 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CEHR-BERT: Incorporating temporal information from structured EHR data to improve prediction tasks
Nov 10, 2021
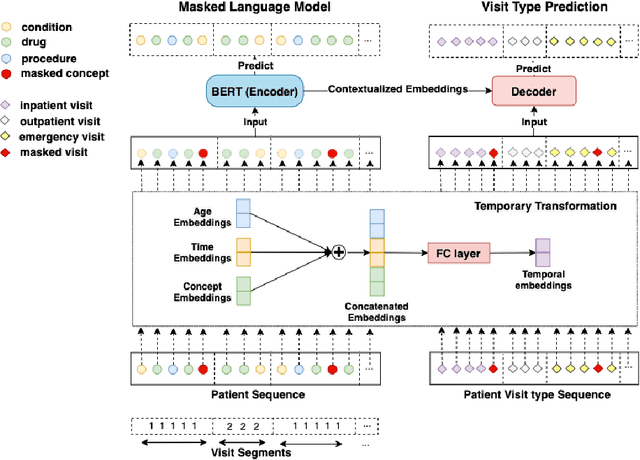

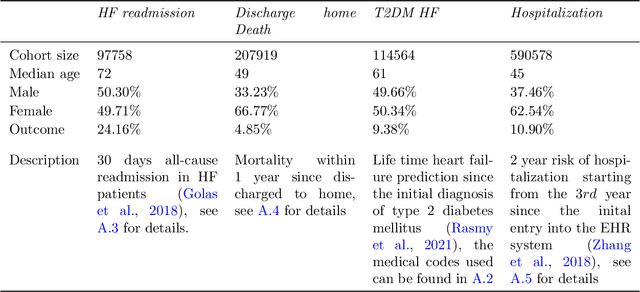

Embedding algorithms are increasingly used to represent clinical concepts in healthcare for improving machine learning tasks such as clinical phenotyping and disease prediction. Recent studies have adapted state-of-the-art bidirectional encoder representations from transformers (BERT) architecture to structured electronic health records (EHR) data for the generation of contextualized concept embeddings, yet do not fully incorporate temporal data across multiple clinical domains. Therefore we developed a new BERT adaptation, CEHR-BERT, to incorporate temporal information using a hybrid approach by augmenting the input to BERT using artificial time tokens, incorporating time, age, and concept embeddings, and introducing a new second learning objective for visit type. CEHR-BERT was trained on a subset of Columbia University Irving Medical Center-York Presbyterian Hospital's clinical data, which includes 2.4M patients, spanning over three decades, and tested using 4-fold cross-validation on the following prediction tasks: hospitalization, death, new heart failure (HF) diagnosis, and HF readmission. Our experiments show that CEHR-BERT outperformed existing state-of-the-art clinical BERT adaptations and baseline models across all 4 prediction tasks in both ROC-AUC and PR-AUC. CEHR-BERT also demonstrated strong transfer learning capability, as our model trained on only 5% of data outperformed comparison models trained on the entire data set. Ablation studies to better understand the contribution of each time component showed incremental gains with every element, suggesting that CEHR-BERT's incorporation of artificial time tokens, time and age embeddings with concept embeddings, and the addition of the second learning objective represents a promising approach for future BERT-based clinical embeddings.
