 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving the quality control of seismic data through active learning
Jan 17, 2022

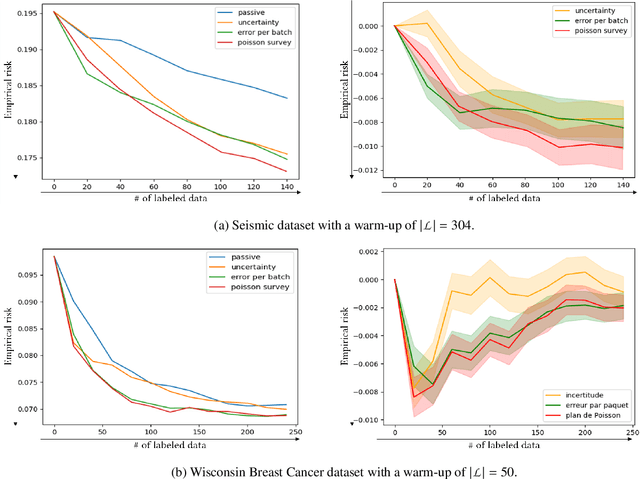
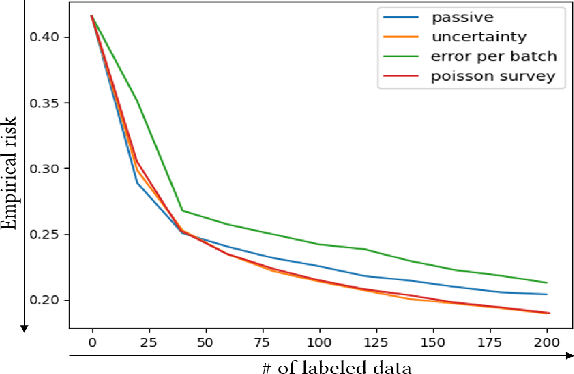
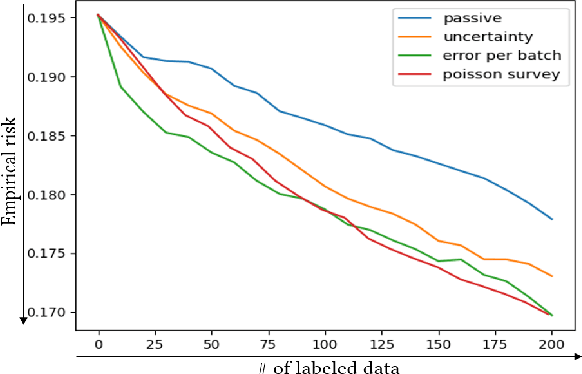
In image denoising problems, the increasing density of available images makes an exhaustive visual inspection impossible and therefore automated methods based on machine-learning must be deployed for this purpose. This is particulary the case in seismic signal processing. Engineers/geophysicists have to deal with millions of seismic time series. Finding the sub-surface properties useful for the oil industry may take up to a year and is very costly in terms of computing/human resources. In particular, the data must go through different steps of noise attenuation. Each denoise step is then ideally followed by a quality control (QC) stage performed by means of human expertise. To learn a quality control classifier in a supervised manner, labeled training data must be available, but collecting the labels from human experts is extremely time-consuming. We therefore propose a novel active learning methodology to sequentially select the most relevant data, which are then given back to a human expert for labeling. Beyond the application in geophysics, the technique we promote in this paper, based on estimates of the local error and its uncertainty, is generic. Its performance is supported by strong empirical evidence, as illustrated by the numerical experiments presented in this article, where it is compared to alternative active learning strategies both on synthetic and real seismic datasets.
