 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Effects on Pre-trained Models for Language Processing Tasks
Nov 24, 2021
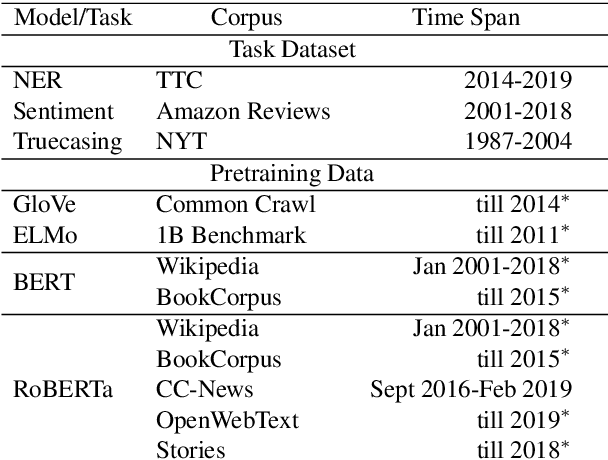
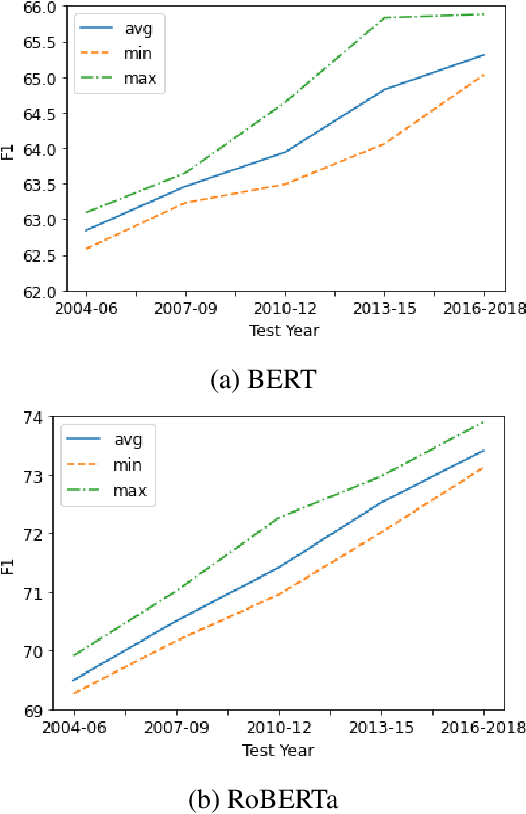
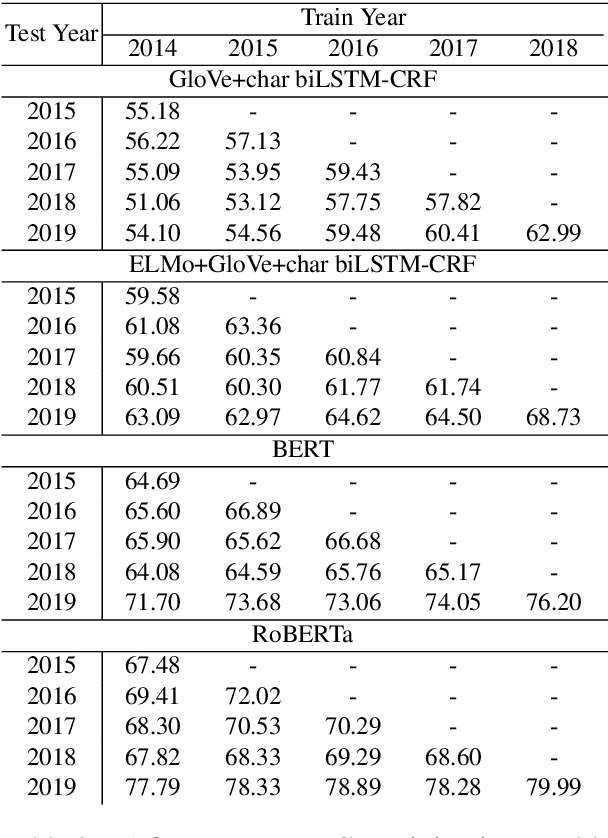
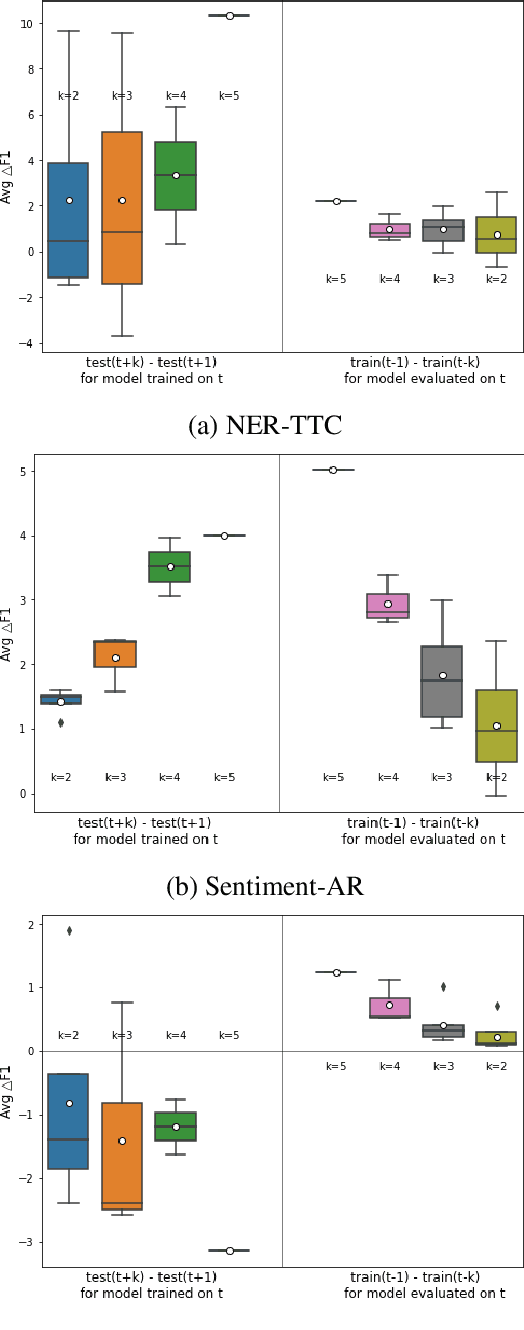
Keeping the performance of language technologies optimal as time passes is of great practical interest. Here we survey prior work concerned with the effect of time on system performance, establishing more nuanced terminology for discussing the topic and proper experimental design to support solid conclusions about the observed phenomena. We present a set of experiments with systems powered by large neural pretrained representations for English to demonstrate that {\em temporal model deterioration} is not as big a concern, with some models in fact improving when tested on data drawn from a later time period. It is however the case that {\em temporal domain adaptation} is beneficial, with better performance for a given time period possible when the system is trained on temporally more recent data. Our experiments reveal that the distinctions between temporal model deterioration and temporal domain adaptation becomes salient for systems built upon pretrained representations. Finally we examine the efficacy of two approaches for temporal domain adaptation without human annotations on new data, with self-labeling proving to be superior to continual pre-training. Notably, for named entity recognition, self-labeling leads to better temporal adaptation than human annotation.
