 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploring the pattern of Emotion in children with ASD as an early biomarker through Recurring-Convolution Neural Network (R-CNN)
Dec 30, 2021
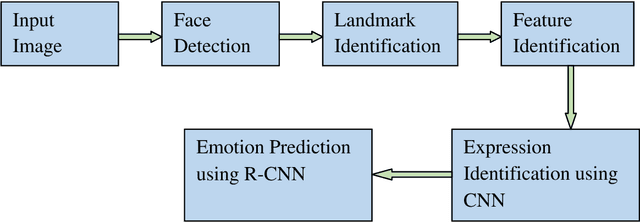
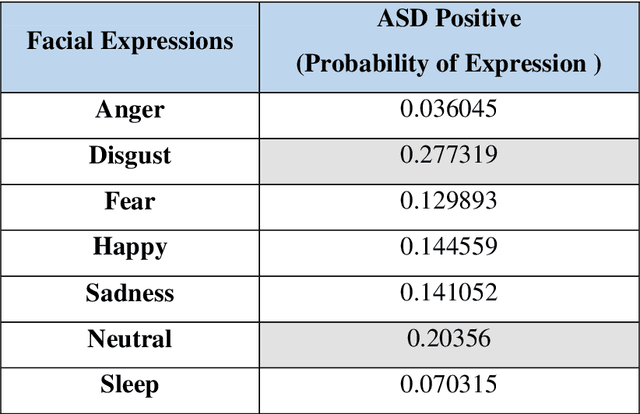
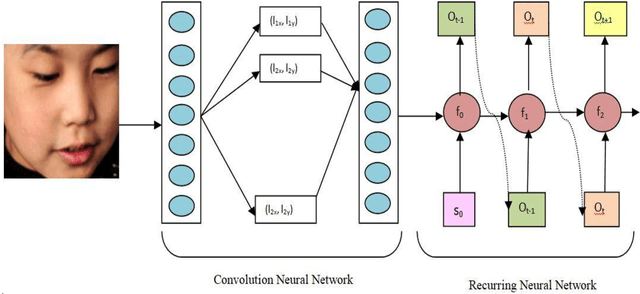
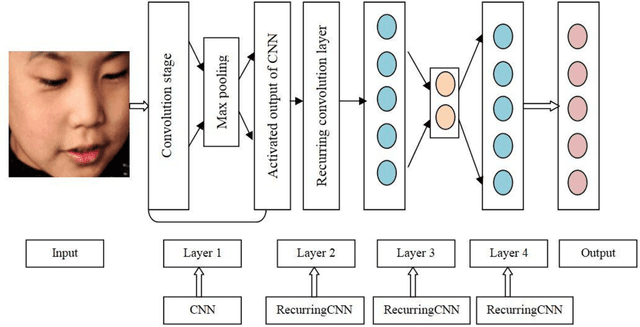
Autism Spectrum Disorder (ASD) is found to be a major concern among various occupational therapists. The foremost challenge of this neurodevelopmental disorder lies in the fact of analyzing and exploring various symptoms of the children at their early stage of development. Such early identification could prop up the therapists and clinicians to provide proper assistive support to make the children lead an independent life. Facial expressions and emotions perceived by the children could contribute to such early intervention of autism. In this regard, the paper implements in identifying basic facial expression and exploring their emotions upon a time variant factor. The emotions are analyzed by incorporating the facial expression identified through CNN using 68 landmark points plotted on the frontal face with a prediction network formed by RNN known as RCNN-FER system. The paper adopts R-CNN to take the advantage of increased accuracy and performance with decreased time complexity in predicting emotion as a textual network analysis. The papers proves better accuracy in identifying the emotion in autistic children when compared over simple machine learning models built for such identifications contributing to autistic society.