Shape-CD: Change-Point Detection in Time-Series Data with Shapes and Neurons
Aug 01, 2020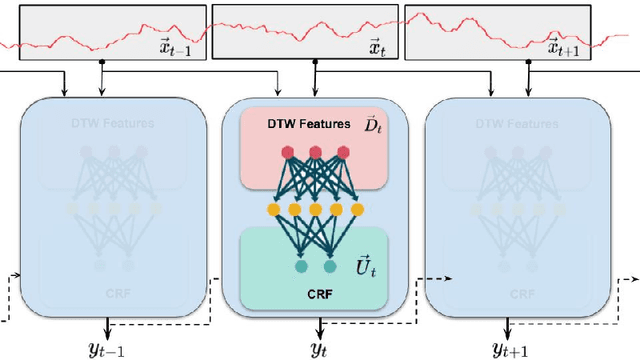
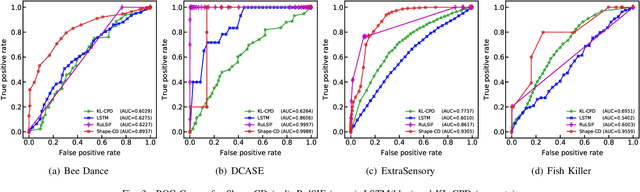
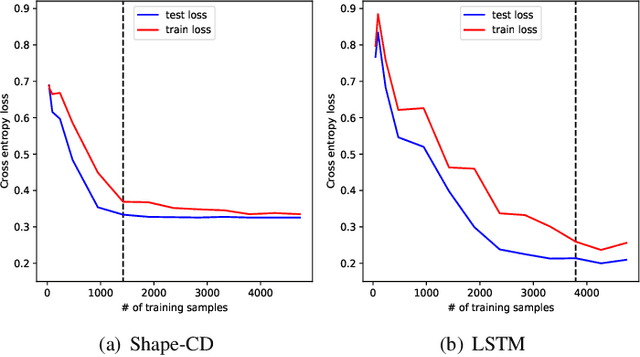
Change-point detection in a time series aims to discover the time points at which some unknown underlying physical process that generates the time-series data has changed. We found that existing approaches become less accurate when the underlying process is complex and generates large varieties of patterns in the time series. To address this shortcoming, we propose Shape-CD, a simple, fast, and accurate change point detection method. Shape-CD uses shape-based features to model the patterns and a conditional neural field to model the temporal correlations among the time regions. We evaluated the performance of Shape-CD using four highly dynamic time-series datasets, including the ExtraSensory dataset with up to 2000 classes. Shape-CD demonstrated improved accuracy (7-60% higher in AUC) and faster computational speed compared to existing approaches. Furthermore, the Shape-CD model consists of only hundreds of parameters and require less data to train than other deep supervised learning models.
Siamese Neural Encoders for Long-Term Indoor Localization with Mobile Devices
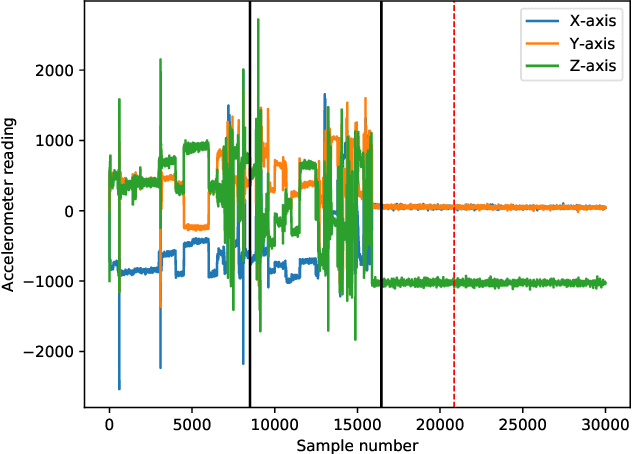
Nov 28, 2021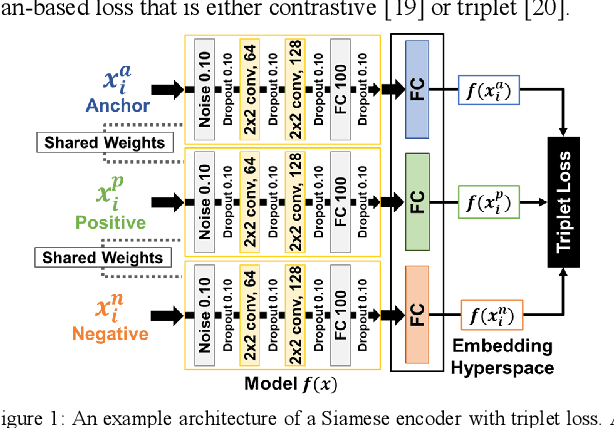
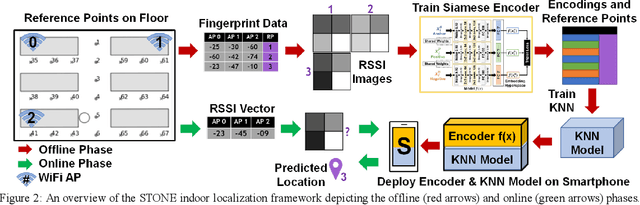
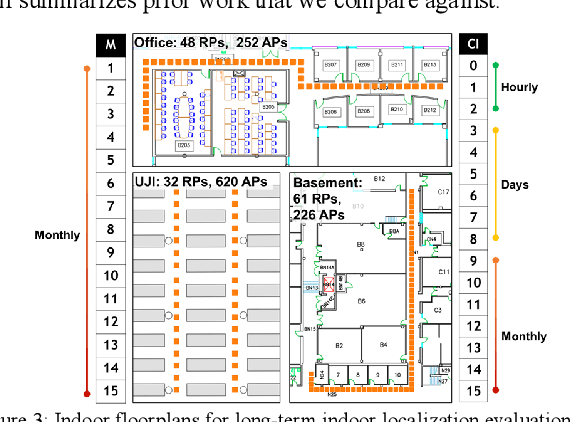
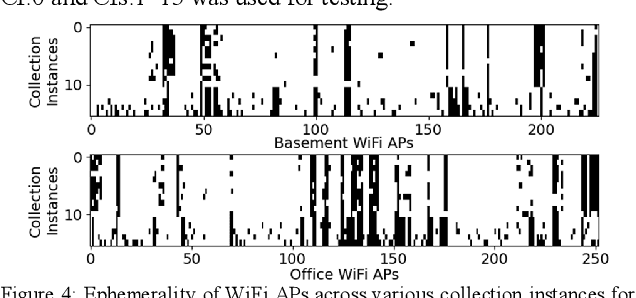
Fingerprinting-based indoor localization is an emerging application domain for enhanced positioning and tracking of people and assets within indoor locales. The superior pairing of ubiquitously available WiFi signals with computationally capable smartphones is set to revolutionize the area of indoor localization. However, the observed signal characteristics from independently maintained WiFi access points vary greatly over time. Moreover, some of the WiFi