 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comprehensive Review of Myoelectric Prosthesis Control
Dec 25, 2021
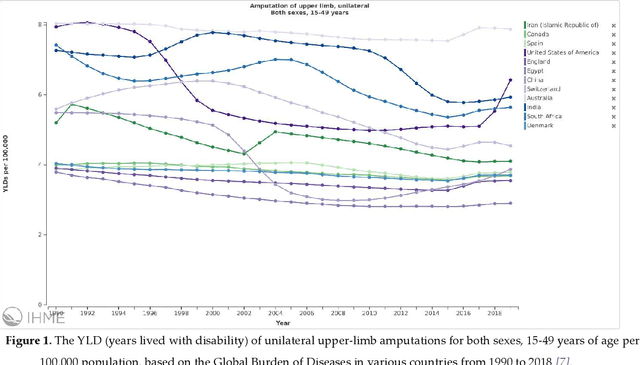
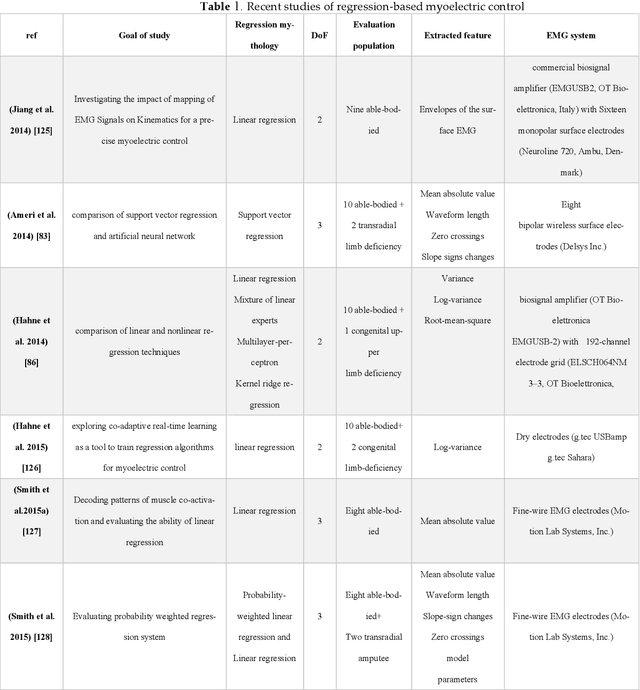
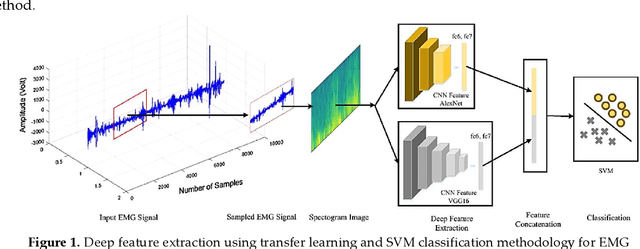
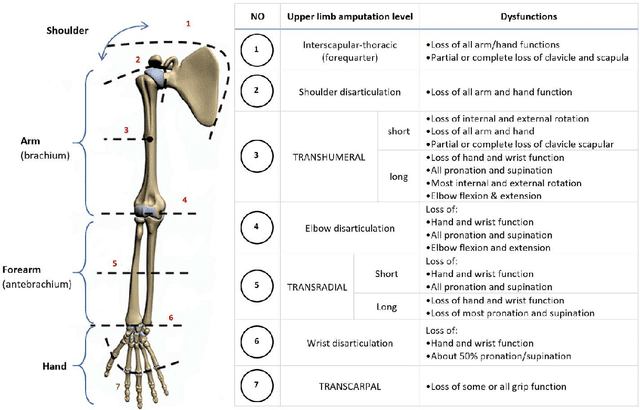
Prosthetic hands can be used to support upper-body amputees. Myoelectric prosthesis, one of the externally-powered active prosthesis categories, requires proper processing units in addition to recording electrodes and instrumentation amplifiers. In this paper, the following myoelectric prosthesis control methods were discussed in detail: On-off and finite-state, proportional, direct, and posture, simultaneous, classification and regression-based control, and deep learning methods. Myoelectric control performance indices, such as completion time and rate, throughput, lag, and path length, were reviewed. The advantages and disadvantages of the control methods were also discussed. Some of myoelectric prosthesis control's significant challenges are comfort, durability, cost, the application of under-sampled signals, and electrode shift. Moreover, the proposed algorithms must be usually tuned after each don and doff, which is not comfortable for the users. Real-time simultaneous and proportional myoelectric control, resampling human's arm, has brought much attention. However, increasing the degree of freedom reduces the overall performance. Applying a 3D printed prosthesis arm and under-sampled electromyographic signals could reduce the fabrication cost and improve the application of such methods in practice. There are many technological and clinical challenges in this area to reduce the prosthesis rejection rate.