SWIM: Selective Write-Verify for Computing-in-Memory Neural Accelerators
Feb 17, 2022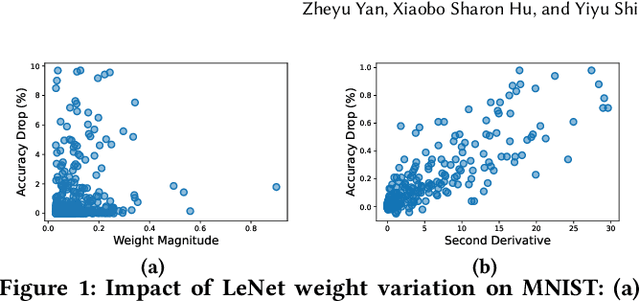
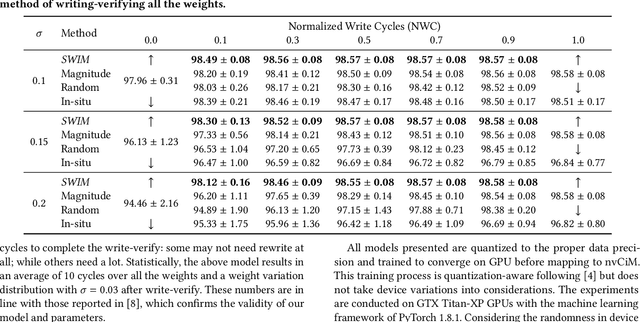
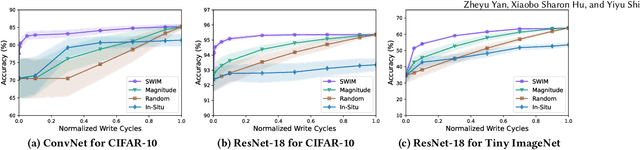
Computing-in-Memory architectures based on non-volatile emerging memories have demonstrated great potential for deep neural network (DNN) acceleration thanks to their high energy efficiency. However, these emerging devices can suffer from significant variations during the mapping process i.e., programming weights to the devices), and if left undealt with, can cause significant accuracy degradation. The non-ideality of weight mapping can be compensated by iterative programming with a write-verify scheme, i.e., reading the conductance and rewriting if necessary. In all existing works, such a practice is applied to every single weight of a DNN as it is being mapped, which requires extensive programming time. In this work, we show that it is only necessary to select a small portion of the weights for write-verify to maintain the DNN accuracy, thus achieving significant speedup. We further introduce a second derivative based technique SWIM, which only requires a single pass of forward and backpropagation, to efficiently select the weights that need write-verify. Experimental results on various DNN architectures for different datasets show that SWIM can achieve up to 10x programming speedup compared with conventional full-blown write-verify while attaining a comparable accuracy.
Video Frame Interpolation without Temporal Priors
Dec 02, 2021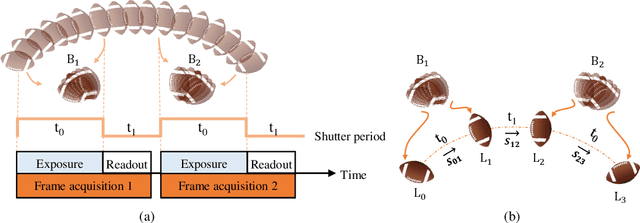
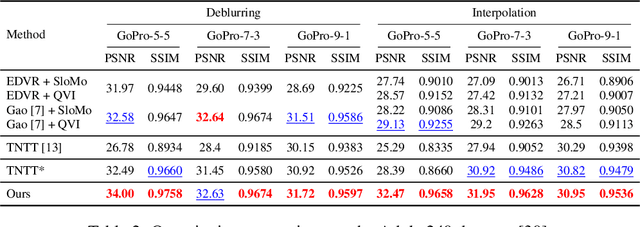
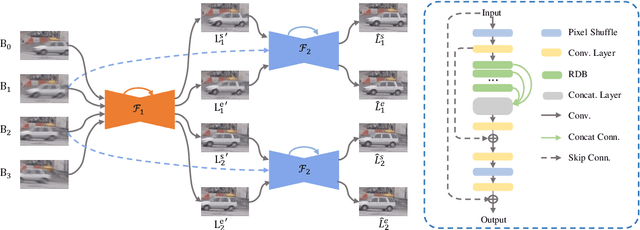
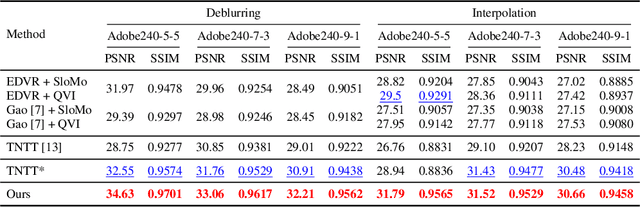
