 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conditional Generation Net for Medication Recommendation
Feb 18, 2022
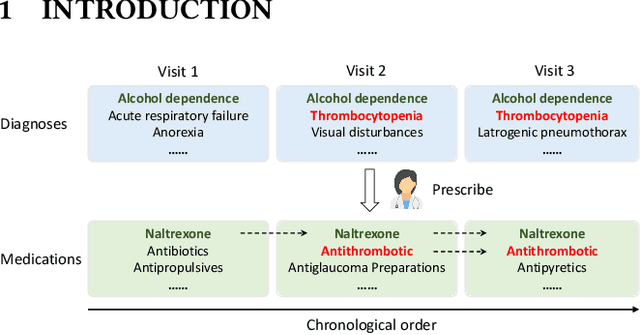
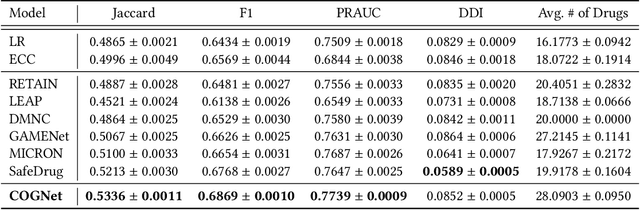
Medication recommendation targets to provide a proper set of medicines according to patients' diagnoses, which is a critical task in clinics. Currently, the recommendation is manually conducted by doctors. However, for complicated cases, like patients with multiple diseases at the same time, it's difficult to propose a considerate recommendation even for experienced doctors. This urges the emergence of automatic medication recommendation which can help treat the diagnosed diseases without causing harmful drug-drug interactions.Due to the clinical value, medication recommendation has attracted growing research interests.Existing works mainly formulate medication recommendation as a multi-label classification task to predict the set of medicines. In this paper, we propose the Conditional Generation Net (COGNet) which introduces a novel copy-or-predict mechanism to generate the set of medicines. Given a patient, the proposed model first retrieves his or her historical diagnoses and medication recommendations and mines their relationship with current diagnoses. Then in predicting each medicine, the proposed model decides whether to copy a medicine from previous recommendations or to predict a new one. This process is quite similar to the decision process of human doctors. We validate the proposed model on the public MIMIC data set, and the experimental results show that the proposed model can outperform state-of-the-art approaches.
Cooperative Multi-UAV Coverage Mission Planning Platform for Remote Sensing Applications
Jan 19, 2022
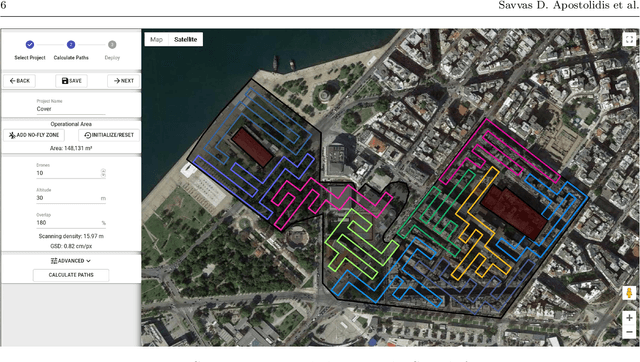
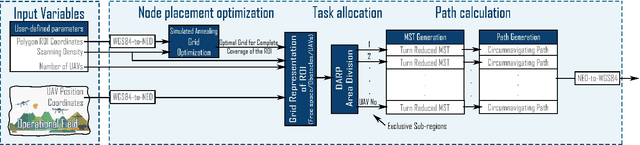

