 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Policy Space Response Oracles
Feb 17, 2022
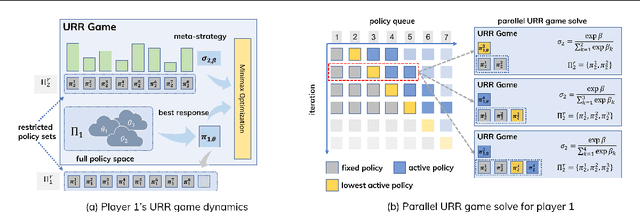
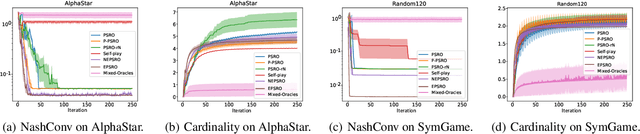
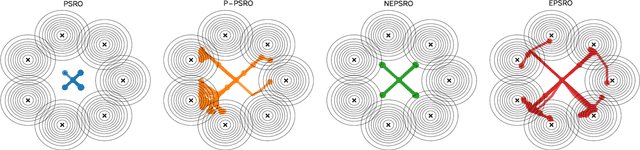
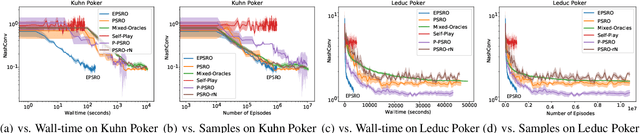
Policy Space Response Oracle method (PSRO) provides a general solution to Nash equilibrium in two-player zero-sum games but suffers from two problems: (1) the computation inefficiency due to consistently evaluating current populations by simulations; and (2) the exploration inefficiency due to learning best responses against a fixed meta-strategy at each iteration. In this work, we propose Efficient PSRO (EPSRO) that largely improves the efficiency of the above two steps. Central to our development is the newly-introduced subroutine of minimax optimization on unrestricted-restricted (URR) games. By solving URR at each step, one can evaluate the current game and compute the best response in one forward pass with no need for game simulations. Theoretically, we prove that the solution procedures of EPSRO offer a monotonic improvement on exploitability. Moreover, a desirable property of EPSRO is that it is parallelizable, this allows for efficient exploration in the policy space that induces behavioral diversity. We test EPSRO on three classes of games and report a 50x speedup in wall-time, 10x data efficiency, and similar exploitability as existing PSRO methods on Kuhn and Leduc Poker games.
MIDAS: Deep learning human action intention prediction from natural eye movement patterns
Jan 22, 2022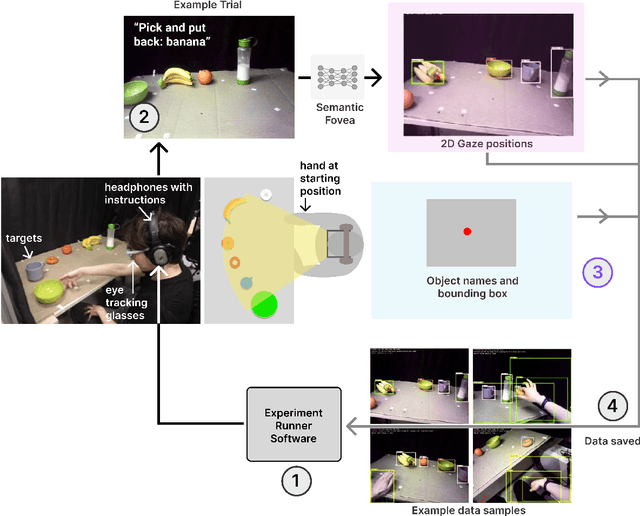
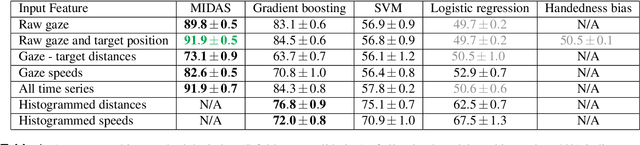
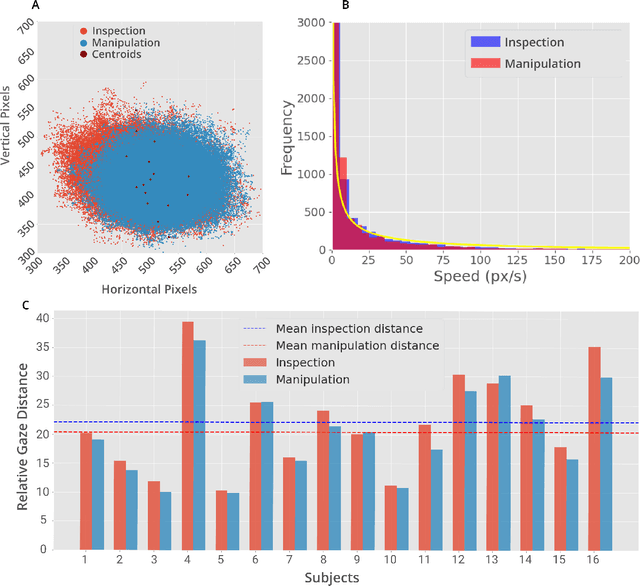
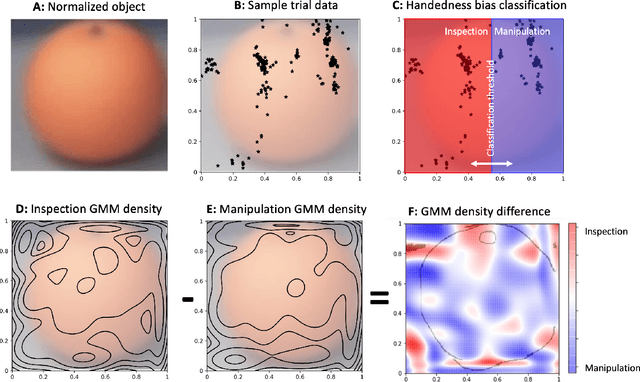