Video frame interpolation, which aims to synthesize non-exist intermediate frames in a video sequence, is an important research topic in computer vision. Existing video frame interpolation methods have achieved remarkable results under specific assumptions, such as instant or known exposure time. However, in complicated real-world situations, the temporal priors of videos, i.e. frames per second (FPS) and frame exposure time, may vary from different camera sensors. When test videos are taken under different exposure settings from training ones, the interpolated frames will suffer significant misalignment problems. In this work, we solve the video frame interpolation problem in a general situation, where input frames can be acquired under uncertain exposure (and interval) time. Unlike previous methods that can only be applied to a specific temporal prior, we derive a general curvilinear motion trajectory formula from four consecutive sharp frames or two consecutive blurry frames without temporal priors. Moreover, utilizing constraints within adjacent motion trajectories, we devise a novel optical flow refinement strategy for better interpolation results. Finally, experiments demonstrate that one well-trained model is enough for synthesizing high-quality slow-motion videos under complicated real-world situations. Codes are available on https://github.com/yjzhang96/UTI-VFI.
Outlier-based Autism Detection using Longitudinal Structural MRI
Feb 21, 2022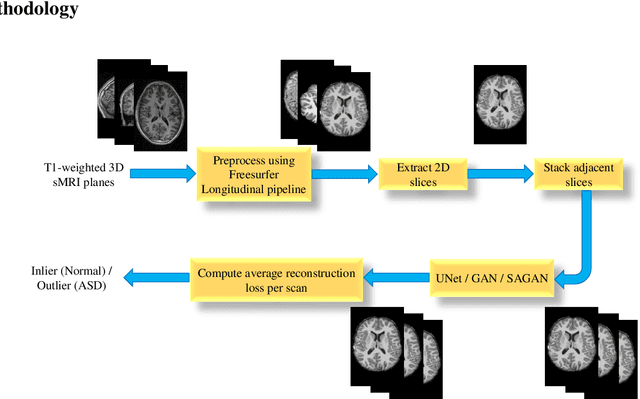
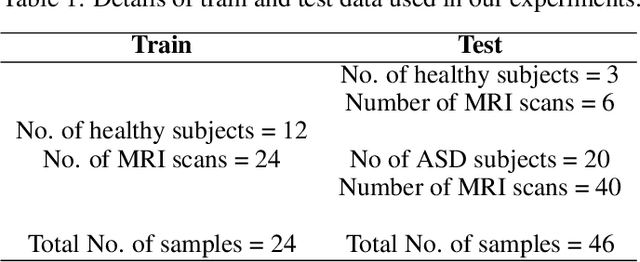
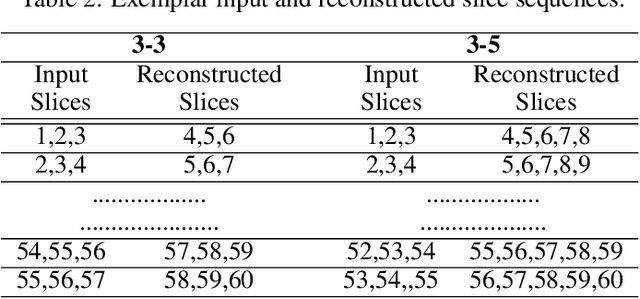
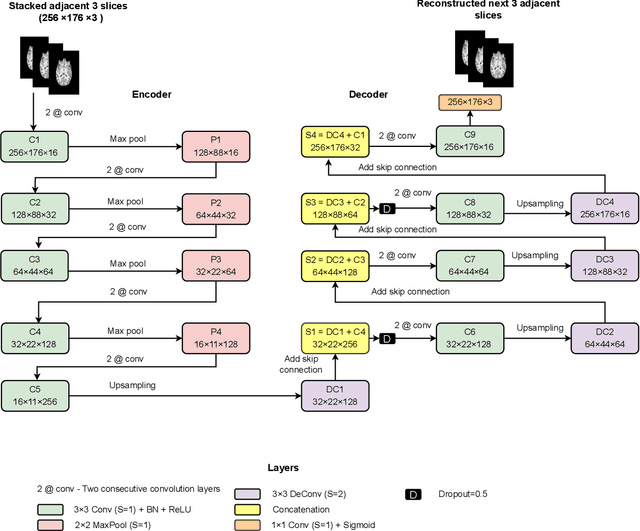
Diagnosis of Autism Spectrum Disorder (ASD) using clinical evaluation (cognitive tests) is challenging due to wide variations amongst individuals. Since no effective treatment exists, prompt and reliable ASD diagnosis can enable the effective preparation of treatment regimens. This paper proposes structural Magnetic Resonance Imaging (sMRI)-based ASD diagnosis via an outlier detection approach. To learn Spatio-temporal patterns in structural brain connectivity, a Generative Adversarial Network (GAN) is trained exclusively with sMRI