 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning with distributional inverters
Dec 23, 2021
We generalize the "indirect learning" technique of Furst et. al., 1991 to reduce from learning a concept class over a samplable distribution $\mu$ to learning the same concept class over the uniform distribution. The reduction succeeds when the sampler for $\mu$ is both contained in the target concept class and efficiently invertible in the sense of Impagliazzo & Luby, 1989. We give two applications. - We show that AC0[q] is learnable over any succinctly-described product distribution. AC0[q] is the class of constant-depth Boolean circuits of polynomial size with AND, OR, NOT, and counting modulo $q$ gates of unbounded fanins. Our algorithm runs in randomized quasi-polynomial time and uses membership queries. - If there is a strongly useful natural property in the sense of Razborov & Rudich 1997 -- an efficient algorithm that can distinguish between random strings and strings of non-trivial circuit complexity -- then general polynomial-sized Boolean circuits are learnable over any efficiently samplable distribution in randomized polynomial time, given membership queries to the target function
Benchmarking Online Sequence-to-Sequence and Character-based Handwriting Recognition from IMU-Enhanced Pens
Feb 14, 2022Handwriting is one of the most frequently occurring patterns in everyday life and with it come challenging applications such as handwriting recognition (HWR), writer identification, and signature verification. In contrast to offline HWR that only uses spatial information (i.e., images), online HWR (OnHWR) uses richer spatio-temporal information (i.e., trajectory data or inertial data). While there exist many offline HWR datasets, there is only little data available for the development of OnHWR methods as it requires hardware-integrated pens. This paper presents data and benchmark models for real-time sequence-to-sequence (seq2seq) learning and single character-based recognition. Our data is recorded by a sensor-enhanced ballpoint pen, yielding sensor data streams from triaxial accelerometers, a gyroscope, a magnetometer and a force sensor at 100Hz. We propose a variety of datasets including equations and words for both the writer-dependent and writer-independent tasks. We provide an evaluation benchmark for seq2seq and single character-based HWR using recurrent and temporal convolutional networks and Transformers combined with a connectionist temporal classification (CTC) loss and cross entropy losses. Our methods do not resort to language or lexicon models.
Recurrent Neural Networks for Dynamical Systems: Applications to Ordinary Differential Equations, Collective Motion, and Hydrological Modeling
Feb 14, 2022

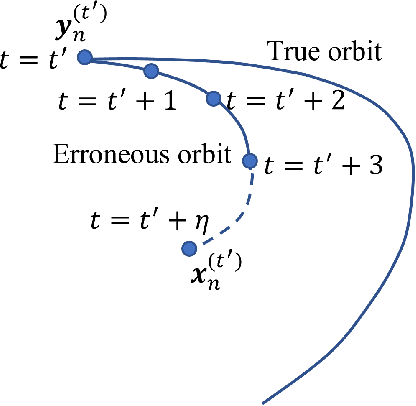

Classical methods of solving spatiotemporal dynamical systems include statistical approaches such as autoregressive integrated moving average, which assume linear and stationary relationships between systems' previous outputs. Development and implementation of linear methods are relatively simple, but they often do not capture non-linear relationships in the data. Thus, artificial neural networks (ANNs) are receiving attention from researchers in analyzing and forecasting dynamical systems. Recurrent neural networks (RNN), derived from feed-forward ANNs, use internal memory to process variable-length sequences of inputs. This allows RNNs to applicable for finding solutions for a vast variety of problems in spatiotemporal dynamical systems. Thus, in this paper, we utilize RNNs to treat some specific issues associated with dynamical systems. Specifically, we analyze the performance of RNNs applied to three tasks: reconstruction of correct Lorenz solutions for a system with a formulation error, reconstruction of corrupted collective motion trajectories, and forecasting of streamflow time series possessing spikes, representing three fields, namely, ordinary differential equations, collective motion, and hydrological modeling, respectively. We train and test RNNs uniquely in each task to demonstrate the broad applicability of RNNs in reconstruction and forecasting the dynamics of dynamical systems.