Generative GaitNet
Jan 28, 2022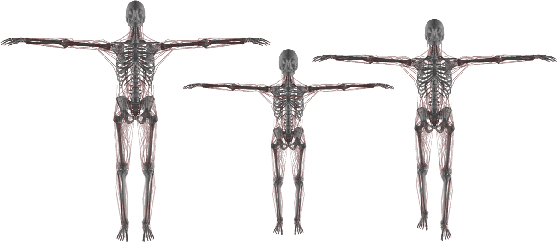
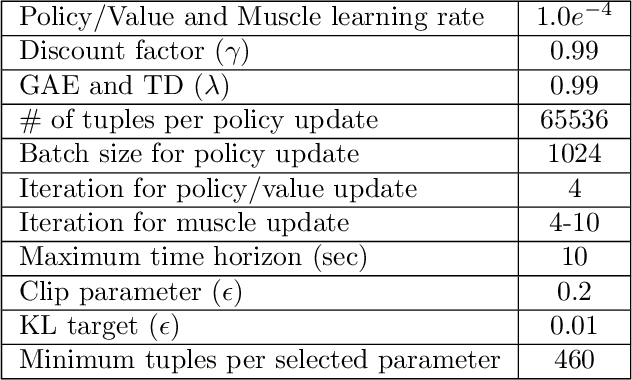
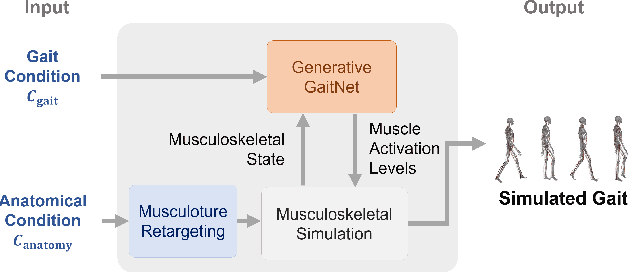
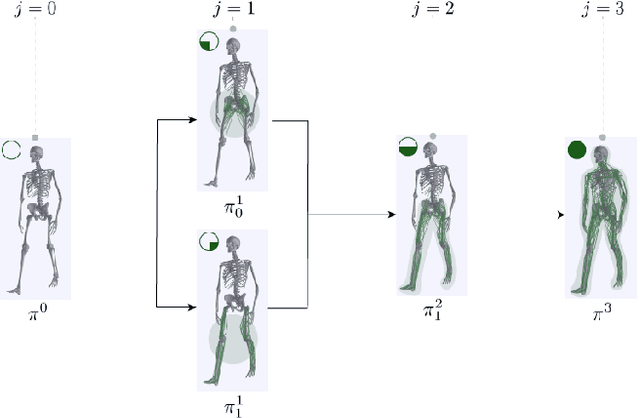
Understanding the relation between anatomy andgait is key to successful predictive gait simulation. Inthis paper, we present Generative GaitNet, which isa novel network architecture based on deep reinforce-ment learning for controlling a comprehensive, full-body, musculoskeletal model with 304 Hill-type mus-culotendons. The Generative Gait is a pre-trained, in-tegrated system of artificial neural networks learnedin a 618-dimensional continuous domain of anatomyconditions (e.g., mass distribution, body proportion,bone deformity, and muscle deficits) and gait condi-tions (e.g., stride and cadence). The pre-trained Gait-Net takes anatomy and gait conditions as input andgenerates a series of gait cycles appropriate to theconditions through physics-based simulation. We willdemonstrate the efficacy and expressive power of Gen-erative GaitNet to generate a variety of healthy andpathologic human gaits in real-time physics-based sim-ulation.