access points visible at the initial deployment phase may be replaced or removed over time. These factors are often ignored in indoor localization frameworks and cause gradual and catastrophic degradation of localization accuracy post-deployment (over weeks and months). To overcome these challenges, we propose a Siamese neural encoder-based framework that offers up to 40% reduction in degradation of localization accuracy over time compared to the state-of-the-art in the area, without requiring any retraining.
Certifiable Robustness for Nearest Neighbor Classifiers
Jan 17, 2022

ML models are typically trained using large datasets of high quality. However, training datasets often contain inconsistent or incomplete data. To tackle this issue, one solution is to develop algorithms that can check whether a prediction of a model is certifiably robust. Given a learning algorithm that produces a classifier and given an example at test time, a classification outcome is certifiably robust if it is predicted by every model trained across all possible worlds (repairs) of the uncertain (inconsistent) dataset. This notion of robustness falls naturally under the framework of certain answers. In this paper, we study the complexity of certifying robustness for a simple but widely deployed classification algorithm, $k$-Nearest Neighbors ($k$-NN). Our main focus is on inconsistent datasets when the integrity constraints are functional dependencies (FDs). For this setting, we establish a dichotomy in the complexity of certifying robustness w.r.t. the set of FDs: the problem either admits a polynomial time algorithm, or it is coNP-hard. Additionally, we exhibit a similar dichotomy for the counting version of the problem, where the goal is to count the number of possible worlds that predict a certain label. As a byproduct of our study, we also establish the complexity of a problem related to finding an optimal subset repair that may be of independent interest.