Augmenting Neural Networks with Priors on Function Values
Feb 10, 2022



The need for function estimation in label-limited settings is common in the natural sciences. At the same time, prior knowledge of function values is often available in these domains. For example, data-free biophysics-based models can be informative on protein properties, while quantum-based computations can be informative on small molecule properties. How can we coherently leverage such prior knowledge to help improve a neural network model that is quite accurate in some regions of input space -- typically near the training data -- but wildly wrong in other regions? Bayesian neural networks (BNN) enable the user to specify prior information only on the neural network weights, not directly on the function values. Moreover, there is in general no clear mapping between these. Herein, we tackle this problem by developing an approach to augment BNNs with prior information on the function values themselves. Our probabilistic approach yields predictions that rely more heavily on the prior information when the epistemic uncertainty is large, and more heavily on the neural network when the epistemic uncertainty is small.
COLA: COarse LAbel pre-training for 3D semantic segmentation of sparse LiDAR datasets
Feb 14, 2022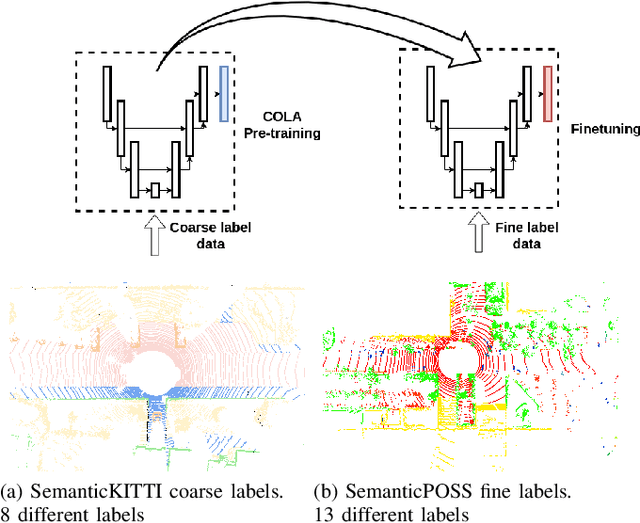
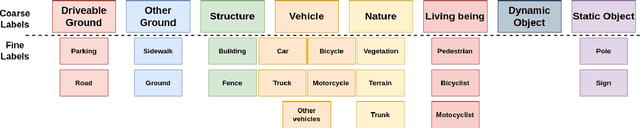
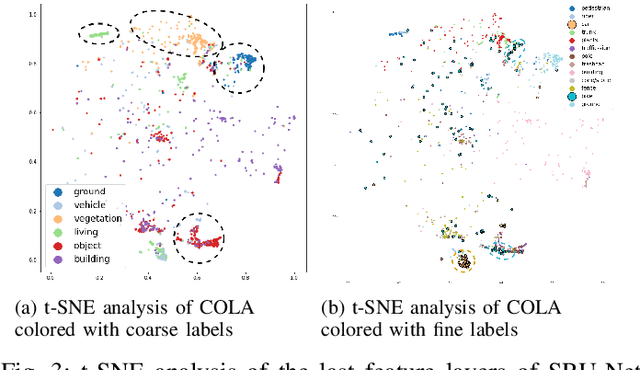
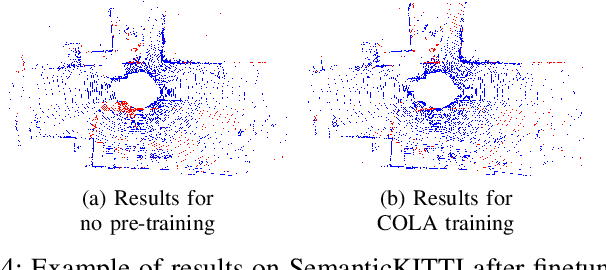
Transfer learning is a proven technique in 2D computer vision to leverage the large amount of data available and achieve high performance with datasets limited in size due to the cost of acquisition or annotation. In 3D, annotation is known to be a costly task; nevertheless, transfer learning methods have only recently been investigated. Unsupervised pre-training has been heavily favored as no very large annotated dataset are available. In this work, we tackle the case of real-time 3D semantic segmentation of sparse outdoor LiDAR scans. Such datasets have been on the rise, but with different label sets even for the same task. In this work, we propose here an intermediate-level label set called the coarse labels, which allows all the data available to be leveraged without any manual labelization. This way, we have access to a larger dataset, alongside a simpler task of semantic segmentation. With it, we introduce a new pre-training task: the coarse label pre-training, also called COLA. We thoroughly analyze the impact of COLA on various datasets and architectures and show that it yields a noticeable performance improvement, especially when the finetuning task has access only to a small dataset.