scans of healthy subjects. Given a stack of three adjacent slices as input, the GAN generator reconstructs the next three adjacent slices; the GAN discriminator then identifies ASD sMRI scan reconstructions as outliers. This model is compared against two other baselines -- a simpler UNet and a sophisticated Self-Attention GAN. Axial, Coronal, and Sagittal sMRI slices from the multi-site ABIDE II dataset are used for evaluation. Extensive experiments reveal that our ASD detection framework performs comparably with the state-of-the-art with far fewer training data. Furthermore, longitudinal data (two scans per subject over time) achieve 17-28% higher accuracy than cross-sectional data (one scan per subject). Among other findings, metrics employed for model training as well as reconstruction loss computation impact detection performance, and the coronal modality is found to best encode structural information for ASD detection.
Real Time Speech Enhancement in the Waveform Domain
Jun 23, 2020
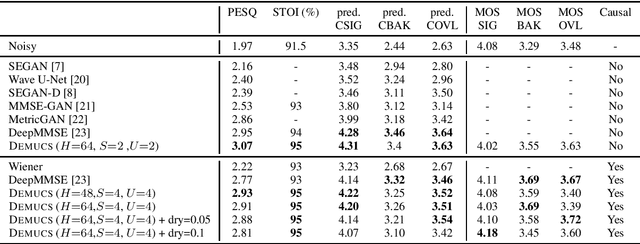
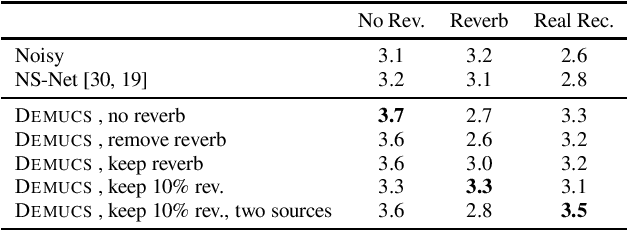

We present a causal speech enhancement model working on the raw waveform that runs in real-time on a laptop CPU. The proposed model is based on an encoder-decoder architecture with skip-connections. It is optimized on both time and frequency domains, using multiple loss functions. Empirical evidence shows that it is capable of removing various kinds of background noise including stationary and non-stationary noises, as well as room reverb. Additionally, we suggest a set of data augmentation techniques applied directly on the raw waveform which further improve model performance and its generalization abilities. We perform evaluations on several standard benchmarks, both using objective metrics and human judgements. The proposed model matches state-of-the-art performance of both causal and non causal methods while working directly on the raw waveform.