This paper proposes a novel mission planning platform, capable of efficiently deploying a team of UAVs to cover complex-shaped areas, in various remote sensing applications. Under the hood lies a novel optimization scheme for grid-based methods, utilizing Simulated Annealing algorithm, that significantly increases the achieved percentage of coverage and improves the qualitative features of the generated paths. Extensive simulated evaluation in comparison with a state-of-the-art alternative methodology, for coverage path planning (CPP) operations, establishes the performance gains in terms of achieved coverage and overall duration of the generated missions. On top of that, DARP algorithm is employed to allocate sub-tasks to each member of the swarm, taking into account each UAV's sensing and operational capabilities, their initial positions and any no-fly-zones possibly defined inside the operational area. This feature is of paramount importance in real-life applications, as it has the potential to achieve tremendous performance improvements in terms of time demanded to complete a mission, while at the same time it unlocks a wide new range of applications, that was previously not feasible due to the limited battery life of UAVs. In order to investigate the actual efficiency gains that are introduced by the multi-UAV utilization, a simulated study is performed as well. All of these capabilities are packed inside an end-to-end platform that eases the utilization of UAVs' swarms in remote sensing applications. Its versatility is demonstrated via two different real-life applications: (i) a photogrametry for precision agriculture and (ii) an indicative search and rescue for first responders missions, that were performed utilizing a swarm of commercial UAVs. The source code can be found at: https://github.com/savvas-ap/mCPP-optimized-DARP
* An implementation of the mCPP methodology introduced in this work, as well as a link for a demonstrative video and a link for a fully functional, on-line hosted instance of the presented platform can be found here: https://github.com/savvas-ap/mCPP-optimized-DARP