Active Sensing for Communications by Learning
Dec 08, 2021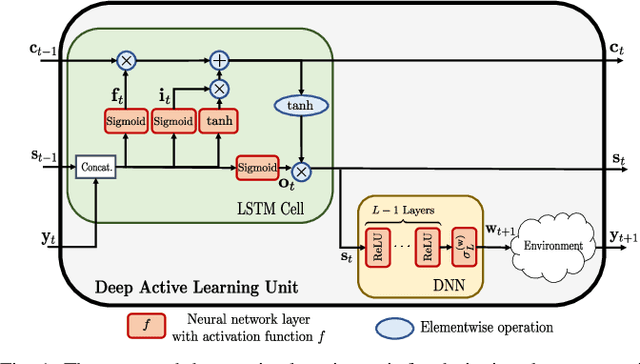
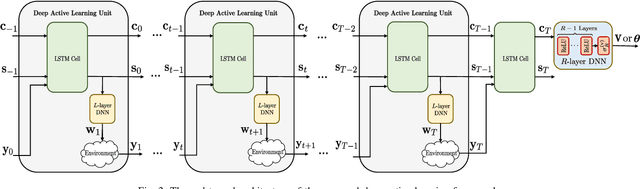
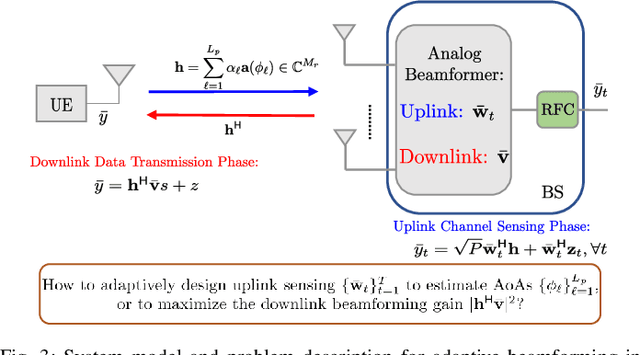
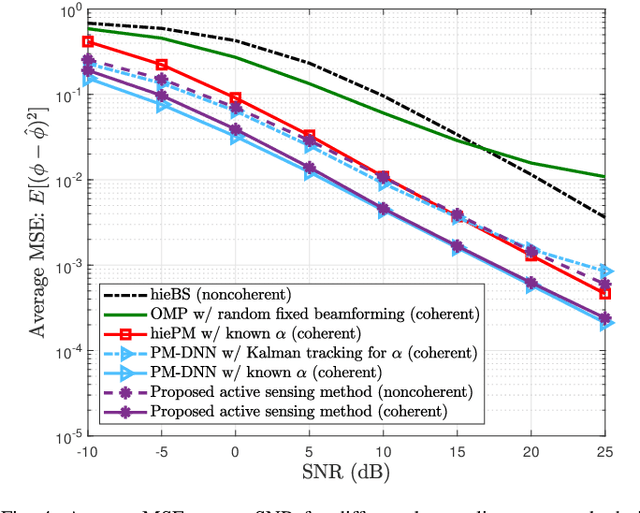
This paper proposes a deep learning approach to a class of active sensing problems in wireless communications in which an agent sequentially interacts with an environment over a predetermined number of time frames to gather information in order to perform a sensing or actuation task for maximizing some utility function. In such an active learning setting, the agent needs to design an adaptive sensing strategy sequentially based on the observations made so far. To tackle such a challenging problem in which the dimension of historical observations increases over time, we propose to use a long short-term memory (LSTM) network to exploit the temporal correlations in the sequence of observations and to map each observation to a fixed-size state information vector. We then use a deep neural network (DNN) to map the LSTM state at each time frame to the design of the next measurement step. Finally, we employ another DNN to map the final LSTM state to the desired solution. We investigate the performance of the proposed framework for adaptive channel sensing problems in wireless communications. In particular, we consider the adaptive beamforming problem for mmWave beam alignment and the adaptive reconfigurable intelligent surface sensing problem for reflection alignment. Numerical results demonstrate that the proposed deep active sensing strategy outperforms the existing adaptive or nonadaptive sensing schemes.