A Fair and Efficient Hybrid Federated Learning Framework based on XGBoost for Distributed Power Prediction
Jan 08, 2022
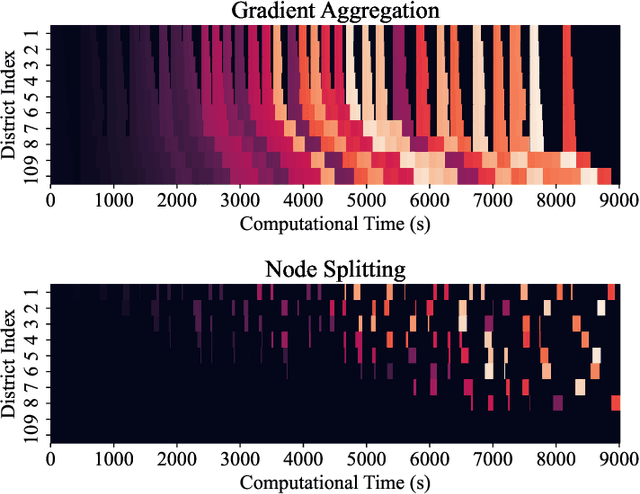
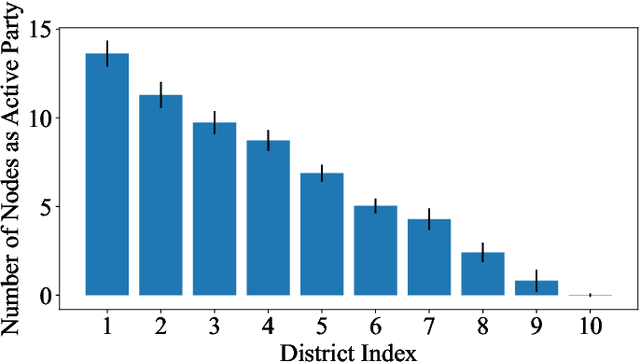
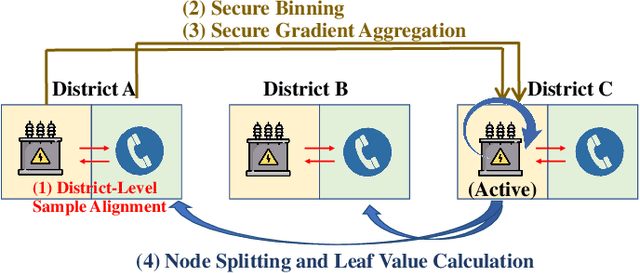
In a modern power system, real-time data on power generation/consumption and its relevant features are stored in various distributed parties, including household meters, transformer stations and external organizations. To fully exploit the underlying patterns of these distributed data for accurate power prediction, federated learning is needed as a collaborative but privacy-preserving training scheme. However, current federated learning frameworks are polarized towards addressing either the horizontal or vertical separation of data, and tend to overlook the case where both are present. Furthermore, in mainstream horizontal federated learning frameworks, only artificial neural networks are employed to learn the data patterns, which are considered less accurate and interpretable compared to tree-based models on tabular datasets. To this end, we propose a hybrid federated learning framework based on XGBoost, for distributed power prediction from real-time external features. In addition to introducing boosted trees to improve accuracy and interpretability, we combine horizontal and vertical federated learning, to address the scenario where features are scattered in local heterogeneous parties and samples are scattered in various local districts. Moreover, we design a dynamic task allocation scheme such that each party gets a fair share of information, and the computing power of each party can be fully leveraged to boost training efficiency. A follow-up case study is presented to justify the necessity of adopting the proposed framework. The advantages of the proposed framework in fairness, efficiency and accuracy performance are also confirmed.
Dilated Continuous Random Field for Semantic Segmentation
Feb 01, 2022
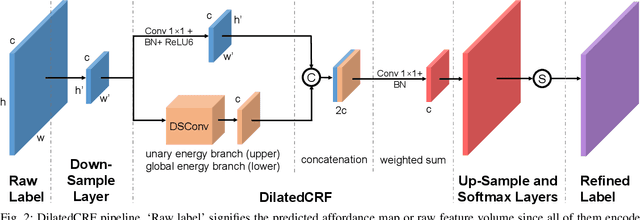
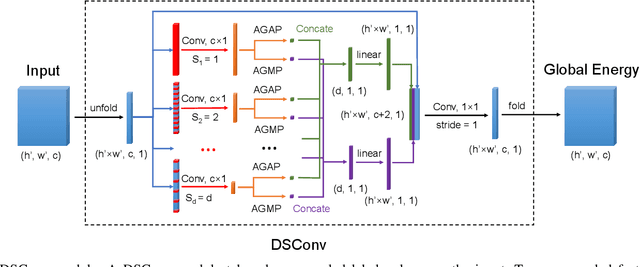
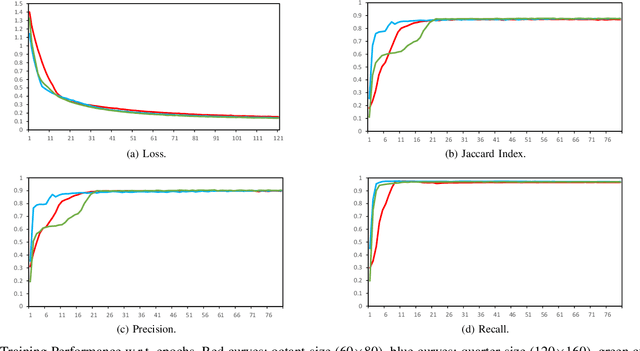