Real-Time Facial Expression Emoji Masking with Convolutional Neural Networks and Homography
Dec 24, 2020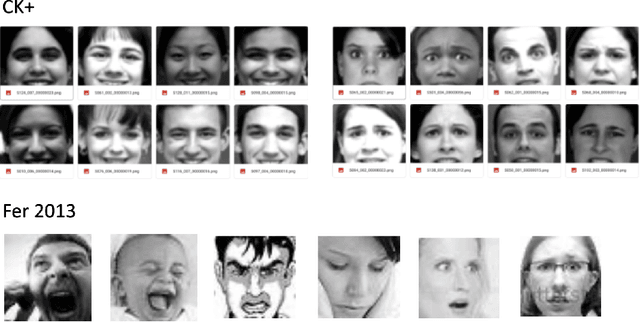



Neural network based algorithms has shown success in many applications. In image processing, Convolutional Neural Networks (CNN) can be trained to categorize facial expressions of images of human faces. In this work, we create a system that masks a student's face with a emoji of the respective emotion. Our system consists of three building blocks: face detection using Histogram of Gradients (HoG) and Support Vector Machine (SVM), facial expression categorization using CNN trained on FER2013 dataset, and finally masking the respective emoji back onto the student's face via homography estimation. (Demo: https://youtu.be/GCjtXw1y8Pw) Our results show that this pipeline is deploy-able in real-time, and is usable in educational settings.
Debiased Pseudo Labeling in Self-Training
Feb 18, 2022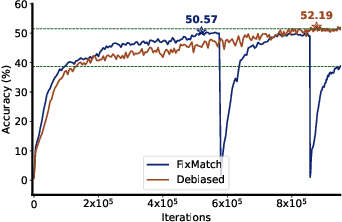
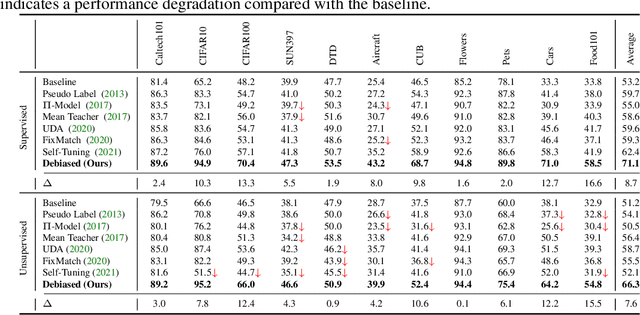
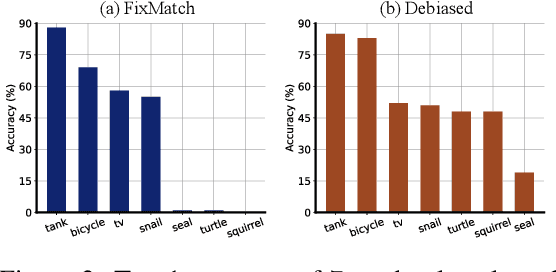
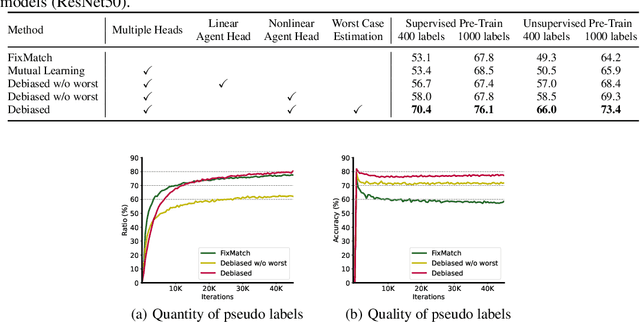
Deep neural networks achieve remarkable performances on a wide range of tasks with the aid of large-scale labeled datasets. However, large-scale annotations are time-consuming and labor-exhaustive to obtain on realistic tasks. To mitigate the requirement for labeled data, self-training is widely used in both academia and industry by pseudo labeling on readily-available unlabeled data. Despite its popularity, pseudo labeling is well-believed to be unreliable and often leads to training instability. Our experimental studies further reveal that the performance of self-training is biased due to data sampling, pre-trained models, and training strategies, especially the inappropriate utilization of pseudo labels. To this end, we propose Debiased, in which the generation and utilization of pseudo