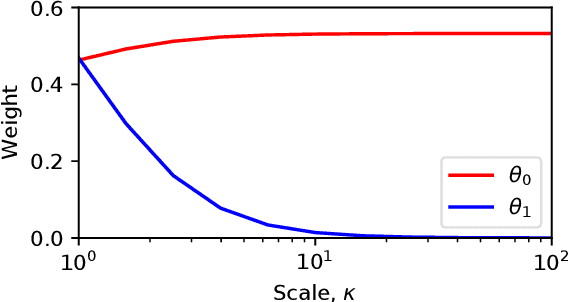
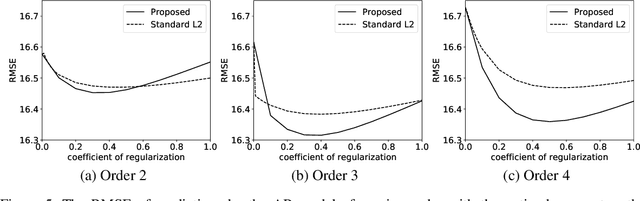
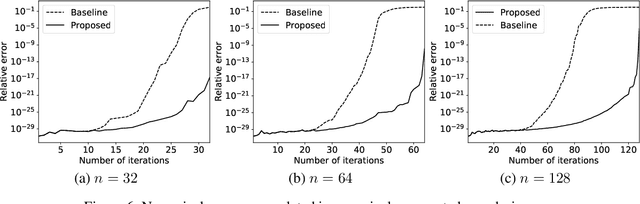
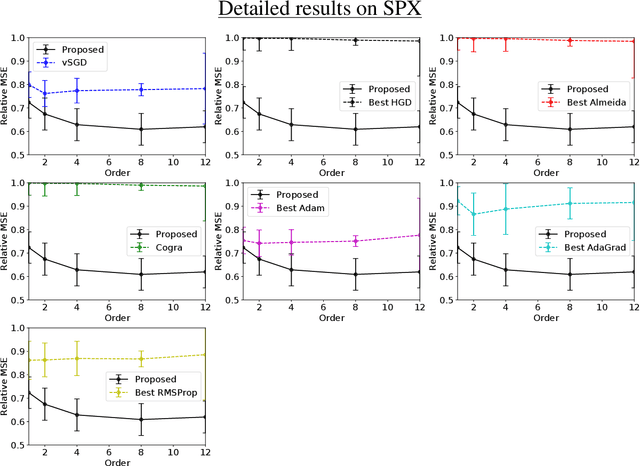
We provide complete proofs of the lemmas about the properties of the regularized loss function that is used in the second order techniques for learning time-series with structural breaks in Osogami (2021). In addition, we show experimental results that support the validity of the techniques.
SegTransVAE: Hybrid CNN -- Transformer with Regularization for medical image segmentation
Jan 21, 2022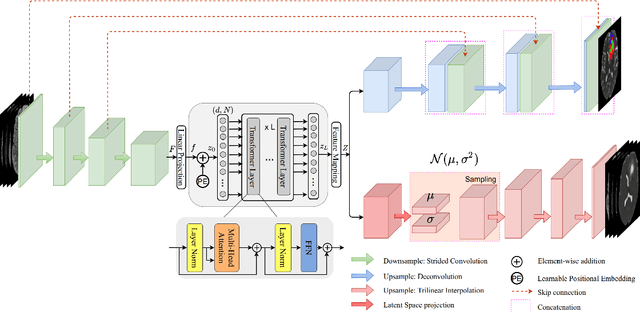
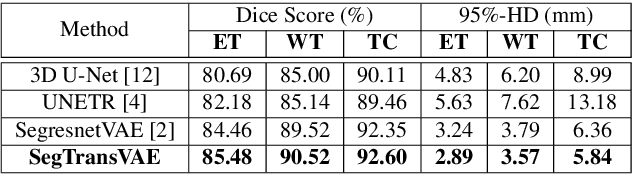
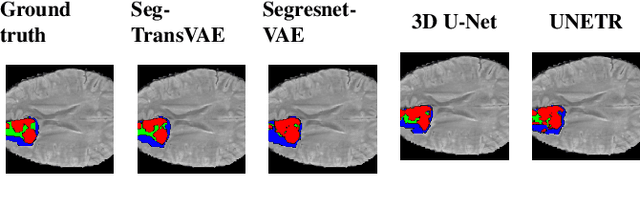
Current research on deep learning for medical image segmentation exposes their limitations in learning either global semantic information or local contextual information. To tackle these issues, a novel network named SegTransVAE is proposed in this paper. SegTransVAE is built upon encoder-decoder architecture, exploiting transformer with the variational autoencoder (VAE) branch to the network to reconstruct the input images jointly with segmentation. To the best of our knowledge, this is the first method combining the success of CNN, transformer, and VAE. Evaluation on various recently introduced datasets shows that SegTransVAE outperforms previous methods in Dice Score and $95\%$-Haudorff Distance while having comparable inference time to a simple CNN-based architecture network. The source code is available at: https://github.com/itruonghai/SegTransVAE.