No Shifted Augmentations (NSA): compact distributions for robust self-supervised Anomaly Detection
Mar 19, 2022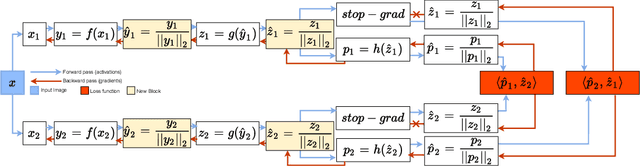
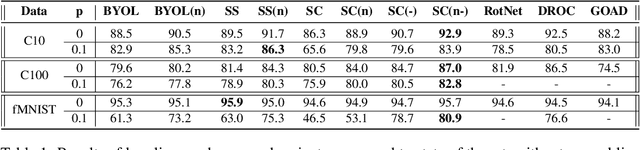
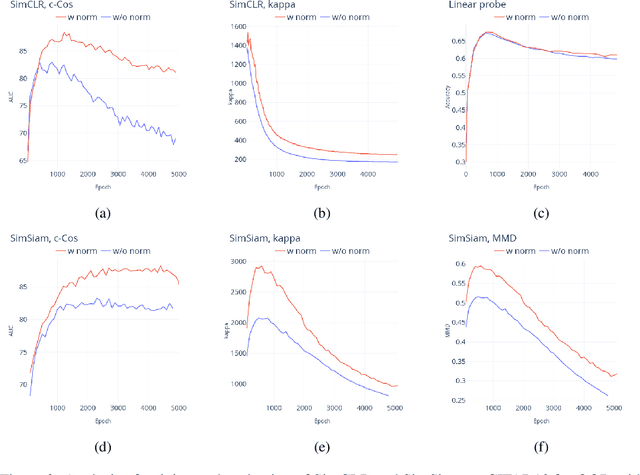
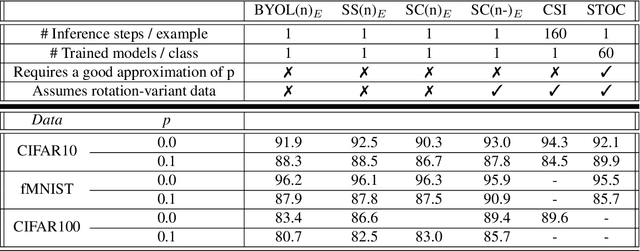
Unsupervised Anomaly detection (AD) requires building a notion of normalcy, distinguishing in-distribution (ID) and out-of-distribution (OOD) data, using only available ID samples. Recently, large gains were made on this task for the domain of natural images using self-supervised contrastive feature learning as a first step followed by kNN or traditional one-class classifiers for feature scoring. Learned representations that are non-uniformly distributed on the unit hypersphere have been shown to be beneficial for this task. We go a step further and investigate how the \emph {geometrical compactness} of the ID feature distribution makes isolating and detecting outliers easier, especially in the realistic situation when ID training data is polluted (i.e. ID data contains some OOD data that is used for learning the feature extractor parameters). We propose novel architectural modifications to the self-supervised feature learning step, that enable such compact distributions for ID data to be learned. We show that the proposed modifications can be effectively applied to most existing self-supervised objectives, with large gains in performance. Furthermore, this improved OOD performance is obtained without resorting to tricks such as using strongly augmented ID images (e.g. by 90 degree rotations) as proxies for the unseen OOD data, as these impose overly prescriptive assumptions about ID data and its invariances. We perform extensive studies on benchmark datasets for one-class OOD detection and show state-of-the-art performance in the presence of pollution in the ID data, and comparable performance otherwise. We also propose and extensively evaluate a novel feature scoring technique based on the angular Mahalanobis distance, and propose a simple and novel technique for feature ensembling during evaluation that enables a big boost in performance at nearly zero run-time cost.