labels are decoupled by two independent heads. To further improve the quality of pseudo labels, we introduce a worst-case estimation of pseudo labeling and seamlessly optimize the representations to avoid the worst-case. Extensive experiments justify that the proposed Debiased not only yields an average improvement of $14.4$\% against state-of-the-art algorithms on $11$ tasks (covering generic object recognition, fine-grained object recognition, texture classification, and scene classification) but also helps stabilize training and balance performance across classes.
Learning to Schedule Heuristics for the Simultaneous Stochastic Optimization of Mining Complexes
Feb 25, 2022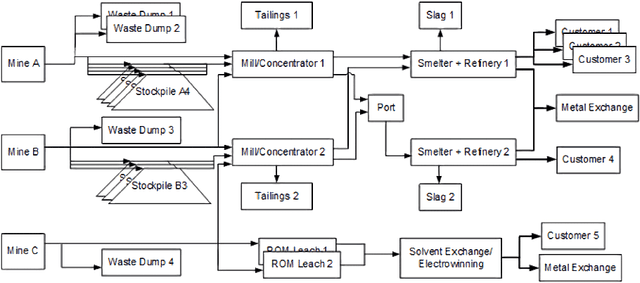
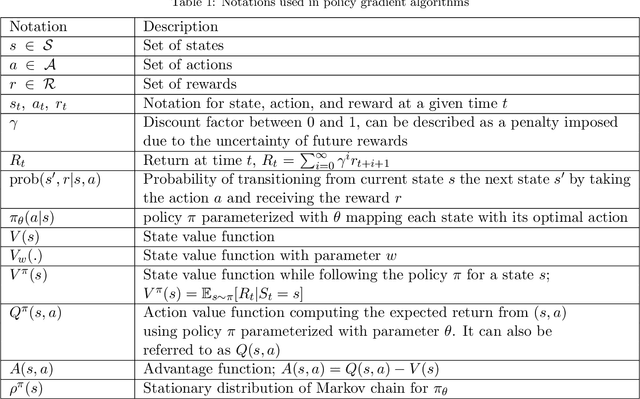
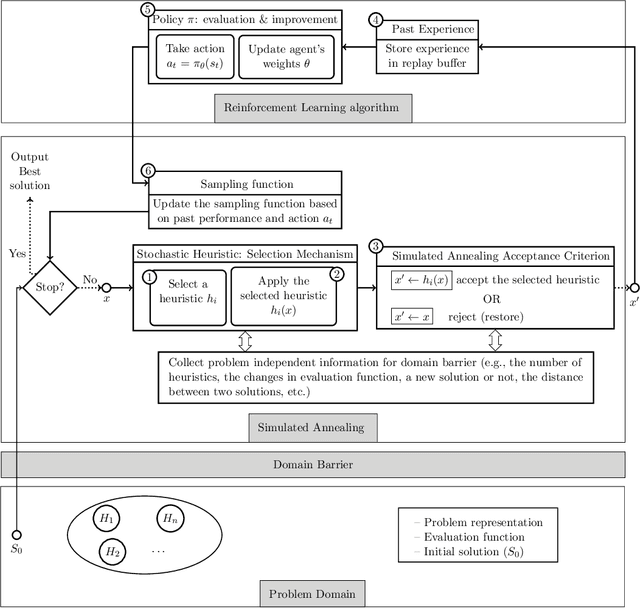
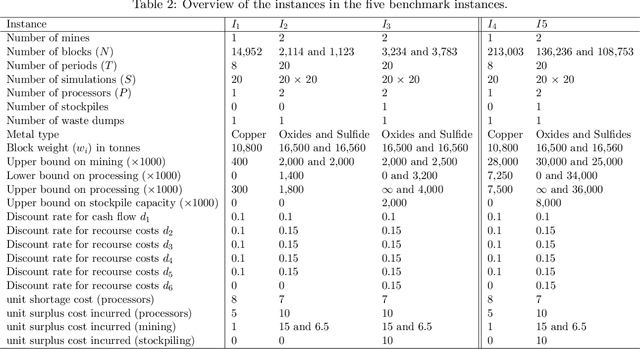
The simultaneous stochastic optimization of mining complexes (SSOMC) is a large-scale stochastic combinatorial optimization problem that simultaneously manages the extraction of materials from multiple mines and their processing using interconnected facilities to generate a set of final products, while taking into account material supply (geological) uncertainty to manage the associated risk. Although simulated annealing has been shown to outperform comparing methods for solving the SSOMC, early performance might dominate recent performance in that a combination of the heuristics' performance is used to determine which perturbations to apply. This work proposes a data-driven framework for heuristic scheduling in a fully self-managed hyper-heuristic to solve the SSOMC. The proposed learn-to-perturb (L2P) hyper-heuristic is a multi-neighborhood simulated annealing algorithm. The L2P selects the heuristic (perturbation) to be applied in a self-adaptive manner using reinforcement learning to efficiently explore which local search is best suited for a particular search point. Several state-of-the-art agents