A Simple But Powerful Graph Encoder for Temporal Knowledge Graph Completion
Dec 14, 2021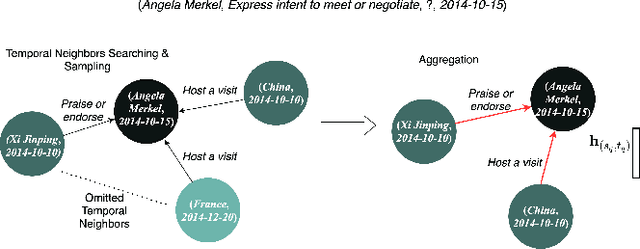
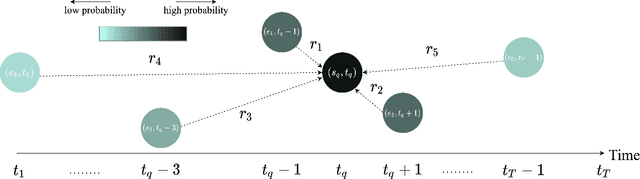
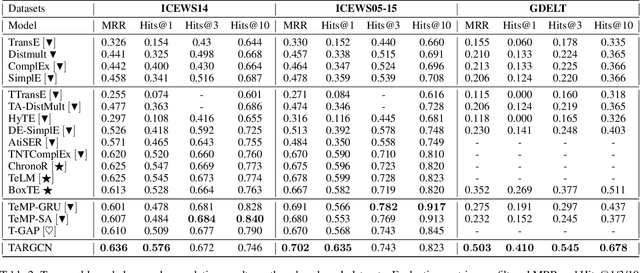
While knowledge graphs contain rich semantic knowledge of various entities and the relational information among them, temporal knowledge graphs (TKGs) further indicate the interactions of the entities over time. To study how to better model TKGs, automatic temporal knowledge graph completion (TKGC) has gained great interest. Recent TKGC methods aim to integrate advanced deep learning techniques, e.g., attention mechanism and Transformer, to boost model performance. However, we find that compared to adopting various kinds of complex modules, it is more beneficial to better utilize the whole amount of temporal information along the time axis. In this paper, we propose a simple but powerful graph encoder TARGCN for TKGC. TARGCN is parameter-efficient, and it extensively utilizes the information from the whole temporal context. We perform experiments on three benchmark datasets. Our model can achieve a more than 42% relative improvement on GDELT dataset compared with the state-of-the-art model. Meanwhile, it outperforms the strongest baseline on ICEWS05-15 dataset with around 18.5% fewer parameters.
Run-time Mapping of Spiking Neural Networks to Neuromorphic Hardware
Jun 11, 2020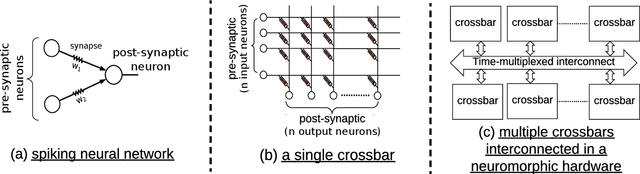
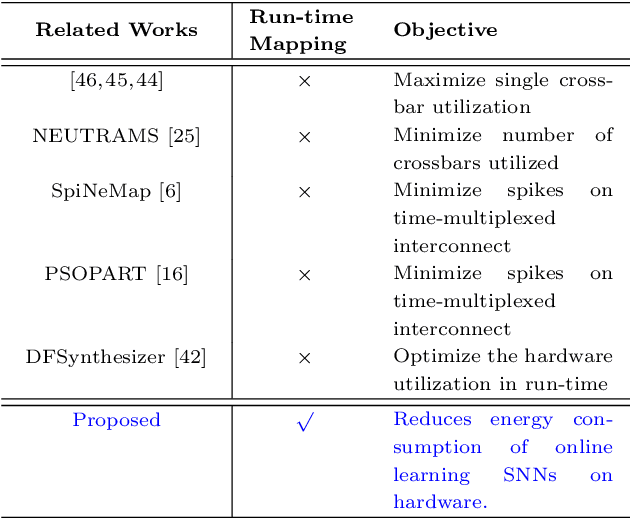
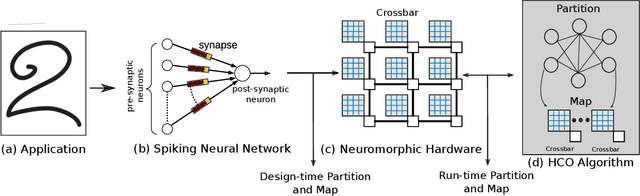
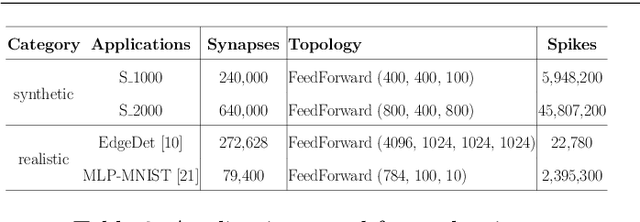
In this paper, we propose a design methodology to partition and map the neurons and synapses of online learning SNN-based applications to neuromorphic architectures at {run-time}. Our design methodology operates in two steps -- step 1 is a layer-wise greedy approach to partition SNNs into clusters of neurons and synapses incorporating the constraints of the neuromorphic architecture, and step 2 is a hill-climbing optimization algorithm that minimizes the total spikes communicated between clusters, improving energy consumption on the shared interconnect of the