Mean field approximation methodology has laid the foundation of modern Continuous Random Field (CRF) based solutions for the refinement of semantic segmentation. In this paper, we propose to relax the hard constraint of mean field approximation - minimizing the energy term of each node from probabilistic graphical model, by a global optimization with the proposed dilated sparse convolution module (DSConv). In addition, adaptive global average-pooling and adaptive global max-pooling are implemented as replacements of fully connected layers. In order to integrate DSConv, we design an end-to-end, time-efficient DilatedCRF pipeline. The unary energy term is derived either from pre-softmax and post-softmax features, or the predicted affordance map using a conventional classifier, making it easier to implement DilatedCRF for varieties of classifiers. We also present superior experimental results of proposed approach on the suction dataset comparing to other CRF-based approaches.
Grammar-Based Grounded Lexicon Learning
Feb 17, 2022
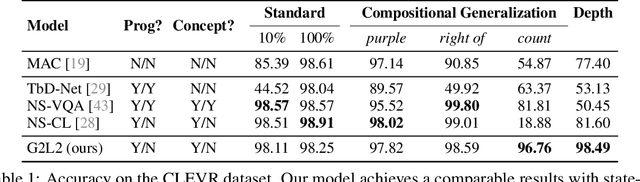
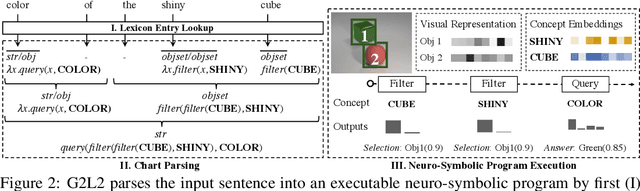
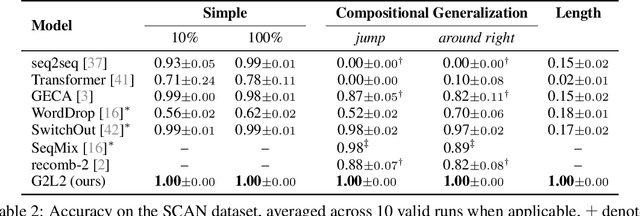
We present Grammar-Based Grounded Lexicon Learning (G2L2), a lexicalist approach toward learning a compositional and grounded meaning representation of language from grounded data, such as paired images and texts. At the core of G2L2 is a collection of lexicon entries, which map each word to a tuple of a syntactic type and a neuro-symbolic semantic program. For example, the word shiny has a syntactic type of adjective; its neuro-symbolic semantic program has the symbolic form {\lambda}x. filter(x, SHINY), where the concept SHINY is associated with a neural network embedding, which will be used to classify shiny objects. Given an input sentence, G2L2 first looks up the lexicon entries associated with each token. It then derives the meaning of the sentence as an executable neuro-symbolic program by composing lexical meanings based on syntax. The recovered meaning programs can be executed on grounded inputs. To facilitate learning in an exponentially-growing compositional space, we introduce a joint parsing and expected execution algorithm, which does local marginalization over derivations to reduce the training time. We evaluate G2L2 on two domains: visual reasoning and language-driven navigation. Results show that G2L2 can generalize from small amounts of data to novel compositions of words.