Practical Evaluation of Adversarial Robustness via Adaptive Auto Attack
Mar 10, 2022
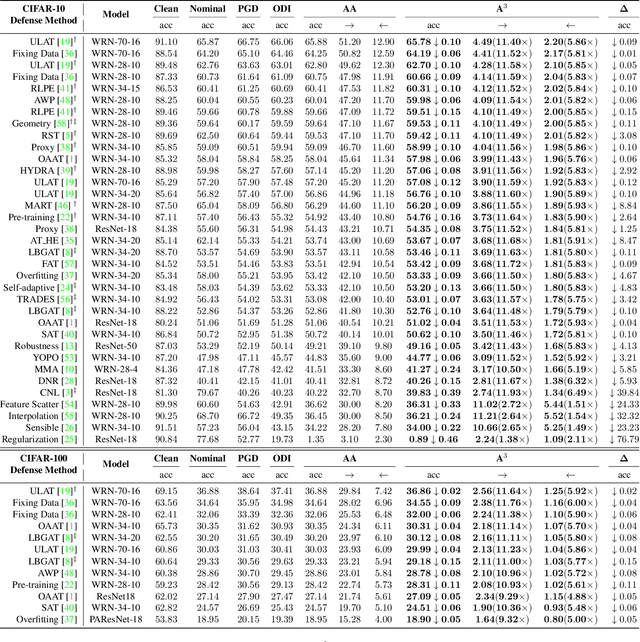
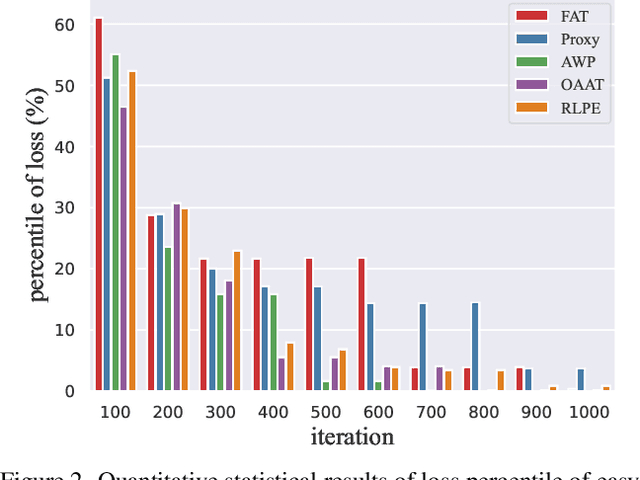
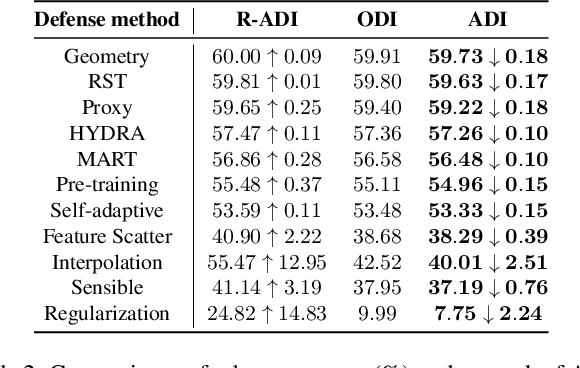
Defense models against adversarial attacks have grown significantly, but the lack of practical evaluation methods has hindered progress. Evaluation can be defined as looking for defense models' lower bound of robustness given a budget number of iterations and a test dataset. A practical evaluation method should be convenient (i.e., parameter-free), efficient (i.e., fewer iterations) and reliable (i.e., approaching the lower bound of robustness). Towards this target, we propose a parameter-free Adaptive Auto Attack (A$^3$) evaluation method which addresses the efficiency and reliability in a test-time-training fashion. Specifically, by observing that adversarial examples to a specific defense model follow some regularities in their starting points, we design an Adaptive Direction Initialization strategy to speed up the evaluation. Furthermore, to approach the lower bound of robustness under the budget number of iterations, we propose an online statistics-based discarding strategy that automatically identifies and abandons hard-to-attack images. Extensive experiments demonstrate the effectiveness of our A$^3$. Particularly, we apply A$^3$ to nearly 50 widely-used defense models. By consuming much fewer iterations than existing methods, i.e., $1/10$ on average (10$\times$ speed up), we achieve lower robust accuracy in all cases. Notably, we won $\textbf{first