A Benchmark Comparison of Learned Control Policies for Agile Quadrotor Flight
Feb 22, 2022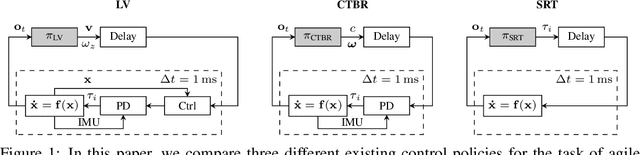
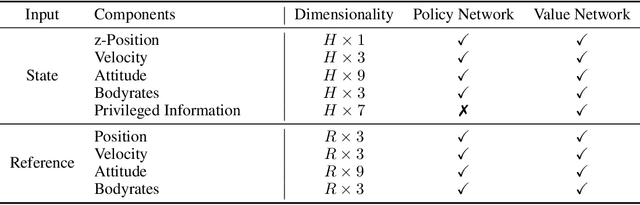
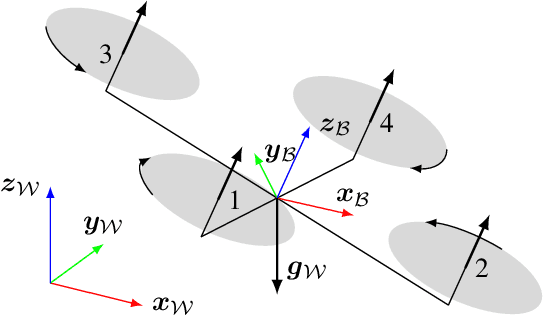

Quadrotors are highly nonlinear dynamical systems that require carefully tuned controllers to be pushed to their physical limits. Recently, learning-based control policies have been proposed for quadrotors, as they would potentially allow learning direct mappings from high-dimensional raw sensory observations to actions. Due to sample inefficiency, training such learned controllers on the real platform is impractical or even impossible. Training in simulation is attractive but requires to transfer policies between domains, which demands trained policies to be robust to such domain gap. In this work, we make two contributions: (i) we perform the first benchmark comparison of existing learned control policies for agile quadrotor flight and show that training a control policy that commands body-rates and thrust results in more robust sim-to-real transfer compared to a policy that directly specifies individual rotor thrusts, (ii) we demonstrate for the first time that such a control policy trained via deep reinforcement learning can control a quadrotor in real-world experiments at speeds over 45km/h.