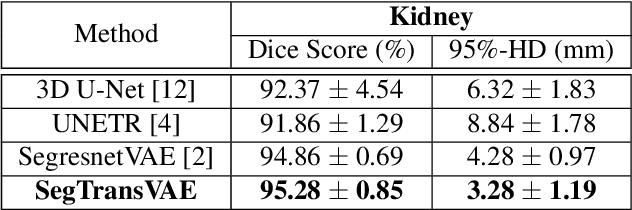
Segmentation and Risk Score Prediction of Head and Neck Cancers in PET/CT Volumes with 3D U-Net and Cox Proportional Hazard Neural Networks
Feb 16, 2022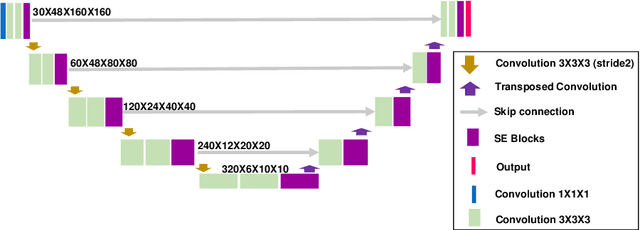
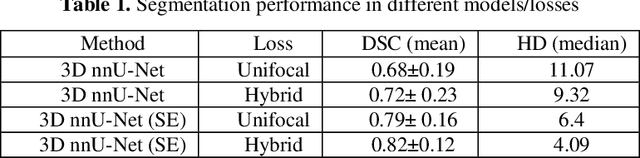
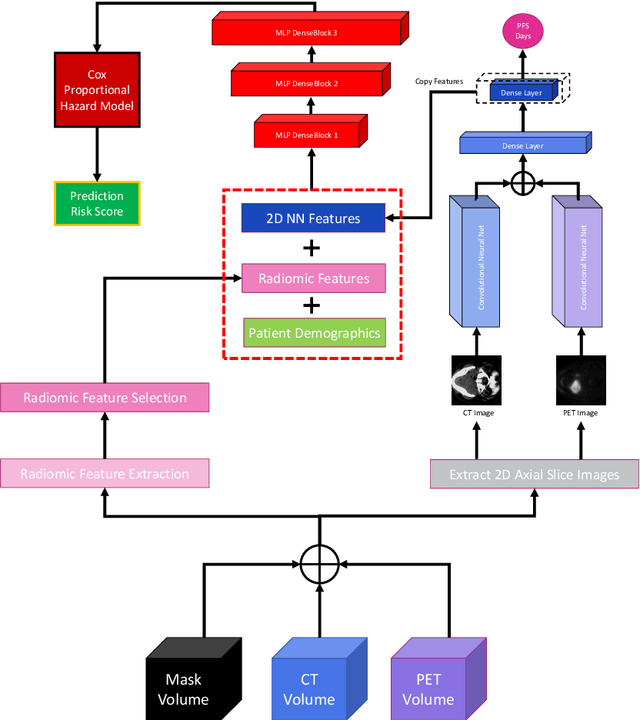
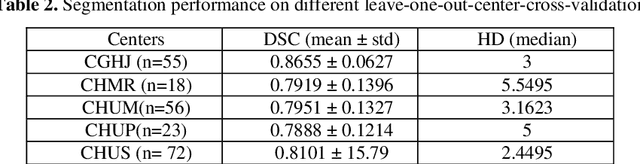
We utilized a 3D nnU-Net model with residual layers supplemented by squeeze and excitation (SE) normalization for tumor segmentation from PET/CT images provided by the Head and Neck Tumor segmentation chal-lenge (HECKTOR). Our proposed loss function incorporates the Unified Fo-cal and Mumford-Shah losses to take the advantage of distribution, region, and boundary-based loss functions. The results of leave-one-out-center-cross-validation performed on different centers showed a segmentation performance of 0.82 average Dice score (DSC) and 3.16 median Hausdorff Distance (HD), and our results on the test set achieved 0.77 DSC and 3.01 HD. Following lesion segmentation, we proposed training a case-control proportional hazard Cox model with an MLP neural net backbone to predict the hazard risk score for each discrete lesion. This hazard risk prediction model (CoxCC) was to be trained on a number of PET/CT radiomic features extracted from the segmented lesions, patient and lesion demographics, and encoder features provided from the penultimate layer of a multi-input 2D PET/CT convolutional neural network tasked with predicting time-to-event for each lesion. A 10-fold cross-validated CoxCC model resulted in a c-index validation score of 0.89, and a c-index score of 0.61 on the HECKTOR challenge test dataset.