Eye movements have long been studied as a window into the attentional mechanisms of the human brain and made accessible as novelty style human-machine interfaces. However, not everything that we gaze upon, is something we want to interact with; this is known as the Midas Touch problem for gaze interfaces. To overcome the Midas Touch problem, present interfaces tend not to rely on natural gaze cues, but rather use dwell time or gaze gestures. Here we present an entirely data-driven approach to decode human intention for object manipulation tasks based solely on natural gaze cues. We run data collection experiments where 16 participants are given manipulation and inspection tasks to be performed on various objects on a table in front of them. The subjects' eye movements are recorded using wearable eye-trackers allowing the participants to freely move their head and gaze upon the scene. We use our Semantic Fovea, a convolutional neural network model to obtain the objects in the scene and their relation to gaze traces at every frame. We then evaluate the data and examine several ways to model the classification task for intention prediction. Our evaluation shows that intention prediction is not a naive result of the data, but rather relies on non-linear temporal processing of gaze cues. We model the task as a time series classification problem and design a bidirectional Long-Short-Term-Memory (LSTM) network architecture to decode intentions. Our results show that we can decode human intention of motion purely from natural gaze cues and object relative position, with $91.9\%$ accuracy. Our work demonstrates the feasibility of natural gaze as a Zero-UI interface for human-machine interaction, i.e., users will only need to act naturally, and do not need to interact with the interface itself or deviate from their natural eye movement patterns.
Machine Learning Empowered Intelligent Data Center Networking: A Survey