* 6 pages (+1 references)
Deep Task-Based Analog-to-Digital Conversion
Jan 29, 2022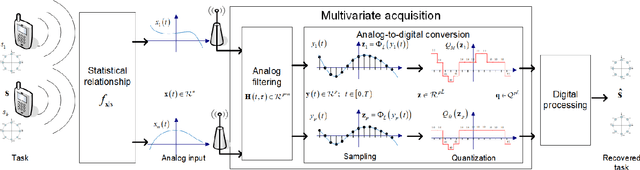
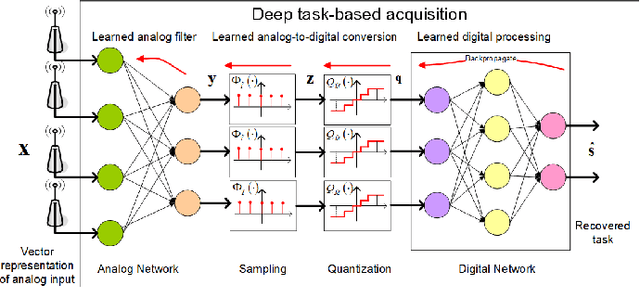
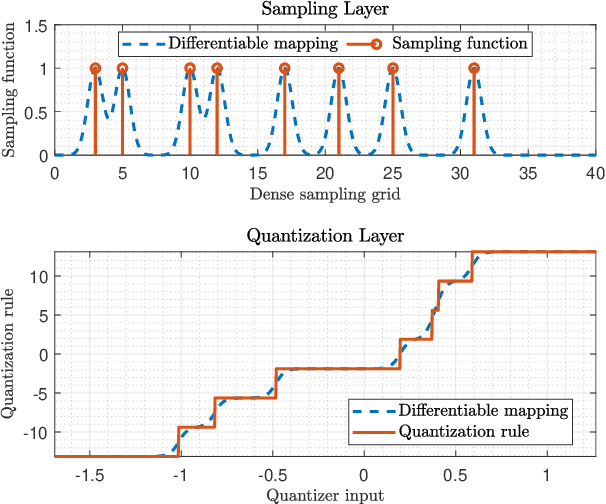
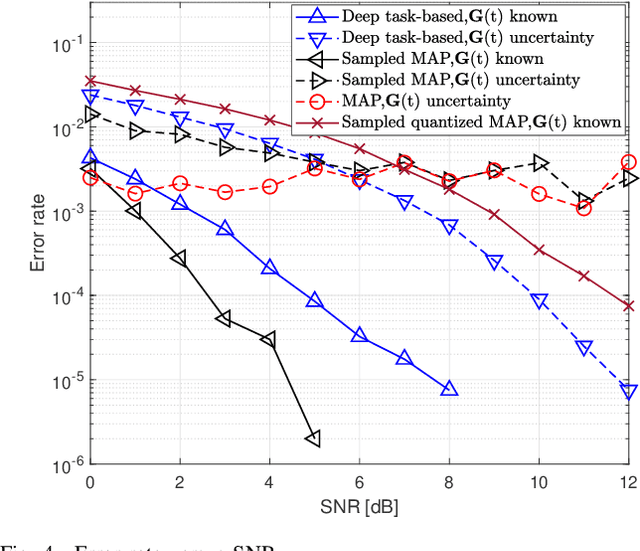
Analog-to-digital converters (ADCs) allow physical signals to be processed using digital hardware. Their conversion consists of two stages: Sampling, which maps a continuous-time signal into discrete-time, and quantization, i.e., representing the continuous-amplitude quantities using a finite number of bits. ADCs typically implement generic uniform conversion mappings that are ignorant of the task for which the signal is acquired, and can be costly when operating in high rates and fine resolutions. In this work we design task-oriented ADCs which learn from data how to map an analog signal into a digital representation such that the system task can be efficiently carried out. We propose a model for sampling and quantization that facilitates the learning of non-uniform mappings from data. Based on this learnable ADC mapping, we present a mechanism for optimizing a hybrid acquisition system comprised of analog combining, tunable ADCs with fixed rates, and digital processing, by jointly learning its components end-to-end. Then, we show how one can exploit the representation of hybrid acquisition systems as deep network to optimize the sampling rate and quantization rate given the task by utilizing Bayesian meta-learning techniques. We evaluate the proposed deep task-based ADC in two case studies: the first considers symbol detection in multi-antenna digital receivers, where multiple analog signals are simultaneously acquired in order to recover a set of discrete information symbols. The second application is the beamforming of analog channel data acquired in ultrasound imaging. Our numerical results demonstrate that the proposed approach achieves performance which is comparable to operating with high sampling rates and fine resolution quantization, while operating with reduced overall bit rate.