Teaching Networks to Solve Optimization Problems
Feb 08, 2022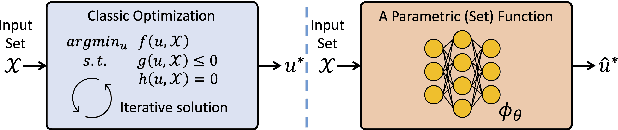
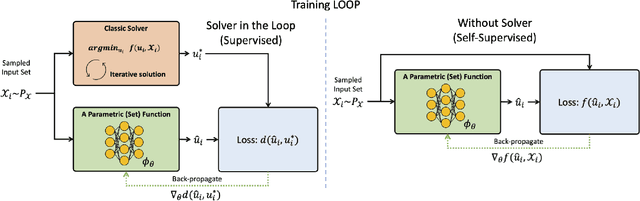
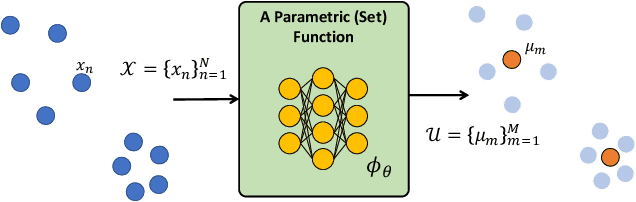
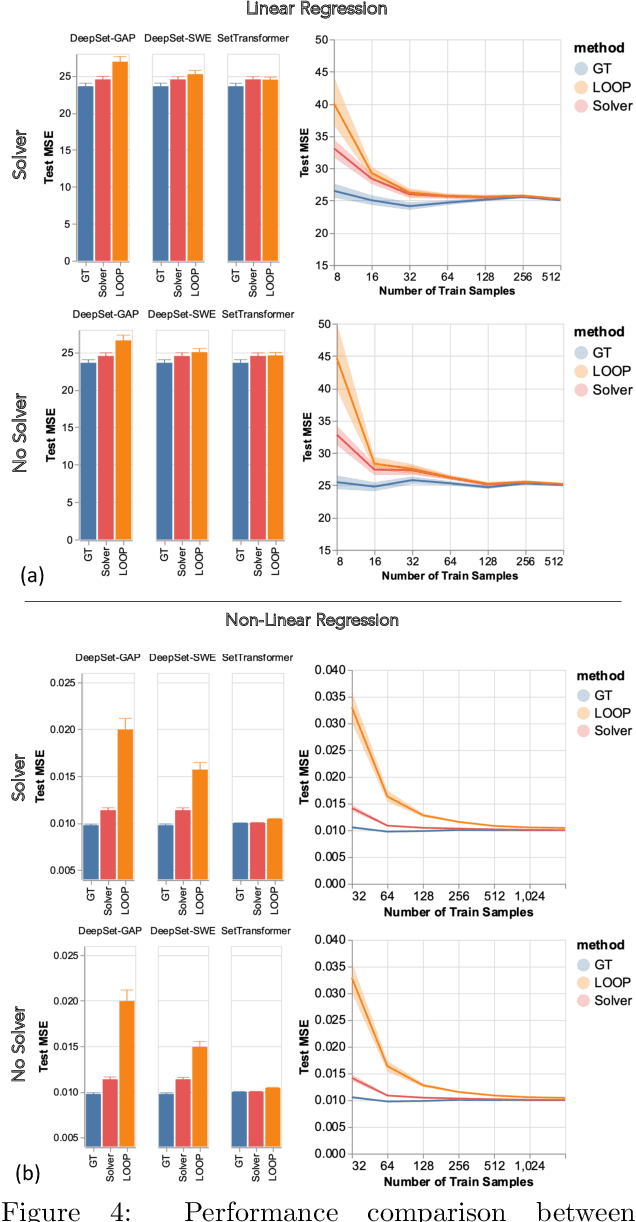
Leveraging machine learning to optimize the optimization process is an emerging field which holds the promise to bypass the fundamental computational bottleneck caused by traditional iterative solvers in critical applications requiring near-real-time optimization. The majority of existing approaches focus on learning data-driven optimizers that lead to fewer iterations in solving an optimization. In this paper, we take a different approach and propose to replace the iterative solvers altogether with a trainable parametric set function that outputs the optimal arguments/parameters of an optimization problem in a single feed-forward. We denote our method as, Learning to Optimize the Optimization Process (LOOP). We show the feasibility of learning such parametric (set) functions to solve various classic optimization problems, including linear/nonlinear regression, principal component analysis, transport-based core-set, and quadratic programming in supply management applications. In addition, we propose two alternative approaches for learning such parametric functions, with and without a solver in the-LOOP. Finally, we demonstrate the effectiveness of our proposed approach through various numerical experiments.