Mar 01, 2022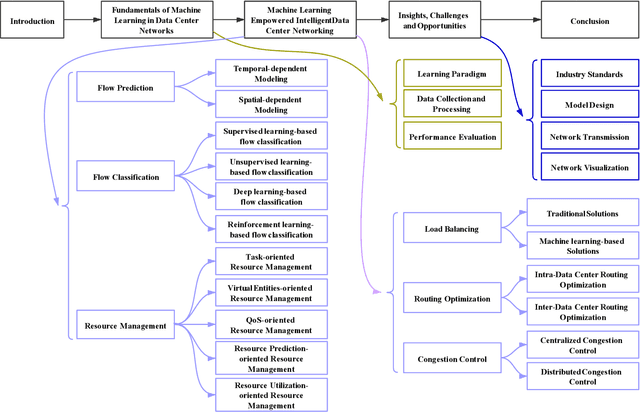
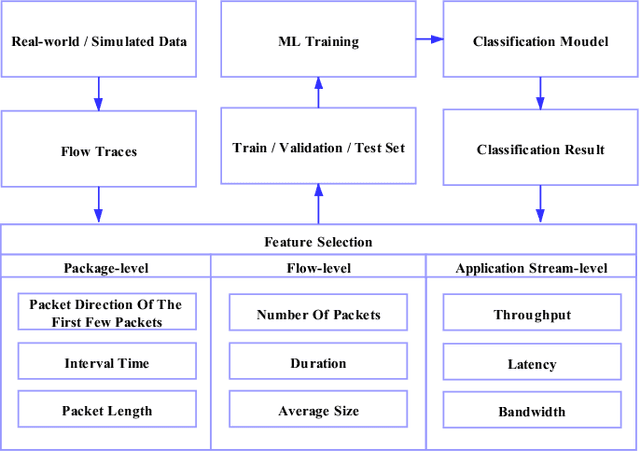
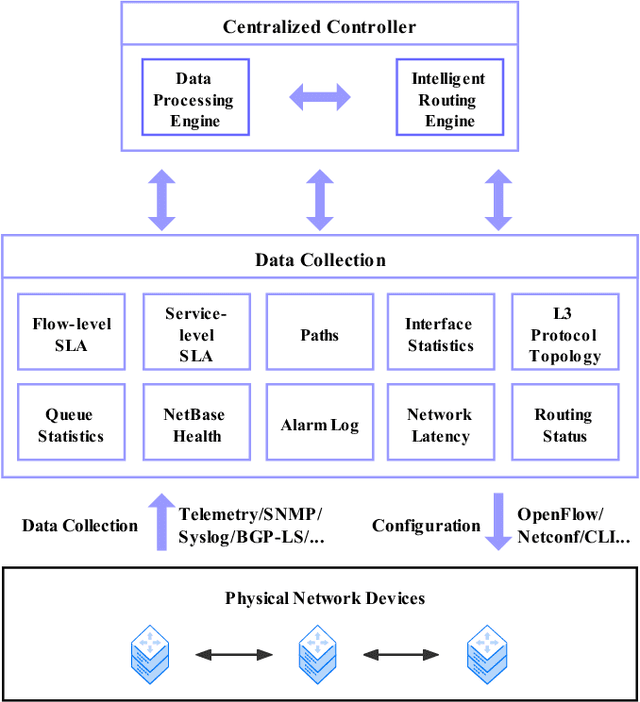
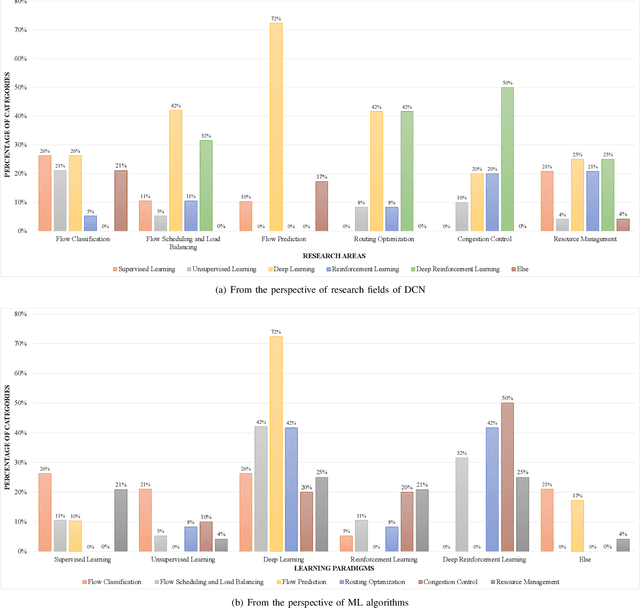
To support the needs of ever-growing cloud-based services, the number of servers and network devices in data centers is increasing exponentially, which in turn results in high complexities and difficulties in network optimization. To address these challenges, both academia and industry turn to artificial intelligence technology to realize network intelligence. To this end, a considerable number of novel and creative machine learning-based (ML-based) research works have been put forward in recent few years. Nevertheless, there are still enormous challenges faced by the intelligent optimization of data center networks (DCNs), especially in the scenario of online real-time dynamic processing of massive heterogeneous services and traffic data. To best of our knowledge, there is a lack of systematic and original comprehensively investigations with in-depth analysis on intelligent DCN. To this end, in this paper, we comprehensively investigate the application of machine learning to data center networking, and provide a general overview and in-depth analysis of the recent works, covering flow prediction, flow classification, load balancing, resource management, routing optimization, and congestion control. In order to provide a multi-dimensional and multi-perspective comparison of various solutions, we design a quality assessment criteria called REBEL-3S to impartially measure the strengths and weaknesses of these research works. Moreover, we also present unique insights into the technology evolution of the fusion of data center network and machine learning, together with some challenges and potential future research opportunities.