Online Self-Calibration for Visual-Inertial Navigation Systems: Models, Analysis and Degeneracy
Jan 26, 2022

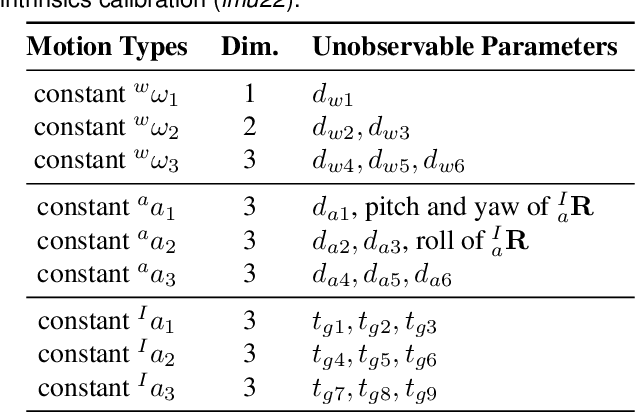
In this paper, we study in-depth the problem of online self-calibration for robust and accurate visual-inertial state estimation. In particular, we first perform a complete observability analysis for visual-inertial navigation systems (VINS) with full calibration of sensing parameters, including IMU and camera intrinsics and IMU-camera spatial-temporal extrinsic calibration, along with readout time of rolling shutter (RS) cameras (if used). We investigate different inertial model variants containing IMU intrinsic parameters that encompass most commonly used models for low-cost inertial sensors. The observability analysis results prove that VINS with full sensor calibration has four unobservable directions, corresponding to the system's global yaw and translation, while all sensor calibration parameters are observable given fully-excited 6-axis motion. Moreover, we, for the first time, identify primitive degenerate motions for IMU and camera intrinsic calibration. Each degenerate motion profile will cause a set of calibration parameters to be unobservable and any combination of these degenerate motions are still degenerate. Extensive Monte-Carlo simulations and real-world experiments are performed to validate both the observability analysis and identified degenerate motions, showing that online self-calibration improves system accuracy and robustness to calibration inaccuracies. We compare the proposed online self-calibration on commonly-used IMUs against the state-of-art offline calibration toolbox Kalibr, and show that the proposed system achieves better consistency and repeatability. Based on our analysis and experimental evaluations, we also provide practical guidelines for how to perform online IMU-camera sensor self-calibration.
$\text{ISS}_2$: An Extension of Iterative Source Steering Algorithm for Majorization-Minimization-Based Independent Vector Analysis
Feb 02, 2022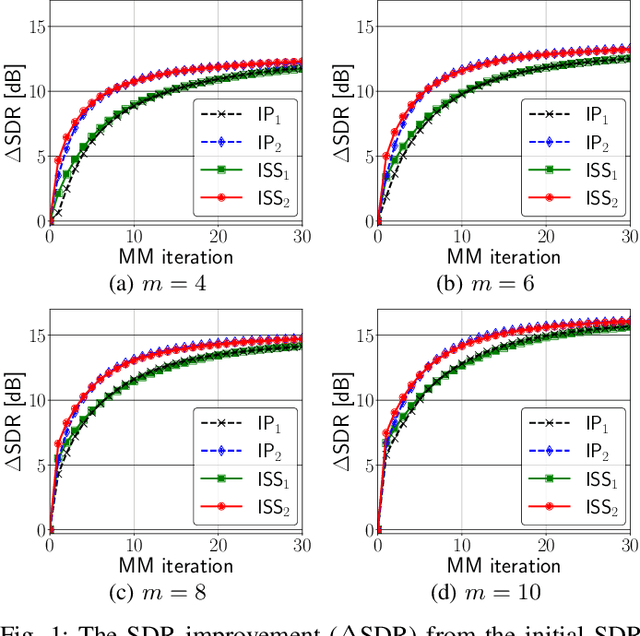
A majorization-minimization (MM) algorithm for independent vector analysis optimizes a separation matrix $W = [w_1, \ldots, w_m]^h \in \mathbb{C}^{m \times m}$ by minimizing a surrogate function of the form $\mathcal{L}(W) = \sum_{i = 1}^m w_i^h V_i w_i - \log | \det W |^2$, where $m \in \mathbb{N}$ is the number of sensors and positive definite matrices $V_1,\ldots,V_m \in \mathbb{C}^{m \times m}$ are constructed in each MM iteration. For $m \geq 3$, no algorithm has been found to obtain a global minimum of $\mathcal{L}(W)$. Instead, block coordinate descent (BCD) methods with closed-form update formulas have been developed for minimizing $\mathcal{L}(W)$ and shown to be effective. One such BCD is called iterative projection (IP) that updates one or two rows of $W$ in each iteration. Another BCD is called iterative source steering (ISS) that updates one column of the mixing matrix $A = W^{-1}$ in each iteration. Although the time complexity per iteration of ISS is $m$ times smaller than that of IP, the conventional ISS converges slower than the current fastest IP (called $\text{IP}_2$) that updates two rows of $W$ in each iteration. We here extend this ISS to $\text{ISS}_2$ that can update two columns of $A$ in each iteration while maintaining its small time complexity. To this end, we provide a unified way for developing new ISS type methods from which $\text{ISS}_2$ as well as the conventional ISS can be immediately obtained in a systematic manner. Numerical experiments to separate reverberant speech mixtures show that our $\text{ISS}_2$ converges in fewer MM iterations than the conventional ISS, and is comparable to $\text{IP}_2$.