have been incorporated into L2P to better adapt the search and guide it towards better solutions. By learning from data describing the performance of the heuristics, a problem-specific ordering of heuristics that collectively finds better solutions faster is obtained. L2P is tested on several real-world mining complexes, with an emphasis on efficiency, robustness, and generalization capacity. Results show a reduction in the number of iterations by 30-50% and in the computational time by 30-45%.
A White-Box SVM Framework and its Swarm-Based Optimization for Supervision of Toothed Milling Cutter through Characterization of Spindle Vibrations
Dec 15, 2021
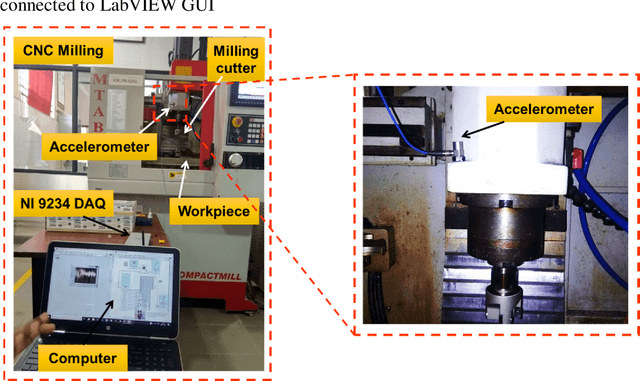
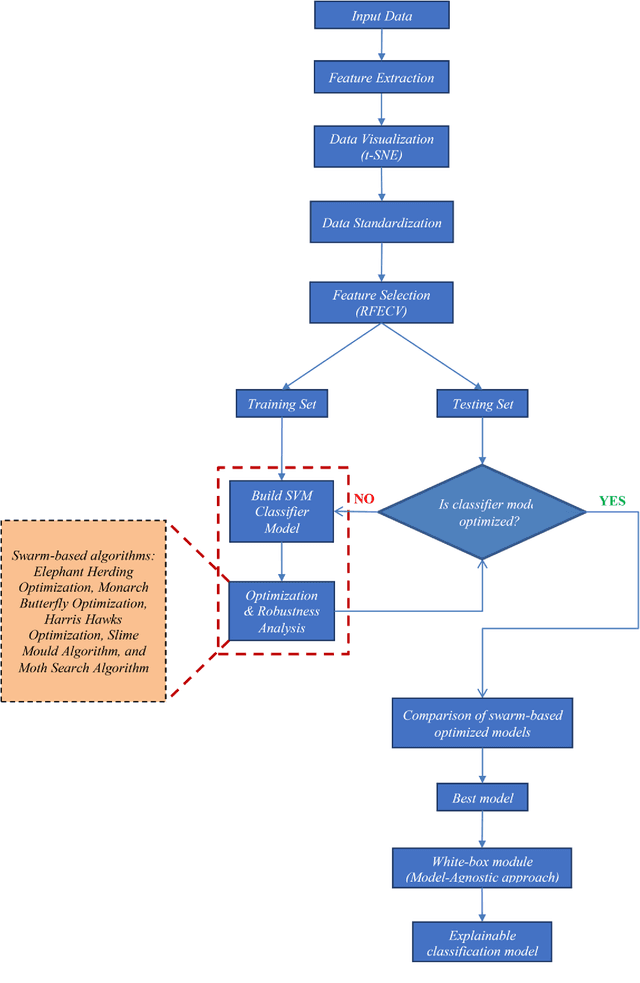
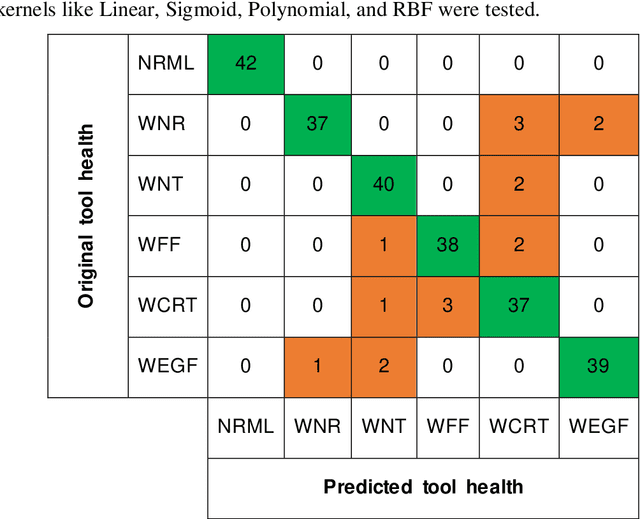
In this paper, a white-Box support vector machine (SVM) framework and its swarm-based optimization is presented for supervision of toothed milling cutter through characterization of real-time spindle vibrations. The anomalous moments of vibration evolved due to in-process tool failures (i.e., flank and nose wear, crater and notch wear, edge fracture) have been investigated through time-domain response of acceleration and statistical features. The Recursive Feature Elimination with Cross-Validation (RFECV) with decision trees as the estimator has been implemented for feature selection. Further, the competence of standard SVM has been examined for tool health monitoring followed by its optimization through application of swarm based algorithms. The comparative analysis of performance of five meta-heuristic algorithms (Elephant Herding Optimization, Monarch Butterfly Optimization, Harris Hawks Optimization, Slime Mould Algorithm, and Moth Search Algorithm) has been carried out. The white-box approach has been presented considering global and local representation that provides insight into the performance of machine learning models in tool condition monitoring.