architecture. We conduct experiments to evaluate the feasibility of our algorithm using synthetic and realistic SNN-based applications. We demonstrate that our algorithm reduces SNN mapping time by an average 780x compared to a state-of-the-art design-time based SNN partitioning approach with only 6.25\% lower solution quality.
Learning to Coordinate in Multi-Agent Systems: A Coordinated Actor-Critic Algorithm and Finite-Time Guarantees
Oct 11, 2021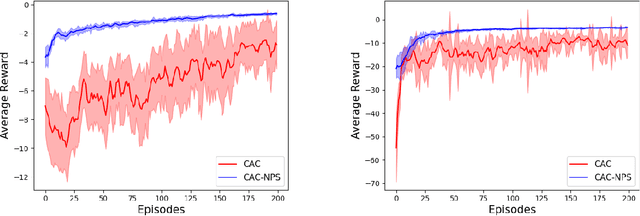
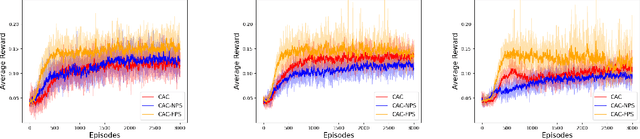
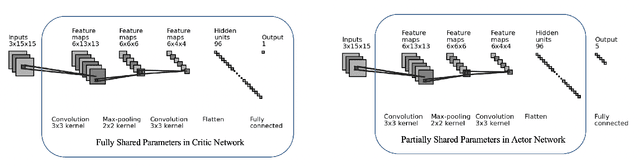
Multi-agent reinforcement learning (MARL) has attracted much research attention recently. However, unlike its single-agent counterpart, many theoretical and algorithmic aspects of MARL have not been well-understood. In this paper, we study the emergence of coordinated behavior by autonomous agents using an actor-critic (AC) algorithm. Specifically, we propose and analyze a class of coordinated actor-critic algorithms (CAC) in which individually parametrized policies have a {\it shared} part (which is jointly optimized among all agents) and a {\it personalized} part (which is only locally optimized). Such kind of {\it partially personalized} policy allows agents to learn to coordinate by leveraging peers' past experience and adapt to individual tasks. The flexibility in our design allows the proposed MARL-CAC algorithm to be used in a {\it fully decentralized} setting, where the agents can only communicate with their neighbors, as well as a {\it federated} setting, where the agents occasionally communicate with a server while optimizing their (partially personalized) local models. Theoretically, we show that under some standard regularity assumptions, the proposed MARL-CAC algorithm requires $\mathcal{O}(\epsilon^{-\frac{5}{2}})$ samples to achieve an $\epsilon$-stationary solution (defined as the solution whose squared norm of the gradient of the objective function is less than $\epsilon$). To the best of our knowledge, this work provides the first finite-sample guarantee for decentralized AC algorithm with partially personalized policies.