A hybrid 2-stage vision transformer for AI-assisted 5 class pathologic diagnosis of gastric endoscopic biopsies
Feb 17, 2022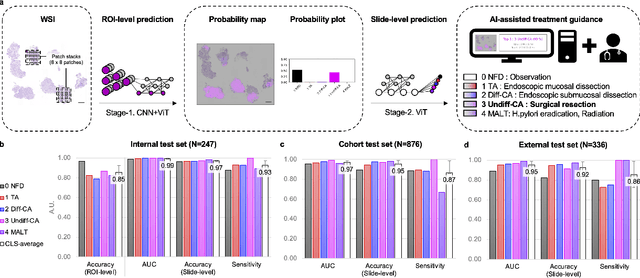
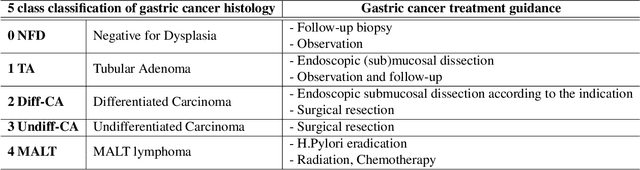
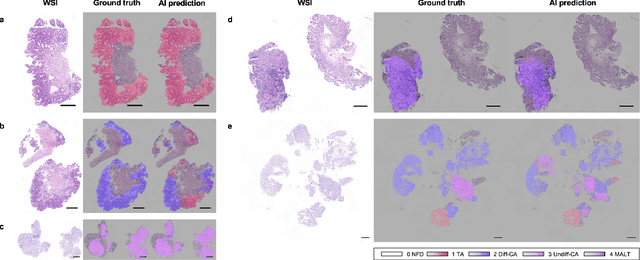
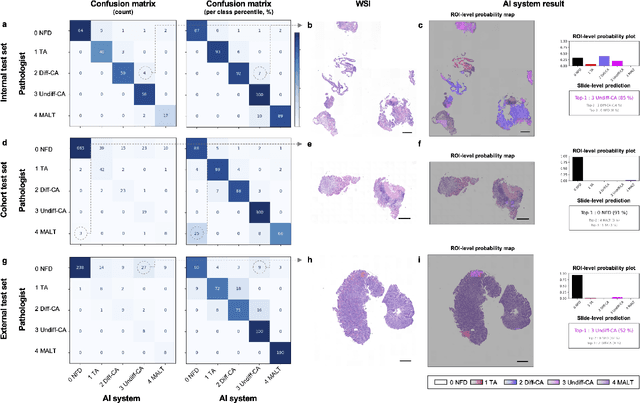
Gastric endoscopic screening is an effective way to decide appropriate gastric cancer (GC) treatment at an early stage, reducing GC-associated mortality rate. Although artificial intelligence (AI) has brought a great promise to assist pathologist to screen digitalized whole slide images, automatic classification systems for guiding proper GC treatment based on clinical guideline are still lacking. Here, we propose an AI system classifying 5 classes of GC histology, which can be perfectly matched to general treatment guidance. The AI system, mimicking the way pathologist understand slides through multi-scale self-attention mechanism using a 2-stage Vision Transformer, demonstrates clinical capability by achieving diagnostic sensitivity of above 85% for both internal and external cohort analysis. Furthermore, AI-assisted pathologists showed significantly improved diagnostic sensitivity by 10% within 18% saved screening time compared to human pathologists. Our AI system has a great potential for providing presumptive pathologic opinion for deciding proper treatment for early GC patients.