Autonomous Robotic Screening of Tubular Structures based only on Real-Time Ultrasound Imaging Feedback
Oct 30, 2020

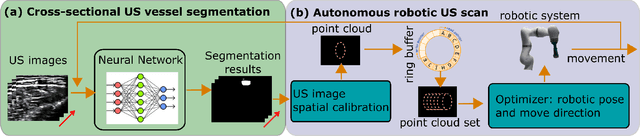
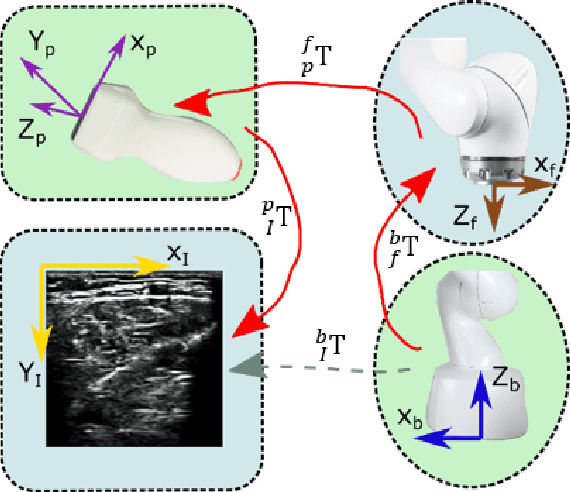
Ultrasound (US) imaging is widely employed for diagnosis and staging of peripheral vascular diseases (PVD), mainly due to its high availability and the fact it does not emit radiation. However, high inter-operator variability and a lack of repeatability of US image acquisition hinder the implementation of extensive screening programs. To address this challenge, we propose an end-to-end workflow for automatic robotic US screening of tubular structures using only the real-time US imaging feedback. We first train a U-Net for real-time segmentation of the vascular structure from cross-sectional US images. Then, we represent the detected vascular structure as a 3D point cloud and use it to estimate the longitudinal axis of the target tubular structure and its mean radius by solving a constrained non-linear optimization problem. Iterating the previous processes, the US probe is automatically aligned to the orientation normal to the target tubular tissue and adjusted online to center the tracked tissue based on the spatial calibration. The real-time segmentation result is evaluated both on a phantom and in-vivo on brachial arteries of volunteers. In addition, the whole process is validated both in simulation and physical phantoms. The mean absolute radius error and orientation error ($\pm$ SD) in the simulation are $1.16\pm0.1~mm$ and $2.7\pm3.3^{\circ}$, respectively. On a gel phantom, these errors are $1.95\pm2.02~mm$ and $3.3\pm2.4^{\circ}$. This shows that the method is able to automatically screen tubular tissues with an optimal probe orientation (i.e. normal to the vessel) and at the same to accurately estimate the mean radius, both in real-time.
SWIM: Selective Write-Verify for Computing-in-Memory Neural Accelerators
Feb 17, 2022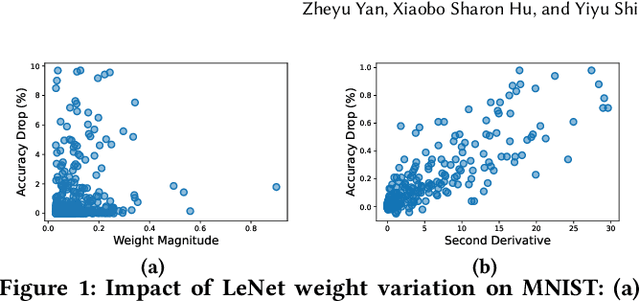
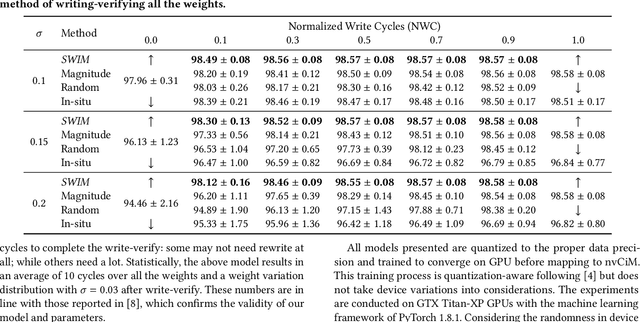
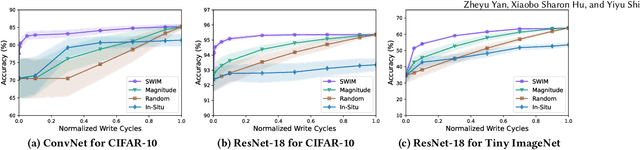
Computing-in-Memory architectures based on non-volatile emerging memories have demonstrated great potential for deep neural network (DNN) acceleration thanks to their high energy efficiency. However, these emerging devices can suffer from significant variations during the mapping process i.e., programming weights to the devices), and if left undealt with, can cause significant accuracy degradation. The non-ideality of weight mapping can be compensated by iterative programming with a write-verify scheme, i.e., reading the conductance and rewriting if necessary. In all existing works, such a practice is applied to every single weight of a DNN as it is being mapped, which requires extensive programming time. In this work, we show that it is only necessary to select a small portion of the weights for write-verify to maintain the DNN accuracy, thus achieving significant speedup. We further introduce a second derivative based technique SWIM, which only requires a single pass of forward and backpropagation, to efficiently select the weights that need write-verify. Experimental results on various DNN architectures for different datasets show that SWIM can achieve up to 10x programming speedup compared with conventional full-blown write-verify while attaining a comparable accuracy.