Using Deep Learning to Bootstrap Abstractions for Hierarchical Robot Planning
Feb 11, 2022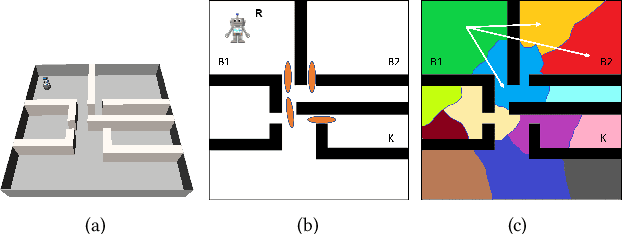
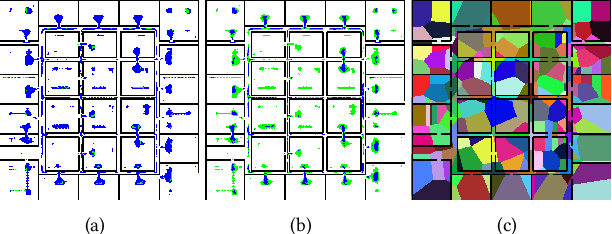
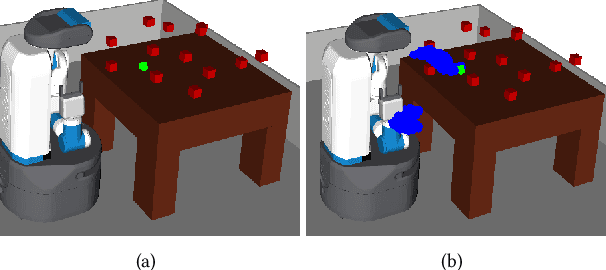
This paper addresses the problem of learning abstractions that boost robot planning performance while providing strong guarantees of reliability. Although state-of-the-art hierarchical robot planning algorithms allow robots to efficiently compute long-horizon motion plans for achieving user desired tasks, these methods typically rely upon environment-dependent state and action abstractions that need to be hand-designed by experts. We present a new approach for bootstrapping the entire hierarchical planning process. This allows us to compute abstract states and actions for new environments automatically using the critical regions predicted by a deep neural network with an auto-generated robot-specific architecture. We show that the learned abstractions can be used with a novel multi-source bi-directional hierarchical robot planning algorithm that is sound and probabilistically complete. An extensive empirical evaluation on twenty different settings using holonomic and non-holonomic robots shows that (a) our learned abstractions provide the information necessary for efficient multi-source hierarchical planning; and that (b) this approach of learning, abstractions, and planning outperforms state-of-the-art baselines by nearly a factor of ten in terms of planning time on test environments not seen during training.