SEED: Sound Event Early Detection via Evidential Uncertainty
Feb 05, 2022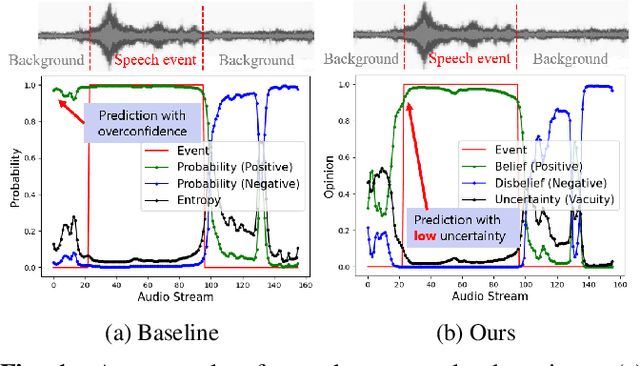

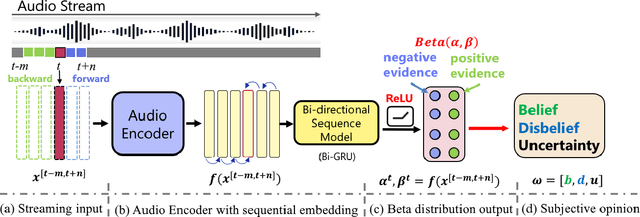
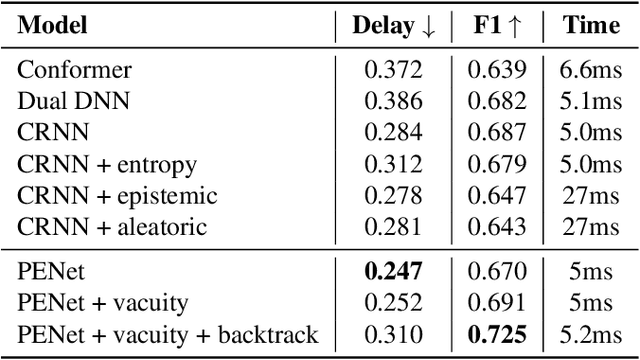
Sound Event Early Detection (SEED) is an essential task in recognizing the acoustic environments and soundscapes. However, most of the existing methods focus on the offline sound event detection, which suffers from the over-confidence issue of early-stage event detection and usually yield unreliable results. To solve the problem, we propose a novel Polyphonic Evidential Neural Network (PENet) to model the evidential uncertainty of the class probability with Beta distribution. Specifically, we use a Beta distribution to model the distribution of class probabilities, and the evidential uncertainty enriches uncertainty representation with evidence information, which plays a central role in reliable prediction. To further improve the event detection performance, we design the backtrack inference method that utilizes both the forward and backward audio features of an ongoing event. Experiments on the DESED database show that the proposed method can simultaneously improve 13.0\% and 3.8\% in time delay and detection F1 score compared to the state-of-the-art methods.
Per-link Parallel and Distributed Hybrid Beamforming for Multi-Cell Massive MIMO Millimeter Wave Full Duplex
Jan 09, 2022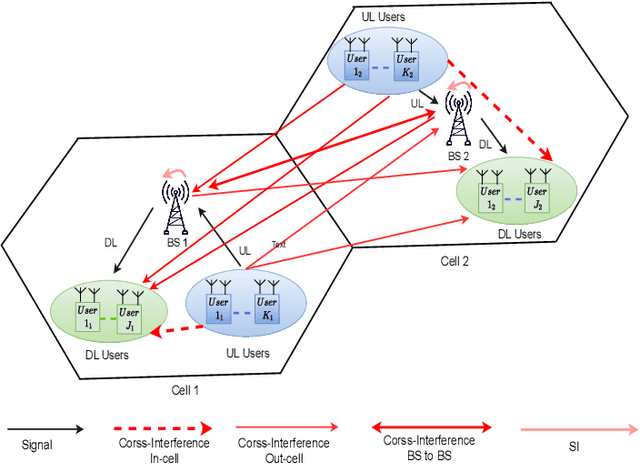
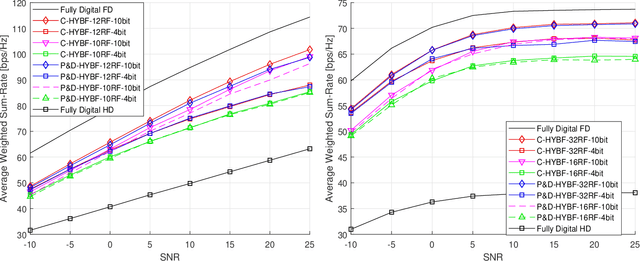
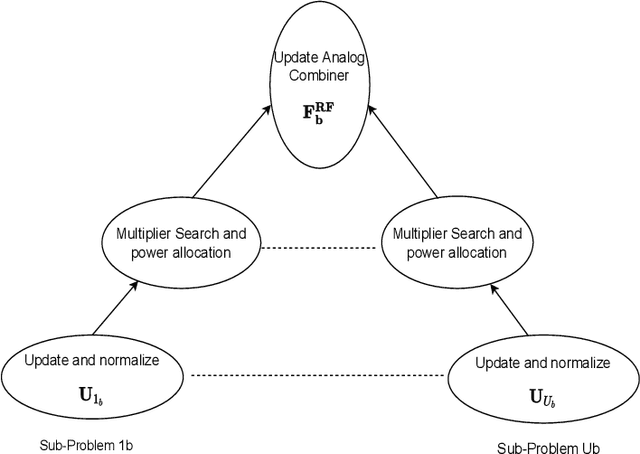
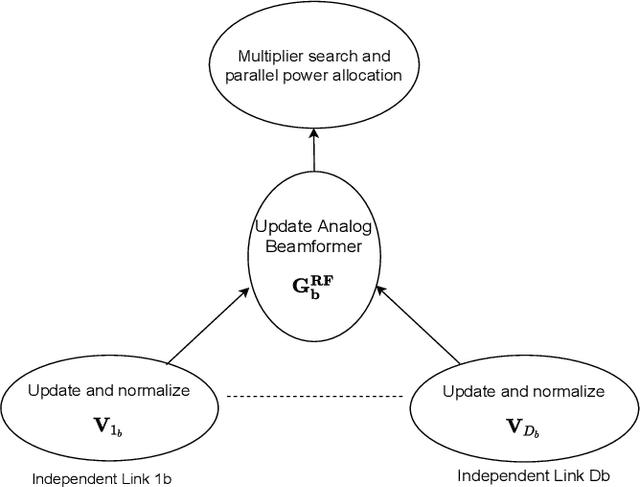
This paper presents two novel hybrid beamforming (HYBF) designs for a multi-cell massive multiple-input-multiple-output (mMIMO) millimeter wave (mmWave) full duplex (FD) system under limited dynamic range (LDR). Firstly, we present a novel centralized HYBF (C-HYBF) scheme based on alternating optimization. In general, the complexity of C-HYBF schemes scales quadratically as a function of the number of users and cells, which may limit their scalability. Moreover, they require significant communication overhead to transfer complete channel state information (CSI) to the central node every channel coherence time for optimization. The central node also requires very high computational power to jointly optimize many variables for the uplink (UL) and downlink (DL) users in FD systems. To overcome these drawbacks, we propose a very low-complexity and scalable cooperative per-link parallel and distributed (P$\&$D)-HYBF scheme. It allows each mmWave FD base station (BS) to update the beamformers for its users in a distributed fashion and independently in parallel on different computational processors. The complexity of P$\&$D-HYBF scales only linearly as the network size grows, making it desirable for the next generation of large and dense mmWave FD networks. Simulation results show that both designs significantly outperform the fully digital half duplex (HD) system with only a few radio-frequency (RF) chains, achieve similar performance, and the P$\&$D-HYBF design requires considerably less execution time.