Bellman Meets Hawkes: Model-Based Reinforcement Learning via Temporal Point Processes
Jan 29, 2022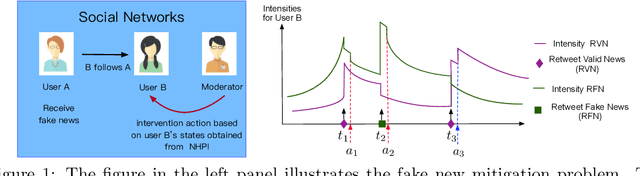
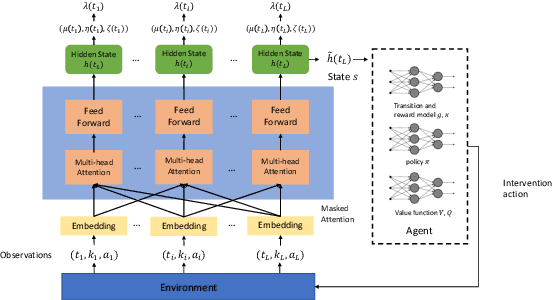
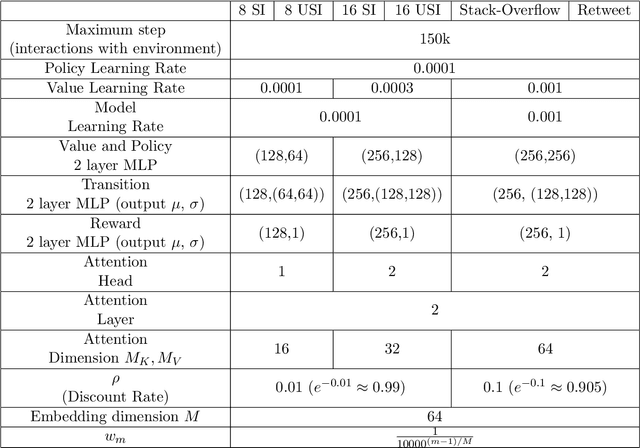
We consider a sequential decision making problem where the agent faces the environment characterized by the stochastic discrete events and seeks an optimal intervention policy such that its long-term reward is maximized. This problem exists ubiquitously in social media, finance and health informatics but is rarely investigated by the conventional research in reinforcement learning. To this end, we present a novel framework of the model-based reinforcement learning where the agent's actions and observations are asynchronous stochastic discrete events occurring in continuous-time. We model the dynamics of the environment by Hawkes process with external intervention control term and develop an algorithm to embed such process in the Bellman equation which guides the direction of the value gradient. We demonstrate the superiority of our method in both synthetic simulator and real-world problem.
Outlier-based Autism Detection using Longitudinal Structural MRI
Feb 21, 2022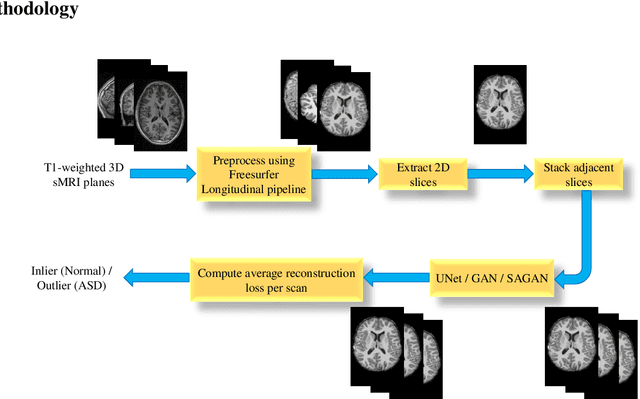
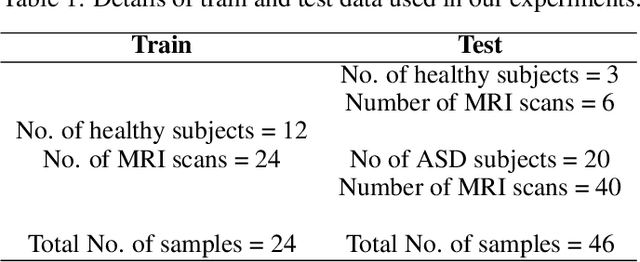
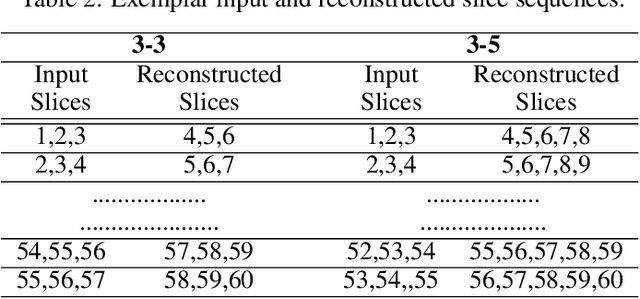
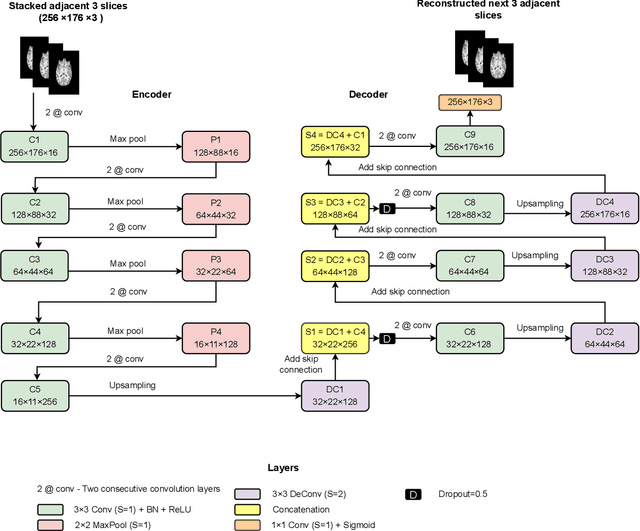
Diagnosis of Autism Spectrum Disorder (ASD) using clinical evaluation (cognitive tests) is challenging due to wide variations amongst individuals. Since no effective treatment exists, prompt and reliable ASD diagnosis can enable the effective preparation of treatment regimens. This paper proposes structural Magnetic Resonance Imaging (sMRI)-based ASD diagnosis via an outlier detection approach. To learn Spatio-temporal patterns in structural brain connectivity, a Generative Adversarial Network (GAN) is trained exclusively with sMRI scans of healthy subjects. Given a stack of three adjacent slices as input, the GAN generator reconstructs the next