DAE : Discriminatory Auto-Encoder for multivariate time-series anomaly detection in air transportation
Sep 08, 2021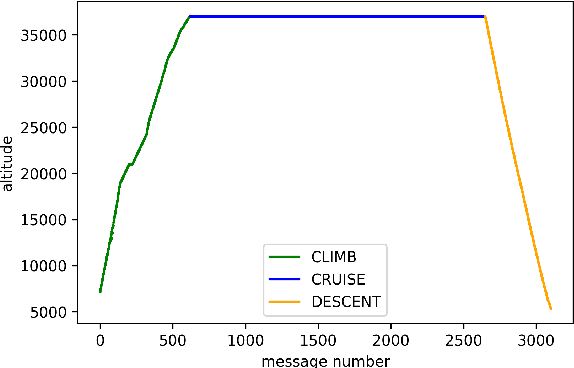
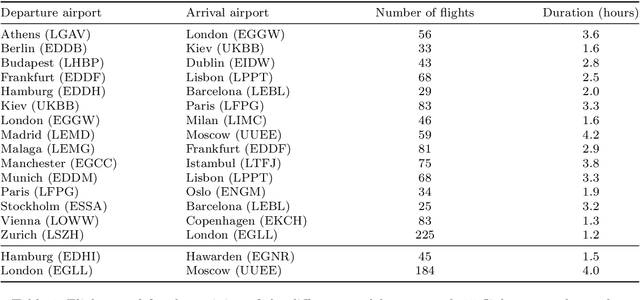
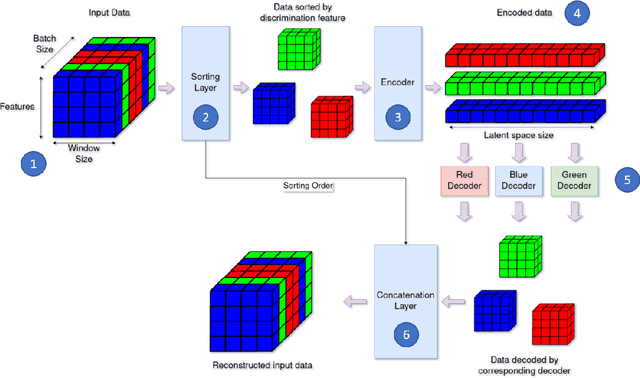
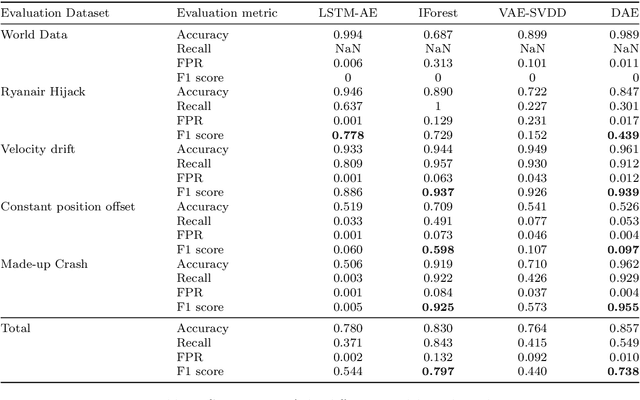
The Automatic Dependent Surveillance Broadcast protocol is one of the latest compulsory advances in air surveillance. While it supports the tracking of the ever-growing number of aircraft in the air, it also introduces cybersecurity issues that must be mitigated e.g., false data injection attacks where an attacker emits fake surveillance information. The recent data sources and tools available to obtain flight tracking records allow the researchers to create datasets and develop Machine Learning models capable of detecting such anomalies in En-Route trajectories. In this context, we propose a novel multivariate anomaly detection model called Discriminatory Auto-Encoder (DAE). It uses the baseline of a regular LSTM-based auto-encoder but with several decoders, each getting data of a specific flight phase (e.g. climbing, cruising or descending) during its training.To illustrate the DAE's efficiency, an evaluation dataset was created using real-life anomalies as well as realistically crafted ones, with which the DAE as well as three anomaly detection models from the literature were evaluated. Results show that the DAE achieves better results in both accuracy and speed of detection. The dataset, the models implementations and the evaluation results are available in an online repository, thereby enabling replicability and facilitating future experiments.