SAFE-OCC: A Novelty Detection Framework for Convolutional Neural Network Sensors and its Application in Process Control
Feb 03, 2022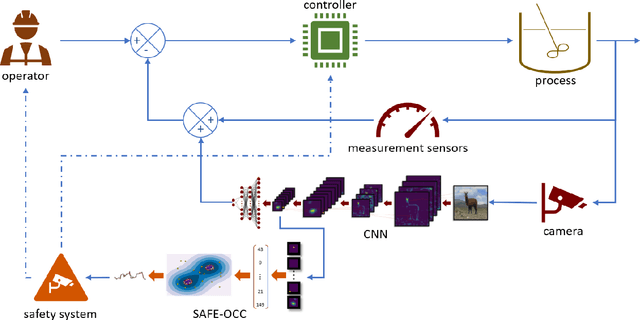
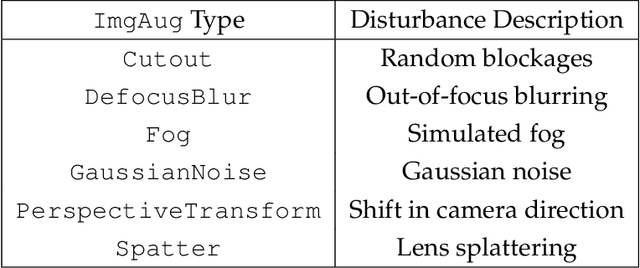
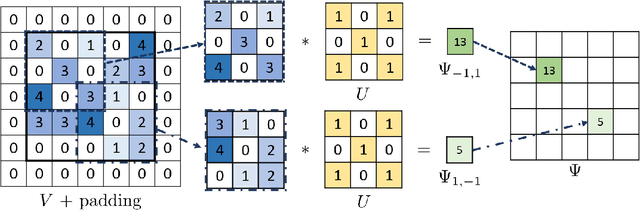
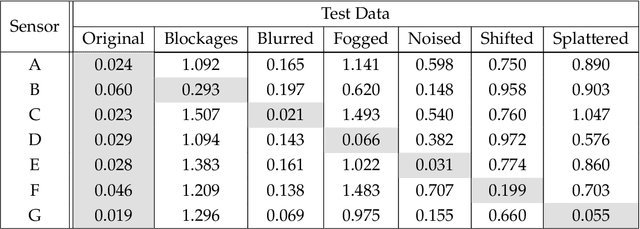
We present a novelty detection framework for Convolutional Neural Network (CNN) sensors that we call Sensor-Activated Feature Extraction One-Class Classification (SAFE-OCC). We show that this framework enables the safe use of computer vision sensors in process control architectures. Emergent control applications use CNN models to map visual data to a state signal that can be interpreted by the controller. Incorporating such sensors introduces a significant system operation vulnerability because CNN sensors can exhibit high prediction errors when exposed to novel (abnormal) visual data. Unfortunately, identifying such novelties in real-time is nontrivial. To address this issue, the SAFE-OCC framework leverages the convolutional blocks of the CNN to create an effective feature space to conduct novelty detection using a desired one-class classification technique. This approach engenders a feature space that directly corresponds to that used by the CNN sensor and avoids the need to derive an independent latent space. We demonstrate the effectiveness of SAFE-OCC via simulated control environments.
FedREP: Towards Horizontal Federated Load Forecasting for Retail Energy Providers
Mar 01, 2022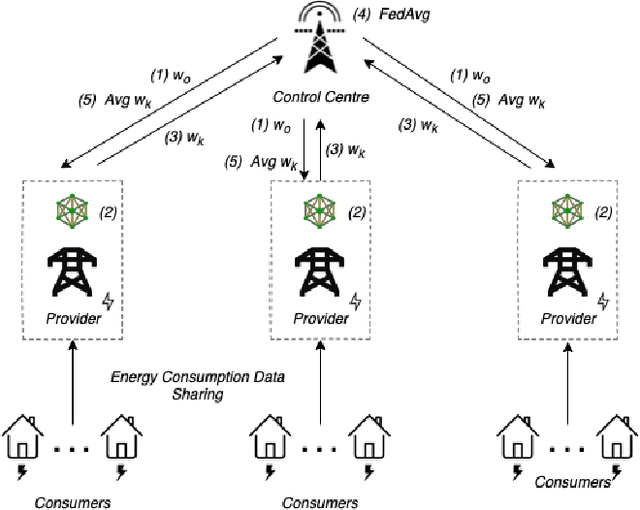
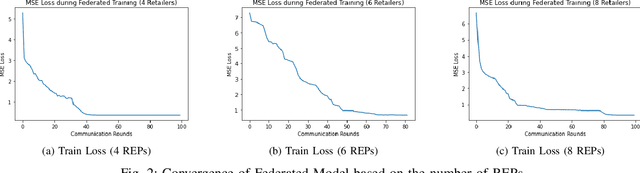
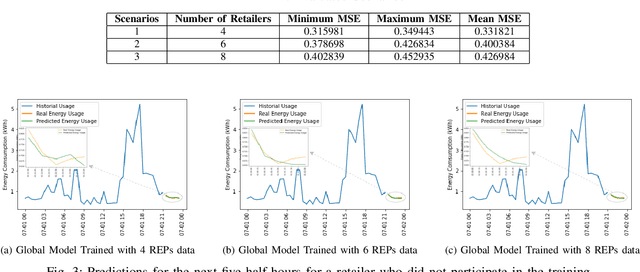
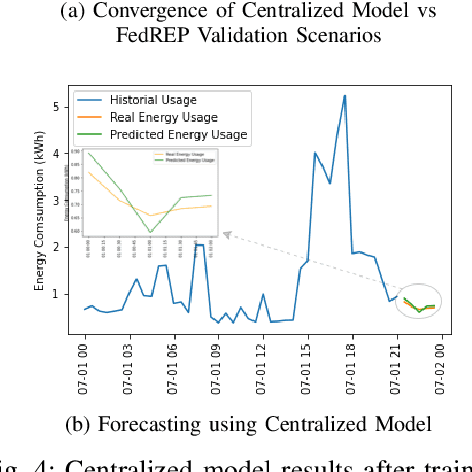
As Smart Meters are collecting and transmitting household energy consumption data to Retail Energy Providers (REP), the main challenge is to ensure the effective use of fine-grained consumer data while ensuring data privacy. In this manuscript, we tackle this challenge for energy load consumption forecasting in regards to REPs which is essential to energy demand management, load switching and infrastructure development. Specifically, we note that existing energy load forecasting is centralized, which are not scalable and most importantly, vulnerable to data privacy threats. Besides, REPs are individual market participants