DRS-LIP: Linear Inverted Pendulum Model for Legged Locomotion on Dynamic Rigid Surfaces
Jan 31, 2022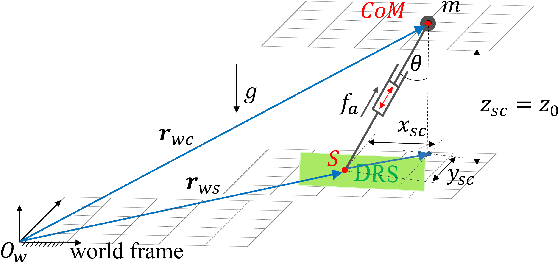
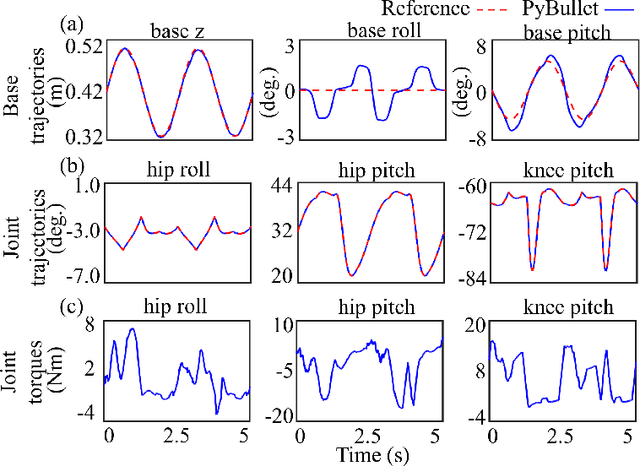
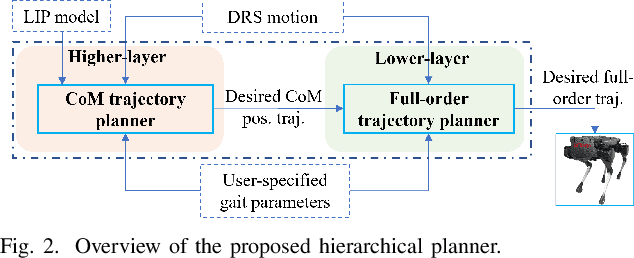
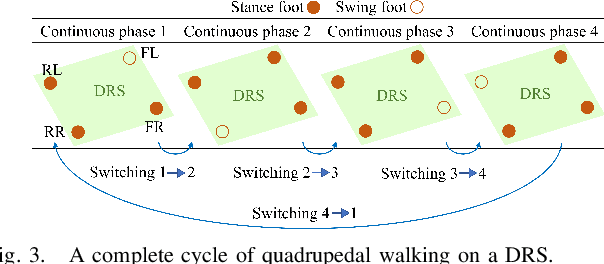
Legged robot locomotion on a dynamic rigid surface (i.e., a rigid surface moving in the inertial frame) involves complex full-order dynamics that is high-dimensional, nonlinear, and time-varying. Towards deriving an analytically tractable dynamic model, this study theoretically extends the reduced-order linear inverted pendulum (LIP) model from legged locomotion on a stationary surface to locomotion on a dynamic rigid surface (DRS). The resulting model is herein termed as DRS-LIP. Furthermore, this study introduces an approximate analytical solution of the proposed DRS-LIP that is computationally efficient with high accuracy. To illustrate the practical uses of the analytical results, they are used to develop a hierarchical planning framework that efficiently generates physically feasible trajectories for DRS locomotion. The effectiveness of the proposed theoretical results and motion planner is demonstrated both through simulations and experimentally on a Laikago quadrupedal robot that walks on a rocking treadmill.