Convolutional neural networks as an alternative to Bayesian retrievals
Mar 03, 2022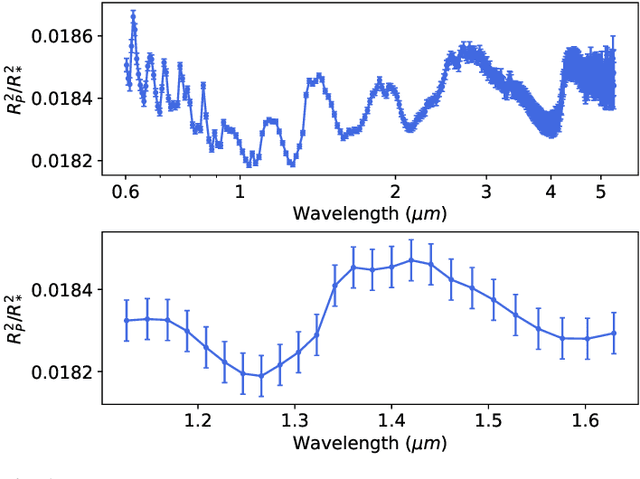
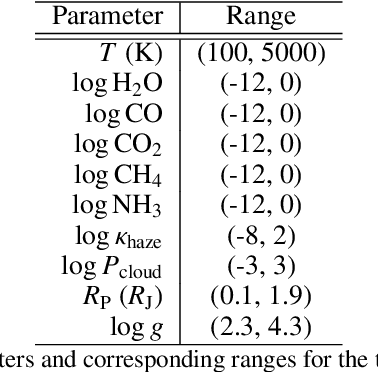
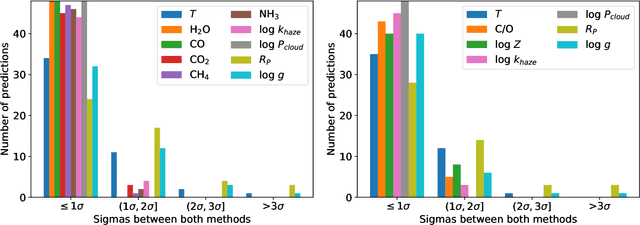
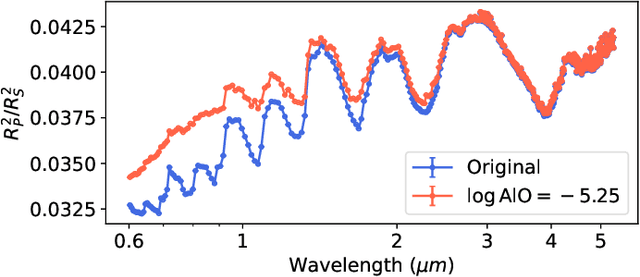
Exoplanet observations are currently analysed with Bayesian retrieval techniques. Due to the computational load of the models used, a compromise is needed between model complexity and computing time. Analysis of data from future facilities, will need more complex models which will increase the computational load of retrievals, prompting the search for a faster approach for interpreting exoplanet observations. Our goal is to compare machine learning retrievals of exoplanet transmission spectra with nested sampling, and understand if machine learning can be as reliable as Bayesian retrievals for a statistically significant sample of spectra while being orders of magnitude faster. We generate grids of synthetic transmission spectra and their corresponding planetary and atmospheric parameters, one using free chemistry models, and the other using equilibrium chemistry models. Each grid is subsequently rebinned to simulate both HST/WFC3 and JWST/NIRSpec observations, yielding four datasets in total. Convolutional neural networks (CNNs) are trained with each of the datasets. We perform retrievals on a 1,000 simulated observations for each combination of model type and instrument with nested sampling and machine learning. We also use both methods to perform retrievals on real WFC3 transmission spectra. Finally, we test how robust machine learning and nested sampling are against incorrect assumptions in our models. CNNs reach a lower coefficient of determination between predicted and true values of the parameters. Nested sampling underestimates the uncertainty in ~8% of retrievals, whereas CNNs estimate them correctly. For real WFC3 observations, nested sampling and machine learning agree within $2\sigma$ for ~86% of spectra. When doing retrievals with incorrect assumptions, nested sampling underestimates the uncertainty in ~12% to ~41% of cases, whereas this is always below ~10% for the CNN.