and liable to ensure the privacy of their own customers. To address this issue, we propose a novel horizontal privacy-preserving federated learning framework for REPs energy load forecasting, namely FedREP. We consider a federated learning system consisting of a control centre and multiple retailers by enabling multiple REPs to build a common, robust machine learning model without sharing data, thus addressing critical issues such as data privacy, data security and scalability. For forecasting, we use a state-of-the-art Long Short-Term Memory (LSTM) neural network due to its ability to learn long term sequences of observations and promises of higher accuracy with time-series data while solving the vanishing gradient problem. Finally, we conduct extensive data-driven experiments using a real energy consumption dataset. Experimental results demonstrate that our proposed federated learning framework can achieve sufficient performance in terms of MSE ranging between 0.3 to 0.4 and is relatively similar to that of a centralized approach while preserving privacy and improving scalability.
Dilated Continuous Random Field for Semantic Segmentation
Feb 01, 2022
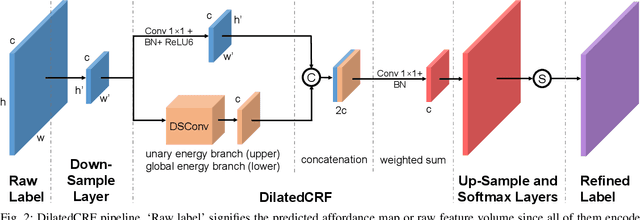
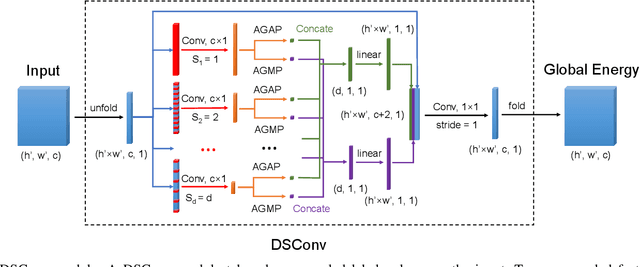
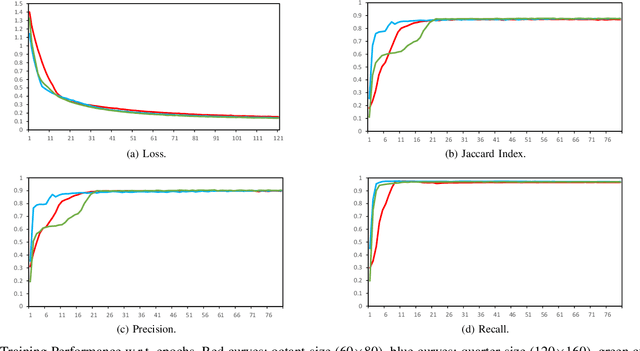
Mean field approximation methodology has laid the foundation of modern Continuous Random Field (CRF) based solutions for the refinement of semantic segmentation. In this paper, we propose to relax the hard constraint of mean field approximation - minimizing the energy term of each node from probabilistic graphical model, by a global optimization with the proposed dilated sparse convolution module (DSConv). In addition, adaptive global average-pooling and adaptive global max-pooling are implemented as replacements of fully connected layers. In order to integrate DSConv, we design an end-to-end, time-efficient DilatedCRF pipeline. The unary energy term is derived either from pre-softmax and post-softmax features, or the predicted affordance map using a conventional classifier, making it easier to implement DilatedCRF for varieties of classifiers. We also present superior experimental results of proposed approach on the suction dataset comparing to other CRF-based approaches.