place}$ out of 1681 teams in CVPR 2021 White-box Adversarial Attacks on Defense Models competitions with this method. Code is available at: $\href{https://github.com/liuye6666/adaptive_auto_attack}{https://github.com/liuye6666/adaptive\_auto\_attack}$
Ensemble Methods for Survival Data with Time-Varying Covariates
May 31, 2020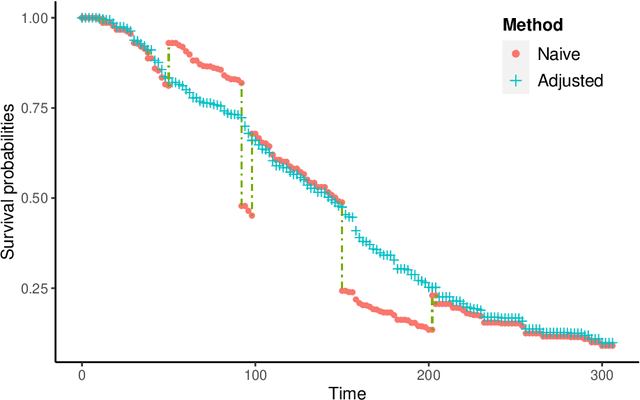
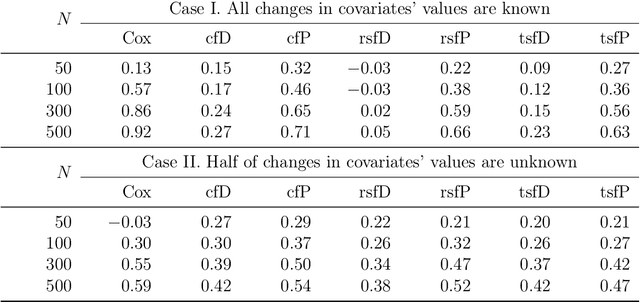
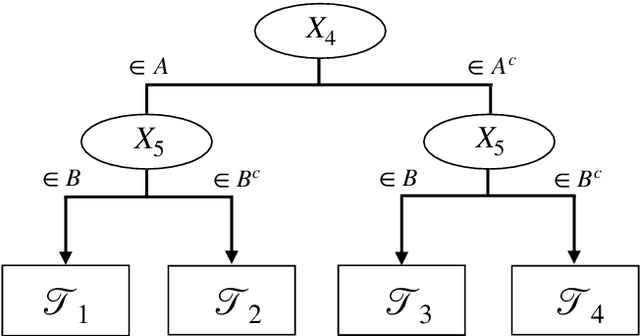
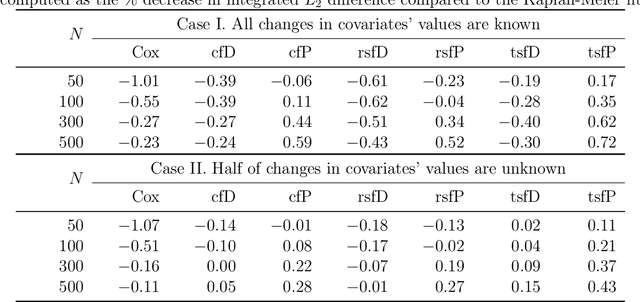
We propose two new survival forests for survival data with time-varying covariates. They are generalizations of random survival forest and conditional inference forest -- the traditional survival forests for right-censored data with time-invariant covariates. We investigate the properties of these new forests, as well as that of the recently-proposed transformation forest, and compare their performances with that of the Cox model via a comprehensive simulation study. In particular, the simulations compare the performance of the forests when all changes in the covariates' values are known with the case when not all changes are known. We also study the forests under the proportional hazards setting as well as the non-proportional hazards setting, where the forests based on log-rank splitting tend to perform worse than does the transformation forest. We then provide guidance for choosing among the modeling methods. Finally, we show that the performance of the survival forests for time-invariant covariate data is broadly similar to that found for time-varying covariate data.