An analysis of deep neural networks for predicting trends in time series data
Sep 22, 2020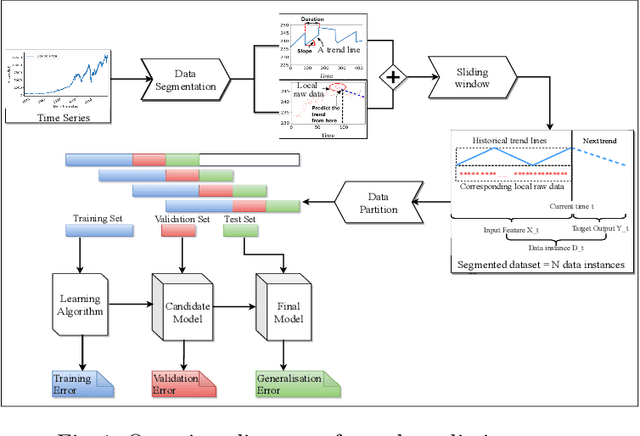

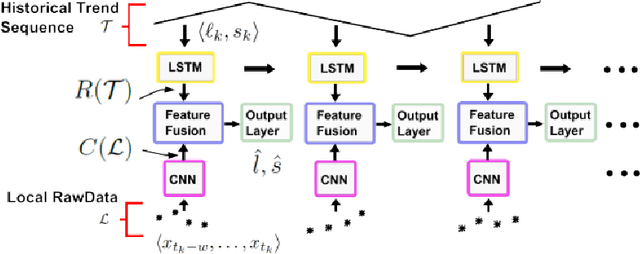
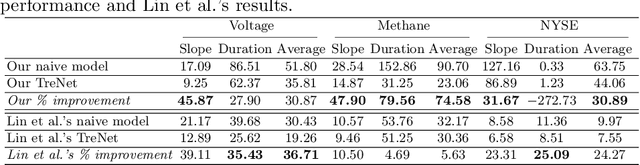
Recently, a hybrid Deep Neural Network (DNN) algorithm, TreNet was proposed for predicting trends in time series data. While TreNet was shown to have superior performance for trend prediction to other DNN and traditional ML approaches, the validation method used did not take into account the sequential nature of time series data sets and did not deal with model update. In this research we replicated the TreNet experiments on the same data sets using a walk-forward validation method and tested our optimal model over multiple independent runs to evaluate model stability. We compared the performance of the hybrid TreNet algorithm, on four data sets to vanilla DNN algorithms that take in point data, and also to traditional ML algorithms. We found that in general TreNet still performs better than the vanilla DNN models, but not on all data sets as reported in the original TreNet study. This study highlights the importance of using an appropriate validation method and evaluating model stability for evaluating and developing machine learning models for trend prediction in time series data.