High Precision Real Time Collision Detection
Jul 23, 2020


Collision detection and collision avoidance are essential components in these systems for safe human-robot interactions. Robotics systems that can work "out-of-the-box" without excessive amount of installation and calibration from the experts is highly ideal. For this, we propose a generic, high precision, collision detect system that only requires the unified robot description format (URDF) and is capable of running in real time. We extended the Gilbert-Johnson-Keerthi (GJK) algorithm by utilizing a geometrical approach to determine the distance between each rigid body in the environment and check for collisions. The proposed system's performance is shown by checking the self-collision of the KUKA LBR iiwa 7 R800 and the Mecademic Meca500. The performance is compared to the Flexible Collision Library (FCL).
SegTransVAE: Hybrid CNN -- Transformer with Regularization for medical image segmentation
Jan 26, 2022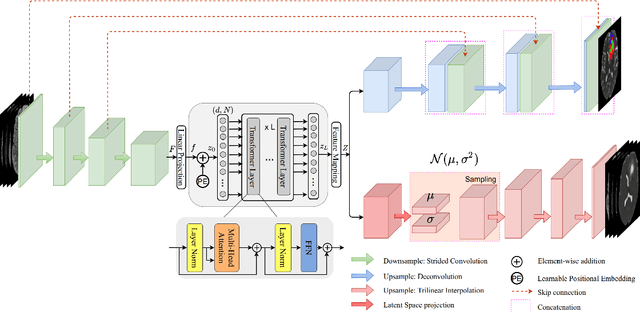
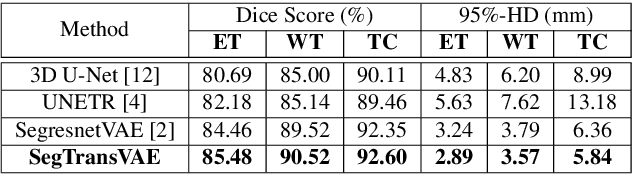
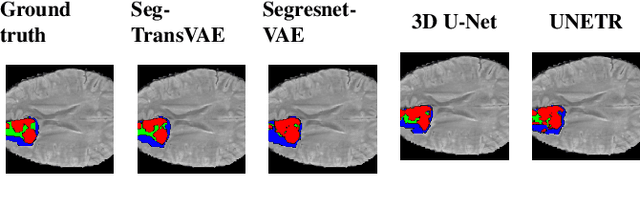
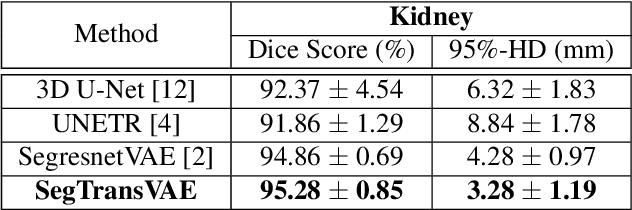
Current research on deep learning for medical image segmentation exposes their limitations in learning either global semantic information or local contextual information. To tackle these issues, a novel network named SegTransVAE is proposed in this paper. SegTransVAE is built upon encoder-decoder architecture, exploiting transformer with the variational autoencoder (VAE) branch to the network to reconstruct the input images jointly with segmentation. To the best of our knowledge, this is the first method combining the success of CNN, transformer, and VAE. Evaluation on various recently introduced datasets shows that SegTransVAE outperforms previous methods in Dice Score and $95\%$-Haudorff Distance while having comparable inference time to a simple CNN-based architecture network. The source code is available at: https://github.com/itruonghai/SegTransVAE.