three adjacent slices; the GAN discriminator then identifies ASD sMRI scan reconstructions as outliers. This model is compared against two other baselines -- a simpler UNet and a sophisticated Self-Attention GAN. Axial, Coronal, and Sagittal sMRI slices from the multi-site ABIDE II dataset are used for evaluation. Extensive experiments reveal that our ASD detection framework performs comparably with the state-of-the-art with far fewer training data. Furthermore, longitudinal data (two scans per subject over time) achieve 17-28% higher accuracy than cross-sectional data (one scan per subject). Among other findings, metrics employed for model training as well as reconstruction loss computation impact detection performance, and the coronal modality is found to best encode structural information for ASD detection.
A Machine Learning Smartphone-based Sensing for Driver Behavior Classification
Feb 01, 2022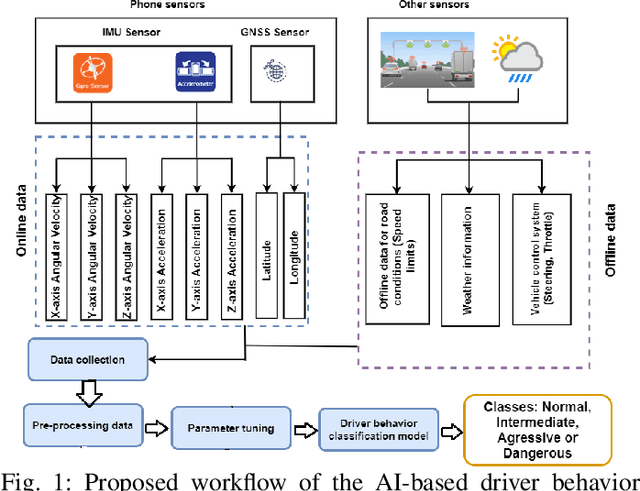

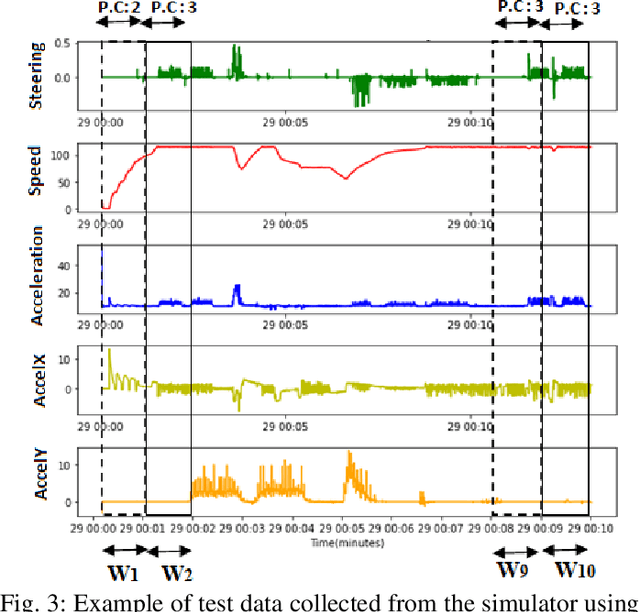
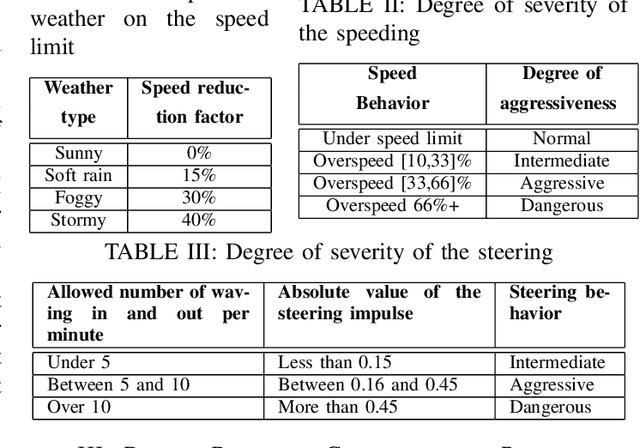
Driver behavior profiling is one of the main issues in the insurance industries and fleet management, thus being able to classify the driver behavior with low-cost mobile applications remains in the spotlight of autonomous driving. However, using mobile sensors may face the challenge of security, privacy, and trust issues. To overcome those challenges, we propose to collect data sensors using Carla Simulator available in smartphones (Accelerometer, Gyroscope, GPS) in order to classify the driver behavior using speed, acceleration, direction, the 3-axis rotation angles (Yaw, Pitch, Roll) taking into account the speed limit of the current road and weather conditions to better identify the risky behavior. Secondly, after fusing inter-axial data from multiple sensors into a single file, we explore different machine learning algorithms for time series classification to evaluate which algorithm results in the highest performance.
(k, l)-Medians Clustering of Trajectories Using Continuous Dynamic Time Warping