Parallel feature selection based on the trace ratio criterion
Mar 03, 2022
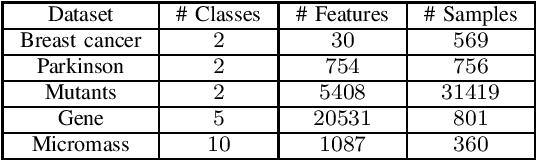

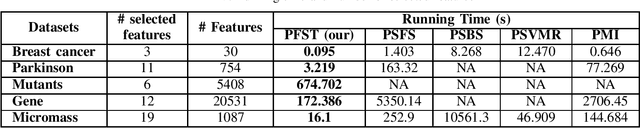
The growth of data today poses a challenge in management and inference. While feature extraction methods are capable of reducing the size of the data for inference, they do not help in minimizing the cost of data storage. On the other hand, feature selection helps to remove the redundant features and therefore is helpful not only in inference but also in reducing management costs. This work presents a novel parallel feature selection approach for classification, namely Parallel Feature Selection using Trace criterion (PFST), which scales up to very large datasets. Our method uses trace criterion, a measure of class separability used in Fisher's Discriminant Analysis, to evaluate feature usefulness. We analyzed the criterion's desirable properties theoretically. Based on the criterion, PFST rapidly finds important features out of a set of features for big datasets by first making a forward selection with early removal of seemingly redundant features parallelly. After the most important features are included in the model, we check back their contribution for possible interaction that may improve the fit. Lastly, we make a backward selection to check back possible redundant added by the forward steps. We evaluate our methods via various experiments using Linear Discriminant Analysis as the classifier on selected features. The experiments show that our method can produce a small set of features in a fraction of the amount of time by the other methods under comparison. In addition, the classifier trained on the features selected by PFST not only achieves better accuracy than the ones chosen by other approaches but can also achieve better accuracy than the classification on all available features.
Revisiting L1 Loss in Super-Resolution: A Probabilistic View and Beyond
Jan 25, 2022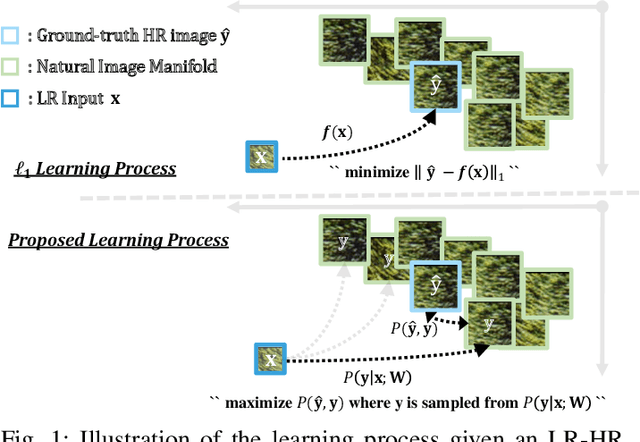
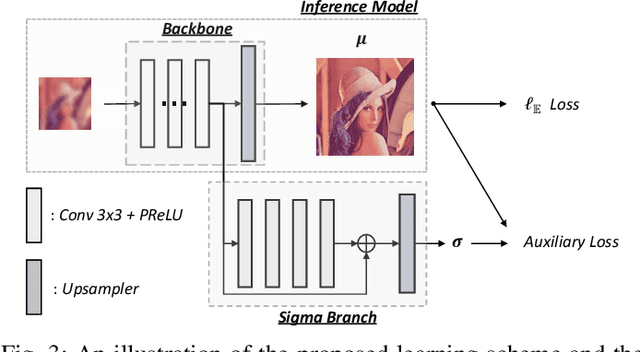
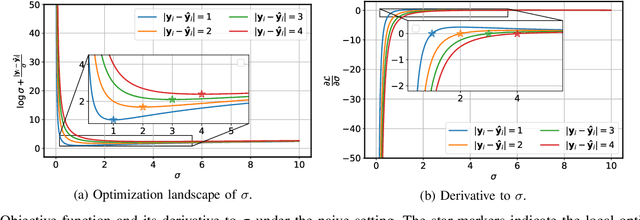
Super-resolution as an ill-posed problem has many high-resolution candidates for a low-resolution input. However, the popular $\ell_1$ loss used to best fit the given HR image fails to consider this fundamental property of non-uniqueness in image restoration. In this work, we fix the missing piece in $\ell_1$ loss by formulating super-resolution with neural networks as a probabilistic model. It shows that $\ell_1$ loss is equivalent to a degraded likelihood function that removes the randomness from the learning process. By introducing a data-adaptive random variable, we present a new objective function that aims at minimizing the expectation of the reconstruction error over all plausible solutions. The experimental results show consistent improvements on mainstream architectures, with no extra parameter or computing cost at inference time.