Joint Channel Estimation and Synchronization Techniques for Time Interleaved Block Windowed Burst OFDM
Mar 30, 2021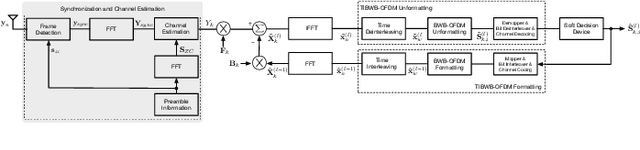
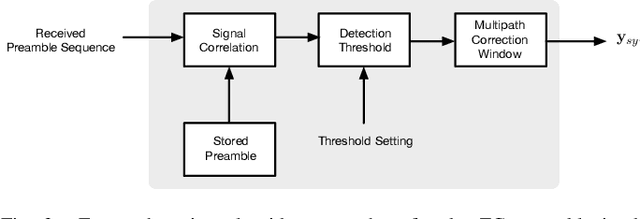
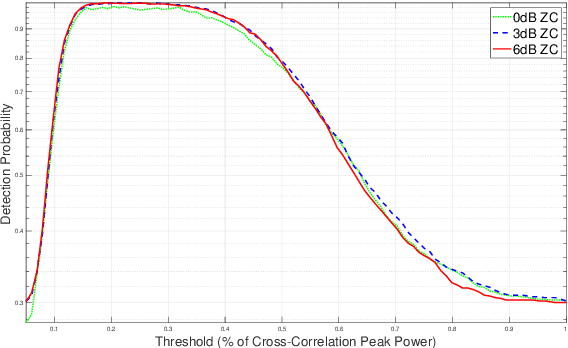
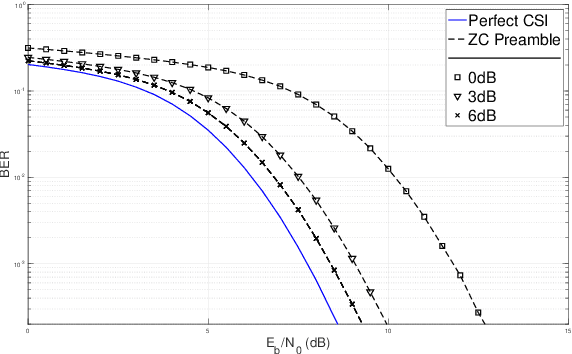
From a conceptual perspective, 5G technology promises to deliver low latency, high data rate and more reliable connections for the next generations of communication systems. To face these demands, modulation schemes based on Orthogonal Frequency Domain Multiplexing (OFDM) can accommodate these requirements for wireless systems. On the other hand, several hybrid OFDM-based systems such as the Time-Interleaved Block Windowed Burst Orthogonal Frequency Division Multiplexing (TIBWB-OFDM) are capable of achieving even better spectral confinement and power efficiency. This paper addresses to the implementation of the TIBWB-OFDM system in a more realistic and practical wireless link scenarios by addressing the challenges of proper and reliable channel estimation and frame synchronization. We propose to incorporate a preamble formed by optimum correlation training sequences, such as the Zadoff-Chu (ZC) sequences. The added ZC preamble sequence is used to jointly estimate the frame beginning, through signal correlation strategies and a threshold decision device, and acquire the channel state information (CSI), by employing estimators based on the preamble sequence and the transmitted data. The employed receiver estimators show that it is possible to detect the TIBWB-OFDM frame beginning and provide a close BER performance comparatively to the one where the perfect channel is known.