Machine Learning in Heterogeneous Porous Materials
Feb 04, 2022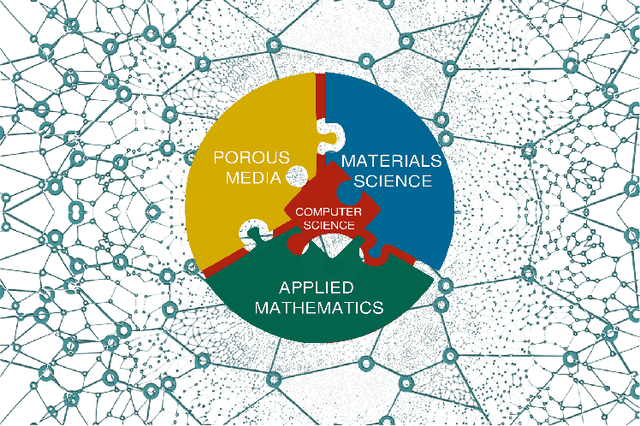

The "Workshop on Machine learning in heterogeneous porous materials" brought together international scientific communities of applied mathematics, porous media, and material sciences with experts in the areas of heterogeneous materials, machine learning (ML) and applied mathematics to identify how ML can advance materials research. Within the scope of ML and materials research, the goal of the workshop was to discuss the state-of-the-art in each community, promote crosstalk and accelerate multi-disciplinary collaborative research, and identify challenges and opportunities. As the end result, four topic areas were identified: ML in predicting materials properties, and discovery and design of novel materials, ML in porous and fractured media and time-dependent phenomena, Multi-scale modeling in heterogeneous porous materials via ML, and Discovery of materials constitutive laws and new governing equations. This workshop was part of the AmeriMech Symposium series sponsored by the National Academies of Sciences, Engineering and Medicine and the U.S. National Committee on Theoretical and Applied Mechanics.
YONO: Modeling Multiple Heterogeneous Neural Networks on Microcontrollers
Mar 08, 2022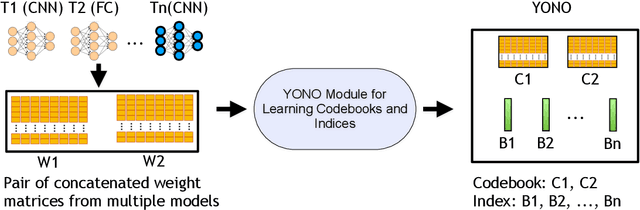
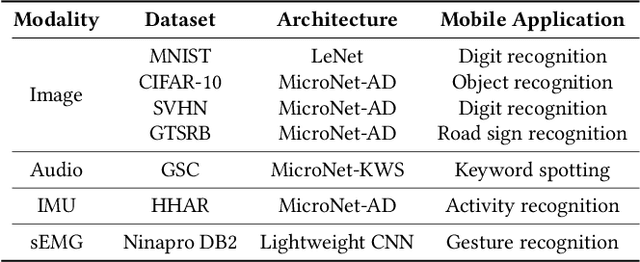
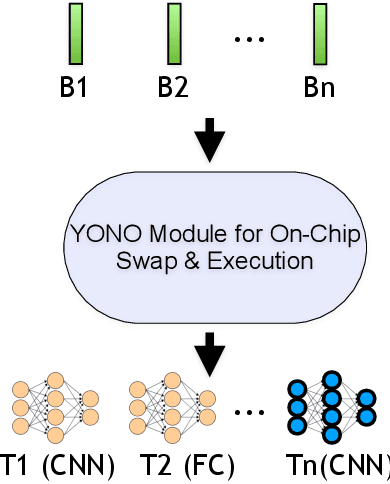

With the advancement of Deep Neural Networks (DNN) and large amounts of sensor data from Internet of Things (IoT) systems, the research community has worked to reduce the computational and resource demands of DNN to compute on low-resourced microcontrollers (MCUs). However, most of the current work in embedded deep learning focuses on solving a single task efficiently, while the multi-tasking nature and applications of IoT devices demand systems that can handle a diverse range of tasks (activity, voice, and context recognition) with input from a variety of sensors, simultaneously. In this paper, we propose YONO, a product quantization (PQ) based approach that compresses multiple heterogeneous models and enables in-memory model execution and switching for dissimilar multi-task learning on MCUs. We first adopt PQ to learn codebooks that store weights of different models. Also, we propose a novel network optimization and heuristics to maximize the compression rate and minimize the accuracy loss. Then, we develop an online component of YONO for efficient model execution and switching between multiple tasks on an MCU at run time without relying on an external storage device. YONO shows remarkable performance as it can compress multiple heterogeneous models with negligible or no loss of accuracy up to 12.37$\times$. Besides, YONO's online component enables an efficient execution (latency of 16-159 ms per operation) and reduces model loading/switching latency and energy consumption by 93.3-94.5% and 93.9-95.0%, respectively, compared to external storage access. Interestingly, YONO can compress various architectures trained with datasets that were not shown during YONO's offline codebook learning phase showing the generalizability of our method. To summarize, YONO shows great potential and opens further doors to enable multi-task learning systems on extremely resource-constrained devices.