Multi-cell Non-coherent Over-the-Air Computation for Federated Edge Learning
Feb 11, 2022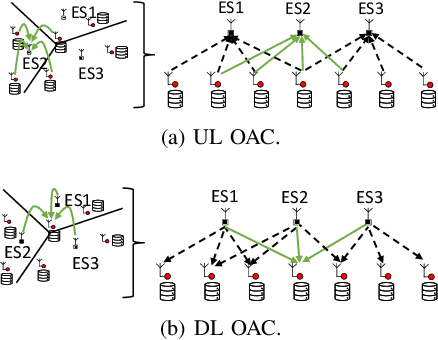
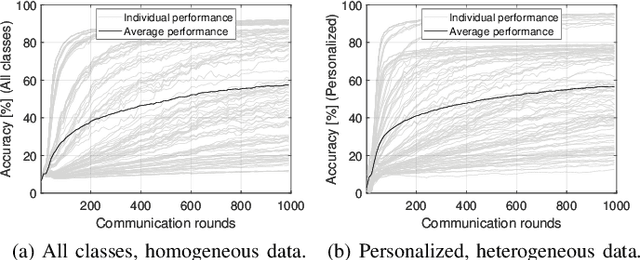
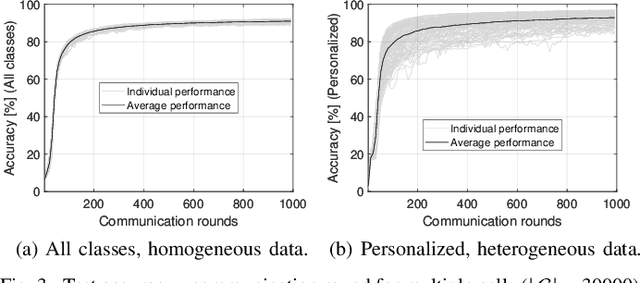
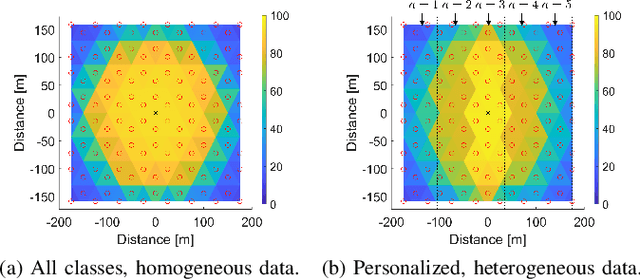
In this paper, we propose a framework where over-the-air computation (OAC) occurs in both uplink (UL) and downlink (DL), sequentially, in a multi-cell environment to address the latency and the scalability issues of federated edge learning (FEEL). To eliminate the channel state information (CSI) at the edge devices (EDs) and edge servers (ESs) and relax the time-synchronization requirement for the OAC, we use a non-coherent computation scheme, i.e., frequency-shift keying (FSK)-based majority vote (MV) (FSK-MV). With the proposed framework, multiple ESs function as the aggregation nodes in the UL and each ES determines the MVs independently. After the ESs broadcast the detected MVs, the EDs determine the sign of the gradient through another OAC in the DL. Hence, inter-cell interference is exploited for the OAC. In this study, we prove the convergence of the non-convex optimization problem for the FEEL with the proposed OAC framework. We also numerically evaluate the efficacy of the proposed method by comparing the test accuracy in both multi-cell and single-cell scenarios for both homogeneous and heterogeneous data distributions.