Using Convolutional Neural Networks for fault analysis and alleviation in accelerator systems
Dec 05, 2021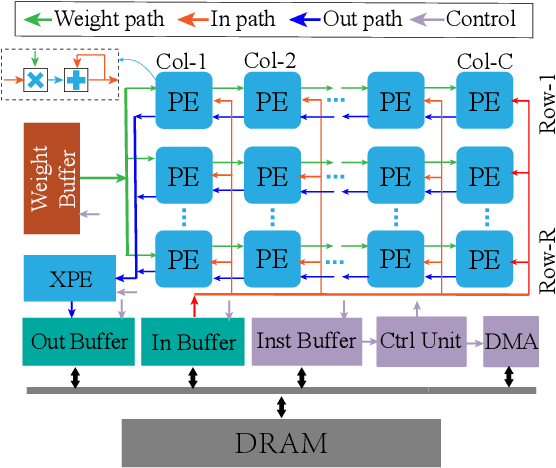
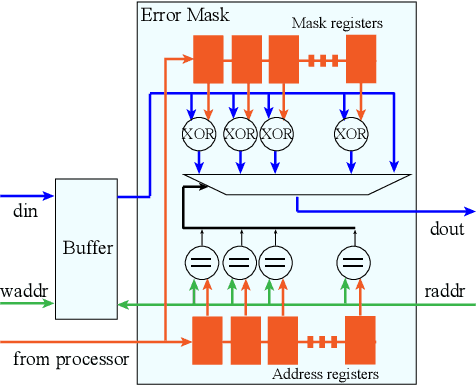
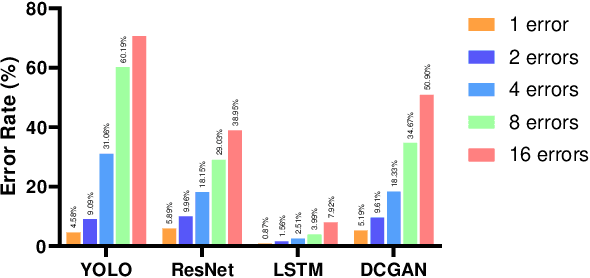
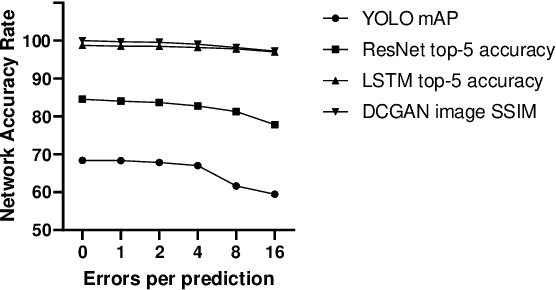
Today, Neural Networks are the basis of breakthroughs in virtually every technical domain. Their application to accelerators has recently resulted in better performance and efficiency in these systems. At the same time, the increasing hardware failures due to the latest (shrinked) semiconductor technology needs to be addressed. Since accelerator systems are often used to back time-critical applications such as self-driving cars or medical diagnosis applications, these hardware failures must be eliminated. Our research evaluates these failures from a systemic point of view. Based on our results, we find critical results for the system reliability enhancement and we further put forth an efficient method to avoid these failures with minimal hardware overhead.