Learning-based Support Estimation in Sublinear Time
Jun 15, 2021
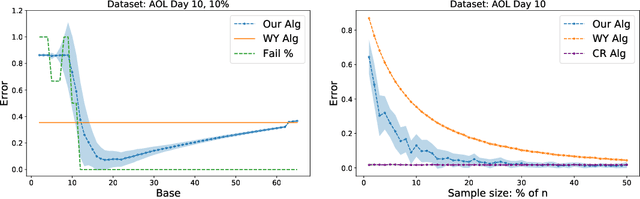
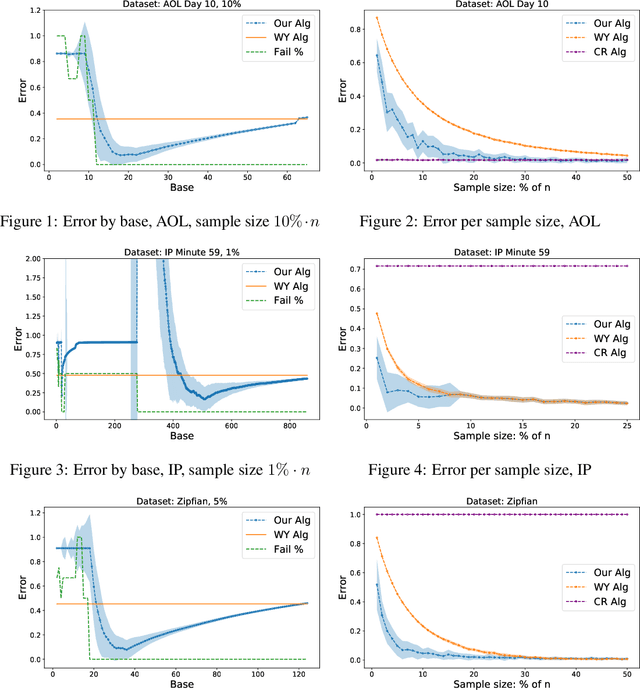
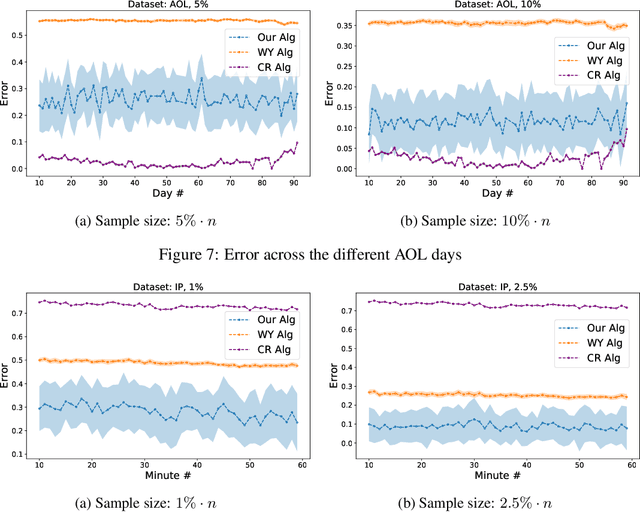
We consider the problem of estimating the number of distinct elements in a large data set (or, equivalently, the support size of the distribution induced by the data set) from a random sample of its elements. The problem occurs in many applications, including biology, genomics, computer systems and linguistics. A line of research spanning the last decade resulted in algorithms that estimate the support up to $ \pm \varepsilon n$ from a sample of size $O(\log^2(1/\varepsilon) \cdot n/\log n)$, where $n$ is the data set size. Unfortunately, this bound is known to be tight, limiting further improvements to the complexity of this problem. In this paper we consider estimation algorithms augmented with a machine-learning-based predictor that, given any element, returns an estimation of its frequency. We show that if the predictor is correct up to a constant approximation factor, then the sample complexity can be reduced significantly, to \[ \ \log (1/\varepsilon) \cdot n^{1-\Theta(1/\log(1/\varepsilon))}. \] We evaluate the proposed algorithms on a collection of data sets, using the neural-network based estimators from {Hsu et al, ICLR'19} as predictors. Our experiments demonstrate substantial (up to 3x) improvements in the estimation accuracy compared to the state of the art algorithm.
Last-Iterate Convergence of Saddle Point Optimizers via High-Resolution Differential Equations
Dec 27, 2021
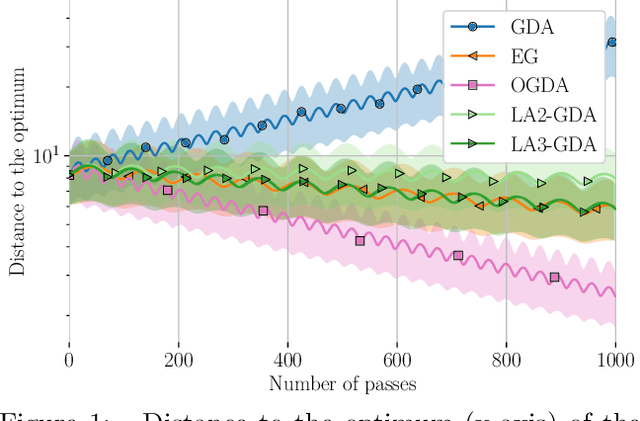

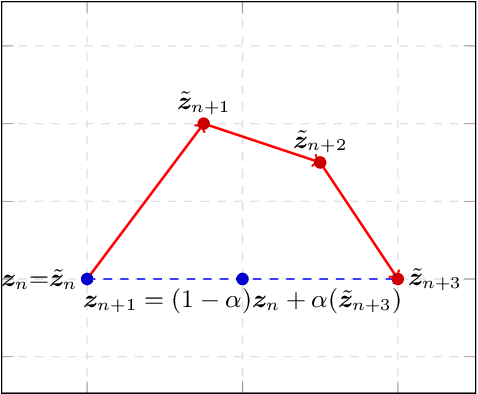
Several widely-used first-order saddle point optimization methods yield an identical continuous-time ordinary differential equation (ODE) to that of the Gradient Descent Ascent (GDA) method when derived naively. However, their convergence properties are very different even on simple bilinear games. We use a technique from fluid dynamics called High-Resolution Differential Equations (HRDEs) to design ODEs of several saddle point optimization methods. On bilinear games, the convergence properties of the derived HRDEs correspond to that of the starting discrete methods. Using these techniques, we show that the HRDE of Optimistic Gradient Descent Ascent (OGDA) has last-iterate convergence for general monotone variational inequalities. To our knowledge, this is the first continuous-time dynamics shown to converge for such a general setting. Moreover, we provide the rates for the best-iterate convergence of the OGDA method, relying solely on the first-order smoothness of the monotone operator.