Dec 01, 2020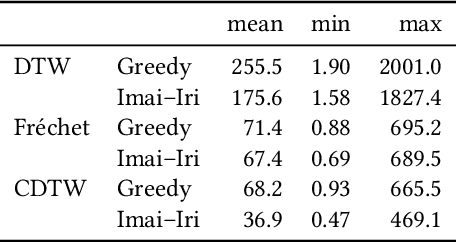
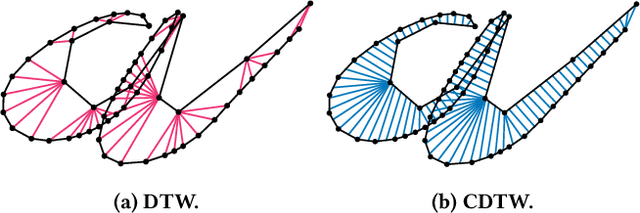
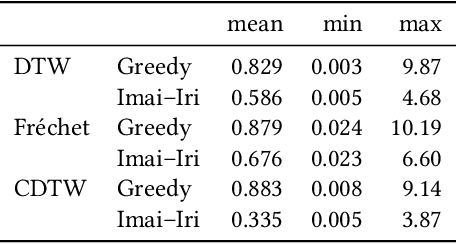
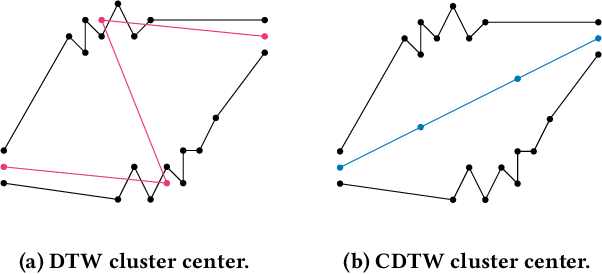
Due to the massively increasing amount of available geospatial data and the need to present it in an understandable way, clustering this data is more important than ever. As clusters might contain a large number of objects, having a representative for each cluster significantly facilitates understanding a clustering. Clustering methods relying on such representatives are called center-based. In this work we consider the problem of center-based clustering of trajectories. In this setting, the representative of a cluster is again a trajectory. To obtain a compact representation of the clusters and to avoid overfitting, we restrict the complexity of the representative trajectories by a parameter l. This restriction, however, makes discrete distance measures like dynamic time warping (DTW) less suited. There is recent work on center-based clustering of trajectories with a continuous distance measure, namely, the Fr\'echet distance. While the Fr\'echet distance allows for restriction of the center complexity, it can also be sensitive to outliers, whereas averaging-type distance measures, like DTW, are less so. To obtain a trajectory clustering algorithm that allows restricting center complexity and is more robust to outliers, we propose the usage of a continuous version of DTW as distance measure, which we call continuous dynamic time warping (CDTW). Our contribution is twofold: 1. To combat the lack of practical algorithms for CDTW, we develop an approximation algorithm that computes it. 2. We develop the first clustering algorithm under this distance measure and show a practical way to compute a center from a set of trajectories and subsequently iteratively improve it. To obtain insights into the results of clustering under CDTW on practical data, we conduct extensive experiments.