MIDAS: Deep learning human action intention prediction from natural eye movement patterns
Jan 22, 2022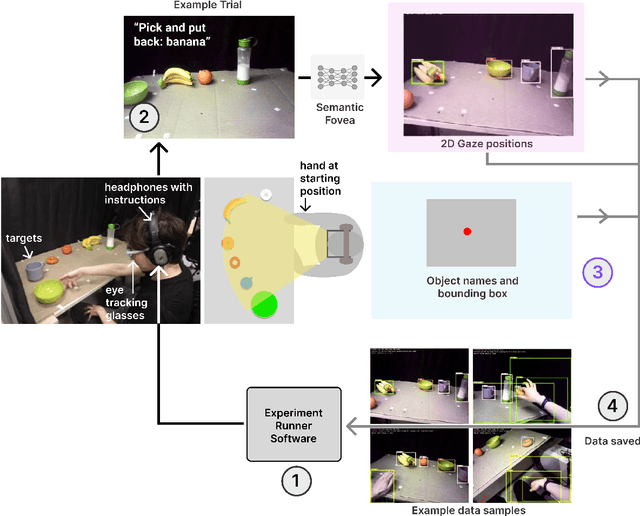
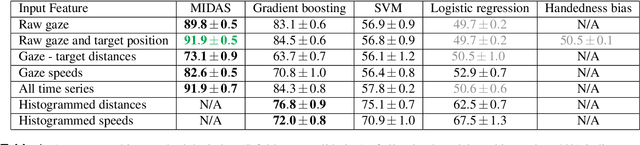
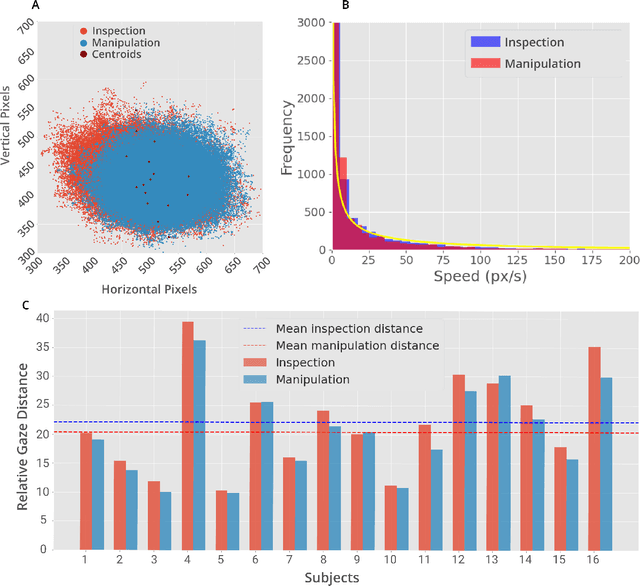
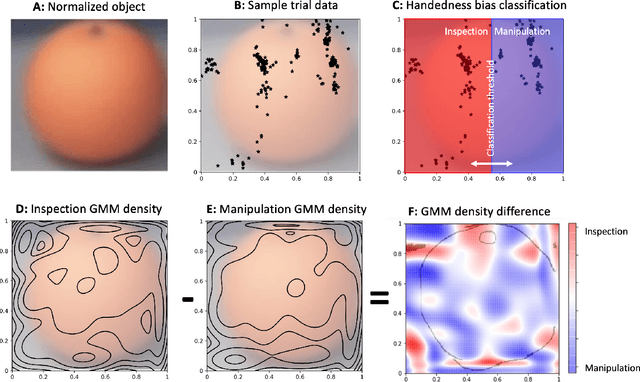
Eye movements have long been studied as a window into the attentional mechanisms of the human brain and made accessible as novelty style human-machine interfaces. However, not everything that we gaze upon, is something we want to interact with; this is known as the Midas Touch problem for gaze interfaces. To overcome the Midas Touch problem, present interfaces tend not to rely on natural gaze cues, but rather use dwell time or gaze gestures. Here we present an entirely data-driven approach to decode human intention for object manipulation tasks based solely on natural gaze cues. We run data collection experiments where 16 participants are given manipulation and inspection tasks to be performed on various objects on a table in front of them. The subjects' eye movements are recorded using wearable eye-trackers allowing the participants to freely move their head and gaze upon the scene. We use our Semantic Fovea, a convolutional neural network model to obtain the objects in the scene and their relation to gaze traces at every frame. We then evaluate the data and examine several ways to model the classification task for intention prediction. Our evaluation shows that intention prediction is not a naive result of the data, but rather relies on non-linear temporal processing of gaze cues. We model the task as a time series classification problem and design a bidirectional Long-Short-Term-Memory (LSTM) network architecture to decode intentions. Our results show that we can decode human intention of motion purely from natural gaze cues and object relative position, with $91.9\%$ accuracy. Our work demonstrates the feasibility of natural gaze as a Zero-UI interface for human-machine interaction, i.e., users will only need to act naturally, and do not need to interact with the interface itself or deviate from their natural eye movement patterns.