cosFormer: Rethinking Softmax in Attention
Feb 17, 2022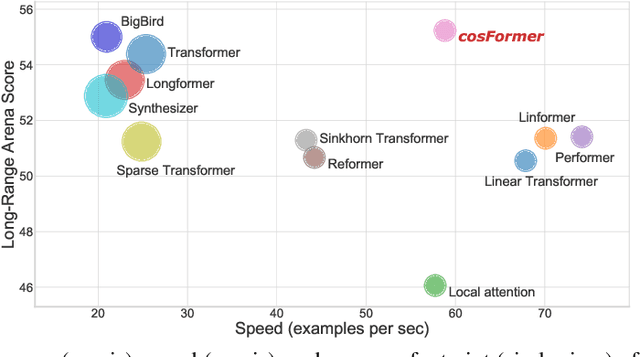
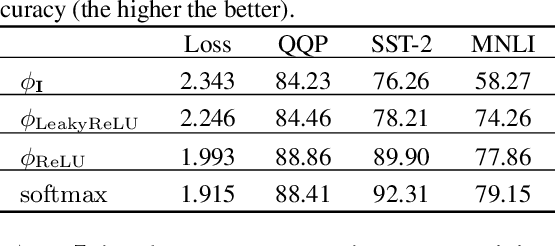
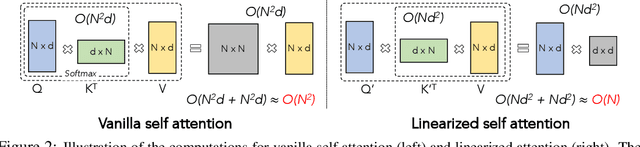
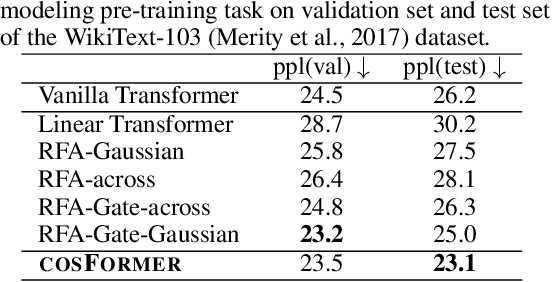
Transformer has shown great successes in natural language processing, computer vision, and audio processing. As one of its core components, the softmax attention helps to capture long-range dependencies yet prohibits its scale-up due to the quadratic space and time complexity to the sequence length. Kernel methods are often adopted to reduce the complexity by approximating the softmax operator. Nevertheless, due to the approximation errors, their performances vary in different tasks/corpus and suffer crucial performance drops when compared with the vanilla softmax attention. In this paper, we propose a linear transformer called cosFormer that can achieve comparable or better accuracy to the vanilla transformer in both casual and cross attentions. cosFormer is based on two key properties of softmax attention: i). non-negativeness of the attention matrix; ii). a non-linear re-weighting scheme that can concentrate the distribution of the attention matrix. As its linear substitute, cosFormer fulfills these properties with a linear operator and a cosine-based distance re-weighting mechanism. Extensive experiments on language modeling and text understanding tasks demonstrate the effectiveness of our method. We further examine our method on long sequences and achieve state-of-the-art performance on the Long-Range Arena benchmark. The source code is available at https://github.com/OpenNLPLab/cosFormer.