Imitation and Adaptation Based on Consistency: A Quadruped Robot Imitates Animals from Videos Using Deep Reinforcement Learning
Mar 02, 2022

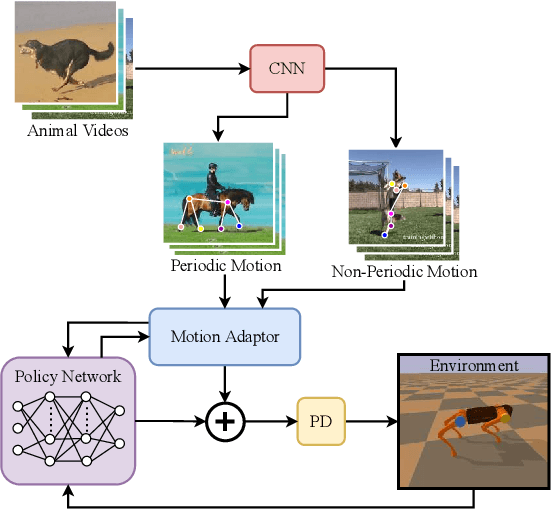
The essence of quadrupeds' movements is the movement of the center of gravity, which has a pattern in the action of quadrupeds. However, the gait motion planning of the quadruped robot is time-consuming. Animals in nature can provide a large amount of gait information for robots to learn and imitate. Common methods learn animal posture with a motion capture system or numerous motion data points. In this paper, we propose a video imitation adaptation network (VIAN) that can imitate the action of animals and adapt it to the robot from a few seconds of video. The deep learning model extracts key points during animal motion from videos. The VIAN eliminates noise and extracts key information of motion with a motion adaptor, and then applies the extracted movements function as the motion pattern into deep reinforcement learning (DRL). To ensure similarity between the learning result and the animal motion in the video, we introduce rewards that are based on the consistency of the motion. DRL explores and learns to maintain balance from movement patterns from videos, imitates the action of animals, and eventually, allows the model to learn the gait or skills from short motion videos of different animals and to transfer the motion pattern to the real robot.
An Intrusion Response System utilizing Deep Q-Networks and System Partitions
Feb 16, 2022
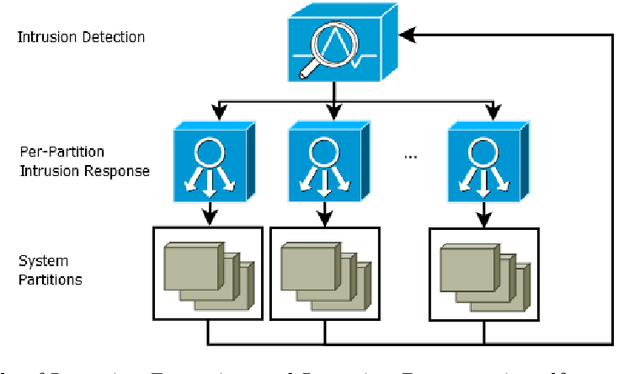
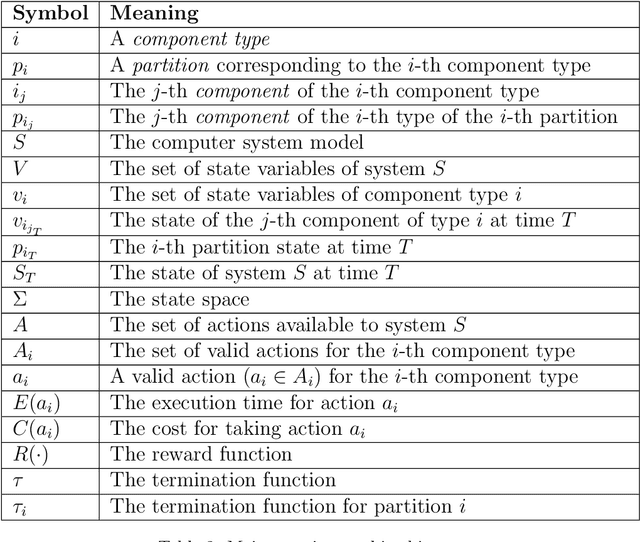
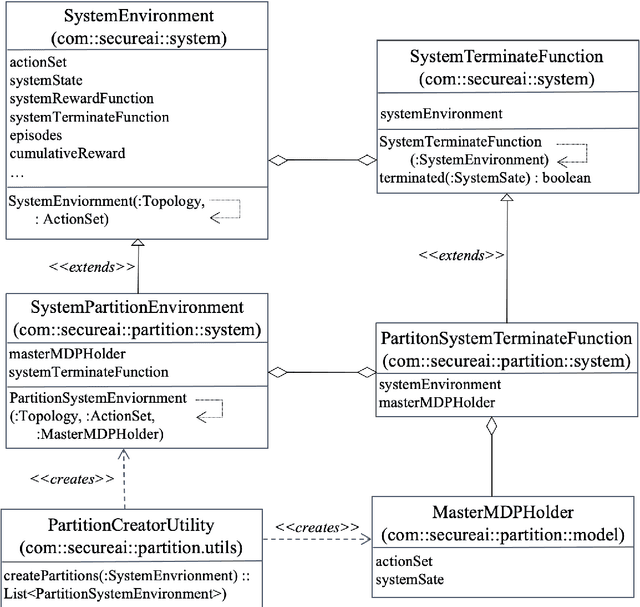
Intrusion Response is a relatively new field of research. Recent approaches for the creation of Intrusion Response Systems (IRSs) use Reinforcement Learning (RL) as a primary technique for the optimal or near-optimal selection of the proper countermeasure to take in order to stop or mitigate an ongoing attack. However, most of them do not consider the fact that systems can change over time or, in other words, that systems exhibit a non-stationary behavior. Furthermore, stateful approaches, such as those based on RL, suffer the curse of dimensionality, due to a state space growing exponentially with the size of the protected system. In this paper, we introduce and develop an IRS software prototype, named irs-partition. It leverages the partitioning of the protected system and Deep Q-Networks to address the curse of dimensionality by supporting a multi-agent formulation. Furthermore, it exploits transfer learning to follow the evolution of non-stationary systems.