Efficient Video Segmentation Models with Per-frame Inference
Feb 24, 2022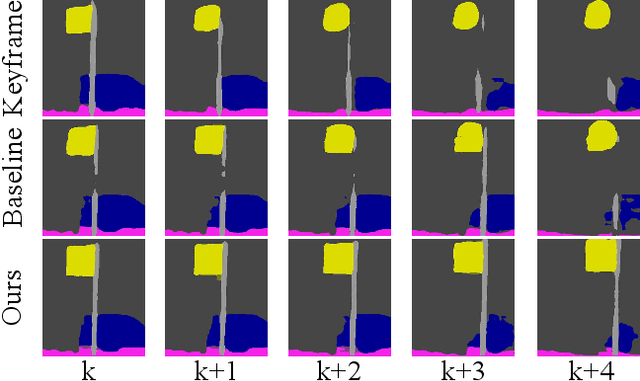
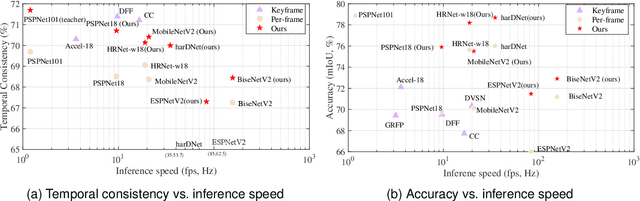
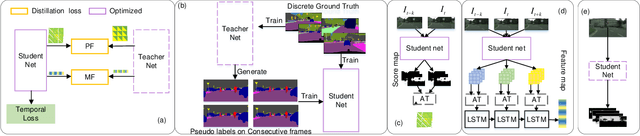
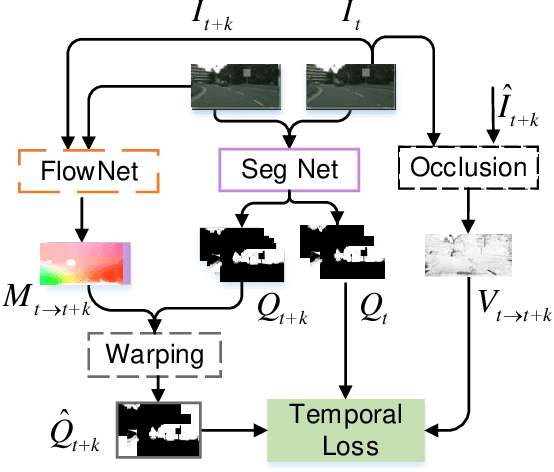
Most existing real-time deep models trained with each frame independently may produce inconsistent results across the temporal axis when tested on a video sequence. A few methods take the correlations in the video sequence into account,e.g., by propagating the results to the neighboring frames using optical flow or extracting frame representations using multi-frame information, which may lead to inaccurate results or unbalanced latency. In this work, we focus on improving the temporal consistency without introducing computation overhead in inference. To this end, we perform inference at each frame. Temporal consistency is achieved by learning from video frames with extra constraints during the training phase. introduced for inference. We propose several techniques to learn from the video sequence, including a temporal consistency loss and online/offline knowledge distillation methods. On the task of semantic video segmentation, weighing among accuracy, temporal smoothness, and efficiency, our proposed method outperforms keyframe-based methods and a few baseline methods that are trained with each frame independently, on datasets including Cityscapes, Camvid, and 300VW-Mask. We further apply our training method to video instance segmentation on YouTubeVISand develop an application of portrait matting in video sequences, by segmenting temporally consistent instance-level trimaps across frames. Experiments show superior qualitative and quantitative results. Code is available at: https://git.io/vidseg.