Sparse-Push: Communication- & Energy-Efficient Decentralized Distributed Learning over Directed & Time-Varying Graphs with non-IID Datasets
Feb 12, 2021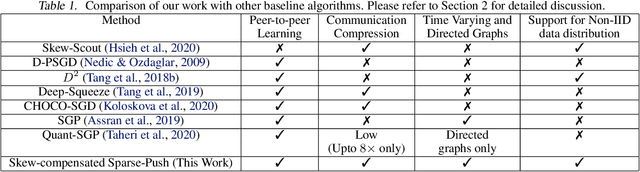
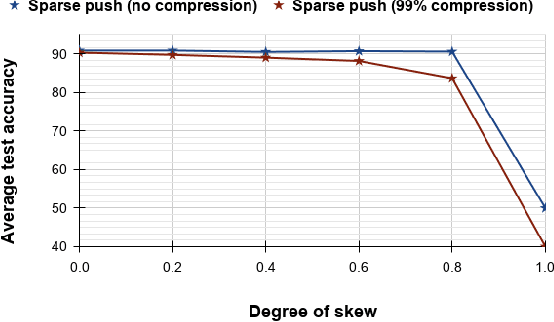
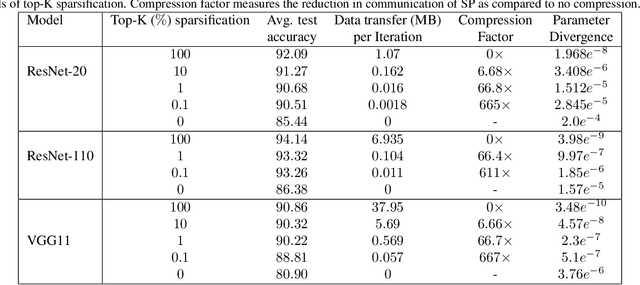
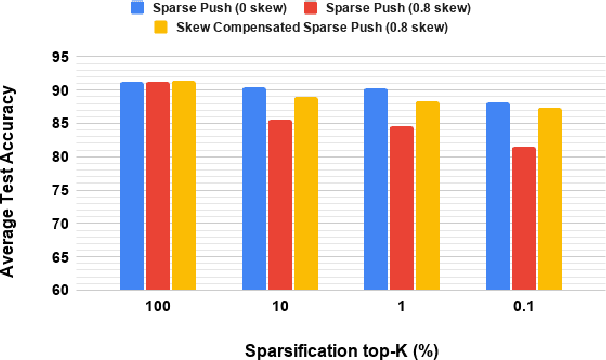
Current deep learning (DL) systems rely on a centralized computing paradigm which limits the amount of available training data, increases system latency, and adds privacy and security constraints. On-device learning, enabled by decentralized and distributed training of DL models over peer-to-peer wirelessly connected edge devices, not only alleviate the above limitations but also enable next-gen applications that need DL models to continuously interact and learn from their environment. However, this necessitates the development of novel training algorithms that train DL models over time-varying and directed peer-to-peer graph structures while minimizing the amount of communication between the devices and also being resilient to non-IID data distributions. In this work we propose, Sparse-Push, a communication efficient decentralized distributed training algorithm that supports training over peer-to-peer, directed, and time-varying graph topologies. The proposed algorithm enables 466x reduction in communication with only 1% degradation in performance when training various DL models such as ResNet-20 and VGG11 over the CIFAR-10 dataset. Further, we demonstrate how communication compression can lead to significant performance degradation in-case of non-IID datasets, and propose Skew-Compensated Sparse Push algorithm that recovers this performance drop while maintaining similar levels of communication compression.
Neural Datalog Through Time: Informed Temporal Modeling via Logical Specification
Jun 30, 2020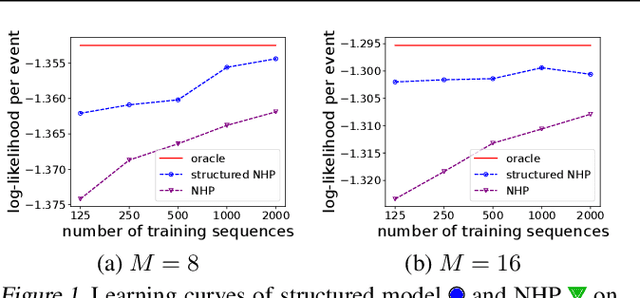
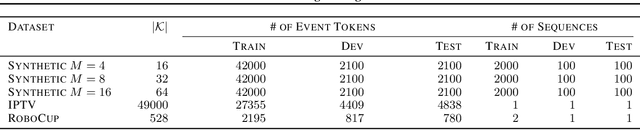
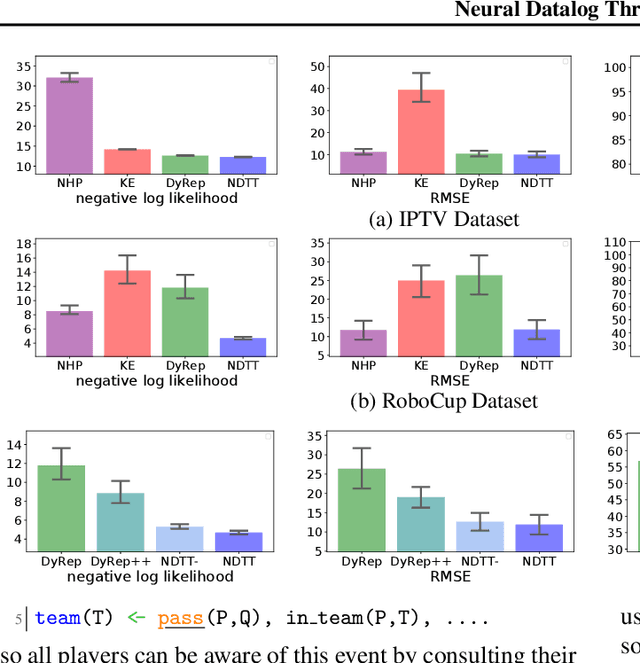
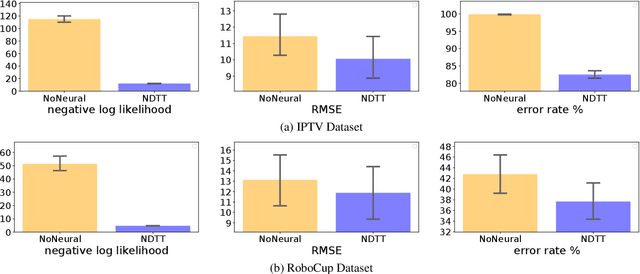