Expert Aggregation for Financial Forecasting
Dec 01, 2021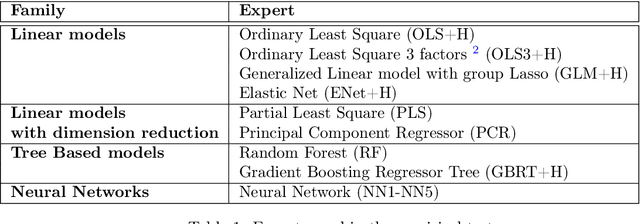
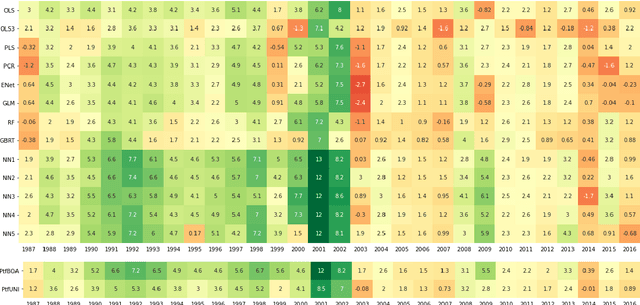
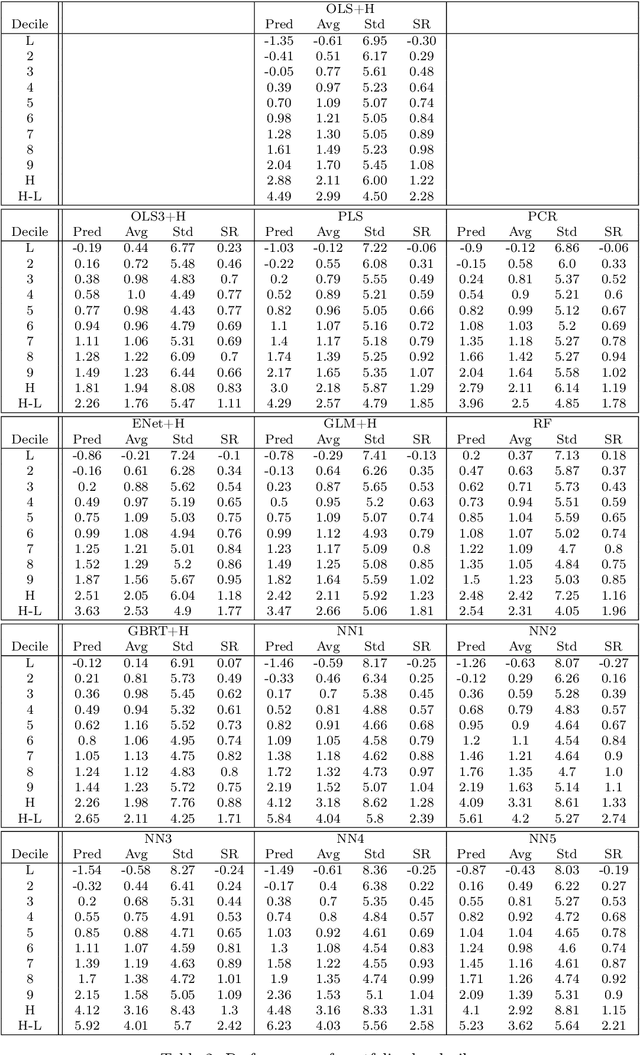
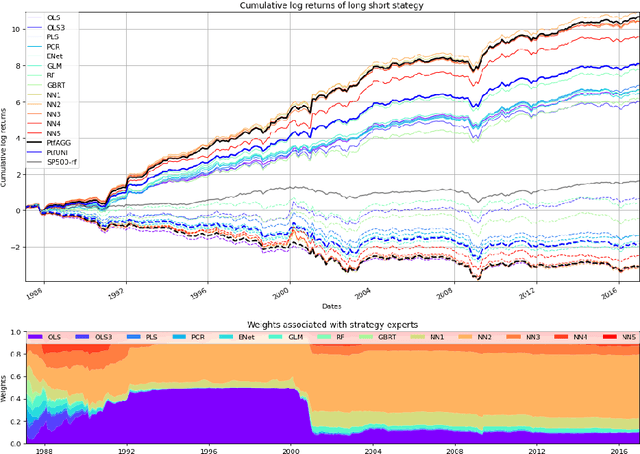
Machine learning algorithms dedicated to financial time series forecasting have gained a lot of interest over the last few years. One difficulty lies in the choice between several algorithms, as their estimation accuracy may be unstable through time. In this paper, we propose to apply an online aggregation-based forecasting model combining several machine learning techniques to build a portfolio which dynamically adapts itself to market conditions. We apply this aggregation technique to the construction of a long-short-portfolio of individual stocks ranked on their financial characteristics and we demonstrate how aggregation outperforms single algorithms both in terms of performances and of stability.