Shape-CD: Change-Point Detection in Time-Series Data with Shapes and Neurons
Aug 01, 2020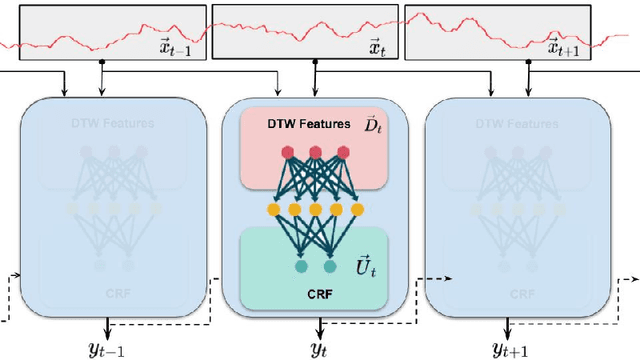
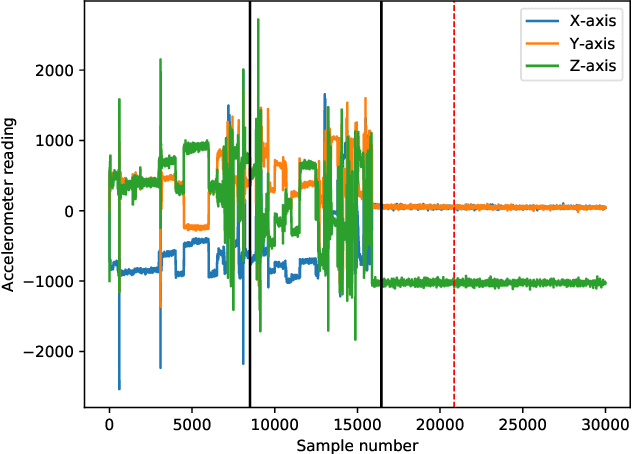
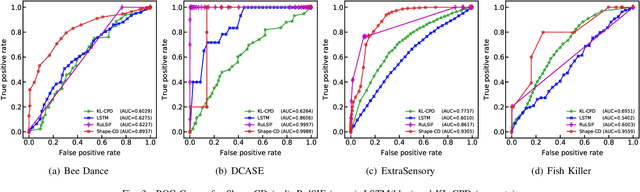
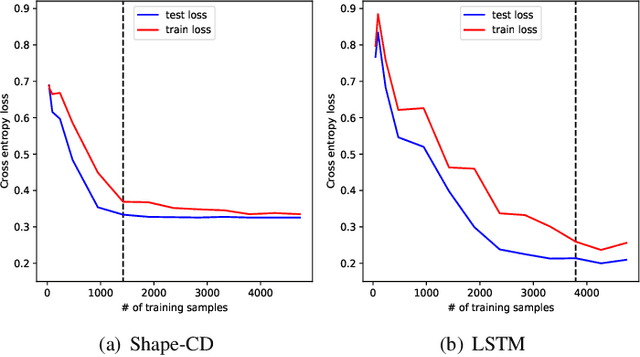
Change-point detection in a time series aims to discover the time points at which some unknown underlying physical process that generates the time-series data has changed. We found that existing approaches become less accurate when the underlying process is complex and generates large varieties of patterns in the time series. To address this shortcoming, we propose Shape-CD, a simple, fast, and accurate change point detection method. Shape-CD uses shape-based features to model the patterns and a conditional neural field to model the temporal correlations among the time regions. We evaluated the performance of Shape-CD using four highly dynamic time-series datasets, including the ExtraSensory dataset with up to 2000 classes. Shape-CD demonstrated improved accuracy (7-60% higher in AUC) and faster computational speed compared to existing approaches. Furthermore, the Shape-CD model consists of only hundreds of parameters and require less data to train than other deep supervised learning models.