Learning how to predict future events from patterns of past events is difficult when the set of possible event types is large. Training an unrestricted neural model might overfit to spurious patterns. To exploit domain-specific knowledge of how past events might affect an event's present probability, we propose using a temporal deductive database to track structured facts over time. Rules serve to prove facts from other facts and from past events. Each fact has a time-varying state---a vector computed by a neural net whose topology is determined by the fact's provenance, including its experience of past events. The possible event types at any time are given by special facts, whose probabilities are neurally modeled alongside their states. In both synthetic and real-world domains, we show that neural probabilistic models derived from concise Datalog programs improve prediction by encoding appropriate domain knowledge in their architecture.
Strategy Synthesis for Zero-sum Neuro-symbolic Concurrent Stochastic Games
Feb 13, 2022
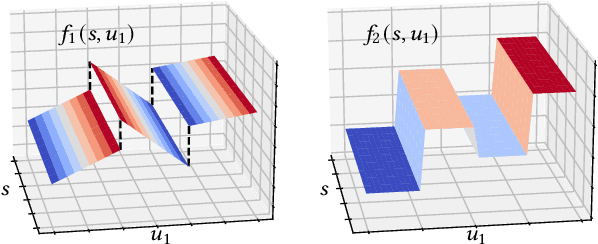
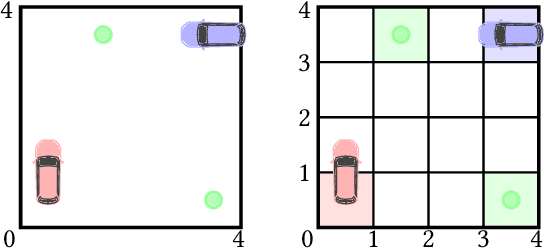
Neuro-symbolic approaches to artificial intelligence, which combine neural networks with classical symbolic techniques, are growing in prominence, necessitating formal approaches to reason about their correctness. We propose a novel modelling formalism called neuro-symbolic concurrent stochastic games (NS-CSGs), which comprise a set of probabilistic finite-state agents interacting in a shared continuous-state environment, observed through perception mechanisms implemented as neural networks. Since the environment state space is continuous, we focus on the class of NS-CSGs with Borel state spaces and Borel measurability restrictions on the components of the model. We consider the problem of zero-sum discounted cumulative reward, proving that NS-CSGs are determined and therefore have a value which corresponds to a unique fixed point. From an algorithmic perspective, existing methods to compute values and optimal strategies for CSGs focus on finite state spaces. We present, for the first time, value iteration and policy iteration algorithms to solve a class of uncountable state space CSGs, and prove their convergence. Our approach works by formulating piecewise linear or constant representations of the value functions and strategies of NS-CSGs. We validate the approach with a prototype implementation applied to a dynamic vehicle parking example.