SmartON: Just-in-Time Active Event Detection on Energy Harvesting Systems
Mar 01, 2021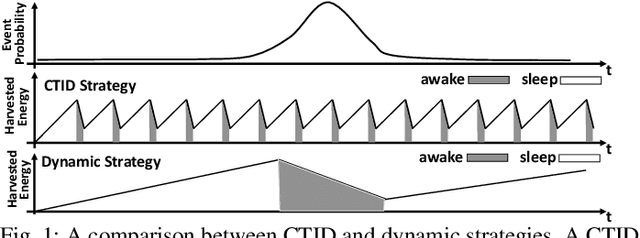
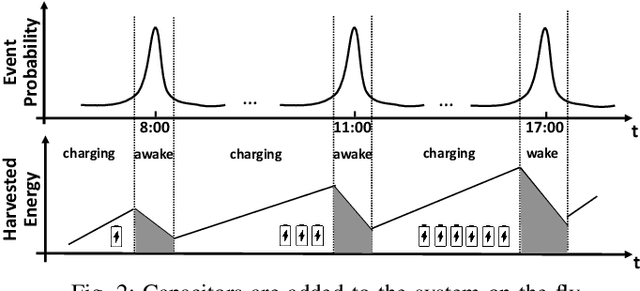
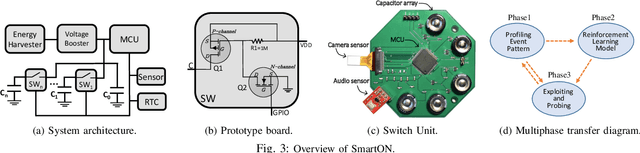
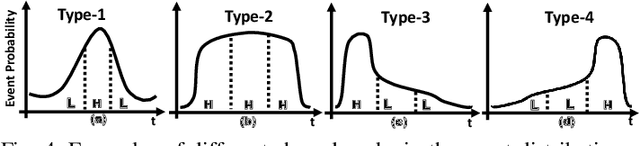
We propose SmartON, a batteryless system that learns to wake up proactively at the right moment in order to detect events of interest. It does so by adapting the duty cycle to match the distribution of event arrival times under the constraints of harvested energy. While existing energy harvesting systems either wake up periodically at a fixed rate to sense and process the data, or wake up only in accordance with the availability of the energy source, SmartON employs a three-phase learning framework to learn the energy harvesting pattern as well as the pattern of events at run-time, and uses that knowledge to wake itself up when events are most likely to occur. The three-phase learning framework enables rapid adaptation to environmental changes in both short and long terms. Being able to remain asleep more often than a CTID (charging-then-immediate-discharging) wake-up system and adapt to the event pattern, SmartON is able to reduce energy waste, increase energy efficiency, and capture more events. To realize SmartON we have developed a dedicated hardware platform whose power management module activates capacitors on-the-fly to dynamically increase its storage capacitance. We conduct both simulation-driven and real-system experiments to demonstrate that SmartON captures 1X--7X more events and is 8X--17X more energy-efficient than a CTID system.