Who will Leave a Pediatric Weight Management Program and When? -- A machine learning approach for predicting attrition patterns
Feb 13, 2022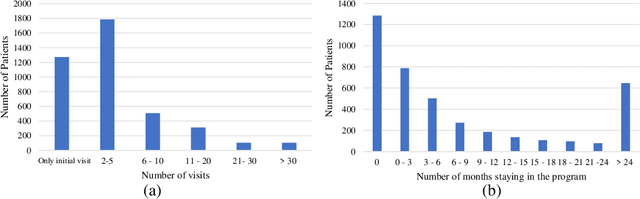
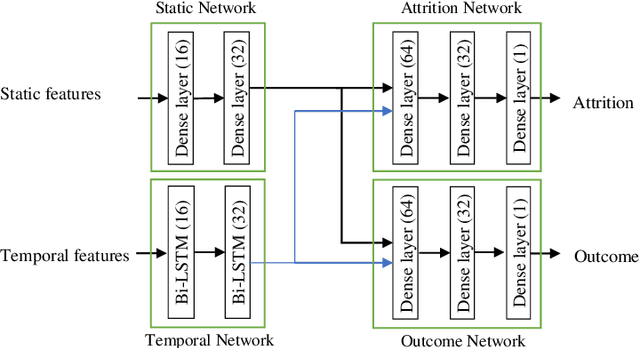
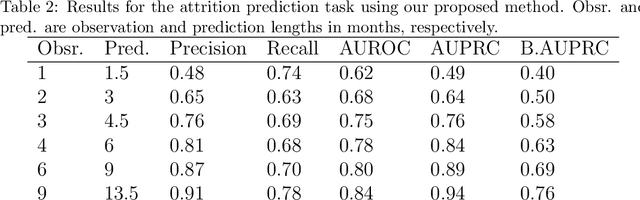
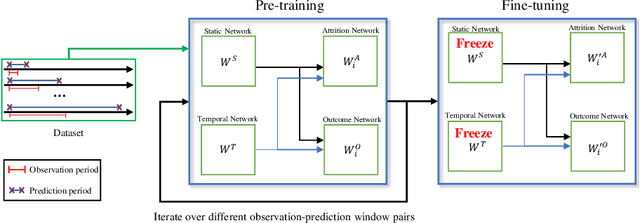
Childhood obesity is a major public health concern. Multidisciplinary pediatric weight management programs are considered standard treatment for children with obesity and severe obesity who are not able to be successfully managed in the primary care setting; however, high drop-out rates (referred to as attrition) are a major hurdle in delivering successful interventions. Predicting attrition patterns can help providers reduce the attrition rates. Previous work has mainly focused on finding static predictors of attrition using statistical analysis methods. In this study, we present a machine learning model to predict (a) the likelihood of attrition, and (b) the change in body-mass index (BMI) percentile of children, at different time points after joining a weight management program. We use a five-year dataset containing the information related to around 4,550 children that we have compiled using data from the Nemours Pediatric Weight Management program. Our models show strong prediction performance as determined by high AUROC scores across different tasks (average AUROC of 0.75 for predicting attrition, and 0.73 for predicting weight outcomes). Additionally, we report the top features predicting attrition and weight outcomes in a series of explanatory experiments.